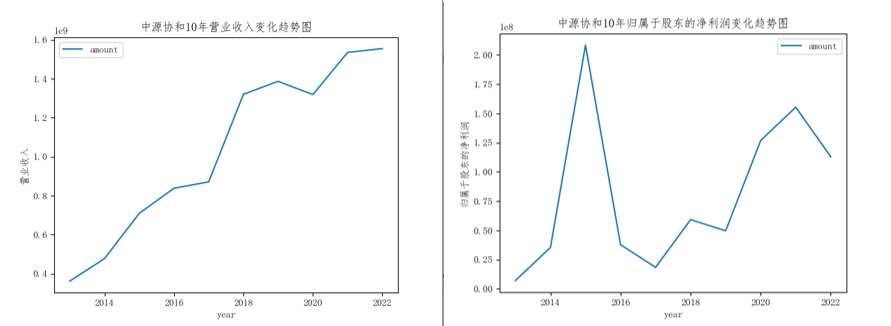
 可以看出中源协和10年的营业收入在逐渐上升,但是其归属于股东的净利润变化极不稳定,波动性很大
可以看出中源协和10年的营业收入在逐渐上升,但是其归属于股东的净利润变化极不稳定,波动性很大
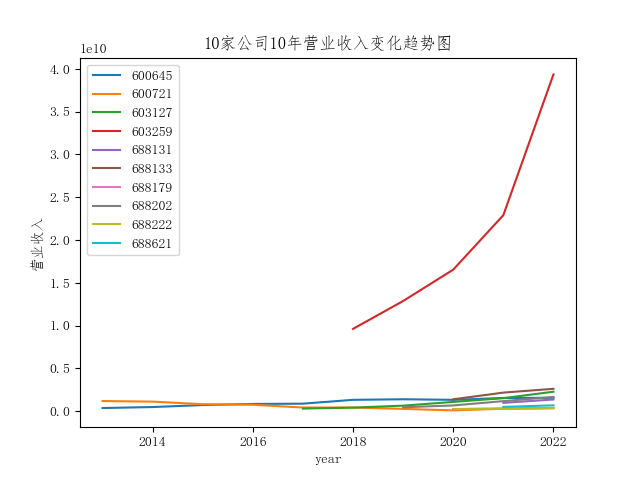
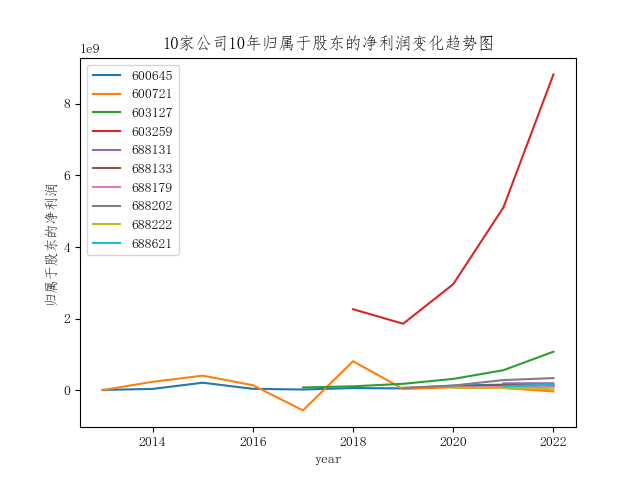 10家公司10年的营业收入也是呈逐渐上升的变化趋势,但是部分公司归属于股东的净利润波动性较大,十分明显的有股票代码为600721和603259两家公司。其中股票代码为603259的公司其营业收入和归属于股东的净利润都要明显高于其他9家公司。
10家公司10年的营业收入也是呈逐渐上升的变化趋势,但是部分公司归属于股东的净利润波动性较大,十分明显的有股票代码为600721和603259两家公司。其中股票代码为603259的公司其营业收入和归属于股东的净利润都要明显高于其他9家公司。
.png)

#获取上交所年报pdf下载链接
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import requests
import re
import fitz
import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
from datetime import datetime
from scipy import stats
mpl.rcParams['font.sans-serif']=['FangSong']
mpl.rcParams['axes.unicode_minus']=False
#edge浏览器
def get_table_sse(code):
browser = webdriver.Edge()
url = "http://www.sse.com.cn/disclosure/listedinfo/regular/"
browser.get(url)
time.sleep(3)
browser.set_window_size(1552, 840)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(3)
#
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
#
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML') #网页数据证券代码部分全获取
#
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
#
browser.quit()
def get_data(tr):
p_td = re.compile('(.*?)',re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1 #起始索引
e = tds[0].rfind('<') #结束索引
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip() #strip是两边如果有空格就删掉空格
data = [code,name,href,title,date]
return(data)
def parse_table(fname):
f = open(fname,encoding='utf-8')
html = f.read()
f.close()
p = re.compile('(.+?) ',re.DOTALL)
trs = p.findall(html)
#删掉空行
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr) #预处理,对空行进行处理
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code':[d[0] for d in data_all],
'name':[d[1] for d in data_all],
'href':[d[2] for d in data_all],
'title':[d[3] for d in data_all],
'date':[d[4] for d in data_all]
})
return(df)
#筛选过滤掉一些不必要的公告链接
def filter_words(words, df, include=True):
'''
筛选保留年报链接
:param words:保留或剔除包含关键词列表
:param df:DataFrame
:param include:keep or exclude
:return:a dataframe
:rtype: DataFrame
'''
ls = []
for word in words:
if include:
# ls.append([word in f for f in df.f_name])
ls.append([word in f for f in df['title']])
else:
# ls.append([word not in f for f in df.f_name])
ls.append([word not in f for f in df['title']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
def filter_date(start, end, df):
date = df['date']
v = [d >= start and d <= end for d in date] #逻辑值列表
df_new = df[v]
