import pdfplumber
import pandas as pd
import re
import fitz
import os
os.chdir("./Final Project")
#把PDF解析成列表
def Pdf_extract_table(filename):
pdf = pdfplumber.open(filename)
page_count = len(pdf.pages)
data = []
for i in range(page_count):
data += pdf.pages[i].extract_table()
pdf.close()
return data
#将上述列表转化成完整的数据框
def Get_alllist(data):
df = pd.DataFrame(data, columns=data[0]).iloc[:, 1:] #去掉第一列
df = df.ffill() #将所属行业类型向后填充
return df
table = Pdf_extract_table("行业分类.pdf") #把PDF解析成列表
company = Get_alllist(table) #将上述列表转化成完整的数据框
companylist = company.loc[company['行业大类代码'] == "15"]
company_list = companylist.loc[ : ,"上市公司简称"][-10:]#第二轮从后往前
company_list[296]="安德利"#运行到该家公司会报错,在 http://www.cninfo.com.cn/new/data/szse_stock.json 查找后发现德利股份改名为安德利
companylist = companylist.iloc[-10:]
for i in range(len(company_list)):# 把*ST前面的"*"
company_list.iloc[i] = company_list.iloc[i].replace('*', '')
#参考https://zhuanlan.zhihu.com/p/377143422
import json
import os
from time import sleep
from urllib import parse
import requests
# #试错次数过多,网站检测到爬虫,断开链接--解决方法:换地址
def get_adress(company_list):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': company_list,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0 (Linux; Android 10; SM-G981B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Mobile Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] # 获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId, plate, code)
return orgId, plate, code
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if "200" in report['announcementTitle']:#但如果将2010/2011也纳入忽略范围时会无法下载,仅建空文件夹
continue
if 'H' in report['announcementTitle']:
continue
if '已取消' in report['announcementTitle']:
continue
if '英文版' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
year = re.findall(r'\b\d{4}\b', pdf_url)
year = [int(i) - 1 for i in year]
year ="".join(list(map(str,year)))
# file_name = report['announcementTitle']
print("正在下载:" + pdf_url, company + year +"年年度报告")
#下载
r = requests.get(pdf_url)
f = open(company +"/"+ company + year +"年年度报告" + ".pdf", "wb")#统一文件名
f.write(r.content)
sleep(2)
if __name__ == '__main__':
for company in company_list[:]:
os.mkdir(company)
orgId, plate, code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载下一家")
print("全部下载完毕!")
file_dir = "E:\\learn\\大三下\\金融数据获取与处理\\Final Project"
filepath=file_dir
filelist=[]
pdfpath=[]
list1= os.listdir(filepath)
for file1 in list1:
path = os.path.join(filepath, file1)
# print(file1)
if os.path.isfile(path):
filelist.append(file1)
pdfpath.append(path)
else:
list2=os.listdir(path)
for file2 in list2:
path2 = os.path.join(path, file2)
# print(file2)
if os.path.isfile(path2):
filelist.append(file2)
pdfpath.append(path2)
filelist.remove('行业分类.pdf')
