#爬取公司为【600080金花股份、600085同仁堂、600161天坛生物、600195中牧股份、600200江苏吴中、600201生物股份、600216浙江医药、600267海正药业、600276恒瑞医药、600351亚宝药业】
'################################一键下载年报##############################'
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import pandas as pd
import re
from filter_url import filter_words,filter_date,start_end_10y,filter_nb_10y,prepare_hrefs_years
from download import download_pdf,download_pdfs,download_pdfs_codes
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
def get_table_sse(code):
browser = webdriver.Edge()
browser.set_window_size(1550, 830)
url = "http://www.sse.com.cn/disclosure/listedinfo/regular/"
browser.get(url)
time.sleep(3)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)#'601919'
selector = ".sse_outerItem:nth-child(4) .filter-option-inner-inner"
browser.find_element(By.CSS_SELECTOR, selector).click()
browser.find_element(By.LINK_TEXT,"年报").click()
time.sleep(3)
#
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
#
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
#
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
#
browser.quit()
#获取元素
def get_data(tr):
p_td = re.compile('(.*?)',re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>')+1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>')+1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="')+6
e = tds[2].find('.pdf"')+4
href = 'http://www.sse.com.cn'+tds[2][s:e]
s = tds[2].find('$(this))">')+10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_table(fname,save=True):
f = open(fname,encoding='utf-8')
html = f.read()
f.close()
#
p = re.compile('
(.+?)
',re.DOTALL)
trs = p.findall(html)
#
trs_new = []
for tr in trs:
if tr.strip()!='':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code':[d[0] for d in data_all],
'name':[d[1] for d in data_all],
'href':[d[2] for d in data_all],
'title':[d[3] for d in data_all],
'date':[d[4] for d in data_all]
})
df = filter_nb_10y(df,keep_words=['年报','年度报告'],exclude_words=['摘要'],start='') #将df处理掉摘要等
tp = prepare_hrefs_years(df) #只留下链接和年份
download_pdfs(tp[0],code,tp[1]) #下载pdf
#
if save:
df.to_csv(f'{fname[0:-5]}.csv')
return(df)
#解析html,获取df并处理掉摘要、只留下代码和链接,并一键下载年报
codes = ['600080','600085','600161','600195','600200','600201','600216','600267','600276','600351']
for code in codes:
get_table_sse(code)
fname = f'{code}.html'
parse_table(fname,save=True)
#调用函数,一键下载所有年报
'############################下载年报代码定义##############################'
import requests
import os
import time
codes = ['600080','600085','600129','600161','600195 ','600196','600200','600201','600216','600222']
