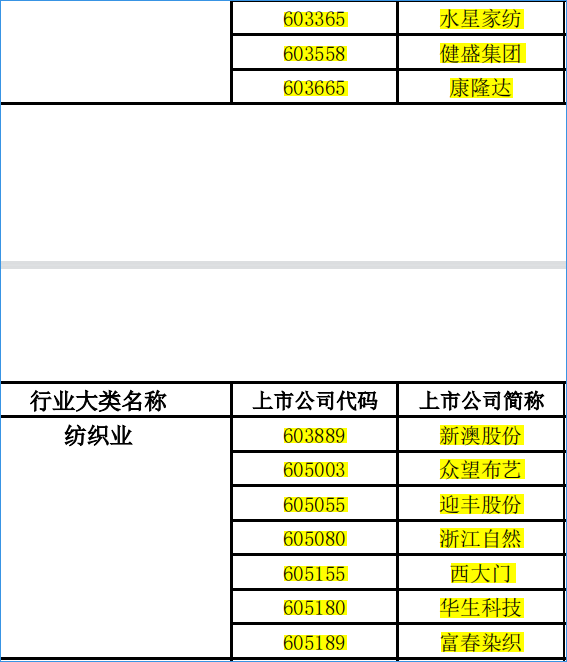
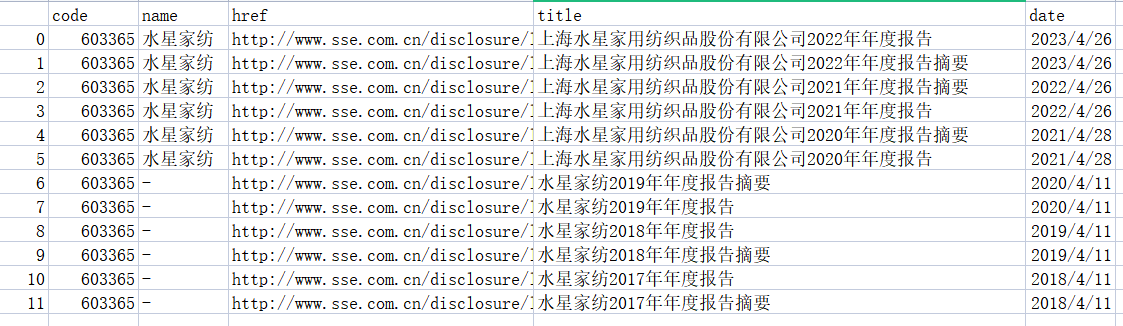
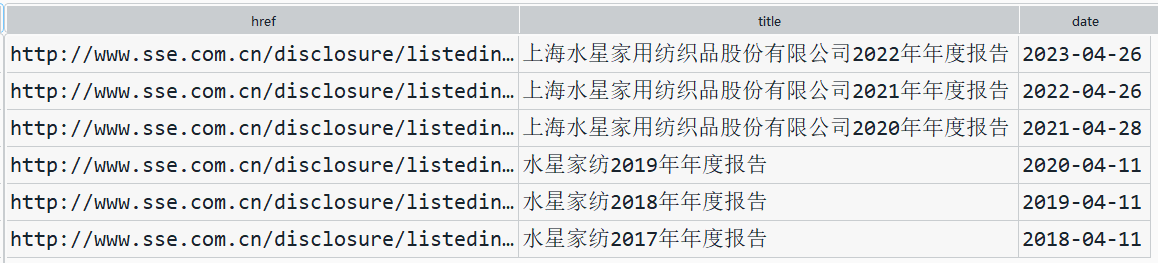
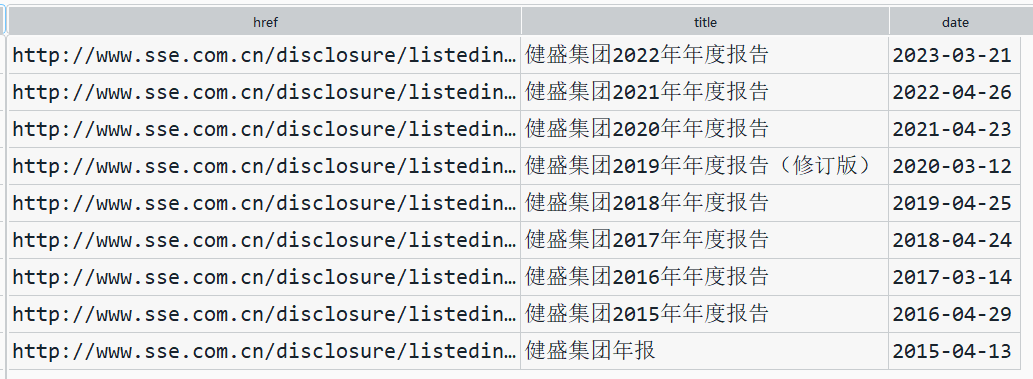
第一步通过selenium爬取了所分配到的纺织业倒数10家上市公司含有年报链接等相关信息的网页文件,然后通过定义函数获取我们所需要的信息,包括代码、公司名字、年报链接、年报名称、发布日期,并信息存为csv文件。通过查看10家上市公司csv文件的title列我们发现,除了我们需要的年报下载链接以外,还包括年报摘要等不相关文件。
注意:
(1)启动浏览器驱动时,要根据浏览器不同进行修改。
(2)在相关地方需设置等待网页加载时间,否则可能无法获取数据






import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
def get_table_sse(code):
browser = webdriver.Edge() #启动浏览器驱动,注意此行要根据浏览器不同进行修改
browser.set_window_size(1550,830) #实现全屏
url='http://www.sse.com.cn/disclosure/listedinfo/regular/'#上证交易所主页网址
browser.get(url) #打开上证交易所主页
time.sleep(3) #设置等待网页加载时间,否则可能无法获取数据
browser.find_element(By.ID, "inputCode").click() # ID定位到搜索框
browser.find_element(By.ID, "inputCode").send_keys(code) #输入股票代码
time.sleep(3)
selector=".sse_outerItem:nth-child(4) .filter-option-inner-inner"
browser.find_element(By.CSS_SELECTOR, selector).click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(3)
selector="body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, selector)
table_html=element.get_attribute('innerHTML')
fname=f'D:/数据处理大作业/{code}.html'
f=open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
'''执行循环,将10家公司含有年报链接的网页下载下来'''
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
get_table_sse(code)
def get_data(tr):
'''
定义一个函数提取网页内我们所需要的信息:包括代码、公司名字、年报链接、年报名称、发布日期
'''
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find(' ')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_table(table_html):
'''
定义一个函数将我们所需要的信息放进二维数据表DateFrame中
----------
table_html : 前面通过selenium所提取出来的所需信息的网页文件
-------
'''
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
'''对存有10家年报链接的网页文件进行循环,解析出我们需要的数据,包括代码、公司名字、年报链接、
年报名称、发布日期,并存为csv文件'''
for code in codes:
f = open(f'D:/数据处理大作业/{code}.html', encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
df.to_csv(f'D:/数据处理大作业/链接文件/{code}.csv')
'''以下为为筛选所需链接所定义的函数,包括筛选正确链接以及上市时间(10年)的筛选'''
def filter_links(words,df,include=True):
'''定义一个筛选保留年报链接的函数
----------
words : 保留或删除包含关键词列表
df : DataFrame
include : TYPE, optional(kepp or exclude), The default is False.
