蔡晓颉的实验报告
第一步 提取年报
from time import sleep
from urllib import parse
import os
import json
import requests
def get_address(bank_code):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_code,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] # 获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId, plate, code)
return orgId, plate, code
def download_PDF(url, file_name):
url = url
r = requests.get(url)
f = open(code + "/" + file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + code + "/" + file_name)
download_PDF(pdf_url, file_name)
sleep(2)
if __name__ == '__main__':
#code list
code_list = ['002293','002327', '002394', '002397', '002516', '003041', '300163', '300577', '300658', '300819']
for code in code_list:
os.mkdir(code)
orgId, plate, code = get_adress(code)
get_PDF(orgId, plate, code)
print("next bank")
print("Finished")
结果展示
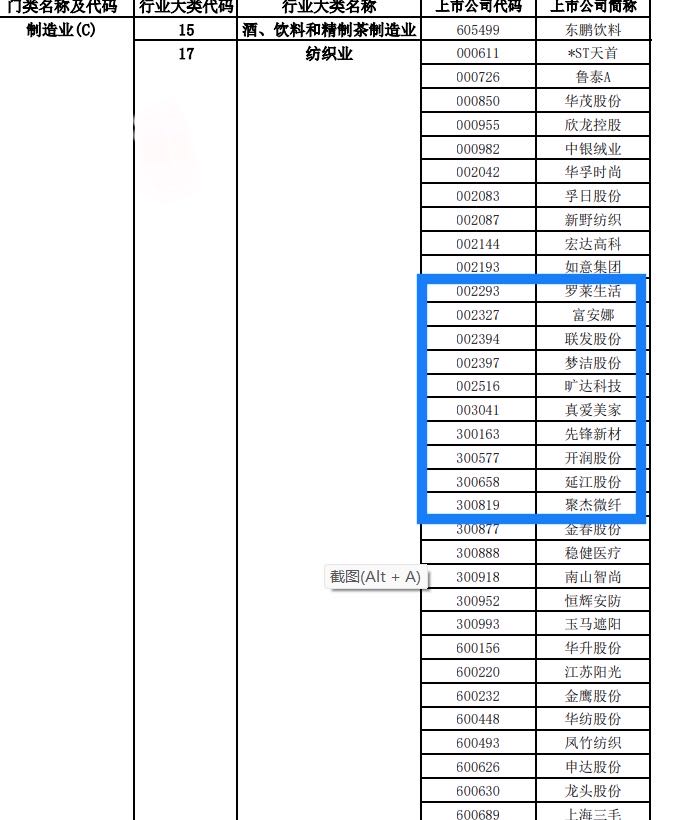
第二步 解析年报
# -*- coding: utf-8 -*-
'''解析年报'''
import fitz
import pandas as pd
import re
from pprint import pprint
filename='2013年年度报告.pdf'
doc=fitz.open(filename)
#找到'主要会计数据和财务指标'所在的页码(该条注释要改)
def get_subtxt(doc,bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首尾页码
start_pageno=0
end_pageno=len(doc)-1
#
lb,ub=bounds
#获取左界页码
for n in range(len(doc)):
page=doc[n]
txt=page.get_text()
if lb in txt:
start_pageno=n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno=n
break
#获取小范围内字符串
txt=''
for n in range(start_pageno,end_pageno+1):
page=doc[n]
txt += page.get_text()
return(txt)
#获取表头
def get_th_span(txt):
nianfen='(20\d\d|199\d)\s*?年' #2016和年之间是空格,而2016年和2015年之间是空格
s=f'{nianfen}\s*{nianfen}.*?{nianfen}'
p=re.compile(s,re.DOTALL) #re.DOTALL指.遇到换行符也是可以的
matchobj=p.search(txt)
#
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2) == 1) and (int(year2)-int(year3) == 1)
#
while (not flag):
matchobj=p.search(txt[end:])
end=matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=(int(year1)-int(year2) == 1)
flag=flag and (int(year2)-int(year3) ==1)
return(matchobj.span())
#获取表格边界
def get_bounds(txt):
th_span_1st=get_th_span(txt)
end=th_span_1st[1]
th_span_2nd=get_th_span(txt[end:])
th_span_2nd=(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'): #如果最后一个不是数字
e=e-1
return(s,e+1)
'''
#获取‘营业收入’和‘归属于上市公司股\n东的净利润’
def get_account_data(account,txt):
p_txt='%s\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)' % account #%s是占位符,用‘account’替换,\D是非数字,\d{1,3}是数字1或2或3个,*可重复,?非贪婪,()内是所要的数字,小数点后\d+表示小数点后至少一位数字
p=re.compile(p_txt)
matchobj=p.search(txt)
amt=matchobj.group(1)
return(amt)
revenue=get_account_data('营业收入', txt) #txt在后面
profit_shlder=get_account_data('\n*'.join('归属于上市公司股东的净利润'), txt)
