


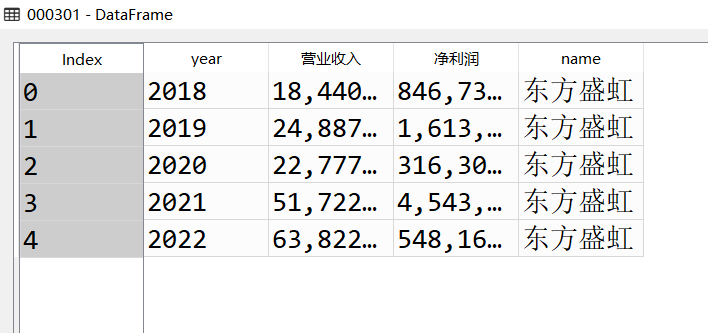





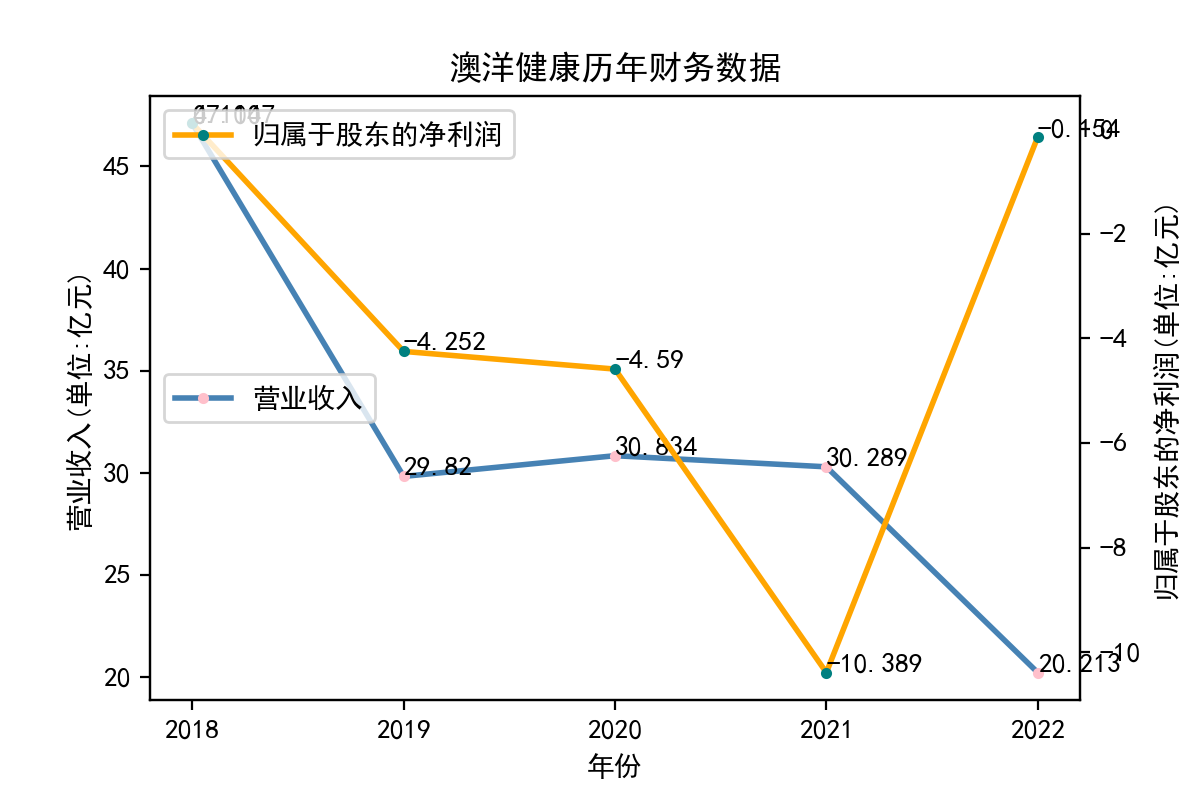
江苏澳洋健康产业股份有限公司于2001年10月22日成立,经营范围包括:健康产业领域的投资、开发;粘胶纤维及粘胶纤维品、可降解纤维、功能性纤维制造、销售,纺织原料、纺织品、化工产品销售,蒸汽热供应,电力生产,自营和代理各类商品及技术的进出口业务等。公司的股东净利润持续处于负值水平,仅在2021~2022年,由-10亿上升至-1,500万接近0。营业收入呈明显下降态势,在2021~2022年降幅尤为明显,近1/3。财务数据显示出该公司的市场前景不容乐观。
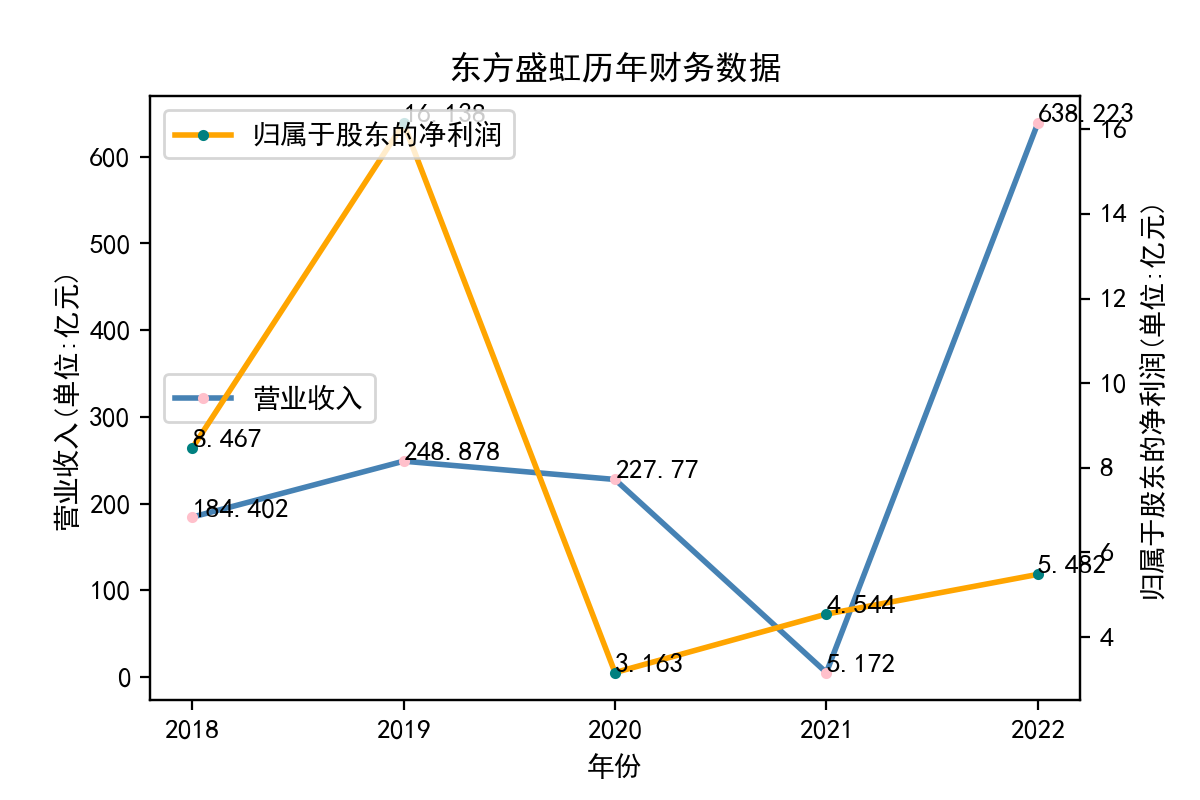
江苏东方盛虹股份有限公司盛泽热电厂于1998年08月21日成立,是一家专注于智能科技产品的研发、生产和销售的知名企业。该公司位于中国深圳,占地面积5000平方米,拥有一支具有丰富经验的技术研发团队,拥有强大的设计和制造能力。主要生产智能家居、智能安防、智能传感器、智能家电等智能产品,涵盖了智能家居解决方案,智能安防解决方案,智能传感器解决方案,智能家电解决方案等多个领域。该公司股东净利润在2019年大幅跃升至16亿,但同年营业收入并无明显起色,2020年股东净收入骤降并稳定在较低位。2021年疫情爆发后营业收入非正常下降至极低点仅5亿元以上;随后于2022年强势反弹,较之前2020年通常水平增长约两倍。总体而言该公司市场效益和利润分配相关的财务波动十分猛烈,缺少科学规划和持久稳定性。
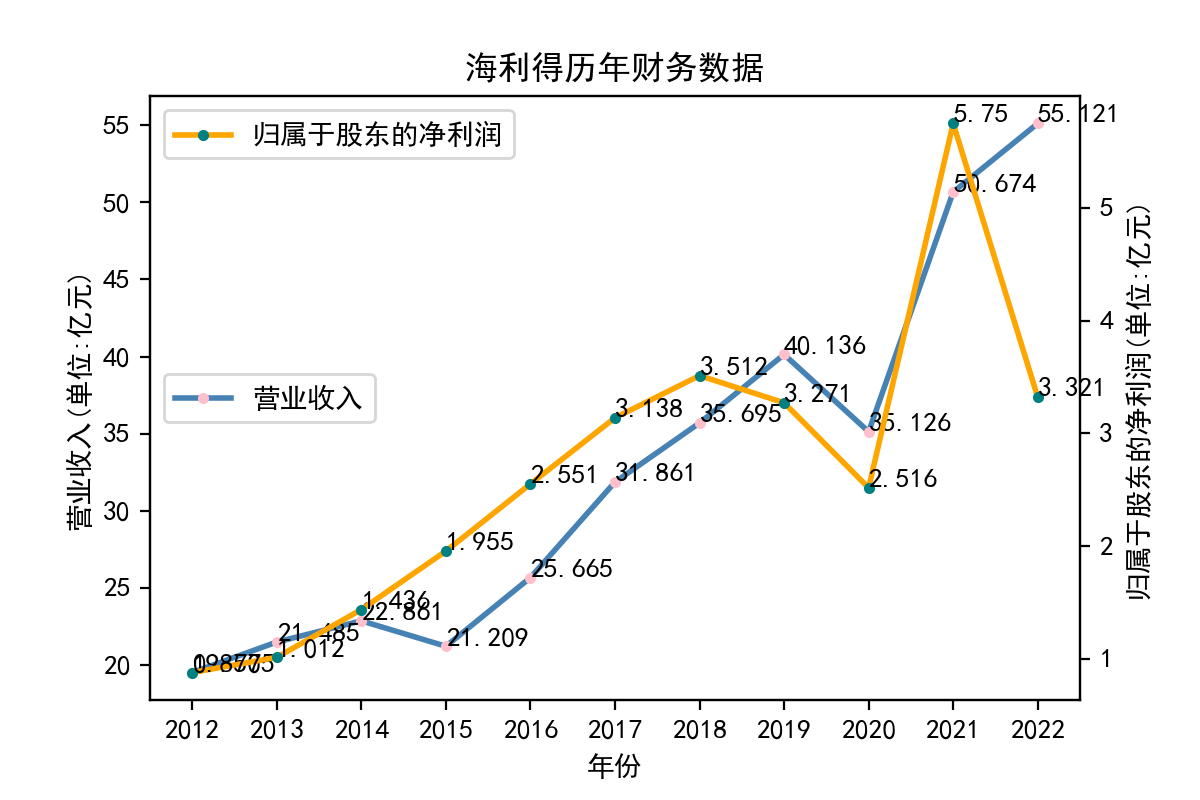
浙江海利得新材料股份有限公司于2008年1月在深圳证券交易所挂牌上市,有员工2800多人,公司主营产品有聚酯切片、涤纶工业丝、轮胎帘子布、数码喷绘材料、涂层材料、装饰材料、石塑地板等,产品远销海内外80余个国家和地区。公司是全国最大的涤纶工业长丝和灯箱布制造企业之一,国家火炬计划重点高新技术企业,2006年全国涤纶工业长丝行业市场销售价格和销售额第1名企业。该公司股东净利润和营业收入都在2020和2021年急剧增长达到最高点。2021年营业收入峰值比2019年最高点40亿多出10亿,随后2022年依然稳步增长至55亿,但股东净利润大幅下跌,回退到2017年以后的3亿上下的水平。
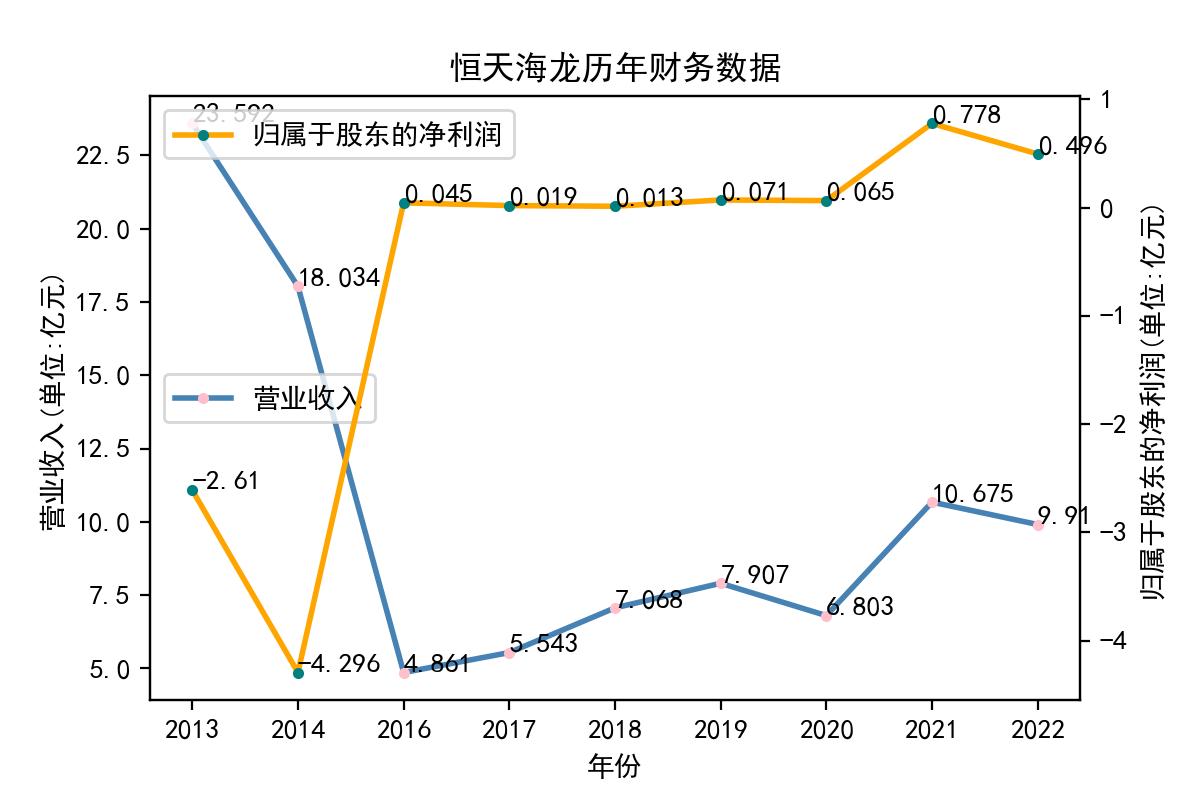
恒天海龙股份有限公司始建于1984年,1996年12月26日在深圳证交所挂牌上市,是潍坊市第一家上市公司,2012年12月26日加入中国恒天集团股份有限公司。辖公司本部、博莱特公司和新疆海龙化纤有限公司,职工6000余名,主营粘胶长丝、粘胶短丝、棉浆粕和帘帆布。恒天海龙股份有限公司始建于1984年,1996年12月26日在深圳证交所挂牌上市,是潍坊市第一家上市公司,2012年12月26日加入中国恒天集团股份有限公司。辖公司本部、博莱特公司和新疆海龙化纤有限公司,职工6000余名。注册资本8.64亿元,公司主营粘胶长丝、粘胶短丝、棉浆粕和帘帆布。
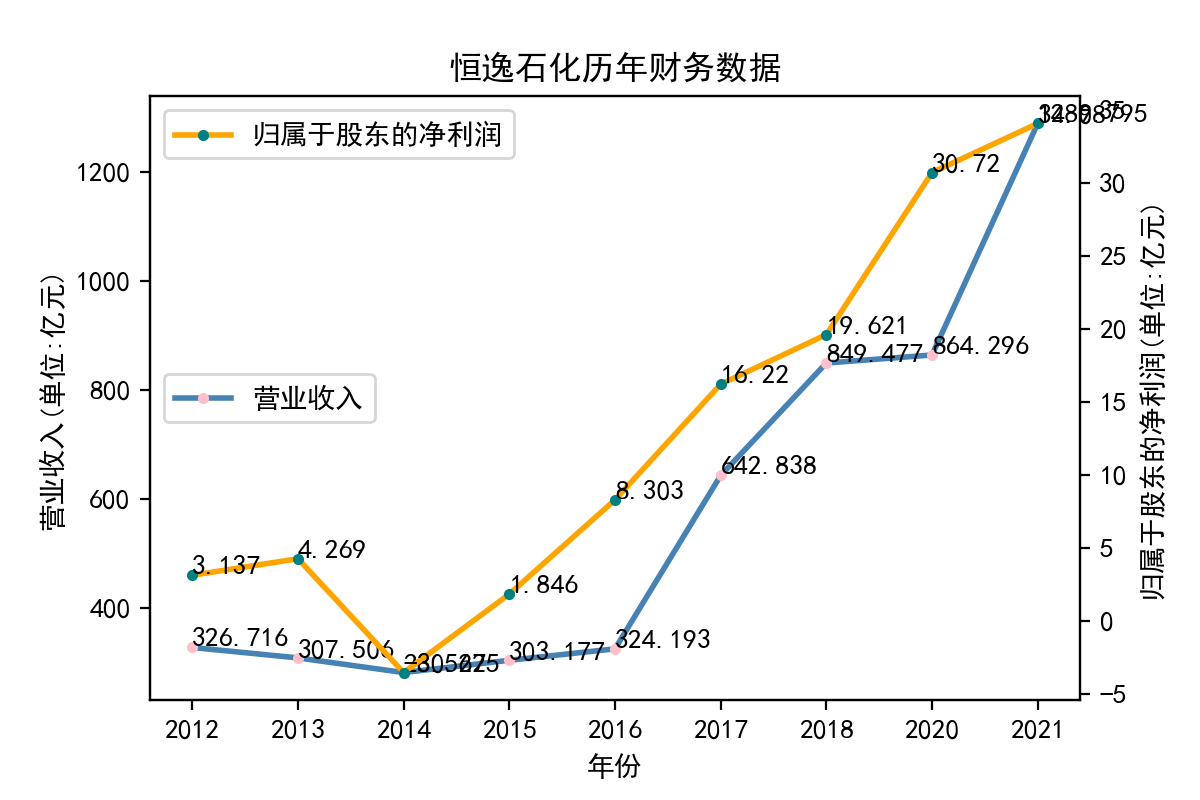
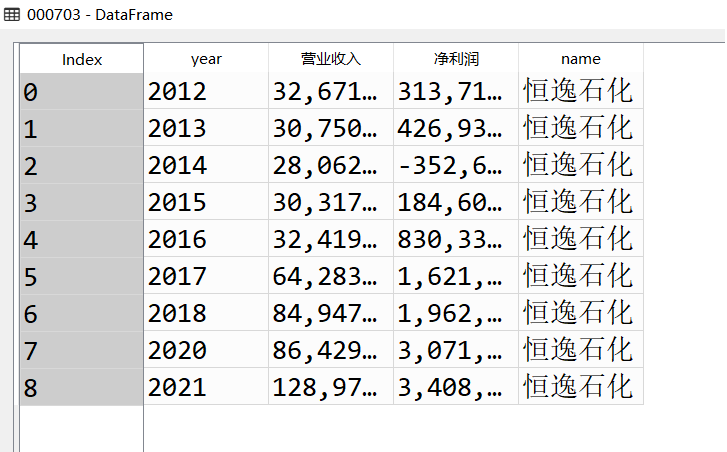
恒逸石化股份有限公司是全球领先的精对苯二甲酸(PTA)和聚酯纤维制造商。公司依托长三角地区发达的产业集群效应,率先实现了产业转型升级,形成了精对苯二甲酸和聚酯纤维上下游产业链一体化和产能规模化的产业格局,其产能规模、装备技术、成本控制、品质管理和产品差异化等方面在同类企业中处于领先地位。公司致力于发展成为全球领先的石化和化纤综合服务商。2020年7月,2020年《财富》中国500强,恒逸石化股份有限公司排名第128位。公司10年间营业收入和股东净利润均实现高速增长,其中营业收入在2014年,实现明显上升转折;股东净利润从自2016年伊始急剧增加。营业收入的两次最大涨幅分别出现在2016~2017年和2020~2021年。该公司依托先进的生产经验和技术条件,实现了疫情间的高速增长与疫情结束后的优势领先局面。
