郭佳莉的实验报告(化学原料和化学制品制造业)
所属行业的10家公司
| 上市公司代码 |
上市公司简称 |
| 600596 |
新安股份 |
| 600610 |
中毅达 |
| 600618 |
氯碱化工 |
| 600623 |
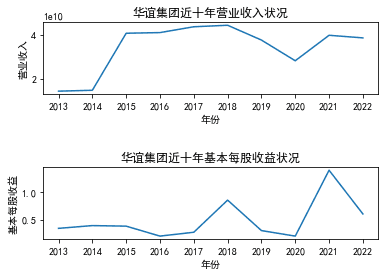
华谊集团 |
| 600691 |
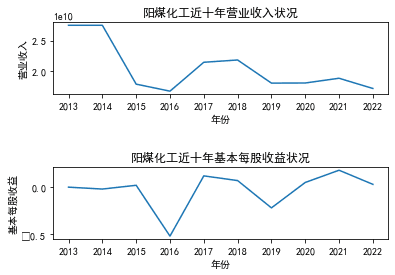
阳煤化工 |
| 600714 |
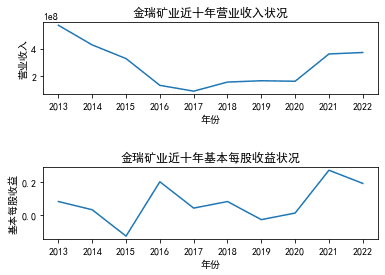
金瑞矿业 |
| 600722 |
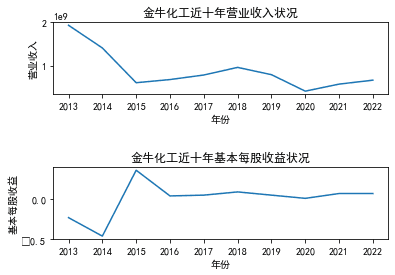
金牛化工 |
| 600727 |
鲁北化工 |
| 600731 |
湖南海利 |
| 600746 |
江苏索普 |
一、年报爬取、处理与下载
#获取年报html
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import os
if not os.path.exists("sh"):
os.mkdir("sh")#上交所
def GetShHtml(code, name):
browser = webdriver.Edge()
browser.set_window_size(1550, 830)
url = "http://www.sse.com.cn//disclosure/listedinfo/regular/"
browser.get(url)
time.sleep(3)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)#'601919'
selector = ".sse_outerItem:nth-child(4) .filter-option-inner-inner"
browser.find_element(By.CSS_SELECTOR, selector).click()
browser.find_element(By.LINK_TEXT,"年报").click()
time.sleep(3)
#
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
#
html = browser.find_element(By.CSS_SELECTOR, css_selector)
innerHTML = html.get_attribute('innerHTML')
time.sleep(3)
f = open(name +'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
time.sleep(3)
browser.quit()
df = pd.read_excel("company.xlsx")
for index, row in df.iterrows():
name = row['上市公司简称']
code = row['上市公司代码']
os.chdir("sh")
GetShHtml(code, name)
#将html解析成csv文件
import re
import pandas as pd
import os
os.chdir('D:/1.Mypython/nianbao/sh')
def get_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
# data = get_data(trs_new[1])
def parse_table(table_html):
p = re.compile('(.+?)
', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
# f = open('table.html', encoding='utf-8')
f = open('新安股份.html', encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
# df.to_csv('公告链接.csv')
df.to_csv('600569.csv')
#下载年报
import json
import os
from time import sleep
from urllib import parse
import requests
import time,random
from fake_useragent import UserAgent
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent':userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
list=['600596','600610','600618','600623','600691','600714','600722','600727','600731','600746']
for company in list:
os.mkdir(company)
orgId, plate, code=get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")
结果
二、提取“营业收入(元)”、“基本每股收益(元 ╱ 股)”
“股票简称”、“股票代码”、“办公地址”、“公司网址”信息数据
import pandas as pd
import fitz
import re
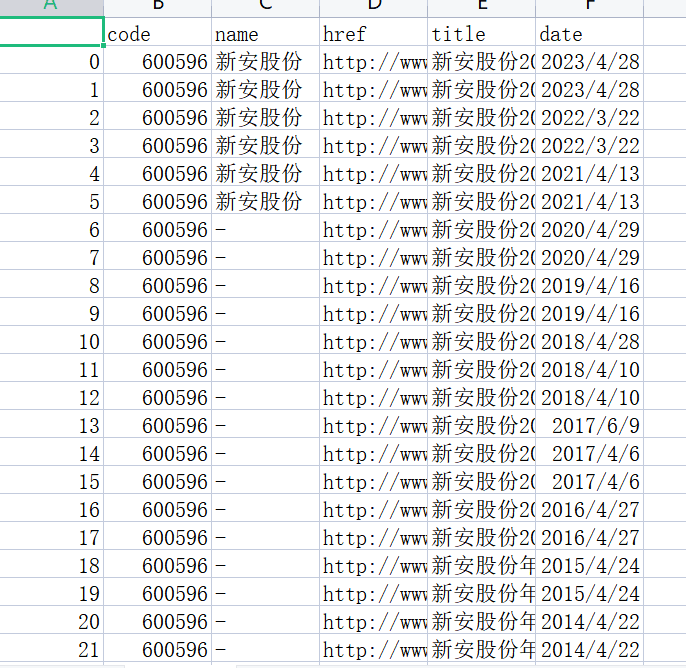
Company=pd.read_csv('company.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
company=Company.iloc[:,1].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(15): #读取每份年报前15页的数据(一般财务指标读15页就够了,全部读取的话会比较耗时间)
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
if year>2011:
pre_rev=final.loc[year-1,'营业收入(元)']
if pre_rev/revenue>2:
print('%s%s营业收入下跌超过百分之50,可能出现问题,请手动查看'%(com,title))
eps=p_eps.search(text).group(1)
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
site=p_site.search(text).group(1) #匹配办公地址和网址(由于取最近一年的,所以只要匹配一次不用循环匹配)
web=p_web.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
print(name+'数据已保存完毕'+'(',t,'/',len(company),')')
结果
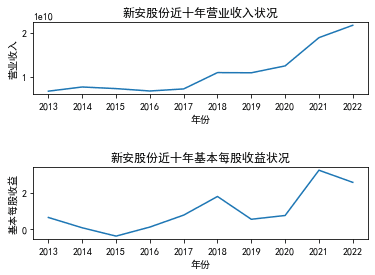
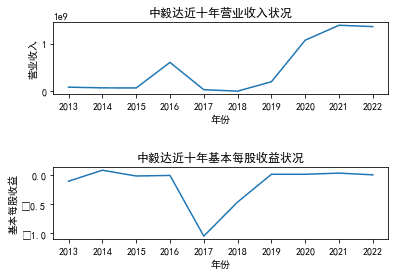
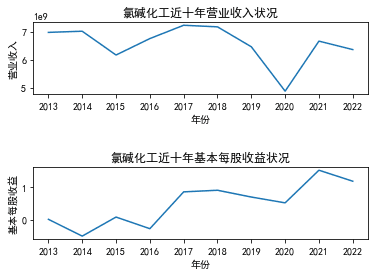
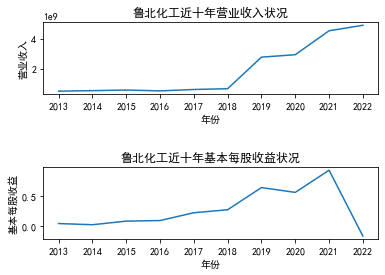
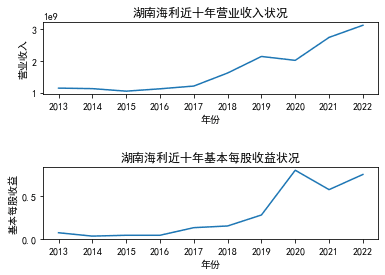
三、图像绘制
#一个一个图画,需要那个就画哪个
import matplotlib.pyplot as plt
import csv
import chardet
import matplotlib.pyplot as plt
import os
os.chdir('csv文件')
x=['2013','2014','2015','2016','2017','2018','2019','2020','2021','2022']
y_data1 = []
y_data2 = []
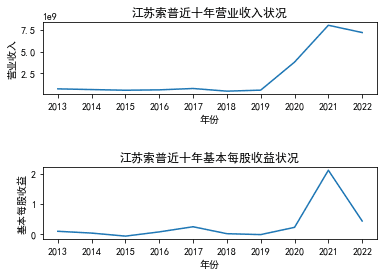
with open('江苏索普.csv', 'r', encoding=encoding) as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
for row in reader:
y_data1.append(float(row[1]))
y_data2.append(float(row[2]))
# 创建窗口和子图
fig, (ax1, ax2) = plt.subplots(2)
# 在第一个子图中绘制数据1
ax1.plot(x, y_data1)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入')
