新中国成立以来,我国有色金属行业发展至今已实现了从贫弱到富有的全面突破,针对发展过程中存在的问题,我国也出台多项政策针对性解决。目前,有色金属行业的传统业务已经发展至成熟期,单一的采矿、冶炼以及加工模式带给企业的利润相较技术含量较高的新材料而言,上限较低,因此近年来,多数不满足于现状的有色金属企业已开始布局新材料、稀土磁材领域,而业务板块未有改变的企业也积极探索生产智能化、绿色化转型道路,为有色金属行业赋予新的发展方向。
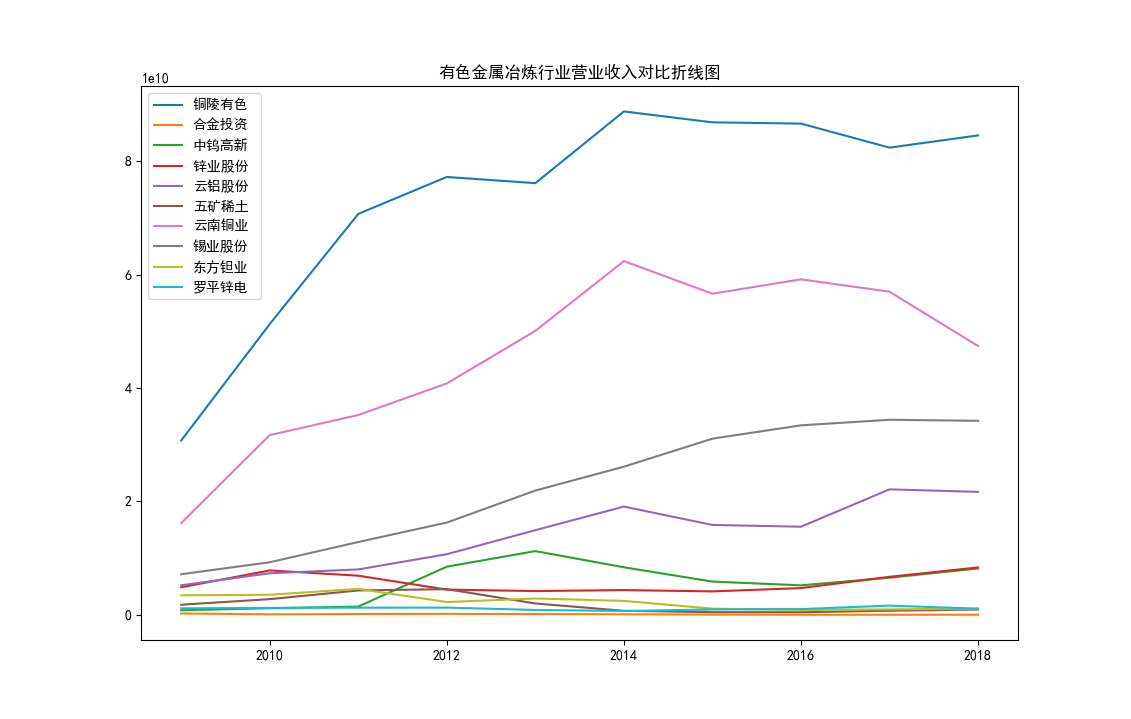
近十年来,我国有色金属行业产量逐年稳定增长。从上图可以看出,以铜陵有色、云南铜业为代表的行业龙头营业收入总体呈上升趋势,体量较小的企业营业收入较为稳定,行业资源逐渐向龙头企业集中。这也符合有色金属行业的竞争力主要由资源占有量决定,矿山布局较多、客户分布更广的企业将在行业竞争中取得优势。由于有色金属矿采选业具有高度资源依赖性,随着区域矿山闭坑以及行业龙头企业不断扩张,行业企业数量减少是必然趋势。
铜陵有色作为国内铜产业链头部企业,背靠全球500强铜陵有色控股集团,是集铜采选、冶炼、加工、贸易为一体的大型全产业链铜生产企业,主要产品涵盖阴极铜、硫酸、黄金、白银、铜箔及铜板带等。公司既在铜矿采选领域有一定积累,又在铜冶炼及铜箔加工等领域有着深厚积累,产业链结构完善,在旗下拥有10座矿山的同时,还具备4个冶炼厂,产能在国内位居行业前列。
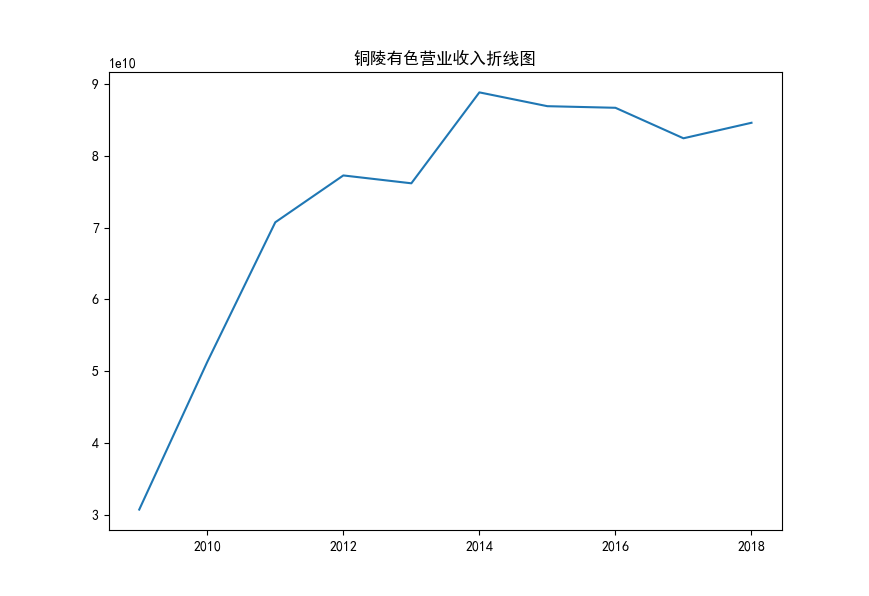
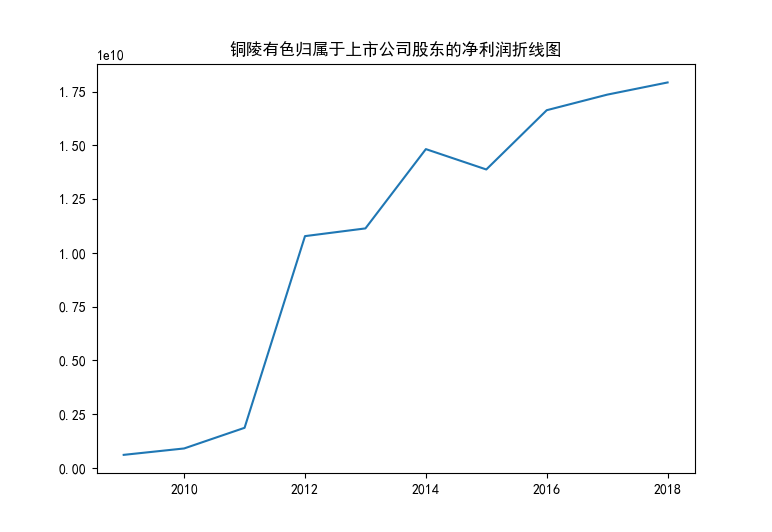
从上图可以观察到,铜陵有色在10年代初期发展迅猛,营业收入和归属于上市公司股东的净利润上升迅速。近些年由于房地产下行的影响,相关材料需求的收缩导致供求矛盾日益凸显,企业营利增速有所放缓,虽然总体保持上升趋势,但依然面临技术创新和转型升级等方面的问题。目前,全球的有色金属市场竞争日益激烈,行业发展趋势也向着绿色、智能、高端方向发展。因此,铜陵有色需要加强其技术研发和创新,提高其产品的科技含量和环保性,以适应行业发展的趋势和需求。
import requests,json,os,time,re
def read_l(txt):
line_l = [line.strip() for line in open(txt, encoding='UTF-8').readlines()]
return line_l
def downloadpdf(pdf_url, filename):
pdf = requests.get(pdf_url)
with open(filename, 'wb') as f:
f.write(pdf.content)
def find_text(text,l):
for i in l:
if i in text:
r = True
break
else:
r = False
return r
def rename(file_name,firm_id):
global pattern,s_l
year = re.findall(pattern,file_name)[0]
for s in s_l:
if s in file_name:
season = str(s_l.index(s)+1)
break
else:
pass
new_name = f'{firm_id}_{year}_{season}.pdf'
return new_name
pattern = '[0-9]{4}'
s_l = ['第一季度','半年度','第三季度','年年度']
txt = r'F:\Download\anaconda3\report\txt.txt'
firm_ids = read_l(txt)
date = ["2010-12-31", "2023-5-29"]
path = r'F:\Download\anaconda3\report\metal'
l = ['摘要','取消','正文']
#url
url = 'http://www.szse.cn/api/disc/announcement/annList?random=0.8015180112682705'
headers = {'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Connection':'keep-alive',
