#通过控制selenium来下载好PDF文件。这里通过使用书上的代码,操控虚拟浏览器来单个下载文件
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import pandas as pd
import urllib.request
import re
import os
import time
import random
#这里利用selenium来操控浏览器寻找我们的目标公司,并且控制浏览器将PDF都下载下来。
browser = webdriver.Edge(executable_path='msedgedriver.exe')
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
#browser.find_element(By.ID, "inputCode").click()
#from selenium.webdriver.support.select import Select
#s = Select(browser.find_element(By.CSS_SELECTOR,"#query > div.mainquery-container > div:nth-child(5) > div > div"))
#s.select_by_value('最近十年')
# s.select_by_visible_text('文本信息')
element = browser.find_element(By.CSS_SELECTOR, ".input-left").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
element = browser.find_element(By.CSS_SELECTOR, ".active li:nth-child(114)").click()
element = browser.find_element(By.LINK_TEXT, "6月").click()
element = browser.find_element(By.CSS_SELECTOR, ".active > .dropdown-menu li:nth-child(1)").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
element = browser.find_element(By.CSS_SELECTOR, ".today > .tdcontainer").click()
element = browser.find_element(By.ID, "query-btn").click()
browser.find_element(By.CSS_SELECTOR,"#select_gonggao .glyphicon").click()
browser.find_element(By.LINK_TEXT,"年度报告").click()
element1 = browser.find_element(By.ID, 'input_code')
#element1.send_keys('科陆电子' + Keys.RETURN)
names=['科陆电子','奥普光电','雪迪龙','埃斯顿','先锋电子','威星智能','三晖电气','智能自控','雷赛智能','华盛昌']
#这里是为了储存html网址,通过网址来一步步筛选网页进行下载
ur1 ='https://www.szse.cn/disclosure/listed/fixed/index.html'
browser.get(ur1)
time.sleep(1)
data = browser.page_source
datas = []
datas.append(data)#把获取的第1页源代码存储到datas列表里
#for i in range(names):#这里为了演示写成range(3),爬取全部要改成range(pages)
# browser.find_element_by_xpath('//*[@id="pagination_title"]/u1/li[12]').click()
# time.sleep(2)
# data = browser.page_source
# datas.append(data)
# time.sleep(1)
alldata=''.join(datas)
browser.quit()
p_title='.*? '
p_date= '(.*?)'
title = re.findall(p_title, alldata)
href = re.findall(p_href, alldata)
date = re.findall(p_date,alldata)
for i in range(len(title)):
if '摘要' in title[i] or '更新前' in title[i]:
title[i]=''
href=[i]=''
date[i]=''
else:
title[i]=title[i]
href[i]=href[i]
date[i]=date[i]
while '' in title:
title.remove('')
while '' in href:
href.remove('')
while '' in date:
date.remove('')
for name in names:
element1.send_keys(name + Keys.RETURN)
time.sleep(3)
try:
# browser.find_element_by_xpath('//*[@id="pagination_title"]/u1/1i[12]').click()
#此处我观察了所有的PDF文件,发现最多的年报数量也只有21个,因此此处设置了21次下载次数
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[1]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[2]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[3]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[4]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[5]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[6]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[7]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[8]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[9]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[10]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