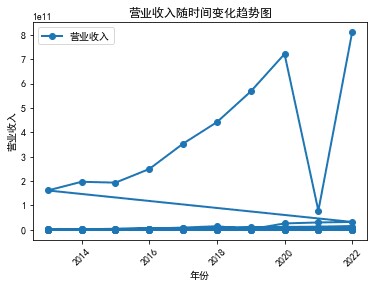
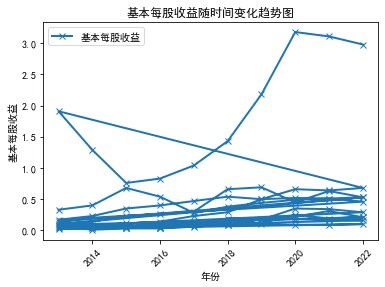
从十家公司近十来的年报分析互联网和相关服务行业近十年的发展,十家公司近十年营业收入来看,总体处于一个向上发展趋势,营业收入在逐年增加,基本每股收益也总体在逐年增加。从而知道整个行业的发展趋势:
行业规模不断扩大:近十年来,该行业的规模不断扩大,成为中国经济的一个重要组成部分。2012年到2020年,中国互联网市场交易规模从2.45万亿元增长到15.91万亿元,增幅近7倍。
移动互联网的兴起:随着智能手机、移动互联网的兴起,移动端用户规模快速扩大。近年来,移动互联网已经成为该行业的重要增长驱动力。不断涌现新技术和新模式:电子商务、在线教育、在线游戏、在线旅游等新兴业务模式快速崛起,为该行业带来了新的增长点。短视频、直播、虚拟现实等新兴技术应用也在逐渐改变我们的生活方式。 产业结构不断升级:随着科技进步,互联网产业的供应链结构也在不断升级过程中。行业证券化、产业链分立、企业向多元化方向转型等成为行业趋势。行业标准体系逐步完善:近十年来,随着国家政策和行业协会的推动,行业标准、自律规范、评测和认证等合规机制逐渐完善,行业监管趋严。
总之,近十年来,互联网和相关服务行业在中国发展势头喜人。在政策、技术、消费等多方面的推动下,该行业的规模、创新、盈利能力等指标都获得了长足的发展。但同时,随着行业竞争加剧、监管趋严等因素的不断增多,该行业的企业未来需要进行创新、调整和优化,以确保长期发展和持续增长。

import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
import pdfplumber
import os
import pandas as pd
import pdfplumber
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
company_list = ["000503","002095","002168","002247","002315","002354","002425","002467","002530","002558"]
for company in company_list:
os.mkdir(company)
orgId, plate,code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")


def getfns(path,suffix):
res=[os.path.join(path,fname) for fname in os.listdir(path) if fname.endswith(suffix)]
return res
paths = ['] # 文件夹路径列表
suffix = '.pdf'
def f1(lst): # get c1
c1 = [e[0] for e in lst]