return(df_new)
def start_end_10y():
dt_now = datetime.datetime.now()
current_year = dt_now.year
start = f'{current_year-9}-01-01'
end = f'{current_year}-12-31'
return((start,end))
def filter_nb_10y(df, keep_words=['年报','年度报告'], exclude_words=['摘要','补充版'], start=''):
if start == '':
start, end = start_end_10y()
else:
start_y = int(start[0:4])
end = f'{start_y + 9}-12-31'
#
df = filter_words(keep_words, df, include=True)
df = filter_words(exclude_words, df, include=False)
df = filter_date(start, end, df)
return(df)
def prepare_hrefs_years(df):
hrefs = df['href'].to_list()
years = [int(d[:4])-1 for d in df['date']]
return((hrefs,years))
#批量下载pdf
def download_pdfs(hrefs, code, years):
#单个股票年报批量下载
for i in range(len(hrefs)):
href = hrefs[i]
year = years[i]
download_pdf(href, code, year)
time.sleep(60) #让下载不那么快
return()
#由于各个年报存在差异,因此给出两种有些许区别的解析年报的方式,这部分解析营业收入和归属于股东的净利润
#以下为第一种
def get_subtxt(doc, bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首位页码
start_pageno = 0
end_pageno = len(doc) - 1
#
lb, ub = bounds #
#获取左界代码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界代码
for n in range(start_pageno, len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围内字符串
txt = ''
for n in range(start_pageno, end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
#识别表的标题
def get_th_span(txt):
nianfen = '(20\d\d|199\d)\s*年' #'(20\d\d|199\d)\s*年'
s = f'{nianfen}\s*{nianfen}.*?{nianfen}'
p = re.compile(s, re.DOTALL)
matchobj = p.search(txt)
#
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
#
while (not flag):
matchobj = p.search(txt[end:])
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
flag = (int(year1) - int(year2) == 1)
flag = flag and (int(year2) - int(year3) == 1)
#
return(matchobj.span())
#有注释的话
def get_bounds(txt):
th_span_1st = get_th_span(txt)
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])
th_span_2nd = (end + th_span_2nd[0], end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0] - 1
#
while (txt[e] not in '0123456789'):
e = e - 1
return(s,e + 1)
def get_keywords(txt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext,keywords):
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
#
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
#获取可能换行的账户名称
matchobj = p.search(line)
account_name = p2.sub('', matchobj.group())
#获取三年数据
amnts = line[matchobj.end():].split()
#加上账户名称
amnts.insert(0, account_name)
#追加到总数据
data.append(amnts)
return(data)
#以下为第二种方法,取第一种方法未取出的数据
def get_target_pageno(doc, anchor='主要会计数据和财务指标'):
pageno = -1
for n in range(len(doc)):
