STEP2:获取可用年报列表
STEP3:获取年报下载链接
STEP4:下载年报
STEP5:获取年报信息,做成csv文件
STEP6:公司信息可视化

STEP1:获取股票及其代码列表
import fitz
import pandas as pd
import pdfplumber
import numpy as np
pdf = pdfplumber.open(r"D:\QQ材料\行业分类.pdf")
page = pdf.pages[74]
table = page.extract_table()
df = pd.DataFrame(table)
df.to_excel(r"D:\QQ材料\行业分类.excel", \
header=False, index=False)
df_c0=pd.read_excel(r'D:\QQ材料\行业分类.xlsx',\
header=0,index_col=None,converters={'上市公司代码':str})
num=df_c0.loc[df_c0['行业大类代码']==45].index.values[0]
num1=df_c0.loc[df_c0['行业大类代码']==46].index.values[0]
df_c=df_c0.loc[num:num1-1] #保留鄙人将要使用行业
df_c=df_c[df_c['上市公司代码']>='600000']#保留可用的6开头的行业代码
df_c=df_c.iloc[:10] #取前十代码
list=df_c['上市公司代码'] #保留代码
list1=df_c['上市公司简称'] #公司名称
list2=list+' '+list1
np.array(list2)
结果展示
需要分析的上市公司,保存为html文件
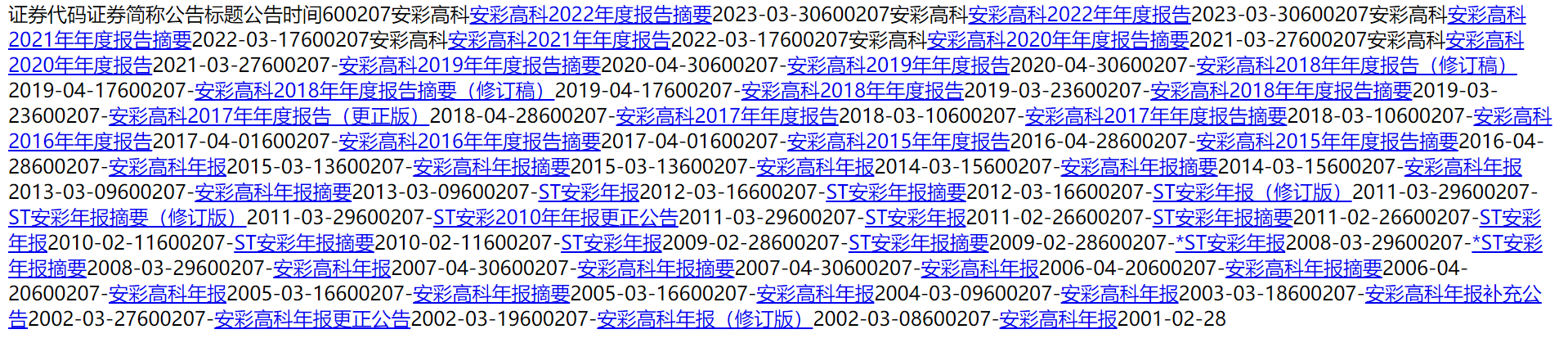
STEP2:获取可用年报列表
def get_table_sse(code,filename):
browser = webdriver.Chrome()
browser.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
