一、实验要求 在深圳交易所爬取并下载十家公司的近十年年报,记录每家公司十年年报对应的网址。利用公司年报解析公司基本信息(网址、电子 信箱、办公地址、法定代表人和董秘电话),同时解析各家公司十年来的营业收入、净利润和归属于上市公司利润,分析其营业指标 二、设计思路 由于深交所上的年报数据是异步加载,无法直接在网页源码中获取年报,如果直接在网路中抓包,因为年报数量庞大,逐个遍历寻找目 标年报的效率不高,所以本文使用selenium库模拟鼠标点击浏览器获取各公司年报的下载界面,再在网络抓包并下载年报数据,将各 个公司近十年的下载界面和下载链接保存为csv文件和html文件。 下载完十家公司的近十年年报后,对各公司的十年年报进行爬取,使用正则表达式爬取各家公司十年来的营业收入、净利润和归属于 上市公司利润以及该公司的网址、电子信箱、办公地址、法定代表人和董秘电话。 最终利用python画图,分析公司的财务状况。
page = pdfplumber.open("C:/Users/一二三/Desktop/金融数据获取与处理/大作业/行业及其代码.pdf").pages[102] #获取第103页
table = page.extract_table()
df102= pd.DataFrame(table)
page = pdfplumber.open("C:/Users/一二三/Desktop/金融数据获取与处理/大作业/行业及其代码.pdf").pages[103] #获取第104页
table = page.extract_table()
df103= pd.DataFrame(table)[1:]
page = pdfplumber.open("C:/Users/一二三/Desktop/金融数据获取与处理/大作业/行业及其代码.pdf").pages[104] #获取第105页
table = page.extract_table()
df104= pd.DataFrame(table)[1:]
df=[]
df=df102.append(df103)
df=df.append(df104)
df.columns = ['行业','行业代码','行业名称','公司代码','公司名称']
df = df.fillna(method='ffill')
df = df.iloc[1:,]
df=df[['行业代码','公司代码','公司名称']]
df.index = df['公司代码']
df = df.loc['000005':'688701',]
dfshenzhen=df.loc['000005':'301049',]
data=dfshenzhen[:10]
图1 生态保护和环境治理业(第77个小行业)的代码以及简称
的代码以及简称.png)
首先是要使用selenium模拟鼠标爬取各个公司的十年年报
爬取完成后保存年报数据,保存网址为csv文件和html文件。以ST星源公司为例,以下各图为运行结果,其中以ST星源(代码000005)做为个体展示的例子
图2 十家公司年报下载链接的csv

图3 ST星源csv的具体内容
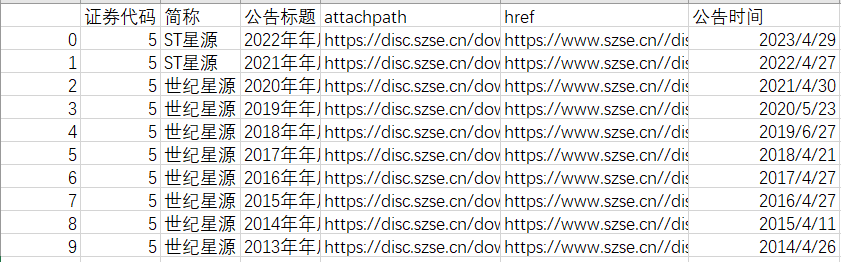
图4 十家公司年报下载链接的html
图5 ST星源html的具体内容

图6 爬取十家公司的年报放置文件夹
图7 ST星源文件夹内容
其中包括从html中解析出下载链接、去除无用链接、自动下载年报的几个重要函数或者板块,最后将他们运行,得到结果
import pdfplumber
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
from bs4 import BeautifulSoup
def InputTime(start,end): #找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): #找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code') # Find the search box
Searchbox.send_keys(name)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
def Clearicon(): #清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): #点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename,content):
with open(filename+'.html','w',encoding='utf-8') as f:
f.write(content)
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
with open(filename+'.html', encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
print('\n(爬取网页中......)')