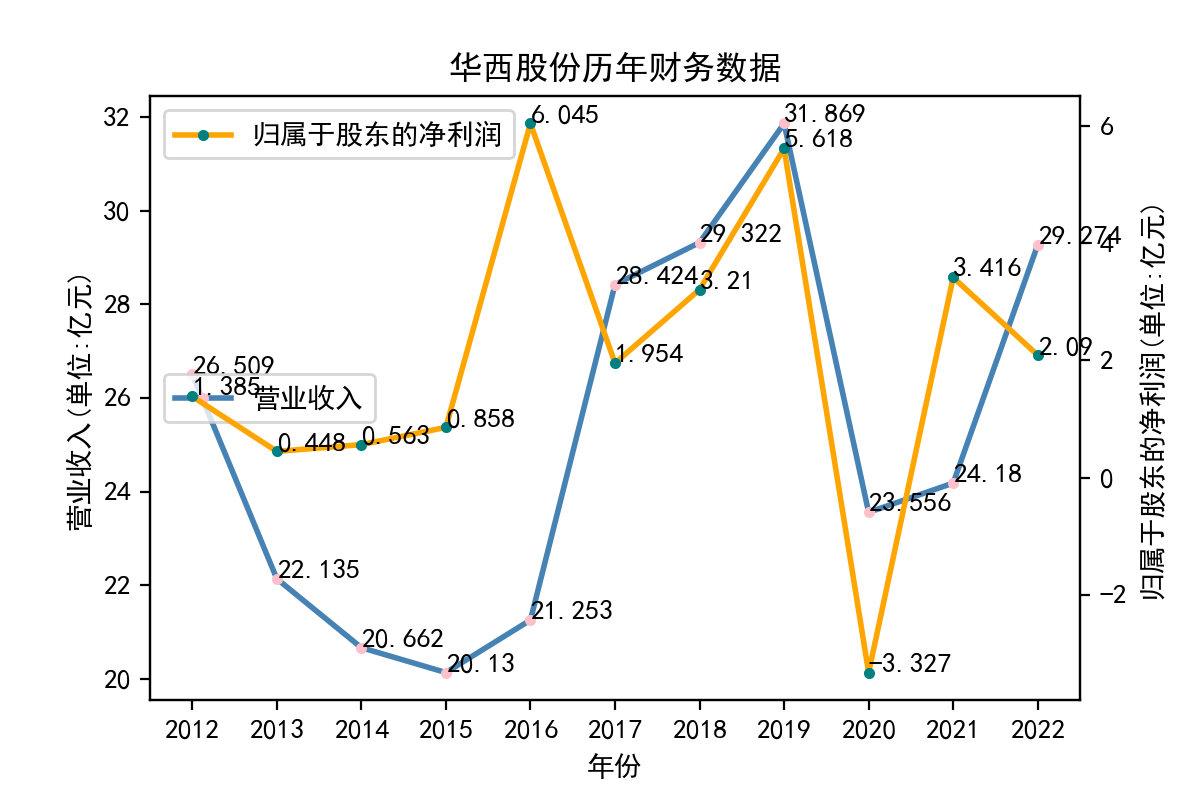
江苏华西村股份有限公司是以江苏华西集团公司为主发起人设立的上市公司,1999在深圳证券交易所发行。公司主要经营范围为:纺织品、化工原料、化学纤维品、国内贸易、热电站。公司拥有特种化纤厂、特种聚酯分厂和二家中外合资企业,现有职工2000多人,包含工程技术人员400多人。公司已形成年产45万吨化纤、年供汽能力70万吨的生产加工能力,涉及总容量达8.3万立方米的化工产品仓储业务公司的营业收入和股东净利润在2012年到2017年呈逆势分布,尤其是2016年股东净利润大幅增长,从连续三年不到1%激增至超过6亿。其后营业收入与股东净利润走势逐渐趋于重合,2019年二者同样达到高峰。2021年再次出现涨跌方向反差,当年的股东净利润从历史性的低点-3亿左右迅速跃升至超过3亿,但营业收入尚徘徊于上一年的低迷数字中。到2022年,营业收入实现大幅增长,接近2019年的历史高点;股东净利润回退至2%。
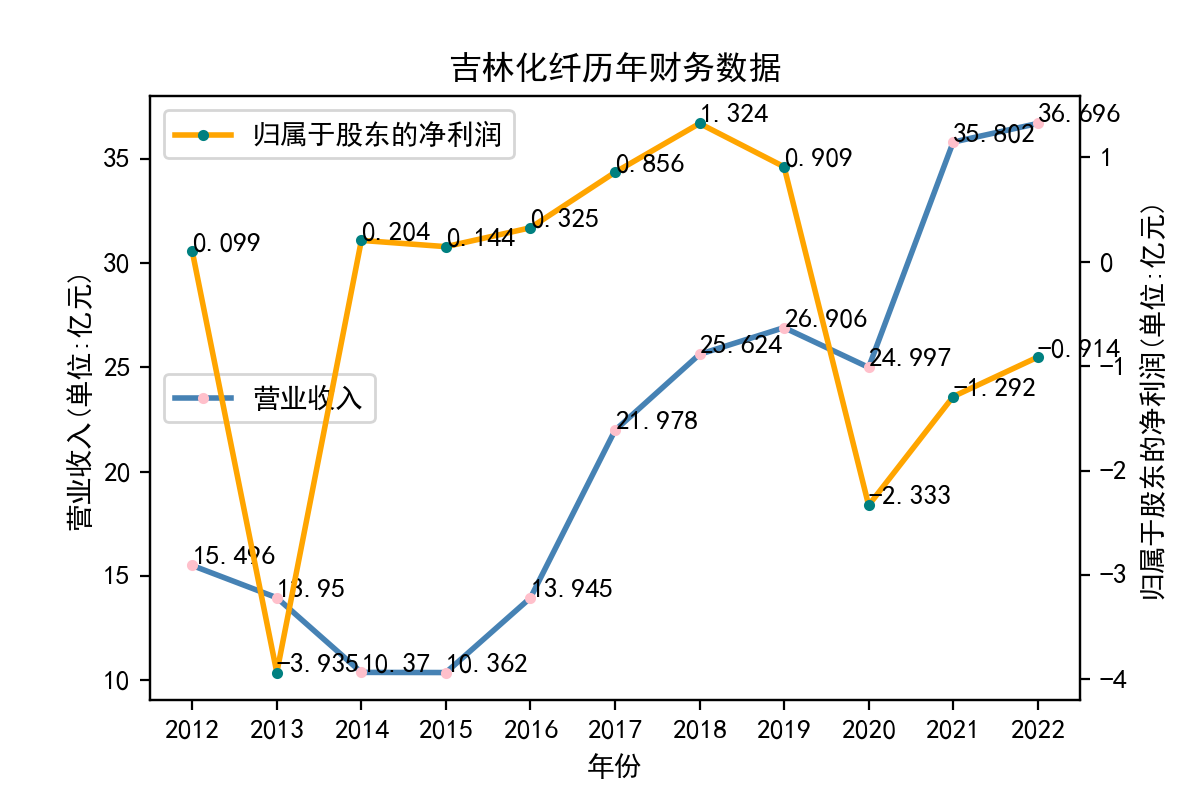
吉林化纤股份有限公司系经吉林省经济体制改革委员会以吉改批(1993)35号文批准, 由吉林化学纤维厂为独家发起人,采取定向募集方式设立的股份制企业, 于1996年在深交所挂牌上市。2013年吉林化纤的股东净利润明显下跌至近-4%,而后在2020年再次明显下跌为负值,随后稳步增长但仍低于0。吉林化纤的营业收入则较为稳定,整体趋势呈上涨态势,2016~2017年和2020~2021年涨幅尤为明显,到2022年疫情末期仍能稳定市场份额且小幅上涨。透过吉林化纤的股东净利润指标分析,我们看出该公司虽然市场规模稳定扩张,但盈利情况不够乐观。

青岛海立美达股份有限公司前身是青岛海立美达钢制品有限公司,成立于2004年12月, 由青岛海立控股有限公司与世界500强企业日本美达王株式会社于2004年合资成立, 2009年5月改制为股份有限公司。美达股份的营业收入和股东净利润, 在2012年到2022年的十年间动荡起伏明显。 营业收入10年间的最低点出现在2016年和2020年, 股东净利润则分别在2014年2016年2022年跌破至负值。 值得注意的是股东净利润的变化与营业收入的变化趋势并不完全同步, 如2014年股东净利润的跌幅,明显大于营业收入跌幅;而2019年到2020年, 股东净利润稳步增长时,营业收入出现大幅下跌。
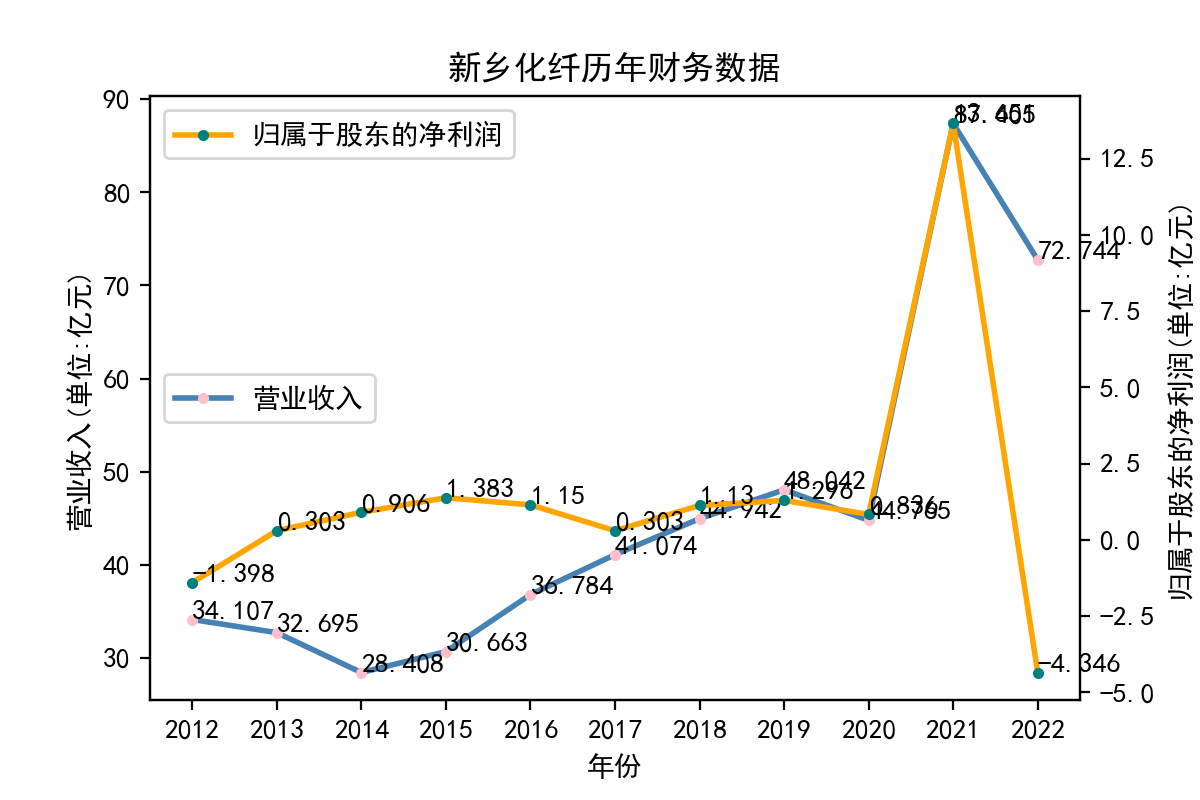
新乡白鹭化纤集团有限责任公司(原新乡化学纤维厂)是我国生产化纤纺织原料的大型一类国有独资企业, 是全国520家重点企业和河南省30家重点企业之一, 是河南省首家《区域全面经济伙伴关系协定》(RCEP)项下经核准出口商。 从2012~2020年,营业收入长期维持在30~50亿元区间, 在2014年触及最低点,随后持续稳定增长至2020年。 受疫情影响,2021年营业收入急剧增长至突破80亿, 但紧接着到2022年迅速回落至不到30亿。股东净利润在2013年转正后, 长期稳定在较低水平,2021年随营业收入同步激增至超过12.5亿, 在2022年营业收入额骤降后,随之暴跌到负值,甚至明显低于2012年的水平。 新乡化纤的数据变化体现出对市场预期的透支和明显的产能过剩现象。 市场需求与生产者的预期相差较大,生产策略的制定受市场波动影响过大。