ax1.set_title('江苏索普近十年营业收入状况')
# 在第二个子图中绘制数据2
ax2.plot(x, y_data2)
ax2.set_xlabel('年份')
ax2.set_ylabel('基本每股收益')
ax2.set_title('江苏索普近十年基本每股收益状况')
plt.subplots_adjust(hspace=1) # 设置垂直间距,可以根据需要调整数
# 显示图形
plt.show()
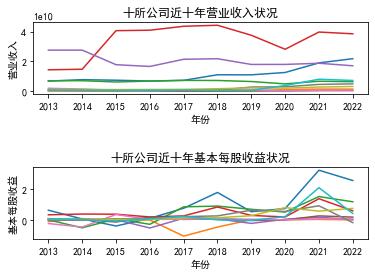
#十所公司放在一起
import matplotlib.pyplot as plt
import csv
import chardet
import matplotlib.pyplot as plt
import os
os.chdir('csv文件')
x=['2013','2014','2015','2016','2017','2018','2019','2020','2021','2022']
y_data11 = []
y_data12 = []
y_data13 = []
y_data14 = []
y_data15 = []
y_data16 = []
y_data17 = []
y_data18 = []
y_data19 = []
y_data110 = []
y_data21 = []
y_data22 = []
y_data23 = []
y_data24 = []
y_data25 = []
y_data26 = []
y_data27 = []
y_data28 = []
y_data29 = []
y_data210 = []
with open('总结.csv', 'r', encoding=encoding) as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
for row in reader:
y_data11.append(float(row[1]))
y_data12.append(float(row[2]))
y_data13.append(float(row[3]))
y_data14.append(float(row[4]))
y_data15.append(float(row[5]))
y_data16.append(float(row[6]))
y_data17.append(float(row[7]))
y_data18.append(float(row[8]))
y_data19.append(float(row[9]))
y_data110.append(float(row[10]))
y_data21.append(float(row[11]))
y_data22.append(float(row[12]))
y_data23.append(float(row[13]))
y_data24.append(float(row[14]))
y_data25.append(float(row[15]))
y_data26.append(float(row[16]))
y_data27.append(float(row[17]))
y_data28.append(float(row[18]))
y_data29.append(float(row[19]))
y_data210.append(float(row[20]))
# 创建窗口和子图
fig, (ax1, ax2) = plt.subplots(2)
# 在第一个子图中绘制数据1
ax1.plot(x, y_data11)
ax1.plot(x, y_data12)
ax1.plot(x, y_data13)
ax1.plot(x, y_data14)
ax1.plot(x, y_data15)
ax1.plot(x, y_data16)
ax1.plot(x, y_data17)
ax1.plot(x, y_data18)
ax1.plot(x, y_data19)
ax1.plot(x, y_data110)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入')
ax1.set_title('十所公司近十年营业收入状况')
# 在第二个子图中绘制数据2
ax2.plot(x, y_data21)
ax2.plot(x, y_data22)
ax2.plot(x, y_data23)
ax2.plot(x, y_data24)
ax2.plot(x, y_data25)
ax2.plot(x, y_data26)
ax2.plot(x, y_data27)
ax2.plot(x, y_data28)
ax2.plot(x, y_data29)
ax2.plot(x, y_data210)
ax2.set_xlabel('年份')
ax2.set_ylabel('基本每股收益')
ax2.set_title('十所公司近十年基本每股收益状况')
plt.subplots_adjust(hspace=1) # 设置垂直间距,可以根据需要调整数
# 显示图形
plt.show()
结果
实验感想