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2014-01-01',End)
Company=pd.DataFrame([['000005','ST星源'],['000035','中国天楹'],['000546','金圆股份'],['000803','北清环能'],['000826','启迪环境'],['000967','盈峰环境'],['002034','旺能环境'],['002266','浙富控股'],['002310','东方园林'],['002549','凯美特气']],columns=['上市公司代码','上市公司简称'])
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
#在深交所官网爬取深交所上市公司年报链接
for index,row in Company.iterrows():
code = row[0]
name = row[1].replace('*','')
SearchCompany(code)
time.sleep(0.5) # 延迟执行0.5秒,等待网页加载
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
Clearicon()
print('\n【开始保存年报】')
print('正在下载深交所上市公司年报')
i = 0
for index,row in Company.iterrows(): #下载在深交所上市的公司的年报
i+=1
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司,当前第',i,'所。')
os.chdir('../') #将当前工作目录爬到父文件夹,防止下一次循环找不到html文件
对年报的pdf处理同样是实验的难点,各家公司十年来的营业收入、净利润和归属于上市公司利润以及该公司的网址、电子信箱、办公地址、法定代表人和董秘电话。本次项目需要获取的信息都在页数较前的地方,为了加快运行速率,每份年报只读取前15页。爬取年报信息的过程见图,涉及具体内容的展示仍以ST星源(代码000005)做例
图8 十家公司年报读取过程
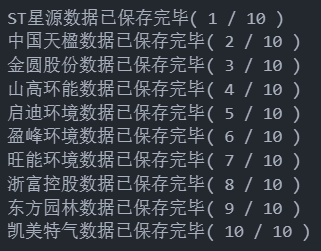
图9 十家公司年报内容解析结果(含财务数据以及公司基本信息)
图10 ST星源年报内容解析结果(含财务数据以及公司基本信息)
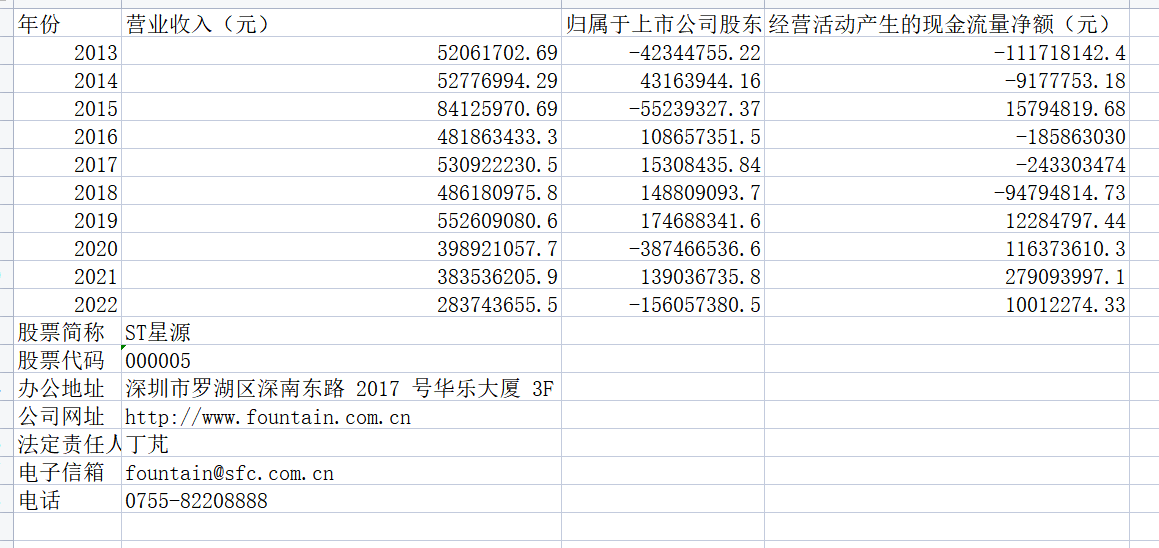
循环读取企业的信息,其难点在于正则表达式的编写
import pandas as pd
import fitz
import re
# Company=pd.read_csv('ST星源.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
a=pd.DataFrame([data.index,data['上市公司简称']]).T
a.columns=['上市公司代码','上市公司简称']
company=a
company=Company.iloc[:,1].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2013,2022)) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(15): #读取每份年报前15页的数据(一般财务指标读15页就够了,全部读取的话会比较耗时间)
page = doc[j]
text += page.get_text()
year = int(title[0:4])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业收入\n?(?元?)?\s?\n?([\d+,]*\n?\.\n?\d\n?\d)\s\n?')
p_eps = re.compile('(?<=\n)归属于上市\n?公\n?司\n?股\n?东\n?的\n?净\n?利\n?润\n?(?\n?元?\n?)?\s?\n?([-\d+,\n]*\n?\.\n?\d\n?\d)\s?\n?')
p_pro=re.compile('(?<=\n)经营活动产\n?生\n?的\n?现\n?金\n?流\n?量\n?净\n?额\n?(?\n?元?\n?)?\n?\s?\n?([-\d+,\n]*\n?\.\n?\d\n?\d)\s\n?')