[11]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[12]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[13]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[14]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[15]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[16]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[17]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[18]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[19]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[20]/td[3]/div/a/span[3]").click()
browser.find_element_by_xpath("/html/body/div[5]/div/div[2]/div/div[3]/div/div[1]/div/table/tbody/tr[21]/td[3]/div/a/span[3]").click()
time.sleep(30)
browser.quit()
except:
print('不是PDF文件')
#此处为定义函数,通过函数将PDF里面的数据解析成为csv文件以及表格等。
import fitz
import re
import pandas as pd
import os
# 读取年报
#doc = fitz.open(r"D:\anaconda\daima new\文件夹\pdf")
# 定位需要的内容
def get_target_subtxt(doc,bounds = (['主要会计数据及财务指标','主要会计数据和财务指标'],'归属于上市公司股东的净资')): #
# 默认设置为首页页码
start_pageno = 0
end_pageno = len(doc) - 1
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0][0] in doc[n].get_text()) or (bounds[0][1] in doc[n].get_text()):
start_pageno = n
break
# 获取下界页码
for i in range(start_pageno,len(doc)):
p = re.compile('(?:\s*\n*归\s*\n*属\s*\n*于\s*\n*上\s*\n*市\s*\n*公\s*\n*司\s*\n*股\s*\n*东\s*\n*的\s*\n*净\s*\n*资\s*\n*产\s*\n*)',re.DOTALL)
a = p.findall(doc[i].get_text())
if len(a)==0:
continue
elif bounds[1] in a[0].replace('\n','').replace(' ',''):
end_pageno = i
break
# 获取界定的内容
txt = ''
if start_pageno == end_pageno:
txt = doc[start_pageno].get_text()
else:
for _ in range(start_pageno,end_pageno + 1):
page =doc[_]
txt += page.get_text()
return txt
# 获取界定
def get_th_span(txt):
nianfen = '(20\d\d|199\d)\s*年末?' #
s = '{}\s*{}.*?{}'.format(nianfen,nianfen,nianfen)
p = re.compile(s,re.DOTALL)
matchobj_ = p.search(txt)
#
end = matchobj_.end()
year1 = matchobj_.group(1)
year2 = matchobj_.group(2)
year3 = matchobj_.group(3)
#
flag = (int(year1) - int(year2) == 1) and (int(year2) - int(year3) == 1)
while not flag:
matchobj_.search(txt[end:])
end = matchobj_.end()
year1 = matchobj_.group(1)
year2 = matchobj_.group(2)
year3 = matchobj_.group(3)
flag = int(year1) - int(year2) == 1
flag = flag and (int(year2) - int(year3) == 1)
return ([year1,year2,year3],matchobj_.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)[1]
end = th_span_1st[1]
th_span_2nd = get_th_span(txt[end:])[1]
th_span_2nd = (end + th_span_2nd[0],end + th_span_2nd[1])
#
s = th_span_1st[1]
e = th_span_2nd[0]-1
while txt[e] not in '0123456789':
e = e-1
return (s,e+1)
# 提取关键字
def get_keywords(subtxt):
p = re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)')
keywords = p.findall(subtxt)
if '营业收入' not in keywords:
keywords.insert(0,'营业收入')
for i in keywords:
if len(i) <= 3:
keywords.remove(i)
for x in keywords:
if ('股份有限公司' or '年度报告') in x:
keywords.remove(x)
return keywords
# 提取成表格
def parse_key_fin_data(subtxt,keywords):
'''
将已知的数据提取成表格
'''
ss = []
s= 0
for kw in keywords:
n = subtxt.find(kw,s)
ss.append(n)
s = n +len(kw)
ss.append(len(subtxt))
data = []
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
