import time
import re
import pandas as pd
import requests
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
#定义登入指定网页的函数
def SZSE(id, start_time, end_time):
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.set_window_size(1280, 720)
driver.execute_script("window.scrollTo(0,81.77550506591797)")
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(id)
#防止操作过快网页尚未加载,等待2秒
time.sleep(2)
driver.find_element(By.CSS_SELECTOR, "strong").click()
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").send_keys(start_time)
driver.find_element(By.CSS_SELECTOR, ".input-right").click()
driver.find_element(By.CSS_SELECTOR, ".input-right").send_keys(end_time)
driver.find_element(By.ID, "query-btn").click()
time.sleep(2)
#定义html的保存和读取函数
def Saveashtml(filename,content):
with open(filename+'.html','w',encoding='utf-8') as f:
f.write(content)
def Readhtml(filename):
with open(filename+'.html', encoding='utf-8') as f:
html = f.read()
return html
#定义关键字摘除函数
def clean(df):
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|英文|取消|更新前", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
#定义下载函数
def Load(df):
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
#封装解析网页的函数, 参照课堂示例
class LOADHTML():
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告题目': [td[2] for td in tds],
'时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告题目']]
times = [get_time(td) for td in df['时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告题目': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'时间': times
})
self.df_data = df
return(df)
利用所定义的函数,下载年报
driver = webdriver.Chrome()
firms=['000150','000509','000516','002044','002173','002219','002524','300015','300143','300224']
for i in range(0,10):
id=firms[i]
#登入深交所网页
SZSE(str(id), '2013-01-01','2023-01-01')
time.sleep(2)
#提取网页指定段落源码
html = driver.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
#将源码保存为html
Saveashtml(str(id), innerHTML)
#读取html并解析出需要的年报
html = Readhtml(str(id))
p_df = LOADHTML(html)
df = p_df.get_data()
nianbao = clean(df)
#为年报创建新文件夹(路径)
os.mkdir(str(id))
os.chdir(str(id))
Load(nianbao)
#防止下载时进入递归,需要回到上一路径
os.chdir(os.path.abspath('..'))
i=i+1
下载后的文件夹截图及内含年报截图


import os
