STEP2:获取分配行业的上交所股票的上市公司年报
STEP3:获取分配行业的深交所股票的上市公司年报
STEP4:绘制各股时间序列图
STEP5:分析与解读
STEP6:源码
STEP1:获取分配行业的上市公司
1.获取分配行业的上市公司
#(一)获取分配行业的上市公司
# 定义所需函数
def get_stock(data, stock_codes):
lst = [x for x in data for start_code in stock_codes if x[3].startswith(start_code)]
df = pd.DataFrame(lst, columns=data[0]).iloc[:, 1:]
return df
pdf = pdfplumber.open('行业分类.pdf')
table = pdf.pages[77].extract_table()
for i in range(len(table)):
if table[i][1] is None:
table[i][1] = table[i-1][1]
sz = get_stock(table, ['000', '200', '300', '00', '080'])
sh = get_stock(table, ['6', '900'])
df_sz = sz[sz['行业大类代码'] == '50']
df_sh = sh[sh['行业大类代码'] == '50']
SZ_Company = df_sz[['上市公司代码', '上市公司简称']]
SH_Company = df_sh[['上市公司代码', '上市公司简称']]
all_company = SZ_Company.append(SH_Company)
all_company.to_csv('company.csv', encoding='utf-8-sig')
分析
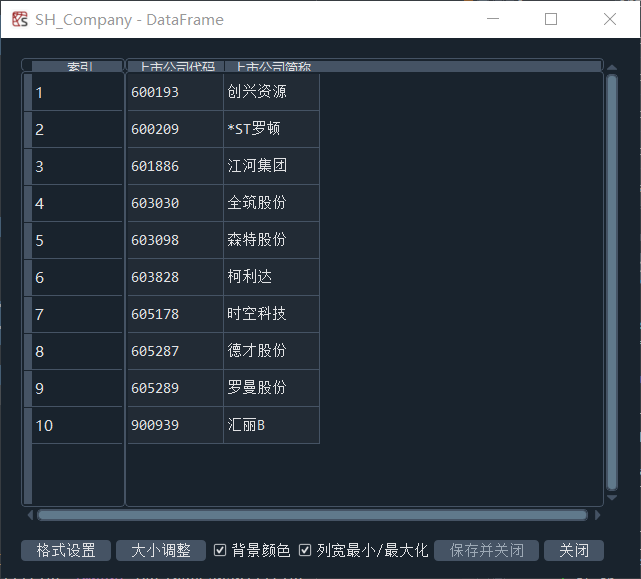
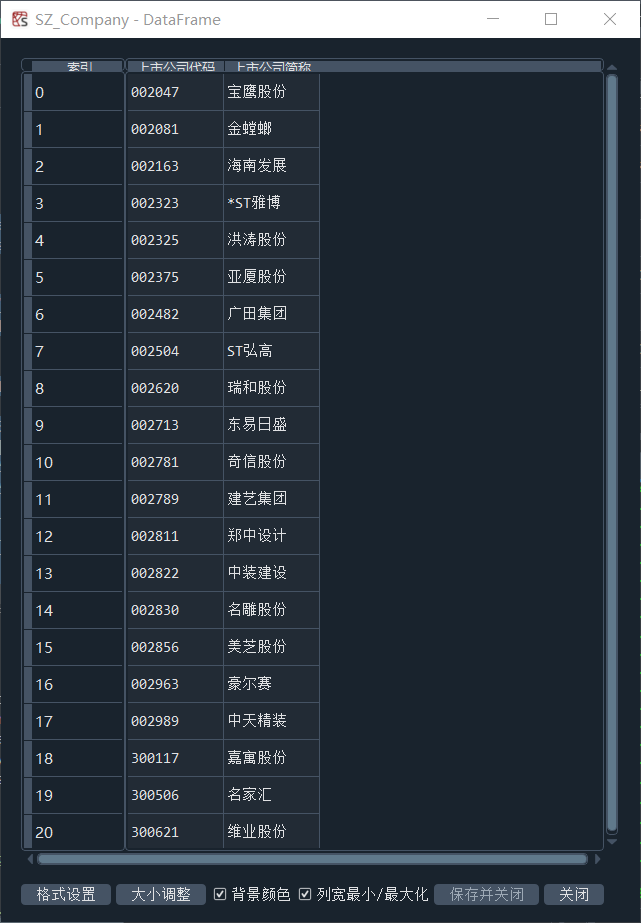
首先,定义了一个get_stock(data, stock_codes)函数,它接受两个参数,一个是表格数据,一个是股票代码的前缀列表。它将返回表格数据中符合股票代码前缀条件的所有行,并去掉第一列。然后,使用pdfplumber读取行业PDF,调用get_stock函数,得到深交所和上交所公司代码与简称,并储存在SZ_Company和SH_Company。基本信息如图1-1,1-2所示。
结果展示
图1-1 获取分配行业的上市公司
图1-2 上交所股票年报连接
STEP2:获取分配行业的上交所股票的上市公司年报
2.1获取上交所股票年报连接
# 2.1 获取上交所股票年报连接
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
def get_table_sse(code):
browser = webdriver.Chrome()
url = 'http://www.sse.com.cn/disclosure/listedinfo/regular/'
browser.get(url)
browser.set_window_size(1550, 830)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code) #"601910"
time.sleep(5)
# 用JavaScript来让下拉菜单可见
browser.execute_script("document.querySelector('.sse_outerItem:nth-child(4) .filter-option-inner-inner').style.display = 'block';")
# 点击下拉菜单,并选择年报选项
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(5)
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
save_folder = r'D:\python homework\nianbao\SH' # 指定保存文件的文件夹路径
fname = os.path.join(save_folder, f'{code}.html')
f = open(fname, 'w', encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
# 获取各股年报网页
for index, row in SH_Company.iterrows():
code = row['上市公司代码']
try:
get_table_sse(code)
except Exception as e:
print(f"Failed to get the table for {code}: {e}")
# 从总网页中获取每年年报的连接
def get_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
code = tds[0].split('>')[1].split('<')[0]
name = tds[1].split('>')[1].split('<')[0]
href = 'http://www.sse.com.cn' + tds[2][tds[2].find('href="') + 6:tds[2].find('.pdf"') + 4]
title = tds[2][tds[2].find('$(this))">') + 10:tds[2].find(' ')]
date = tds[3].strip()
return [code, name, href, title, date]
def parse_table(table_html):
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(table_html)
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
folder = r'D:\python homework\nianbao\SH'
files = os.listdir(folder)
save_folder = r'D:\python homework\nianbao\SH'
df_all = pd.DataFrame()
for file in files: # 遍历每个文件名
f = open(os.path.join(folder, file), encoding='utf-8') # 打开HTML文件并读取内容
html = f.read()
f.close()
df = parse_table(html) # 调用parse_table函数
df_all = df_all.append(df)
df_all.to_csv('all_data.csv')
# 去除不符合的报告
list_1= []
df_all = df_all.reset_index()
