Ⅰ.获取html并从中提取公司信息并获取年报
Ⅱ.通过年报获取公司营业信息并进行绘图
Ⅲ.结果解读
Ⅳ.心得体会
import re
import pandas as pd
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
df_sz = pd.DataFrame({'index':['000030','000338','000550','000559','000572','000581','000625','000700','000800','000868'],
'name': ['富奥股份','潍柴动力','江铃汽车','万向钱潮','海马汽车','威孚高科','长安汽车','模塑科技','一汽解放','安凯客车']})
name_sz = df_sz['name'].tolist()
driver = webdriver.Chrome()
def getszHTML(name): #定义获取深交所公司html的函数
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
html = driver.find_element(By.ID, 'disclosure-table')
time.sleep(3)
innerHTML = html.get_attribute('innerHTML')
df = open(name+'.html','w',encoding='gbk')
df.write(innerHTML)
df.close()
driver.refresh()
for name in name_sz:
getszHTML(name)
time.sleep(1)
driver.quit()
def Readhtml(filename):
with open(filename+'.html', encoding='gbk') as f:
html = f.read()
return html
class DisclosureTable():
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'公告时间': times,
'href': [prefix_href + aht[1] for aht in ahts]
})
self.df_data = df
return(df)
def Loadpdf(df):
d = []
for index, row in df.iterrows():
a = row[2] #公告标题这一行
n = re.search('摘要|取消|更新前|12', a)
if n != None:
d.append(index)
dfnew = df.drop(d).reset_index(drop = True)
dfnew.to_csv(name + '.csv',encoding = 'gbk')
os.makedirs(name, exist_ok = True)
os.chdir(name)
#
d1 = {}
for index, row in dfnew.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
key = key.strip('公司').strip('(更新后)').strip('(更新后)').strip('全文')
with open (key + ".pdf", "wb") as code:
code.write(f.content)
os.chdir('../')
for index,row in df_sz.iterrows():
name = row[1].replace('*','')
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
Loadpdf(df)
driver.quit()

import re
import pandas as pd
import fitz
import pdfplumber
import matplotlib.pyplot as plt
import os
def findAllFile(base):
for root, ds, fs in os.walk(base):
for f in fs:
yield f
def main():
base = r'C:\Users\baozi\baozi.data\nianbao\安凯客车\\'
res = []
res3=[]
for i in findAllFile(base):
text = []
url=base+''+i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text .append(page.extract_text()) # 提取文本
# print(text)
b=(str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./安凯客车\\'+i+'.csv','w') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a=(str(text).find('营业总收入'))
res.append(float(str(text)[a + 6:a + 22].replace(',', '')))
d = (str(text).find('归属于上市公司股东的净利'))
sss=((str(text)[d+13:d+30].replace(',','').find(' ')))
ss = ((str(text)[d + 13:d + 30].replace(',', '').find('n')))
try:
res3.append(float(str(text)[d+13:d+30].replace(',','')[ss+1:sss]))
except:
continue
print(res3)
time1 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 =res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("安凯客车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
plt.savefig('./安凯客车/gif1.png')
time2 = [2013,2014,2015,2016,2017,2018,2020,2022]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("安凯客车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
plt.savefig('./安凯客车/gif2.png')
base = r'C:\Users\baozi\baozi.data\nianbao\富奥股份\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./富奥股份\\'+i+'.csv','w') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('一、营业总收入'))
res.append(float(str(text)[a + 8:a + 24].replace(',', '')))
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 13:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 13:d + 30].replace(',', '').find('n')))
try:
res3.append(float(str(text)[d + 13:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("富奥股份")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./富奥股份/gi3.png')
time2 = [2013, 2014, 2015, 2016, 2017, 2018,2019, 2020, 2021]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("富奥股份")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./富奥股份/gif4.png')
base = r'C:\Users\baozi\baozi.data\nianbao\海马汽车\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./海马汽车\\'+i+'.csv','w') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('一、营业总收入'))
res.append(float(str(text)[a + 8:a + 24].replace(',', '')))
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 13:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 13:d + 30].replace(',', '').find('.')))