p3 = re.compile('(\s*\n*\-*(\d{1,3}(?:,\d{3})*(?:\.\d+)?(?:\%)?)\s*){3,4}',re.DOTALL)
for n in range(len(ss)-1):
s = ss[n]
e = ss[n+1]
line = subtxt[s:e]
# 获取可能换行的账户名
matchobj = p.search(line)
account_name = matchobj.group().replace('\n','')
account_name = p2.sub('',matchobj.group())
# 获取3年数据
#amnts = line[matchobj.end():].split()
#
matchobjs = p3.search(line)
amnts = matchobjs.group().split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
#
def pdf_sum_pa(paths,fil_name):
'''
将上述函数汇总,并将解析出来的结果
保存为一个csv文件
'''
pdf_path = '{}\{}'.format(paths,fil_name)
doc = fitz.open(r'{}'.format(pdf_path)) # r'E:/张艺轩/计算机实验/金融数据获取与处理/nianbao/src/nianbao/data/pdf_data/002028/002028_2022.pdf'
# 获取大致范围的文本
txt = get_target_subtxt(doc)
# 建立列名
col = [ x for x in get_th_span(txt)[0]]
col.insert(-1,'变动')
# 获取精确范围
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
# 获取项目名称
keywords = get_keywords(subtxt)
# 建立成列表族
datas = parse_key_fin_data(subtxt,keywords)
# 换成DataFame
df = pd.DataFrame(datas,columns=col)
new_dirs = r"D:\anaconda\daima new\文件夹\csv数据"
dir_name = new_dirs+'\{}'.format(fil_name[0:6])
if os.path.exists(dir_name) == False:
os.makedirs(dir_name)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
else:
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
#
def file_name_walk(file_dir):
'''
定义一个返回文件所在的绝对路径和
文件名的列表的函数
'''
file_path_lst = []
for x in os.walk(file_dir):
file_path_lst.append((x[0],x[2]))
return file_path_lst
# 临时定义一个起始页码的函数
def get_target(doc,bounds =['股票简称','信息披露及备置地点']):
# 默认设置为首页页码
start_pageno = 0
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0] or bounds[0]) in doc[n].get_text():
start_pageno = n
break
return start_pageno
# 从文件中获取csv表格,以调用出所需数据
file_dir = r'D:\anaconda\daima new\文件夹\pdf_data'
pdf_path = file_name_walk(file_dir)
del pdf_path[0]
for ele in pdf_path[-2:]:
for name_ in ele[1]:
try:
pdf_sum_pa(ele[0],name_)
except Exception as e:
print('--------------------------------------------------')
print(name_,'出现异常.错误类型为:',e)
# 利用pdfplumber进行提取
new_pos = '{}/{}'.format(ele[0],name_)
new_dirs = r'D:\anaconda\daima new\文件夹\csv_data'
dir_name = new_dirs+'\{}'.format(name_[0:6])
import pdfplumber
page = pdfplumber.open(new_pos).pages
for i in page:
if '主要会计数据和财务指标' in i.extract_text():
df = pd.DataFrame(i.extract_table())
df.columns = df.iloc[0]
df.drop(0,inplace = True)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,name_[0:6],name_[7:-4]))
#
print(name_,'错误已解决,内容成功为pdfplumber所提取')
import chardet
#这里通过对于数据的调用,为后面的制图提供数据依据。由于此处的代码对于我来说过于困难,因此我请教了杨真同学和张艺轩同学,在他们的帮助下完成了这部分的代码完成
file_dir = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/csv_data'
file_pos = file_name_walk(file_dir)
del file_pos[0]
Series_Data_Path = 'D:/Ana/.spyder-py3/nianbao/src/nianbao/Series_data'
for i in file_pos:
joint_lst = []
for x in i[1]:
#用chardet库检测文件编码方式,并使用正确的编码方式进行解码,避免出现无法解码的情况
with open('{}/{}'.format(i[0],x), 'rb') as f:
content = f.read()
encoding = chardet.detect(content)['encoding']
df = pd.read_csv('{}/{}'.format(i[0],x), dtype=object, encoding=encoding)
# df = pd.read_csv('{}/{}'.format(i[0],x),dtype = object,encoding='gb2312')
if 'Unnamed: 0' in df.columns:
df = df.drop('Unnamed: 0', axis=1)
lst = ['营业收入(元)','营业收入',
'归属于上市公司股东的净利润(元)',
'归属于上市公司股东的净利润']
# keys_ = '|'.join(lst)
df = df[df['指标'].isin(lst)].iloc[:,0:2]
df.index = range(len(df))
df = df.T
df.columns = df.iloc[0]
df.drop(index = '指标',inplace = True)
# df
joint_lst.append(df)
Series_Data = pd.concat(joint_lst,axis = 0)
for i in Series_Data.index:
# 用any判断是否有些行的内容与列相同,如果True,则删去与列相同的行
if any(Series_Data.columns == Series_Data.loc[i]) == True:
Series_Data.drop(i,inplace = True)
#Series_Data.index = range(len(Series_Data))
Series_Data.to_csv('{}/{}.csv'.format(Series_Data_Path,x[0:6]),encoding = 'ANSI')
# 提取10家公司营业收入时间序列
series_pos = "D:\anaconda\daima new\文件夹\Series_data"
csv_name = os.listdir(series_pos)
# 创建代码名称字典
code_ = ['002122','002338','002658','002747','002767','002849','002857','002877','002979','002980']
values = ['科陆电子','奥普光电','雪迪龙','埃斯顿','先锋电子','威星智能','三晖电气','智能自控','雷赛智能','华盛昌']
nvs = zip(code_,values)
nvDict = dict( (name,value) for name,value in nvs)
merge_lst = []
for _ in csv_name:
df = pd.read_csv('{}/{}'.format(series_pos,_),encoding = 'ANSI',dtype = object,index_col = 0)
df_revenue = df.iloc[:,0]
df_revenue.rename(nvDict[_[0:-4]],inplace = True)
df_revenue.columns = [nvDict[_[0:-4]]]
merge_lst.append(df_revenue)
revenue_series = pd.concat(merge_lst,axis = 1)
year_data = revenue_series.applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000)
# 合并上市公司股东净利润的时间序列表格
merge_lst_1 = []
for _ in csv_name:
df = pd.read_csv('{}/{}'.format(series_pos,_),encoding = 'ANSI',dtype = object,index_col = 0)
df_profit = df.iloc[:,1]
df_profit.rename(nvDict[_[0:-4]],inplace = True)
df_profit.columns = [nvDict[_[0:-4]]]
merge_lst_1.append(df_profit)
profit_series = pd.concat(merge_lst_1,axis = 1)
profit_data = profit_series.applymap(lambda x : x.replace(',','')).applymap(pd.to_numeric).applymap(lambda x : x/10000)
#此处为画图部分
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 字体的路径
import plotly
import plotly.graph_objs as go
import numpy
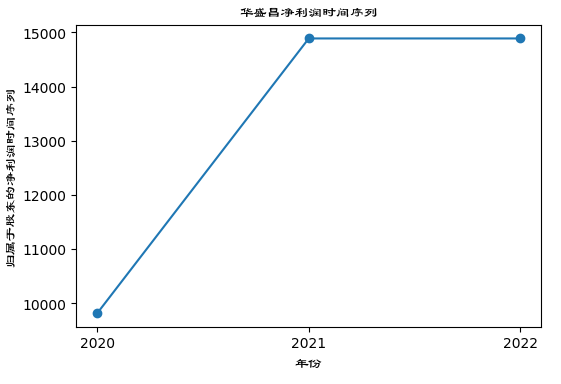
#归属于股东的净利润时间序列
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 150
#x = np.arange(2020, 2023)
plt.plot(profit_data.iloc[:,0],label = profit_data.iloc[:,0].name)
plt.title("华盛昌净利润时间序列", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("归属于股东的净利润时间序列", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
plt.plot(x,y, marker = 'o')
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
ax.plot(year_data.iloc[:,0],label = revenue_series.iloc[:,0].name)
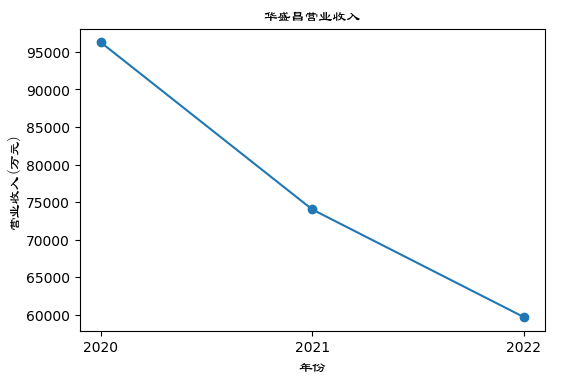
plt.title("华盛昌营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax1=plt.plot(x,y, marker = 'o')
#由于后面代码一直运行失败,我对于python知识的了解还很浅薄,无法找出错误,因此后面的数据由我手动输入。
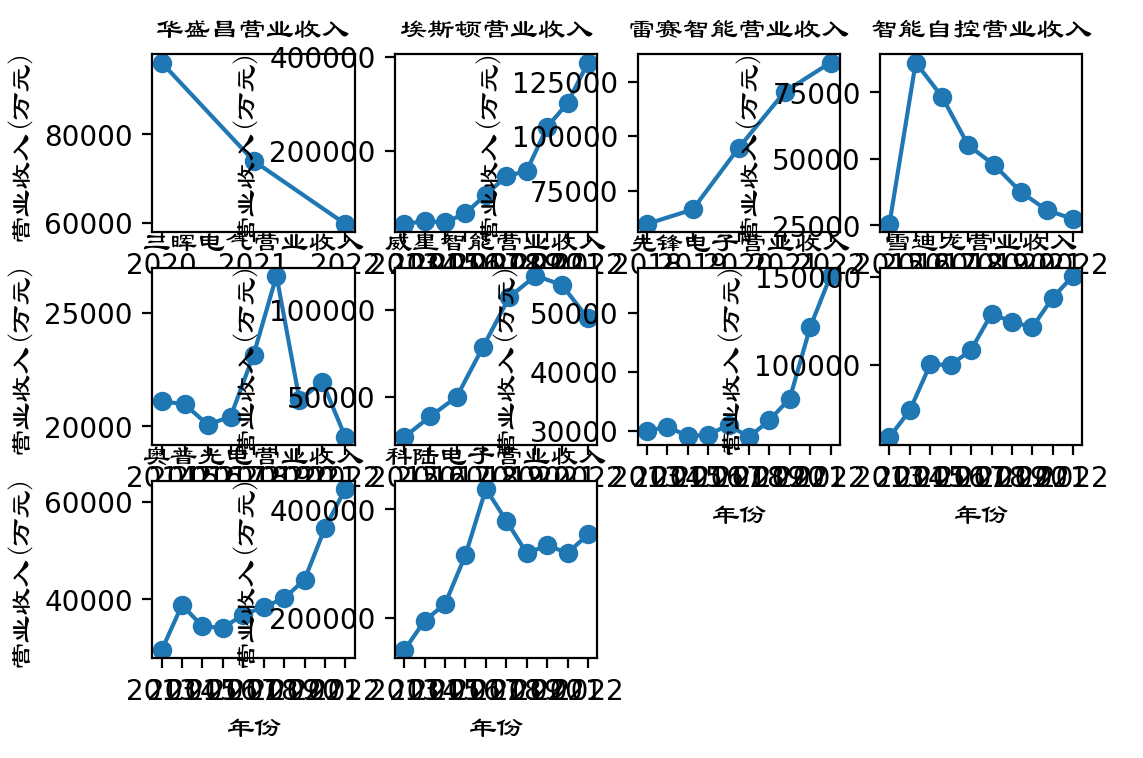
plt.subplot(3, 4, 1)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2020', '2021', '2022'])
y = np.array([96266.08, 74005.16, 59677.53])
plt.title("华盛昌营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax1=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 2)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2013','2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([45012.68, 51186.67, 48314.41, 67834.97, 107650.31, 146102.45, 158126.11, 251016.65, 302037.73, 388077.85])