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
def download_pdf(href,code,year):
r = requests.get(href,allow_redirects=True)
pdf_name = f'{code}_{year}.pdf'
f = open(pdf_name,'wb')
f.write(r.content)
f.close()
#
r.close()
def download_pdfs(hrefs,code,years):
for i in range(len(hrefs)):
href = hrefs[i]
year = years[i]
download_pdf(href,code,year)
time.sleep(30)
return()
def download_pdfs_codes(list_hrefs,codes,list_years):
for i in range(len(list_hrefs)):
hrefs = list_hrefs[i]
years = list_years[i]
code = code[i]
download_pdf(hrefs,code,years)
return()
'###########################年报处理代码定义###############################'
import datetime
def filter_words(words,df,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df['title']])
else:
ls.append([word not in f for f in df['title']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
def filter_date(start,end,df):
date = df['date']
v = [d>=start and d<=end for d in date]
df_new = df[v]
return(df_new)
def start_end_10y():
dt_now = datetime.datetime.now()
current_year = dt_now.year
start = f'{current_year-9}-01-01'
end = f'{current_year}-12-31'
return((start,end))
def filter_nb_10y(df,
keep_words=['年报','年度报告','年度报告(修订版)'],
exclude_words=[['摘要']],
start=''):
if start == '':
start,end = start_end_10y()
else:
start_y = int(start[0:4])
end = f'{start_y+9}-12-31'
#
df = filter_words(keep_words,df,include=True)
df = filter_words(exclude_words,df,include=False)
df = filter_date(start,end,df)
return(df)
def prepare_hrefs_years(df):
hrefs = df['href'].to_list()
years = [int(d[:4])-1 for d in df['date']]
return((hrefs,years))
结果
二、数据处理与筛选
2.1提取公司基础信息
# 利用file_name_walk找出pdf_data下所有文件的路径和文件名
import os
def file_name_walk(file_dir):
'''
定义一个返回文件所在的绝对路径和
文件名的列表的函数
'''
file_path_lst = []
for x in os.walk(file_dir):
file_path_lst.append((x[0],x[2]))
return file_path_lst
def get_target(doc,bounds =['公司简称','信息披露及备置地点']):
# 默认设置为首页页码
start_pageno = 0
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0] or bounds[0]) in doc[n].get_text():
start_pageno = n
break
return start_pageno
def get_subtxtt(doc,bounds=('公司代码','信息披露及备置地点')):
# 默认设置为首尾页码
start_pageno = 0
end_pageno = len(doc) - 1
#
lb,ub = bounds # lb:lower bound(下界); ub: upper bound(上界)
#获取左界页码
for n in range(len(doc)):
page = doc[n];txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
paths = "C:\\Users\\12738\\Documents\\Python Scripts\\nianbao\\src\\nianbao"
paths_pos = file_name_walk(paths)
del paths_pos[0]