print((str(text)[d + 13:d + 30].replace(',', '')))
try:
res3.append(float(str(text)[d + 13:d + 30].replace(',', '')[sss :ss]))
except:
continue
print(res3)
time1 = [2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("海马汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./海马汽车/gif5.png')
time2 = [2013, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("海马汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./海马汽车/gif6.png')
base = r'C:\Users\baozi\baozi.data\nianbao\江铃汽车\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./江铃汽车\\'+i+'.csv','w',encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 13:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 13:d + 30].replace(',', '').find('n')))
try:
res3.append(float(str(text)[d + 13:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2015, 2016, 2017, 2018, 2019, 2020, 2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("江铃汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./江铃汽车/gif7.png')
time2 = [2015,2019,2020]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("江铃汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./江铃汽车/gif8.png')
base = r'C:\Users\baozi\baozi.data\nianbao\模塑科技\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./模塑科技\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 17:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 17:d + 30].replace(',', '').find('n')))
# print(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("模塑科技")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./模塑科技/gif9.png')
time2 = [2013,2015,2016,2017, 2018, 2019,2021,2022]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("模塑科技")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./模塑科技/gif10.png')
base = r'C:\Users\baozi\baozi.data\nianbao\万向钱潮\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
print(b,c)
with open('./万向钱潮\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 17:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 17:d + 30].replace(',', '').find('n')))
# print(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2014,2015,2017,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("万向钱潮")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()hen
plt.savefig('./万向钱潮/gif11.png')