-------
'''
ls=[]
for word in words:
if include:
ls.append([word in f for f in df['title']])
else:
ls.append([word not in f for f in df['title']])
index=[]
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag=flag or ls[c][r]
else:
flag=flag and ls[c][r]
index.append(flag)
df2=df[index]
return(df2)
def romove_old_version(df):
'''
定义一个函数保留修订版并删除原版
'''
#通过观察csv文件中'title'列发现不属于年报的pdf文件中含有以下关键字
# words=['摘要','财务报表','关于','述职报告','专项报告','财务决算报告','专项审计说明']
df_nb=filter_links(['摘要','财务报表','关于','述职报告','专项报告','财务决算报告','专项审计说明'],df,include=False)
df_xd=filter_links(['修订版'],df_nb,include=True) #保留修订版
df_nb.sort_values(by='date',ascending=False,inplace=True)
href=df_nb['href'].to_list()
title=df_nb['title'].to_list()
date=df_nb['date'].to_list()
old_index=[]
for i in range(len(df_xd)):
d=df_xd['date'].iloc[i]
for j in range(len(date)):
d2=date[j]
if d2 < d:
old_index.append(j)
break
for j in old_index:
del date[j],href[j],title[j]
return(href,title,date)
from datetime import datetime
def filter_nb_10y(df):
'''
定义一个筛选出近十年来上市公司年报链接的函数
----------
start : 开始时间
end : 结束时间
df : DateFrame
-------
'''
dt_now=datetime.now()
current_year=dt_now.year
start=f'{current_year-9}-01-01'
end=f'{current_year}-12-31'
date=df['date']
v=[d >= start and d <= end for d in date]
df_new=df[v]
return(df_new)
#此代码用来测试我们定义的函数是否能将不属于年报的文件链接删除,并且保留修订版年报,并将原年报删除
# df=pd.read_csv(r'D:/数据处理大作业/链接文件/603558.csv')
# href,title,date=romove_old_version(df)
# df1=pd.DataFrame([href,title,date],index=['href','title','date']).T
'''以下是为了下载年报链接定义的函数'''
import requests
def download_pdf(href,code,year):
'''
下载单份年报,自动命名保存
----------
href : 下载链接
code : 证券代码
year : 年报年份
-------
'''
r=requests.get(href,allow_redirects=True)
fname=f'D:/数据处理大作业/pdf/{code}_{year}.pdf'
f=open(fname,'wb')
f.write(r.content)
f.close()
r.close()
def download_pdfs(hrefs,code,years):
for i in range(len(hrefs)):
href=hrefs[i]
year=years[i]
download_pdf(href,code,year)
time.sleep(30)
return()
#此函数可通过年报链接列表,代码,年份列表对10家公司所有年报进行下载,此代码并未使用
def download_pdfs_codes(list_hrefs,codes,list_years):
for i in range(len(list_hrefs)):
hrefs=list_hrefs[i]
years=list_years[i]
code=codes[i]
download_pdfs(hrefs,code,years)
return()
'''通过以下循环实现pdf的下载'''
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
df=pd.read_csv(f'D:/数据处理大作业/DateFrame/{code}.csv')
#筛选年报链接,将筛选出来的链接,年报文件名,日期放入表格并进行转置
#所分配到的10家上市公司上市时间均未达到10年,所以不需要对年报时间进行筛选,如有超过
#10年的年报,则需用前文的filter_nb_10y(df)函数进行筛选
href,title,date=romove_old_version(df)
df1=pd.DataFrame([href,title,date],index=['href','title','date']).T
#在df1中加入一列年份,便于提取years,首先将df1中的'date'列提取出前4个字符,获取年份列
#并加入df1中,但是上市公司是第二年初发布上一年的年报,所以需要对year列同时减去1年
def extractFirst6(s):
return s[:4]
df1['year']=df1['date'].apply(lambda s:extractFirst6(s)) #使用lambda函数式编程实现
df1['year']=df1['year'].astype('int') #将字符转为数值
df1['year']=df1['year'].map(lambda x: x-1)
hrefs=df1['href']
years=df1['year']
download_pdfs(hrefs,code,years)
import fitz
import pandas as pd
import re
from pprint import pprint
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')):
'''
定义一个函数找到'主要会计数据和财务指标'所在的页码
----------
doc :pdf文件
-------
'''
#默认设置为首尾页码
start_pageno=0
end_pageno=len(doc)-1
#
lb,ub=bounds
#获取左界页码
for n in range(len(doc)):
page=doc[n]
txt=page.get_text()
if lb in txt:
start_pageno=n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno=n
break
#获取小范围内字符串
txt=''
for n in range(start_pageno,end_pageno+1):
page=doc[n]
txt += page.get_text()
return(txt)
def get_th_span(txt):
'''
定义一个获取表头的函数
----------
txt : pdf文件的文本内容
-------
None.