page = doc[n] #n=0是第一页
txt = page.get_text()
if anchor in txt:
pageno = n
break
return(pageno)
def parse_key_fin_data1(subtext):
keywords = ['营业收入','归属于上市公司股东的\n净利润'] #归属于上市公司股东的净利\n润
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return(data)
#解析公司基本信息,由于各年报存在差异,因此这里也分两种
#第一种
def get_target_pageno1(doc, anchor='公司信息'):
pageno = -1
for n in range(len(doc)):
page = doc[n] #n=0是第一页
txt = page.get_text()
if anchor in txt:
pageno = n
break
return(pageno)
def parse_key_fin_data2(subtext):
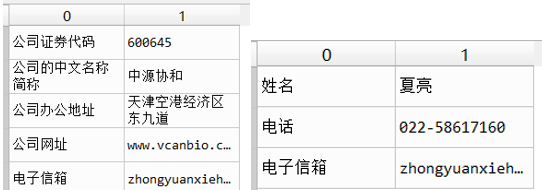
keywords = ['公司的中文名称简称','公司办公地址 ','公司网址','电子信箱',]
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw) #为什么加len(kw)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return(data)
#第二种
def get_target_pageno2(doc, anchor='公司基本情况'):
pageno = -1
for n in range(len(doc)):
page = doc[n] #n=0是第一页
txt = page.get_text()
if anchor in txt:
pageno = n
break
return(pageno)
def parse_key_fin_data3(subtext):
keywords = ['公司的中文简称','公司办公地址 ','公司网址','电子信箱',]
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return(data)
#解析公司董秘信息
def get_target_pageno3(doc, anchor='联系人和联系方式'):
pageno = -1
for n in range(len(doc)):
page = doc[n] #n=0是第一页
txt = page.get_text()
if anchor in txt:
pageno = n
break
return(pageno)
def parse_key_fin_data3(subtext):
keywords = ['姓名','电话 ','电子信箱',]
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return(data)
#取出10年的年份
def get_years(csvs):
years = []
#
for i in csvs:
year = f'{int(i[7:11])}'
years.append(year)
return(years)
#取出10年每年的营业收入数额
def get_yysr1(csvs):
nums = []
#
for i in csvs:
data=pd.read_csv(i,header=None,index_col=0)
data.columns = [f'{int(i[7:11])}',f'{int(i[7:11])-1}','本期比上年同期增减(%)',f'{int(i[7:11])-2}']
data1 = data[0:2].iloc[:,0]
#
num = np.array(data1)
num1 = num[0]
nums.append(num1)
#对营业收入字符串数据进行处理,删去逗号,使之成为浮点数
nums11 = []
for i in nums:
i = i.replace(',', '')
nums11.append(i)
nums2 = [float(x) for x in nums11]
return(nums2)
#取出10年每年的归属于股东的净利润
def get_gsygdjlr1(csvs):
numss = []
#
for i in csvs:
data=pd.read_csv(i,header=None,index_col=0)
data.columns = [f'{int(i[7:11])}',f'{int(i[7:11])-1}','本期比上年同期增减(%)',f'{int(i[7:11])-2}']
data1 = data[0:2].iloc[:,0]
#
num = np.array(data1)
num1 = num[1]
numss.append(num1)
#对归属于股东的净利润字符串数据进行处理,删去逗号,使之成为浮点数
numss11 = []
for i in numss:
i = i.replace(',', '')
numss11.append(i)
#
numss2 = [float(x) for x in numss11]
return(numss2)
#10家公司10年的年份和营业收入合并,并保存并画图
def linkyysr_save(csvs):
years = get_years(csvs)
pic = [years]
nums2 = get_yysr1(csvs)
nums2_2 = get_yysr1(csvs1)
