import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import re
import pdfplumber
import fitz
sse=['600037','600050','600637','600831','600936','600959','600996','601698','601728','601929']
def get_table_sse(code,fname='url_table.html'):
browser=webdriver.Chrome()
url=("http://www.sse.com.cn/disclosure/listedinfo/regular/")
browser.get(url)
time.sleep(3)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)#
#browser.find_element(By.CSS_SELECTOR, ".bi-search").click()
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(3)
#
selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
#
element = browser.find_element(By.CSS_SELECTOR, selector)
table_html = element.get_attribute('innerHTML')
#
fname=f'{code}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
def get_table_sse_codes(codes):
for code in codes:
get_table_sse(code)
#get_table_sse_codes(sse)
def get_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
def parse_table(table_html):
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
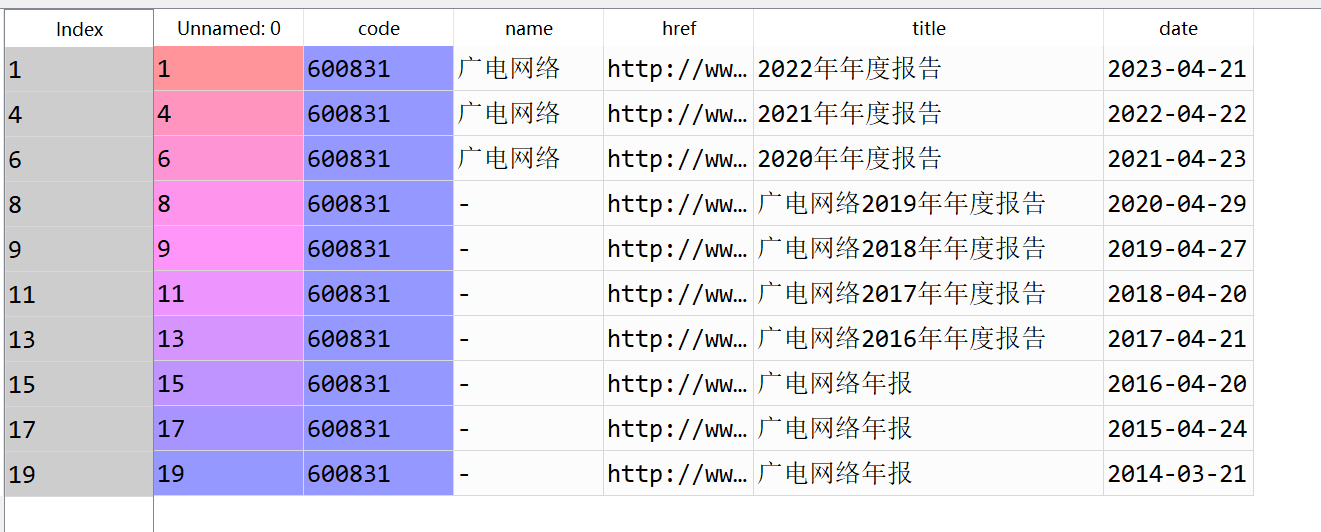
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
for i in sse:
f = open('{}.html'.format(i), encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
# df.to_csv('公告链接.csv')
df.to_csv('{}.csv'.format(i))
for i, file_name in enumerate(sse):
var_name = f"df_{i}"
exec(f"{var_name} = pd.read_csv('{file_name}.csv')")
import datetime
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
#ls.append([word in fa for f in df.f_name])
ls.append([word in f for f in df['title']])
else:
#ls.append([word not in f for f in df.f_name])
ls.append([word not in f for f in df['title']])
index=[]
for r in range(len(df)):
flag=not include
for c in range(len(words)):
if include:
flag=flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2=df[index]
return(df2)
def filter_date(start,end,df):
date=df['date']
v=[d>=start and d<= end for d in date]
df_new=df[v]
return(df_new)
def start_end_10y():
dt_now=datetime.datetime.now()
current_year=dt_now.year
start=f'{current_year-9}-01-01'
end=f'{current_year}-12-31'
return ((start,end))
def filter_nb_10y(df,keep_words,exclude_words,start=''):
if start =='':
start ,end = start_end_10y()
else:
start_y = int(start[0:4])
end=f'{start_y+9}-12-31'
#
df=filter_links(keep_words, df,include=True)
df=filter_links(exclude_words, df,include=False)
df=filter_date(start,end,df)
return(df)
words=['摘要','专项','鉴证','意见','督导','评估']
keep_words=['']
for i in range(0, 10):
var_name = f"df_{i}"
exec(f"{var_name} = filter_nb_10y({var_name}, keep_words, words)")
import requests
import time
def download_pdf(href, code, year):
r=requests.get(href, allow_redirects=True)
code_str = str(code).replace('\n', '').replace('/', '').replace('\\', '').replace(' ', '-')
fname=f'{code_str}-{year}.pdf'
with open(fname, 'wb') as f:
f.write(r.content)
def download_pdfs(df):
for name, group in df.groupby('code'):
hrefs = group['href']
years = pd.DatetimeIndex(group['date']).year
codes = group['code']
for i in range(len(hrefs)):
href = hrefs.iloc[i]
code = codes.iloc[i]
year = years[i]
try:
download_pdf(href, code, year)
time.sleep(30)
except Exception as e:
print(f"Error occurred when downloading {code}-{year}.pdf: {e}")
# 将 10 个 DataFrame 存储在列表中
df_list = [df_0, df_1, df_2, df_3, df_4, df_5, df_6, df_7, df_8, df_9]
#for i in range(len(df_list)):
#download_pdfs(df_list[i])
def get_subtxt(doc, bounds=('主要会计数据和财务指标','总资产')):
#默认设置为首尾页码
short_pageno = 0
end_pageno = len(doc) - 1