'''
nianfen='(20\d\d|199\d)\s*?年'
s=f'{nianfen}\s*{nianfen}.*?{nianfen}'
p=re.compile(s,re.DOTALL) #re.DOTALL指.遇到换行符也是可以的
matchobj=p.search(txt)
#
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2) == 1) and (int(year2)-int(year3) == 1)
#
while (not flag):
matchobj=p.search(txt[end:])
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=(int(year1)-int(year2) == 1)
flag=flag and (int(year2)-int(year3) ==1)
return(matchobj.span())
def get_bounds(txt):
'''
定义一个函数获取表格边界
----------
txt : pdf文件的文本内容
-------
'''
th_span_1st=get_th_span(txt)
end=th_span_1st[1]
th_span_2nd=get_th_span(txt[end:])
th_span_2nd=(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'): #如果最后一个不是数字
e=e-1
return(s,e)
def get_keywords(txt):
'''
定义一个函数获取关键词
----------
txt : pdf文件的文本内容
-------
'''
p=re.compile(r'\d+\s+([\u2E80-\u9FFF]+)')
keywords=p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtxt,keywords):
'''
定义一个函数获取整张表格我们所需要的信息以及数据
'''
ss=[]
s=0
for kw in keywords:
n=subtxt.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtxt))
data=[]
p=re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2=re.compile('\s')
for n in range(len(ss)-1):
s=ss[n]
e=ss[n+1]
line=subtxt[s:e]
#获取可能换行的账户名称
matchobj=p.search(line)
account_name=p2.sub('',matchobj.group())
#获取三年数据
amnts=line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
#对于单个pdf可解析出表格数据并存放在DataFrame中(只解析前四个数据)
filename='D:/数据处理大作业/pdf/605080/605080_2022.pdf'
doc=fitz.open(filename)
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
data=parse_key_fin_data(subtxt, keywords)
data=data[:4]
df_chart=pd.DataFrame({'指标':[d[0] for d in data],
'2017年':[d[1] for d in data],
'2016年':[d[2] for d in data],
'变动':[d[3] for d in data],
'2015年':[d[4] for d in data]
})
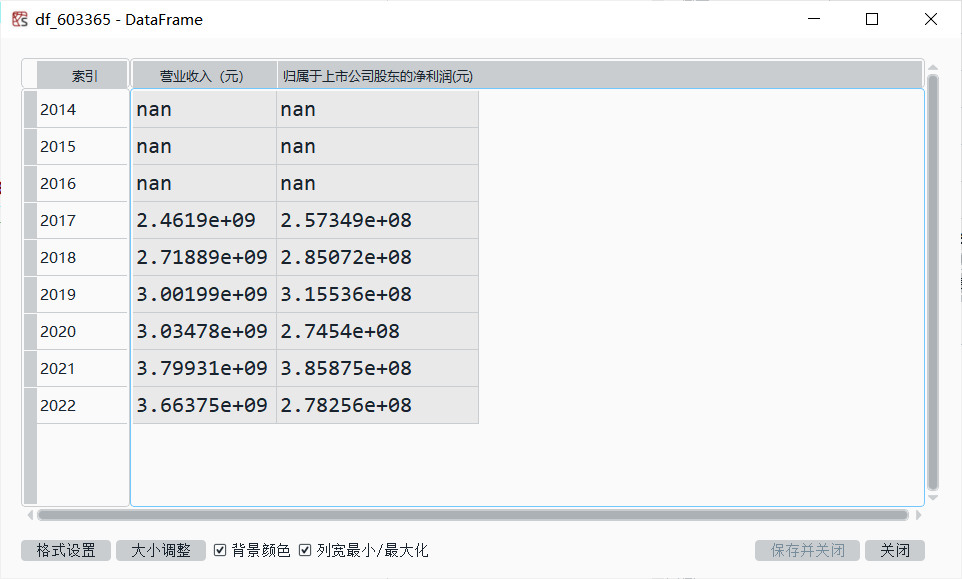