p_user=re.compile('(?<=\n)\w*公司的法定代表人:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_site = re.compile('(?<=\n)\w*办公地址?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z0-9./:/-]*)\s?(?=\n)',re.DOTALL)
p_mail=re.compile('(?<=\n)电子信箱:?\s?\n?([a-zA-Z0-9+@\-\.]*)\s?(?=\n)',re.DOTALL)
p_tel=re.compile('(?<=\n)电话:?\s?\n?([0-9\-、]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','').replace('\n','')) #将匹配到的营业收入的千分位去掉并转为浮点数
eps=p_eps.search(text).group(1).replace(',','').replace('\n','')
pro=p_pro.search(text).group(1).replace(',','').replace('\n','')
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'归属于上市公司股东的净利润(元)']=eps
final.loc[year,'经营活动产生的现金流量净额(元)']=pro
final.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
site=p_site.search(text).group(1) #匹配办公地址和网址(由于取最近一年的,所以只要匹配一次不用循环匹配)
web=p_web.search(text).group(1)
user=p_user.search(text).group(1)
mail=p_mail.search(text).group(1)
tel=p_tel.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f: #把股票简称,代码,办公地址和网址写入文件末尾
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s\n法定责任人,%s\n电子信箱,%s\n电话,%s'%(name,code,site,web,user,mail,tel)
f.write(content)
print(name+'数据已保存完毕'+'(',t,'/',len(company),')')
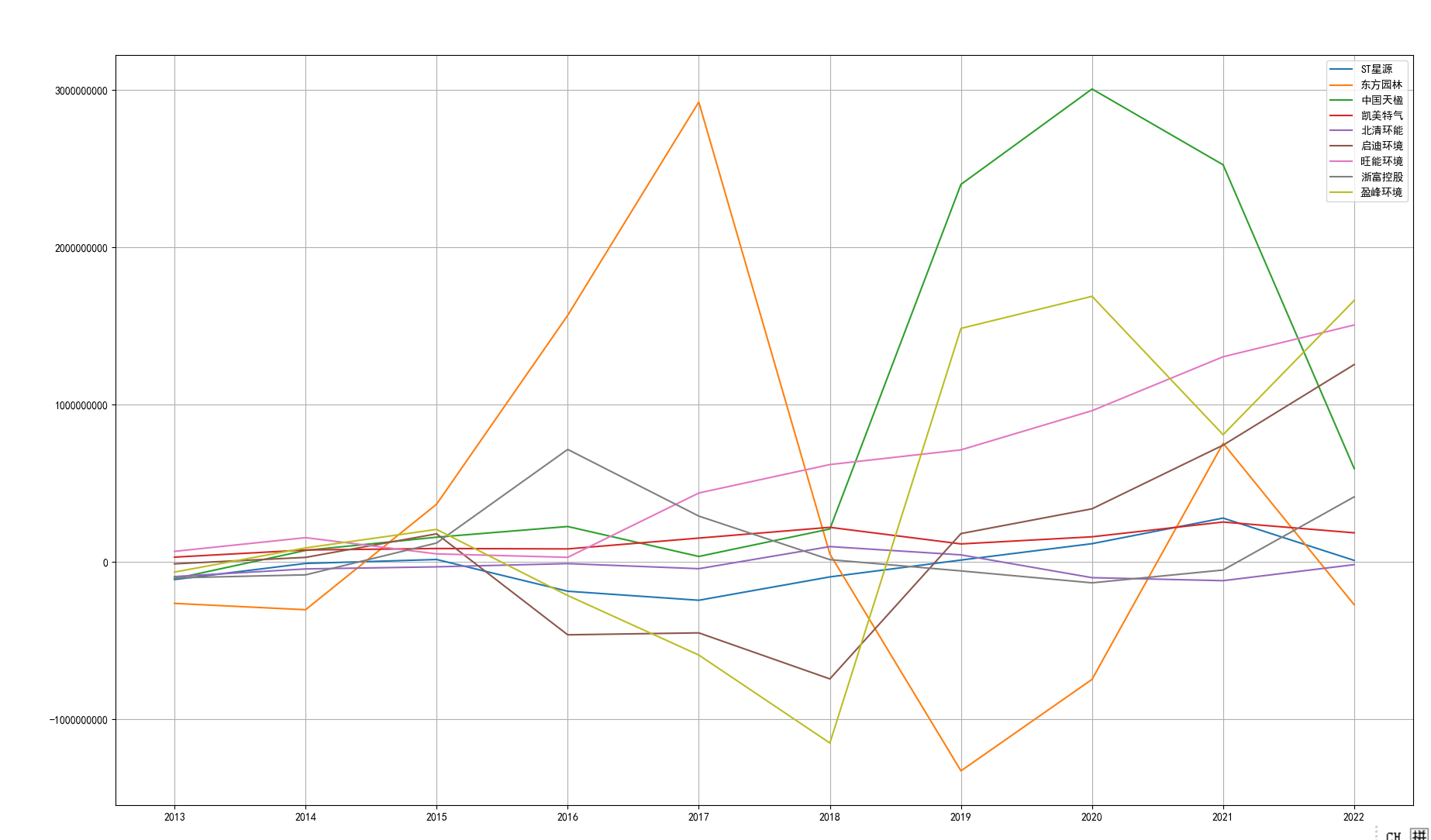
将十家公司的营业收入及净利润循环作图,由于三维图并不利于得出结论,没有加入现金流量
图11 系列图:十家公司各自的纵向对比
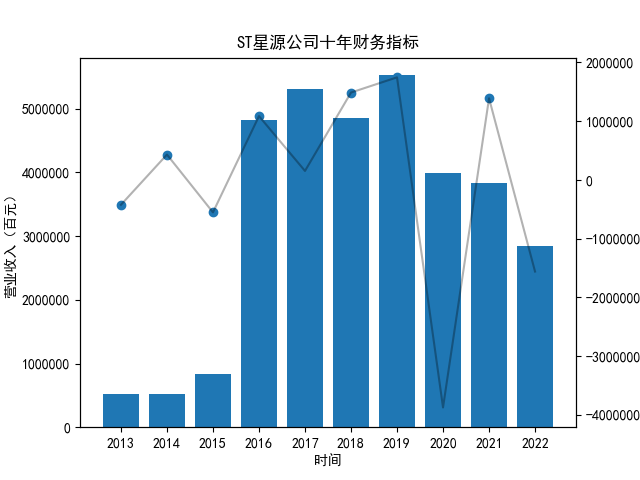
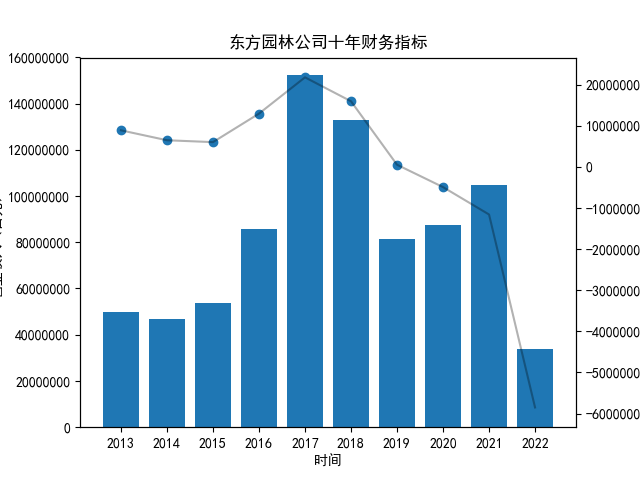
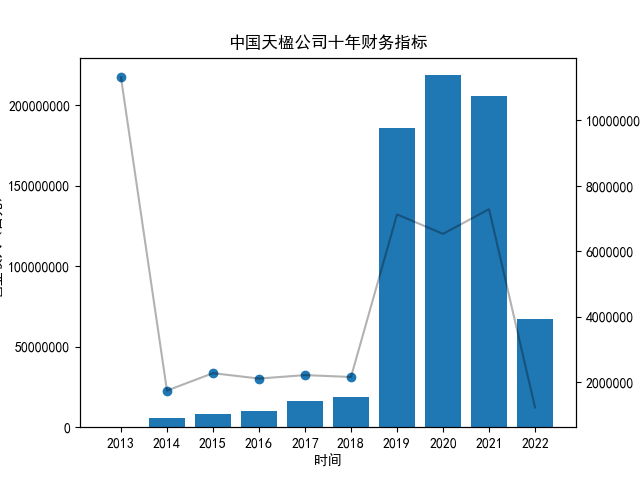
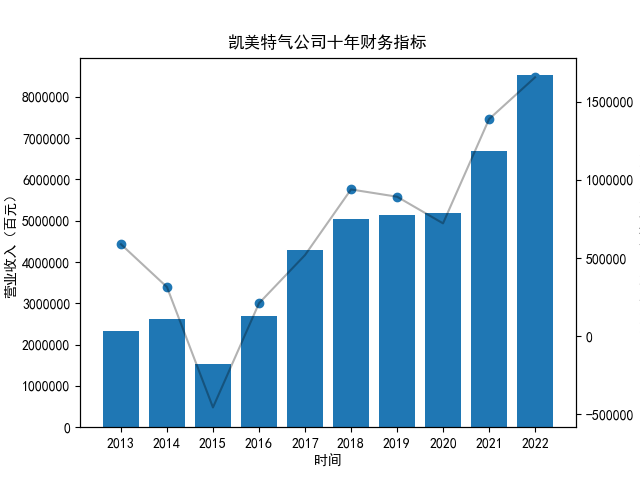
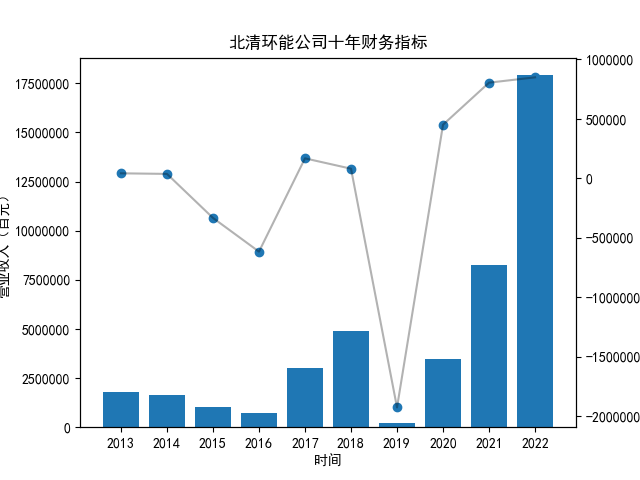
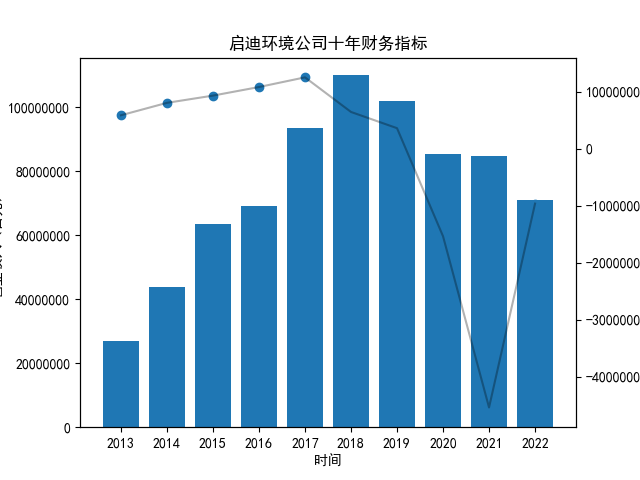
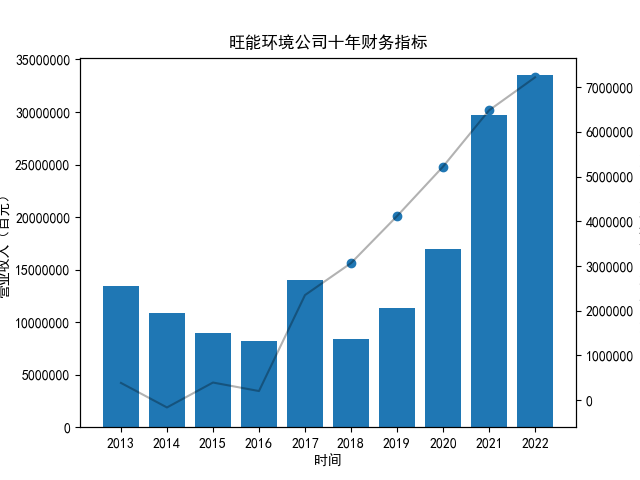
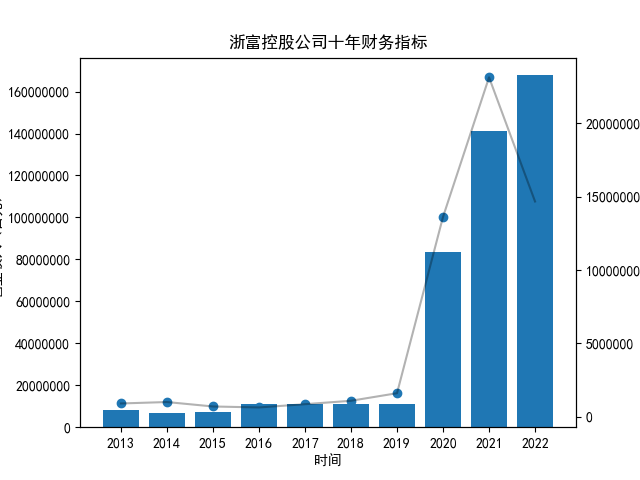
