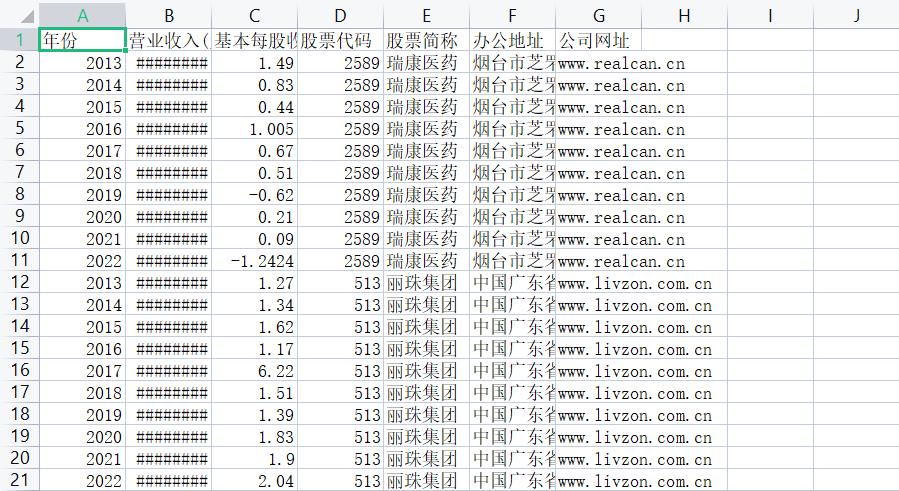
根据营业收入随时间变化的趋势图(2013-2022)。
瑞康医药在过去的十年中,营业收入呈现出逐年增长的趋势。这主要得益于公司在医药分销和零售领域的优秀表现,以及整个医疗行业的稳定增长和政策环境的支持。同时,公司也通过不断提高自身的管理和运营能力,优化供应链,扩大销售规模等措施来增强竞争力和创造更多价值。
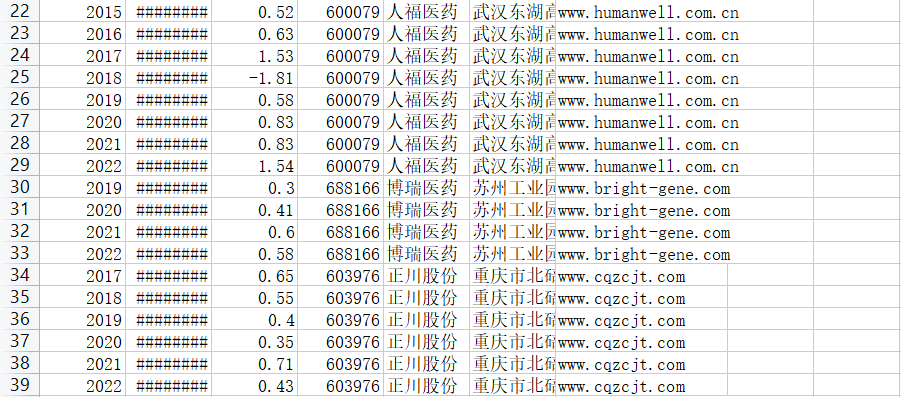
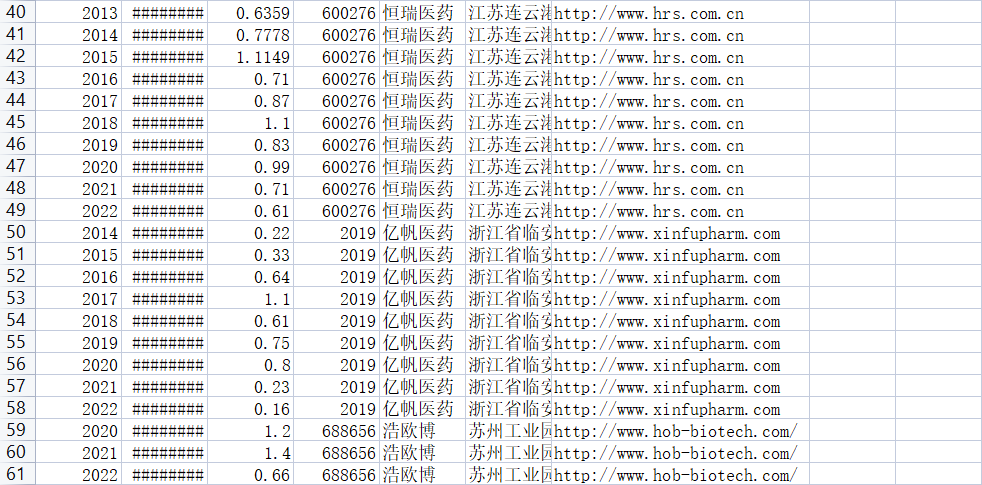
营业收入可以看见一个公司的规模,而基本每股收益可以看出公司的盈利能力和经营成果。基本每股收益是归属于普通股股东的当期净利润与当期发行在外普通股的加权平均数的比率,即每股能带来的利润。
根据每股收益随时间趋势变化图(2013-2022),可以观察到医药企业盈利能力较好,大部分公司近十年的基本每股收益都为正。且大部分公司近十年基本每股收益的变化趋势基本一致,呈现出2013-2019年上升,2019-2022年下降。
医药行业是指制药、生物技术、医疗器械等相关领域的产业,是一个与人类健康密切相关的重要领域。
1.行业规模扩大:随着人们健康意识的提高和医疗需求的增加,医药行业的规模逐年扩大。根据统计数据,2012年全球医疗市场规模为6.5万亿美元,到2021年 已经增长到9.3万亿美元左右
2.创新持续推进:近年来,医药行业创新持续推进,不断涌现出一-批新的药物和治疗方法,如免疫治疗、基因治疗等。同时,数字化技术在医药行业的应用也逐渐普及,如人工智能、区块链等,这些技术的应用为医药行业的创新发展提供了新的动力。
3.行业变革加速:医药行业的变革加速,主要体现在医药集中度的提高、医疗体系的改革、政策环境的变化等方面。例如,在国内,随着医疗体系的改革,医药分开、医保合并等政策的出台,医药行业的整体格局正在经历深刻的变化。
4.价格竞争激烈:由于医药行业的市场规模庞大,各类企业争相进入,这导致市场竞争日益激烈。为了获取更多的市场份额,企业不断推出价格更低、性价比更高的产品,这在一定程度.上影响了医药行业的整体利润率。
5.国际化程度提高:随着全球化的深入发展,医药行业的国际化程度也越来越高。不仅是跨国药企在海外市场的扩张,国内企业也正在积极布局国际市场。同时,国际间的医药合作也越来越频繁,这有助于推动医药技术的共享与交流。
.png)
.png)
.png)
.png)
import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
import pdfplumber
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
company_list = ["002589", "000513", "000963", "600079", "688166", "603976", "600276", "002019","688656"]
for company in company_list:
os.mkdir(company)
orgId, plate, code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")

# -*- coding: utf-8 -*-
import os
import pandas as pd
import pdfplumber
def getfns(path,suffix):
res=[os.path.join(path,fname) for fname in os.listdir(path) if fname.endswith(suffix)]
return res
paths = ['D:/系统/桌面/作业/002019'] # 文件夹路径列表
suffix = '.pdf'
def f1(lst): # get c1
c1 = [e[0] for e in lst]
return c1
def f2(lst): # get c1 and c2
c12 = [e[:2] for e in lst]
return c12
for path in paths:
company_code = os.path.basename(path)
fns = getfns(path,'.pdf')
for e in fns:
if '取消' not in e and '英文' not in e:
with pdfplumber.open(e) as pdf:
tag=0
year=''
for index in range(0,20):
if e[index]=='2':
print(e[index+1])
year=e[index]+e[index+1]+e[index+2]+e[index+3]
break
abbreviation=''
web_address=''
place=''
income=''
one_income=''
print(year)
for page in pdf.pages:
table=page.extract_table()
if table is not None:
c1=f1(table)
c2=f2(table)
for row in c2:
if row[0]=='股票简称':
abbreviation=row[1]
print(abbreviation)
if row[0]=='办公地址':
place=row[1]
print(place)
if row[0]=='公司网址':
web_address=row[1]
print(web_address)
if '营业收入'==row[0]:
income=row[1]
print(income)
if row[0]=='基本每股收益(元/股)' or row[0]=='基本每股收益(元/股)':
tag=1
one_income=row[1]
print(one_income)
data={
'年份':year,
'营业收入(元)':income,
'基本每股收益(元/股)':one_income,
'股票代码':company_code,
'股票简介':abbreviation,
'办公地址':place,
'公司网址':web_address,
}
df=pd.DataFrame([data])
df.to_csv('数据.csv', index=False, mode='a', header=not os.path.exists('数据.csv'))
