按照老师的要求,依据证监会所发布的最新一版的行业分类,匹配到了计算机、通信和其他电子设备制造业的前10家公司。现将该行业前10家上市公司的基本信息列示如下。
| 上市公司代码 | 上市公司简称 |
|---|---|
| 000016 | 深康佳A |
| 000020 | 深华发A |
| 000045 | 深纺织A |
| 000050 | 深天马A |
| 000413 | 东旭光电 |
| 000561 | 烽火电子 |
| 000586 | 汇源通信 |
| 000636 | 风华高科 |
| 000725 | 京东方A |
| 000733 | 振华科技 |
该部分函数旨在定义爬取各大交易所交易所定期报告页面的函数, 并对爬取之后的页面进行信息提取。即提取出每一家公司的年报的名称、 pdf的链接等等,最终将这些指标保存为一个CSV文件。因为我的公司都是属于深交所,所以我只需到深交所官网爬取数据就行。
#深交所官网数据获取
import time
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#爬取网页
def get_table_szse(code):
driver = webdriver.Edge()
url= "http://www.szse.cn/disclosure/listed/fixed/index.html"
driver.get(url)
driver.set_window_size(1552, 832)
time.sleep(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(code)
time.sleep(3)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
time.sleep(3)
driver.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(3)
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
element = driver.find_element(By.ID, 'disclosure-table')
# add
time.sleep(5)
table_html = element.get_attribute('innerHTML')
fname=f'{code}.html'
f = open(r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\html_\{}'.format(fname),'w',encoding='utf-8')
f.write(table_html)
f.close()
driver.quit() #关闭网页
#循环获取每个网页
def get_table_szse_codes(codes):
for code in codes:
get_table_szse(code)
#HTML的解析
def get_szse_data(tr):
p_td = re.compile('(.*?)',re.DOTALL)
tds = p_td.findall(tr) #tds是一个列表,包含四个(.+?) ',re.DOTALL)
trs = p.findall(html)
# 找出不为空的“tr对”
trs_new = []
for tr in trs:
if tr.strip() != '':
trs_new.append(tr)
#del trs_new[0]
# 应用get_data()函数和提取code、name、herf、title 和 date;
data_all = [get_szse_data(tr) for tr in trs_new[1:]]
df = pd.DataFrame({'code':[d[0] for d in data_all],
'name':[d[1] for d in data_all],
'href':[d[2] for d in data_all],
'title':[d[3] for d in data_all],
'date':[d[4] for d in data_all]})
# 将时间序列标准化
df['date'] = df['date'].apply(pd.to_datetime)
#
return df
#筛选过滤出一些不必要的公告链接
#参考吴老师上课分享的代码
import pandas as pd
from datetime import datetime
def filter_links(words,df,include = True):
'''
筛选保留的年报链接
words : 保留或删除包含关键词列表
df :DataFrame
include : keep or exclude
Returns: a dataframe
'''
ls = []
for word in words:
if include:
ls.append([word in f for f in df['title']])
else:
ls.append([word not in f for f in df['title']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return df2
def filter_date(start,end,df):
start = pd.to_datetime(start)
end = pd.to_datetime(end)
date = df['date']
v = [d >= start and d <= end for d in date]
df_new = df[v]
return df_new
def start_end_10y():
df_now = datetime.now()
current_year = df_now.year
start = f'{current_year-9}-01-01'
end = f'{current_year}-12-31'
return (start,end)
#集成过滤函数
def filter_nb_10y(df,keepwords = ['年报','年度报告','更新后','更正后','更新'],
exclude_word = ['摘要','已取消','英文版','英文','更新前']
,start = '',end = ''):
if start == '':
start,end = start_end_10y()
else:
start_y = int(pd.to_datetime(start[0:4]))
end = '{}-12-31'.format(start_y + 9)
#
df = filter_links(keepwords,df,include=True)
df = filter_links(exclude_word,df,include= False)
df = filter_date(start,end,df)
return df
def prepare_hrefs_years(df):
hrefs = list(df['href'])
years = [str(int(d[0:4])-1) for d in df['date']]
code = list(df['code'])
return pd.DataFrame([code,hrefs, years],index = ['code','href','year']).T
import requests
import pandas as pd
import time
import os
#年报批量下载
def download_pdf(href, code, year):
'''
href :download link address.下载链接地址
code : 证券代码
year : 年报年份
'''
r = requests.get(href, allow_redirects=True)