time2 = [2014,2015,2017, 2019, 2020,2021]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("万向钱潮")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./万向钱潮/gif12.png')
base = r'C:\Users\baozi\baozi.data\nianbao\威孚高科\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
print(b,c)
with open('./威孚高科\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 17:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 17:d + 30].replace(',', '').find('n')))
# print(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("威孚高科")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()hen
plt.savefig('./威孚高科/gif13.png')
time2 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("威孚高科")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./威孚高科/gif14.png')
base = r'C:\Users\baozi\baozi.data\nianbao\潍柴动力\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
print(b,c)
with open('./潍柴动力\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 17:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 17:d + 30].replace(',', '').find('n')))
# print(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("潍柴动力")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()hen
plt.savefig('./潍柴动力/gif15.png')
time2 = [2013,2015,2016,2017,2018,2019,2020,2021,2022]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("潍柴动力")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./潍柴动力/gif16.png')
base = r'C:\Users\baozi\baozi.data\nianbao\一汽解放\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
print(b,c)
with open('./一汽解放\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('归属于上市公司股东的净利'))
sss = ((str(text)[d + 17:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 17:d + 30].replace(',', '').find('n')))
# print(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 17:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2013,2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("一汽解放")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()hen
plt.savefig('./一汽解放/gif17.png')
time2 = [2015,2016,2017,2018,2019,2021]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("一汽解放")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./一汽解放/gif18.png')
base = r'C:\Users\baozi\baozi.data\nianbao\长安汽车\\'
res = []
res3 = []
for i in findAllFile(base):
text = []
url = base + '' + i