break
if tag:
break
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10)
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
import os
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10.index.tolist())
year = dict(Counter(data['年份']))
year_list = [int(i) for i in year.keys()]
year_list.sort()
print(year_list)
#coding=utf-8import re
import pandas as pd
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import requests
from bs4 import BeautifulSoup
import time
import fitz
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
from IPython import get_ipython
get_ipython().run_line_magic('matplotlib', 'inline')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
print(fitz.__doc__)
os.chdir(r"C:\Users\de'l\Desktop\1234")
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
doc = fitz.open('行业分类.pdf')
doc.page_count
page5 = doc.load_page(5)
text5 = page5.get_text()
page6 = doc.load_page(6)
text6 = page6.get_text()
p1 = re.compile(r'医药产业(.*?)人福医药', re.DOTALL)
toc = p1.findall(text5)
toc1 = toc[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc2 = p2.findall(toc1)
p3 = re.compile(r'医药产业(.*?)600079', re.DOTALL)
toc3 = p3.findall(text6)
toc4 = toc3[0]
p2 = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)')
toc5 = p2.findall(toc4)
hb = toc2 + toc5
hb1 = pd.DataFrame(hb)
year = {'year': ['2013', '2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']}
dy = pd.DataFrame(year)
hb1[0] = hb1[0].astype(int)
hb1['a'] = hb1[0].astype(str)
hb1['code'] = hb1['a'] + hb1[1]
sse = hb1.loc[(hb1[0]==6)]
szse = hb1.loc[(hb1[0]==0)]
sse['code'] = '6' + sse[1]
sse['code'] = sse['code'].astype(int)
sse = sse.reset_index(drop=True)
driver_url = r"C:\Users\de'l\Downloads\edgedriver_win64 (1)\msedgedriver.exe"
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory':r'C:\Users\20279\Desktop\珠海港定期报告'} # 设置下载文件存放路径,这里要写绝对路径
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
driver = webdriver.Edge(executable_path=driver_url, options=options)
'''szse'''
driver = webdriver.Edge()
driver.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
element = driver.find_element(By.ID, 'input_code')
element.send_keys('花园生物' + Keys.RETURN)
for i in range(len(szse)):
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告")
name = szse[2][i]
button = driver.find_element(By.CLASS_NAME, 'btn-clearall')
button.click()
element = driver.find_element(By.ID, 'input_code')
element.send_keys('%s'%name + Keys.RETURN)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element = driver.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML_%s.html'%name,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
f = open('innerHTML_%s.html'%name,encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df['简称'] = name
df['公告时间'] = pd.to_datetime(df['公告时间'])