'''画图时我们只需要得到每一个上市公司年报中的营业收入和归属于上市公司股东的净利润两类数据'''
codes=[603365,603558,603665,603889,605003,605080,605155,605180,605189]
for code in codes:
import os
fname=[]
#遍历某文件夹下的所有pdf文件并获取文件名
def main():
file_path = f'D:/数据处理大作业/pdf/{code}'#文件路径(当路径里存在变量时需要在前面加上'f')
folders = os.listdir(file_path) #提取文件中的所有文件生成一个列表
for file in folders: #判断文件后缀名是否为pdf
if(file.split('.')[-1]=='pdf'):
fname.append(file) #将pdf文件名添加到提前创建的列表中用于遍历
if __name__ == '__main__':
main()
#创建一个空表格用于存放数据
locals()[f'df_{code}']=pd.DataFrame(index=range(2014,2023),
columns=['营业收入(元)','归属于上市公司股东的净利润(元)'])
for f in fname:
doc=fitz.open(f'D:/数据处理大作业/pdf/{code}/{f}')
#解析表格
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
data=parse_key_fin_data(subtxt, keywords)
#提取营业收入和归属于上市公司股东的净利润并存放到DataFrame中
revenue=float(data[0][1].replace(',','')) #转化为浮点数并去掉分隔号“,”
profit=float(data[1][1].replace(',',''))
#利用正则表达式获取正在解析年报的所属年份
text=''
for i in range(20): #读取每份年报前20页的数据
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
locals()[f'df_{code}'].loc[year,'营业收入(元)']=revenue
locals()[f'df_{code}'].loc[year,'归属于上市公司股东的净利润(元)']=profit
locals()[f'df_{code}'].to_csv(f'D:/数据处理大作业/上市公司数据/{code}.csv')
#创建一个表格存放信息
df_mes=pd.DataFrame(index=['公司简称','办公地址','公司网址','电子信箱','董秘的姓名','董秘的电话','董秘的电子信箱'],
columns=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189])
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
doc=fitz.open(f'D:/数据处理大作业/pdf/{code}/{code}_2022.pdf')
text=''
for i in range(20): #读取每份年报前20页的数据即可得到我们想要的信息
page = doc[i]
text += page.get_text()
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
site=p_site.search(text).group(1) #匹配办公地址
df_mes.loc['办公地址',{code}]=site
#p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)\s?公司网址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