import fitz
import pandas as pd
import re
#建立空列表储存数据
data1=[]
data2=[]
data3=[]
data4=[]
data5=[]
data6=[]
#写出底层工作路径
sub_path = 'D:\学习\作业\公司年报'
firms=['000150','000509','000516','002044','002173','002219','002524','300015','300143','300224']
#通过oswalk遍历年报
for i in firms:
work_path = os.path.join(sub_path, i)
os.chdir(work_path)
for root, dirs, files in os.walk(work_path):
for filename in files:
doc = fitz.open(filename)
start_pageno = 0
end_pageno = len(doc)-1
lb = '联系人'
ub = '信息披露'
#lb:下界 ub:上界
#获取左界页码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno, len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno, end_pageno+1):
page=doc[n]
txt += page.get_text()
#基本信息只取最新一年,写在循环外层
#split法提取关键信息
s = txt.find('公司的中文名称')
e = txt.find('外文')
subtxt1=txt[s:e]
lst1=subtxt1.split()
name=lst1[1]
data1.append(name)
#办公地址中含有空格,只能用正则表达式匹配
find_location = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
location=find_location.search(txt).group(1)
data2.append(location)
#办部分公司没有网址,采用正则表达式匹配
find_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
web=find_web.search(txt).group(1)
data3.append(web)
s = txt.find('姓名')
e = txt.find('联系地址')
subtxt4=txt[s:e]
lst4=subtxt4.split()
sec=lst4[1]
data4.append(sec)
s = txt.find('电话')
e = txt.find('传真')
subtxt5=txt[s:e]
lst5=subtxt5.split()
tel=lst5[1]
data5.append(tel)
s = txt.find('电子信箱')
e = txt.find('信息披露')
subtxt6=txt[s:e]
lst6=subtxt6.split()
email=lst6[1]
data6.append(email)
#把数据写成csv文件
title=['公司名称', '办公地址', '公司网址','董事会秘书','电话','电子信箱']
data = [data1,data2,data3,data4,data5,data6]
df = pd.DataFrame(data)
df_T = pd.DataFrame(df.values.T,columns=title)
os.chdir(sub_path)
df_T.to_csv('股票所属公司基本信息.csv')
#把数据写成excel文件
import openpyxl
workbook = openpyxl.Workbook()
sheet0 = workbook.create_sheet(index=0)
# 循环写入数据
for i in range(len(data)):
for j in range(len(data[i])):
sheet0.cell(j+2,i+1).value = data[i][j]
for t in range(len(title)):
sheet0.cell(1,t+1).value = title[t]
workbook.save('股票所属公司基本信息.xlsx')
运行结果,以excel文件为例,空白处表示该公司无该信息 (文件夹截图内显示的是csv文件与excel文件)


import os
import fitz
import pandas as pd
def get_subtxt(doc):
#默认设置为首尾页码
start_pageno = 0
end_pageno = len(doc)-1
#
lb = '主要会计数据和财务指标'
ub = '总资产'