time.sleep(5)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(5)
selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div >div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, selector)
table_html = element.get_attribute('innerHTML')
element0 = browser.find_elements(By.LINK_TEXT, "下一页")
if element0 != []:
browser.find_element(By.LINK_TEXT, "下一页").click()
element1 = browser.find_element(By.CSS_SELECTOR, selector)
table_html1 = element1.get_attribute('innerHTML')
table_html1 = table_html1.strip('<thead><tr><th>证券代码</th><th>证券简称
</th><th>\公告标题</th><th>公告时间</th></tr></thead><tbody><tr><td')
table_html1 ='</span></a></td><td '+table_html1
else:
table_html1=''
fname=f'{filename}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html+table_html1)
f.close()
#
browser.quit()
for (i,j) in zip(list,list1):
get_table_sse(i,i+' '+j)
结果展示
html文件实例如下,共有10个,此处示例一个
STEP3:获取年报下载链接,保存为csv文件
###########获取年报下载链接
def get_data(tr):
p_td = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
# data = get_data(trs_new[1])
def parse_table(table_html):
p = re.compile('<tr>(.+?)</tr>', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
for i in list2:
f = open('{}.html'.format(i), encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
df0=df.set_index('date')
df0=df0[:'2014-00-00']
list_1=[]
df0=df0.reset_index()
for j in range(len(df0)):
if '摘要' in df0['title'][j] or '修订稿' in df0['title'][j] or '更正版' in df0['title'][j] or '修订版' in df0['title'][j]:
list_1.append(j)
if '年度报告' not in df0['title'][j] and '年报' not in df0['title'][j]:
list_1.append(j)
df0.drop(df0.index[list_1],inplace=True)
if i == '600635 大众公用':
df0.drop(1,inplace=True)
df0 = df0.reset_index(drop=True)
df0.to_csv('{}.csv'.format(i))
结果展示
csv文件实例如下,共有10个,此处示例一个
STEP4:下载年报
##########下载年报
for name in list2:
data0= pd.read_csv('{}.csv'.format(name), index_col=0, parse_dates=True)