2021~2022年间为疫情主要蔓延期,口罩等相关医护产品需求量大,大部分化学纤维制造行业的企业,营业收入增长明显。其中一部分到2022年仍保持相当的市场份额甚至小幅上涨,但股东净利润率往往下跌明显。行业样本中,恒逸石化的表现最为亮眼,新乡化纤中规中矩。其他企业有些则财务状况波动剧烈,往往来源于战略制定和技术储备上的明显薄弱之处。
在本学期节奏紧凑的学习中,我逐渐接触和熟悉使用Python进行上市公司年报爬取,用Pdfplumber对数据进行提取并通过Matplotlib进行数据可视化的操作流程。通过对行业年报的爬取和图表可视化,我对于数据有了量化分析的科学严谨认识,同时大大减小了误差以及重复大规模劳动的工作量。爬虫技术是数据收集的第一步,尤其是在本学期的任务当中,针对证券交易所的PDF年报文件,这一步的基础显得至关重要。Pdfplumber库是我目前接触到为数不多的专用解析PDF文件的强大工具,数据提取起来得心应手。Matplotlib的数据可视化功能则为图表化展现数据、总结规律提供了十分便宜的路径。金融数据获取处理课程的学习,使我对于分析大批量财务数据,有了方法上的初步认识,并在各次作业和实验报告中亲身体验熟习,使我在增长核心能力的同时体会到了独特的成就感。感谢吴老师高质量、宽视野、厚心意的严谨教学,这对我今后的学术和事业,无论任何领域,都将起到弥足珍贵的作用!
# -*- coding: utf-8 -*-
import web_crawling as wc
import find_assignment as fa
import download as dl
import tool
import read_data as rd
import draw_pics as dp
import pandas as pd
import numpy as np
if __name__ == "__main__":
df_code = fa.find_assignment(tool.get_No(),10)
code_list = df_code['code_list']
name_list = df_code['name_list']
for code in code_list:
wc.get_table(code)
print("股票" + code + " completed...")
for code in code_list:
dl.get_pdf_link(code)
print("股票" + code + "的年报下载 completed...")
tool.clean_pdf()
data = rd.read_all_data(df_code)
seperated_data = tool.seperate_df(df_code,data)
np.save('seperated_data.npy',seperated_data)
seperated_data = np.load('seperated_data.npy',allow_pickle = 'True').item()
for key in seperated_data.keys():
dp.draw_pics_twinx(seperated_data.get(key))
import fitz
import re
import pandas as pd
#判断行业中上市公司个数是否满足大于等于10的要求
def does_match(text):
if len(re.findall('\n\d{6}\n',text)) < 10:
return False
else:
return True
def find_assignment(No,num):
#No为int类型,表示在本次作业中该学生的序号
#num代表该行业前num家上市公司
#读取所有的内容
text = ''
with fitz.open('../1638277734844_11692.pdf') as doc:
for page in doc:
text = text + page.get_text('text')