path = "C:\\Users\\所念皆星河\\Desktop\\nianbao\\src\\nianbao\pdf_"
if os.path.exists(path+'\\{}'.format(code)) == True:
fname = '{}_{}.pdf'.format(code,year)
f = open(path+'\\{}\\{}'.format(code,fname), 'wb')
f.write(r.content)
f.close()
r.close()
else:
os.mkdir(path+'\\{}'.format(code)) #创建一个新的文件夹
fname = '{}_{}.pdf'.format(code,year)
f = open(path+'\\{}\\{}'.format(code,fname), 'wb')
f.write(r.content)
f.close()
r.close()
def download_pdfs(hrefs,code, years):
for i in range(len(hrefs)):
href= hrefs[i]
year = years[i]
download_pdf(href, code, year)
time.sleep(30)
return()
#下载年报用的最终函数
def download_pdfs_codes(list_hrefs, codes, list_years):
for i in range(len(list_hrefs)):
hrefs = list_hrefs[i]['href']
years = list_years
code= codes[i]
download_pdfs(hrefs, code, years)
return()
该部分利用之前定义的函数,先爬取HTML提取信息,过滤后保存为CSV文件。 而后通过读取CSV文件,访问每一张DataFrame的href列,获取pdf下载链接, 最终爬取到10家上市公司的10年的pdf格式的年报。运行结果如下所示。
import datetime
from szse import get_table_szse,get_table_szse_codes,get_szse_data,parse_szse_table
from filter_url import filter_words,filter_date,start_end_10y,filter_nb_10y,prepare_hrefs_years
from download import download_pdf,download_pdfs,download_pdfs_codes
import pandas as pd
import numpy as np
from parse_ar import get_target_subtxt,get_th_span,get_bounds,get_keywords,parse_key_fin_data,file_name_walk,pdf_sum_pa,get_target
import fitz
import re
import os
import pandas as pd
# ----------------------------------------HTML爬取-------------------------------------------------------
# 建立一个文件夹路径备用
paths = r"C:\Users\所念皆星河\Desktop\nianbao\src\nianbao"
# 过滤已经保存的CSV文件,去掉含有'摘要','已取消','英文版','英文'和'更新前'等字段的链接
obj = os.listdir(r"C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\html_")
#用于获取指定目录下的文件和文件夹列表。
for i in obj:
df = parse_szse_table(r'{}\html_\{}'.format(paths,i))
df = filter_nb_10y(df,keep_words = ['年报','年度报告','更新后','更正后','更新'],
exclude_words = ['摘要','已取消','英文版','英文','更新前']
,start = '',end = '')
df.to_csv(r'{}\csv_\{}.csv'.format(paths,i[0:6]))
#------------------------------------------下载年报-----------------------------------------------------
# 整理CSV,整理出符合要求的href列表
obj1 = os.listdir(r"C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\csv_")
list_hrefs = []
for i in obj1:
df = pd.read_csv(r'{}\csv_\{}'.format(paths,i),dtype = object) #必须dtype = object,否则前面的0将省略
temp = prepare_hrefs_years(df)
list_hrefs.append(temp)
list_hrefs[1] = list_hrefs[1].drop(2)
#重新排列索引为1-10
for df in list_hrefs:
df.reset_index(drop=True, inplace=True) # 重新排列索引为1-10
# 获取年报
download_pdfs_codes(list_hrefs,codes,list_hrefs[0]['year'])
所爬取的HTML文件列表、从CSV当中提取的信息组成的CSV文件及文件列表以及10家公司年报列表如下所示。
.png)
.png)
import fitz
import re
import pandas as pd
import os
# 定位需要的内容
def get_target_subtxt(doc,bounds = ('主要会计数据和财务指标','归属于上市公司股东的净资产')): #
# 默认设置为首页页码
start_pageno = 0
end_pageno = len(doc) - 1
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0] in doc[n].get_text()):
start_pageno = n
break
# 获取下界页码
for i in range(start_pageno,len(doc)):
p = re.compile('(?:\s*\n*归\s*\n*属\s*\n*于\s*\n*上\s*\n*市\s*\n*公\s*\n*司\s*\n*股\s*\n*东\s*\n*的\s*\n*净\s*\n*资\s*\n*产\s*\n*)',re.DOTALL)
a = p.findall(doc[i].get_text())
if len(a)==0:
continue
elif bounds[1] in a[0].replace('\n','').replace(' ',''):
end_pageno = i
break
# 获取界定的内容
txt = ''
if start_pageno == end_pageno:
txt = doc[start_pageno].get_text()
else:
for _ in range(start_pageno,end_pageno + 1):
page =doc[_]
txt += page.get_text()
return txt
# 获取界定
def get_th_span(txt):
nianfen='(20\d\d|199\d)\s*年末?'
