STEP1:获取股票及其代码列表
import fitz
import pandas as pd
import pdfplumber
import numpy as np
pdf = pdfplumber.open(r'C:\Users\34618\Desktop\课程数据\行业分类.pdf')
page = pdf.pages[74] #保留鄙人将要使用行业
table = page.extract_table()
df = pd.DataFrame(table)
df.to_excel(r"C:\Users\34618\Desktop\课程数据\行业分类.xlsx", \
header=False, index=False)
df_c0=pd.read_excel(r'C:\Users\34618\Desktop\课程数据\行业分类.xlsx',\
header=0,index_col=None,converters={'上市公司代码':str})
num=df_c0.loc[df_c0['行业大类代码']==45].index.values[0]
num1=df_c0.loc[df_c0['行业大类代码']==46].index.values[0]
df_c=df_c0.loc[num:num1-1] #保留鄙人将要使用行业
df_c=df_c[df_c['上市公司代码']>='600000']#保留可用的6开头的行业代码
df_c=df_c.iloc[:10] #取前十代码
list=df_c['上市公司代码'] #保留代码
list1=df_c['上市公司简称'] #公司名称
list2=list+' '+list1
np.array(list2)
结果展示
需要分析的上市公司,保存为html文件
STEP2:获取可用年报列表
def get_table_sse(code,filename):
browser = webdriver.Chrome()
browser.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code)
time.sleep(5)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(5)
selector = "body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div >div.sse_colContent.js_regular > div.table-responsive > table"
element = browser.find_element(By.CSS_SELECTOR, selector)
table_html = element.get_attribute('innerHTML')
element0 = browser.find_elements(By.LINK_TEXT, "下一页")
if element0 != []:
browser.find_element(By.LINK_TEXT, "下一页").click()
element1 = browser.find_element(By.CSS_SELECTOR, selector)
table_html1 = element1.get_attribute('innerHTML')
table_html1 = table_html1.strip('<thead><tr><th>证券代码</th><th>证券简称
</th><th>\公告标题</th><th>公告时间</th></tr></thead><tbody><tr><td')
table_html1 ='</span></a></td><td '+table_html1
else:
table_html1=''
fname=f'{filename}.html'
f = open(fname,'w',encoding='utf-8')
f.write(table_html+table_html1)
f.close()
#
browser.quit()
for (i,j) in zip(list,list1):
get_table_sse(i,i+' '+j)
结果展示
html文件实例如下,共有10个,此处示例一个

STEP3:获取年报下载链接,保存为csv文件
###########获取年报下载链接
def get_data(tr):