'Content-Length':'92',
'Content-Type':'application/json',
'DNT':'1',
'Host':'www.szse.cn',
'Origin':'http://www.szse.cn',
'Referer':'http://www.szse.cn/disclosure/listed/fixed/index.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'X-Request-Type':'ajax',
'X-Requested-With':'XMLHttpRequest'}
#payload,获取源代码
for firm_id in firm_ids:
dirname = path+f'{firm_id}'
os.mkdir(dirname)
for page in range(1,5):
try:
payload = {'seDate': date,
'stock': ["{firm_id}".format(firm_id=firm_id)],
'channelCode': ["fixed_disc"],
'pageSize': 30,
'pageNum': '{page}'.format(page=page)}
response = requests.post(url, headers=headers, data=json.dumps(payload))
doc = response.json()
if response.status_code==200:
print('获取{0}的第{1}页源代码成功'.format(firm_id,page))
#提取pdf_url和年报信息
#count = doc.get('announceCount')
datas = doc.get('data')
#print(datas)
for i in range(len(datas)):
data = datas[i]
pdf_url = 'http://disc.static.szse.cn/download'+data.get('attachPath')
title = data.get('title')
publish_time = data.get('publishTime')[:9]
#filename = f'{firm_id}_{title}.pdf'
filename = rename(title,firm_id)
if find_text(title,l):
continue
else:
downloadpdf(pdf_url, dirname+'/'+filename)
print(f'开始下载{filename}')
time.sleep(2)
except:
print('{0}的第{1}页不存在'.format(firm_id,page))
pass
import pdfplumber
import pandas as pd
#提取公司信息存为csv文件
filename = "F:\\Download\\anaconda3\\report\\metal000633\\000633_2014_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[5]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000633.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000657\\000657_2018_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000657.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000751\\000751_2018_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000751.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000807\\000807_2018_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000807.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000831\\000831_2018_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000831.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000878\\000878_2018_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000878.csv')