pdfpath.remove('E:\learn\大三下\金融数据获取与处理\Final Project\行业分类.pdf')
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首尾页码
start_pageno=0
end_pageno=len(doc)-1
#
lb,ub=bounds
#获取左界页码
for n in range(len(doc)):
page=doc[n]
txt=page.get_text()
if lb in txt:
start_pageno=n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno=n
break
#获取小范围内字符串
txt=''
for n in range(start_pageno,end_pageno+1):
page=doc[n]
txt += page.get_text()
return(txt)
#获取表头
def get_th_span(txt):
nianfen='(20\d\d|199\d)\s*?年' #2016和年之间是空格,而2016年和2015年之间是空格
s=f'{nianfen}\s*{nianfen}.*?{nianfen}'
p=re.compile(s,re.DOTALL) #re.DOTALL指.遇到换行符也是可以的
matchobj=p.search(txt)
#
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2) == 1) and (int(year2)-int(year3) == 1)
#
while (not flag):
matchobj=p.search(txt[end:])
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=(int(year1)-int(year2) == 1)
flag=flag and (int(year2)-int(year3) ==1)
return(matchobj.span())
#获取表格边界
def get_bounds(txt):
th_span_1st=get_th_span(txt)
end=th_span_1st[1]
th_span_2nd=get_th_span(txt[end:])
th_span_2nd=(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'): #如果最后一个不是数字
e=e-1
return(s,e+1)
#获取‘营业收入’和‘归属于上市公司股\n东的净利润’
def get_account_data(account,txt):
p_txt='%s\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)' % account #%s是占位符,用‘account’替换,\D是非数字,\d{1,3}是数字1或2或3个,*可重复,?非贪婪,()内是所要的数字,小数点后\d+表示小数点后至少一位数字
p=re.compile(p_txt)
matchobj=p.search(txt)
amt=matchobj.group(1)
return(amt)
#获取整张表格
# subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
def get_keywords(txt):
p=re.compile(r's\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)')
keywords=p.findall(txt)
return(keywords)
def parse_key_fin_data(subtxt,keywords):
# keywords=['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss=[]
s=0
for kw in keywords:
n=subtxt.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtxt))
data=[]
p=re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2=re.compile('\s')
for n in range(len(ss)-1):
s=ss[n]
e=ss[n+1]
line=subtxt[s:e]
#获取可能换行的账户名称
matchobj=p.search(line)
account_name=p2.sub('',matchobj.group())
#获取三年数据
amnts=line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
import matplotlib.pyplot as plt
# from pylab import *
plt.rcParams['font.sans-serif'] = ['SimHei']
#东鹏特饮 仅2年年报
filename='E:\learn\大三下\金融数据获取与处理\Final Project\东鹏饮料\东鹏饮料2021年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
dp_sr=[]
dp_jlr=[]
dp_sr.append(data_get[4])#19
dp_jlr.append(data_get[10])#19
filename='E:\learn\大三下\金融数据获取与处理\Final Project\东鹏饮料\东鹏饮料2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
dp_year=['2019年','2020年','2021年','2022年']
dp_sr.append(data_get[4])#20
dp_sr.append(data_get[2])#21
dp_sr.append(data_get[1])#22
dp_jlr.append(data_get[10])#20
dp_jlr.append(data_get[8])#21
