import datetime
import pandas as pd
import re
import time
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def Input_timeNtype(start,end,typ):
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
browser.find_element(By.LINK_TEXT,typ).click()
ActionChains(browser).move_by_offset(200, 100).click().perform()
def start_end_10y():
dt_now = datetime.datetime.now()
current_year = dt_now.year
start = f'{current_year-9}-01-01'
end = f'{current_year}-5-28'
return((start,end))
def get_szse(code,count):
Searchbox = browser.find_element(By.ID, 'input_code')
Searchbox.send_keys(code)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
time.sleep(0.5)
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
fname = f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser = webdriver.Firefox()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
start,end = start_end_10y()
typ = '年度报告'
Input_timeNtype(start,end,typ)
get_szse('002095',0)
def get_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('attachid="') +10
e = tds[2].find('"pdf') -15
href = 'https://www.szse.cn/api/disc/info/download?id=' + tds[2][s:e]
#
s = tds[2].find('title="') +7
e = tds[2].find('">20')
title = tds[2][s:e]
#
s = tds[3].find('time">')+6
e = tds[3].find('')
date = tds[3][s:e]
data = [code,name,href,title,date]
return(data)
def parse_table(fname,save=True):
f = open(fname,encoding='utf-8')
html = f.read()
f.close()
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
if save:
df.to_csv(f'{fname[0:-5]}.csv')
return(df)
f = open('000503.html', encoding='utf-8')
html = f.read()
f.close()
df = parse_table('000503.html')
df = df[~df['title'].str.contains('摘要|已取消', na=False)]
df.to_csv('000503.csv')
import requests
import csv
import webbrowser
import os
import pandas as pd
import time
import codecs
def download_pdf(href,code,year):
r = requests.get(href,allow_redirects=True )
fname = f'{code}_{year}.pdf'
f = open(fname,'wb')
f.write(r.content)
f.close()
#
r.close()
def download_pdfs(hrefs,codes,years):
for i in range (len(hrefs)):
href = hrefs[i]
year = years[i]
download_pdf(href,codes,year)
time.sleep(30)
return ()
folder_path = '000676pdf'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
df = pd.read_csv(r'C:\Users\apple\Desktop\数据获取代码\nianbao\网址csv\000676.csv',encoding='utf-8')
hrefs = df['href']
years=df['title'].str[:4]
download_pdfs(hrefs,'000676',years)
import pandas as pd
import os
import re
import fitz
from datetime import datetime
def get_subtxt(doc,bounds=('公司信息','三、信息披露及备置地点')):
#默认设置为首尾页码
start_pageno = 0
end_pageno =len(doc)-1
#
lb,ub = bounds
#lb=下界,ub=上界
#获取左界页码
for n in range(len(doc)):
page =doc[n]#页
txt = page.get_text()
if lb in txt:
start_pageno = n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
page =doc[n]#页
txt = page.get_text()
if ub in txt:
end_pageno = n
break
#获取小范围内字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page =doc[n]#页
txt += page.get_text()
return(txt)
def get_df(txt):
df = pd.DataFrame({'year':[filename[-8:-4]]})
address_pattern = r'公司网址\s*(.*?)\s*电子信箱'
address = re.findall(address_pattern,txt)[0].strip()
df['公司网址'] = address
email_pattern = r'电子信箱\s*(.*?)\s*二'
email = re.findall(email_pattern,txt)[0].strip()
df['电子信箱'] = email
office_address_pattern = r'办公地址\s*(.*?)\s*办公地址的邮政编码'
office_address = re.findall(office_address_pattern,txt)[0].strip()
df['办公地址'] = office_address
name_pattern = r'姓名\s*(.*?) .*'
name= re.findall(name_pattern,txt)[0].strip()
df['董事会秘书姓名'] = name
telephone_pattern = r'电话\s*(.*?) .*'
telephone= re.findall(telephone_pattern,txt)[0].strip()
df['董事会秘书电话'] = telephone
email2_pattern = r'传真\s*.*\s*电子信箱\s*(.*?) (.*?)\s*三'
email2= re.findall(email2_pattern,txt, re.DOTALL)[0]
email3=email2[0]
df['董事会秘书电子信箱'] = email3
return df
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2013.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df1=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2014.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df2=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2015.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df3=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2016.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df4=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2017.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df5=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2018.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df6=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2019.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df7=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2020.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df8=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2021.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df9=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\002174pdf\002174_2022.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df10=get_df(txt)
# 使用concat()将它们合并
result_df= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
# 将合并后的DataFrame保存到新的csv文件中
result_df.to_csv('002174公司信息.csv', index=False)

import pandas as pd
import os
import re
import fitz
from datetime import datetime
def get_subtxt(doc,bounds=('主要会计数据和财务指标','二、非经常性损益项目及金额')):#元组
#默认设置为首尾页码
start_pageno = 0
end_pageno =len(doc)-1
#
lb,ub = bounds
#lb=下界,ub=上界
#获取左界页码
for n in range(len(doc)):
page =doc[n]#页
txt = page.get_text()
if lb in txt:
start_pageno = n
break
#获取右界页码
for n in range(start_pageno,len(doc)):
page =doc[n]#页
txt = page.get_text()
if ub in txt:
end_pageno = n
break
#获取小范围内字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page =doc[n]#页
txt += page.get_text()
return(txt)
def get_df(txt):
df = pd.DataFrame({'year':[filename[-8:-4]]})
company_revenues_pattern = '营业收入(元)\D*?(\d{1,3}(?:,\d{3})*(?:\.\d+)?)'