for j in range(len(df_all)):
if '摘要' in df_all['title'][j] or'督导年度报告' in df_all['title'][j] or '修订稿' in df_all['title'][j] or '更正版' in df_all['title'][j] or '修订版' in df_all['title'][j]:
list_1.append(j)
if '年度报告' not in df_all['title'][j] and '年报' not in df_all['title'][j]:
list_1.append(j)
df_all.drop(df_all.index[list_1],inplace=True)
分析
首先,导入selenium模块,用它模拟浏览器操作,从上交所网站获取上市公司的年报信息,并将其封装成函数get_table_sse(code)。接下来从保存的年报网页中提取每年年报的连接,定义函数get_data(tr),用于从表格行中提取股票代码、连接等信息。定义函数parse_table(table_html),用于解析年报表格的HTML代码,并返回一个包含提取信息的数据框(详细代码见源码2.1节)。遍历保存的年报网页文件,逐个读取HTML文件的内容。调用parse_table函数,解析HTML代码并返回为df_all,同时去除不符合条件的年报信息。结果如图2-1所示。
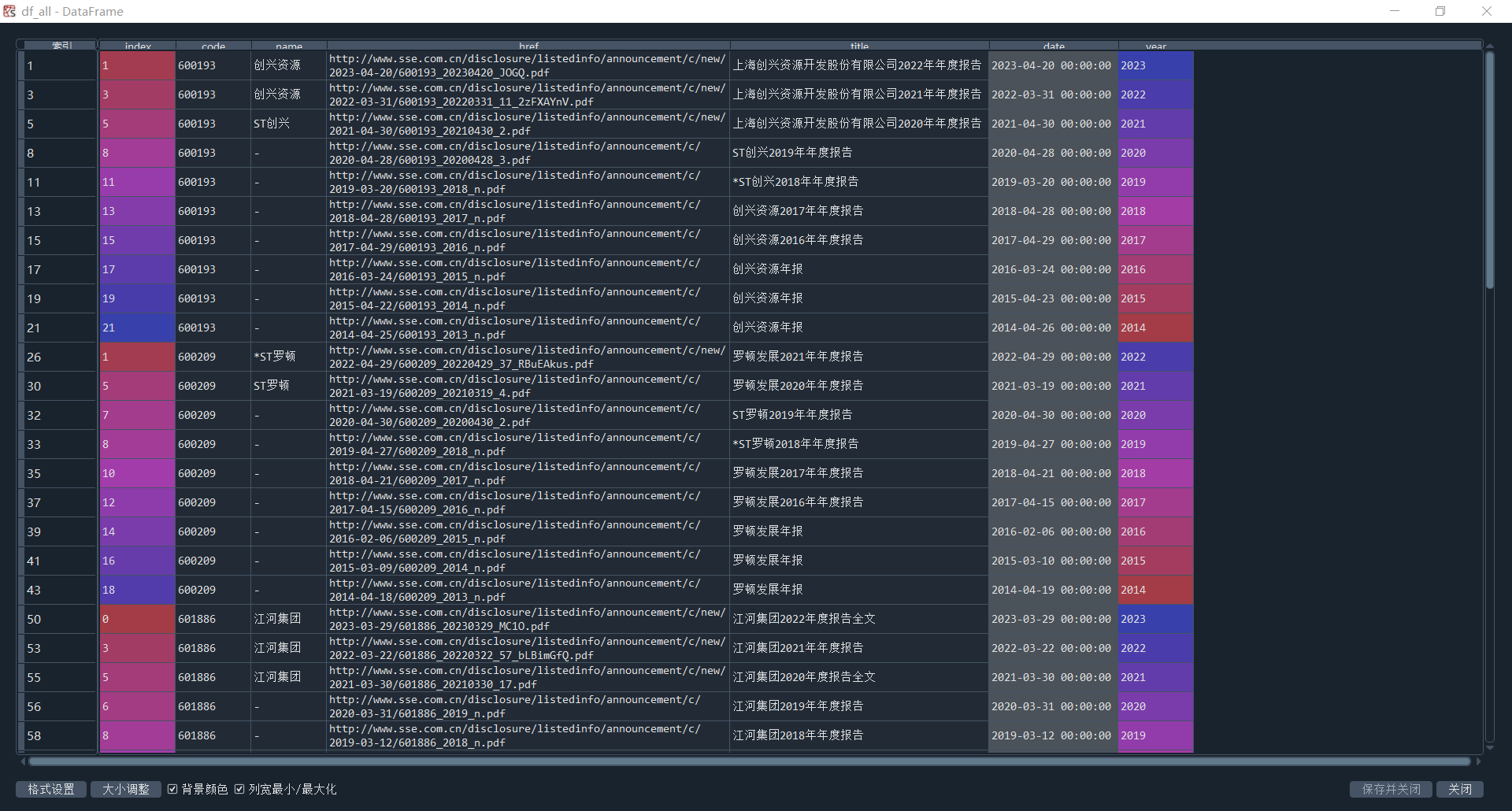
图2-1 上交所股票年报连接
2.2 下载各公司10年内年报
# 2.2 下载各公司10年内年报
df_all=df_all[(df_all['date'] > '2014-01-01')] # 筛选出2014年前的年报
df_all['date'] = pd.to_datetime(df_all['date']) # 将data列转换为日期格式
df_all['year'] = df_all['date'].dt.year # 获取年份
# 遍历每一行,获取股票代码、年份和PDF链接,并发送GET请求保存PDF文件到本地
for index, row in df_all.iterrows():
code = row['code']
year = row['year']-1
url = row['href'] # 获取股票代码、年份和PDF链接
response = requests.get(url) # 发送GET请求并保存PDF文件到指定的文件夹中
with open(os.path.join(save_folder, f'{code}_{year}.pdf'), 'wb') as f:
f.write(response.content)
分析
在这一步,遍历df_all的每一行,获取股票代码、年份和年报文件的链接。使用requests库发送GET请求获取年报文件的内容。使用打开文件的方式,将年报文件内容写入到本地指定的文件夹中,文件名格式为股票代码_年份.pdf(详细代码见源码2.2节)。结果如图2-2所示:
图2-2 上交所各公司年报PDF
2.3 提取上交所所属股票的公司信息
#2.3 提取公司信息
import fitz
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as ticker
from matplotlib.ticker import MaxNLocator
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
sns.set_style("whitegrid",{'font.sans-serif':['simhei','Arial']})
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf')
def extract_annual_report_data(folder_path):
df = pd.DataFrame(columns=['股票代码', '年份', '营业收入'])
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
# 提取股票代码和年份
code_year = filename.split("_")
if len(code_year) != 2:
continue # 文件名不符合要求,跳过当前文件
code, year = code_year
file_path = os.path.join(folder_path, filename)
doc = fitz.open(file_path)
whole_text = '' # 提取整个年报文本
for page in doc:
whole_text += page.get_text()
start_index = whole_text.find('主要会计数据') #起始位置
if start_index == -1:
continue
end_index = whole_text.find('总资产', start_index) #结束位置
text = whole_text[start_index:end_index]
# 提取营业收入和归属上市公司股东的净利润数据
keywords = ['营业收入','归属于上市公司股\n东的净利润','归属于上市公司股东\n的净利润'
,'归属于上市公司股东的\n净利润','归属于上市公司股东的净\n利润'
,'归属于上市公司股东的净利\n润','归属于上\n市公司股\n东的净利\n润'
,'归属于上市公\n司股东的净利\n润','归 属 于 上 市\n公 司 股 东 的\n净利润'
,'归属于上市公司\n股东的净利润','归属于上市\n公司股东的\n净利润'
,'归 属 于上 市公\n司 股 东的 净利\n润','归 属 于 上 市 公\n司 股 东 的 净 利\n润'
,'归 属 于 上 市公 司\n股东的净利润','归属于上市公司股东的净'
,'归属于上市公司普通股股东的净\n利']
data = {}
for keyword in keywords:
pattern = re.compile(re.escape(keyword) + r"[\s\S]*?([-]?\d[\d,\.]*)")
match = pattern.search(text)
if match:
value = match.group(1)
value = float(value.replace(',', '')) #去除数据中的逗号转为浮点数
data[keyword] = value
df = df.append({'股票代码': code, '年份': year.replace('.pdf', ''), '营业收入': data.get('营业收入', None)
,'1': data.get('归属于上市公司股\n东的净利润', None),'2': data.get('归属于上市公司股东\n的净利润', None)