#
lb, ub = bounds #lb:lower bound(下界); ub: upper bound(上界)
# 获取左界页码
for n in range(len(doc)):
page = doc[n]; txt = page.get_text()
if lb in txt:
start_pageno = n; break
#获取右界页码
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n; break
#获取小范围字符串
txt = ''
for n in range(start_pageno,end_pageno+1):
page = doc[n]
txt += page.get_text()
return(txt)
def get_th_span(txt):
nianfen = '(20\d\d|199\d)\s*年末?' #199\d
s = f'{nianfen}\s*{nianfen}.*?{nianfen}'
p = re.compile(s,re.DOTALL)
matchobj = p.search(txt)
#
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
#
while (not flag):
matchobj = p.search(txt[end:])
end = matchobj.end()
year1 = matchobj.group(1)
year2 = matchobj.group(2)
year3 = matchobj.group(3)
flag = (int(year1) - int(year2) == 1)
flag = flag and (int(year2) - int(year3) == 1)
#
return(matchobj.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])
th_span_2nd = (end + th_span_2nd[0], end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0]-1
#
while (txt[e] not in '0123456789'):
e = e-1
return(s,e+1)
def get_keywords(txt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(txt)
keywords.insert(0,'营业收入')
return(keywords)
def parse_key_fin_data(subtext, keywords):
# kwds = ['营业收入','营业成本','毛利','归属于上市','归属于上市','经营活动']
ss = []
s = 0
for kw in keywords:
n = subtext.find(kw,s)
ss.append(n)
s = n + len(kw)
ss.append(len(subtext))
data = []
#
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
# 获取可能换行的账户名称
matchobj = p.search(line)
account_name = p2.sub('',matchobj.group())
#获取三年数据
amnts = line[matchobj.end():].split()
#加上账户名称
amnts.insert(0, account_name)
#追加到总数据
data.append(amnts)
return(data)
def get_csv(doc,bounds=('联系人和联系方式','四、 信息披露及备置地点')):
start_pageno = 0
end_pageno = len(doc) - 1