#找到所有行业的两位代码
locs = re.finditer('\n\d{2}\n',text)
#注意locs里面可能有重复的行业标号,需要筛选一下
loc_dict = {}
for loc in locs:
#loc.span()的结果为左开右闭的区间,去除两端的换行符
s = loc.span()[0] + 1
e = loc.span()[1] - 1
if text[s:e] in loc_dict:
continue
else:
loc_dict[text[s:e]] = [s,e]
#获取有效行业(上市公司>=10),将他们放入列表effective_industries中,
last_key = '' #保存上一次循环中的key
last_value = 0 #保存上一次循环中的value[1],即行业代码的索引的后一位置(为换行符)
effective_industries = []
for key,value in loc_dict.items():
if key != '01':
subtext = text[last_value:value[0]]
if does_match(subtext) == False:
last_key = key
last_value = value[1]
continue
else:
effective_industries.append(last_key)
#第一个的key必定是01,所以第一次循环直接跳到这一步
last_key = key
last_value = value[1]
#注意,最后还剩下一部分没循环到
subtext = text[last_value:len(text)]
if does_match(subtext) == True:
effective_industries.append(key)
#判断No匹配哪个行业
#可能会出现No超过了有效行业数,故采用模运算
No = No % len(effective_industries)
my_industry = effective_industries[No-1]
print('第'+ str(No) + '号的作业是行业 ' + my_industry)
'''
附加代码,找到自己的行业包含的所有公司代码,以列表返回
'''
s = loc_dict.get(my_industry)[1]
#获得下一个键值对,如'01'之后为'02'
if int(my_industry) < 9:
nxt = '0' + str(int(my_industry) + 1)
elif int(my_industry) == 9:
nxt = '10'
else:
nxt = str(int(my_industry) + 1)
e = loc_dict.get(nxt)[0]
subtext = text[s:e]
code_list = re.findall('\n\d{6}\n',subtext)
code_list = [code.strip() for code in code_list]
'''
附加代码,找到自己的行业包含的所有公司名称,以列表返回
'''
name_list = []
for code in code_list:
code_first_loc = subtext.find(code)
start = code_first_loc + 7
end = subtext.find('\n', start)
name = subtext[start : end]
name_list.append(name)
'''
把公司代码code_list和公司名称name_list合并成dataframe
'''
df = {'code_list':code_list[0:num], 'name_list':name_list[0:num]}