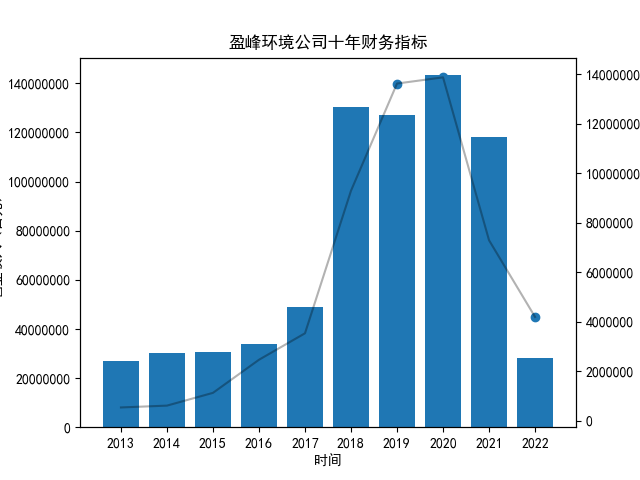
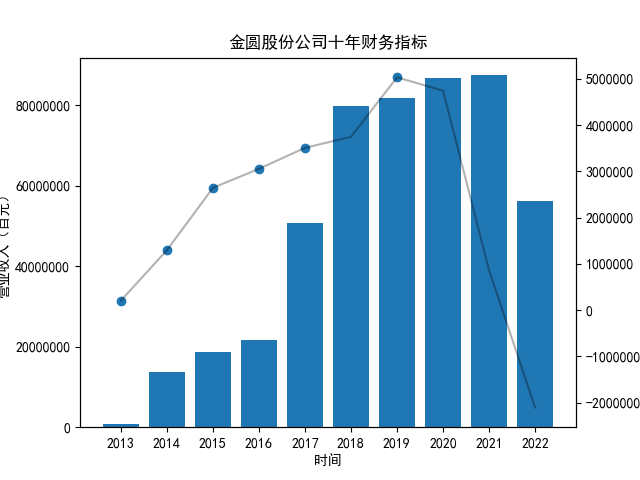
首先将所有公司的数据根据columns分到三个dataframe,对dataframe的每一列进行作图
图12 数据汇总结果展示
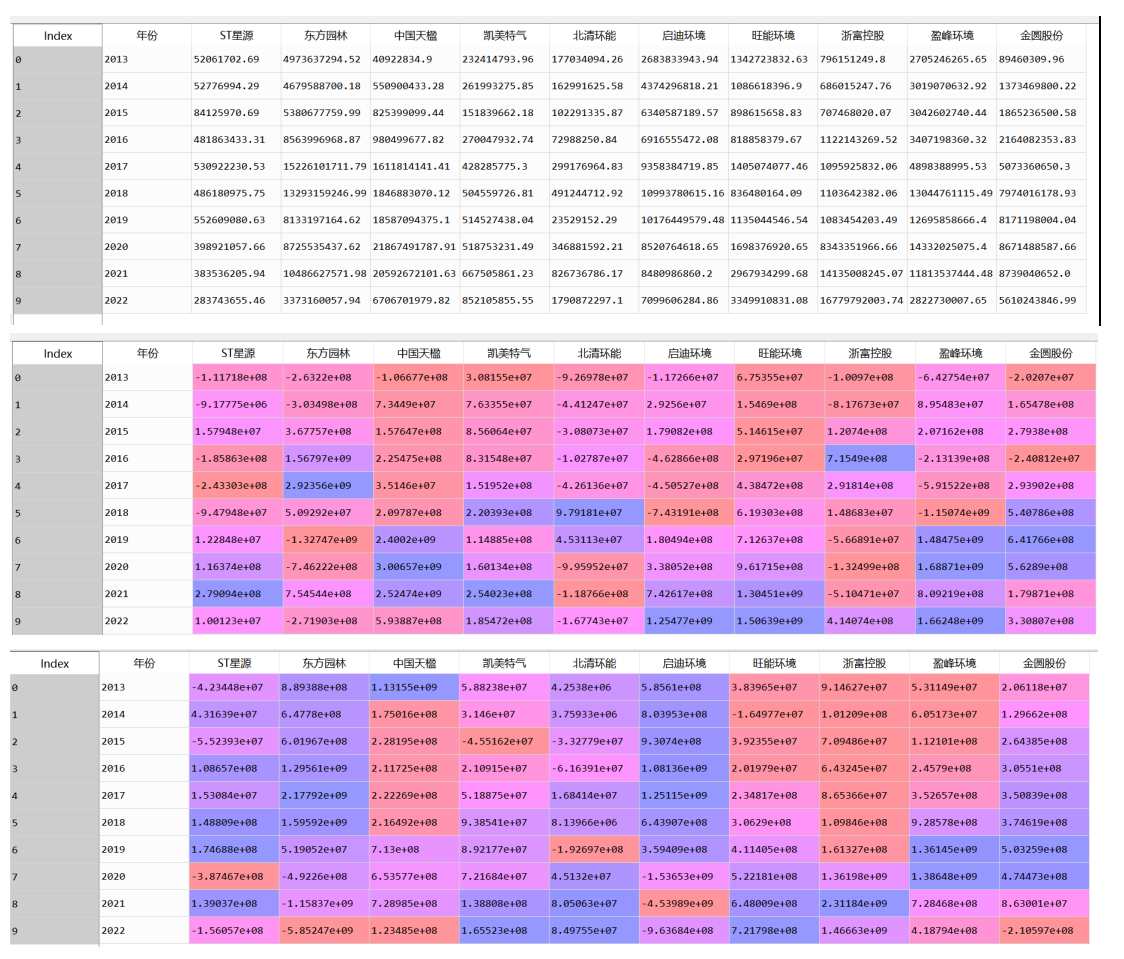
图13 十家公司营业收入横向对比
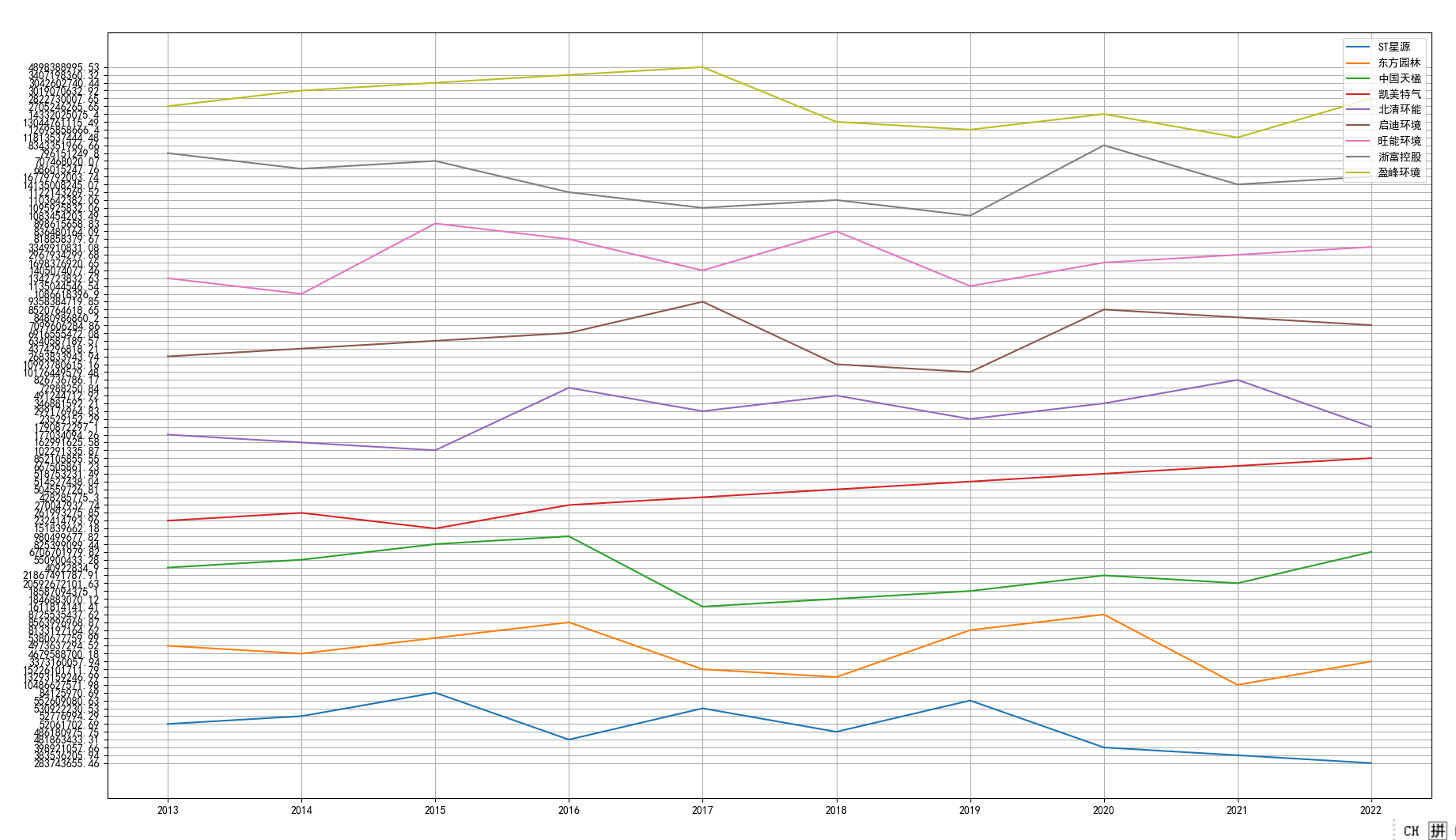
图14 十家公司净利润横向对比
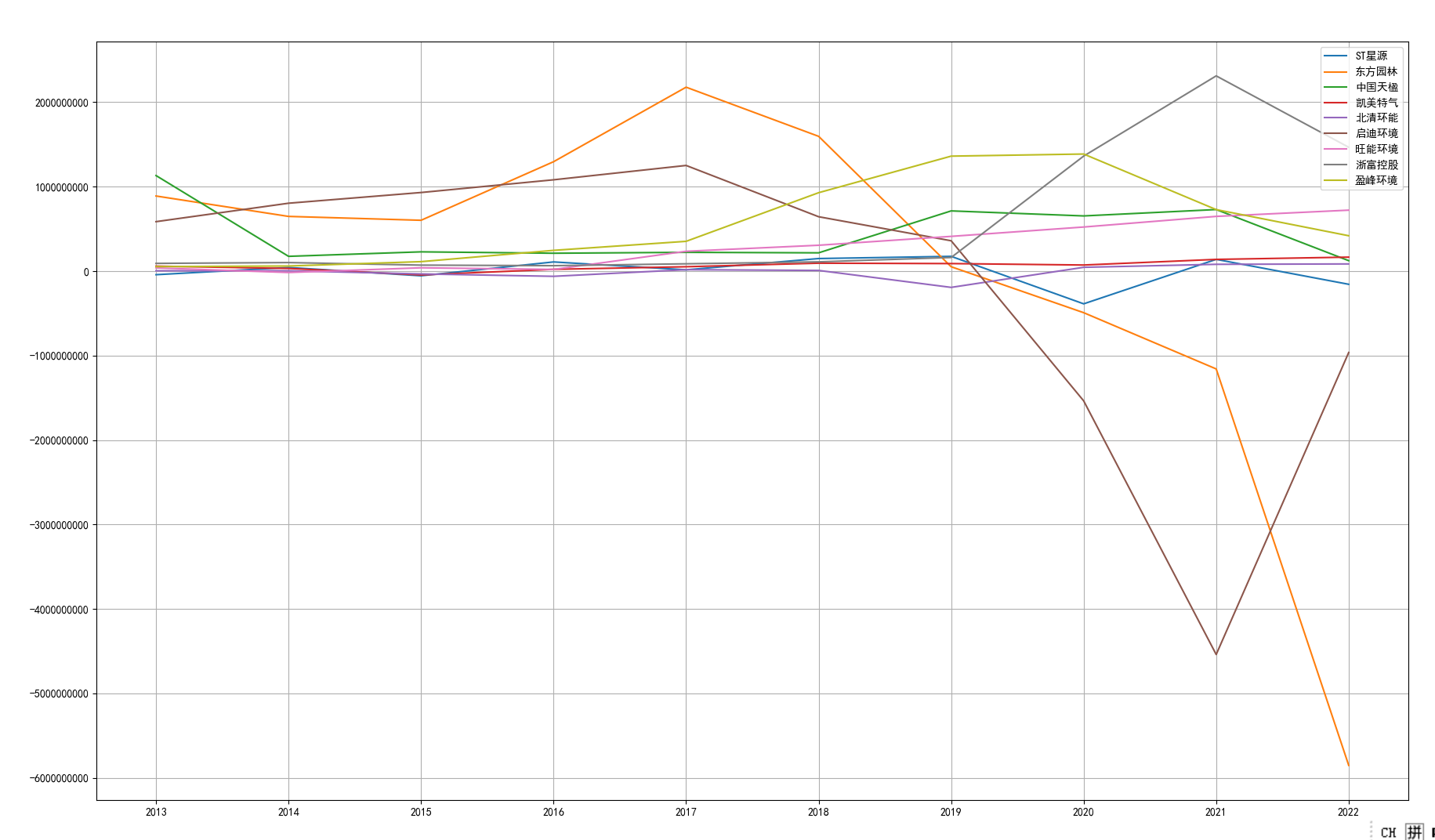
图15 十家公司现金流量横向对比
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' #显示中文
plt.rcParams['axes.unicode_minus'] = False #显示负号
import os
pd.set_option('display.float_format',lambda x : '%.3f' % x)
path = "C:/Users/一二三/Desktop/金融数据获取与处理/support/解析结果" #文件夹目录
files= os.listdir(path,encoding='gbk') #得到文件夹下的所有文件名称
yingyea=pd.DataFrame(caiwu['年份'])
jingliruna=pd.DataFrame(caiwu['年份'])
xianjina=pd.DataFrame(caiwu['年份'])
b=['年份']
for i in range(10):
caiwu=pd.read_csv(path+"/"+files[i])