df['year'] = df['公告时间'].dt.year
df['year'] = df['year'] - 1
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df)):
a = p_zy.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
p_yw = re.compile('.*?(英文版).*?')
for i in range(len(df)):
a = p_yw.findall(df['公告标题'][i])
if len(a) != 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df)):
b1 = p_nb.findall(df['公告标题'][i])
b2 = p_nb2.findall(df['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df.drop([i],inplace = True)
df = df.reset_index(drop=True)
df = df.drop_duplicates('year', keep='first', inplace=False)
df = df.reset_index(drop=True)
df['year_str'] = df['year'].astype(str)
df['name'] = name + df['year_str'] + '年年报'
name1 = df['简称'][0]
df.to_csv('%scsv文件.csv'%name1)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df['简称'][0]
rename = name1 + ye
for a in range(len(df)):
if df['name'][a] == '%s年年报'%rename:
href0 = df.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
p_a = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
p_span = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_data(df_txt):
prefix_href = 'http://www.sse.com.cn/'
df = df_txt
ahts = [get_link(td) for td in df['公告标题']]
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['名称']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
})
return(df)
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
dropdown = driver.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
time.sleep(1)
for i in range(len(sse)):
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告")
code = sse['code'][i]
driver.find_element(By.ID, "inputCode").clear()
driver.find_element(By.ID, "inputCode").send_keys("%s"%code)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "全部").click()
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
soup = BeautifulSoup(innerHTML)
html = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html)
n = len(trs)
for i in range(len(trs)):
if n >= i:
if len(trs[i]) == 5:
del trs[i]
n = len(trs)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'名称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
df_data = get_data(df)
df_data = pd.concat([df_data, df['公告时间']], axis=1)
df_data['公告时间'] = pd.to_datetime(df_data['公告时间'])
df_data['year'] = df_data['公告时间'].dt.year
df_data['year'] = df_data['year'] - 1
name = df_data['简称'][0]
df_data['简称'] = name
p_zy = re.compile('.*?(摘要).*?')
for i in range(len(df_data)):
a = p_zy.findall(df_data['公告标题'][i])
if len(a) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_nb = re.compile('.*?(年度报告).*?')
p_nb2 = re.compile('.*?(年报).*?')
for i in range(len(df_data)):
b1 = p_nb.findall(df_data['公告标题'][i])
b2 = p_nb2.findall(df_data['公告标题'][i])
if len(b1) == 0 and len(b2) == 0:
df_data.drop([i],inplace = True)
df_data = df_data.reset_index(drop=True)
p_bnb = re.compile('.*?(半年).*?')