dp_jlr.append(data_get[7])#22
#今世缘
jsy_sr=[]
jsy_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\今世缘\今世缘2014年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jsy_sr.append(data_get[4])
jsy_jlr.append(data_get[10])
jsy_sr.append(data_get[2])
jsy_jlr.append(data_get[8])
jsy_sr.append(data_get[1])
jsy_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\今世缘\今世缘2017年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jsy_sr.append(data_get[5])
jsy_jlr.append(data_get[13])
jsy_sr.append(data_get[2])
jsy_jlr.append(data_get[10])
jsy_sr.append(data_get[1])
jsy_jlr.append(data_get[9])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\今世缘\今世缘2020年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jsy_sr.append(data_get[4])
jsy_jlr.append(data_get[10])
jsy_sr.append(data_get[2])
jsy_jlr.append(data_get[8])
jsy_sr.append(data_get[1])
jsy_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\今世缘\今世缘2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jsy_sr.append(data_get[2])
jsy_jlr.append(data_get[8])
jsy_sr.append(data_get[1])
jsy_jlr.append(data_get[7])
# year=['2019年','2020年','2021年','2022年']
#口子窖
kzj_sr=[]
kzj_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2015年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
kzj_sr.append(data_get[4])
kzj_jlr.append(data_get[10])
kzj_sr.append(data_get[2])
kzj_jlr.append(data_get[8])
kzj_sr.append(data_get[1])
kzj_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2018年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
kzj_sr.append(data_get[4])
kzj_jlr.append(data_get[15])
kzj_sr.append(data_get[2])
kzj_jlr.append(data_get[13])
kzj_sr.append(data_get[1])
kzj_jlr.append(data_get[12])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2021年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
kzj_sr.append(data_get[4])
kzj_jlr.append(data_get[10])
kzj_sr.append(data_get[2])
kzj_jlr.append(data_get[8])
kzj_sr.append(data_get[1])
kzj_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
kzj_sr.append(data_get[1])
kzj_jlr.append(data_get[7])
#均瑶健康
jyjk_sr=[]
jyjk_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\均瑶健康\均瑶健康2020年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jyjk_sr.append(data_get[4])
jyjk_jlr.append(data_get[10])
jyjk_sr.append(data_get[2])
jyjk_jlr.append(data_get[8])
jyjk_sr.append(data_get[1])
jyjk_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
jyjk_sr.append(data_get[2])
jyjk_jlr.append(data_get[8])
jyjk_sr.append(data_get[1])
jyjk_jlr.append(data_get[7])
#威龙股份
wlgf_sr=[]
wlgf_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\威龙股份\威龙股份2016年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
data_get2=data[1]
wlgf_sr.append(data_get[4])
wlgf_jlr.append(data_get2[4])
wlgf_sr.append(data_get[2])