s = '{}\s*{}.*?{}'.format(nianfen,nianfen,nianfen)
p= re.compile(s,re.DOTALL)
matchobj= p.search(txt)
#
end= matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
#
flag=(int(year1)-int(year2) == 1) and (int(year2)-int(year3) == 1)
while not flag:
matchobj.search(txt[end:])
end= matchobj.end()
year1=matchobj.group(1)
year2=matchobj.group(2)
year3=matchobj.group(3)
flag=int(year1) - int(year2) ==1
flag = flag and (int(year2) - int(year3) ==1)
return([year1,year2,year3],matchobj.span())
def get_bounds(txt):
th_span_1st = get_th_span(txt)[1]
end = th_span_1st[1]
th_span_2nd =get_th_span(txt[end:])[1]
th_span_2nd =(end+th_span_2nd[0],end+th_span_2nd[1])
#
s=th_span_1st[1]
e=th_span_2nd[0]-1
#
while txt[e] not in '0123456789':
e =e -1
return(s,e+1)
# 提取关键字
def get_keywords(txt):
p=re.compile(r'\d+\s*?\n\s*?([\u2E80-\u9FFF]+)') #\s匹配空格
keywords = p.findall(txt)
if '营业收入' not in keywords:
keywords.insert(0,'营业收入')
for i in keywords:
if len(i) <= 3:
keywords.remove(i)
for x in keywords:
if ('股份有限公司' or '年度报告') in x:
keywords.remove(x)
return keywords
# 提取成表格
def parse_key_fin_data(subtext,keywords):
#keywords= ["营业收入","营业成本","毛利","归属于上市","归属于上市","经营活动"]
ss=[]
s=0
for kw in keywords:
n= subtext.find(kw,s)
ss.append(n)
s=n+len(kw)
ss.append(len(subtext))
data= []
p = re.compile('\D+(?:\s+\D*)?(?:(.*)|\(.*\))?')
p2 = re.compile('\s')
p3 = re.compile('(\s*\n*\-*(\d{1,3}(?:,\d{3})*(?:\.\d+)?(?:\%)?)\s*){3,4}',re.DOTALL)
for i in range(len(ss)-1):
s=ss[i]
e =ss[i+1]
line= subtext[s:e]
#获取可能换行的账户名
matchobj = p.search(line)
account_name = matchobj.group().replace('\n','')
account_name = p2.sub('',matchobj.group())
# 获取3年数据
#amnts = line[matchobj.end():].split()
#
matchobjs = p3.search(line)
amnts = matchobjs.group().split()
#加上账户名称
amnts.insert(0,account_name)
#追加到总数据
data.append(amnts)
return data
#
def pdf_sum_pa(paths,fil_name):
'''
将上述函数汇总,并将解析出来的结果
保存为一个csv文件
'''
pdf_path = '{}\{}'.format(paths,fil_name)
doc = fitz.open(r'{}'.format(pdf_path)) # r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\pdf_\000016\000016_2013.pdf'
# 获取大致范围的文本
txt = get_target_subtxt(doc)
# 建立列名
col = [ x for x in get_th_span(txt)[0]]
col.insert(-1,'变动')
col.insert(0,'指标')
# 获取精确范围
span = get_bounds(txt)
subtxt = txt[span[0]:span[1]]
# 获取项目名称
keywords = get_keywords(subtxt)