p_td = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = p_td.findall(tr)
#
s = tds[0].find('>') + 1
e = tds[0].rfind('<')
code = tds[0][s:e]
#
s = tds[1].find('>') + 1
e = tds[1].rfind('<')
name = tds[1][s:e]
#
s = tds[2].find('href="') + 6
e = tds[2].find('.pdf"') + 4
href = 'http://www.sse.com.cn' + tds[2][s:e]
s = tds[2].find('$(this))">') + 10
e = tds[2].find('')
title = tds[2][s:e]
#
date = tds[3].strip()
data = [code,name,href,title,date]
return(data)
# data = get_data(trs_new[1])
def parse_table(table_html):
p = re.compile('<tr>(.+?)</tr>', re.DOTALL)
trs = p.findall(table_html)
#
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#
data_all = [get_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({
'code': [d[0] for d in data_all],
'name': [d[1] for d in data_all],
'href': [d[2] for d in data_all],
'title': [d[3] for d in data_all],
'date': [d[4] for d in data_all]
})
return(df)
for i in list2:
f = open('{}.html'.format(i), encoding='utf-8')
html = f.read()
f.close()
df = parse_table(html)
df0=df.set_index('date')
df0=df0[:'2014-00-00']
list_1=[]
df0=df0.reset_index()
for j in range(len(df0)):
if '摘要' in df0['title'][j] or '修订稿' in df0['title'][j] or '更正版' in df0['title'][j] or '修订版' in df0['title'][j]:
list_1.append(j)
if '年度报告' not in df0['title'][j] and '年报' not in df0['title'][j]:
list_1.append(j)
df0.drop(df0.index[list_1],inplace=True)
if i == '600635 大众公用':
df0.drop(1,inplace=True)
df0 = df0.reset_index(drop=True)
df0.to_csv('{}.csv'.format(i))
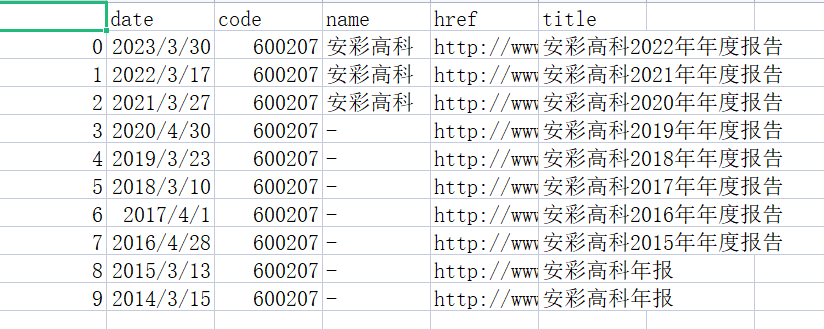
结果展示
csv文件实例如下,共有10个,此处示例一个
STEP4:下载年报
##########下载年报
for name in list2:
data0= pd.read_csv('{}.csv'.format(name), index_col=0, parse_dates=True)
j=0
for i in data0['href']:
href = i
r = requests.get(href, allow_redirects=True)
f = open('{}{}.pdf'.format(name,data0['date'][j][:4]), 'wb')
j=j+1
f.write(r.content)
f.close()
结果展示
下载的年报,共87个
STEP5:获取年报信息,做成csv文件
import pandas as pd
import fitz
import pandas as pd