wlgf_jlr.append(data_get2[1])
wlgf_sr.append(data_get[1])
wlgf_jlr.append(data_get2[1])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\威龙股份\威龙股份2019年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
wlgf_sr.append(data_get[4])
wlgf_jlr.append(data_get[10])
wlgf_sr.append(data_get[2])
wlgf_jlr.append(data_get[8])
wlgf_sr.append(data_get[1])
wlgf_jlr.append(data_get2[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\威龙股份\威龙股份2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
wlgf_sr.append(data_get[4])
wlgf_jlr.append(data_get[42])
wlgf_sr.append(data_get[2])
wlgf_jlr.append(data_get[40])
wlgf_sr.append(data_get[1])
wlgf_jlr.append(data_get[39])
#安德利
adl_sr=[]
adl_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\安德利\安德利2020年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
adl_sr.append(data_get[4])
adl_jlr.append(data_get[10])
adl_sr.append(data_get[2])
adl_jlr.append(data_get[8])
adl_sr.append(data_get[1])
adl_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\安德利\安德利2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
adl_sr.append(data_get[2])
adl_jlr.append(data_get[8])
adl_sr.append(data_get[1])
adl_jlr.append(data_get[7])
#李子园
lzy_sr=[]
lzy_jlr=[]
filename='E:\learn\大三下\金融数据获取与处理\Final Project\李子园\李子园2020年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
data_get2=data[1]
lzy_sr.append(data_get[4])
lzy_jlr.append(data_get2[4])
lzy_sr.append(data_get[2])
lzy_jlr.append(data_get2[2])
lzy_sr.append(data_get[1])
lzy_jlr.append(data_get2[1])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\安德利\安德利2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
lzy_sr.append(data_get[2])
lzy_jlr.append(data_get[8])
lzy_sr.append(data_get[1])
lzy_jlr.append(data_get[7])
#迎驾贡酒
yjgj_sr=[]
yjgj_jlr=[]
filename=['E:\learn\大三下\金融数据获取与处理\Final Project\迎驾贡酒\迎驾贡酒2015年年度报告.pdf' ,'E:\learn\大三下\金融数据获取与处理\Final Project\迎驾贡酒\迎驾贡酒2018年年度报告.pdf' ]
for i in filename:
doc=fitz.open(i)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
yjgj_sr.append(data_get[4])
yjgj_jlr.append(data_get[10])
yjgj_sr.append(data_get[2])
yjgj_jlr.append(data_get[8])
yjgj_sr.append(data_get[1])
yjgj_jlr.append(data_get[7])
filename=['E:\learn\大三下\金融数据获取与处理\Final Project\迎驾贡酒\迎驾贡酒2020年年度报告.pdf' ,'E:\learn\大三下\金融数据获取与处理\Final Project\迎驾贡酒\迎驾贡酒2022年年度报告.pdf' ]
for i in filename:
doc=fitz.open(i)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
yjgj_sr.append(data_get[2])
yjgj_jlr.append(data_get[8])
yjgj_sr.append(data_get[1])
yjgj_jlr.append(data_get[7])
#金徽酒
jhj_sr=[]
jhj_jlr=[]
filename=['E:\learn\大三下\金融数据获取与处理\Final Project\金徽酒\金徽酒2016年年度报告.pdf' ,'E:\learn\大三下\金融数据获取与处理\Final Project\金徽酒\金徽酒2019年年度报告.pdf' ,'E:\learn\大三下\金融数据获取与处理\Final Project\金徽酒\金徽酒2022年年度报告.pdf' ]
for i in filename:
doc=fitz.open(i)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
data_get2=data[1]
jhj_sr.append(data_get[4])
jhj_jlr.append(data_get2[4])
jhj_sr.append(data_get[2])
jhj_jlr.append(data_get2[2])
jhj_sr.append(data_get[1])
jhj_jlr.append(data_get2[1])
#香飘飘
xpp_sr=[]
xpp_jlr=[]
filename=['E:\learn\大三下\金融数据获取与处理\Final Project\香飘飘\香飘飘2017年年度报告.pdf' ,'E:\learn\大三下\金融数据获取与处理\Final Project\香飘飘\香飘飘2020年年度报告.pdf' ]
for i in filename:
doc=fitz.open(i)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
xpp_sr.append(data_get[4])
xpp_jlr.append(data_get[10])
xpp_sr.append(data_get[2])
xpp_jlr.append(data_get[8])
xpp_sr.append(data_get[1])
xpp_jlr.append(data_get[7])
filename='E:\learn\大三下\金融数据获取与处理\Final Project\香飘飘\香飘飘2022年年度报告.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
keywords=['营业收入','归属于上市公司股东的净利润']
data=parse_key_fin_data(subtxt, keywords)
data_get=data[0]
xpp_sr.append(data_get[2])
xpp_jlr.append(data_get[8])
xpp_sr.append(data_get[1])
xpp_jlr.append(data_get[7])
#将str转化为float
def tran(data,newlist):
for i in data:
i=i.replace(',','')
newlist.append(float(i))
#dp
dp1=[]
tran(dp_sr,dp1)
dp2=[]
tran(dp_jlr,dp2)
#jsy
jsy1=[]
tran(jsy_sr,jsy1)
jsy2=[]
tran(jsy_jlr,jsy2)
#kzj
kzj1=[]
kzj1=[]
tran(kzj_sr,kzj1)
kzj2=[]
tran(kzj_jlr,kzj2)
#jyjk
jyjk1=[]
tran(jyjk_sr,jyjk1)
jyjk2=[]
tran(jyjk_jlr,jyjk2)
#wlgf
wlgf1=[]
tran(wlgf_sr,wlgf1)
wlgf2=[]
tran(wlgf_jlr,wlgf2)
#adl
adl1=[]
tran(adl_sr,adl1)
adl2=[]
tran(adl_jlr,adl2)
#lzy
lzy1=[]
tran(lzy_sr,lzy1)
lzy2=[]
tran(lzy_jlr,lzy2)
#yjgj
yjgj1=[]
tran(yjgj_sr,yjgj1)
yjgj2=[]
tran(yjgj_jlr,yjgj2)
#jhj
jhj1=[]
tran(jhj_sr,jhj1)
jhj2=[]
tran(jhj_jlr,jhj2)
#xpp
xpp1=[]
tran(xpp_sr,xpp1)
xpp2=[]
tran(xpp_jlr,xpp2)
#画图
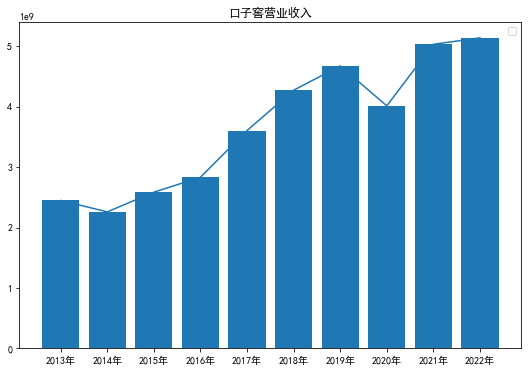
ykzj=['2013年','2014年','2015年','2016年','2017年','2018年','2019年','2020年','2021年','2022年']
plt.figure(figsize=(9, 6))
plt.plot(ykzj,kzj1)
plt.bar(ykzj,kzj1)
plt.title(u'口子窖营业收入')
plt.legend()
plt.show()
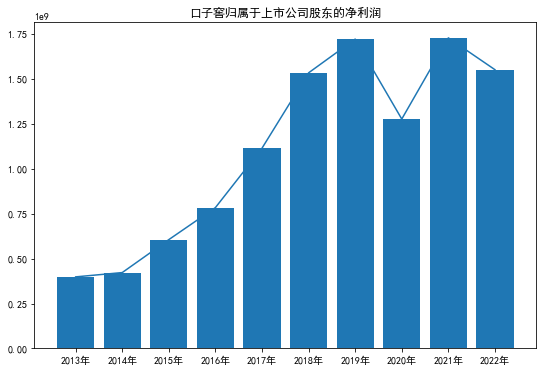
plt.figure(figsize=(9, 6))
plt.plot(ykzj,kzj2)
plt.bar(ykzj,kzj2)
plt.title(u'口子窖归属于上市公司股东的净利润')
plt.show()
#多公司比较
#营业收入
form={'东鹏饮料':dp1}
a = ['2013','2014','2015','2016','2017','2018','2019','2020','2021','2022']
b_1 = [None,None,None,None,None,None]+dp1
b_2 = jsy1[1:]
b_3 = kzj1
b_4 = [None,None,None,None,None]+jyjk1
b_5 = [None]+wlgf1
b_6 = [None,None,None,None,None]+adl1
b_7 = [None,None,None,None,None]+lzy1
b_8 = yjgj1
b_9 = [None]+jhj1
b_10 = [None,None]+xpp1
#设置图片尺寸与清晰度
plt.figure(figsize=(10, 8), dpi=80)
#导入数据,绘制条形图
plt.plot(a, b_1, marker = "o", mfc = "white", label='东鹏饮料')
plt.plot( a,b_2, marker = "o", mfc = "white",label='今世缘')
plt.plot( a,b_3, marker = "o", mfc = "white",label='口子窖')
plt.plot( a,b_4, marker = "o", mfc = "white", label='均瑶健康')