# 建立成列表族
datas = parse_key_fin_data(subtxt,keywords)
# 换成DataFame
df = pd.DataFrame(datas,columns=col)
new_dirs = r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\csv_data'
dir_name = new_dirs+'\{}'.format(fil_name[0:6])
if os.path.exists(dir_name) == False:
os.makedirs(dir_name)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
else:
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,fil_name[0:6],fil_name[7:-4]))
#
def file_name_walk(file_dir):
'''
定义一个返回文件所在的绝对路径和
文件名的列表的函数
'''
file_path_lst = []
for x in os.walk(file_dir):
file_path_lst.append((x[0],x[2]))
return file_path_lst
# 临时定义一个起始页码的函数
def get_target(doc,bounds =['股票简称','信息披露及备置地点']):
# 默认设置为首页页码
start_pageno = 0
# 获取上界页码
for n in range(len(doc)):
# texts = page.get_text()
if (bounds[0] or bounds[0]) in doc[n].get_text():
start_pageno = n
break
return start_pageno
该部分内容,充分利用正则表达式,旨在按要求提取出10家上市公司“公司简称”“股票代码”“办公地址”“公司网址”“董秘电话”“董秘&公司电子信箱”等指标的关键信息。 数据以每家公司最新的年报为准,故而将每个公司最新的年报提取至2021年报文件夹中 如下
# ---------------------------------------提取公司信息------------------------------------------------
# 利用file_name_walk找出pdf_data下所有文件的路径和文件名
# 提前创建一个表格,以便于存储数据
keys_Data = pd.DataFrame(columns=['公司简称','股票代码','办公地址','公司网址','董秘电话','董秘&公司电子信箱'])
for i in abs_pos_lst:
docs = fitz.open(i)#i[0]+'\\{}'.format(n)
brief_ =docs[get_target(docs,bounds =['股票简称','信息披露及备置地点'])].get_text()
# name
cor_name_compile = re.compile('.*股票简称.*?\n(.*?)\s*\n*股票代码.*',re.DOTALL)
name = cor_name_compile.findall(brief_)[0].strip()
# code
cor_code_compile = re.compile('.*股票代码.*?\n(.*?)\s.*',re.DOTALL)
code = cor_code_compile.findall(brief_)[0].strip()
# address
cor_address_compile = re.compile('办公地址.*?\n(.*?)\s*\n.*?',re.DOTALL)
address = cor_address_compile.findall(brief_)[0].strip()
# web
cor_web_compile = re.compile('公司网址.*?\n\s*(.*?)\n电子信箱',re.DOTALL)
web = cor_web_compile.findall(brief_)[0].strip()
# secretary_telephone
sec_tel_compile = re.compile('.*电话.*?\n\s*(.*?)\s*\n.*?',re.DOTALL)
tele = sec_tel_compile.findall(brief_)[0].strip()
# secretary_mail
sec_mail_compile = re.compile('.*电子信箱.*?\n\s*(.*?)\n.*',re.DOTALL)
mail = sec_mail_compile.findall(brief_)[0].strip()
keys_Data.loc[len(keys_Data.index)] = {'公司简称':name,'股票代码':code,
'办公地址':address,'公司网址':web,
'董秘电话':tele,'董秘&公司电子信箱':mail}