,'3': data.get('归属于上市公司股东的\n净利润', None),'4': data.get('归属于上市公司股东的净\n利润', None)
,'5': data.get('归属于上市公司股东的净利\n润', None),'6': data.get('归属于上\n市公司股\n东的净利\n润', None)
,'7': data.get('归属于上市公\n司股东的净利\n润', None),'8': data.get('归 属 于 上 市\n公 司 股 东 的\n净利润', None)
,'9': data.get('归属于上市公司\n股东的净利润', None),'10': data.get('归属于上市\n公司股东的\n净利润', None)
,'11': data.get('归 属 于上 市公\n司 股 东的 净利\n润', None),'12': data.get('归 属 于 上 市 公\n司 股 东 的 净 利\n润', None)
,'13': data.get('归 属 于 上 市公 司\n股东的净利润', None) ,'14': data.get('归属于上市公司股东的净', None)
,'15': data.get('归属于上市公司普通股股东的净\n利', None)
},ignore_index=True)
return df
def process_annual_report_data(folder_path, output_file, company_df):
df = extract_annual_report_data(folder_path) # 读取股票年度报告数据
df = df.fillna('') # 处理数据格式
df['归属于上市公司股东的净利润'] = df.iloc[:, 3:].apply(lambda x: ' '.join(x.dropna().astype(str).unique()), axis=1)
df = df.drop(df.columns[3:-1], axis=1)
df['归属于上市公司股东的净利润'] = df['归属于上市公司股东的净利润'].apply(lambda x: x.split()[-1])
df['归属于上市公司股东的净利润'] = df['归属于上市公司股东的净利润'].astype(float)
df.to_csv(output_file, index=False)
df['年份'] = pd.to_datetime(df['年份'], format='%Y')
# 合并公司简称到原数据框
merged_df = pd.merge(df, company_df, left_on='股票代码', right_on='上市公司代码', how='left')
merged_df = merged_df.drop(columns=['上市公司代码'])
merged_df = merged_df.rename(columns={'上市公司简称': '公司简称'})
return merged_df
#获取最终公司信息
DF_SH = process_annual_report_data("D:/python homework/nianbao/SH", 'financial_data_SH.csv', SH_Company)
分析
主要使用正则表达式pattern = re.compile(re.escape(keyword) + r"[\s\S]*?([-]?\d[\d,\.]*)")来匹配营业收入与归属于上市公司股东净利润的数据。其中,[\s\S] 匹配任何空白字符(\s)或非空白字符(\S)。它们一起匹配任何字符,包括换行符。[\s\S]*? 匹配零个或多个任意字符,但尽可能少匹配。([-]?\d[\d,\.]*) 捕获数值部分。部分年报中净利润一栏由于存在多个换行符,无法正确匹配,所以选择将其关键字一一罗列出来。并将遍历、清洗等行为一起封装为函数extract_annual_report_data,具体代码如图2-4所示。同时定义函数process_annual_report_data(folder_path, output_file, company_df)用于匹配股票代码与公司简称,便于后续画图处理。得出上交所该行业10年各公司数据如图2-3所示
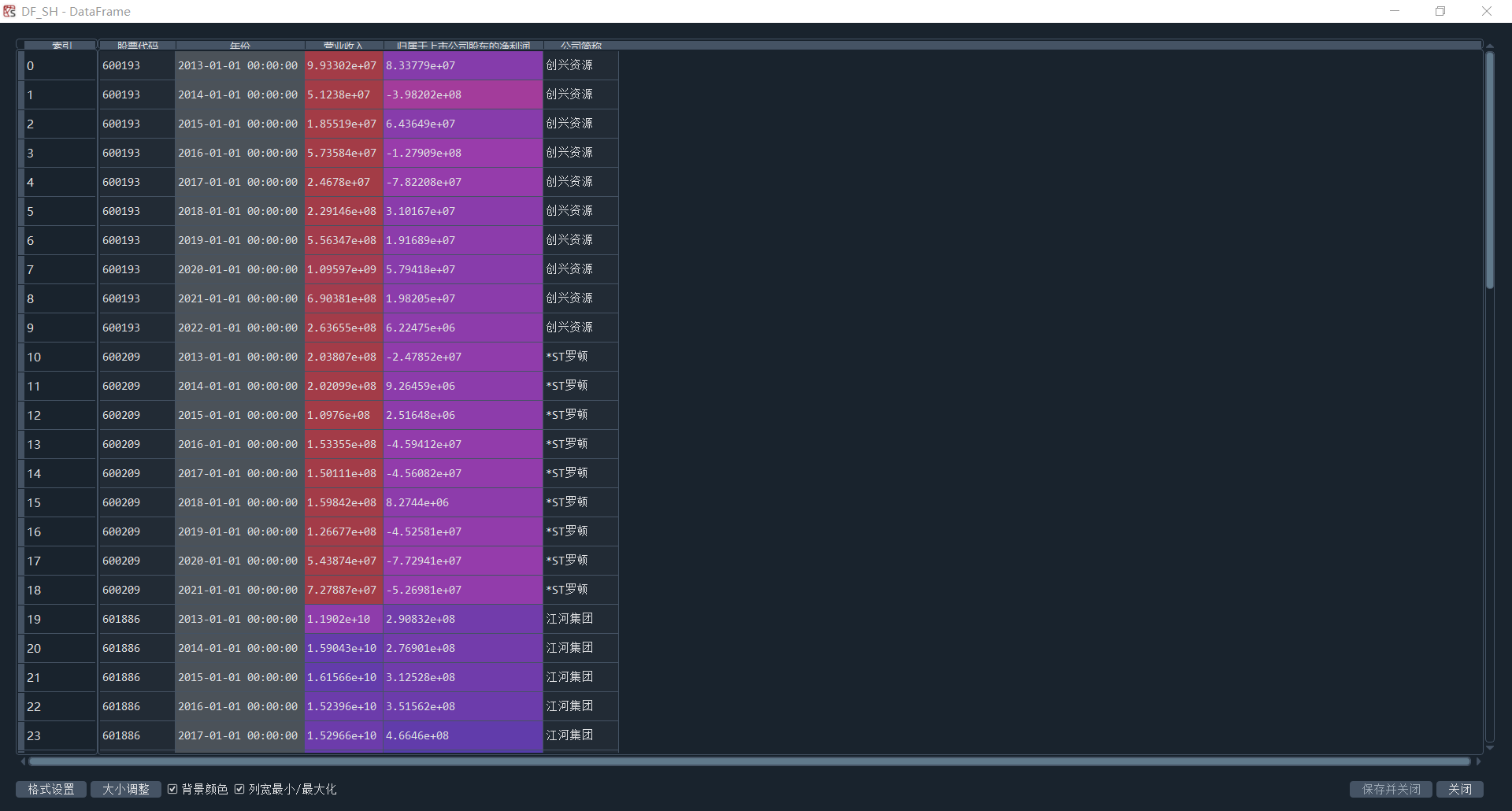
图2-3 上交所所属股票的公司信息
STEP3:获取分配行业的深交所股票的上市公司年报
3.1 获取深交所股票年报连接
# 3.1 获取深交所股票年报连接
def InputTime(start,end): # 找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): # 找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code')
Searchbox.send_keys(name)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
def Clearicon(): # 清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): # 点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename, content):
directory = r"D:\python homework\nianbao\SZ" # 指定保存的目录
if not os.path.exists(directory): # 如果目录不存在,则创建目录
os.makedirs(directory)
filepath = os.path.join(directory, filename + ".html") # 构建完整的文件路径
with open(filepath, "w", encoding="utf-8") as f:
f.write(content)
class DisclosureTable(): #解析深交所定期报告页搜索表格
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?) ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2013-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
# 在深交所官网爬取深交所上市公司年报链接
for index, row in SZ_Company.iterrows():
code = row[0]
name = row[1].replace("*", "")
SearchCompany(code)
time.sleep(0.5) # 延迟执行0.5秒,等待网页加载
html = browser.find_element(By.ID, "disclosure-table")
innerHTML = html.get_attribute("innerHTML")
Save(name, innerHTML)