company_revenues = re.findall(company_revenues_pattern,txt, re.DOTALL)[0]
df[filename[-15:-9]] = company_revenues
return df
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2013.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df1=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2014.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df2=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2015.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df3=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2016.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df4=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2017.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df5=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2018.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df6=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2019.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df7=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2020.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df8=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2021.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df9=get_df(txt)
filename=r'C:\Users\apple\Desktop\数据获取代码\nianbao\000503pdf\000503_2022.pdf'
doc = fitz.open(filename)
txt = get_subtxt(doc)
df10=get_df(txt)
# 使用concat()将它们合并
result_df1= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df2= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df3= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df4= pd.concat([df0,df1, df2, df3, df4, df5, df6, df7, df8, df9], ignore_index=True)
result_df5= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df6= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df7= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df8= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df9= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df10= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
revenues= pd.concat([result_df1,result_df2, result_df3, result_df4, result_df5, result_df6, result_df7, result_df8, result_df9,result_df10], axis=1)
revenues.to_csv('营业收入.csv', index=False)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 确保显示中文
plt.rcParams['axes.unicode_minus'] = False # 确保显示负数的参数设置
plt.rcParams['font.size'] = 60
df = pd.read_csv(r'C:\Users\apple\Desktop\数据获取代码\nianbao\src\nianbao\营业收入.csv',encoding='utf-8')
df = df.applymap(lambda x: float(x.replace(',', '')) if isinstance(x, str) else x)
company_revenues = [
df['000503'],
df['000606'],
df['000676'],
df['000835'],
df['002072'],
df['002095'],
df['002113'],
df['002131'],
df['002168'],
df['002174']
]
year = df['year']
plt.figure(figsize=(40, 20)) # 设置图形大小
for revenue in company_revenues:
plt.plot(year, revenue,linewidth=10) # 绘制折线图
plt.title(f'互联网和相关服务行业十个公司近十年营业收入折线图') # 设置标题
plt.legend(['国新健康', 'ST顺利', '智度股份', '*ST长动', '*ST凯瑞', '生意宝', 'ST天润', '利欧股份', '惠程科技', '游族网络']) # 设置图例
plt.xlabel('年份') # 设置x轴标签
plt.ylabel('营业收入') # 设置y轴标签
plt.show() # 显示图形
def get_df(txt):
df = pd.DataFrame({'year':[filename[-8:-4]]})
company_revenues_pattern = '归属于上市公司股东的净利\s*润(元)\D*?(-?\d{1,3}(?:,\d{3})*(?:\.\d+)?)'