keys_Data.to_csv(r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\all_information.csv',encoding = 'utf-8')
此处在提取会计数据表格时,我借鉴了张艺轩同学的方法,使用了“try-except”异常处理结构:如果格式正常,则正常执行“try”后的语句; 如果解析格式异常,则打印错误类型,执行except后面的内容(用pdfplumber提取)。这样就保证了保证程序的正常运行。
#-------------------------------------------表格提取------------------------------------------------------
# 提取每家公司每年的主要会计数据和财务指标,并保存为csv数据
file_dir = r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\pdf_'
pdf_path = file_name_walk(file_dir)
del pdf_path[0]
for ele in pdf_path:
for name_ in ele[1]:
# 利用异常处理结构,保证程序正常运行
try:
pdf_sum_pa(ele[0],name_)
except Exception as e:
print('--------------------------------------------------')
print(name_,'出现异常.错误类型为:',e)
# 利用pdfplumber进行提取
new_pos = '{}/{}'.format(ele[0],name_)
new_dirs = r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\csv_data'
dir_name = new_dirs+'\{}'.format(name_[0:6])
import pdfplumber
page = pdfplumber.open(new_pos).pages
for i in page:
if '主要会计数据和财务指标' in i.extract_text():
df = pd.DataFrame(i.extract_table())
df.columns = df.iloc[0]
df.drop(0,inplace = True)
df.to_csv(r'{}\{}_{}.csv'.format(dir_name,name_[0:6],name_[7:-4]))
#
print(name_,'错误已解决,内容成功为pdfplumber所提取')
接下来,从提取出来的表格提取“营业收入”“归属于上市公股东的净利润” 等字段在当年的数据,按照公司为类别合并成时间序列类型的表格。 执行代码如下所示。具体结果见下文“执行结果”一栏。
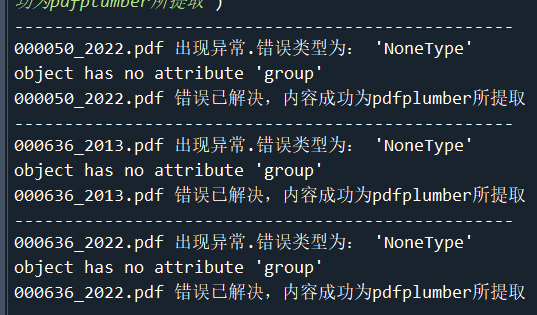
在本例中,经过检查,发现代码为000050的公司2022年、000636的公司的2013年与2022年的年报解析失败,原因是读取pdf出了错,由于我对这方面的理解不深,只能采取手动修改数据。修正的结果见下文的“错误解决.png”。
# ----获取每一家公司由10年“营业收入”“归属于上市公司股东的净利润”组成的的时间序列表格------
folder_path = r'C:\Users\所念皆星河\Desktop\nianbao\src\nianbao\csv_data'
folders = ['000016','000020','000045','000050','000413','000561','000586','000636','000725','000733']
# 定义年份范围
years = range(2013, 2023)
# 建立一个空的字典用于存储数据
data = {}
# 遍历每个文件夹
for folder in folders:
# 在每个文件夹中遍历每个年份
for year in years:
# 构建文件路径
file_path = os.path.join(folder_path, folder, f"{folder}_{year}.csv")
# 如果文件存在,则读取
if os.path.exists(file_path):
# 使用pandas读取csv文件,返回DataFrame对象
df = pd.read_csv(file_path)
if 'Unnamed: 0' in df.columns:
df = df.drop('Unnamed: 0', axis=1)
df=df.iloc[:2,0:2]
# 以(folder, year)作为键,DataFrame作为值存储在字典中
data["{}_{}".format(folder,year)] = df
#对data进行修改,('000050', 2022),('000636', 2022)两个数据出错,我选择直接根据pdf,手动修改。
da = pd.DataFrame([["营业收入(元)","31,447,476,894.80"], ["归属于上市公司股东的净利润(元)","112,521,171.81"]], columns=["指标", "2022"])