return c1
def f2(lst): # get c1 and c2
c12 = [e[:2] for e in lst]
c6 = d[5]
return c12
for path in paths:
company_code = os.path.basename(path)
fns = getfns(path,'.pdf')
for e in fns:
if '更新' not in e:
with pdfplumber.open(e) as pdf:
for page in pdf.pages:
d = page.extract_table()
if d is not None:
c1 = f1(d)
if '' == c1[0] and '营业收入(元)' in c1 and '基本每股收益(元/股)' in c1:
c12 = f2(d)
print(c12[0][1], c12[1][1])
for c in c12:
if c[0] == '基本每股收益(元/股)':
print(c[1])
data = {
'年份': c12[0][1],
'营业收入(元)': c12[1][1],
'基本每股收益(元/股)': c[1],
'股票代码': company_code,
'办公地址': c12[10],
'公司网址': c12[12],
}
df = pd.DataFrame([data])
df.to_csv('数据.csv', index=False, mode='a', header=not os.path.exists('数据.csv'))
break # 添加注释,结束循环
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10)
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
import os
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10.index.tolist())
year = dict(Counter(data['年份']))
year_list = [int(i) for i in year.keys()]
year_list.sort()
print(year_list)

#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_excel('C:/Users/Desktop/数据.xlsx', usecols=['年份', '营业收入', '基本每股收益'],sheet_name='Sheet2')
plt.figure()
plt.plot(df['年份'], df['营业收入'], 'o-', label='营业收入', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('营业收入')