nums2_3 = get_yysr1(csvs2)
nums2_4 = get_yysr1(csvs3)
nums2_5 = get_yysr1(csvs4)
nums2_6 = get_yysr1(csvs5)
nums2_7 = get_yysr1(csvs6)
nums2_8 = get_yysr1(csvs7)
nums2_9 = get_yysr1(csvs8)
nums2_10 = get_yysr1(csvs9)
snums = [nums2,nums2_2,nums2_3,nums2_4,nums2_5,nums2_6,nums2_7,nums2_8,nums2_9,nums2_10]
for i in snums:
pic.append(i)
pic1 = pd.DataFrame(pic)
df_T = pd.DataFrame(pic1.values.T, index=pic1.columns, columns=pic1.index) #转置
df_T.to_csv('tenyearyysr10.csv',index=False,header=False)
#读取10家公司10年的年份和营业收入,并画图
df_Tdata = pd.read_csv('tenyearyysr10.csv', header=None,names=['year', '600645','600721','603127','603259','688131','688133','688179','688202','688222','688621'],index_col=0)
df_Tdata.plot(ylabel=u'营业收入',title=u'10家公司10年营业收入变化趋势图',figsize=(15,18))
plt.savefig('10家公司10年营业收入变化趋势图.png')
return()
#读取10家公司10年的年份和归属于股东的净利润,并保存并画图
def linkjlr_save(csvs):
years = get_years(csvs)
pic2 = [years]
numss2 = get_gsygdjlr1(csvs)
numss2_2 = get_gsygdjlr1(csvs1)
numss2_3 = get_gsygdjlr1(csvs2)
numss2_4 = get_gsygdjlr1(csvs3)
numss2_5 = get_gsygdjlr1(csvs4)
numss2_6 = get_gsygdjlr1(csvs5)
numss2_7 = get_gsygdjlr1(csvs6)
numss2_8 = get_gsygdjlr1(csvs7)
numss2_9 = get_gsygdjlr1(csvs8)
numss2_10 = get_gsygdjlr1(csvs9)
snumss = [numss2,numss2_2,numss2_3,numss2_4,numss2_5,numss2_6,numss2_7,numss2_8,numss2_9,numss2_10]
for i in snumss:
pic2.append(i)
pic22 = pd.DataFrame(pic2)
df_T1 = pd.DataFrame(pic22.values.T, index=pic22.columns, columns=pic22.index) #转置
df_T1.to_csv('tenyeargsygdjlr10.csv',index=False,header=False)
#读取10家公司10年的年份和归属于股东的净利润,并画图
df_T1data = pd.read_csv('tenyeargsygdjlr10.csv', header=None,names=['year', '600645','600721','603127','603259','688131','688133','688179','688202','688222','688621'],index_col=0)
df_T1data.plot(ylabel=u'归属于股东的净利润',title=u'10家公司10年归属于股东的净利润变化趋势图',figsize=(15,18))
plt.savefig('10家公司10年归属于股东的净利润变化趋势图.png')
return()
#中源协和10年营业收入和归属于股东净利润时序图
def zyxh_plot(csvs):
years = get_years(csvs)
nums2 = get_yysr1(csvs)
numss2 = get_gsygdjlr1(csvs)
#年份和营业收入合并
pic = []
pic.append(years)
pic.append(nums2)
pic = list(map(list, zip(*pic))) #转置
pic1 = pd.DataFrame(pic)
#保存10年营业收入
pic1.to_csv('tenyearyysr.csv',index=False,header=False)
#年份和归属于股东的净利润合并
pic1 = []
pic1.append(years)
pic1.append(numss2)
pic1 = list(map(list, zip(*pic1))) #转置
pic2 = pd.DataFrame(pic1)
#保存10年归属于股东的净利润
pic2.to_csv('tenyeargsygdjlr.csv',index=False,header=False)
#读取10年营业收入
data = pd.read_csv('tenyearyysr.csv', header=None,names=['year', 'amount'],index_col=0)
data.plot(ylabel=u'营业收入',title=u'中源协和10年营业收入变化趋势图')