plt.title("埃斯顿营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax2=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 3)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2018','2019','2020', '2021', '2022'])
y = np.array([59650.78, 66326.39, 94642.62, 120315.81, 133786.21])
plt.title("雷赛智能营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax3=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 4)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([25534.56, 86250.15, 73420.15, 55172.47, 47661.37, 37605.11, 30742.31, 27362.83])
plt.title("智能自控营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax4=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 5)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([21103.40, 20977.86, 20080.04, 20420.73, 23142.07, 26643.08, 21172.80, 21954.49,19521.76])
plt.title("三晖电气营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax5=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 6)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([26955.05, 38994.21, 50150.07, 78854.74, 107410.56, 119814.47, 114548.06, 95253.46])
plt.title("威星智能营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax6=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 7)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2013','2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([29942.55, 30672.42, 29114.74, 29291.24, 30980.99, 28902.25, 31774.83, 35444.11, 47553.90, 56263.36])
plt.title("先锋电子营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax7=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 8)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2013','2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([58899.73, 74148.03, 100235.47, 99811.98, 108424.85, 128879.23, 124328.63, 121279.51, 138091.21, 150477.15])
plt.title("雪迪龙营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax8=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 9)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2013','2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([29543.90, 38870.12, 34472.60, 34185.77, 36843.77, 38476.54, 40219.28, 44074.59, 54684.92, 62706.39])
plt.title("奥普光电营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax9=plt.plot(x,y, marker = 'o')
plt.subplot(3, 4, 10)
pyplt = plotly.offline.plot
fname = "C:\Windows\Fonts\SIMLI.TTF"
zhfont1 = fm.FontProperties(fname=fname)
plt.rcParams['figure.dpi'] = 200
#x = np.arange(2020, 2023)
x = np.array(['2013','2014','2015','2016','2017','2018','2019','2020', '2021', '2022'])
y = np.array([140878.45, 195460.88, 226142.33, 316190.46, 437602.57, 379132.13, 319532.50, 333728.89, 319816.19, 353881.62])
plt.title("科陆电子营业收入", fontproperties=zhfont1)
# fontproperties 设置中文显示,fontsize 设置字体大小
plt.xlabel("年份", fontproperties=zhfont1)
plt.ylabel("营业收入(万元)", fontproperties=zhfont1)
#plt.scatter(x, y)
#plt.show()
ax10=plt.plot(x,y, marker = 'o')
此次python作业的难度对我来说很大,在这次作业中,我很大程度上提示了自己对于python这门学科的认识。老师上课循循善诱,讲的内容也很丰富,可以很好的带领我们进一步学习python编程的知识。但我个人由于基础不牢,学习状态不足,个人能力等问题,并没有完全掌握老师所传授的知识,作业完成度也欠佳。但这次的挫败并不能打到我,我相信 在今后的学习中,如果我能以更加勤奋的姿态来学习python这门课程,我可以取得更大的进步。