lb,ub=bounds
for n in range(len(doc)):
page = doc[n]
txt = page.get_text()
if lb in txt:
start_pageno = n; break
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n+1; break
txt1 = ''
for n in range(start_pageno,end_pageno):
page = doc[n]
txt1 += page.get_text()
return(txt1)
#提取基本信息CSV
import numpy as np
import os
na=[np.nan]*len(sse)
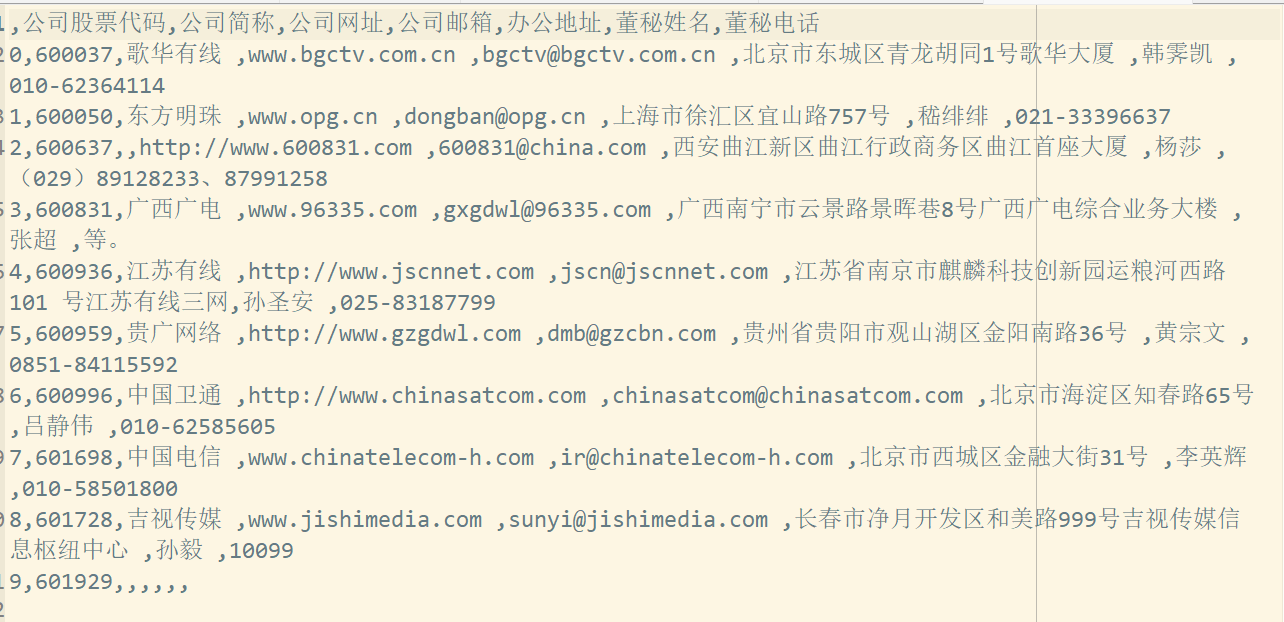
csv2=pd.DataFrame(data={'公司股票代码':sse,
'公司简称':na,
'公司网址':na,
'公司邮箱':na,
'办公地址':na,
'董秘姓名':na,
'董秘电话':na})
col=csv2.columns
p_list=['公司的中文简称.*?\n(.*?)\n',
'公司网址.*?\n(.*?)\n',
'电子信箱.*?电子信箱.*?\n(.*?)\n',
'公司办公地址.*?\n(.*?)\n',
'姓名.*?\n(.*?)\n',
'电话.*?\n(.*?)\n']
file_list=os.listdir()
file_list=[i for i in file_list if i.endswith('.pdf') and '2023' in i]
for n in range(len(file_list)):
# n=4
filename = file_list[n]
doc = fitz.open(filename)
csv1=get_csv(doc)
i=1
for p in p_list:
try:
p1 = re.compile(p,re.DOTALL)
# p1 = re.compile(p_list[0],re.DOTALL)
IR = p1.findall(csv1)[0]
# IR
csv2.loc[n,col[i]]=IR
# csv2.loc[4,col[1]]='利柏特'
i+=1
except:
i+=1
csv2.to_csv('公司基本信息.csv')
def get_rev(doc,bounds=('主要会计数据和财务指标','主要财务指标')):
start_pageno = 0
end_pageno = len(doc) - 1
lb,ub=bounds
for n in range(len(doc)):
page = doc[n]
txt = page.get_text()
if lb in txt:
start_pageno = n; break
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n+1; break
txt1 = ''
for n in range(start_pageno,end_pageno):
page = doc[n]
txt1 += page.get_text()
return(txt1)
def get_netp(doc,bounds=('利润分配情况','销售退回')):
start_pageno = 0
end_pageno = len(doc) - 1
lb,ub=bounds
for n in range(len(doc)):
page = doc[n]
txt = page.get_text()
if lb in txt:
start_pageno = n; break
for n in range(start_pageno,len(doc)):
if ub in doc[n].get_text():
end_pageno = n+1; break