df = pd.DataFrame(df)
return df
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import tool
def get_table_sse(code):#code here refers to stock code
browser = webdriver.Chrome()
url = 'http://www.sse.com.cn/disclosure/listedinfo/regular/'
browser.get(url)
time.sleep(3)
browser.set_window_size(1550, 830)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
time.sleep(3)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
# dropdown = browser.find_element(By.CSS_SELECTOR, ".dropup > .selectpicker")
# dropdown.find_element(By.XPATH, "//option[. = '年报']").click()
time.sleep(3)#sleep的原因是需要等待浏览器渲染
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
fname = f'../nianbao/{code}.html'
with open(fname,'w',encoding='utf-8') as f:
f.write(table_html)
def get_table_szse(code):
browser = webdriver.Chrome()
url = 'http://www.szse.cn/disclosure/listed/fixed/index.html'
browser.get(url)
time.sleep(3)
browser.set_window_size(1550, 840)
browser.find_element(By.ID, "input_code").click()
browser.find_element(By.ID, "input_code").send_keys(code)
time.sleep(3)
browser.find_element(By.CSS_SELECTOR, ".active:nth-child(1) > a").click()
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
time.sleep(3)
browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(3)
css_selector = "#disclosure-table > div > div.table-con-outer > div > table"
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
fname = f'../nianbao/{code}.html'
with open(fname,'w',encoding='utf-8') as f:
f.write(table_html)
def get_table(code):
market = tool.which_market(code)
if market == 'sse':
get_table_sse(code)
elif market == 'szse':
get_table_szse(code)
import re
import tool