#lb:下界 ub:上界
#获取左界页码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno, len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno, end_pageno+1):
page=doc[n]
txt += page.get_text()
return(txt)
#定义函数遍历股票名字
def get_indexname(lb,ub):
sub_path = 'D:\学习\作业\公司年报'
firms=['000150','000509','000516','002044','002173','002219','002524','300015','300143','300224']
for i in firms:
work_path = os.path.join(sub_path, i)
os.chdir(work_path)
for root, dirs, files in os.walk(work_path):
for filename in files:
doc = fitz.open(filename)
start_pageno = 0
end_pageno = len(doc)-1
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno, len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno, end_pageno+1):
page=doc[n]
txt += page.get_text()
s = txt.find('股票简称')
e = txt.find('外文')
subtxt1=txt[s:e]
lst=subtxt1.split()
iname=str(lst[1])
#对ST股票名称拼接还原
a='*ST'
if iname == a:
iname=str(lst[1])+str(lst[2])
indexname.append(iname)
return(indexname)
#新建列表储存数据
data1=[]
data2=[]
data3=[]
data4=[]
data5=[]
data6=[]
data7=[]
data8=[]
data9=[]
data10=[]
dt=[data1,data2,data3,data4,data5,data6,data7,data8,data9,data10]
j=0
#定义底层工作路径
sub_path = 'D:\学习\作业\公司年报'
firms=['000150','000509','000516','002044','002173','002219','002524','300015','300143','300224']
#oswalk遍历年报
for i in firms:
work_path = os.path.join(sub_path, i)
os.chdir(work_path)
for root, dirs, files in os.walk(work_path):
for filename in files:
doc = fitz.open(filename)
txt = get_subtxt(doc)
s = txt.find('营业收入')
e = txt.find('境内外')
subtext = txt[s:e]
lst=subtext.split()
#数据异常处理,如异常,显示特定数字
if lst == []:
lst = [1,100]
yysr = lst[1]
if len(str(yysr)) > 20:
yysr = 100
yysr=float(str(yysr).replace(',',''))
#每10个数据一组写入列表
if len(dt[j]) < 10:
dt[j].append(yysr)
if len(dt[j]) >= 10:
j=j+1
if j > 9:
break
#对异常数据手动补充
data8[0]=1640130450.79
data9[0]=247828230.65
data10[0]=812428913.26
#得到股票名字
indexname = []
lb='联系人'
ub='信息披露'
get_indexname(lb,ub)
#写出年份列表
colnames = ['2012年','2013年','2014年','2015年','2016年','2017年','2018年','2019年','2020年','2021年']
#把数据写成csv文件
df=pd.DataFrame(dt,columns = colnames, index=indexname)
df_T = pd.DataFrame(df.values.T,columns=indexname,index=colnames)
os.chdir(sub_path)
#转置csv