txt1 = ''
for n in range(start_pageno,end_pageno):
page = doc[n]
txt1 += page.get_text()
return(txt1)
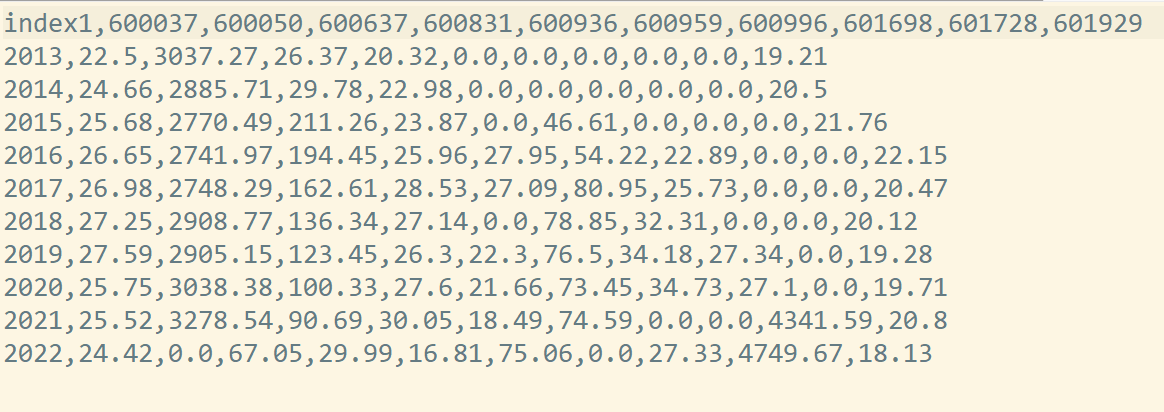
csv_rev=pd.DataFrame(data={'公司股票代码':sse})
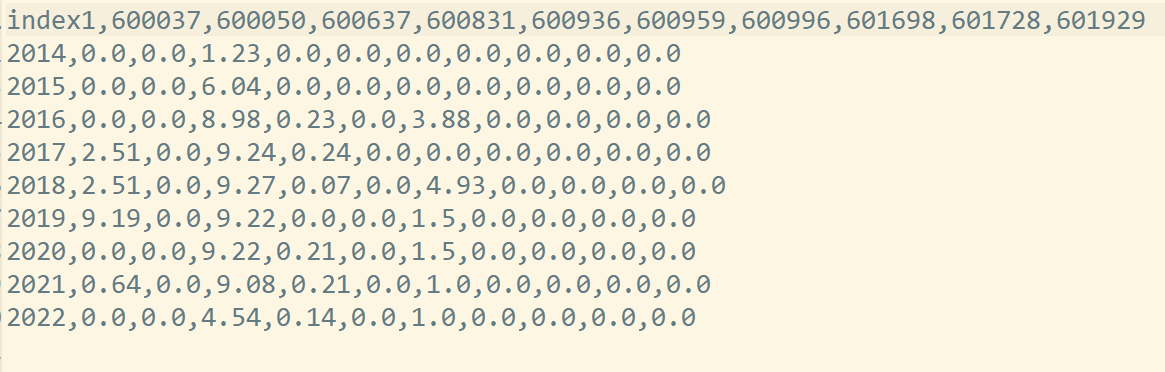
csv_netp=pd.DataFrame(data={'公司股票代码':sse})
d_list=['营业收入.*?\n(.*?)\s',
'拟分配的利润或股利.*?\n(.*?)\s']
for n in range(len(sse)):
# n=0
file_list=os.listdir()
file_list=[i for i in file_list if i.endswith('.pdf') and sse[n] in i]
for f in range(len(file_list)):
# f=0
try:
doc = fitz.open(file_list[f])
txt11=get_rev(doc)
p1 = re.compile(d_list[0],re.DOTALL)
r = p1.findall(txt11)[0]
r=r.replace(',','')
r=round(float(r)/(10**8),2)
csv_rev.loc[n,file_list[f][7:11]]=r
except:
pass
try:
txt12=get_netp(doc)
p2 = re.compile(d_list[1],re.DOTALL)
netp = p2.findall(txt12)[0]
netp=netp.replace(',','')
netp=round(float(netp)/(10**8),2)
csv_netp.loc[n,file_list[f][7:11]]=netp
except:
pass
csv_rev=csv_rev.set_index(['公司股票代码'])
csv_rev=csv_rev.T
csv_rev = csv_rev.sort_index(ascending=True)
csv_netp=csv_netp.set_index(['公司股票代码'])
csv_netp=csv_netp.T
csv_netp = csv_netp.sort_index(ascending=True)
csv_rev=csv_rev.fillna(0)
csv_netp=csv_netp.fillna(0)
index1=[ int(i)-1 for i in csv_rev.index]
csv_rev['index1']=index1
csv_rev=csv_rev.set_index(['index1'])
index2=[ int(i)-1 for i in csv_netp.index]
csv_netp['index1']=index2
csv_netp=csv_netp.set_index(['index1'])
csv_rev.to_csv('revenue.csv')
csv_netp.to_csv('profit.csv')
import pandas as pd
import numpy as np
from matplotlib import pyplot
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
dt = pd.read_csv('C:/Users/junyi/Desktop/homeworks/revenue.csv', index_col=0)
fig,ax = plt.subplots(figsize = (14,8), dpi = 300)
index = np.arange(len(dt))