company_revenues = re.findall(company_revenues_pattern,txt, re.DOTALL)[0]
df[filename[-15:-9]] = company_revenues
return df
result_df1= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df2= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df3= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df4= pd.concat([df0,df1, df2, df3, df4, df5, df6, df7, df8, df9], ignore_index=True)
result_df5= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df6= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df7= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df8= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df9= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
result_df10= pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9,df10], ignore_index=True)
revenues= pd.concat([result_df1,result_df2, result_df3, result_df4, result_df5, result_df6, result_df7, result_df8, result_df9,result_df10], axis=1)
revenues.to_csv('净利润.csv', index=False)
plt.rcParams['font.size'] = 50
df = pd.read_csv(r'C:\Users\apple\Desktop\数据获取代码\nianbao\src\nianbao\净利润.csv',encoding='utf-8')
df = df.applymap(lambda x: float(x.replace(',', '')) if isinstance(x, str) else x)
company_net_profits = [
df['000503'],
df['000606'],
df['000676'],
df['000835'],
df['002072'],
df['002095'],
df['002113'],
df['002131'],
df['002168'],
df['002174']
]
year = df['year']
plt.figure(figsize=(40, 20)) # 设置图形大小
for net_profits in company_net_profits:
plt.plot(year, net_profits,linewidth=10) # 绘制折线图
plt.title(f'互联网和相关服务行业十个公司近十年归属于上市公司股东的净利润折线图') # 设置标题
plt.legend(['国新健康', 'ST顺利', '智度股份', '*ST长动', '*ST凯瑞', '生意宝', 'ST天润', '利欧股份', '惠程科技', '游族网络'],bbox_to_anchor=(0, 0), loc=3, borderaxespad=0) # 设置图例
plt.xlabel('年份') # 设置x轴标签
plt.ylabel('归属于上市公司股东的净利润') # 设置y轴标签
plt.show() # 显示图形
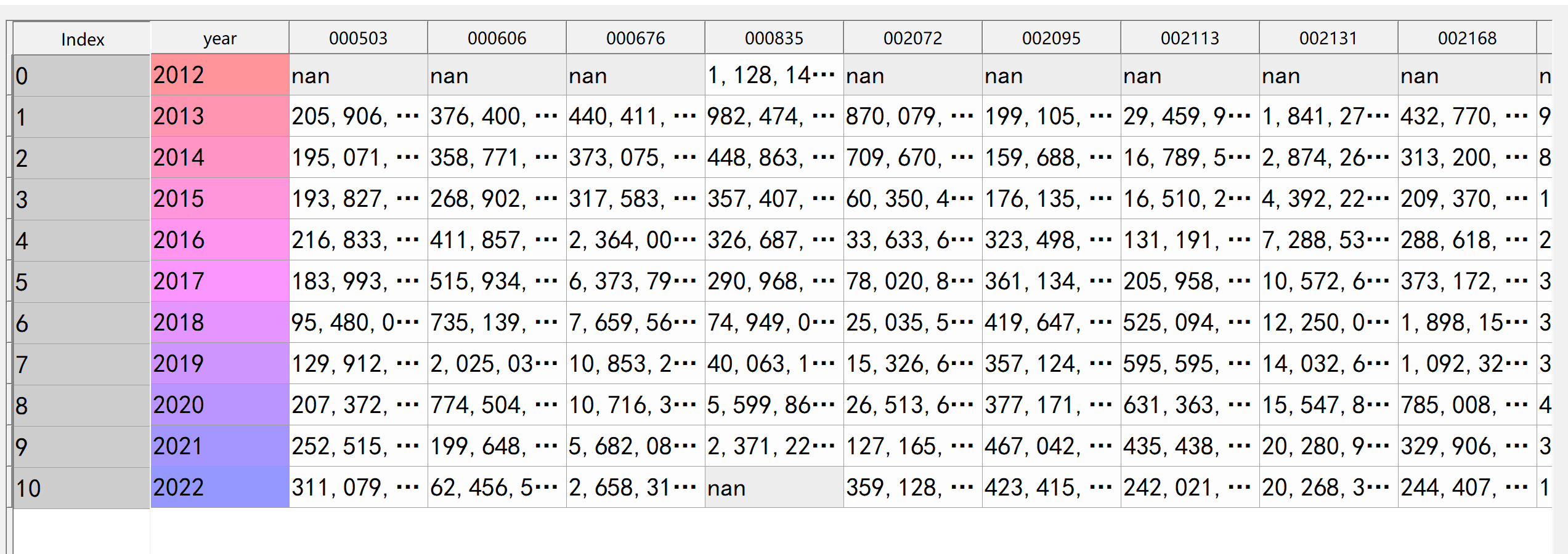
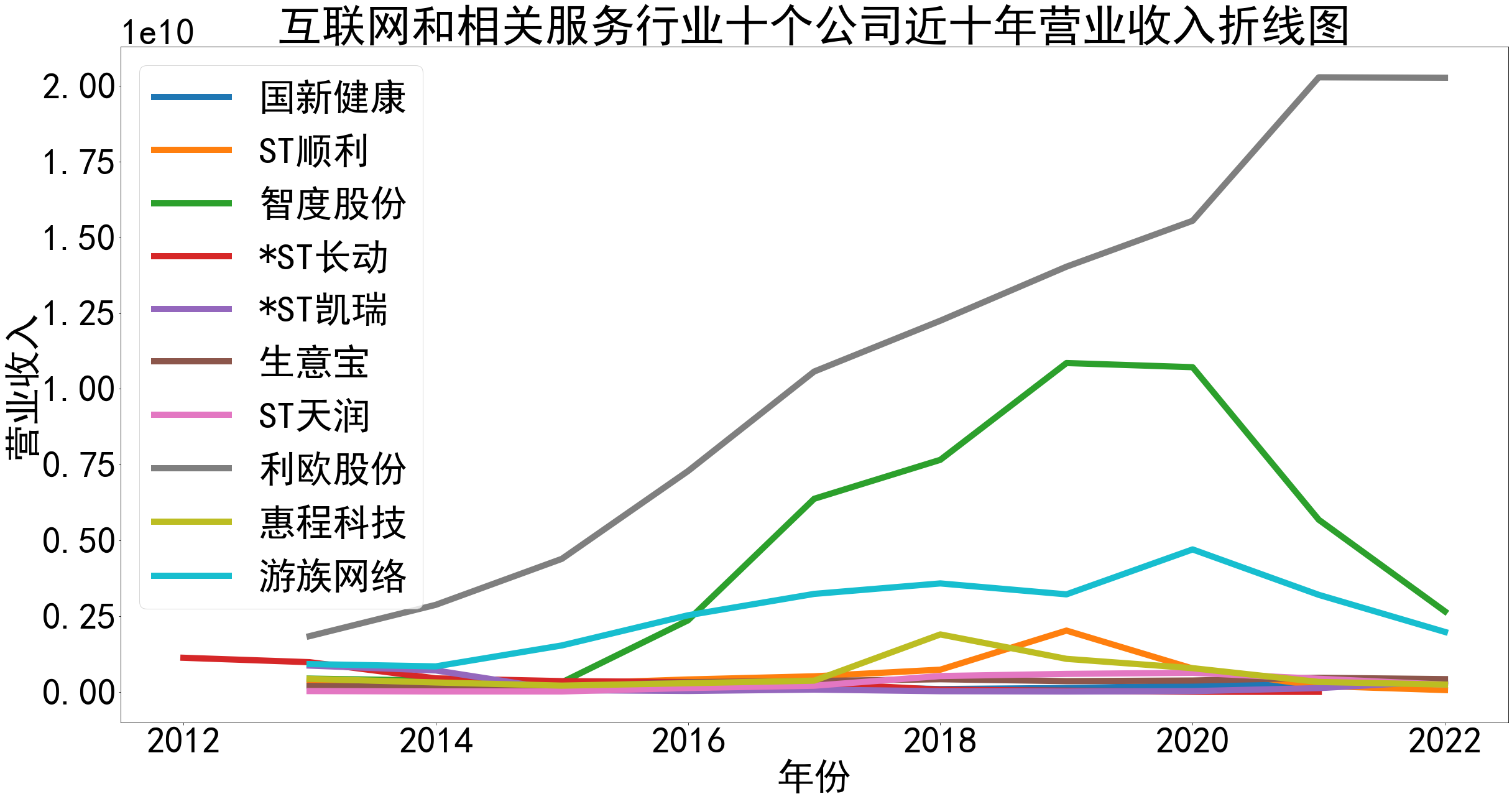

本次实验报告我的行业是互联网和相关服务,通过此次对数据的获取与处理,该行业多家上市公司的营业收入和归属于上市公司股东的净利润我有了较为初步的理解与认识。 从营业收入变化的角度来看,绘图结果可知,近十年利欧股份始终遥遥领先于其他公司,并且营业收入持续增长,最近两年营业收入增速变缓。2020年之前,智度股份、游族网络营业收入稳步增长,自2020年后急速下滑。 从归属于上市公司股东的净利润变化的角度来看,绘图结果可知,十家上市公司前几年基本保持正向营收,企业发展态势良好;但在2018年,利欧股份基本每股收益大幅下跌,但其于2020年又大幅上升。自2020年以来,受疫情冲击,大部分公司收益跌到负值,其中智度股份下跌最多。 总体来看,该行业近十年行业环境存在较大波动,但于现在基本都趋于平稳。
这次的实验报告对于我来说是一个很大的挑战,大一和大二上的python相关课程都让我感到十分痛苦,没有从中得到乐趣。这学期的课程中,我发现一个可以帮助我修改代码的软件,运行中报错的问题都基本通过它来解决,这大大增强了我的信心,并帮助我完成这次实验报告。从中也让我深深意识到自己在Python的学习中还有很多基础不扎实的地方,在将来我会继续学习并运用Python到学习和工作中去。感谢吴老师的教导,本学期教了我们很多实用的知识,年报自动下载真的很神奇,让我接触到了新的领域。