Clearicon()
分析
由于深交所与上交所的网页有所不同,因此使用了新的DisclosureTable 类对HTML内容进行处理,提取年报表格数据(具体代码见源码3.1节)。获取的深交所股票年报连接如图3-1所示。
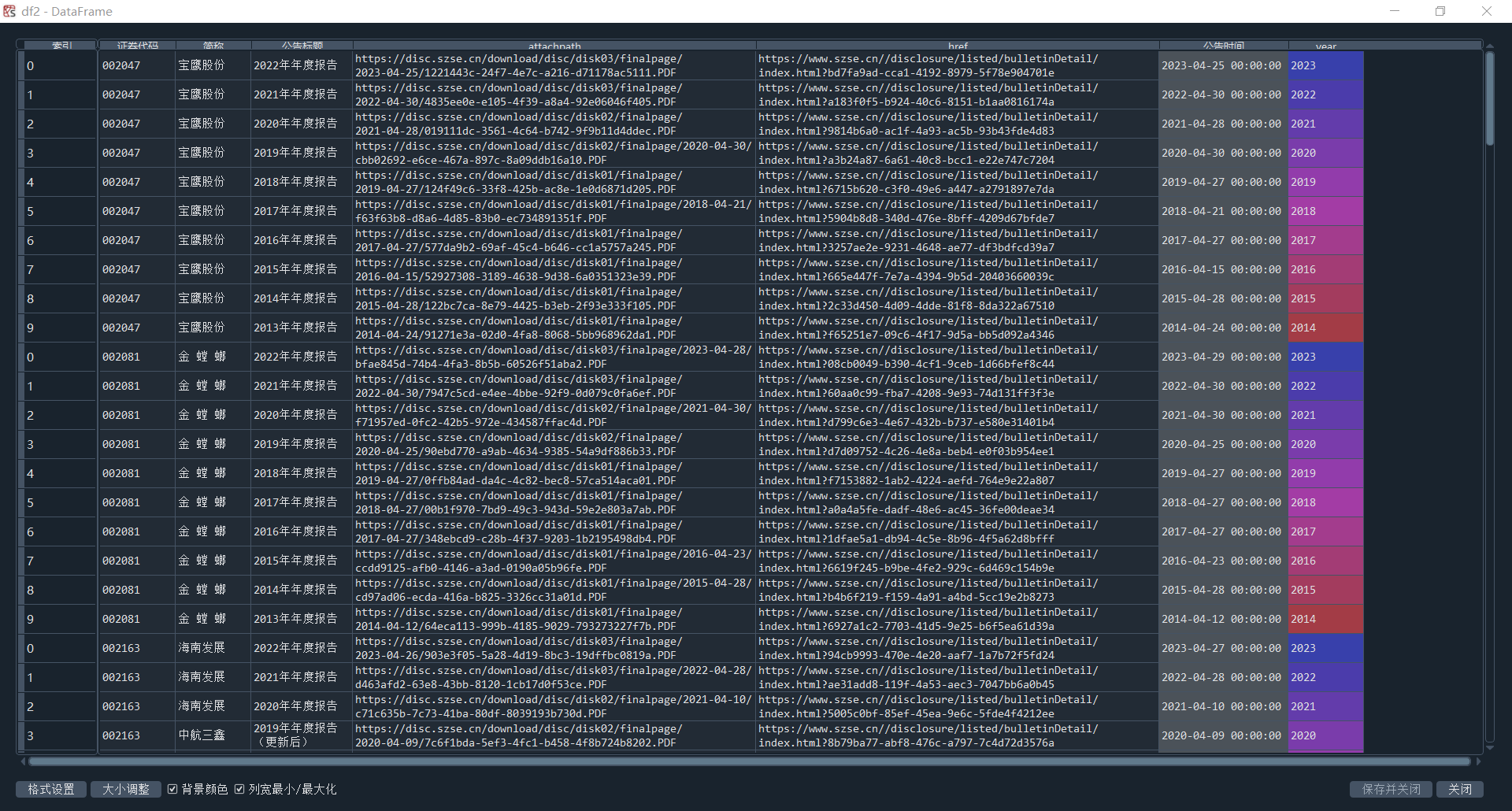
图3-1 深交所所属股票年报连接
3.2 解析html获取年报表格存储到本地并下载年报文件
#3.2 解析html获取年报表格存储到本地并下载年报文件
# 过滤年报并下载文件
def Readhtml(filename): # 读取年报html
file_path = os.path.join(r'D:\python homework\nianbao\SZ', f'{filename}.html')
with open(file_path, encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
save_dir = r'D:\python homework\nianbao\SZ' # 指定保存目录
df2 = pd.DataFrame()
i = 0
for index,row in SZ_Company.iterrows(): # 下载在深交所上市的公司的年报
i+=1
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1['公告时间'] = pd.to_datetime(df1['公告时间'])# 获取年份
df1['year'] = df1['公告时间'].dt.year
df1=df1[(df1['公告时间'] > '2014-01-01')]
df2 = df2.append(df1)
df2.to_csv('SZ_data.csv')
for index, row in df2.iterrows(): # 获取股票代码,年份和PDF链接
code = row['证券代码']
year = row['year'] - 1
url = row['attachpath']
response = requests.get(url)
save_path = os.path.join(save_dir, f'{code}_{year}.pdf') # 构造保存路径
with open(save_path, 'wb') as f:
f.write(response.content)
分析
创建空的数据框df2来存储所有公司的年报数据。使用SZ_Company 数据框中的每一行,遍历在深交所上市的公司。根据公司名称读取对应的HTML文件内容。使用tidy(df) 函数清除不需要的年报数据。将清理后的数据框添加到总的数据框df2中。将最终的数据框df2存储为CSV文件,命名为"SZ_data.csv"。遍历df2中的每一行,获取股票代码、年份和PDF链接。使用requests.get()函数发送GET请求获取PDF文件的内容(具体代码见源码3.2节),结果如图3-2所示。
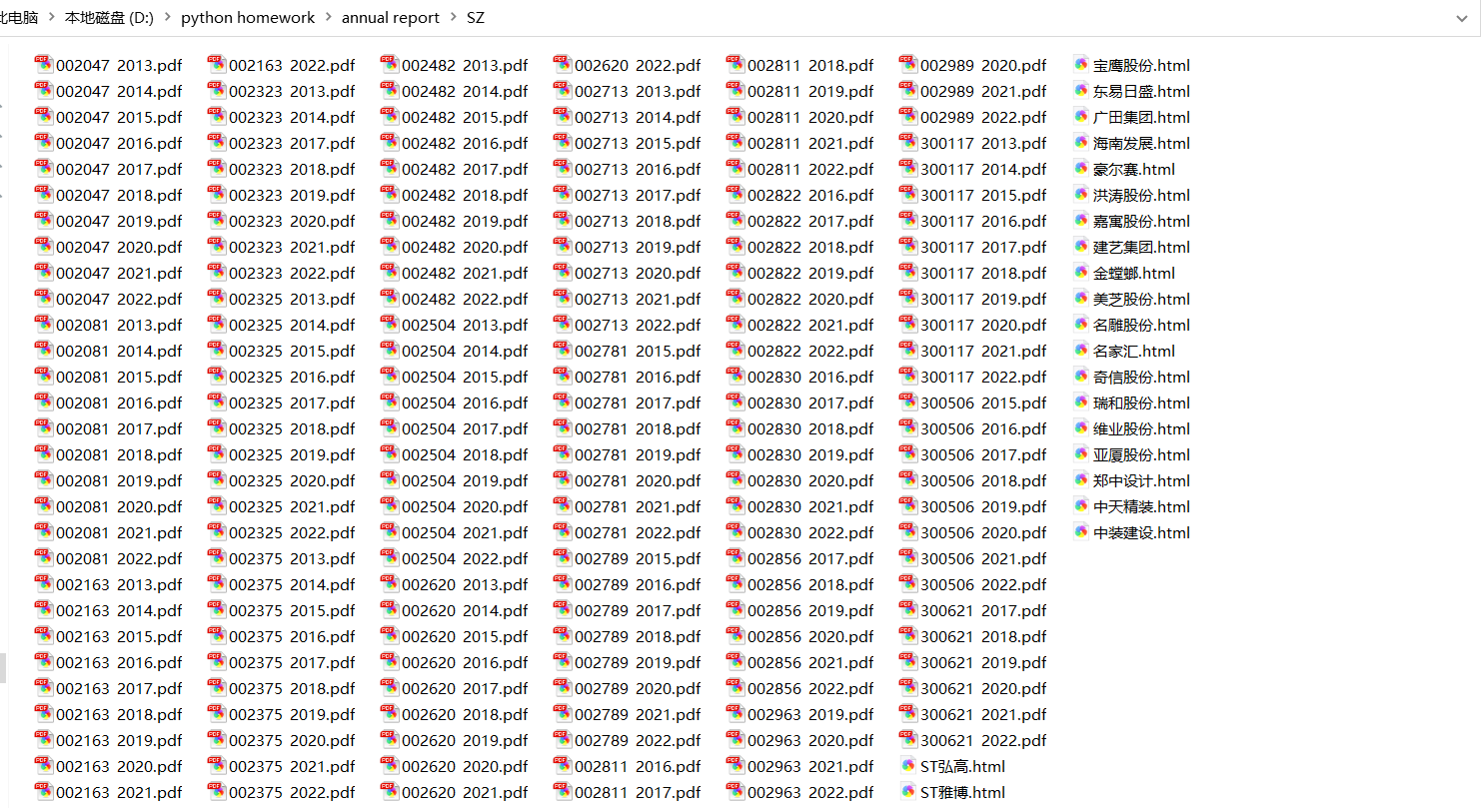
图3-2 深交所各股票年报PDF
3.3 提取深交所所属股票的公司信息
#3.3 提取年报公司信息
DF_SZ = process_annual_report_data("D:/python homework/nianbao/SZ", 'financial_data_SZ.csv', SZ_Company)
分析
调用process_annual_report_data函数,获取深交所该行业10年各公司数据如图3-3所示。
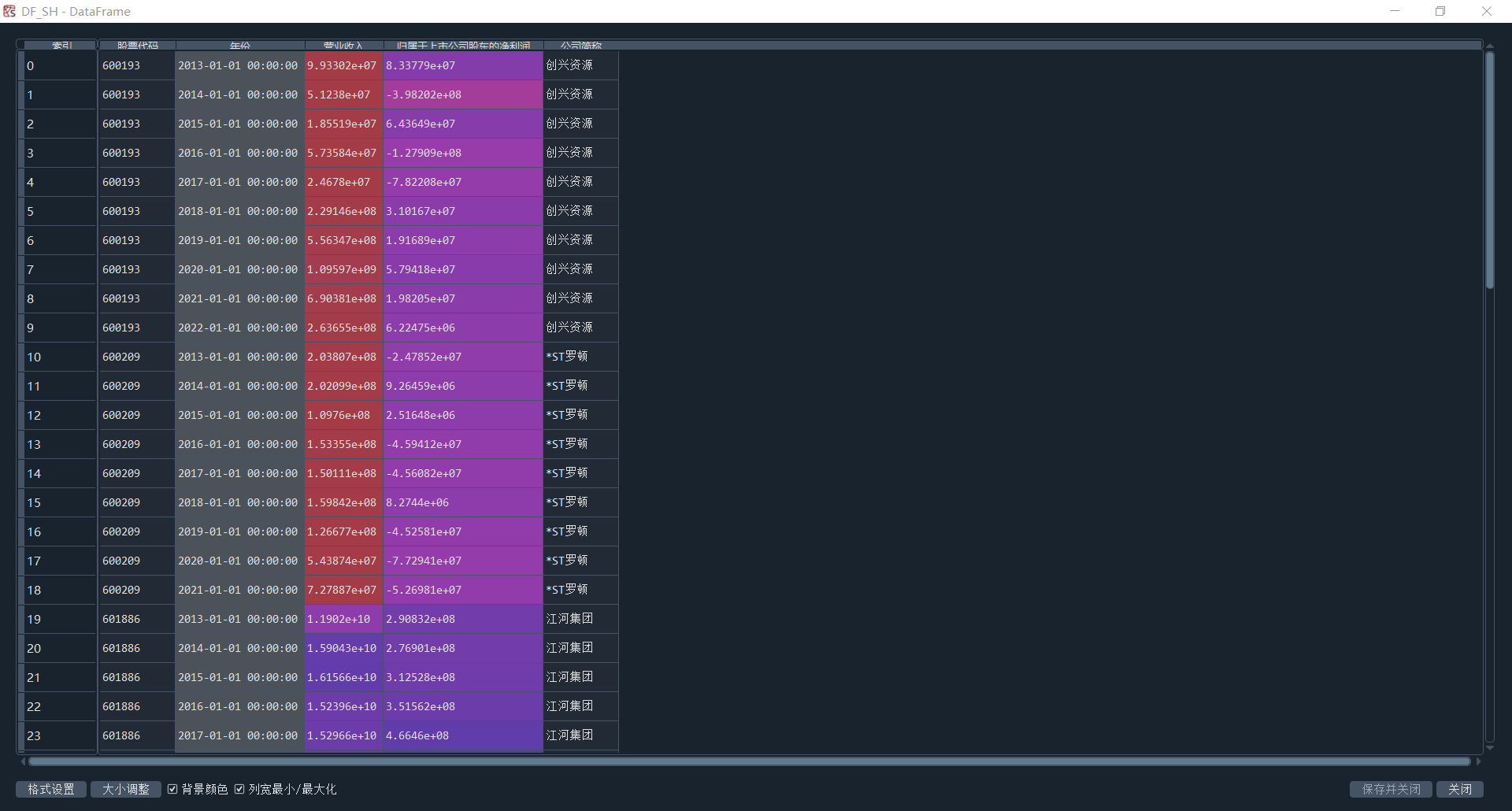
图3-3 深交所股票公司信息
STEP4:绘制各股时间序列图
4.1 提取出符合要求的10家公司
# 4.1 提取出符合要求的10家公司
ALL_df = pd.concat([DF_SZ, DF_SH], ignore_index=True) # 合并DF_SZ和DF_SH
df_2022 = ALL_df[ALL_df['年份'] == '2022-01-01'] # 筛选出2022年的营业收入前10的公司
df_2022_sorted = df_2022.sort_values('营业收入', ascending=False) # 按营业收入降序排序
top_10_companies = df_2022_sorted.head(10) # 选前10行数据
top_10_companies.to_csv('top_10_companies.csv',encoding='utf-8-sig')
selected_companies = top_10_companies['股票代码'].unique()
TOP_10 = ALL_df[ALL_df['股票代码'].isin(selected_companies)]
TOP_10.to_csv('TOP_10.csv',encoding='utf-8-sig')
TOP_10_unique = TOP_10.drop_duplicates(subset=['股票代码', '公司简称'])
plt.figure(figsize=(10, 6))
plt.bar(top_10_companies['公司简称'], top_10_companies['营业收入'])
plt.title('TOP 10 公司营业收入');plt.xlabel('2022年');plt.ylabel('营业收入(亿元)')
plt.xticks(rotation=45, ha='right')
plt.show()
分析
将获取的所有公司数据合并后,通过sort_values方法,按营业收入列降序排列,获取营业收入的前10家公司,并绘制柱状图,结果如图4-1-1,4-1-2所示。
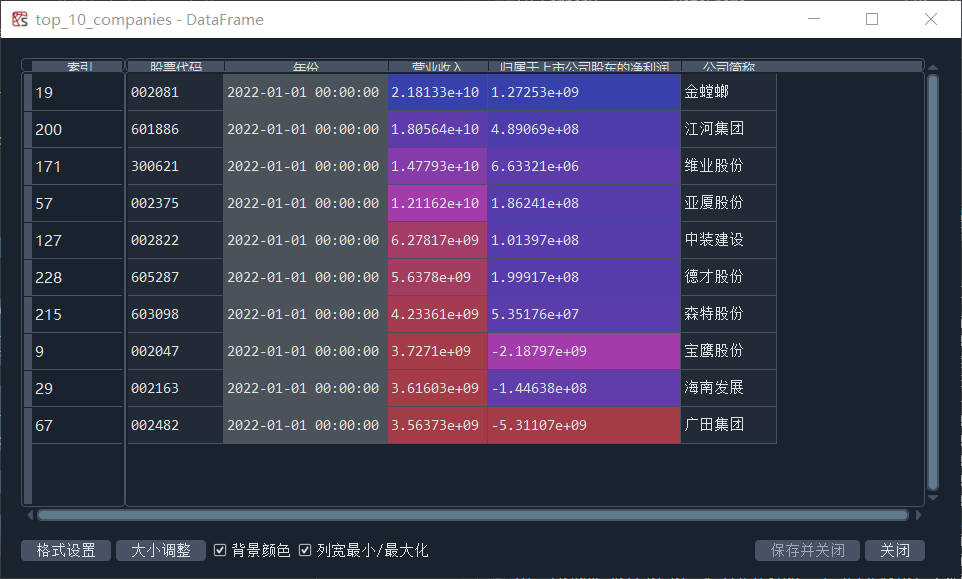
图4-1-1 TOP10公司
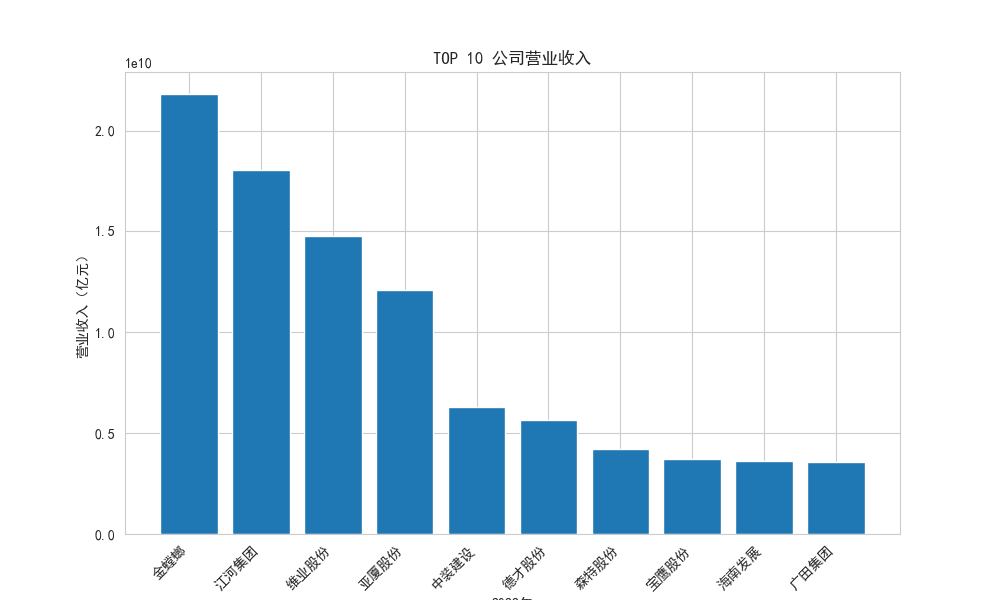
图4-1-2 TOP10公司营业收入
4.2 绘制营业收入时间序列图
#4.2 绘制营业收入时间序列图
def plot_time_series(data, x, y, title, xlabel, ylabel):
palette = 'bright'
plt.figure(figsize=(16, 8))
sns.lineplot(data=data, x=x, y=y, hue='股票代码', style='股票代码', markers=True, markersize=9, palette=palette)
plt.title(title, fontsize=16)
plt.xlabel(xlabel, fontsize=12)
plt.ylabel(ylabel, fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.yticks(fontsize=10)
stock_labels = data['股票代码'] + ' ' + data['公司简称']