'''
#获取整张表格
# subtxt=txt[txt.find('营业收入'):txt.find('总资产')]
def get_keywords(txt):
p=re.compile(r'\d+\s+([\u2E80-\u9FFF]+)')
keywords=p.findall(txt)
return(keywords)
def parse_key_fin_data(subtxt,keywords):
#keywords=['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss=[]
s=0
for kw in keywords:
n=subtxt.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtxt))
data=[]
p=re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2=re.compile('\s')
for n in range(len(ss)-1):
s=ss[n]
e=ss[n+1]
line=subtxt[s:e]
#获取可能换行的账户名称
matchobj=p.search(line)
account_name=p2.sub('',matchobj.group())
#获取三年数据
amnts=line[matchobj.end():].split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
txt=get_subtxt(doc)
span=get_bounds(txt)
subtxt=txt[span[0]:span[1]]
keywords=get_keywords(subtxt)
# keywords.insert(0,'营业收入')
data=parse_key_fin_data(subtxt, keywords)
print(data)
第三步 绘制图像
import pdfplumber
import os
def search_table(pdf_name , search_text):
target_page = None
with pdfplumber.open(pdf_name) as pdf:
for i, page in enumerate(pdf.pages):
text = page.extract_text()
if search_text in text:
target_page = i + 1 # 页数从 1 开始计数
break # 找到第一个匹配后停止搜索
page1 = pdf.pages[target_page-1]
tables = page1.extract_tables()
for index, table in enumerate(tables):
for a in table:
for b in remove(a):
if search_text in b:
print("文字 '{}' 第一次出现在页数: {},出现在这一页的第{}个表格".format(search_text, target_page,index))
return table
def zhuanhua(string_number):
try:
re = float(string_number.replace(",", ""))*0.00000001
except Exception as e:
return ''
return re
def remove(original_list):
# 移除空字符串
return [item for item in original_list if item is not None and item != '']
def is_numeric(value):
try:
float(value)
return True
except ValueError:
return False
def fuzzy_search(lst, keyword):
return [index for index, item in enumerate(lst) if keyword in item]
if __name__ == '__main__':
# 指定目录路径
directory = "data/年报"
# 获取目录下的文件名称列表
file_list_row = os.listdir(directory)
# 输出文件名称列表
for file_list_sub in file_list_row:
file_list = os.listdir(directory+'/'+file_list_sub)
plot_data = [[] for _ in range(len(file_list))]
for i,dir in enumerate(file_list):
all_list = []
da = search_table(directory+'/'+file_list_sub+'/'+dir,"股东的净")
for j in da:
all_list +=j
da = [item for item in all_list if item is not None and item != '']
print(dir[0:4])
plot_data[i].append(str(dir[0:4])+'年')
if is_numeric(zhuanhua(da[fuzzy_search(da, '营业收入')[0] + 1].replace('\n', ''))):
print(zhuanhua(da[fuzzy_search(da, '营业收入')[0] + 1].replace('\n', '')))
plot_data[i].append(zhuanhua(da[fuzzy_search(da, '营业收入')[0] + 1].replace('\n', '')))