def parse_key_fin_data(subtext):
keywords = ['营业收入','股东的净利润']
ss = []
for kw0 in keywords:
if len(kw0) == 4:
txt = subtext
x = re.search("(营)[' ','\n','业','收']*(入)", txt)
kw0=x.group()
else:
txt = subtext
x = re.search("(股)[' ','\n','东','的','净','利']*(润)", txt)
kw0=x.group()
n = subtext.find(kw0,0)
ss.append(n)
s = n + len(kw0)
ss.append(len(subtext))
data = []
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtext[s:e]
data.append(line.split())
return (data)
dff = pd.DataFrame()
list=list2.tolist()
for name in list:
data0= pd.read_csv('{}.csv'.format(name), index_col=0, parse_dates=True)
dfff = pd.DataFrame()
for j in range(len(data0)):
doc = fitz.open('{}{}.pdf'.format(name,data0['date'][j][:4]))
text = ''
for page in doc:
text += page.get_text()
s = text.find('主要会计数据 ')
subtext = text[s-50:]
e = subtext.find('总资产')
subtext = subtext[:e]
data = parse_key_fin_data(subtext)
al=0
for el in data[1][0:7]:
al1=0
for em in data[0][0:6]:
if el[0]<'a' and em[0]<'a':
df = pd.DataFrame({'指标':[d[0] for d in data],'{}'.format(int(data0['date']
[j][:4])-1):[float(data[0][al1].replace(',','')),float(data[1][al].replace(',',''))]
})
break
al1+=1
al+=1
if el[0]<'a' and em[0]<'a':
break
if '单位:元' in subtext:
df['{}'.format(int(data0['date'][j][:4])-1)] = round(df['{}'.format(int(data0['date'][j][:4])-1)]/10000,2)
df=df.set_index('指标').T
df.columns=['{}营业收入'.format(name),'{}股东的净利润'.format(name)]
dfff = pd.concat([dfff,df],axis=0)
dff= pd.concat([dfff,dff],axis=1)
dff.fillna(0,inplace=True)
dff.to_csv('公司年报数据.csv')
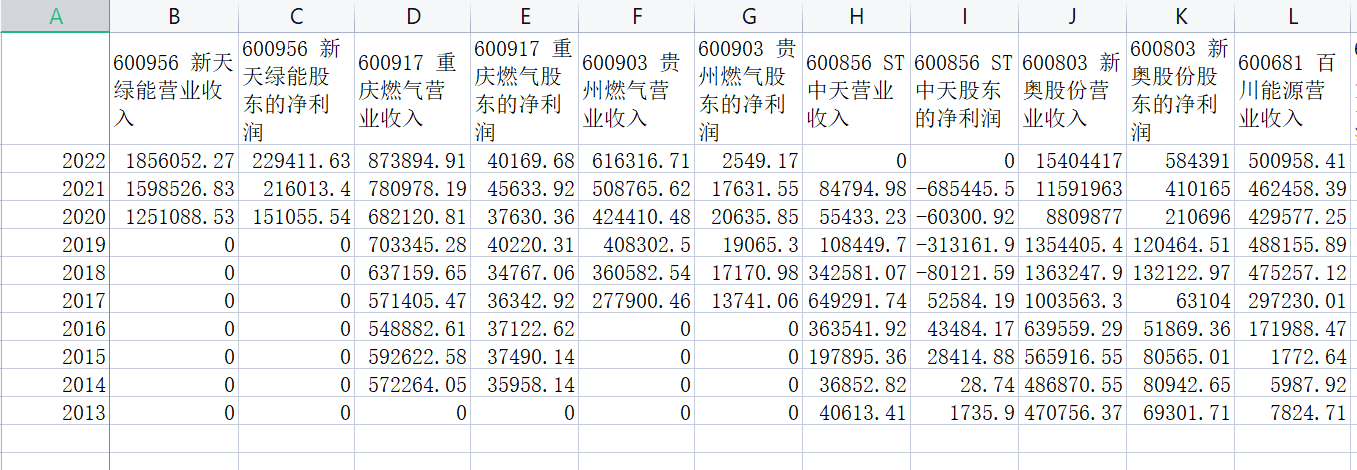
结果展示
公司年报数据,csv展示
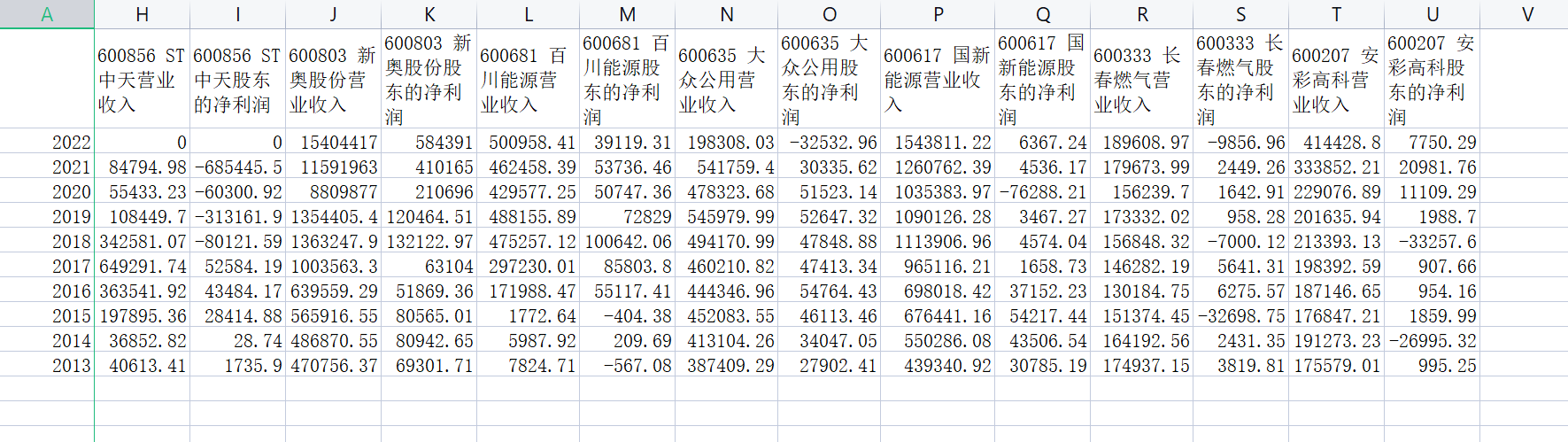
STEP6:公司信息可视化
##########画图
dff= pd.read_csv('公司年报数据.csv', index_col=0, parse_dates=True)
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['FangSong']
mpl.rcParams['axes.unicode_minus']=False
markerall=['*','o','s','D','H','h','^','+','<','>']
linestyleall=['-','-.','--',':','-','-.','--',':','-','-.']