plt.legend(title='股票代码 公司简称', labels=stock_labels, loc='upper left', bbox_to_anchor=(1, 1))
plt.tight_layout()
plt.show()
plot_time_series(TOP_10, '年份', '营业收入', '图1 各股营业收入时间序列图', '年份', '营业收入(亿元)')
分析
使用matplotlib.pyplot模块作图,定义一个plot_time_series(data, x, y, title, xlabel, ylabel)函数,用来输入对应X、Y轴数据,来绘制各公司营业收入时间序列图。结果如图4-2所示。
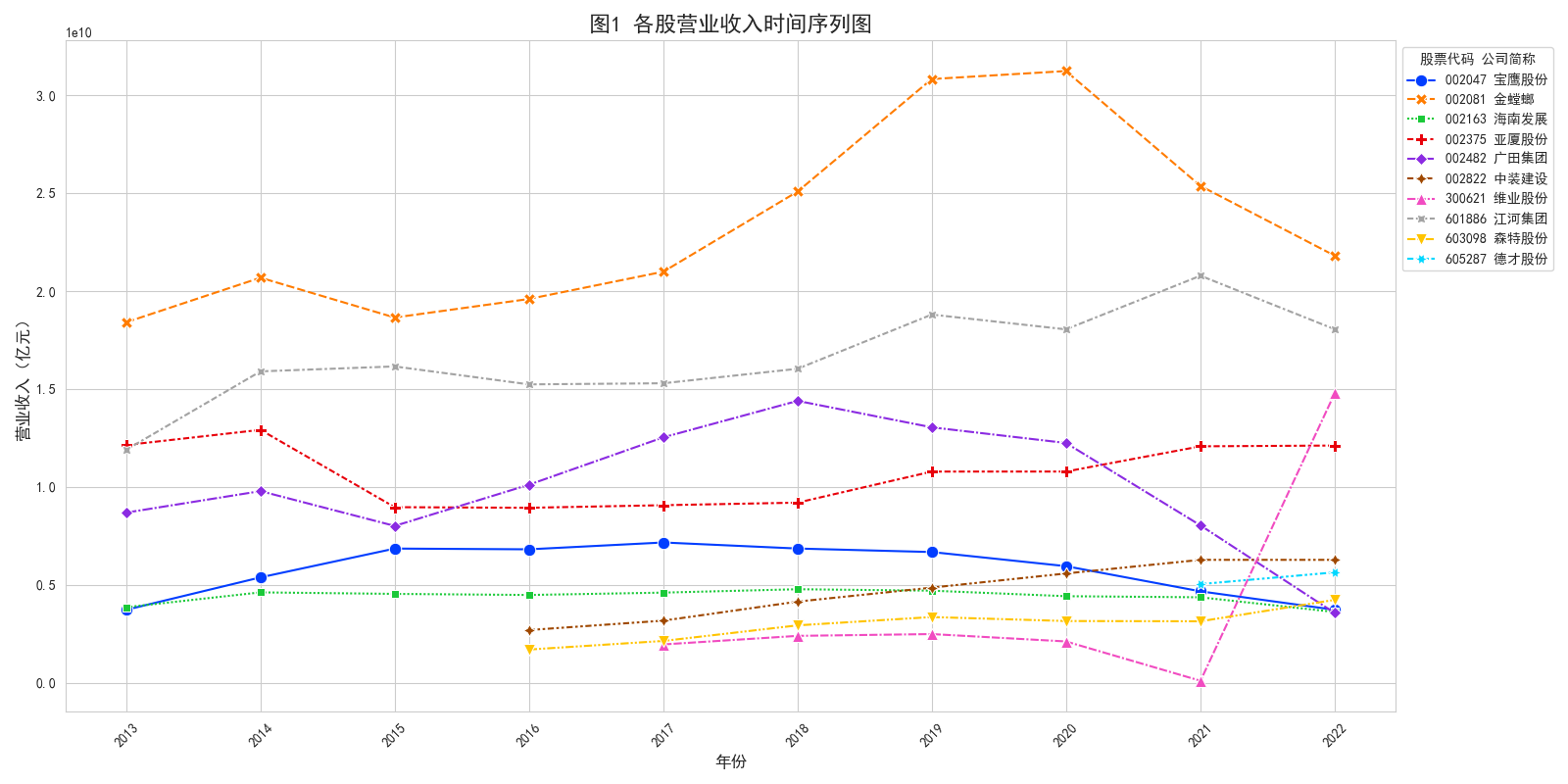
图4-2 营业收入时间序列图
4.3 绘制净利润时间序列图
# 4.3 绘制净利润时间序列图
plot_time_series(TOP_10, '年份', '归属于上市公司股东的净利润', '图2 各股归属于上市公司股东的净利润时间序列图', '年份', '归属于上市公司股东的净利润(亿元)')
分析
调用plot_time_series函数,绘制各公司绘制净利润时间序列图。结果如图4-3所示。
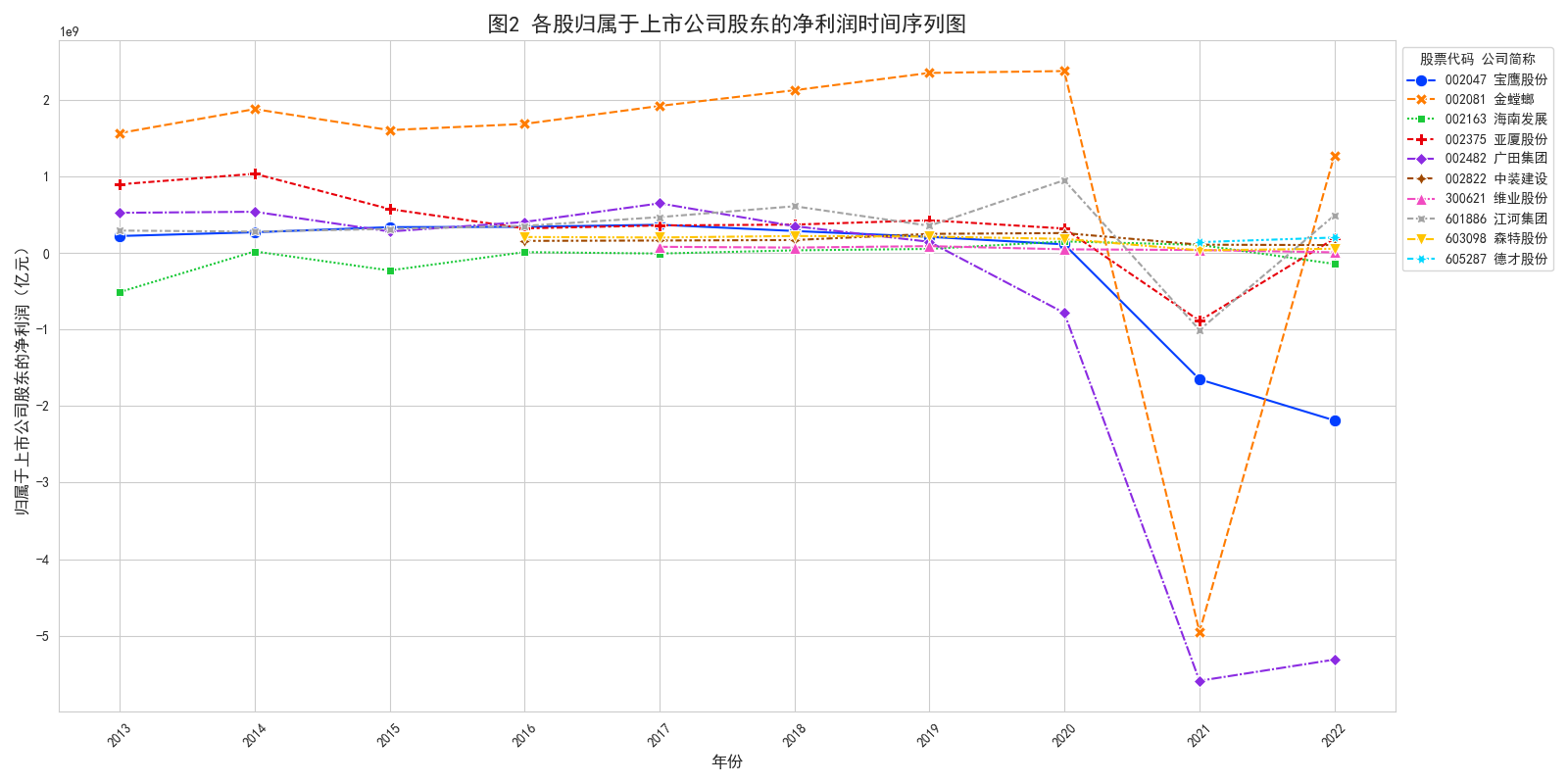
图4-3 净利润时间序列图
STEP5:行业解读
从营业收入来看,大部分公司营业收入在2013年到2019年基本呈现出增长的趋势,主要受益于国家经济发展、城镇化进程、基础设施建设、房地产市场等因素的推动。其中金螳螂、江河集团和中装建设的营业收入增速高于其他公司,表明它们在市场上有较强的竞争力和发展潜力。2020年受新冠疫情的影响,受到新冠疫情的冲击,建筑装饰和其他建筑业的营业收入受到了显著的影响。疫情导致了一系列的限制措施,包括施工停工、项目推迟和需求下降,对行业的运营产生了严重的不利影响。其中,宝鹰股份、亚厦股份和维业股份的营业收入下降幅度高于其他公司,显示出它们在疫情期间面临了较大的挑战。2021年随着疫情防控措施的逐步放宽和市场复苏的初步显现,行业复苏迹象明显,营业收入重新回到增长轨道。这主要得益于国家“稳增长”政策的支持、基础设施投资的加快、房地产市场的回暖等因素。其中,金螳螂、江河集团和中装建设的营业收入增速仍然高于其他公司,表明它们在市场复苏中抓住了机遇。预计2023年这些公司的营业收入将继续保持增长态势,但增速可能有所放缓,主要是因为经济增长可能面临一定的下行压力、房地产市场可能面临调控风险、成本上涨可能挤压利润空间等因素。总体而言,建筑装饰和其他建筑业的营业收入规模在近十年内保持了较高水平,但增速有所放缓,与国家经济发展和城镇化进程相一致。
从归属于上市公司股东的净利润来看,大部分公司归属于上市公司股东的净利润在2013年到2019年呈现出波动下降的趋势,主要是因为行业竞争激烈、利润率下降、资金链紧张、质量安全问题等因素的影响。其中金螳螂、江河集团和中装建设的净利润水平高于其他公司,表明它们在市场上有较强的盈利能力和风险抵御能力。2020年受新冠疫情的影响,行业净利润出现了大幅下滑,主要是因为疫情防控导致施工停工、项目延期、需求减少等问题导致收入减少,同时成本上升、资金紧张、坏账风险增加等问题导致支出增加。其中,宝鹰股份、亚厦股份和维业股份的净利润下降幅度高于其他公司,甚至出现了巨额亏损,表明它们在疫情防控期间受到了较大的损失。2021年随着疫情防控形势好转,这些公司的净利润重新回到增长轨道,其中金螳螂、江河集团和中装建设的净利润增速仍然高于其他公司,表明它们在市场复苏中实现了较好的效益,这些公司在应对疫情期间采取了积极的措施,如降低成本、加强项目管理、开拓新市场等,有效应对了疫情带来的挑战。预计2023年这些公司的净利润增速可能会相对缓慢。总体而言,建筑装饰和其他建筑业的净利润水平在近十年内呈现下降趋势,且波动幅度较大,与行业竞争激烈、成本上升、利润率下降等因素相一致。
综上所述,建筑装饰和其他建筑业是一个与国家经济发展和城镇化进程密切相关的行业,其发展规模和速度受到多方面因素的影响,呈现出不同的特点和趋势。未来,该行业将面临更多的机遇和挑战,需要不断创新和转型,以适应新发展阶段、新发展理念、新发展格局的要求,实现高质量发展。
STEP6:源码
import pdfplumber
import pandas as pd
import re
import os
import requests
from bs4 import BeautifulSoup
import csv
#(一)获取分配行业的上市公司
# 定义所需函数
def get_stock(data, stock_codes):
lst = [x for x in data for start_code in stock_codes if x[3].startswith(start_code)]
df = pd.DataFrame(lst, columns=data[0]).iloc[:, 1:]
return df
pdf = pdfplumber.open('行业分类.pdf')
table = pdf.pages[77].extract_table()
for i in range(len(table)):
if table[i][1] is None:
table[i][1] = table[i-1][1]
sz = get_stock(table, ['000', '200', '300', '00', '080'])
sh = get_stock(table, ['6', '900'])
df_sz = sz[sz['行业大类代码'] == '50']
df_sh = sh[sh['行业大类代码'] == '50']
SZ_Company = df_sz[['上市公司代码', '上市公司简称']]
SH_Company = df_sh[['上市公司代码', '上市公司简称']]
all_company = SZ_Company.append(SH_Company)
all_company.to_csv('company.csv', encoding='utf-8-sig')
#(二)获取分配行业的上交所股票的上市公司年报
# 2.1 获取上交所股票年报连接
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
def get_table_sse(code):
browser = webdriver.Chrome()
url = 'http://www.sse.com.cn/disclosure/listedinfo/regular/'
browser.get(url)
browser.set_window_size(1550, 830)
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code) #"601910"
time.sleep(5)