plt.savefig('中源协和10年营业收入变化趋势图.png')
#读取10年归属于股东的净利润
data1 = pd.read_csv('tenyeargsygdjlr.csv', header=None,names=['year', 'amount'],index_col=0)
data1.plot(ylabel=u'归属于股东的净利润',title=u'中源协和10年归属于股东的净利润变化趋势图')
plt.savefig('中源协和10年归属于股东的净利润变化趋势图.png')
return()
代码实现
#获取网页、下载pdf
#600645
df_1 = get_table_sse('600645')
df1_1 = parse_table('600645.html')
df1_1.to_csv('600645.csv')
csv_1 = pd.read_csv('600645.csv')
csv_new_1 = filter_nb_10y(csv_1, keep_words=['年报','年度报告'], exclude_words=['摘要','补充版'], start='')
hrefs_1, years_1 = prepare_hrefs_years(csv_new_1)
csv_pdf_1 = download_pdfs(hrefs_1, 600645, years_1)
#600721
df_2 = get_table_sse('600721')
df1_2 = parse_table('600721.html')
df1_2.to_csv('600721.csv')
csv_2 = pd.read_csv('600721.csv')
csv_new_2 = filter_nb_10y(csv_2, keep_words=['年报','年度报告'], exclude_words=['摘要','修订稿','修订版'], start='')
hrefs_2, years_2 = prepare_hrefs_years(csv_new_2)
csv_pdf_2 = download_pdfs(hrefs_2, 600721, years_2)
#603127
df_3 = get_table_sse('603127')
df1_3 = parse_table('603127.html')
df1_3.to_csv('603127.csv')
csv_3 = pd.read_csv('603127.csv')
csv_new_3 = filter_nb_10y(csv_3, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_3, years_3 = prepare_hrefs_years(csv_new_3)
csv_pdf_3 = download_pdfs(hrefs_3, 603127, years_3)
#603259
df_4 = get_table_sse('603259')
df1_4 = parse_table('603259.html')
df1_4.to_csv('603259.csv')
csv_4 = pd.read_csv('603259.csv')
csv_new_4 = filter_nb_10y(csv_4, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_4, years_4 = prepare_hrefs_years(csv_new_4)
csv_pdf_4 = download_pdfs(hrefs_4, 603259, years_4)
#688131
df_5 = get_table_sse('688131')
df1_5 = parse_table('688131.html')
df1_5.to_csv('688131.csv')
csv_5 = pd.read_csv('688131.csv')
csv_new_5 = filter_nb_10y(csv_5, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_5, years_5 = prepare_hrefs_years(csv_new_5)
csv_pdf_5 = download_pdfs(hrefs_5, 688131, years_5)
#688133
df_6 = get_table_sse('688133')
df1_6 = parse_table('688133.html')
df1_6.to_csv('688133.csv')
csv_6 = pd.read_csv('688133.csv')
csv_new_6 = filter_nb_10y(csv_6, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_6, years_6 = prepare_hrefs_years(csv_new_6)
csv_pdf_6 = download_pdfs(hrefs_6, 688133, years_6)
#688179
df_7 = get_table_sse('688179')
df1_7 = parse_table('688179.html')
df1_7.to_csv('688179.csv')
csv_7 = pd.read_csv('688179.csv')
csv_new_7 = filter_nb_10y(csv_7, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_7, years_7 = prepare_hrefs_years(csv_new_7)
csv_pdf_7 = download_pdfs(hrefs_7, 688179, years_7)