filename = "F:\\Download\\anaconda3\\report\\metal000960\\000960_2017_4.pdf"
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[4]
tables = page01.extract_tables()#提取多个表格
pd.set_option('display.max_columns',None)#把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1,df2])
print(df3)
df3.to_csv('F:\\Download\\anaconda3\\report\\information\\info_000960.csv')
#合并csv文件
df1 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000630.csv')
df2 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000633.csv')
df3 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000657.csv')
df4 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000751.csv')
df5 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000807.csv')
df6 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000831.csv')
df7 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000878.csv')
df8 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000960.csv')
df9 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_000962.csv')
df0 = pd.read_csv('F:\\Download\\anaconda3\\report\\information\\info_002114.csv')
merged_df = pd.merge(df1,df2,df3,df4,df5,df6,df7,df8,df9,df0, on='common_column')
merged_df.to_csv('F:\\Download\\anaconda3\\report\\information\\merged_file.csv', index=False)

import pdfplumber
import pandas as pd
from openpyxl import Workbook
with pdfplumber.open("F:\\Download\\anaconda3\\report\\metal000630\\000630_2018_4.pdf") as pdf:
page01 = pdf.pages[7]
table = page01.extract_table()
workbook = Workbook()
sheet = workbook.active
for row in table:
sheet.append(row)
print(type(workbook))