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import requests
def download_pdf_from_szse(url):
options = webdriver.ChromeOptions()
download_path = "D:\\CS\\py_fi\\scores_3\\nianbao\\src\\pdf"
profile = {"plugins.plugins_list": [{"enabled": False, "name": "Chrome PDF Viewer"}],
"download.default_directory": download_path}
options.add_experimental_option("prefs", profile)
browser = webdriver.Chrome(chrome_options=options)
browser.get(url)
time.sleep(3)
browser.set_window_size(1552, 840)
browser.find_element(By.ID, "annouceDownloadBtn").click()
#简便起见,直接使用sleep函数等待下载.但最好还是想办法循环判断是否下载完成
time.sleep(15)
print(url + '\n下载完成')
def get_pdf_link_from_szse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('',re.DOTALL)
links = pattern.findall(html)
#得到的url包含英文版年报或者摘要,需要将这两种年报链接去除
full_links = []
for lk in links:
if '摘要' in lk[1] or '英文' in lk[1]:
continue
else:
full_links.append(lk[0])
for i in range(0,len(full_links)):
full_links[i] = 'https://www.szse.cn' + full_links[i]
'''
以上是获取所有的下载链接
下面是下载,需要调用download_pdf模块
'''
for i in range(0,min(len(full_links),10)):
try: download_pdf_from_szse(full_links[i])
except: print('股票'+code+'缺失,请到'+
full_links[i]+'重新下载')
def download_pdf_from_sse(url):
fname = '../pdf/' + url.split('/')[-1]
with open(fname,'wb') as pdf:
pdf.write(requests.get(url).content)
print(url + '\n下载完成')
def get_pdf_link_from_sse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('',re.DOTALL)
links = pattern.findall(html)
#得到的url包含摘要,需要将这三种年报链接去除
full_links = []
for lk in links:
if '摘要' in lk[1] or '英文' in lk[1]:
continue
else:
full_links.append(lk[0])
for i in range(0,len(full_links)):
full_links[i] = 'http://www.sse.com.cn' + full_links[i]
