import requests,time,random,json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import fitz
import os
import sys
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体为SimHei
plt.rcParams['axes.unicode_minus'] =False #正确显示负号
def getText(pdf):
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.get_text()
doc.close()
return(text)
def req(stock,year,org_dict,place):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
"pageNum":"1",
"pageSize":"30",
"tabName":"fulltext",
"stock":stock + "," + org_dict[stock] ,# 按照浏览器开发者模式中显示的参数格式构造参数
"seDate":f"{str(int(year)+1)}-01-01~{str(int(year)+1)}-12-31",
"column":"szse",
"category":"category_ndbg_szsh",
"isHLtitle": "true",
"sortName":"time",
"sortType": "desc"
}
# 请求头
headers = {"Content-Length": "201","Content-Type":"application/x-www-form-urlencoded"}
# 发起请求
req = requests.post(url,data=data,headers=headers)
if json.loads(req.text)["announcements"]:# 确保json.loads(req.text)["announcements"]非空,是可迭代对象
for item in json.loads(req.text)["announcements"]:# 遍历announcements列表中的数据,目的是排除英文报告和报告摘要,唯一确定年度报告或者更新版
if "摘要" not in item["announcementTitle"]:
if "英文" not in item["announcementTitle"]:
if "修订" in item["announcementTitle"] or "更新" in item["announcementTitle"]:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("{}".format(place) +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
else:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("{}".format(place) +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
# 该函数主要是通过http://www.cninfo.com.cn/new/data/szse_stock.json该json数据,找到每个stock对应的orgid,并存储在字典org_dict中
def get_orgid():
org_dict = {}
org_json = requests.get("http://www.cninfo.com.cn/new/data/szse_stock.json").json()["stockList"]
for i in range(len(org_json)):
org_dict[org_json[i]["code"]] = org_json[i]["orgId"]
return org_dict
stock_code_all=fitz.open('行业分类.pdf')
stock_code_all=getText(stock_code_all)
stock_code_all_0=stock_code_all.find('土木工程建筑业')
stock_code_all_1=stock_code_all.find('建筑安装业')
sub_stockcode_all=stock_code_all[stock_code_all_0:stock_code_all_1]
p_stockcode=re.compile('\d{6}')
stock_code_all=p_stockcode.findall(sub_stockcode_all)
if __name__ == "__main__":# 程序入口
# 读取需要爬取的股票代码
org_dict = get_orgid()
for stock in stock_code_all:# 一层循环,按股票代码循环
year=str('2022')
req(stock,year,org_dict,'年报new')# 调用req函数
time.sleep(random.randint(0,2))# 适当休眠,避免爬虫过快
我首先定义了这个股票的调用函数以及定义了读取PDF文件所需要的函数
Def getText(pdf) 接着定义调用函数 def req(stock,year,org_dict,place) 该函数通过模拟巨潮网的请求获得每一个年报在指定年份的年报网址,并将其下载 再定义def get_orgid(): 该函数主要是通过http://www.cninfo.com.cn/new/data/szse_stock.json该json数据 ,找到每个stock对应的orgid,并存储在字典org_dict中 利用正则表达读取行业分类这个PDF中所有土木工程建筑业的股票代码并将其存在一个LIST中 调用之前我们所定义的函数,获取这些股票的全部年报,并将其存在年报文件夹中
调用之前我们所定义的函数,获取这些股票的全部年报,并将其存在年报文件夹中
def find_income_profit(path0,place):
direc=os.listdir(path0)
#这个list需要包括所有股票的代码
number2='-?\d{1,3}(?:,\d{3})*(?:.\d+)?'
income=[]
profit=[]
PATH=[]
for directory in direc:
Path='F:/桌面/金融数据获取与处理/期末/{PLACE}/{PDF}'.format(PLACE=place,PDF=directory)
PATH.append(Path)
for i in range(len(direc)):
try:
pdf = fitz.open(PATH[i])
text=getText(pdf)
s0=text.find('主要会计数据和财务指标')
s1=text.find('总资产')
if s1 < s0:
s1=s0+1000
subtext=text[max(s0,0):s1]
p_revenue=re.compile('(营业收入)[(元)\s]*(%s)' %number2)
p_net_profit=re.compile('(归[属于上市母公司股东的净利润\s]*)[\n(元)]*\s+(%s)' %number2)
revenue=p_revenue.findall(subtext)
net_profit=p_net_profit.findall(subtext)
income.append(revenue)
profit.append(net_profit)
except:
print('第{}次运行失败'.format(i+1))
return(income,profit,direc)
path='F:/桌面/金融数据获取与处理/期末/年报'
income_all,profit_all,direc0=find_income_profit(path,'年报')
def mode(lines):
X=[]
for line in lines:
line = line.strip("\n")
line = line.replace(",","")
line = line.replace(" ",".")