name=re.split('【|】',files[i])[1]
caiwu=caiwu.iloc[:10]
xianjina=pd.concat([xianjina,caiwu['经营活动产生的现金流量净额(元)']], axis=1)
jingliruna=pd.concat([jingliruna,caiwu['归属于上市公司股东的净利润(元)']], axis=1)
yingyea=pd.concat([yingyea,caiwu['营业收入(元)']], axis=1)
b.append(name)
fig=plt.figure()
x=caiwu['年份']
y1=caiwu['营业收入(元)'].astype(float)/100
y2=caiwu['归属于上市公司股东的净利润(元)'].astype(float)/100
#ax1显示y1,ax2显示y2
ax1=fig.subplots()
ax2=ax1.twinx() #使用twinx(),得到与ax1 对称的ax2,共用一个x轴,y轴对称(坐标不对称)
ax1.bar(x,y1)
ax2.plot(x,y2,color='k',alpha=0.3)
ax2.scatter(x,y2)
ax1.set_xlabel('时间')
ax1.set_ylabel('营业收入(百元)')
ax1.ticklabel_format(axis="y", style='plain')
ax2.set_ylabel('归属于上市公司股东的净利润(百元)')
ax2.ticklabel_format(axis="y", style='plain')
plt.title("%s公司十年财务指标"%name)
plt.savefig("%s公司十年财务指标.png"%name)
plt.show()