'''
以上是获取所有的下载链接
下面是下载pdf文件,需要调用download_pdf模块
'''
for i in range(0,min(len(full_links),10)):
try: download_pdf_from_sse(full_links[i])
except: print('股票'+code+'缺失,请到'+
full_links[i]+'重新下载')
def get_pdf_link(code):
market = tool.which_market(code)
if market == 'sse':
get_pdf_link_from_sse(code)
elif market == 'szse':
get_pdf_link_from_szse(code)
import re
import pandas as pd
import os
import tool
import pdfplumber
def is_fin_number(string):
if string == '':
return False
try:
string = string.strip()
string = string.replace(',','')
except: return False
for s in string:
if s.isdigit() == True or s == '-' or s == '.' or s == ' ' or s == '\n':
continue
else:
return False
return True
def get_data(row,name_mode):
rc = re.compile(name_mode,re.DOTALL)
bound = 0
for i in range(0,len(row)):
rs = None
try:
rs = rc.search(row[i]) #row[i]可能是None
except:
continue
if rs is None:
continue
else:
bound = i
break
if rs is None: #意味着没有找到
return -1
for i in range(bound,len(row)):
if is_fin_number(row[i]) == True:
return row[i]
return 'other row' # 说明虽然匹配到了文字,但数据不在当行
#该页是否是主要会计数据和财务指标
def is_this_page(text):
mode = '\n.*?主+要+会+计+数+据+和+财+务+指+标+.*?\n'
if re.search(mode,text) is None:
return False
else:
return True
def get_twin_data(fname):
earnings = -1
try: #未知原因, 打开文件时会出现assert error
with pdfplumber.open('../pdf/' + fname) as pdf:
s = 0
for i in range(0,len(pdf.pages)):
text = pdf.pages[i].extract_text()
if is_this_page(text) == True:
s = i
break
else:
continue
page_index = 0
bound = 0
for i in range(s,s+2): #deterministic
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
for j in range(0,len(table)):
e = get_data(table[j],'.*?营业收入.*?')