X.append(float(line))
return X
income_all_0=[]
for num in range(len(income_all)):
x=income_all[num][0][1]
income_all_0.append(x)
direc=os.listdir(path)
direc=pd.DataFrame(direc)
direc.columns=['code']
income_all_new=mode(income_all_0)
stock_code_all_new=direc['code'].str.replace('-2022年度报告.pdf','')
all_income_code=pd.DataFrame(index=stock_code_all_new,data=income_all_new,columns=['income'])
all_income_code_sort = all_income_code.sort_values(by = 'income',ascending = False)
stockcode=all_income_code_sort.index[:10]
 将这些函数作为索引,收入作为数据,获得下图数据
将这些函数作为索引,收入作为数据,获得下图数据
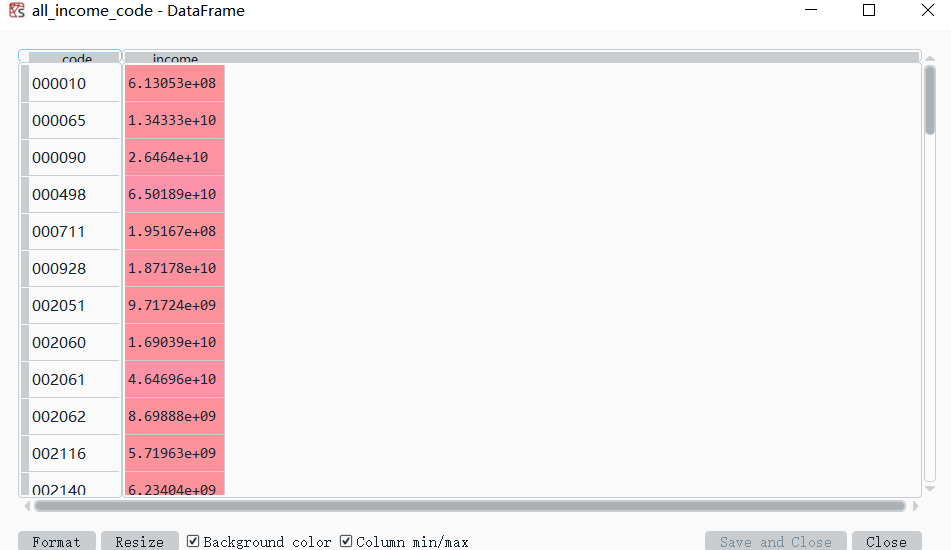 最后通过stockcode=all_income_code_sort.index[:10]代码来获取,收入排行前10的股票代码
最后通过stockcode=all_income_code_sort.index[:10]代码来获取,收入排行前10的股票代码
if __name__ == "__main__":# 程序入口
org_dict = get_orgid()
for stock in stockcode:# 一层循环,按股票代码循环
