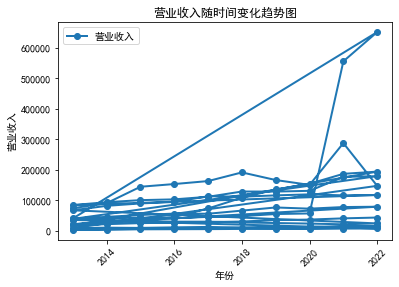
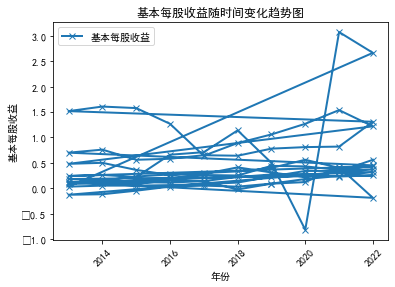
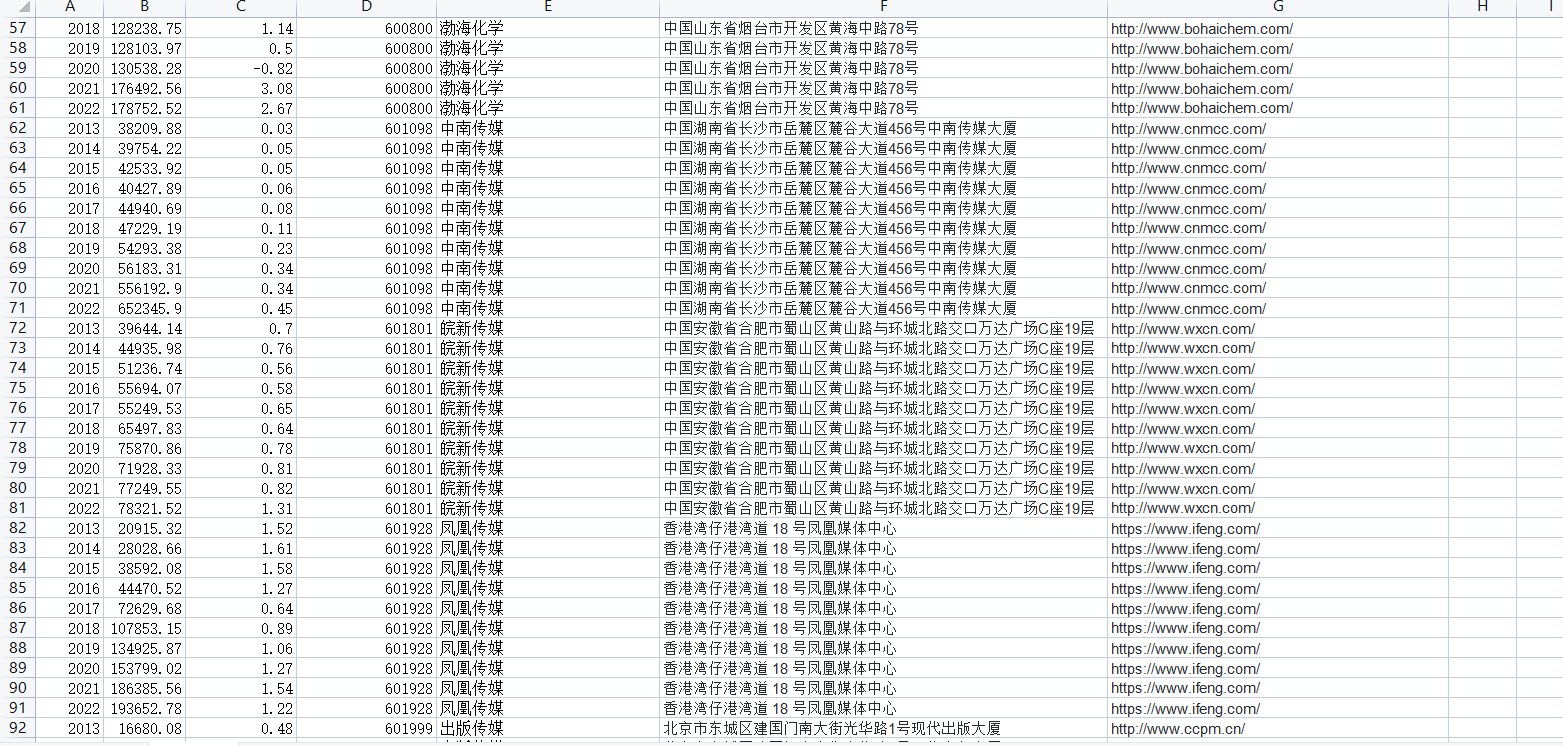
从这十家公司的营业收入以及基本每股收益分析得知近十年,随着信息技术的迅速发展,传媒行业得以快速发展,基本向上发展趋势。分析如下:
市场规模持续扩大:随着社会经济的快速发展,媒体在大众生活中的影响越来越大,人们对于信息获取需求不断增加。根据统计,近十年传媒行业的市场规模持续扩大,产品线也不断拓展,包括数字内容、新媒体、影视、游戏等领域。新媒体的崛起:新兴媒体如移动互联网、社交网络与大数据等技术的快速普及和应用,催生了微信、微博、短视频等平台的诞生,使得新兴媒体成为传媒行业的一个重要分支。新媒体平台因其内容的更加生动、立体和交互性更强,更加符合当下年轻人的口味和消费习惯。播出权及衍生品开发的盈利模式:随着影视、音乐、综艺等类别的行业竞争的激烈化,自制内容成为内容创造者的主要方向。自制内容的形式多样,包括电视电影、网络大电影、短视频、综艺、儿童节目等。在内容产业高收益的情况下,更多公司趋于将重心由传统广告转向强调播出权和衍生品的开发领域,以此获取更大的利润空间。
广告营销从传统广告向智能化广告转移:随着移动互联网的快速崛起和市场细分化程度的不断加深,智慧营销模式逐渐替代了传统的广告形式,互联网广告已成为传媒行业的新趋势。智能化广告更加注重精准投放,为求职人群提供了更舒适、有针对性和满意度更高的广告阅读体验。信息融合是行业发展的未来趋势:信息融合是当前传媒行业发展的一大趋势,视频、音频、图像等多种信息形式在一起交融,信息更加高效、深度的传递给用户。多媒体化的传播形式可以给受众带来更加丰富的视听感受,也增加了广告投放及在线交流、咨询的灵活性。
总体来说,传媒行业随着市场需求和科技进步不断向前发展,其中市场规模和新兴媒体领域的快速崛起,广告营销从传统广告向智能化广告的转移,以及信息融合是行业发展的未来趋势等,是近年来传媒行业发展的几个重要方向。
.png)
.png)
.png)