# 创建一个只包含每只股票2022年年报绝对路径的列表,然后遍历调用
abs_pos_lst = []
for i in file_name_walk(paths):
for n in i[1]:
if '2022' in n:
abs_pos = '{}/{}'.format(i[0],n)
abs_pos_lst.append(abs_pos)
else:
continue
# 提前创建一个表格,以便于存储数据
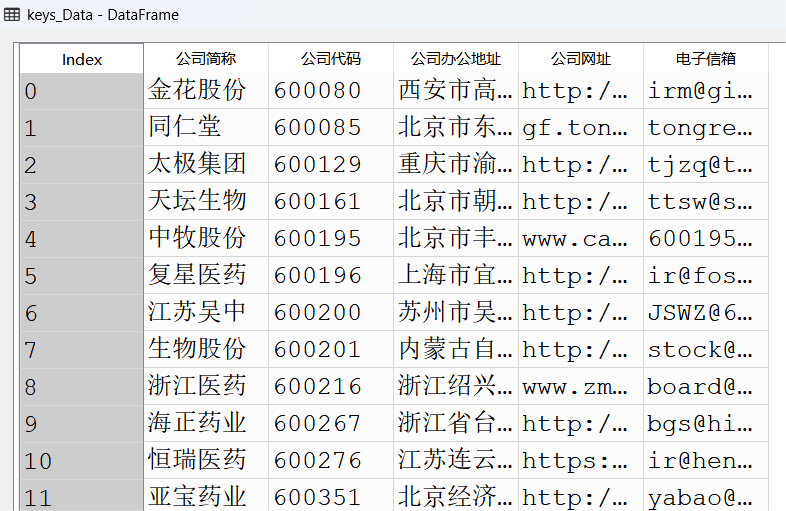
keys_Data = pd.DataFrame(columns=['公司简称','公司代码','公司办公地址','公司网址','电子信箱'])
for i in abs_pos_lst:
docs = fitz.open(i)#i[0]+'\\{}'.format(n)
brief_ = get_subtxtt(docs,bounds=('公司代码','信息披露及备置地点'))
# name
cor_name_compile = re.compile('.*公司简称:(.*?)\s.*',re.DOTALL)
name = cor_name_compile.findall(brief_)[0].strip()
# code
cor_code_compile = re.compile('.*公司代码:(.*?)\s.*',re.DOTALL)
code = cor_code_compile.findall(brief_)[0].strip()
# address
cor_address_compile = re.compile('公司办公地址.*?\n(.*?)\s*\n.*?',re.DOTALL)
address = cor_address_compile.findall(brief_)[0].strip()
# web
cor_web_compile = re.compile('公司网址.*?\n\s*(.*?)\n电子信箱',re.DOTALL)
web = cor_web_compile.findall(brief_)[0].strip()
# secretary_mail
sec_mail_compile = re.compile('.*电子信箱.*?\n\s*(.*?)\n.*',re.DOTALL)
mail = sec_mail_compile.findall(brief_)[0].strip()
keys_Data.loc[len(keys_Data.index)] = {'公司简称':name,'公司代码':code,
'公司办公地址':address,'公司网址':web,
'电子信箱':mail}
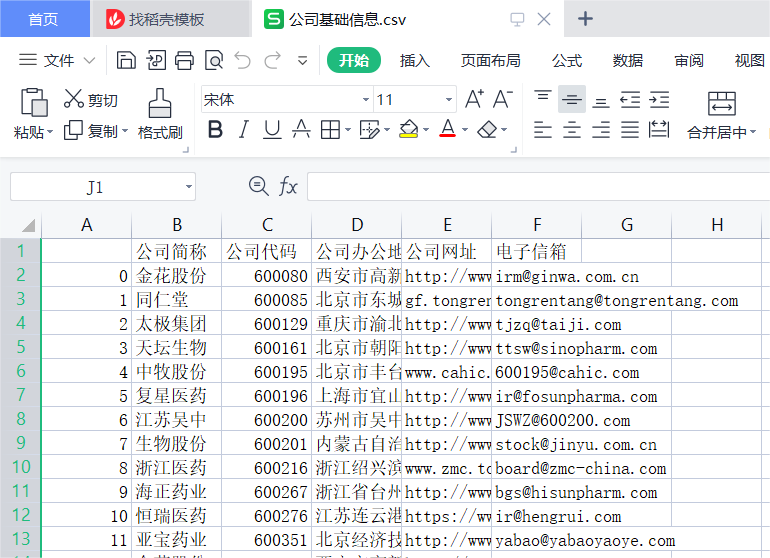
keys_Data.to_csv('公司基础信息.csv')
结果
2.2提取营业收入、归属于上市公司股东净利润
'###########################年报数据解析获取##############################'
import fitz
import pandas as pd
import re
#filename = '2022_600000.PDF'
#doc = fitz.open(filename)
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')):
# 默认设置为首尾页码
start_pageno = 0
end_pageno = len(doc) - 1
#
lb,ub = bounds # lb:lower bound(下界); ub: upper bound(上界)
#获取左界页码
for n in range(len(doc)):
page = doc[n];txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
def get_th_span(txt):
nianfen ='(20\d\d|199\d)\s*年末?' #|199\d
s = f'{nianfen}\s*{nianfen}.*?{nianfen}'
p = re.compile(s,re.DOTALL)
matchobj = p.search(txt)
#
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
#
while(not flag):
matchobj = p.search(txt[end:])
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
flag = (int(year1) - int(year2) == 1)
flag = flag and (int(year2) - int(year3) == 1)
#
return(matchobj.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])
th_span_2nd = (end + th_span_2nd[0],end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0]
#
while (txt[e] not in '0123456789'):
e = e - 1
return(s,e)
def get_keywords(txt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext,keywords):
# kwds = ['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)-1
ss.append(len(subtext))
data = []