# 用JavaScript来让下拉菜单可见
browser.execute_script("document.querySelector('.sse_outerItem:nth-child(4) .filter-option-inner-inner').style.display = 'block';")
# 点击下拉菜单,并选择年报选项
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(5)
css_selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, css_selector)
table_html = element.get_attribute('innerHTML')
save_folder = r'D:\python homework\nianbao\SH' # 指定保存文件的文件夹路径
fname = os.path.join(save_folder, f'{code}.html')
f = open(fname, 'w', encoding='utf-8')
f.write(table_html)
f.close()
browser.quit()
# 获取各股年报网页
for index, row in SH_Company.iterrows():
code = row['上市公司代码']
try:
get_table_sse(code)
except Exception as e:
print(f"Failed to get the table for {code}: {e}")
# 从总网页中获取每年年报的连接
def get_data(tr):
p_td = re.compile('(.*?)', re.DOTALL)
tds = p_td.findall(tr)
code = tds[0].split('>')[1].split('<')[0]
name = tds[1].split('>')[1].split('<')[0]
href = 'http://www.sse.com.cn' + tds[2][tds[2].find('href="') + 6:tds[2].find('.pdf"') + 4]
title = tds[2][tds[2].find('$(this))">') + 10:tds[2].find(' ')]
date = tds[3].strip()
return [code, name, href, title, date]
def parse_table(table_html):
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(table_html)
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
folder = r'D:\python homework\nianbao\SH'
files = os.listdir(folder)
save_folder = r'D:\python homework\nianbao\SH'
df_all = pd.DataFrame()
for file in files: # 遍历每个文件名
f = open(os.path.join(folder, file), encoding='utf-8') # 打开HTML文件并读取内容
html = f.read()
f.close()
df = parse_table(html) # 调用parse_table函数
df_all = df_all.append(df)
df_all.to_csv('all_data.csv')
# 去除不符合的报告
list_1= []
df_all = df_all.reset_index()
for j in range(len(df_all)):
if '摘要' in df_all['title'][j] or'督导年度报告' in df_all['title'][j] or '修订稿' in df_all['title'][j] or '更正版' in df_all['title'][j] or '修订版' in df_all['title'][j]:
list_1.append(j)
if '年度报告' not in df_all['title'][j] and '年报' not in df_all['title'][j]:
list_1.append(j)
df_all.drop(df_all.index[list_1],inplace=True)
# 2.2 解析html获取年报表格存储到本地并下载年报文件
df_all=df_all[(df_all['date'] > '2014-01-01')] # 筛选出2014年前的年报
df_all['date'] = pd.to_datetime(df_all['date']) # 将data列转换为日期格式
df_all['year'] = df_all['date'].dt.year # 获取年份
# 遍历每一行,获取股票代码、年份和PDF链接,并发送GET请求保存PDF文件到本地
for index, row in df_all.iterrows():
code = row['code']
year = row['year']-1
url = row['href'] # 获取股票代码、年份和PDF链接
response = requests.get(url) # 发送GET请求并保存PDF文件到指定的文件夹中
with open(os.path.join(save_folder, f'{code}_{year}.pdf'), 'wb') as f:
f.write(response.content)
#2.3 提取公司信息
import fitz
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as ticker
from matplotlib.ticker import MaxNLocator
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
sns.set_style("whitegrid",{'font.sans-serif':['simhei','Arial']})
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf')
def extract_annual_report_data(folder_path):
df = pd.DataFrame(columns=['股票代码', '年份', '营业收入'])
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
# 提取股票代码和年份
code_year = filename.split("_")
if len(code_year) != 2:
continue # 文件名不符合要求,跳过当前文件
code, year = code_year
file_path = os.path.join(folder_path, filename)