db = pd.DataFrame([["营业收入(元)","3,873,931,995.77"], ["归属于上市公司股东的净利润(元)","327,037,938.38"]], columns=["指标", "2022"])
dc = pd.DataFrame([["营业收入(元)","2,230,701,463.90"], ["归属于上市公司股东的净利润(元)","87,845,807.13"]], columns=["指标", "2013"])
data["{}_{}".format('000050', 2022)]=da
data["{}_{}".format('000636', 2022) ]=db
data["{}_{}".format('000636', 2013)]=dc
将每一个指标(以“营业收入”为例)时间序列按公司合并, 整理成时间序列类型的数据,方便后续绘图调用。
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['fangsong']
mpl.rcParams['axes.unicode_minus']=False
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# 定义一个字典,保存数据
data_dict = {}
# 遍历所有数据,将每个股票每一年的营业收入(元)保存在一个列表中
for key in data.keys():
stock_code = key.split('_')[0] # 获取股票代码
year = key.split('_')[1] # 获取年份
if '其他' in data[key] or str(year) not in data[key]:
continue
income = float(data[key][str(year)][0].replace(',', '')) # 获取营业收入并将其转换成浮点数
if stock_code not in data_dict:
# 如果字典中没有这个股票的记录,就新增一个字典
data_dict[stock_code] = {year:int(income)}
else:
# 如果有记录,就在这个股票对应的字典中新增一条记录
data_dict[stock_code][year] = int(income)
# 定义一个字典,保存每个股票的营业收入列表
income_dict = {}
# 遍历所有股票,保存每个股票的营业收入列表
for stock_code in data_dict.keys():
income_list = [] # 每个股票的营业收入列表
for year in range(2013, 2023):
# 如果这个年份没有营业收入记录就跳过
if str(year) not in data_dict[stock_code]:
continue
income_list.append(int(data_dict[stock_code][str(year)]))
income_dict[stock_code] = income_list
# 定义一个字典,保存归属于上市公司股东的净利润(元)
jlr_dict = {}
# 遍历所有数据,将每个股票每一年的归属于上市公司股东的净利润(元)保存在一个列表中
for key in data.keys():
stock_code = key.split('_')[0] # 获取股票代码
year = key.split('_')[1] # 获取年份
if '其他' in data[key] or str(year) not in data[key]:
continue
jlr = float(data[key][str(year)][1].replace(',', '')) # 获取归属于上市公司股东的净利润(元)并将其转换成浮点数
if stock_code not in jlr_dict:
# 如果字典中没有这个股票的记录,就新增一个字典
jlr_dict[stock_code] = {year:int(jlr)}
else:
# 如果有记录,就在这个股票对应的字典中新增一条记录
jlr_dict[stock_code][year] = int(jlr)
# 定义一个字典,保存每个股票的归属于上市公司股东的净利润(元)列表
jlr_dict1 = {}
# 遍历所有股票,保存每个股票的营业收入列表
for stock_code in jlr_dict.keys():
jlr_list1 = [] # 每个股票的营业收入列表
for year in range(2013, 2023):
# 如果这个年份没有营业收入记录就跳过
if str(year) not in jlr_dict[stock_code]:
continue
jlr_list1.append(int(jlr_dict[stock_code][str(year)]))
jlr_dict1[stock_code] = jlr_list1
| 公司简称 | 股票代码 | 办公地址 | 公司网址 | 董秘电话 | 董秘& 公司电子信箱 |
|---|---|---|---|---|---|