#688202
df_8 = get_table_sse('688202')
df1_8 = parse_table('688202.html')
df1_8.to_csv('688202.csv')
csv_8 = pd.read_csv('688202.csv')
csv_new_8 = filter_nb_10y(csv_8, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_8, years_8 = prepare_hrefs_years(csv_new_8)
csv_pdf_8 = download_pdfs(hrefs_8, 688202, years_8)
#688222
df_9 = get_table_sse('688222')
df1_9 = parse_table('688222.html')
df1_9.to_csv('688222.csv')
csv_9 = pd.read_csv('688222.csv')
csv_new_9 = filter_nb_10y(csv_9, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_9, years_9 = prepare_hrefs_years(csv_new_9)
csv_pdf_9 = download_pdfs(hrefs_9, 688222, years_9)
#688621
df_10 = get_table_sse('688621')
df1_10 = parse_table('688621.html')
df1_10.to_csv('688621.csv')
csv_10 = pd.read_csv('688621.csv')
csv_new_10 = filter_nb_10y(csv_10, keep_words=['年报','年度报告'], exclude_words=['摘要'], start='')
hrefs_10, years_10 = prepare_hrefs_years(csv_new_10)
csv_pdf_10 = download_pdfs(hrefs_10, 688621, years_10)
#解析年报
filenames = ['600645_2013.pdf','600645_2014.pdf','600645_2015.pdf','600645_2016.pdf','600645_2017.pdf','600645_2018.pdf','600645_2019.pdf','600645_2020.pdf','600645_2021.pdf','600645_2022.pdf']
filenames1 = ['600721_2013.pdf','600721_2014.pdf','600721_2015.pdf','600721_2016.pdf','600721_2017.pdf','600721_2018.pdf','600721_2019.pdf','600721_2020.pdf','600721_2021.pdf','600721_2022.pdf']
filenames2 = ['603127_2017.pdf','603127_2018.pdf','603127_2019.pdf','603127_2020.pdf','603127_2021.pdf','603127_2022.pdf']
filenames3 = ['603259_2018.pdf','603259_2019.pdf','603259_2020.pdf','603259_2021.pdf','603259_2022.pdf']
filenames4 = ['688131_2021.pdf','688131_2022.pdf']
filenames5 = ['688133_2020.pdf','688133_2021.pdf','688133_2022.pdf']
filenames6 = ['688179_2020.pdf','688179_2021.pdf','688179_2022.pdf']
filenames7 = ['688202_2019.pdf','688202_2020.pdf','688202_2021.pdf','688202_2022.pdf']
filenames8 = ['688222_2020.pdf','688222_2021.pdf','688222_2022.pdf']
filenames9 = ['688621_2021.pdf','688621_2022.pdf']
for i in filenames9:
doc = fitz.open(i)
txt = get_subtxt(doc)
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
keywords = get_keywords(subtxt)
data = parse_key_fin_data(subtxt,keywords)
data1 = pd.DataFrame(data)
data2 = data1[0:5].iloc[:,[0,1,2,3,4]]
data2.to_csv(f'{i[0:11]}.csv',index=False,header=False)
filenames_1 = ['600645_2013.pdf','600721_2013.pdf','603127_2017.pdf','603259_2018.pdf']
filenames1_1 = ['688131_2021.pdf','688133_2020.pdf','688179_2020.pdf','688202_2019.pdf','688222_2020.pdf','688621_2021.pdf']