plt.plot( a,b_5, marker = "o", mfc = "white",label='威龙股份')
plt.plot( a,b_6, marker = "o", mfc = "white",label='安德利')
plt.plot( a,b_7, marker = "o", mfc = "white",label='李子园')
plt.plot( a,b_8, marker = "o", mfc = "white", label='迎驾贡酒')
plt.plot( a,b_9, marker = "o", mfc = "white", label='金徽酒')
plt.plot( a,b_10, marker = "o", mfc = "white", label='香飘飘')
#添加标题
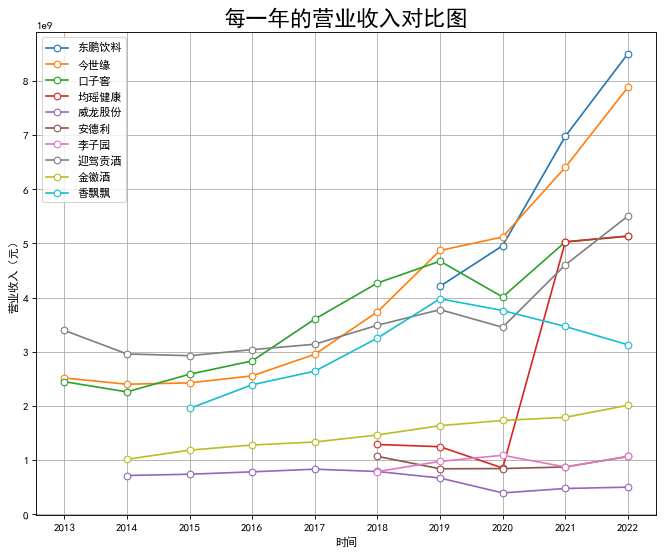
plt.title('每一年的营业收入对比图', size=20)
#添加xy轴
plt.xlabel('时间')
plt.ylabel('营业收入(元)')
#x轴刻度
plt.grid()
plt.legend()
#展示效果图
plt.show()
#dp
filename="E:\learn\大三下\金融数据获取与处理\Final Project\东鹏饮料\东鹏饮料2021年年度报告.pdf"
pdf = pdfplumber.open(filename)
page1 = pdf.pages[4]
table1 = page1.extract_tables()[2]
df1 = pd.DataFrame(table1)
page2 = pdf.pages[5]
table2 = page2.extract_tables()[0]
df2 = pd.DataFrame(table2)
dp=pd.concat([df1,df2], ignore_index=True)
dp.set_index([0],inplace=True)
dp=dp.iloc[:,0]
dp=pd.DataFrame(dp)
dp.columns=["东鹏饮料"]
#jsy
filename="E:\learn\大三下\金融数据获取与处理\Final Project\今世缘\今世缘2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page1 = pdf.pages[3]
table1 = page1.extract_tables()[2]
df1 = pd.DataFrame(table1)
page2 = pdf.pages[3]
table2 = page2.extract_tables()[3]
df2 = pd.DataFrame(table2)
jsy=pd.concat([df1,df2], ignore_index=True)
jsy.set_index([0],inplace=True)
jsy=jsy.iloc[:,0]
jsy=pd.DataFrame(jsy)
jsy.columns=["今世缘"]
#kzj
filename="E:\learn\大三下\金融数据获取与处理\Final Project\口子窖\口子窖2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page1 = pdf.pages[3]
table1 = page1.extract_tables()[2]
df1 = pd.DataFrame(table1)
page2 = pdf.pages[3]
table2 = page2.extract_tables()[3]
df2 = pd.DataFrame(table2)
page3 = pdf.pages[4]
table3 = page3.extract_tables()[0]
df3 = pd.DataFrame(table3)
kzj=pd.concat([df1,df2,df3], ignore_index=True)
kzj.set_index([0],inplace=True)
kzj=pd.DataFrame(kzj)
kzj.columns=["口子窖"]
#jyjk
filename="E:\learn\大三下\金融数据获取与处理\Final Project\均瑶健康\均瑶健康2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page1 = pdf.pages[5]
table1 = page1.extract_tables()[2]
df1 = pd.DataFrame(table1)
table2 = page1.extract_tables()[3]
df2 = pd.DataFrame(table2)
jyjk=pd.concat([df1,df2], ignore_index=True)
jyjk.set_index([0],inplace=True)
jyjk=jyjk.iloc[:,0]
jyjk=pd.DataFrame(jyjk)
jyjk.columns=["均瑶健康"]
#wlgf
filename="E:\learn\大三下\金融数据获取与处理\Final Project\威龙股份\威龙股份2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page1 = pdf.pages[4]
table1 = page1.extract_tables()[2]
df1 = pd.DataFrame(table1)
table2 = page1.extract_tables()[3]
df2 = pd.DataFrame(table2)
wlgf=pd.concat([df1,df2], ignore_index=True)
wlgf.set_index([0],inplace=True)
wlgf=wlgf.iloc[:,0]
wlgf=pd.DataFrame(wlgf)
wlgf.columns=["威龙股份"]
#adl
filename="E:\learn\大三下\金融数据获取与处理\Final Project\安德利\安德利2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page = pdf.pages[4]