web=p_web.search(text).group(1) #匹配公司网址
df_mes.loc['公司网址',{code}]=web
p_com=re.compile('(?<=公司简称:).*(?=\n)')
com=p_com.search(text).group() #匹配公司简称
df_mes.loc['公司简称',{code}]=com
p_email=re.compile('(?<=\n)电子信箱 ?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
email=p_email.search(text).group(1) #匹配董秘的电子信箱
df_mes.loc['董秘的电子信箱',{code}]=email #一般年报中匹配到的第一个电子信箱就是董秘的
p_name=re.compile('(?<=\n)董事会秘书 ?\s?\n?(证券事务代表?\s?\n?)(姓名?\s?\n?)(.*?)\s?(?=\n)',re.DOTALL)
name=p_name.search(text).group(3) #匹配董秘的姓名
df_mes.loc['董秘的姓名',{code}]=name
p_number=re.compile('(?<=\n)电话 ?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
number=p_number.search(text).group(1) #匹配董秘的电话号码
df_mes.loc['董秘的电话',{code}]=number
p_email2=re.compile('(?<=\n)\s?公司网址?\s?\n?(.*?)(电子信箱?\s?\n?)(.*?)\s?(?=\n)',re.DOTALL)
email2=p_email2.search(text).group(3) #匹配公司的电话信箱
df_mes.loc['电子信箱',{code}]=email2
df_mes.to_csv('D:/数据处理大作业/上市公司相关信息/上市公司相关信息汇总.csv')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']#仿宋字体显示中文
mpl.rcParams['axes.unicode_minus']=False #在图像中正常显示负号
#将10家公司得数据导入为DataFrame
codes=[603365,603558,603665,603889,605003,605055,605080,605155,605180,605189]
for code in codes:
locals()[f'df_{code}']=pd.read_csv(f'D:/数据处理大作业/上市公司数据/{code}.csv',
sep=',',encoding="utf-8")
locals()[f'df_{code}'].columns =['时间','营业收入','归属于上市公司股东的净利润']
locals()[f'df_{code}'].set_index('时间',inplace=True) #将时间列作为索引
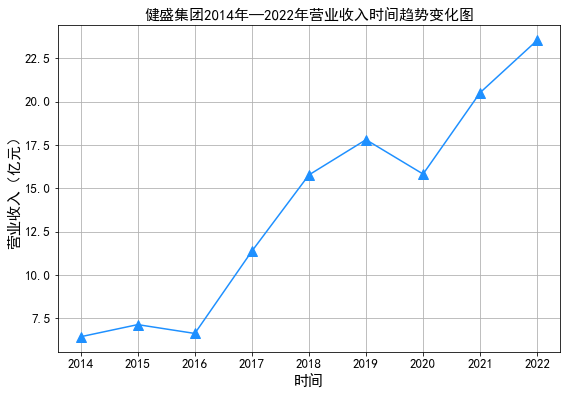
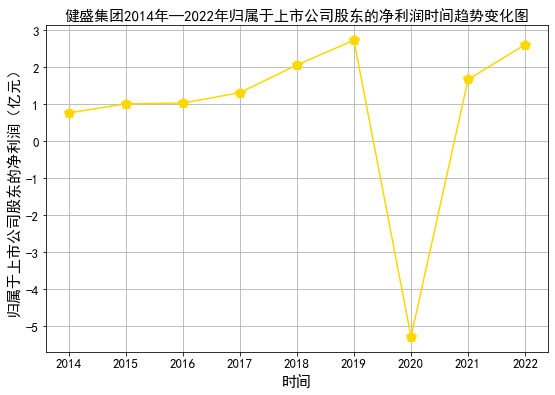
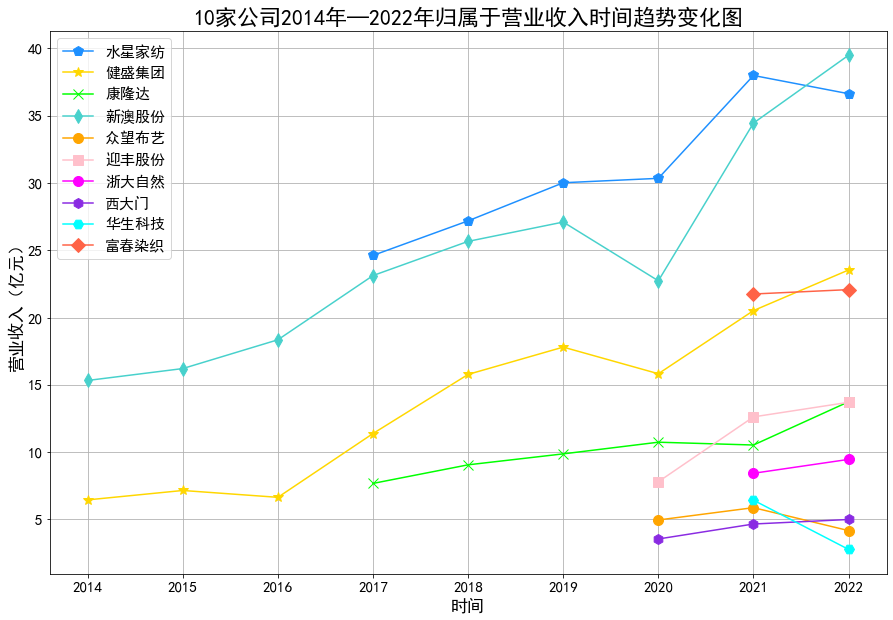
#由于所分配到得10家公司上市时间均比较短,上市时间最长的也才9年,考虑图形得客观性我们选择上市时间最长的一家公司
#选择一家公司:603558健盛集团 画出其上市9年以来营业收入和归属于上市公司股东净利润的时间序列图
plt.figure(figsize=(9,6))
plt.plot(df_603558['营业收入']/100000000, color='#1E90FF',marker='^',markersize=10) #将单位转换为亿元
plt.xlabel(u'时间',fontsize=15)