#
# p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*)|(.*\))?')
# p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p = re.compile('\D+(?:\s+\D*)?')
p2 = re.compile('\s')
for n in range(len(ss)-1):
s = ss[n]
e =ss[n+1]
line = subtext[s:e]
#获取可能换行的账户名称
matchobj = p.search(line)
account_name = p2.sub('',matchobj.group())
#获取三年数据
amnts = line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return(data)
def get_data_csv(code,data):
csv_name=f'{code}_data.csv'
data.to_csv(csv_name)
#这一步将有用的数据保存在csv_name的CSV中
#get_data_csv(code,pd.DataFrame(all_data))
#all_data=pd.read_csv(r'C:\Users\12738\Documents\Python Scripts\nianbao\src\nianbao\all_data.csv')
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
all_data=[]
def get_datas(code):
for Y in years:
pdf_name=f'{code}_{Y}.pdf'
doc = fitz.open(pdf_name)
txt = get_subtxt(doc)
txt = txt.replace(' ','')
span = get_bounds(txt)
subtext = txt[span[0]:span[1]]
#去除字符串头部的所有空格函数用法
subtext=subtext.replace(' ','')
keywords = get_keywords(subtext)
data = parse_key_fin_data(subtext,keywords)
all_data.append(data)
# all_data=pd.DataFrame(all_data)
get_data_csv('code',pd.DataFrame(all_data))
#get_datas('600035')
codes = ['600080','600085','600161','600195','600200','600201','600216','600267','600276','600351']
for code in codes:
get_datas(code)
get_data_csv('code',pd.DataFrame(all_data))
all_data=pd.read_csv(r'C:\Users\12738\Documents\Python Scripts\nianbao\src\nianbao\code_data.csv') #读取df
'#########################爬取的数据把字符串转为数字便于画图###################'
import matplotlib
print (matplotlib.matplotlib_fname()) # 将会获得matplotlib配置文件
from matplotlib.font_manager import _rebuild
_rebuild()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
#解决matplotlib中文显示问题
import matplotlib.pyplot as plt
from pylab import mpl
def get_sep(tr):
data=[]
for i in range(len(tr)):
temp=re.search(r'\d{1,3}(,\d{3})*(\.\d+)?',tr[i]).group()