fig,ax=plt.subplots()
fig1,ax1=plt.subplots()
for i in range(10):
na=dff.iloc[:,::2].columns[i]
na1=dff.iloc[:,1::2].columns[i]
dff.iloc[:,::2].plot(y=na,title='营业收入 单位:万元',grid='-',linestyle=linestyleall[i],marker=markerall[i],markersize=10,ax=ax)
dff.iloc[:,1::2].plot(y=na1,title='股东的净利润 单位:万元',grid='-',linestyle=linestyleall[i],marker=markerall[i],markersize=10,ax=ax1)
结果展示
公司年报数据可视化,图片展示
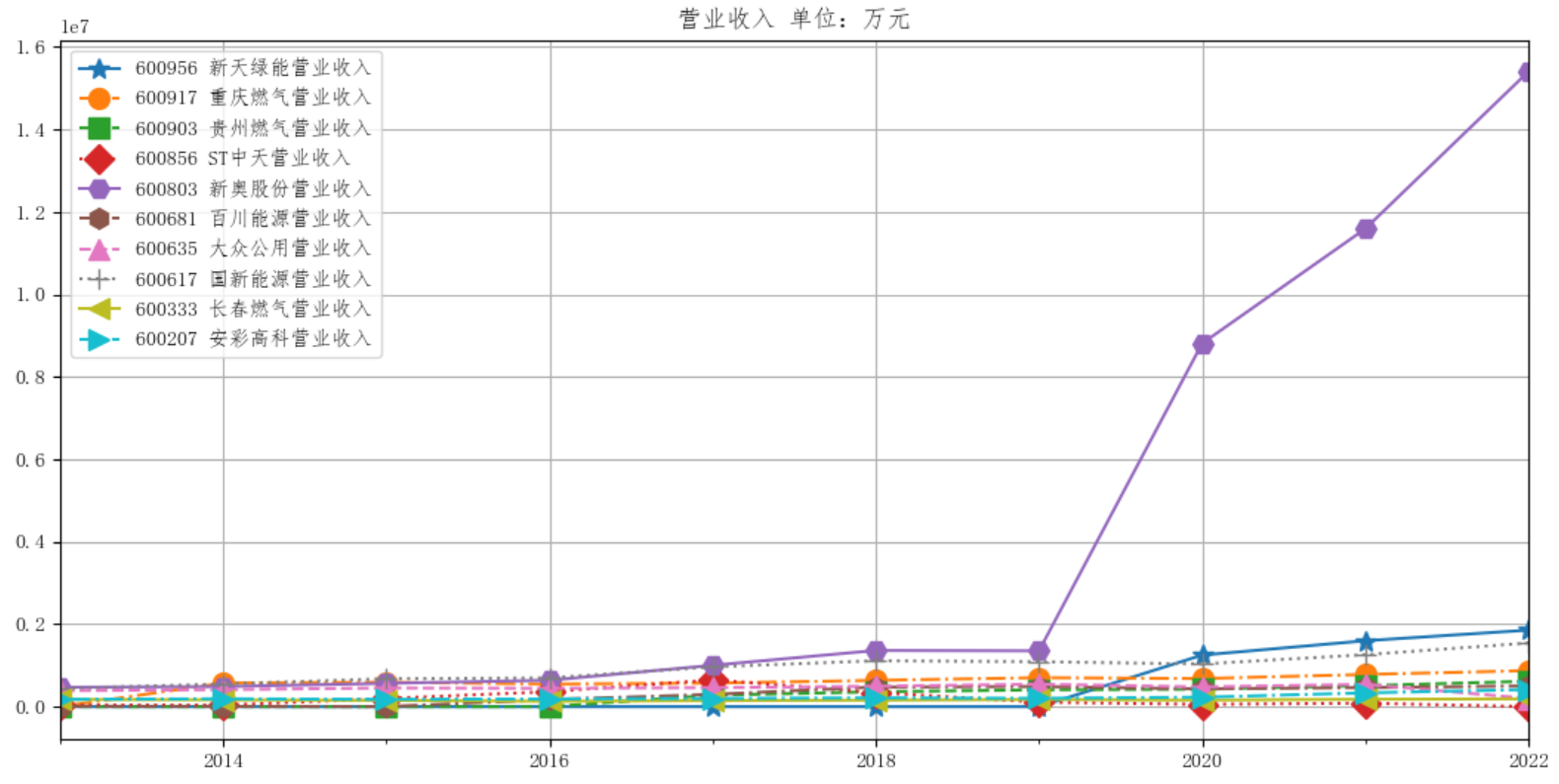

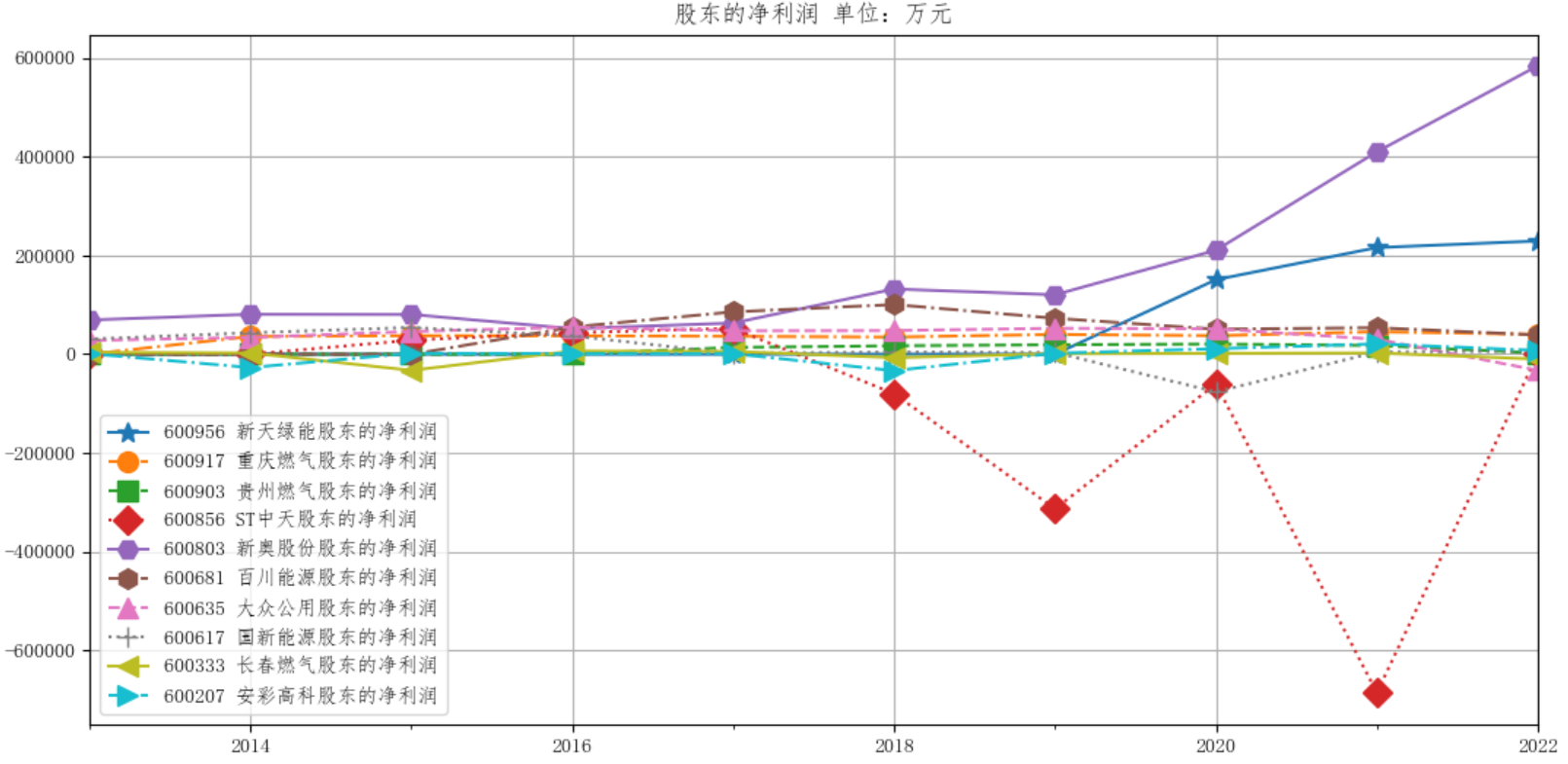
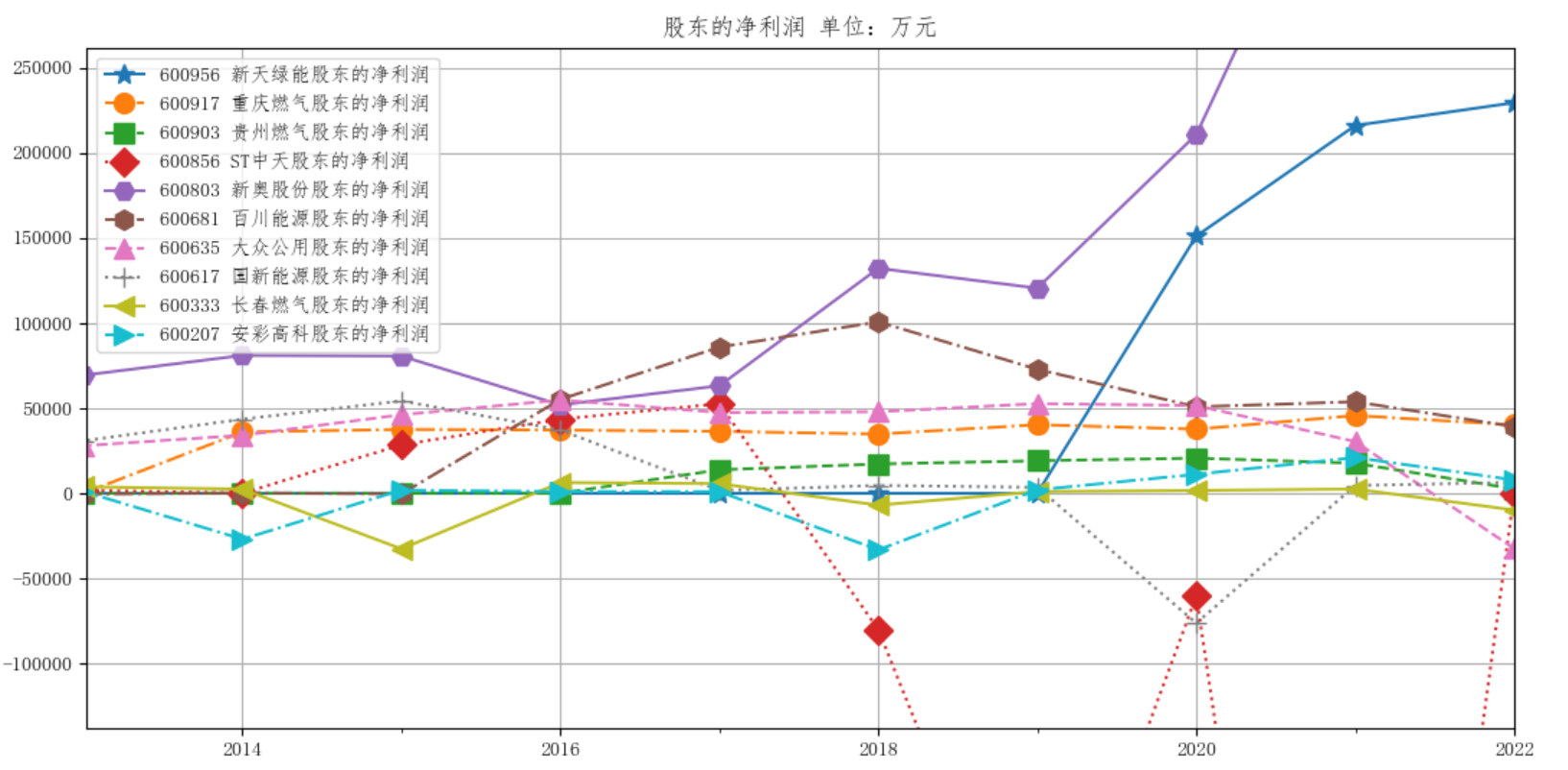
燃气生产和供应业解读与分析
- 1、行业总体解读
- 2、各公司解读