doc = fitz.open(file_path)
whole_text = '' # 提取整个年报文本
for page in doc:
whole_text += page.get_text()
start_index = whole_text.find('主要会计数据') #起始位置
if start_index == -1:
continue
end_index = whole_text.find('总资产', start_index) #结束位置
text = whole_text[start_index:end_index]
# 提取营业收入和归属上市公司股东的净利润数据
keywords = ['营业收入','归属于上市公司股\n东的净利润','归属于上市公司股东\n的净利润'
,'归属于上市公司股东的\n净利润','归属于上市公司股东的净\n利润'
,'归属于上市公司股东的净利\n润','归属于上\n市公司股\n东的净利\n润'
,'归属于上市公\n司股东的净利\n润','归 属 于 上 市\n公 司 股 东 的\n净利润'
,'归属于上市公司\n股东的净利润','归属于上市\n公司股东的\n净利润'
,'归 属 于上 市公\n司 股 东的 净利\n润','归 属 于 上 市 公\n司 股 东 的 净 利\n润'
,'归 属 于 上 市公 司\n股东的净利润','归属于上市公司股东的净'
,'归属于上市公司普通股股东的净\n利']
data = {}
for keyword in keywords:
pattern = re.compile(re.escape(keyword) + r"[\s\S]*?([-]?\d[\d,\.]*)")
match = pattern.search(text)
if match:
value = match.group(1)
value = float(value.replace(',', '')) #去除数据中的逗号转为浮点数
data[keyword] = value
df = df.append({'股票代码': code, '年份': year.replace('.pdf', ''), '营业收入': data.get('营业收入', None)
,'1': data.get('归属于上市公司股\n东的净利润', None),'2': data.get('归属于上市公司股东\n的净利润', None)
,'3': data.get('归属于上市公司股东的\n净利润', None),'4': data.get('归属于上市公司股东的净\n利润', None)
,'5': data.get('归属于上市公司股东的净利\n润', None),'6': data.get('归属于上\n市公司股\n东的净利\n润', None)
,'7': data.get('归属于上市公\n司股东的净利\n润', None),'8': data.get('归 属 于 上 市\n公 司 股 东 的\n净利润', None)
,'9': data.get('归属于上市公司\n股东的净利润', None),'10': data.get('归属于上市\n公司股东的\n净利润', None)
,'11': data.get('归 属 于上 市公\n司 股 东的 净利\n润', None),'12': data.get('归 属 于 上 市 公\n司 股 东 的 净 利\n润', None)
,'13': data.get('归 属 于 上 市公 司\n股东的净利润', None) ,'14': data.get('归属于上市公司股东的净', None)
,'15': data.get('归属于上市公司普通股股东的净\n利', None)
},ignore_index=True)
return df
def process_annual_report_data(folder_path, output_file, company_df):
df = extract_annual_report_data(folder_path) # 读取股票年度报告数据
df = df.fillna('') # 处理数据格式
df['归属于上市公司股东的净利润'] = df.iloc[:, 3:].apply(lambda x: ' '.join(x.dropna().astype(str).unique()), axis=1)
df = df.drop(df.columns[3:-1], axis=1)
df['归属于上市公司股东的净利润'] = df['归属于上市公司股东的净利润'].apply(lambda x: x.split()[-1])
df['归属于上市公司股东的净利润'] = df['归属于上市公司股东的净利润'].astype(float)
df.to_csv(output_file, index=False)
df['年份'] = pd.to_datetime(df['年份'], format='%Y')
# 合并公司简称到原数据框
merged_df = pd.merge(df, company_df, left_on='股票代码', right_on='上市公司代码', how='left')
merged_df = merged_df.drop(columns=['上市公司代码'])
merged_df = merged_df.rename(columns={'上市公司简称': '公司简称'})
return merged_df
#获取最终公司信息
DF_SH = process_annual_report_data("D:/python homework/nianbao/SH", 'financial_data_SH.csv', SH_Company)
#(三)获取分配行业的深交所股票的上市公司年报
# 3.1 获取深交所股票年报连接
def InputTime(start,end): # 找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): # 找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code')
Searchbox.send_keys(name)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
def Clearicon(): # 清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): # 点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename, content):
directory = r"D:\python homework\nianbao\SZ" # 指定保存的目录
if not os.path.exists(directory): # 如果目录不存在,则创建目录
os.makedirs(directory)