j=0
for i in data0['href']:
href = i
r = requests.get(href, allow_redirects=True)
f = open('{}{}.pdf'.format(name,data0['date'][j][:4]), 'wb')
j=j+1
f.write(r.content)
f.close()
结果展示
下载的年报,共87个
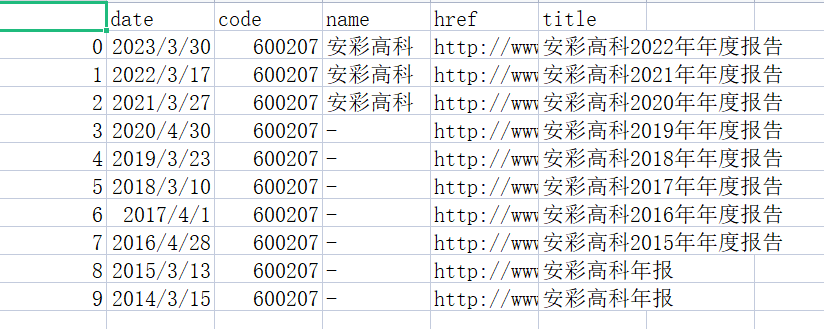
STEP5:获取年报信息,做成csv文件
import pandas as pd
import fitz
import pandas as pd
def parse_key_fin_data(subtext):
keywords = ['营业收入','股东的净利润']
ss = []
for kw0 in keywords:
if len(kw0) == 4:
txt = subtext
x = re.search("(营)[' ','\n','业','收']*(入)", txt)
kw0=x.group()
else:
txt = subtext
x = re.search("(股)[' ','\n','东','的','净','利']*(润)", txt)
kw0=x.group()
n = subtext.find(kw0,0)
ss.append(n)
s = n + len(kw0)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return (data)
dff = pd.DataFrame()
list=list2.tolist()
for name in list:
data0= pd.read_csv('{}.csv'.format(name), index_col=0, parse_dates=True)
dfff = pd.DataFrame()
for j in range(len(data0)):