import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
import pdfplumber
import os
import pandas as pd
import pdfplumber
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
company_list = ["000607","000719","600373","600551","600757","600800","601098", "601801", "601928","601999"]
for company in company_list:
os.mkdir(company)
orgId, plate,code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")

import csv
import re
from pdfminer.high_level import extract_text
# 从PDF文件中提取文本
with open('test.pdf', 'rb') as file:
text = extract_text(file)
# 提取信息
year = re.search('(\d{4})年年报', text).group(1)
revenue = re.search('营业收入[\s\S]*?([\d,\.]+)元', text).group(1)
earning_per_share = re.search('基本每股收益[\s\S]*?([-\d\.]+)元?', text).group(1)
stock_code = re.search('股票代码:([0-9]+)', text).group(1)
stock_name = re.search('\n([\u4e00-\u9fa5]+)股份有限公司', text).group(1)
office_address = re.search('公司地址:([\S\s]+?)\n', text).group(1).strip()
company_website = re.search('公司网址:([\S\s]+?)\n', text).group(1).strip()
# 将信息写入CSV文件
with open('company_info.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['年份', '营业收入', '基本每股收益', '股票代码', '股票简称', '公司办公地址', '公司网址'])
writer.writerow([year, revenue, earning_per_share, stock_code, stock_name, office_address, company_website])

#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_excel('D:\BaiduNetdiskDownload\金融数据.xlsx', usecols=['年份', '营业收入', '基本每股收益'],sheet_name='Sheet2')
plt.figure()
plt.plot(df['年份'], df['营业收入'], 'o-', label='营业收入', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.title('华媒控股营业收入随时间变化趋势图')
plt.legend()
plt.show()
plt.figure()
plt.plot(df['年份'], df['基本每股收益'], 'x-', label='基本每股收益', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益')
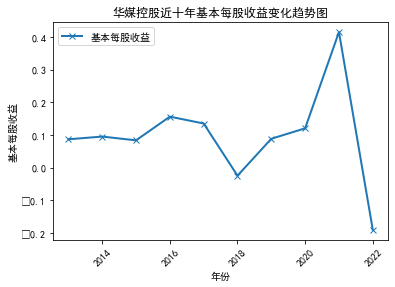
plt.title('华媒控股基本每股收益随时间变化趋势图')
plt.legend()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_excel('C:/Users/xiaolu/Documents/Tencent Files/2927627761/FileRecv/nianbao.xls', usecols=['年份', '股票简称', '股票代码', '营业收入', '基本每股收益'])
grouped = df.groupby(['年份'])
for name, group in grouped:
plt.figure(figsize=(12, 6))
plt.suptitle(f"{name}年营业收入和基本每股收益柱状图")
plt.subplot(211)
plt.bar(group['股票简称'], group['营业收入'], width=0.3, label='营业收入')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('营业收入')
plt.legend()
plt.subplot(212)
plt.bar(group['股票简称'], group['基本每股收益'], width=0.3, label='基本每股收益')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('基本每股收益')
plt.legend()
plt.show()
经过一学期的学习,我终于初窥门径,掌握了以前令我感到神奇的爬虫技术,也惊叹于处理数据的便捷以及各种语法的精妙。这个作业的难度要求还是挺高的,多亏了老师和同学们的帮助,解决了一个又一个难题,但由于自己能力有限,图表可能不太美观,以后还是要继续努力。最后要感谢吴老师,吴老师耐心教导是最打动我的地方,我以前是个急性子,尤其是碰到代码出错更是急不可耐,但是每当看到老师在耐心帮助同学解决各种各样的花样问题,我知道一定不要急躁要慢下来,不懂就问,耐心是学习这么课的最重要的精神,感谢吴老师在技术和精神上给我以启迪。以后将继续学习这方面的知识,不断挑战自己,达到可以充分利用这么技术为大家和自己造就便利、节约时间等目的。