s=re.search(r'\d{1,3}(,\d{3})*(\.\d+)?',tr[i]).start()
e=re.search(r'\d{1,3}(,\d{3})*(\.\d+)?',tr[i]).end()
p=re.search(r'(\.)',tr[i]).start()
num=change_int(s,e,p,temp)
data.append(num)
return(data)
##该函数用于将字符串转成浮点数并存在列表里用于作图
def change_int(s,e,p,temp):
a=int((p-s)/4)
b=(p-s)-(a*4)
num=(int(temp[0:b]))*(10**(3*a))
for n in range(a+1):
if n == a:
if temp[b+1+(4*n):] =='':
num += 0
else:
num += (int(temp[b+1+(4*n):]))*(10**-(len(temp[b+1+(4*n):])))
else:
num += (int(temp[b+1+(4*n):b+4+(4*n)]))*(10**((2-n)*a))
return(num)
'####################得出营业收入和归属于上市公司股东的净利润###################'
ls=[]
for i in range(10):
temp=all_data.iloc[10*i:10*i+10]
ls.append(temp)
ls2=list(map(lambda x:x.reset_index(drop=True),ls))
revenue = [] #营业收入
for i in range(10):
revenue.append(get_sep(ls2[i].iloc[0:10,1]))
netincome = [] #归属于上市公司股东的净利润
for i in range(10):
netincome.append(get_sep(ls2[i].iloc[0:10,2]))
结果
三、图像绘制与对照
import matplotlib
print (matplotlib.matplotlib_fname()) # 将会获得matplotlib配置文件
from matplotlib.font_manager import _rebuild
_rebuild()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
#解决matplotlib中文显示问题
import matplotlib.pyplot as plt
from pylab import mpl
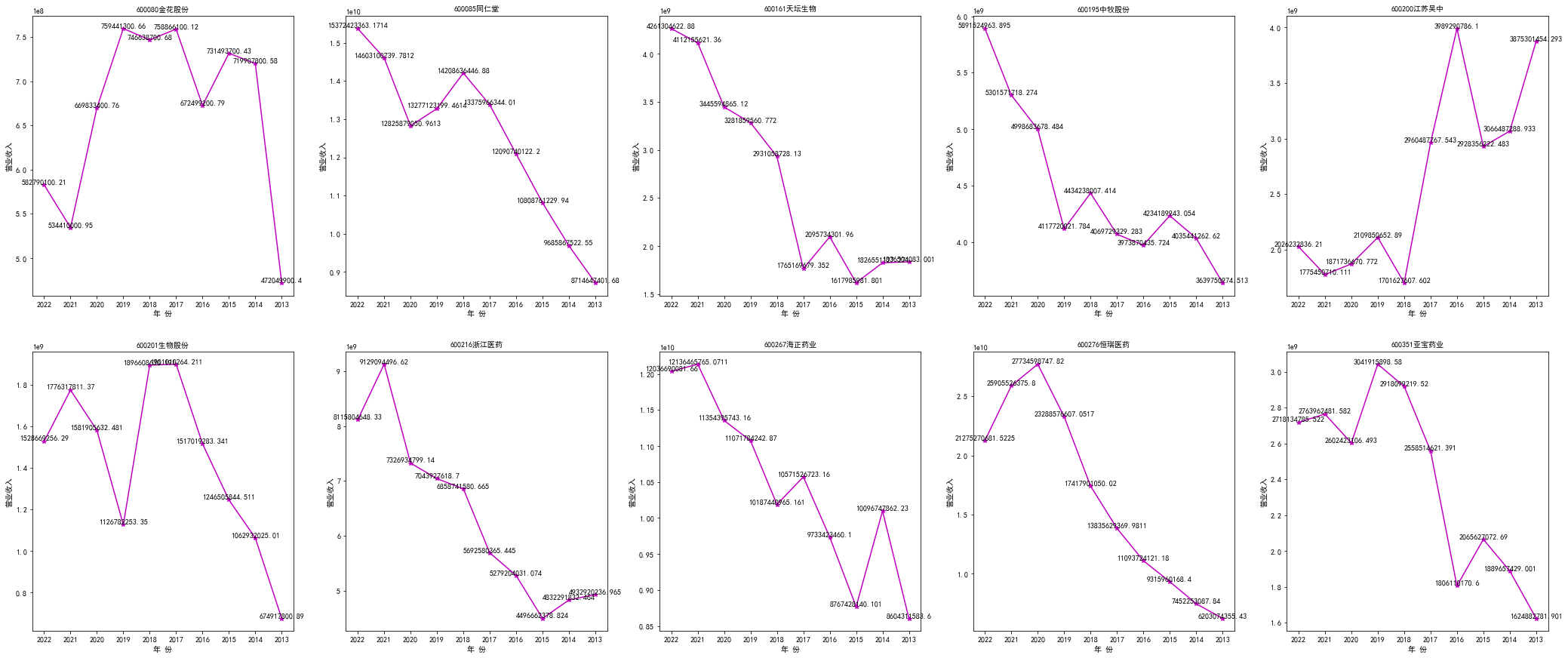
'###############################营业收入###############################'
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
x = years
fig1 = plt.figure(figsize=(36,15))
#plt.title(u'十家公司营业收入时间序列图',fontsize=13)
ax1 = fig1.add_subplot(251)
ax1.plot(x,revenue[0],'m*-')
for a, b in zip(x,revenue[0]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax1.set_xlabel('年 份',fontsize=10)
ax1.set_ylabel('营业收入',fontsize=10)
ax1.set_title('600080金花股份',fontsize=10)
ax2 = fig1.add_subplot(252)
ax2.plot(x,revenue[1],'m*-')
for a, b in zip(x,revenue[1]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax2.set_xlabel('年 份',fontsize=10)