table1 = page.extract_tables()[0]
df1 = pd.DataFrame(table1)
table2 = page.extract_tables()[1]
df2 = pd.DataFrame(table2)
adl=pd.concat([df1,df2], ignore_index=True)
adl.set_index([0],inplace=True)
adl=adl.iloc[:,0]
adl=pd.DataFrame(adl)
adl.columns=["安德利"]
#lzy
filename="E:\learn\大三下\金融数据获取与处理\Final Project\李子园\李子园2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page = pdf.pages[5]
table1 = page.extract_tables()[1]
df1 = pd.DataFrame(table1)
table2 = page.extract_tables()[2]
df2 = pd.DataFrame(table2)
lzy=pd.concat([df1,df2], ignore_index=True)
lzy.set_index([0],inplace=True)
lzy=lzy.iloc[:,0]
lzy=pd.DataFrame(lzy)
lzy.columns=["李子园"]
#yjgj
filename="E:\learn\大三下\金融数据获取与处理\Final Project\迎驾贡酒\迎驾贡酒2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page = pdf.pages[3]
table1 = page.extract_tables()[2]
df1 = pd.DataFrame(table1)
page = pdf.pages[4]
table2 = page.extract_tables()[0]
df2 = pd.DataFrame(table2)
yjgj=pd.concat([df1,df2], ignore_index=True)
yjgj.set_index([0],inplace=True)
yjgj=yjgj.iloc[:,0]
yjgj=pd.DataFrame(yjgj)
yjgj.columns=["迎驾贡酒"]
#jhj表格不规则 半手动提取
import numpy as np
filename="E:\learn\大三下\金融数据获取与处理\Final Project\金徽酒\金徽酒2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page = pdf.pages[4]
table1 = page.extract_tables()[0]
df1 = pd.DataFrame(table1)[1]
df3 = pd.DataFrame(np.array(['','','','姓名','联系地址','电话','传真','电子信箱']))
df1=pd.concat([df3,df1],axis=1, ignore_index=True)[1:]
df1=df1.drop([2])
df2 =pd.DataFrame([['公司注册地址','甘肃省陇南市徽县伏家镇'],['公司注册地址的历史变更情况','不适用'],['公司办公地址','甘肃省陇南市徽县伏家镇'],['公司办公地址的邮政编码','742308'],['公司网址','www.jinhuijiu.com'],['电子信箱','jhj@jinhuijiu.com']])
jhj=pd.concat([df1,df2], ignore_index=True)
jhj.set_index([0],inplace=True)
jhj=pd.DataFrame(jhj)
jhj.columns=["金徽酒"]
#xpp
filename="E:\learn\大三下\金融数据获取与处理\Final Project\香飘飘\香飘飘2022年年度报告.pdf"
pdf = pdfplumber.open(filename)
page = pdf.pages[5]
table1 = page.extract_tables()[1]
df1 = pd.DataFrame(table1)
table2 = page.extract_tables()[2]
df2 = pd.DataFrame(table2)
xpp=pd.concat([df1,df2], ignore_index=True)
xpp.set_index([0],inplace=True)
xpp=xpp.iloc[:,0]
xpp=pd.DataFrame(xpp)
xpp.columns=["香飘飘"]
allinfo= pd.concat([dp, jsy,kzj,jyjk,wlgf,adl,lzy,yjgj,jhj,xpp], axis=1, ignore_index=False)
allinfo=allinfo.iloc[1:]

营业收入: 大部分公司总体上涨,部分公司波动较大,且香飘飘、威龙股份主要呈现下降的趋势。
从对比图的结果来看,东鹏饮料与今世缘等公司涨势凶猛,金徽酒则较为平稳。体现产业投资向高附加值产品倾斜。
结果总结:从细分龙头发展历程看集中度发展趋势:2010年-2020年我国制造业细分龙头企业不断崛起,产业内的地位持续巩固。对比盈利能力,大多数龙头公司的利润率都要优于各自行业水平。往后看,预计各类行业集中度将进一步呈现上升趋势。首先,中游原材料加工业方面,碳中和及碳达峰将推动集中度持续提升。具备成本优势、技术优势的行业龙头企业将脱颖而出。下游制造业方面,龙头企业凭借高研发力度建立成长优势,奠定强者恒强的局面。下游消费品方面,在社会消费升级的环境下消费行业龙头更容易通过推出高端产品、加大营销等方式扩张市场占有率。
过程艰难,由于是公司列表从后往前的第二轮,大部分公司的年报数量都不一,难以采用循环方法,最后为了节省时间采用了手动方法。感谢老师的教导,在做实验的过程中,对正则表达式和爬虫有了更熟练的运用。但仍然不够得心应手,还需要继续精进。