| 深康佳 A、深康佳 B | 000016、200016 | 深圳市南山区粤海街道科技园科技南十二路 28 号康佳研发大厦 15-24 层 | www.konka.com | 0755-26609138 | szkonka@konka.com |
| 深华发 A 、 深华发 B | 000020、200020 | 深圳市福田区华发北路 411 栋华发大厦东座六楼 | http://www.hwafa.com.cn | 0755-86360201 | huafainvestor@126.com.cn |
| 深纺织 A、深纺织 B | 000045、200045 | 深圳市福田区华强北路 3 号深纺大厦 A 座六楼 | http://www.chinasthc.com | 0755-83776043 | jiangp@chinasthc.com |
| 深天马 A | 000050 | 深圳市南山区马家龙工业城 64 栋 | http://www.tianma.com | 0755-86225886 | sztmzq@tianma.cn |
| 东旭光电、东旭 B | 000413、200413 | 北京市西城区菜园街一号 | www.dongxuguangdian.com.cn | 010-63541061 | wangqing@dongxu.com |
| 烽火电子 | 000561 | 陕西省宝鸡市清姜路 72 号 | http://www.fenghuo.cn | 0757-22321218 | weihg@shunna.com.cn |
| 京东方 A,京东方 B | 000725 | 北京市北京经济技术开发区西环中路 12 号 | www.boe.com | 010-64318888 转 | liuhongfeng@boe.com.cn |
| 汇源通信 | 000586 | 四川省成都市高新区天府大道北段 28 号茂业中心 C 座 2605 号 | www.schy.com.cn | 028-85516608 | xuanzhang24@163.com |
| 风华高科 | 000636 | 广东省肇庆市风华路 18 号风华电子工业城 | http://www.china-fenghua.com | 0758-2844724 | 000636@china-fenghua.com |
| 振华科技 | 000733 | 贵州省贵阳市乌当区新添大道北段 268 号 | http://www.czst.com.cn | 0851-86301078 | hugw@czelec.com.cn |
本部分绘图的数据来自于第二部分整理合并的各指标时间序列。笔者从时间序列和横截面横向对比两个角度,对营业收入和上市公司股东净利润进行了可视化处理。
# 各家公司营业收入绘图
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['fangsong']
mpl.rcParams['axes.unicode_minus']=False
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
# 遍历字典,给每一组数据进行绘制
name_list = ['2013','2014','2015','2016','2017','2018','2019','2020','2021','2022']
list_name_1 = ['000016','000020','000045','000050','000413','000561','000586','000636','000725','000733']
plt.figure(figsize=(24, 30))
plt.suptitle('2013-2022各公司的营业收入时序图',fontsize = 25,fontweight='heavy')
for i, stock in enumerate(list_name_1):
plt.subplot(2, 5, i+1)
income = income_dict[stock]
rects=plt.barh(range(len(income)),income,color=['r','g','b','y'])
N=10
import numpy as np
index = np.arange(N)
plt.yticks(index,name_list)
plt.yticks(rotation=30) # 将 x 轴标签旋转 30 度
plt.title("{} 13—22营业收入对比".format(stock),fontsize=16)
plt.ylabel("Year",fontsize=14)
plt.xlabel("营业收入(元)",fontsize=8)
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.show()
plt.figure(figsize=(24, 30))
plt.subplots_adjust(wspace=0.5, hspace=0.5)
plt.suptitle('2013-2022各公司的净利润时序图',fontsize = 25,fontweight='heavy')
for i, stock in enumerate(list_name_1):