ax2.set_ylabel('营业收入',fontsize=10)
ax2.set_title('600085同仁堂',fontsize=10)
ax3 = fig1.add_subplot(253)
ax3.plot(x,revenue[2],'m*-')
for a, b in zip(x,revenue[2]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax3.set_xlabel('年 份',fontsize=10)
ax3.set_ylabel('营业收入',fontsize=10)
ax3.set_title('600161天坛生物',fontsize=10)
ax4 = fig1.add_subplot(254)
ax4.plot(x,revenue[3],'m*-')
for a, b in zip(x,revenue[3]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax4.set_xlabel('年 份',fontsize=10)
ax4.set_ylabel('营业收入',fontsize=10)
ax4.set_title('600195中牧股份',fontsize=10)
ax5 = fig1.add_subplot(255)
ax5.plot(x,revenue[4],'m*-')
for a, b in zip(x,revenue[4]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax5.set_xlabel('年 份',fontsize=10)
ax5.set_ylabel('营业收入',fontsize=10)
ax5.set_title('600200江苏吴中',fontsize=10)
ax6 = fig1.add_subplot(256)
ax6.plot(x,revenue[5],'m*-')
for a, b in zip(x,revenue[5]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax6.set_xlabel('年 份',fontsize=10)
ax6.set_ylabel('营业收入',fontsize=10)
ax6.set_title('600201生物股份',fontsize=10)
ax7 = fig1.add_subplot(257)
ax7.plot(x,revenue[6],'m*-')
for a, b in zip(x,revenue[6]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax7.set_xlabel('年 份',fontsize=10)
ax7.set_ylabel('营业收入',fontsize=10)
ax7.set_title('600216浙江医药',fontsize=10)
ax8 = fig1.add_subplot(258)
ax8.plot(x,revenue[7],'m*-')
for a, b in zip(x,revenue[7]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax8.set_xlabel('年 份',fontsize=10)
ax8.set_ylabel('营业收入',fontsize=10)
ax8.set_title('600267海正药业',fontsize=10)
ax9 = fig1.add_subplot(259)
ax9.plot(x,revenue[8],'m*-')
for a, b in zip(x,revenue[8]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax9.set_xlabel('年 份',fontsize=10)
ax9.set_ylabel('营业收入',fontsize=10)
ax9.set_title('600276恒瑞医药',fontsize=10)
ax10 = fig1.add_subplot(2,5,10)
ax10.plot(x,revenue[9],'m*-')