else:
print(zhuanhua(da[fuzzy_search(da, '营业收入')[0] + 2].replace('\n', '')))
plot_data[i].append(zhuanhua(da[fuzzy_search(da, '营业收入')[0] + 2].replace('\n', '')))
if is_numeric(zhuanhua(da[fuzzy_search(da, '归属')[0] + 1].replace('\n', ''))):
print(zhuanhua(da[fuzzy_search(da, '归属')[0] + 1].replace('\n', '')))
plot_data[i].append(zhuanhua(da[fuzzy_search(da, '归属')[0] + 1].replace('\n', '')))
else:
print(zhuanhua(da[fuzzy_search(da, '归属')[0] + 2].replace('\n', '')))
plot_data[i].append(zhuanhua(da[fuzzy_search(da, '归属')[0] + 2].replace('\n', '')))
print(plot_data)
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
font = FontProperties(family='SimHei', size=12) # 替换为你系统中已安装的中文字体名称
data = plot_data
years = [item[0][0:-1] for item in data]
value1 = [round(item[1],3) for item in data]
value2 = [round(item[2],3) for item in data]
plt.plot(years, value1, label='营业收入(万元)')
plt.plot(years, value2, label='净利润(万元)')
plt.xlabel('年份',fontproperties=font)
plt.ylabel('万元',fontproperties=font)
#plt.title('Plot of Values over Time',fontproperties=font)
plt.legend(prop=font)
plt.show()
import pdfplumber
def remove(original_list):
# 移除空字符串
return [item for item in original_list if item is not None and item != '']
def search_table(pdf_name , search_text):
target_page = None