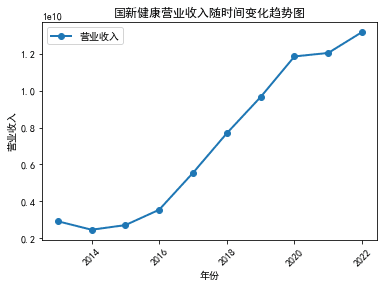
plt.title('国新健康营业收入随时间变化趋势图')
plt.legend()
plt.show()
plt.figure()
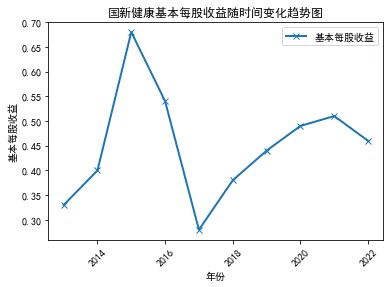
plt.plot(df['年份'], df['基本每股收益'], 'x-', label='基本每股收益', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.title('国新健康基本每股收益随时间变化趋势图')
plt.legend()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_excel('C:/Users/xiaolu/Documents/Tencent Files/2927627761/FileRecv/nianbao.xls', usecols=['年份', '股票简称', '股票代码', '营业收入', '基本每股收益'])
grouped = df.groupby(['年份'])
for name, group in grouped:
plt.figure(figsize=(12, 6))
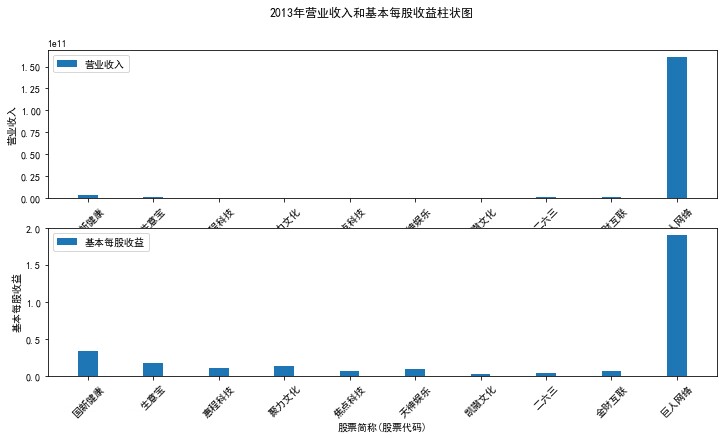
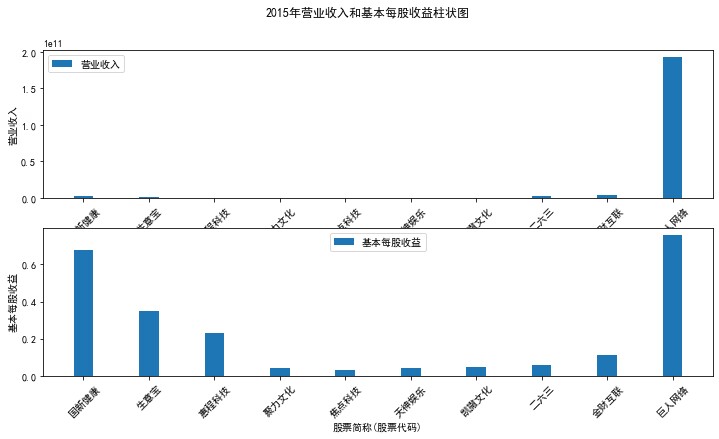
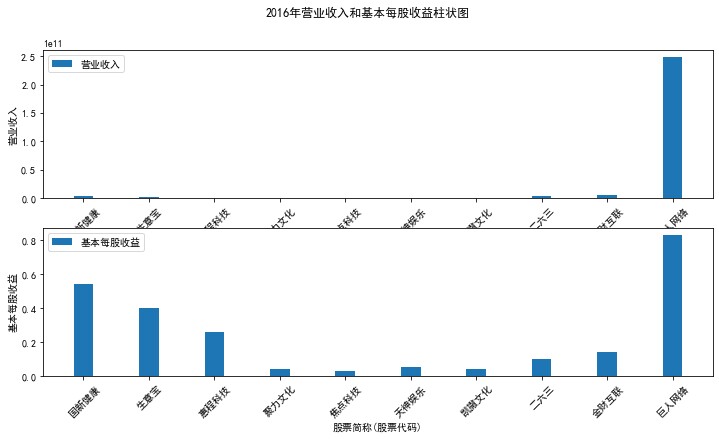
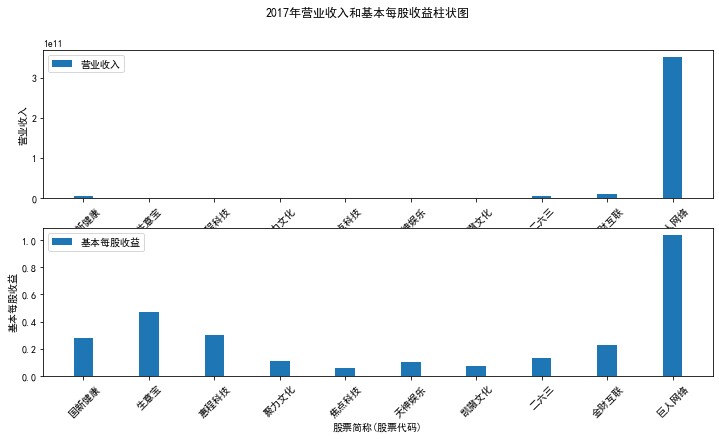
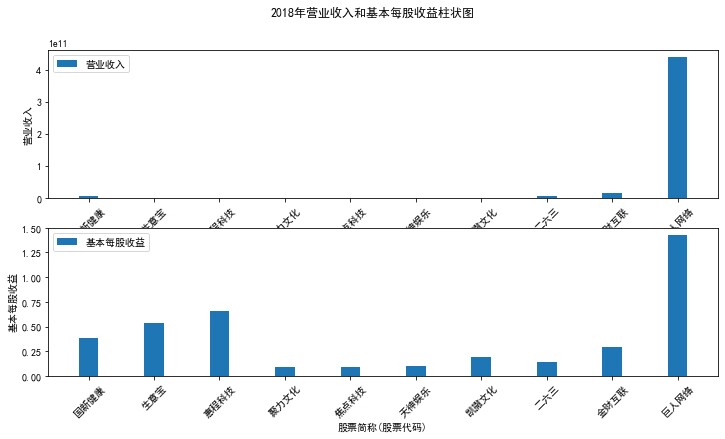
plt.suptitle(f"{name}年营业收入和基本每股收益柱状图")
plt.subplot(211)
plt.bar(group['股票简称'], group['营业收入'], width=0.3, label='营业收入')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('营业收入')
plt.legend()
plt.subplot(212)
plt.bar(group['股票简称'], group['基本每股收益'], width=0.3, label='基本每股收益')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('基本每股收益')
plt.legend()
plt.show()
本次实验,是整个学期课程的一个概括总结,Python课程确实很难,这种实验结果也没有如所想那样完美,从这节课中我学到了很多知识,也懂得了如何运用Python进行爬虫和分析,对我以后无论是工作还是学习都很有帮助,再次感谢老师的指导。希望自己以后能更加投入去学习新的知识,不断进行Python练习,更熟练掌握一门技巧。