doc = fitz.open('{}{}.pdf'.format(name,data0['date'][j][:4]))
text = ''
for page in doc:
text += page.get_text()
s = text.find('主要会计数据 ')
subtext = text[s-50:]
e = subtext.find('总资产')
subtext = subtext[:e]
data = parse_key_fin_data(subtext)
al=0
for el in data[1][0:7]:
al1=0
for em in data[0][0:6]:
if el[0]<'a' and em[0]<'a':
df = pd.DataFrame({'指标':[d[0] for d in data],'{}'.format(int(data0['date']
[j][:4])-1):[float(data[0][al1].replace(',','')),float(data[1][al].replace(',',''))]
})
break
al1+=1
al+=1
if el[0]<'a' and em[0]<'a':
break
if '单位:元' in subtext:
df['{}'.format(int(data0['date'][j][:4])-1)] = round(df['{}'.format(int(data0['date'][j][:4])-1)]/10000,2)
df=df.set_index('指标').T
df.columns=['{}营业收入'.format(name),'{}股东的净利润'.format(name)]
dfff = pd.concat([dfff,df],axis=0)
dff= pd.concat([dfff,dff],axis=1)
dff.fillna(0,inplace=True)
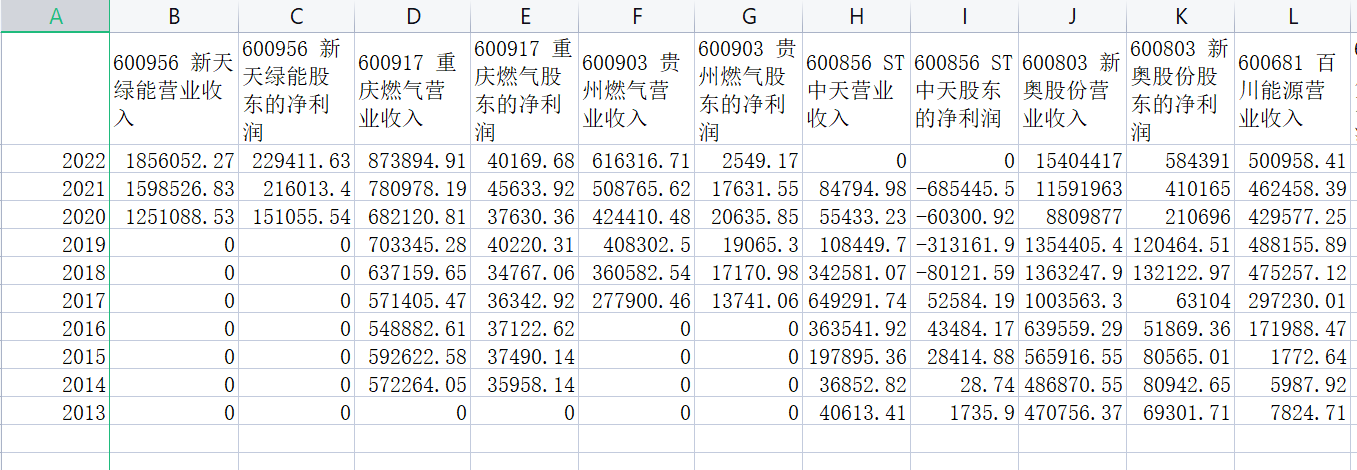
dff.to_csv('公司年报数据.csv')
结果展示
公司年报数据,csv展示