#此时文字和数据错行,需要继续往上搜索
if e == 'other row':
for k in range(j-1, 0,-1):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
e = table[k][h]
break
else:
continue
else:
if is_fin_number(e) == True:
break
if e != -1:
earnings = e
bound = j
break
else:
continue
if earnings == -1:
continue
page_index = i
break
#循环结束仍然没有获得营业收入
if earnings == 0:
return None
net_income = -1
for i in range(page_index,page_index + 2):
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
ni_mode = '.*?归属于.*?(所有者|股东)?的?.?净?.?利?.?润?.*?'
if i == page_index: #说明此时还没有换页
for j in range(bound + 1,len(table)):
ni = get_data(table[j], ni_mode)
#此时文字和数据错行,需要继续往下搜索
if ni == 'other row':
for k in range(j, len(table)):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
net_income = table[k][h]
return [earnings,net_income]
else:
continue
if ni == 'other row':
return 'data is at the next page'
elif ni != -1:
net_income = ni
break
else:
continue
else: #此时换页
for j in range(0,len(table)):
ni = get_data(table[j], ni_mode)
if ni != -1:
net_income = ni
break
else:
continue
if net_income == -1: continue
else: return [earnings,net_income]
except: print(fname+'出现AssertionError')
#该函数需要在pdf目录下查找对应的文件名
def read_all_data(df):
#df为包含两列(code_list和name_list)的dataframe
filename_list = []
year_list = []
data_list = []
for index,row in df.iterrows():
for filepath,dirnames,filenames in os.walk('../pdf'):
for filename in filenames:
#print(filename)
if (row['name_list'] in filename) or (row['code_list'] in filename):
print(filename)
data = get_twin_data(filename)
if data is not None:
filename_list.append(filename)
year_list.append(tool.get_year(filename,row['code_list']))
data_list.append(get_twin_data(filename))
print(filename + ' completed')
rt_list,ni_list = zip(*data_list)
df_data = {'filename':filename_list,'year':year_list,
'营业收入':rt_list,'净利润':ni_list}
df_data = pd.DataFrame(df_data)
return df_data
import os
import re
import pandas as pd
def get_No():
print('程序开始前的注意事项:\n')
print("1.请先下载好相关模块,并在网络通畅的情况下运行本程序;\n")
print("2.本程序的爬虫部分使用的是chrome浏览器,请下载对应的webdriver;\n")
print('3.下载时间较长,请耐心等待;\n')
print('4.由于爬取深交所的代码的下载路径是绝对路径,请先创建如下目录路径:')
print("D:\\CS\\py_fi\\scores_3\\nianbao\\src\\pdf\n")
print('\n\n\n--------程序开始--------\n\n\n')
return int(input("请输入你的序号:"))
def to_wan(num):
return num/10000
def to_yi(num):
return num/100000000
def is_year(string):
if len(string) == 4:
return True
else:
return False
def to_num(string):
if type(string) == type('str'):
string = string.replace(',','')
string = string.replace('\n','')
return float(format(to_yi(float(string)), '.3f'))
else:
return string
def to_year_list(str_list):
for i in range(0,len(str_list)):
str_list[i] = str(str_list[i])
def to_num_list(str_list):
for i in range(0,len(str_list)):
str_list[i] = to_num(str_list[i])
def which_market(code):
if code[0:2] == '60' or code[0:3] == '688' or code[0:3] == '900':
return 'sse'
elif code[0:2] == '00' or code[0:3] == '200' or code[0:2] == '30':
return 'szse'
def clean_pdf():
for filepath,dirnames,filenames in os.walk('../pdf'):
for filename in filenames:
if '取消' in filename:
os.remove('../pdf/'+ filename)
print(filename + '+ deleted')
def get_year_sse(fname):
year = re.search('\d{6}_(\d{4}).*?\.pdf',fname,re.IGNORECASE)
return year.group(1)
def get_year_szse(fname):
year = re.search('.*?(\d{4}).*?\.pdf',fname,re.IGNORECASE)
return year.group(1)
def get_year(fname,code):
m = which_market(code)
if m == 'sse':
return get_year_sse(fname)
elif m == 'szse':
return get_year_szse(fname)
def be_contigious(this_data):
#对于某个公司的绘图数据,我们只取从最近时间到最远时间的连续数据
length = len(this_data)
last = int(this_data['year'][length - 1])
for i in range(length-2, -1, -1):
nxt = int(this_data['year'][i])
if last - nxt != 1:#说明不连续
return this_data.loc[i+1 : length]
else:
continue
return this_data
def seperate_df(df_code,data):
seperated_data = {}
for j,row1 in df_code.iterrows():
name = row1['name_list']
code = row1['code_list']
this_data = pd.DataFrame(columns = ['year','营业收入','净利润'])
for i,row2 in data.iterrows():
fn = row2['filename']
if name in fn or code in fn:
data_dict = {'name': name,
'year': row2['year'],
'营业收入':row2['营业收入'],
'净利润':row2['净利润']}
this_data = this_data.append(data_dict,ignore_index=True)
be_contigious(this_data)
seperated_data[code] = this_data
return seperated_data
import matplotlib.pyplot as plt
import numpy as np
import tool
def draw_pics_twinx(df):
plt.rcParams['figure.dpi'] = 200
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图片显示中文
x = df['year']
tool.to_year_list(x)
y_rt = df['营业收入']
tool.to_num_list(y_rt)
y_ni = df['净利润']
tool.to_num_list(y_ni)
fig = plt.figure()
ax1 = fig.subplots()
ax1.plot(x, y_rt,'steelblue',label="营业收入",linestyle='-',linewidth=2,
marker='o',markeredgecolor='pink',markersize='2',markeredgewidth=2)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_rt[i],(y_rt[i]),fontsize = '10')
ax1.legend(loc = 6)
ax2 = ax1.twinx()
ax2.plot(x, y_ni, 'orange',label = "归属于股东的净利润",linestyle='-',linewidth=2,
marker='o',markeredgecolor='teal',markersize='2',markeredgewidth=2)
ax2.set_ylabel('归属于股东的净利润(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_ni[i],(y_ni[i]),fontsize = '10')
ax2.legend(loc = 2)
'''
title部分必须放最后,否则会出现左边的y轴有重复刻度的问题
'''
title = df['name'][0] + '历年' + '财务数据'
plt.title(title)
plt.savefig('../pics/' + title + '.png')
plt.show()