filepath = os.path.join(directory, filename + ".html") # 构建完整的文件路径
with open(filepath, "w", encoding="utf-8") as f:
f.write(content)
class DisclosureTable(): #解析深交所定期报告页搜索表格
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2013-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
# 在深交所官网爬取深交所上市公司年报链接
for index, row in SZ_Company.iterrows():
code = row[0]
name = row[1].replace("*", "")
SearchCompany(code)
time.sleep(0.5) # 延迟执行0.5秒,等待网页加载
html = browser.find_element(By.ID, "disclosure-table")
innerHTML = html.get_attribute("innerHTML")
Save(name, innerHTML)
Clearicon()
#3.2 解析html获取年报表格存储到本地并下载年报文件
# 过滤年报并下载文件
def Readhtml(filename): # 读取年报html
file_path = os.path.join(r'D:\python homework\nianbao\SZ', f'{filename}.html')
with open(file_path, encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
save_dir = r'D:\python homework\nianbao\SZ' # 指定保存目录
df2 = pd.DataFrame()
i = 0
for index,row in SZ_Company.iterrows(): # 下载在深交所上市的公司的年报
i+=1
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1['公告时间'] = pd.to_datetime(df1['公告时间'])# 获取年份
df1['year'] = df1['公告时间'].dt.year
df1=df1[(df1['公告时间'] > '2014-01-01')]
df2 = df2.append(df1)
df2.to_csv('SZ_data.csv')
for index, row in df2.iterrows(): # 获取股票代码,年份和PDF链接
code = row['证券代码']
year = row['year'] - 1
url = row['attachpath']
response = requests.get(url)
save_path = os.path.join(save_dir, f'{code}_{year}.pdf') # 构造保存路径
with open(save_path, 'wb') as f:
f.write(response.content)
#3.3 提取年报公司信息
DF_SZ = process_annual_report_data("D:/python homework/nianbao/SZ", 'financial_data_SZ.csv', SZ_Company)
#(四)绘制各股时间序列图
# 4.1 提取出符合要求的10家公司
ALL_df = pd.concat([DF_SZ, DF_SH], ignore_index=True) # 合并DF_SZ和DF_SH
df_2022 = ALL_df[ALL_df['年份'] == '2022-01-01'] # 筛选出2022年的营业收入前10的公司
df_2022_sorted = df_2022.sort_values('营业收入', ascending=False) # 按营业收入降序排序
top_10_companies = df_2022_sorted.head(10) # 选前10行数据
top_10_companies.to_csv('top_10_companies.csv',encoding='utf-8-sig')
selected_companies = top_10_companies['股票代码'].unique()
TOP_10 = ALL_df[ALL_df['股票代码'].isin(selected_companies)]
TOP_10.to_csv('TOP_10.csv',encoding='utf-8-sig')
TOP_10_unique = TOP_10.drop_duplicates(subset=['股票代码', '公司简称'])
plt.figure(figsize=(10, 6))
plt.bar(top_10_companies['公司简称'], top_10_companies['营业收入'])
plt.title('TOP 10 公司营业收入');plt.xlabel('2022年');plt.ylabel('营业收入(亿元)')
plt.xticks(rotation=45, ha='right')
plt.show()
#4.2 绘制营业收入时间序列图
def plot_time_series(data, x, y, title, xlabel, ylabel):
palette = 'bright'
plt.figure(figsize=(16, 8))
sns.lineplot(data=data, x=x, y=y, hue='股票代码', style='股票代码', markers=True, markersize=9, palette=palette)
plt.title(title, fontsize=16)
plt.xlabel(xlabel, fontsize=12)
plt.ylabel(ylabel, fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.yticks(fontsize=10)
stock_labels = data['股票代码'] + ' ' + data['公司简称']
plt.legend(title='股票代码 公司简称', labels=stock_labels, loc='upper left', bbox_to_anchor=(1, 1))
plt.tight_layout()
plt.show()
plot_time_series(TOP_10, '年份', '营业收入', '图1 各股营业收入时间序列图', '年份', '营业收入(亿元)')
# 4.3 绘制净利润时间序列图
plot_time_series(TOP_10, '年份', '归属于上市公司股东的净利润', '图2 各股归属于上市公司股东的净利润时间序列图', '年份', '归属于上市公司股东的净利润(亿元)')