for a, b in zip(x,revenue[9]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax10.set_xlabel('年 份',fontsize=10)
ax10.set_ylabel('营业收入',fontsize=10)
ax10.set_title('600351亚宝药业',fontsize=10)
plt.show()
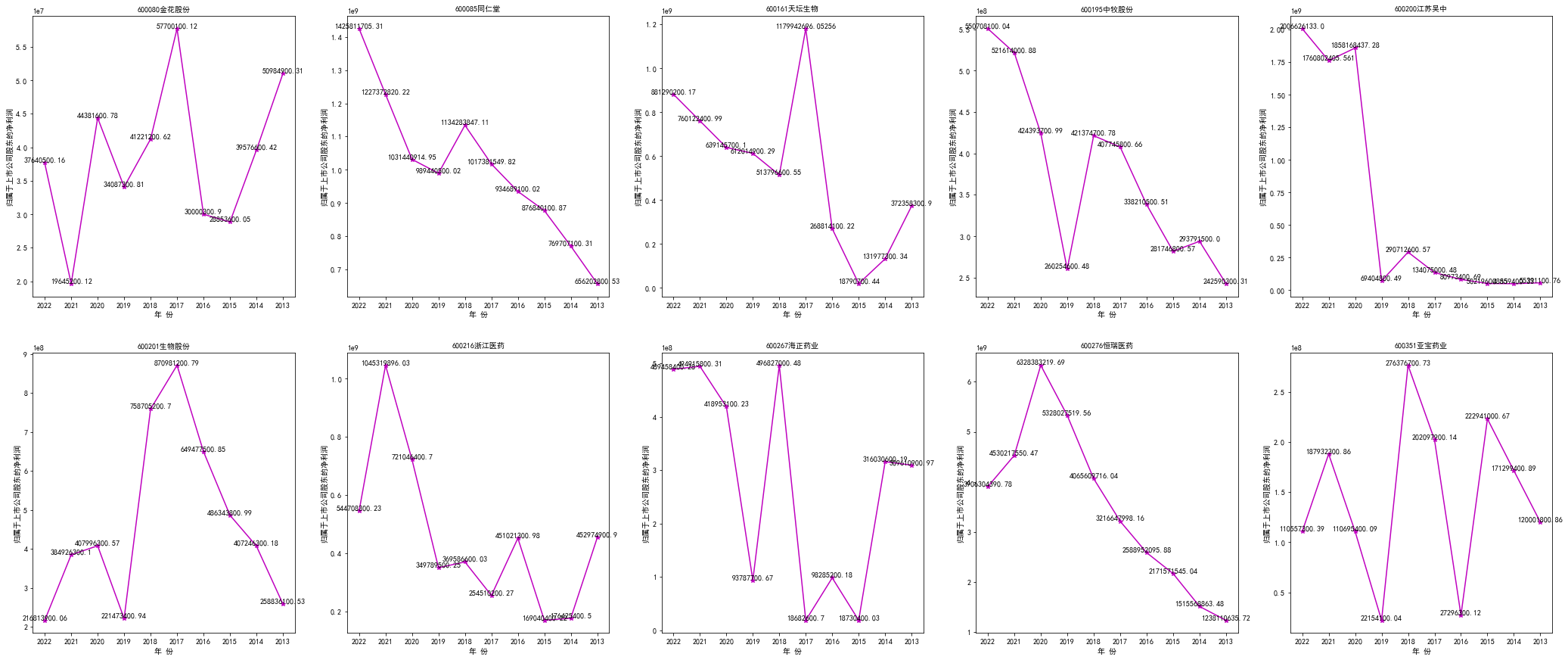
'#######################归属于上市公司股东的净利润###########################'
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
x = years
fig1 = plt.figure(figsize=(36,15))
#plt.title(u'十家公司营业收入时间序列图',fontsize=13)
ax1 = fig1.add_subplot(251)
ax1.plot(x,netincome[0],'m*-')
for a, b in zip(x,netincome[0]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax1.set_xlabel('年 份',fontsize=10)
ax1.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax1.set_title('600080金花股份',fontsize=10)
ax2 = fig1.add_subplot(252)
ax2.plot(x,netincome[1],'m*-')
for a, b in zip(x,netincome[1]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax2.set_xlabel('年 份',fontsize=10)
ax2.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax2.set_title('600085同仁堂',fontsize=10)
ax3 = fig1.add_subplot(253)
ax3.plot(x,netincome[2],'m*-')
for a, b in zip(x,netincome[2]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax3.set_xlabel('年 份',fontsize=10)
ax3.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax3.set_title('600161天坛生物',fontsize=10)
ax4 = fig1.add_subplot(254)
ax4.plot(x,netincome[3],'m*-')
for a, b in zip(x,netincome[3]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax4.set_xlabel('年 份',fontsize=10)
ax4.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax4.set_title('600195中牧股份',fontsize=10)
ax5 = fig1.add_subplot(255)
ax5.plot(x,netincome[4],'m*-')
for a, b in zip(x,netincome[4]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax5.set_xlabel('年 份',fontsize=10)
ax5.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax5.set_title('600200江苏吴中',fontsize=10)
ax6 = fig1.add_subplot(256)
ax6.plot(x,netincome[5],'m*-')