df_T.to_csv('各股十年财报营业收入.csv')
#把数据写成excel文件
import openpyxl
workbook = openpyxl.Workbook()
sheet0 = workbook.create_sheet(index=0)
for i in range(len(dt)):
for j in range(len(dt[i])):
sheet0.cell(j+2,i+2).value = dt[i][j]
for t in range(len(indexname)):
sheet0.cell(1,t+2).value = indexname[t]
for f in range(len(colnames)):
sheet0.cell(f+2,1).value = colnames[f]
workbook.save('各股十年财报营业收入.xlsx')
运行结果

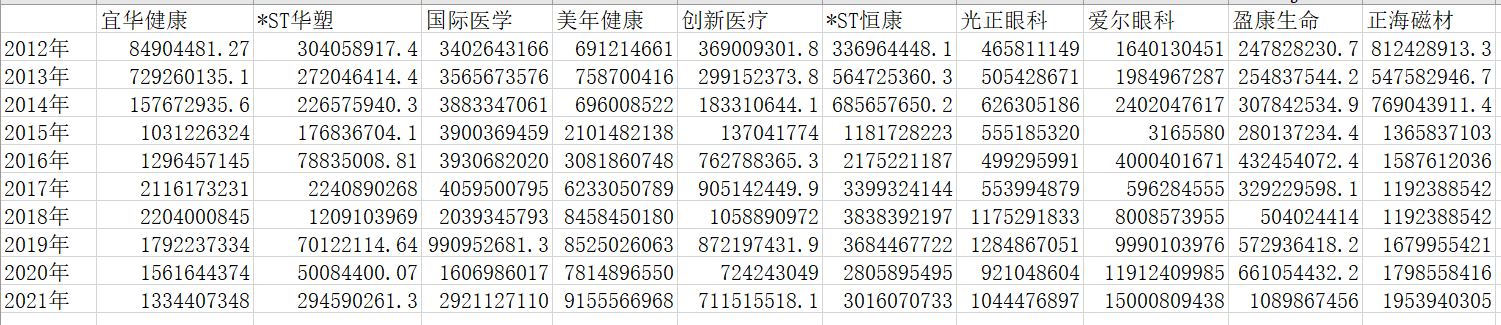
#接上,画图
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['FangSong']
mpl.rcParams['axes.unicode_minus']=False
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
Index=pd.read_excel('各股十年财报营业收入.xlsx',sheet_name='Sheet1',header=0,index_col=0)
Index.plot(figsize=(15,7),grid=True,fontsize=20)
plt.title('卫生行业十年营业收入总体趋势图',fontsize=20)
plt.ylabel(u'金额',fontsize=18)
plt.xlabel(u'年份',fontsize=18)
plt.savefig('卫生行业十年财报营业收入趋势图.jpg', dpi = 100, bbox_inches = 'tight')
Index.plot(kind='bar',figsize=(15,7),grid=True,fontsize=20)
plt.title('卫生行业每年营业收入横向对比图',fontsize=20)
plt.savefig('卫生行业每年营业收入横向对比图.jpg', dpi = 100, bbox_inches = 'tight')
卫生行业营业收入总体趋势图和各股票横向对比图
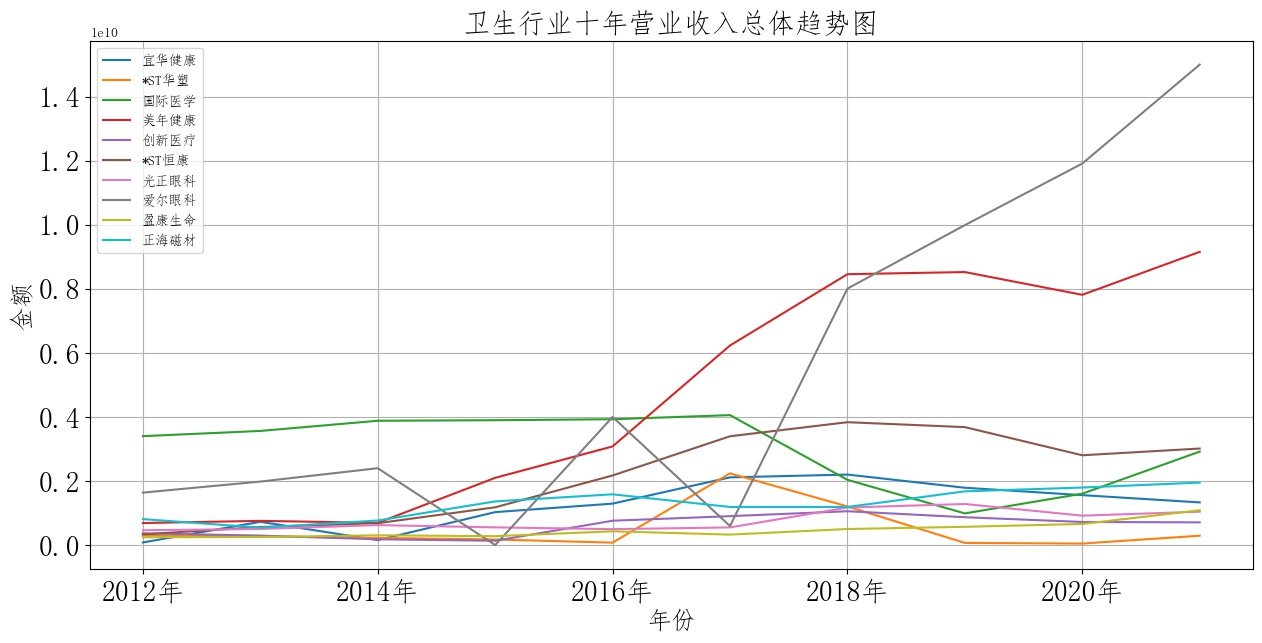
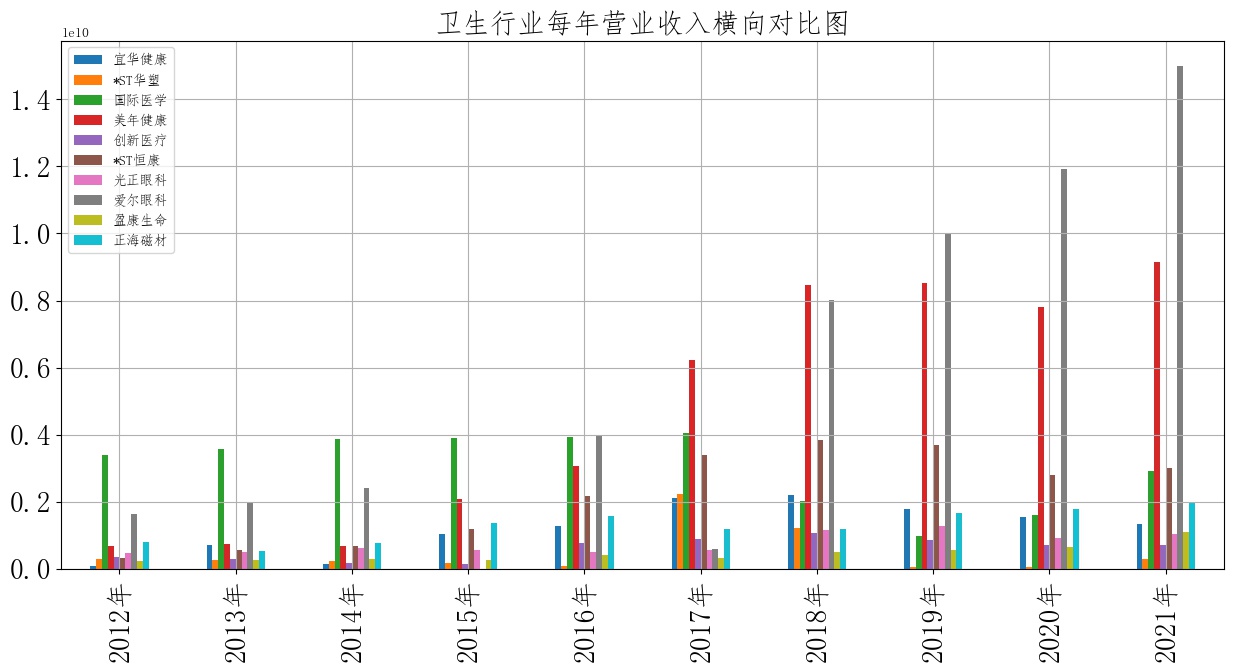
从图中可以看出深交所上市的十家卫生行业企业整体水平并无太大波动。营业收入整体趋于平缓走势。作为国民民生行业,走势平稳、增长缓慢代表民生服务供需基本平衡,反映出我国卫生行业建设稳定向好。以年份来说,2019年十家卫生企业营业收入均产生小幅度上升,这与2019年传染疾病的爆发关系紧密。此外,图中可以看见两家较为特殊的公司。一家为美年健康,一家为爱尔眼科。 通过查阅两家企业近年年报主营业务变更情况,可以发现美年健康企业的主要业务分布在卫生检查领域,而新冠感冒(更名前为“新冠疫情”)流行以来,我国国民卫生自检意识显著增强,自检需求大幅提高,该企业营业收入的大幅上升并不意外; 爱尔眼科与其说受到环境影响,对比主营业务一同集中与眼睛健康领域的光正眼科收入,我们可以看出其营业收入的增加更多来源于公司自身策略得当、而非乘领域东风发展。
可以看出,自2017年起到2021年,卫生行业内美年健康与爱尔眼科已成两大龙头,营业收入在横向对比中远超其他企业水平。 恒康医疗则自16年后保持着较为稳定的态势,代表了行业中的中等收入水平。 较为可惜的是国际医学,该企业在2012~2017年均保持着行业内较高的收入水平,而17年后营业收入却急剧下降,行业收入优势地位被美年健康、爱尔眼科等企业所占据。 查阅国际医学17年至18年年报材料,可以发现18年该企业将100%的股权出售转让,并将主营业务从医疗器械零售更新为高新技术医疗服务。此后该企业一直处于业务转型的阵痛阶段,收入保持较低水平。 值得注意的是,该企业转型的方向为“互联网+医疗服务”,虽然在19年至20年流行病影响下发展缓慢,但仍不失为卫生行业未来的重要发展方向。参照2021年国际医学行业内收入对比,可以看出起转型效果初显,收入重回当年水准,未来可期。
在本次实验过程中,最令人印象深刻的是正则表达式知识的应用。在理论讲解的过程中,我对正则表达式的应用范围尚不了解。直到参与实验后才发现正则表达式不论是在爬取网页的过程,还是在分析文本的过程,都扮演着举足轻重的角色。只有熟练掌握正则表达式,才能让自己对数据的处理能力更上一层楼。可惜的是本人对正则表达式知识点的掌握仍旧有明显不足,在实际操作时应用起来十分困难,最后只能小范围使用。 希望通过这次数据处理的经验可以加深我对正则表达式的理解,以期在未来的学习工作中能够熟练使用。