for year in np.arange(2013,2023,1):# 二层按年份循环
year=str(year)
req(stock,year,org_dict,'年报new')# 调用req函数
time.sleep(random.randint(0,2))# 适当休眠,避免爬虫过快
path_new='F:/桌面/金融数据获取与处理/期末/年报new'
income_new,profit_new,direc1=find_income_profit(path_new,'年报new')
income_=[]
profit_=[]
for num in range(len(direc1)):
try:
x=income_new[num][0][1]
y=profit_new[num][0][1]
income_.append(x)
profit_.append(y)
except:
print('第{}次运行失败'.format(num))
income_float=mode(income_)
profit_float=mode(profit_)
direc_1=pd.DataFrame(direc1)
direc_1=direc_1[0].str.replace('-\d{4}年度报告.pdf','')
dic_income={"income":income_float,
'other':direc_1}
dic_profit={"profit":profit_float,
'other':direc_1}
data_income=pd.DataFrame(dic_income)
data_profit=pd.DataFrame(dic_profit)
data1=data_income.groupby(by='other')
data1=list(data1)
data2=data_profit.groupby(by='other')
data2=list(data2)
stockname=['浙江建投','四川路桥','上海建工','陕建股份','安徽建工','绿地控股','中国化学','中国核建','中国电建','中国交建']
for i in range(len(data1)):
data=data1[i]
data_tempory=data[1]['income']
date_time=np.arange(2013,2023)
length=10-len(data_tempory)
s=np.pad(data_tempory,(length,0),'constant',constant_values=(0,0))
ax=plt.subplot(3,4,i+1)
plt.plot(date_time,s)
plt.legend()
#plt.title('{}'.format(data[0]),size=16)
plt.title(stockname[i])
plt.xlabel('年份',size=12)
plt.ylabel('营业收入',size=12)
plt.show()
for i in range(len(data2)):
data=data2[i]
data_tempory=data[1]['profit']
date_time=np.arange(2013,2023)
length=10-len(data_tempory)
s=np.pad(data_tempory,(length,0),'constant',constant_values=(0,0))
ax=plt.subplot(3,4,i+1)
plt.plot(date_time,s)
plt.legend()
#plt.title('{}'.format(data[0]),size=16)