燃气生产和供应业行业总体上在2023年之前发展稳中向好。除了st中天(已经退市)和常春燃气营业收入近年来总体上营业收入没有增长外,其他公司的营业收入整体上随时间上升。新奥股份的营业收入涨的最快,其于2019被并购。各公司的归属于上市公司股东的净利润 总体上波动比较大,除了st中天、新奥股份波动剧烈和新天绿能的归属于上市公司股东的净利润实现增长外,其他公司的波动较为平均。
1. 新天绿能是近几年上市的公司,主要从事新能源和清洁能源的开发与利用,旗下拥有两大业务板块:风电业务和天然气业务。 可以看到其年报从20年开始公布,它营业收入稳定上升,营业收入2020-2023年分别为125,159,185亿人民币,增长稳定。而其归属于上市公司股东的净利润每年也在增长。这主要是因为近年国家扶持绿色能源,位于风口。
2. 重庆燃气集团于2014年上市,主营业务为重庆市管道燃气供应及燃气设施、设备的安装服务,综合服务,综合能源等。其营业收入增长较为缓慢,但是增长很稳定,在14年营业收入为57亿,22年为87亿。各年的归属于上市公司股东的净利润在3.6亿左右,很稳定。这可能与其市场规模固定,市场需求固化有关。
3. 贵州燃气主要从事城市燃气运营,主要业务为燃气销售及天然气支线管道、城市燃气输配系统、液化天然气接收储备供应站、加气站等设施的建设、运营、服务管理,以及相应的工程设计、施工、维修。可以看到贵州燃气于2017年上市,2017-2022年,营业收入稳定增长,由27亿增长为61亿,涨幅较大,各年的归属于上市公司股东的净利润在1.8亿左右。涨幅比较大,主要是因为近年国家扶持农村,为农村地区大力安装燃气管道,而贵州地区大部分比较偏远,所以增长比较快。
4. ST中天(中兴天恒能源科技股份公司)在2022年退市,主营业务为天然气的生产和销售,海外油气资产的并购、投资及运营。其营业收入2018年之前稳定增长,在2018年开始大幅下跌,2018年开始归属于上市公司股东的净利润为负值,22年该公司破产。
5. 新奥天然气股份有限公司于2019年并购重组,主要业务包含天然气销售业务、工程建造及安装业务、能源生产业务、综合能源业务及增值业务、基础设施运营。可以看到其营业收入一直是增长的,在2019年并购重组后实现大幅增长,2020年翻了六倍。其归属于上市公司股东的净利润增长趋势也大致如此。
6. 百川能源(原名万鸿集团)在2016年转型燃气行业,主要从事城市燃气业务,主营业务为城市管道燃气销售、燃气工程安装、燃气具销售。转型前其营业收入逐年下跌,到了0.17亿,转型后增长到17亿,并且开始逐年上升。