with pdfplumber.open(pdf_name) as pdf:
for i, page in enumerate(pdf.pages):
text = page.extract_text()
if search_text in text:
target_page = i + 1 # 页数从 1 开始计数
break # 找到第一个匹配后停止搜索
page1 = pdf.pages[target_page-1]
tables = page1.extract_tables()
for index, table in enumerate(tables):
for a in table:
for b in remove(a):
if search_text in b :
print("文字 '{}' 第一次出现在页数: {},出现在这一页的第{}个表格".format(search_text, target_page,index))
return table
# 读取pdf文件,保存为pdf实例
table1 = search_table('data/'+"2016年年度报告.pdf",'股票简称')
# 将公司资料里的公司网址
# 办公地址电子信箱董秘的姓名电话号码
# 电子信箱信息找出来保存为CSV文件
# 最后要以文档的形式呈现结果
print(table1[-2][1])#网址
print(table1[8][1])#办公地址
print(table1[11][1])#电子信箱
table2 = search_table('data/'+"2014年年度报告.pdf",'董事会秘书')
print(table2[1][1]) #姓名
print(table2[3][1]) #电话
print(table2[5][1]) #信箱
结果展示
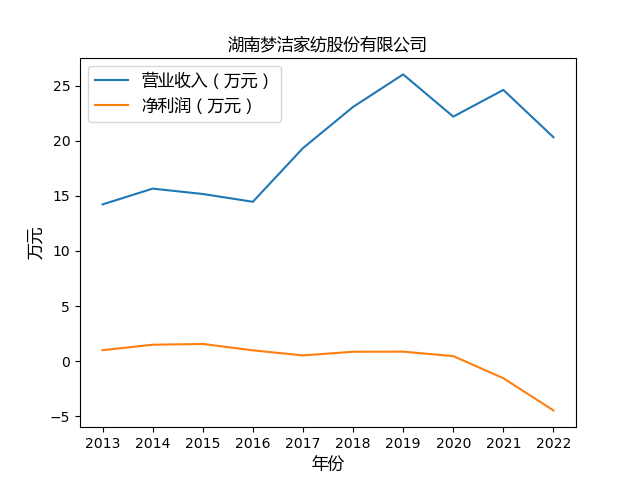
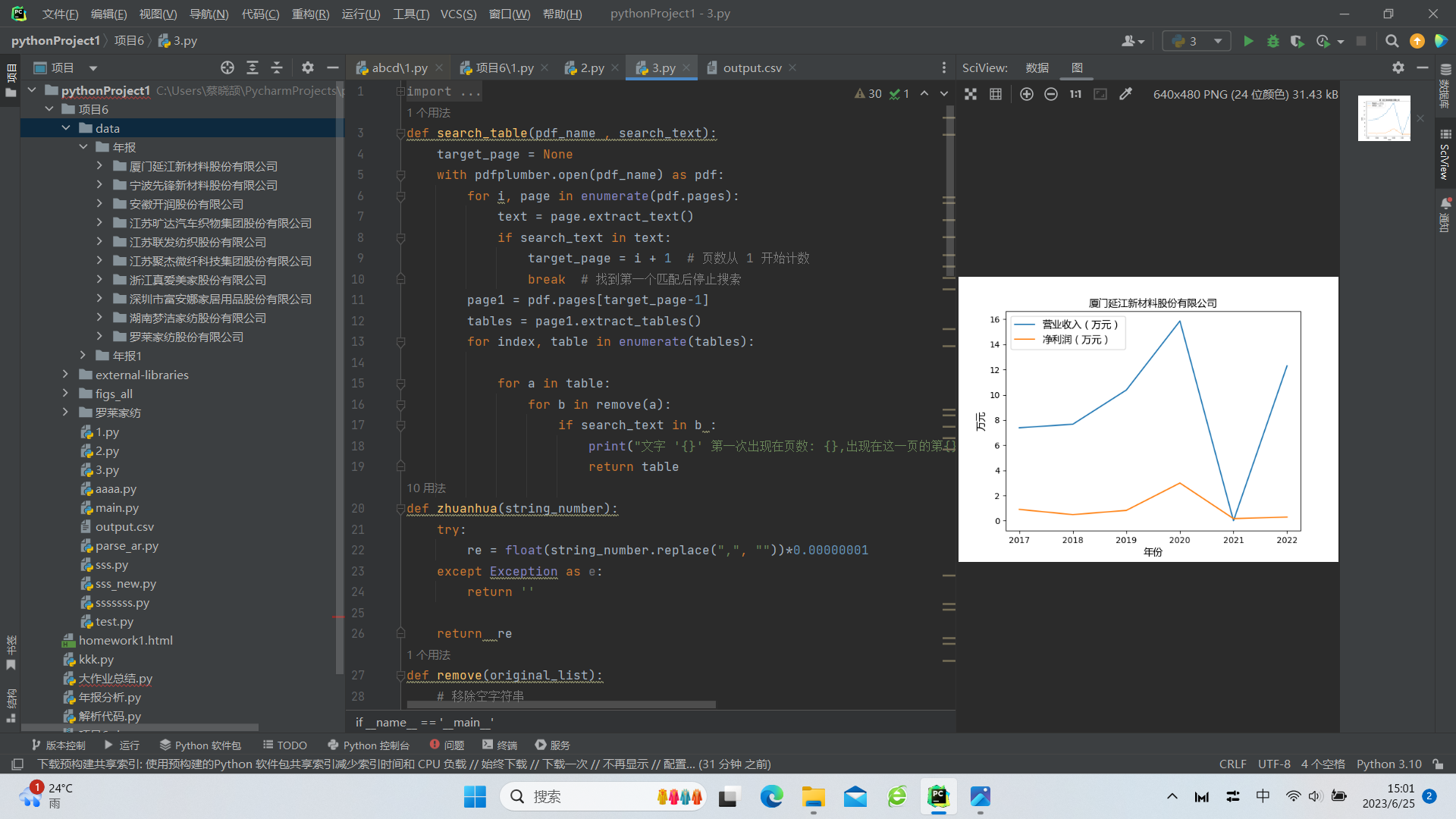
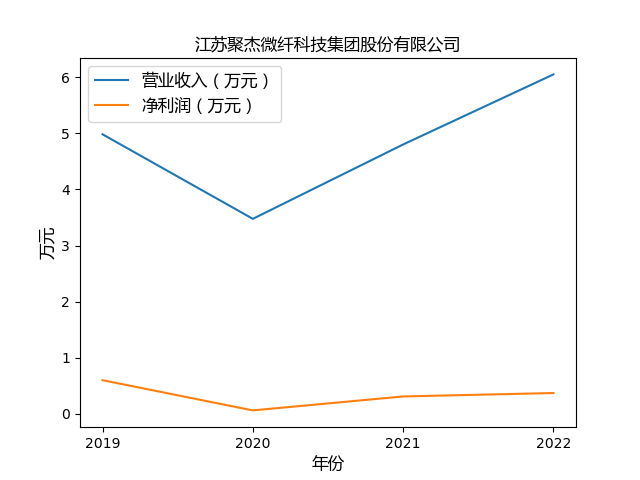
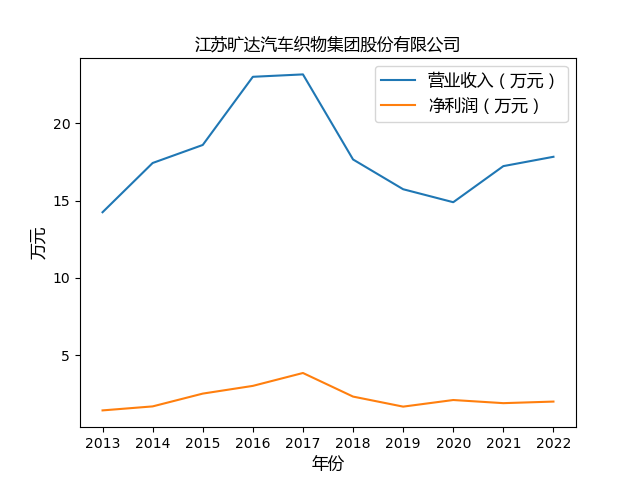
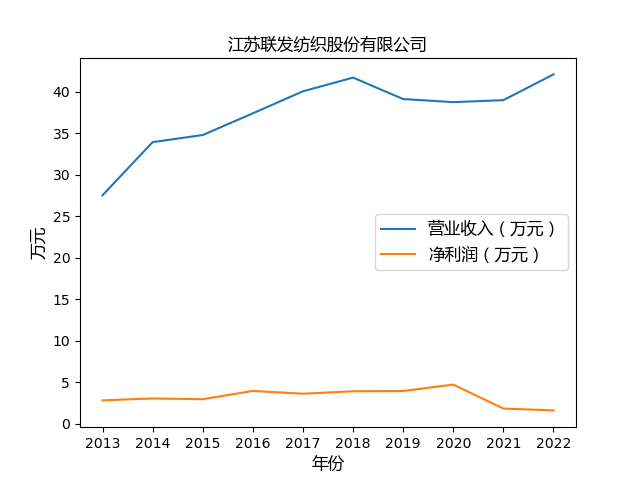
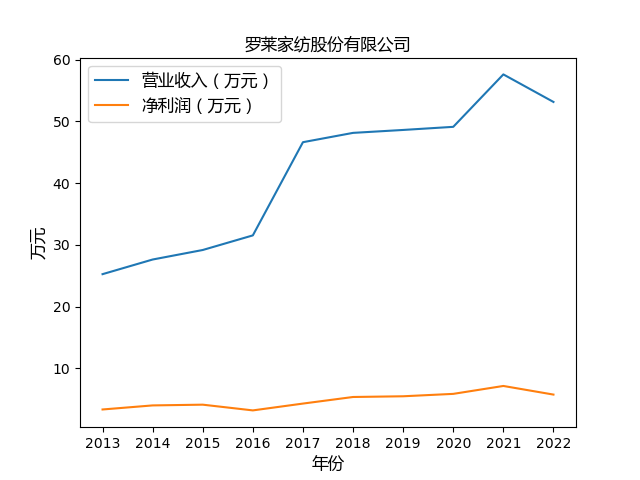
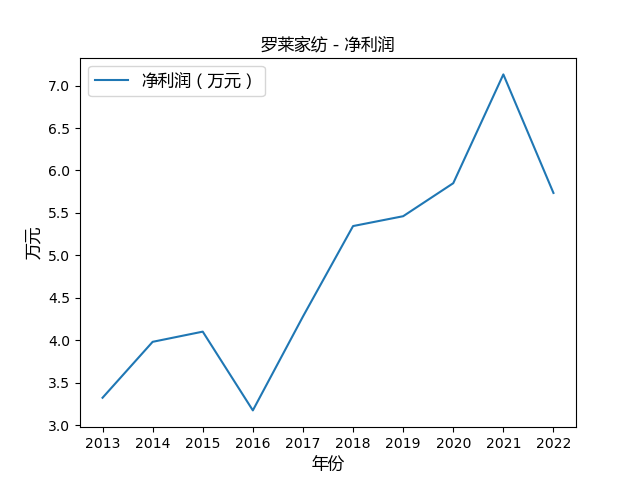
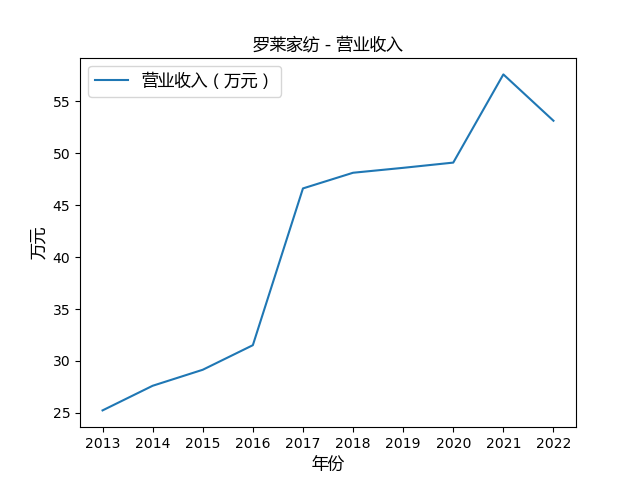
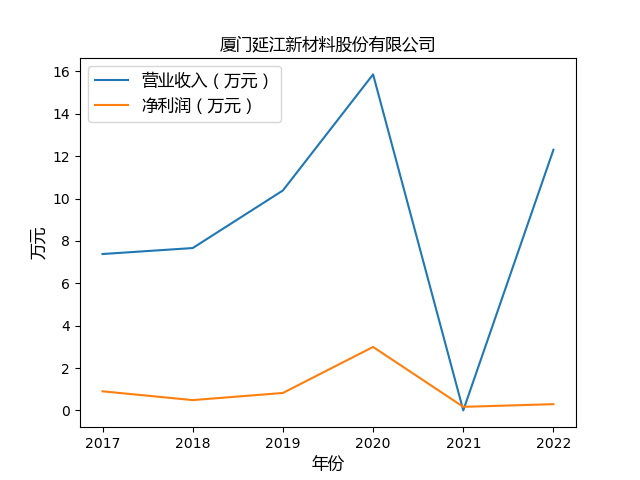
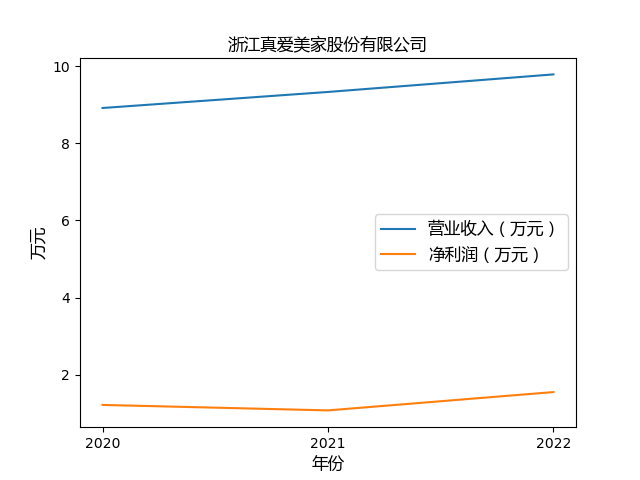
心得
通过这次动手制作,我发现python课程相当不易,要用心学习才能学的好,感谢老师一学期的教授,让我学习了很多python,希望在以后的生活中学习更多的有关python的技能,探索更多相关知识。