for a, b in zip(x,netincome[5]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax6.set_xlabel('年 份',fontsize=10)
ax6.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax6.set_title('600201生物股份',fontsize=10)
ax7 = fig1.add_subplot(257)
ax7.plot(x,netincome[6],'m*-')
for a, b in zip(x,netincome[6]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax7.set_xlabel('年 份',fontsize=10)
ax7.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax7.set_title('600216浙江医药',fontsize=10)
ax8 = fig1.add_subplot(258)
ax8.plot(x,netincome[7],'m*-')
for a, b in zip(x,netincome[7]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax8.set_xlabel('年 份',fontsize=10)
ax8.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax8.set_title('600267海正药业',fontsize=10)
ax9 = fig1.add_subplot(259)
ax9.plot(x,netincome[8],'m*-')
for a, b in zip(x,netincome[8]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax9.set_xlabel('年 份',fontsize=10)
ax9.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax9.set_title('600276恒瑞医药',fontsize=10)
ax10 = fig1.add_subplot(2,5,10)
ax10.plot(x,netincome[9],'m*-')
for a, b in zip(x,netincome[9]):
plt.text(a, b+3, b, ha='center', va='bottom')
ax10.set_xlabel('年 份',fontsize=10)
ax10.set_ylabel('归属于上市公司股东的净利润',fontsize=10)
ax10.set_title('600351亚宝药业',fontsize=10)
plt.show()
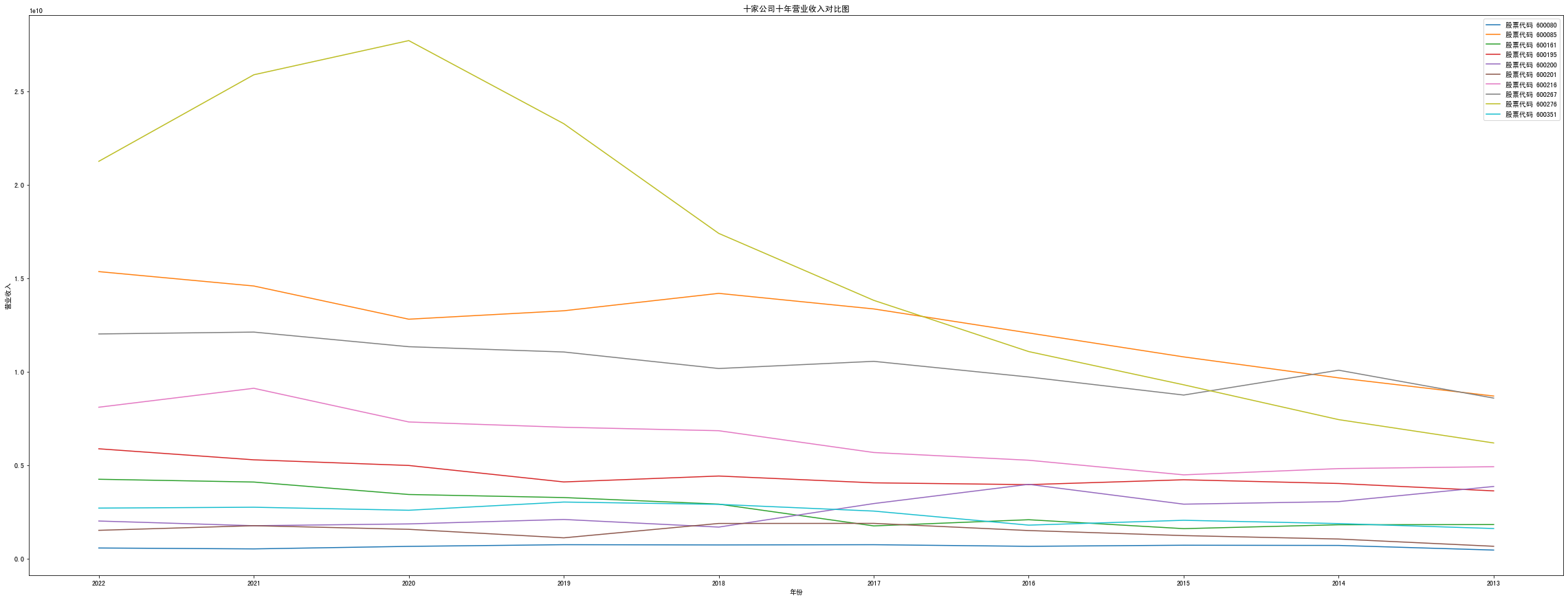
years = ['2022','2021','2020','2019','2018','2017','2016','2015','2014','2013']
x = years
y = revenue
fig= plt.figure(figsize=(60,35))
plt.xlabel("年份")
plt.ylabel("营业收入")
plt.title("十家公司十年营业收入对比图")
for i in range(len(y)):
plt.plot(x,y[i],label = '股票代码 %s'%codes[i])
plt.legend()
plt.show()
x = years
y = netincome
fig= plt.figure(figsize=(60,35))
plt.xlabel("年份")
plt.ylabel("归属于上市公司股东的净利润")
plt.title("十家公司十年归属于上市公司股东的净利润对比图")
for i in range(len(y)):
plt.plot(x,y[i],label = '股票代码 %s'%codes[i])
plt.legend()
plt.show()