for i in filenames_1:
doc = fitz.open(i)
#
n = get_target_pageno1(doc)
page = doc[n]
txt = page.get_text()
#
s = txt.find('公司信息')
e = txt.find('四、 信息披露及备置地点 ')
subtext = txt[s:e]
#
data = parse_key_fin_data2(subtext)
data1 = pd.DataFrame(data)
data2 = data1[0:4].iloc[:,[0,1]]
namecode = ['公司证券代码',f'{i[0:6]}']
namecode = pd.DataFrame(namecode).transpose()
data3 = pd.concat([namecode,data2],axis=0)
data3.to_csv(f'{i[0:6]}_message.csv',index=False,header=False)
for i in filenames1_1:
doc = fitz.open(i)
#
n = get_target_pageno2(doc)
page = doc[n]
txt = page.get_text()
#
s = txt.find('公司基本情况')
e = txt.find('二、联系人和联系方式 ')
subtext = txt[s:e]
#
data = parse_key_fin_data3(subtext)
data1 = pd.DataFrame(data)
data2 = data1[0:4].iloc[:,[0,1]]
namecode = ['公司证券代码',f'{i[0:6]}']
namecode = pd.DataFrame(namecode).transpose()
data3 = pd.concat([namecode,data2],axis=0)
data3.to_csv(f'{i[0:6]}_message.csv',index=False,header=False)
for i in filenames_1:
doc = fitz.open(i)
#
n = get_target_pageno3(doc)
page = doc[n]
txt = page.get_text()
#
s = txt.find('联系人和联系方式')
e = txt.find('三、 基本情况简介 ')
subtext = txt[s:e]
#
data = parse_key_fin_data3(subtext)
data1 = pd.DataFrame(data)
data2 = data1[0:4].iloc[:,[0,1]]
data2.to_csv(f'{i[0:6]}_secretary_message.csv',index=False,header=False)
for i in filenames1_1:
doc = fitz.open(i)
#
n = get_target_pageno3(doc)
page = doc[n]
txt = page.get_text()
#
s = txt.find('联系人和联系方式')
e = txt.find('三、信息披露及备置地点 ')
subtext = txt[s:e]
#
data = parse_key_fin_data3(subtext)
data1 = pd.DataFrame(data)
data2 = data1[0:4].iloc[:,[0,1]]
data2.to_csv(f'{i[0:6]}_secretary_message.csv',index=False,header=False)
#画图
a = linkyysr_save(csvs)
b = linkjlr_save(csvs)
c = zyxh_plot(csvs)
1.) 首先,利用已经定义了的get_table_sse、get_data、parse_table函数从上交所上获取年报pdf的下载链接。 2.) 然后利用定义了的filter_words、filter_date、start_end_10y、filter_nb_10y函数过滤掉不需要的年报链接。 3.) 利用prepare_hrefs_years函数获取年份以及相应的链接,再利用download_pdfs函数对公司年报pdf链接进行下载。 4.) 下载完毕之后进入解析年报的环节 4.1) 利用get_subtxt、get_th_span、get_bounds、get_keywords、get_target_pageno、parse_key_fin_data1函数将公司营业收入和归属于股东的净利润取出。 4.2) 接下来利用get_target_pageno1、parse_key_fin_data2、get_target_pageno2、parse_key_fin_data3、get_target_pageno3、parse_key_fin_data3函数获取公司的基本信息和董秘信息, 实际上这些函数与上面获取营业收入的函数类似。 5.) 最后进入画图环节 5.1) 首先利用get_years、get_yysr1、get_gsygdjlr1函数取出年份以及每年的营业收入和归属于股东的净利润。 5.2) 先绘制中源协和一家公司十年的营业收入和归属于公司股东净利润的时序图 5.2.1) 利用zyxh_plot函数处理数据、保存并画图。 5.3) 然后绘制10家公司10年的营业收入和归属于公司股东净利润的时序图 5.3.1) 利用linkjlr_save函数将年份和股东净利润合并保存并画图。 5.3.2) 利用linkyysr_save函数将年份和营业收入合并保存并画图。