plt.title(stockname[i])
plt.xlabel('年份',size=12)
plt.ylabel('归属于公司股东的净利润',size=12)
plt.show()
all_income=pd.DataFrame()
for i in range(len(data1)):
data=data1[i]
data_tempory=data[1]['income']
date_time=np.arange(2013,2023)
length=10-len(data_tempory)
s=np.pad(data_tempory,(length,0),'constant',constant_values=(0,0))
pd1=pd.DataFrame(s,index=date_time,columns=['{}'.format(data[0])])
all_income=pd.concat([all_income,pd1],axis=1)
all_profit=pd.DataFrame()
for i in range(len(data2)):
data=data2[i]
data_tempory=data[1]['profit']
date_time=np.arange(2013,2023)
length=10-len(data_tempory)
s=np.pad(data_tempory,(length,0),'constant',constant_values=(0,0))
pd1=pd.DataFrame(s,index=date_time,columns=['{}'.format(data[0])])
all_profit=pd.concat([all_profit,pd1],axis=1)
stockname=['浙江建投','四川路桥','上海建工','陕建股份','安徽建工','绿地控股','中国化学','中国核建','中国电建','中国交建']
all_income.columns=stockname
all_profit.columns=stockname
all_income.plot(xlabel='年份',ylabel='营业收入',title='十家上市公司的营业收入')
all_profit.plot(xlabel='年份',ylabel='归属于公司股东的净利润',title='十家上市公司的净利润')
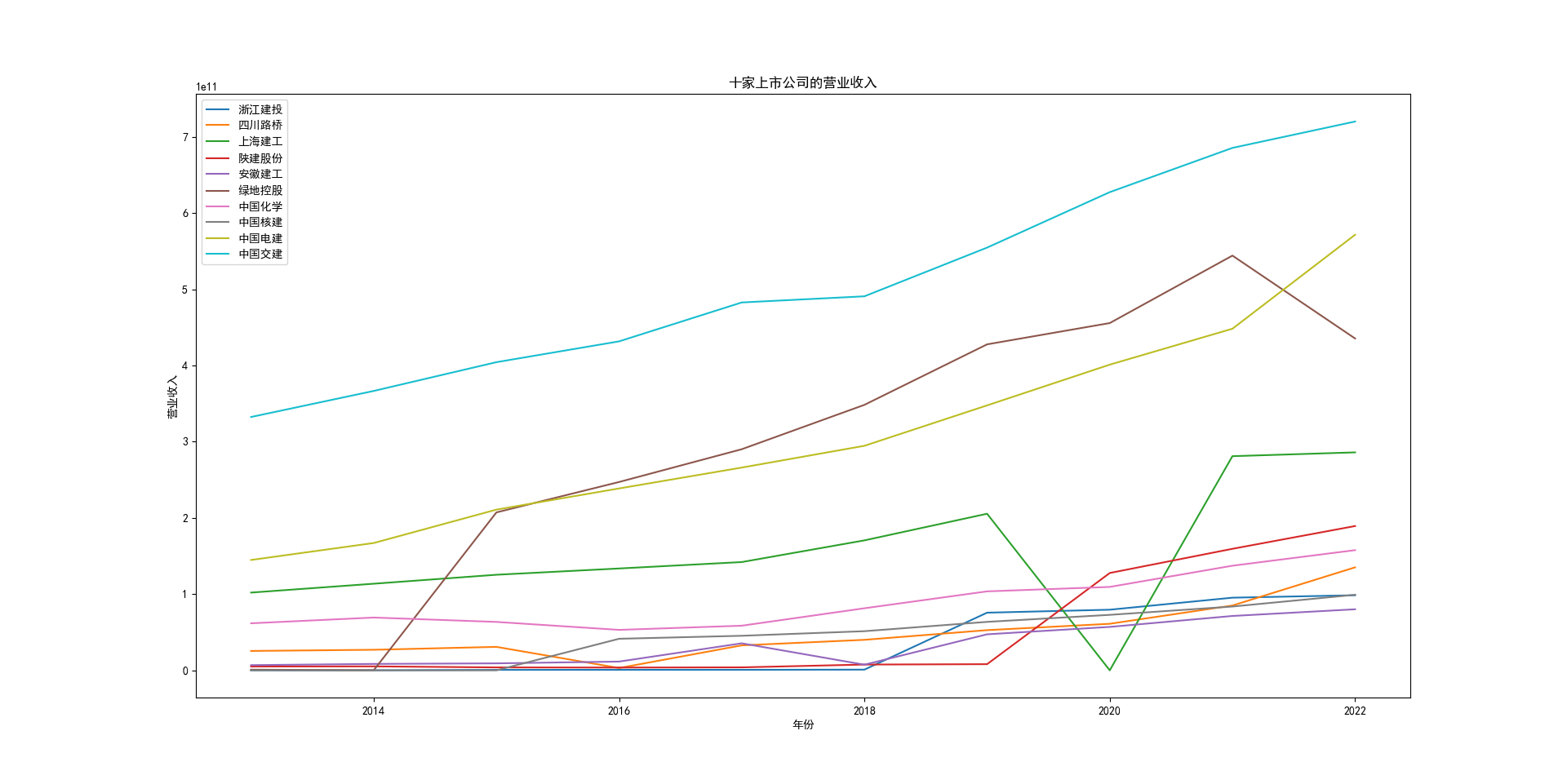
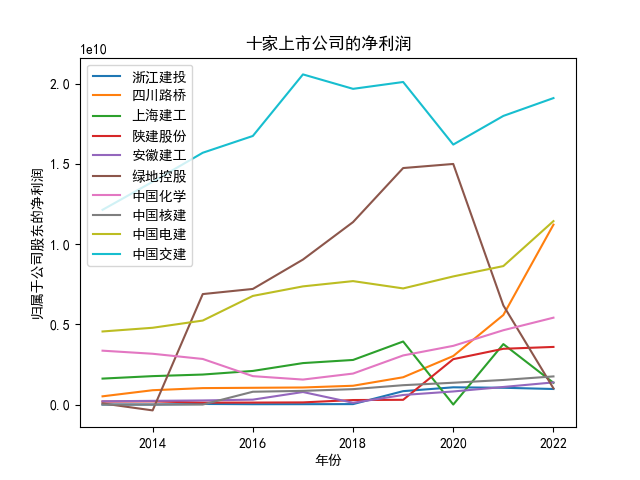
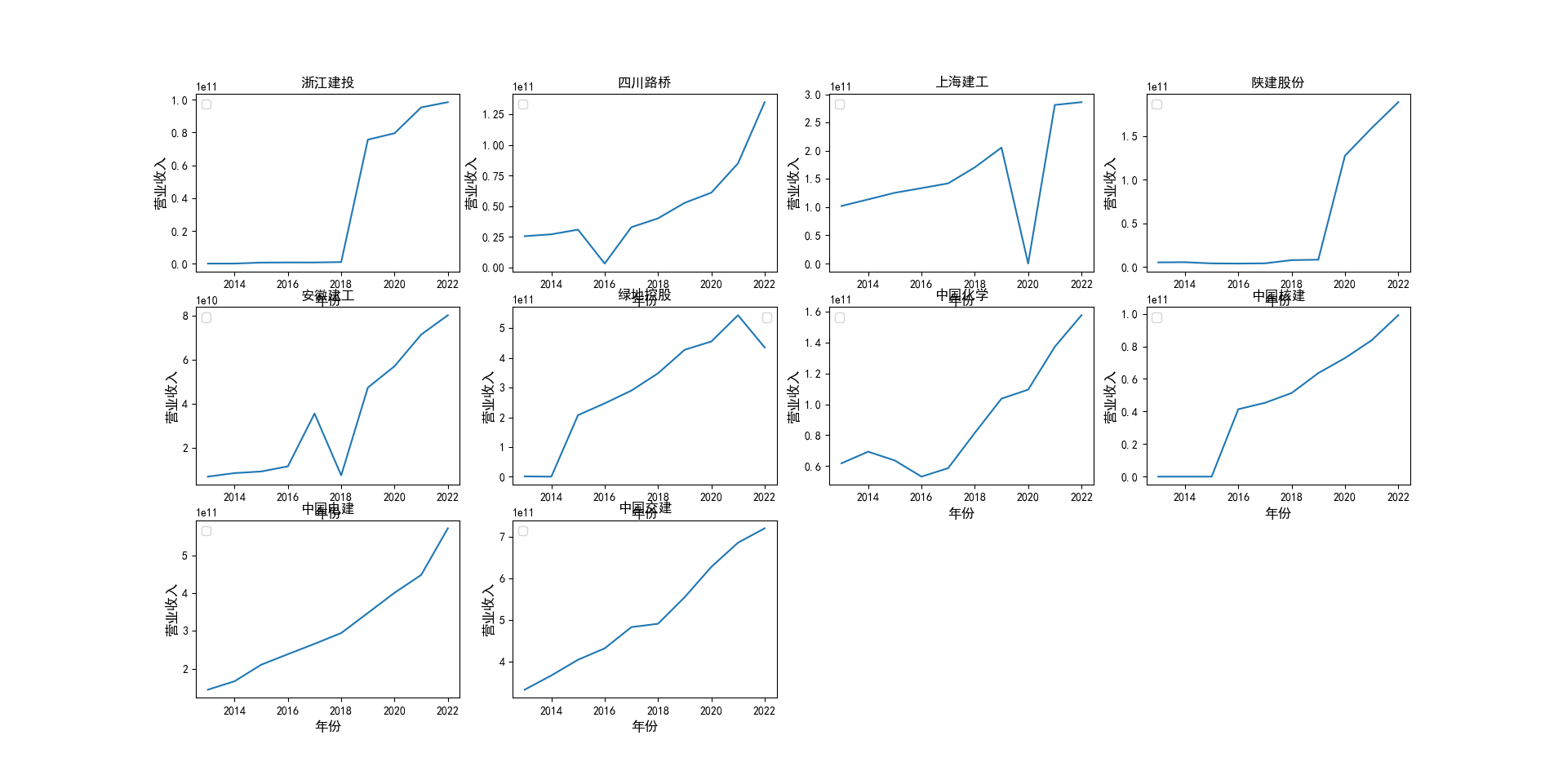
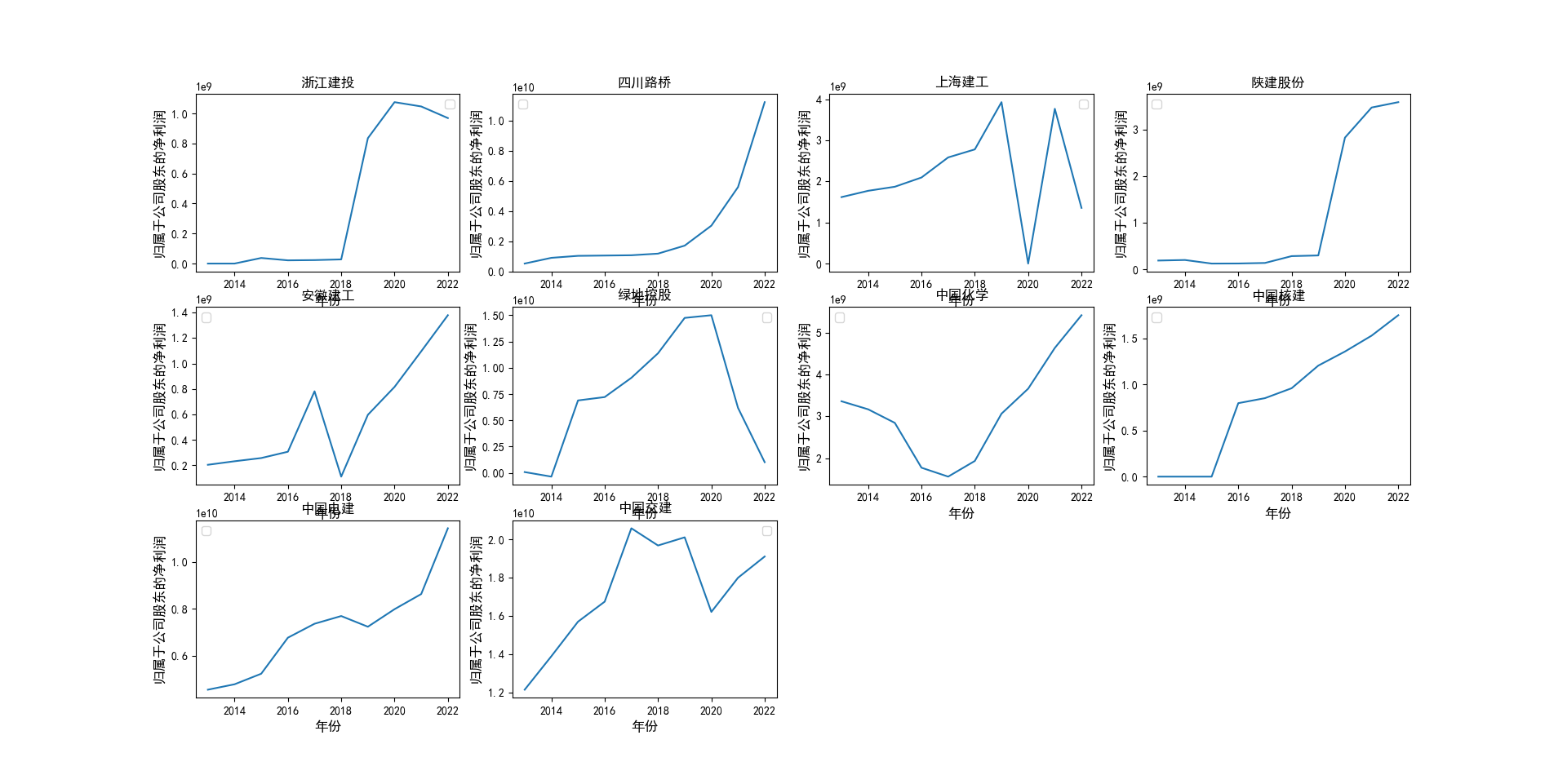
本次实验报告我的行业是土木工程建筑业,通过此次对数据的获取与处理,
该行业多家上市公司的营业收入和归属于上市公司股东的净利润我有了较为初步的理解与认识。
中国交建、中国电建再十年内的营业收入和净利润都维持在一个较高水平,并且能够实现稳步向上增长。
收房地产产业影响,绿地控股在营业收入变动较小的情况下,净利润实现了大幅度的下降。
四川路桥在近年来由于国家的大力支持,订单数量得到了增加在净利润上得到了巨大的增长。
上海建工则是在2020,2021,2022年三年内受到疫情的影响,在营业收入和净利润上都有所下降。
安徽建工在十年内收入总体上实现了稳步增长,但是在2018年却在收入和净利润上有同比的大幅度下跌。
其余个股的数据在10年来都得到了稳步的增长。
并且感叹于其在数据获取与处理方面的方便性。
通过本次实验报告的编写,我可以更为熟练的使用正则表达式实现数据的处理。
最后感谢吴老师的教导,本学期教了我们很多实用的知识,让我再python方面有了更多的理解。