plt.ylabel(u'营业收入(亿元)',fontsize=15)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.title(u'健盛集团2014年—2022年营业收入时间趋势变化图',fontsize=15)
plt.grid()
plt.savefig("D:/数据处理大作业/结果图片/p1")
plt.show()
plt.figure(figsize=(9,6))
plt.plot(df_603558['归属于上市公司股东的净利润']/100000000, color='#FFD700',marker='p',markersize=10) #将单位转换为亿元
plt.xlabel(u'时间',fontsize=15)
plt.ylabel(u'归属于上市公司股东的净利润(亿元)',fontsize=15)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.title(u'健盛集团2014年—2022年归属于上市公司股东的净利润时间趋势变化图',fontsize=15)
plt.grid()
plt.savefig("D:/数据处理大作业/结果图片/p2")
plt.show()
plt.figure(figsize=(15,10))
plt.plot(df_603365['营业收入']/100000000, color='#1E90FF',label='水星家纺',marker='p',markersize=10)
plt.plot(df_603558['营业收入']/100000000, color='#FFD700',label='健盛集团',marker='*',markersize=10)
plt.plot(df_603665['营业收入']/100000000, color='#00FF00',label='康隆达',marker='x',markersize=10)
plt.plot(df_603889['营业收入']/100000000, color='#48D1CC',label='新澳股份',marker='d',markersize=10)
plt.plot(df_605003['营业收入']/100000000, color='#FFA500',label='众望布艺',marker='o',markersize=10)
plt.plot(df_605055['营业收入']/100000000, color='#FFC0CB',label='迎丰股份',marker='s',markersize=10)
plt.plot(df_605080['营业收入']/100000000, color='#FF00FF',label='浙大自然',marker='o',markersize=10)
plt.plot(df_605155['营业收入']/100000000, color='#8A2BE2',label='西大门',marker='h',markersize=10)
plt.plot(df_605180['营业收入']/100000000, color='#00FFFF',label='华生科技',marker='H',markersize=10)
plt.plot(df_605189['营业收入']/100000000, color='#FF6347',label='富春染织',marker='D',markersize=10)
plt.xlabel(u'时间',fontsize=17)
plt.ylabel(u'营业收入(亿元)',fontsize=17)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.title(u'10家公司2014年—2022年营业收入时间趋势变化图',fontsize=22)
plt.grid()
plt.legend(fontsize=15)
plt.savefig("D:/数据处理大作业/结果图片/p3")
plt.show()