print('大作业实验报告')
#####运行
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
import datetime
mpl.rcParams['font.sans-serif']=['FangSong']
mpl.rcParams['axes.unicode_minus']=False
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
import requests
import fitz
import re
import pandas as pd
from pprint import pprint
import os
##需要的股票代码
codes1=['688566',
'688575',
'688578',
'688606',
'688656',
'688658',
'688670',
'688687',
'688767',
'688799']
codes2=['688575',
'688670',
'688767' ]
codes3=['688566',
'688575',
'688578',
# '688606', #
'688656',
'688658',
'688670',
'688687',
# '688767', #
'688799']
##################################
###1.批量下载PDF网站
from get_html import pl_get_table_see
pl_get_table_see(codes1)
##################################
##2.删除无关的网站
from leach import pl_shanchu,pl_filter_nb_10y
pl_shanchu(codes1)
pl_filter_nb_10y(codes1)
##################################
##3.下载年报
from download import prepare_hrefs_years,download_pdfs
for code in codes1:
fname = f'C:/Users/lenovo/Desktop/{code}.csv'
df =pd.read_csv(fname)
n=prepare_hrefs_years(df)
hrefs=n[0]
years=n[1]
download_pdfs(hrefs,code,years)
利用定义的函数从网址获取到下载网址,再对网址进行过滤,接着根据过滤好的网址来下载年报PDF文件。
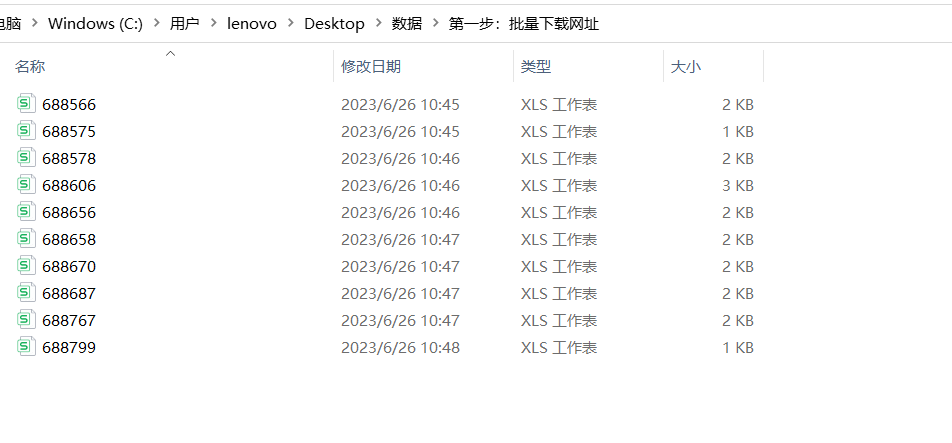
1.结果一:下载的网址文件。
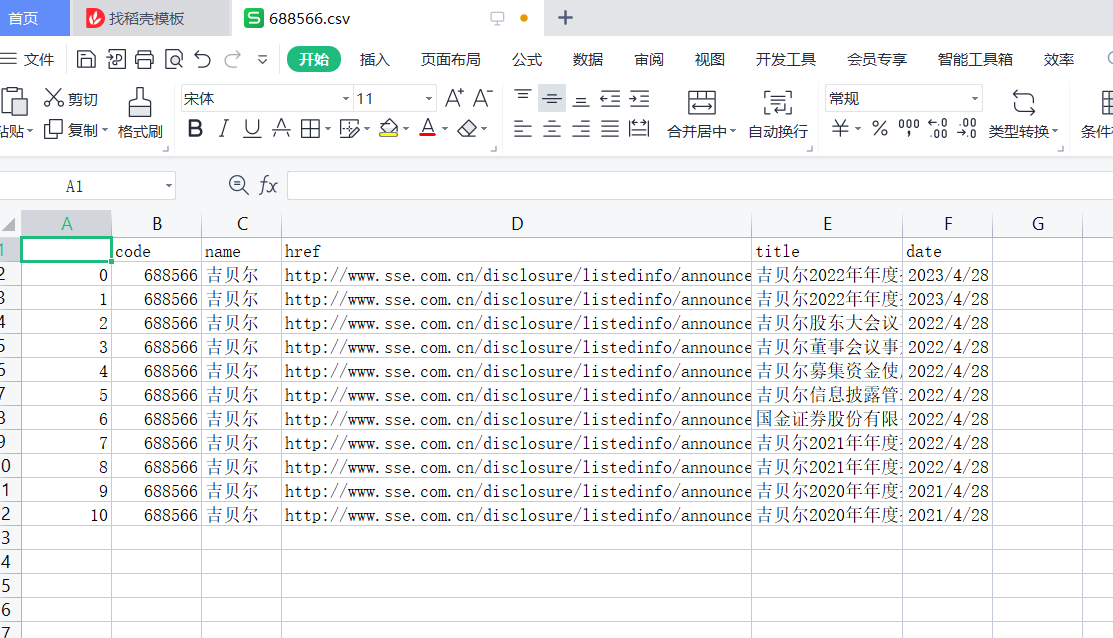
2.结果一(以688566为例):结果一具体截图以股票688566来展示(由于公司上市时间比较晚,故数据量少)。
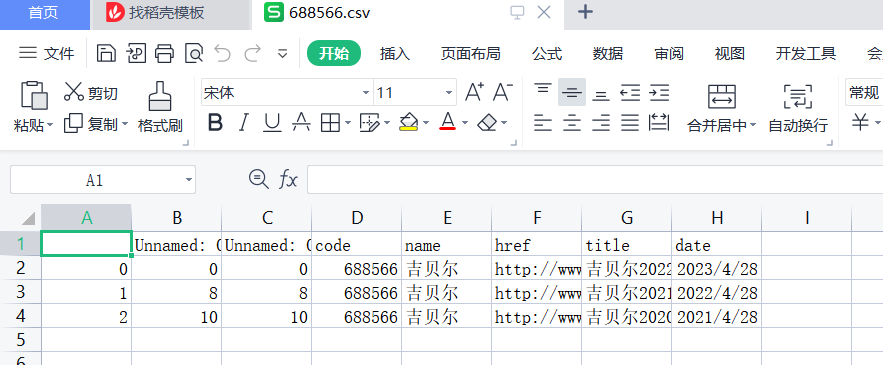
3.结果二(以688566为例):过滤后的网址文件
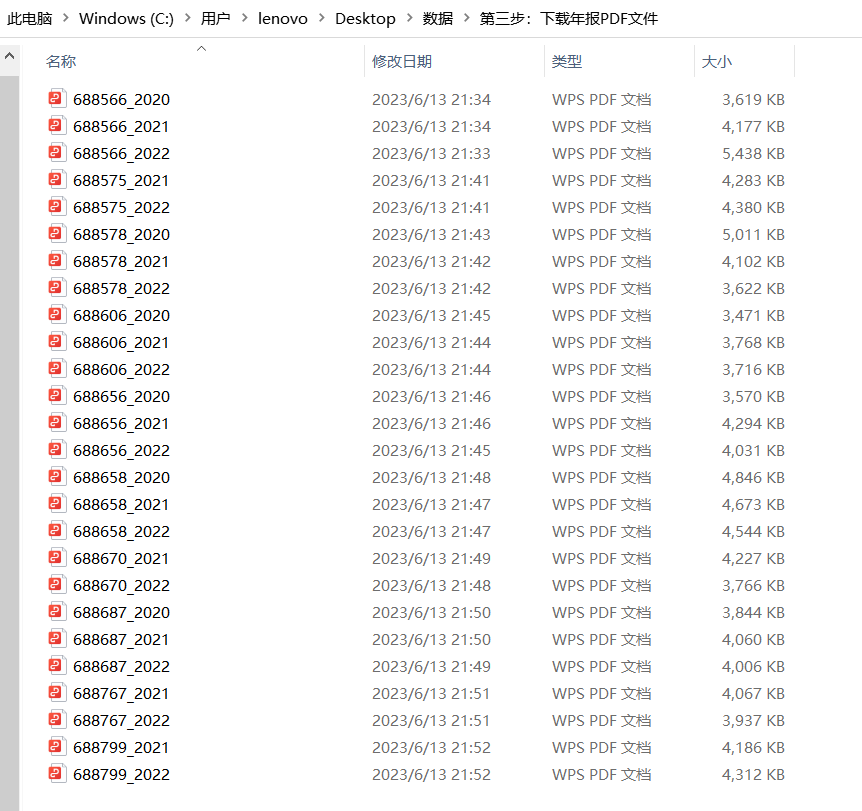
4.结果三:下载好的年报PDF文件