for i in range(len(df_data)):
c = p_bnb.findall(df_data['公告标题'][i])
if len(c) != 0:
df_data.drop([i],inplace = True)
df_data = df_data.drop_duplicates('year', keep='first', inplace=False)
df_data = df_data.reset_index(drop=True)
df_data['year_str'] = df_data['year'].astype(str)
df_data['name'] = name + df_data['year_str'] + '年年报'
name1 = df_data['简称'][0]
df_data.to_csv('%scsv文件.csv'%name1)
year = {'year': ['2013', '2014','2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']}
dy = pd.DataFrame(year)
os.mkdir('%s年度报告'%name)
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\%s年度报告"%name)
for y in range(len(dy)):
y = int(y)
ye = dy['year'][y]
name1 = df_data['简称'][0]
rename = name1 + ye
for a in range(len(df_data)):
if df_data['name'][a] == '%s年年报'%rename:
href0 = df_data.iat[a,3]
r = requests.get(href0, allow_redirects=True)
f = open('%s年度报告.pdf'%rename, 'wb')
f.write(r.content)
f.close()
r.close()
'''解析年报'''
hbcwsj = pd.DataFrame(index=range(2012,2021),columns=['营业收入','基本每股收益'])
hbsj = pd.DataFrame()
#i = 31
for i in range(len(hbe)):
name2 = hb1[2][i]
code = hb1['code']
dcsv = pd.read_csv(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\%scsv文件.csv"%name2)
dcsv['year_str'] = dcsv['year'].astype(str)
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\%s年度报告"%name2)
#r = 5
for r in range(len(dcsv)):
year_int = dcsv.year[r]
if year_int >= 2012:
year2 = dcsv.year_str[r]
aba = name2 + year2
doc = fitz.open(r'%s年度报告.PDF'%aba)
text=''
for j in range(22):
page = doc[j]
text += page.get_text()
#p_year = re.compile('.*?(\d{4}) .*?年度报告.*?')
#year_int = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
#p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]*)\s?(?=\n)')
p_rev = re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)')
revenue = float(p_rev.search(text).group(1).replace(',',''))
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n([-\d+,.]*)\s?(?=\n)')
#p_eps = re.compile('(?<=\n)基本每股收益.*?\n.*?\n?([-\d+,.]+)\s?(?=\n)')
p_eps = re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)')
eps = float(p_eps.search(text).group(1))
#p_web = re.compile('(?<=\n)公司.*?网址.*?\n(.*?)(?=\n)')
p_web = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)')
web = p_web.search(text).group(1)
p_site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)')
site = p_site.search(text).group(1)
hbcwsj.loc[year_int,'营业收入'] = revenue
hbcwsj.loc[year_int,'基本每股收益'] = eps
hbcwsj = hbcwsj.astype(float)
hbcwsj.to_csv(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\%s财务数据.csv"%name2)
hbsj = hbsj.append(hbcwsj.tail(1))
#with open('C:\Users\20279\Desktop\医药产业10年内年度报告\%s财务数据.csv'%name2,'a',encoding='utf-8') as f:
#content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name2,code,site,web)
# f.write(content)
hbsj.index = Series(hb[2])
hbsj.sort_values(by='营业收入',axis=0,ascending=True)
hbsj2 = hbsj.head(5)
hbsj2['name'] = hbsj2.index
hbsj2 = hbsj2.reset_index(drop=True)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.grid(True)
plt.title('营业收入')
i=0
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\s%财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['rev']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
os.chdir(r"C:\Users\de'l\Desktop\医药产业10年内年度报告")
plt.savefig('十家营业收入最高的公司的收入走势图')
plt.clf()
plt.xlabel('年份')
plt.ylabel('eps')
plt.grid(True)
plt.title('每股收益')
for i in range(len(hbsj2)):
name3 = hbsj2.name[i]
cwsj = pd.read_csv(r"C:\Users\de'l\Desktop\医药产业10年内年度报告\s%财务数据.csv"%name3)
cwsj.columns = ['year', 'rev', 'eps']
x = cwsj['year']
y = cwsj['eps']
plt.plot(x, y, label='%s'%name3, marker = 'o')
plt.legend(loc='upper left')
plt.savefig('十家营业收入最高的公司的eps走势图')
plt.clf()
这学期的实验报告难度对我来说非常大,因为本身就不擅长这个领域,但是在老师的指导和帮助下,我慢慢掌握了方法,花费了大量时间和心血,认真抓住每个细节,才完成了这个报告。
通过一个学期对于金融数据获取与处理课程的学习,我学习到了如何使用Python对大批量的数据进行处理的便捷,也深感这门课给我带来的收获,最后要感谢吴老师的悉心教导和耐心解答,让我对Python有了更深层次的理解,我会推荐其他同学选择这门课程的。