ax = plt.subplot(2, 5, i+1) # 获取 subplot 对象
jlr = jlr_dict1[stock]
rects = ax.barh(range(len(jlr)), jlr, color=['r', 'g', 'b', 'y'])
N = 10
index = np.arange(N)
ax.set_yticks(index) # 设置 y 轴刻度
ax.set_yticklabels(name_list) # 设置 y 轴标签
plt.setp(ax.get_xticklabels(), fontsize=12) # 设置 x 轴刻度的字体大小
plt.setp(ax.get_yticklabels(), fontsize=14, rotation=30) # 设置 y 轴刻度的字体大小和旋转角度
ax.set_title("{} 13—22净利润对比".format(stock), fontsize=16)
ax.set_xlabel("净利润(元)", fontsize=10) # 修改 x 轴标签
ax.set_ylabel("Year", fontsize=14) # 修改 y 轴标签
for rect in rects:
w = rect.get_width()
ax.text(w, rect.get_y() + rect.get_height() / 2, w, size=10, ha='left', va='center')
plt.show()
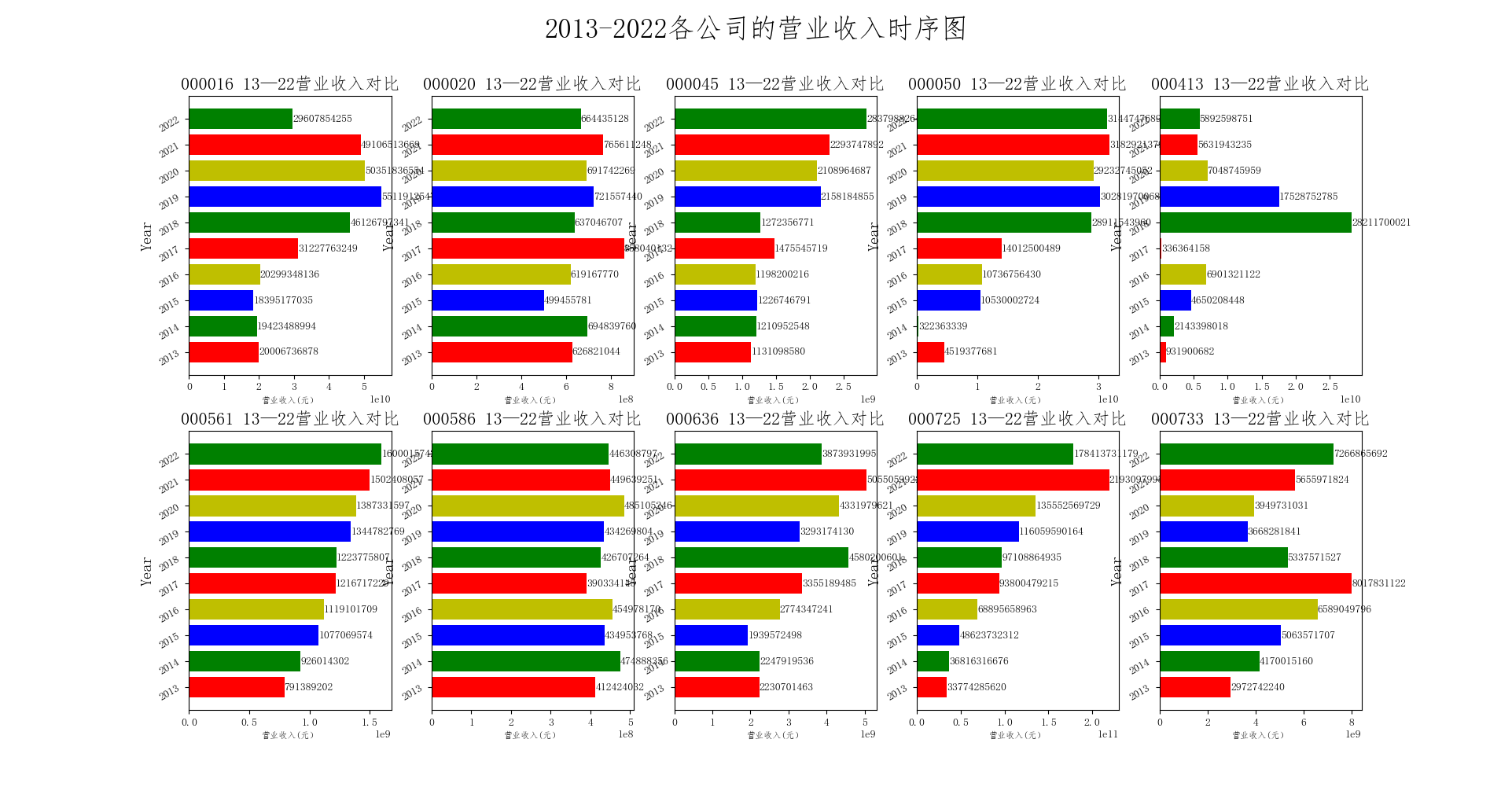
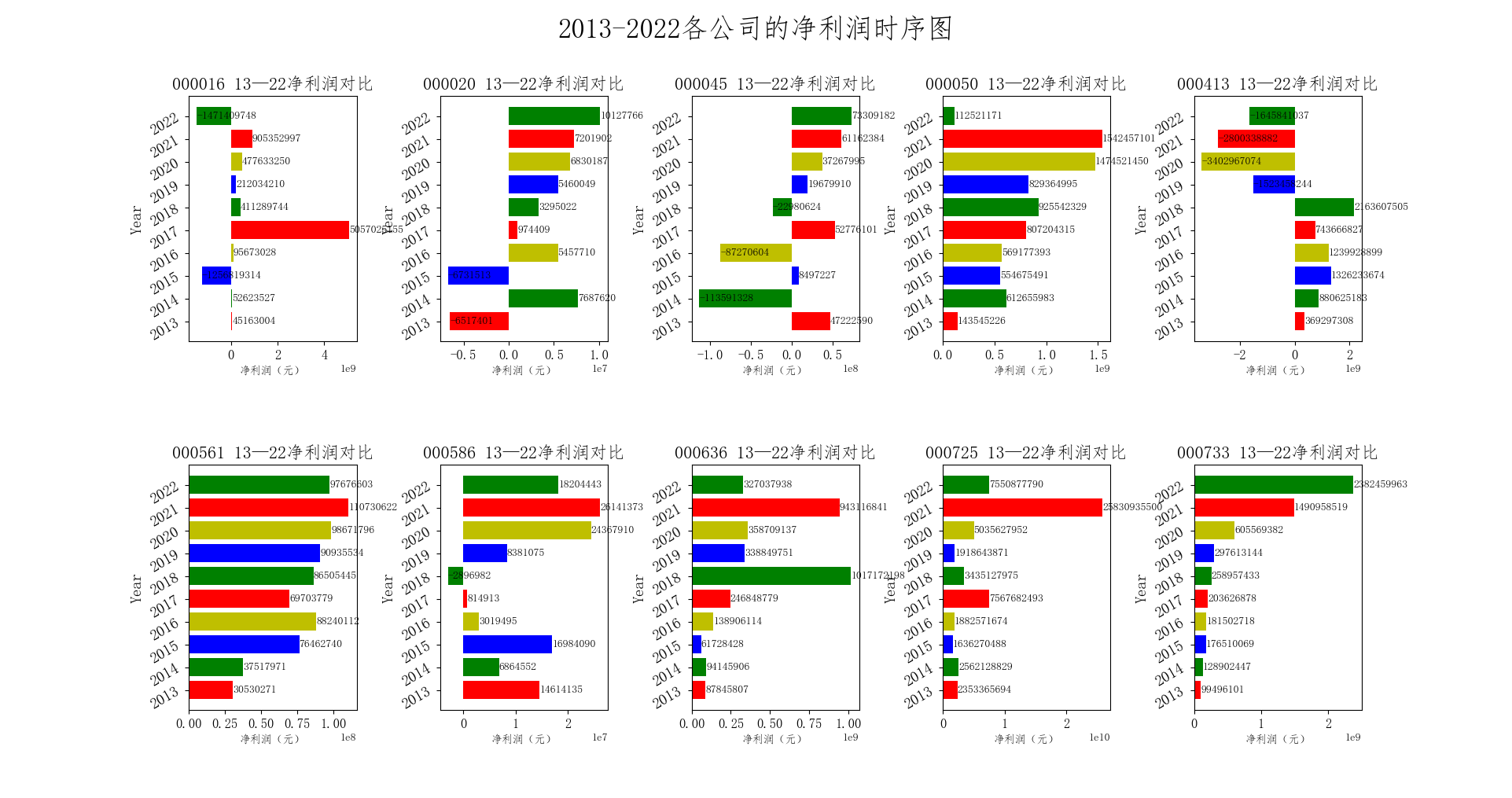

首先,通过对比可知,“京东方A”、“深天马A”,“深康佳A”在这十个公司的营业收入方面,占据前三的位置,并且“京东方A”与第二名差距仍然很大,稳坐第一,且“京东方A”、“深天马A”的营业收入和净利润连年稳定增长,“京东方A”在2021年实现了258亿的净利润。其余几家公司的营业收入和净利润波动较大。其中,像“东旭光电”在2018年后出现了较大幅度的下滑,营业收入减少,净利润一直保持亏损状态。
综上可知,在2018年中美贸易战和我国全面推进供给侧结构性改革的背景下,计算机、通信和其他电子设备制造行业的发展连续3年下行压力巨大,庆幸的是,由于部分企业市场份额较大,能够抵抗受到的冲击。而且在2020年-2021年新冠疫情的冲击甚至创下了营业收入的新高,整个行业在经济复苏后的上涨势头明显,大部分公司营业收入均出现了缓慢的上升。
如图所示,在10家上市公司中,尽管上市时间有所不同,但如深纺织A、深天马A、烽火电子、风华高科、京东方A的营业收入都呈现上升趋势,而东旭光电的营业收入波动幅度巨大。
众所周知,计算机、通信和其他电子设备制造行业的β值较大,其发展与经济周期存在着密切的关系。并且计算机的性能和显卡有关、通信设备、电子设备的性能和其芯片的强弱息息相关,自中美贸易摩擦以来,中国的计算机、通信、电子设备行业遭受冲击,并且由于最近10年的经济下行压力持续加大,对电子设备制造行业各公司产生了不同程度的冲击。
自2013年以来,图中计算机、通信和其他电子设备制造行业大部分公司营业收入均出现呈现出稳步增长的态势,其中原因包括。科技创新的突破:在这十年里,中国科技产业得到了迅速发展和升级,不仅在研发和制造方面取得了重大突破,也在自主品牌上取得了显著成果,成为全球科技领域的重要参与者。消费升级的拉动:人们对智能手机、电脑、电视等电子设备越来越依赖,这也促进了市场的推动发展,这和国内市场的大规模消费升级密不可分。巨头企业加速崛起:中国的本土科技巨头企业逐步崛起,例如华为、京东方、小米、TCL等,他们的崛起也促进和推进了该市场的不断发展。
由图可知,归属于上市公司股东的净利润(以下简称“净利润”)的差异还是很大的,其中市场份额持有较大的公司,净利润的变动更加稳定,因为其且受市场波动的影响较小。有的时候会因为市场波动过大,净利润出现很大的提升或减少,但是仍然有市场份额很大的企业在最近2年的净利润出现了很大波动,比如“京东方A”,
从图中可以看出,在2013年到2022年的这段时间里,深康佳A的营业收入呈现出增长的趋势,在2018年之前呈现增长速度较快,在2018年后增长速度逐渐减缓;而净利润则在2013年到2017年之间波动较大,而在2018年之后逐渐稳定上升。
总的来说,从深康佳A的财务指标来看,该公司的盈利能力一般,经营状况并不是很乐观。但是深康佳A在财务方面尚有改进空间,重点在于提升盈利能力和控制成本,同时要注重提高资产质量和偿债能力。
本次实验,从编写到测试,历时1周,熬了几个通宵,最终得以顺利完成。经历了无数次报错和代码的重新写,虽然最后呈现的效果不太尽人意,但是在我对错误的分析处理当中,自己对Python编程又有更新的认识。也明白了自己在编程上的弱势,自己在这门课程当中主要的收获有以下几点:
首先,在吴燕丰老师的指导下,我对正则表达式有了新的认识,学会了贪婪与非贪婪,对部分代码的编写也比以往更熟练、更加精简。
其次,我要感谢张艺轩同学对我的帮助,没有他的指导,我写不出来这份报告,也让我自己对于爬虫、正则表达式的编写有了一定的掌握。
最后,希望在日后的学习中,自己能够继续努力,更加努力地学习、掌握一些更加面向实践的数理算法。