plt.bar(index,dt['600037'],width=0.05)
plt.bar(index+0.08,dt['600050'],width=0.08)
plt.bar(index+0.16,dt['600637'],width=0.08)
plt.bar(index+0.24,dt['600831'],width=0.08)
plt.bar(index+0.32,dt['600936'],width=0.08)
plt.bar(index+0.40,dt['600959'],width=0.08)
plt.bar(index+0.48,dt['600996'],width=0.08)
plt.bar(index+0.56,dt['601698'],width=0.08)
plt.bar(index+0.64,dt['601728'],width=0.08)
plt.bar(index+0.72,dt['601929'],width=0.08)
plt.legend(['600037','600050','600637','600831','600936','600959','600996','601698','601728','601929'])
plt.title('十年十家公司营业收入对比')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.xticks(index+0.3,dt.index)
dt = pd.read_csv('C:/Users/junyi/Desktop/homeworks/profit.csv' , index_col=0, encoding='GB2312')
fig,ax = plt.subplots(figsize = (14,8), dpi = 300)
index = np.arange(len(dt))
plt.bar(index,dt['600037'],width=0.05)
plt.bar(index+0.08,dt['600050'],width=0.08)
plt.bar(index+0.16,dt['600637'],width=0.08)
plt.bar(index+0.24,dt['600831'],width=0.08)
plt.bar(index+0.32,dt['600936'],width=0.08)
plt.bar(index+0.40,dt['600959'],width=0.08)
plt.bar(index+0.48,dt['600996'],width=0.08)
plt.bar(index+0.56,dt['601698'],width=0.08)
plt.bar(index+0.64,dt['601728'],width=0.08)
plt.bar(index+0.72,dt['601929'],width=0.08)
plt.legend(['600037','600050','600637','600831','600936','600959','600996','601698','601728','601929'])
plt.title('十年十家公司利润分配对比')
plt.xlabel('年份')
plt.ylabel('归属于上市公司股东利润(元)')
plt.xticks(index+0.3,dt.index)
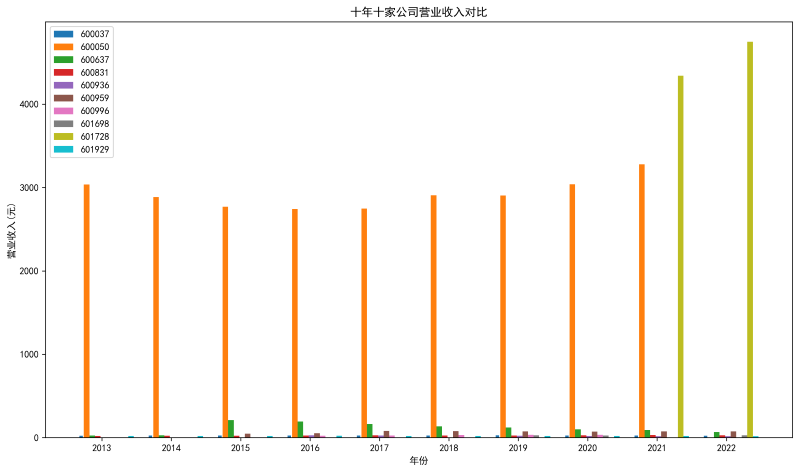
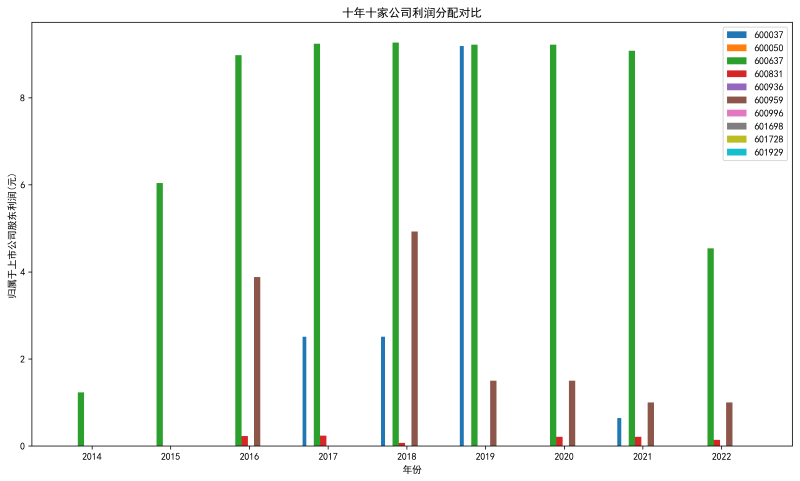
首先,本次实验我的实验行业是电信、广播、电视和卫星传输服务,然后选取了其中的10家上市公司进行年报分析。 从营业收入变化的角度来看,绘图结果可知,前八年600050(中国联通)的营业收入是最多的,近两年601728(中国电信)的营业收入最多。 从归属于上市公司股东的净利润变化的角度来看,绘图结果可知,600637(东方明珠)的股东利润分配是最多的。
这次的实验很难,非常感谢好朋友的帮助。