7. 上海大众公用事业集团(大众公用)主要从事天然气下游需求端的城市燃气业务,包括居民及商业用气,主要业务范围包括燃气销售和管道施工,经营模式为向上游供应商购买气源后,通过自有管网体系,销售给终端客户并提供相关输配服务。其营业收入近十年在45亿左右,波动比较小,增长不明显,但是在2022年大幅下跌,且此年的归属于上市公司股东的净利润变成负值,营收出现亏损。
8. 国新能源主要业务为天然气开发利用与咨询服务;燃气经营;储气设施租赁服务;集中供热项目的开发、建设、 经营、管理、供热系统技术咨询及维修;天然气灶具、仪器仪表设备的生产、加工、销售;信息技术开发与咨询服务。其营业收入逐年稳定增长,归属于上市公司股东的净利润除2022年外都为正值。
9.长春燃气终主要从事城市管道燃气业务、市政工程建设(设计、施工、监理)业务、综合能源利用业务及延伸业务。其营业收入在2013-2016年处于下降趋势,于2017年实现稳定增长。主要原因为2015 年9 月30 日,公司宣布全部停止煤焦化业务,完成资产结构调整,2016 年业务成为单一燃气,于是公司扭亏为盈。
10.安彩高科主营业务包括光伏玻璃、浮法玻璃和天然气业务。光伏玻璃业务主要经营光伏玻璃的生产和销售。其营业收入逐年稳定增长直到2020年,增长率较为正常,2021年实现大幅增长。主要因为2021年一季度光伏玻璃市场需求旺盛,产品价格处于高位。