STEP6:公司信息可视化
##########画图
dff= pd.read_csv('公司年报数据.csv', index_col=0, parse_dates=True)
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['FangSong']
mpl.rcParams['axes.unicode_minus']=False
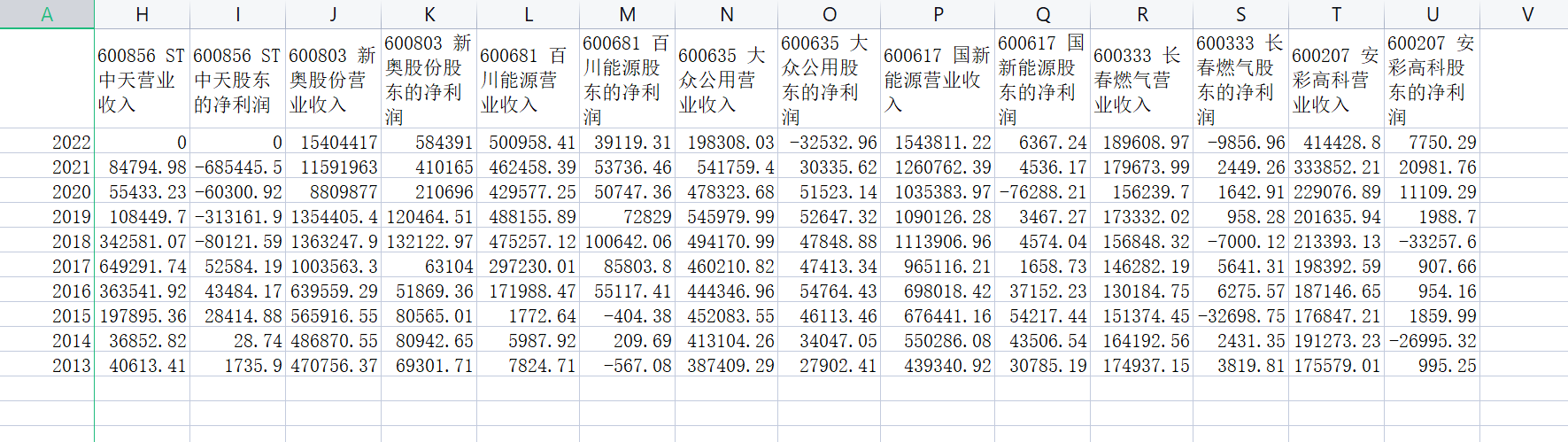
dff1=dff.iloc[:,::2].plot(figsize=(10, 6),title='营业收入 单位:万元')
dff2=dff.iloc[:,1::2].plot(figsize=(10, 6),title='营业收入 单位:万元')
结果展示
公司年报数据可视化,图片展示
结果截图
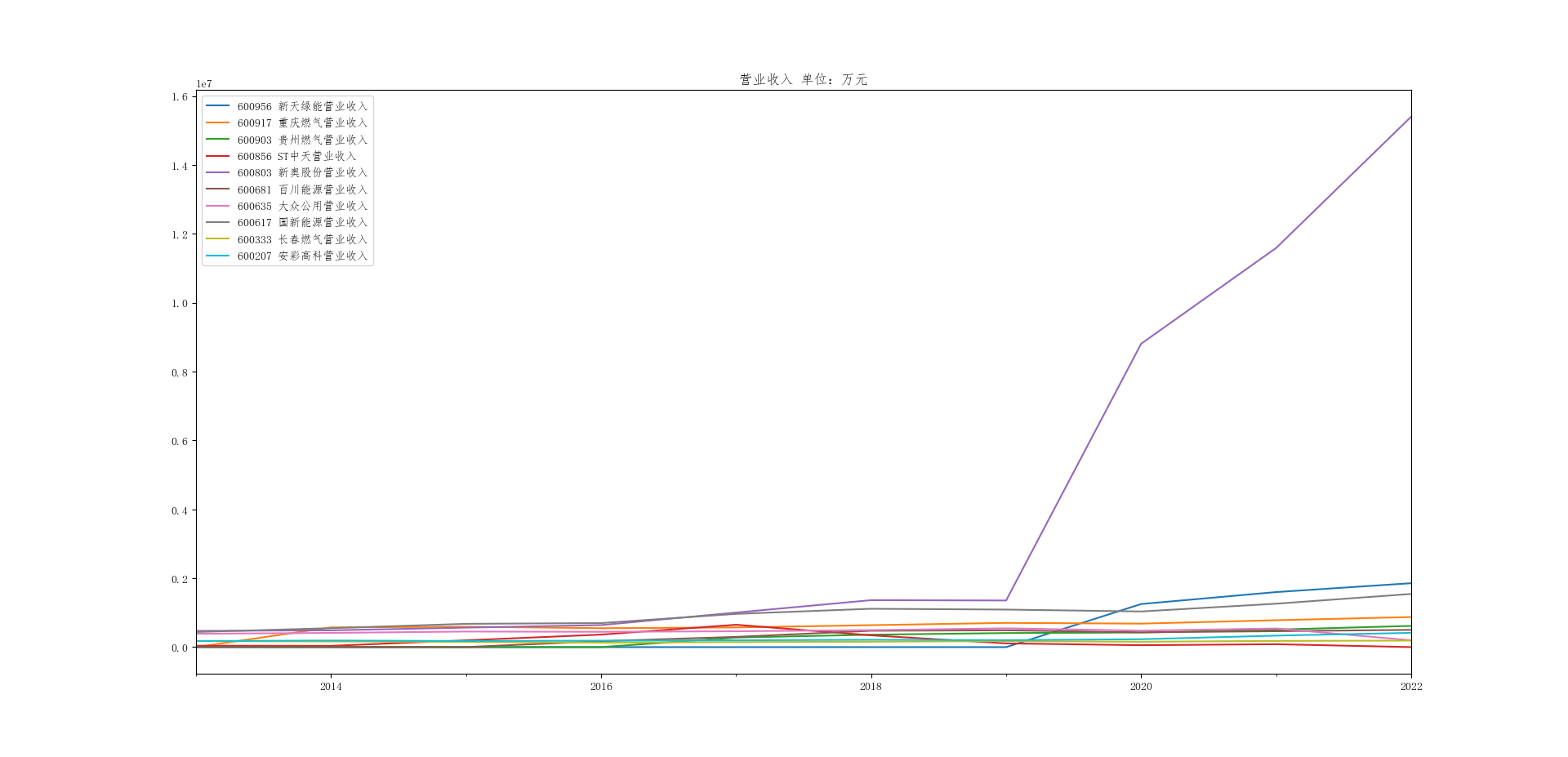
结果截图局部放大
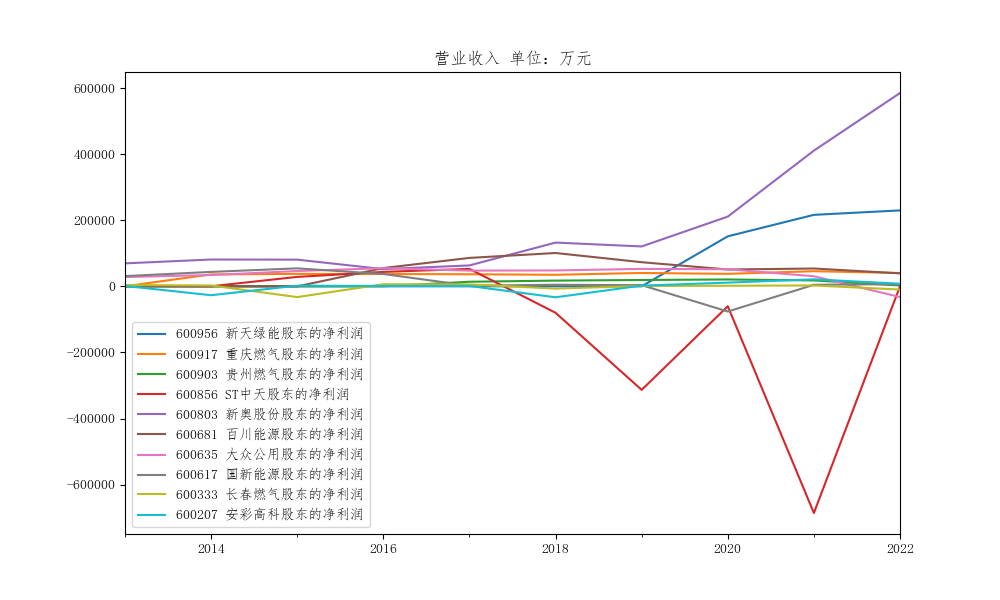
结果截图
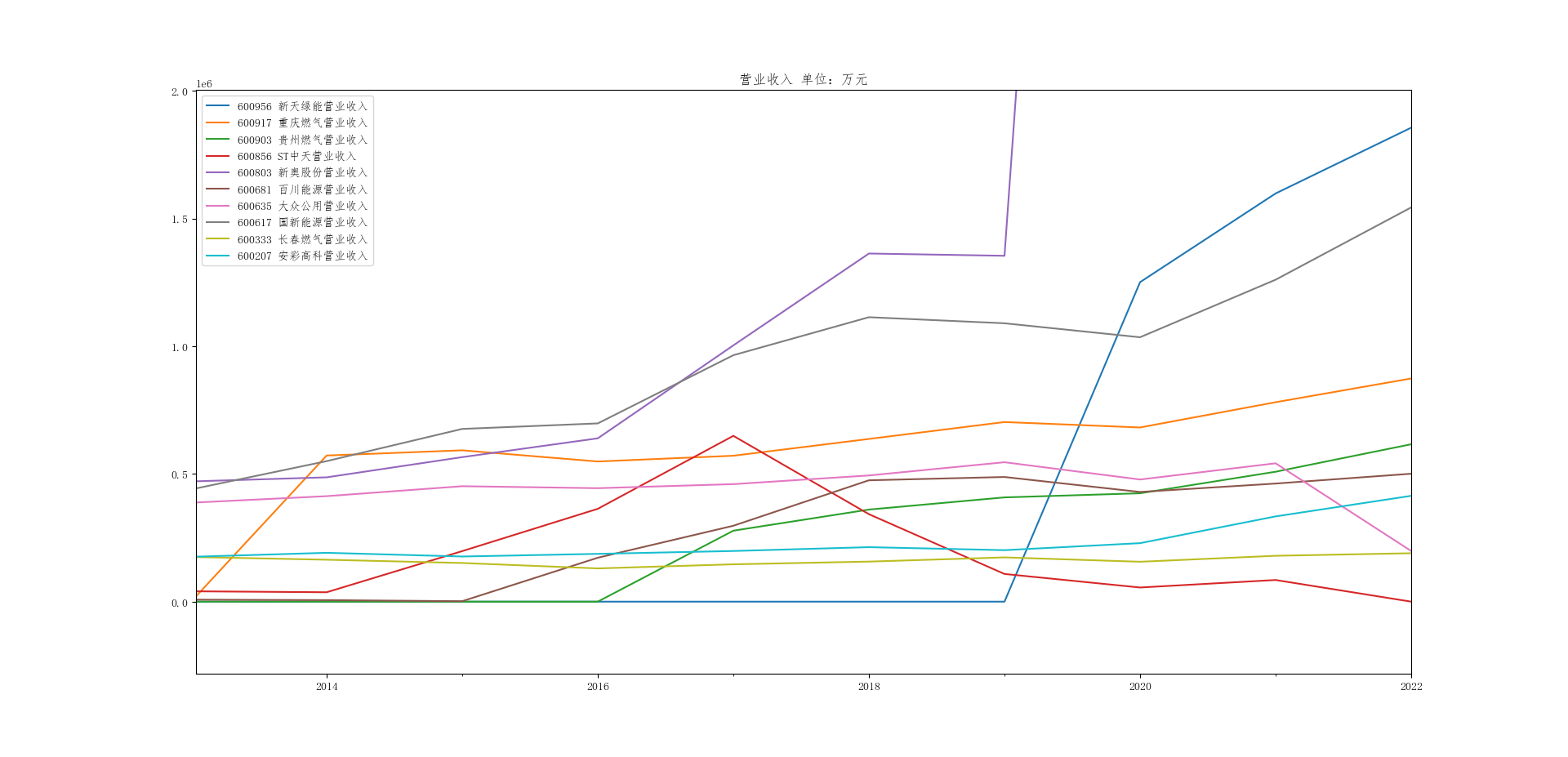
结果截图局部放大
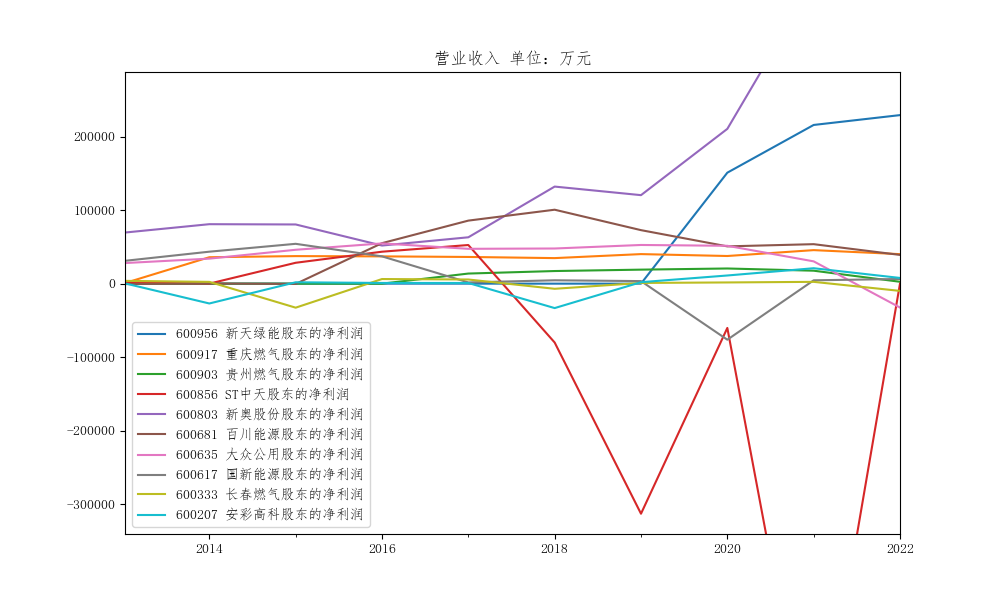
航空运输业解读与分析
- 分析
航空运输业在2013-2016年间稳定发展,发展较好。2017-2022年波动较大,个别企业飞速发展,如新奥,营业收入翻番,主要是因为在国民经济的快速发展背景下,改变能源结构、改善大气质量问题吸引了各界目光,燃气作为清洁能源代替人工煤气收到追捧,市场前景广阔,最近几年我国燃气的消费量处于上升状态,受环保需求的推动、供给侧改革、社会用电需求增长等导向和经济驱动的多重因素影响,我国城镇居民、工业及发电用燃气的需求保持着较高的增长速度,所以新奥收益增长较快。但个别企业业绩波动很大,如st中天,不稳定型资产较多,随着新技术的发展和不断涌现的新品牌,ST中天面临激烈的市场竞争,而且市场监管政策经常发生变化,可能还有疫情等影响,对ST中天产生不利影响。但总的来说,航空运输业还是稳重向好。