yingyea.columns=b
jingliruna.columns=b
xianjina.columns=b
def plot_company(data):
x=data['年份']
data=data.drop(['年份'],axis=1)
plt.figure()
names = locals()
for j in range(9):
names[f'y{j + 1}'] = data[data.columns[j]].values.tolist()
plt.plot(x, names[f'y{j + 1}'],label = data.columns[j])
plt.ticklabel_format(axis="y", style='plain')
plt.legend(loc='upper right')
plt.grid()
plot_company(yingyea)
plot_company(jingliruna)
plot_company(xianjina)
分析主要从行业稳定性、营业收入、净利润和现金流等方面展开了分析。
根据图形展示结果,这十家公司在行业内处于稳固的地位,行业处于成熟期,竞争程度相对较低。市场容量大且潜在竞争对手的进入难
度较高。这种稳定性在营业收入方面体现得尤为明显,这十家公司的营业收入长期以来都表现出较为平稳的趋势,变化较小且没有明显的交叉。
这主要是由于营业收入体量大,小的量级变化难以体现;另一方面,也反映出行业内发展程度较为稳定,没有“黑马”的出现;也反映出这些
公司具有较强的市场调节能力,能够有效地操作并应对市场波动,保持盈利稳定。
然而,净利润和现金流则表现出较大的波动。虽然净利润和现金流一般情况下存在正相关关系,但也存在特例。例如在2021年,浙富控股
的净利润最高,但现金流则处于中等水平,这也表明该公司管理层的财务管理能力较为一般。