print(i)
with pdfplumber.open(url) as pdf:
for page in pdf.pages:
text.append(page.extract_text()) # 提取文本
# print(text)
b = (str(text).find('董事会秘书'))
c = (str(text).find('三、信息披露及备置地点'))
with open('./长安汽车\\' + i + '.csv', 'w', encoding='utf-8') as f:
f.write(str(text)[b:c])
print(str(text)[b:c])
a = (str(text).find('营业收入(元)'))
res.append(float(str(text)[a + 8:a + 23].replace(',', '')))
print(res)
d = (str(text).find('上市公司股东的净利'))
sss = ((str(text)[d + 11:d + 30].replace(',', '').find(' ')))
ss = ((str(text)[d + 11:d + 30].replace(',', '').find('n')))
print(float(str(text)[d + 11:d + 30].replace(',', '')[ss + 1:sss]))
try:
res3.append(float(str(text)[d + 11:d + 30].replace(',', '')[ss + 1:sss]))
except:
continue
print(res3)
time1 = [2014,2015,2016,2017,2018,2019,2020,2021,2022]
res2 = res
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time1, res2)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("长安汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["营业总收入"], loc="upper right") ##右上方
# plt.show()hen
plt.savefig('./长安汽车/gif19.png')
time2 = [2014,2015,2016,2017,2018,2019,2020,2021,2022]
plt.figure(figsize=(9, 4)) # 设置分辨率900X400
plt.plot(time2, res3)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.title("长安汽车")
plt.xlabel("height")
plt.ylabel("width")
# plt.xticks(range(0, len(time1), 61), rotation=60) # 设置x轴间隔
# 设置图例
plt.legend(["股东的净利润"], loc="upper right") ##右上方
# plt.show()
plt.savefig('./长安汽车/gif20.png')
if __name__ == '__main__':
main()
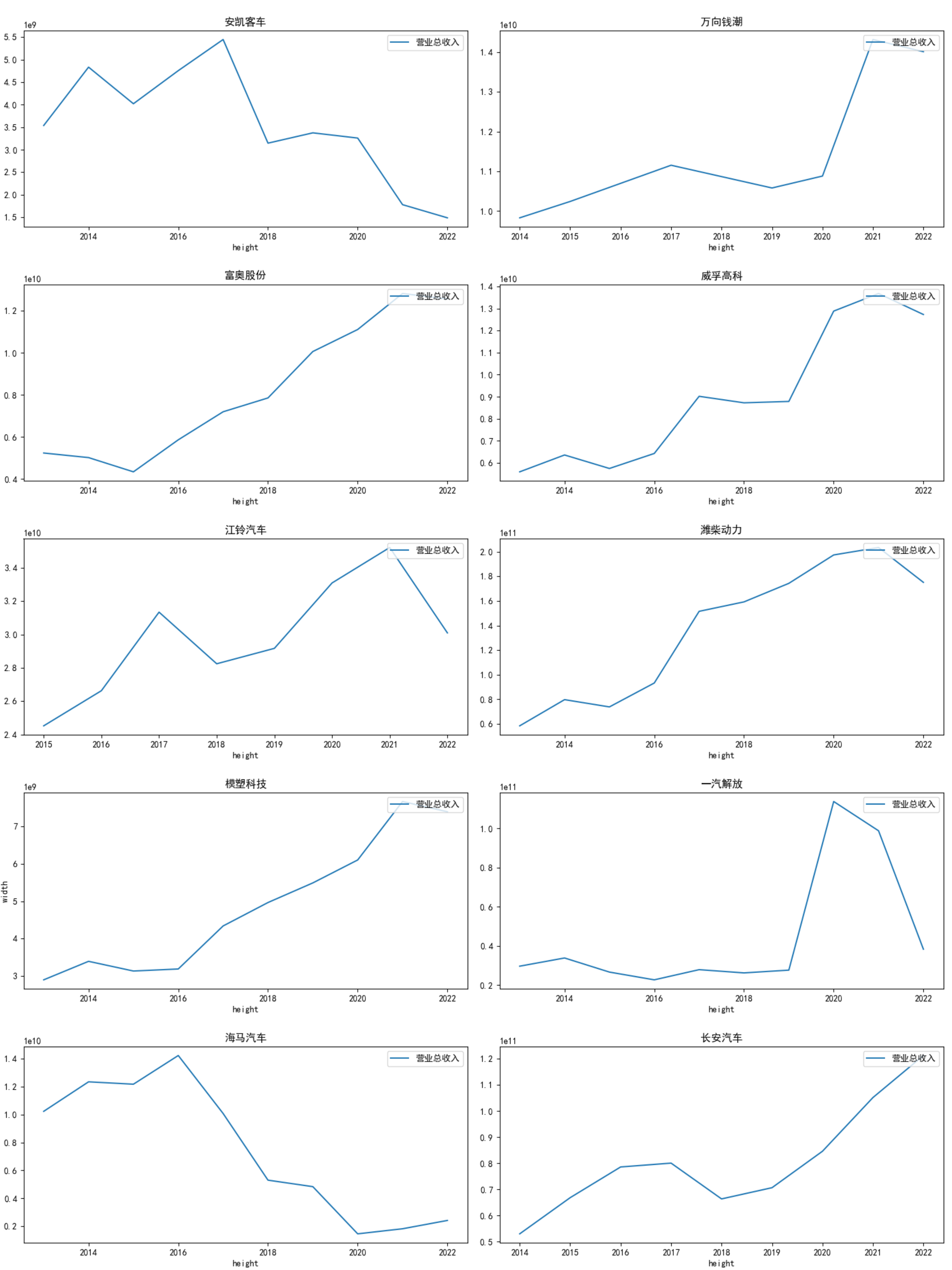
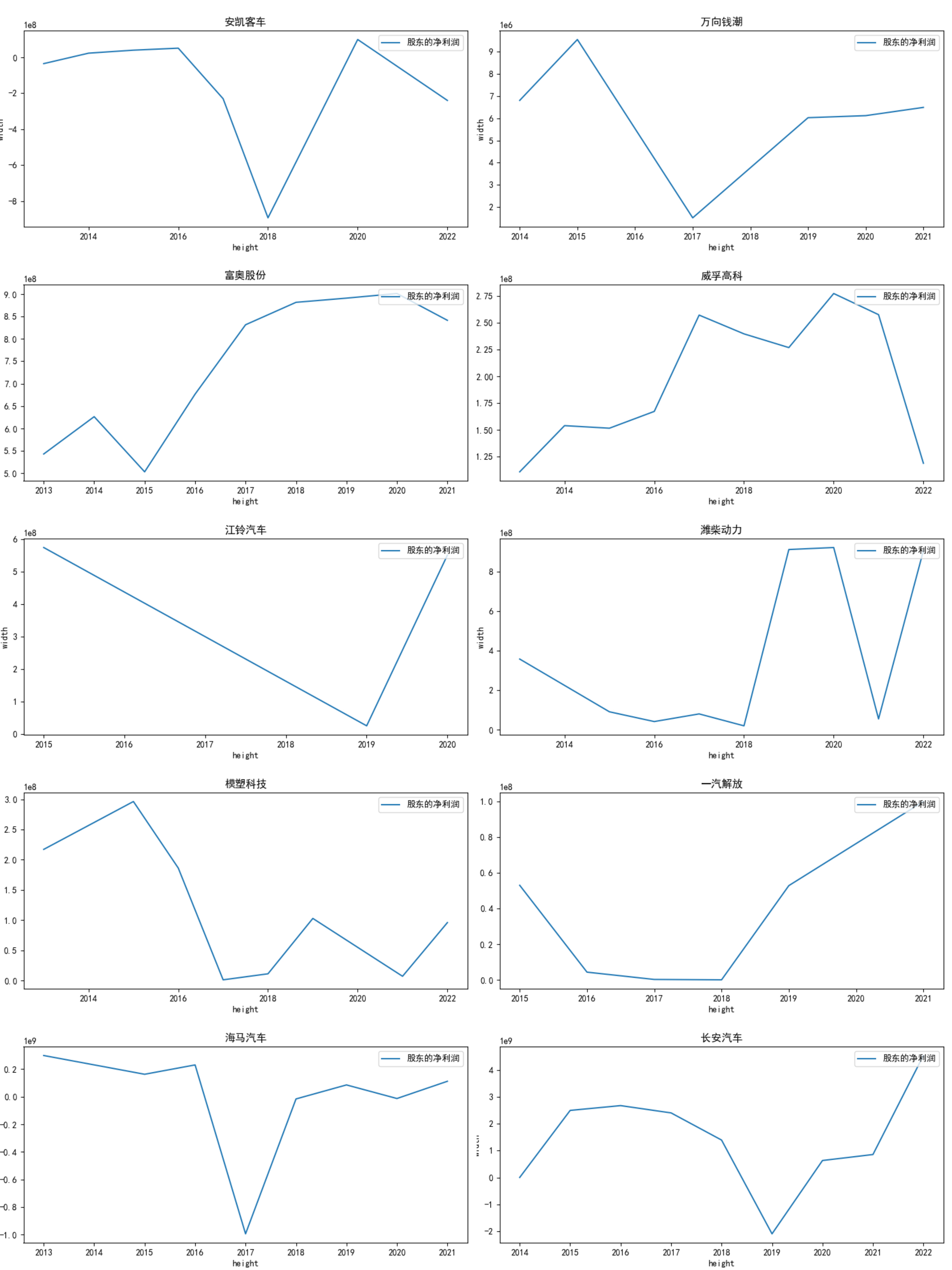
根据营业收入随时间变化的趋势图,目前汽车页的第一梯队公司当属一汽解放,长安汽车。 在2013-2022年,一汽解放一直处于总营业收入第一的地位,规模最大。研发、生产和销售中重型载重车、整车、客车、客车底盘、中型卡车变形车、汽车总成及零部件、机械加工、柴油机及配件(非车用)、机械设备及配件、仪器仪表设备,技术服务、技术咨询,安装维修机械设备,机械设备和设施租赁,房屋和厂房租赁,劳务(不含对外劳务合作经营和国内劳务派遣),钢材、汽车车箱、五金交电、电子产品销售,内燃机检测,工程技术研究及试验,广告设计制作发布,货物进出口和技术进出口(不包括出版物进口业务及国家限定公司经营或禁止进出口的商品及技术);(以下各项由分公司经营)中餐制售、仓储物流(不含易燃易爆和易制毒危险化学品)、汽车修理、化工液体罐车罐体制造、汽车车箱制造(依法须经批准的项目,经相关部门批准后方可开展经营活动)与自身的畜牧业务良好配合,多途径创造收益。
我是秉着学到知识可以为自己所用的目标选的这门课。但由于我对python这一编程语言实在是不熟悉,所以学习过程中还是很吃力。上课我尽量做到跟上老师的节奏,但由于课后没有及时跟进练习,所以面对这个大作业的时候我是有点崩溃的。
但好在往届优秀学长学姐的报告可以供我们参考,结合老师上课所教的代码我学会了如何获取html和下载pdf。除了在网络搜寻信息外也收到了很多人的帮助,最终才有了这一个报告。 这篇实验报告还有许多不足之处,所提取的信息也是经过了我的手动修改才呈现出来,希望以后我能真正运用编程语言就能很好地达到自己想要的效果。