workbook.save(filename="F:\\Download\\anaconda3\\report\\metal_excel\\metal_000630.xlsx")
#保存为csv格式
def xlsx_to_csv_pd():
data_xls = pd.read_excel('F:\\Download\\anaconda3\\report\\metal_excel\\metal_000630.xlsx', index_col=0)
data_xls.to_csv('000630.csv', encoding='utf-8')
xlsx_to_csv_pd()
data = pd.read_csv('000630.csv')
print(data)

import matplotlib.pyplot as plt
import pandas as pd
#对铜陵有色进行数据可视化分析:
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文标签
x = range(2009,2019)
y1=[30755175529.14,51303778519.82,70740641187.81,77258770498.98,76164734293.74,88818485807.64,86896604108.22,86674103277.75,82429067171.61,84589124365.35]
#对其营业收入做折线图
plt.plot(x,y1)
plt.title("铜陵有色营业收入折线图")
plt.show()
#对归属于上市公司股东的净利润(元)做折线图
y2 = [607890154.35,905724015.40,1866261629.83,10781039475.95,11140318264.02,14828140856.93,13881309565.24,16637735113.07,17361088240.78,17928085686.15]
plt.plot(x,y2)
plt.title("铜陵有色归属于上市公司股东的净利润折线图")
plt.show()
#绘制十家公司十年的营业收入曲线
x = range(2009,2019)
data = pd.read_excel(r"F:\Download\anaconda3\report\income\ten_company_income.xlsx")
print(data)
data = data.T
data = data.rename(columns={0:"铜陵有色",1:"合金投资",2:"中钨高新",3:"锌业股份 ",4:"云铝股份",5:"五矿稀土",6:"云南铜业",7:"锡业股份",8:"东方钽业",9:"罗平锌电"})
data.plot()
plt.title("有色金属冶炼行业营业收入对比折线图")
plt.show()
使用Python进行上市公司年报爬取、使用pdfplumber对数据进行提取,并通过Matplotlib进行数据可视化是一项有趣和富有挑战性的任务。这个过程中,我获得了以下感想和感悟:
首先,爬取上市公司年报是一项重要的数据收集任务。通过编写Python爬虫代码,我能够从各种来源获取年报PDF文件,包括公司官方网站和证券交易所的网站。 其次,使用pdfplumber库对年报PDF进行数据提取是一项关键的技术。PDF是一种复杂的文件格式,其中的文本和表格数据通常不易提取。pdfplumber提供了强大的工具和方法来解析PDF文件,并提取所需的数据。这使我能够有效地处理年报中的文本内容、表格和其他结构化数据。pdfplumber的灵活性和稳定性让我对其功能和性能印象深刻。 最后,通过Matplotlib进行数据可视化是将年报数据呈现出来的有力工具。Matplotlib提供了各种绘图选项和样式,使我能够根据需要创建各种图表,如折线图、柱状图和饼图等。通过可视化年报数据,我能够更好地理解和分析公司的财务状况、趋势和关键指标。这为我提供了一种更直观、易于理解的方式来传达数据和发现洞察力。
通过这门课的学习,我发现了处理和分析大量财务数据的潜力和乐趣。这种综合应用的过程让我更深入地了解了Python在数据处理和可视化领域的强大能力,并在实践中提升了我的技能和经验。虽然仅仅通过这一学期的理论知识学习与实践,我还有很多Python的知识没有完全掌握,但我在今后会坚持学习和联系,努力将所学运用到实践。感谢吴老师这一学期的悉心教导。