同时,疫情的出现对2020年的经济发展造成了较为显著的冲击,行业整体营业收入波动较大,净利润也出现了下降。但是这十家公司通过
调整经营策略,实施成本优化和审慎资本开支来降低经营风险,并优化运营模式来应对不利影响。由此可见这些公司具备对外部环境变化较好的
适应性,保持了盈利稳定和业务可持续发展。
综上所述,这十家公司在行业内具有较为稳定的地位并且有足够的市场竞争力,为未来的发展打下了稳固的基础。即便在遭受重大挑战
时,这些公司都能够通过成熟的运营模式和应对策略来保持财务和业务稳定,因此未来的发展前景值得期待。
本学期的python课符合我最初选择这门课的想法,教授python爬虫以及文件解析。原因是我在今年年初希望获得精细化的债券数据用于论
文写作,徐军伟,毛捷,管星华(2020)采用手工操作的方法手动摘录所需要的几千家公司的债券数据,但是我个人由于时间原因无法这样操作,
也就萌生了python爬虫的想法,但是考虑到爬虫之后对债券发行说明书的用途等方式仍需要手工,只能被迫放弃。经过这门课程的学习,希望我
在学期结束后,再次重复数据的获取。
本次实验帮助我进一步了解了爬虫和文件解析两项实用的数据获取工具。实验的难点为下载各个公司的十年年报和正则表达式,下载年报
使用selenium库完成。而正则表达式的编写则较为麻烦,有许多意料不到的问题,比如有些公司的年报数据名和数值会有过长而回车到下一行的
问题,需要对出现各种情况逐个解决。
通过这次实验,收获了很多:在大的层面,掌握了一定的爬虫、文件解析能力和初级网页制作能力,对我们写论文具有很大的作用,之前
在别的课程上,更多的是在讲解数据获得后的处理与分析,而数据怎样获取则基本没有涉及,这是唯一一门涉及数据之前工作的课程。在具体的
python实操上,老师也讲解了许多python的实用小技巧,也熟练掌握了函数定义,使得代码更加简洁。