


# 导入pandas工具库
import pandas as pd
#实现系统功能
import os
#读取excel
import xlrd
#写入excel
import xlwt
#解析json
import json
#获取网页内容
import requests
#数学函数
import math
#正则表达
import re
#下载网络文件到本地
from urllib.request import urlretrieve
# 从以下url中提取所需要的上市企业数据源信息
url = "http://www.cninfo.com.cn/new/data/szse_stock.json"
ret = requests.get(url = url)
ret = ret.content
stock_list = json.loads(ret)["stockList"]
len(stock_list)
# 检查数据格式案例
stock_list[:2]
def export_excel(export):
# 将字典列表转换为DataFrame
pf = pd.DataFrame(export)
# 指定字段顺序
order = ['orgId', 'category', 'code', 'pinyin', 'zwjc']
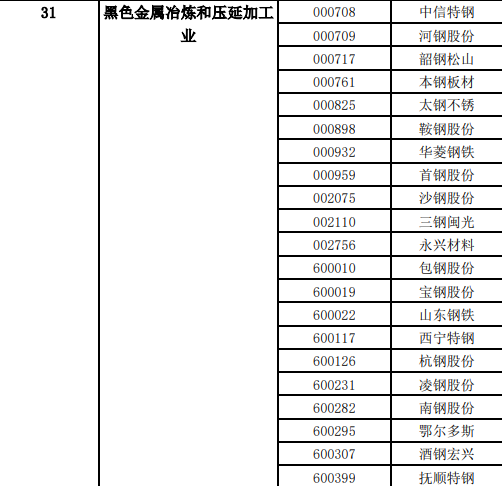
pf = pf[order]
# 将列名替换为中文
columns_map = {
'orgId': 'orgId(原始ID)',
'category': 'category(股市类型)',
'code': 'code(代码)',
'pinyin': 'pinyin(拼音)',
'zwjc': 'zwjc()'
}
pf.rename(columns=columns_map, inplace=True)
# 指定生成的Excel表格名称
file_path = pd.ExcelWriter('code_list.xlsx')
# 替换空单元格
pf.fillna(' ', inplace=True)
# 输出
pf.to_excel(file_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
if __name__ == '__main__':
# 将分析完成的列表导出为excel表格
export_excel(stock_list)
code_dic = {(it['code']): it['orgId'] for it in stock_list}
print(code_dic)
len(code_dic)
class excel_read:
# 定义一个读取函数,其中excel_path为待爬取企业清单的路径,需自定义
def __init__(self, excel_path=r"D:\crawler_SZSE-main\black_metal\2.xlsx", encoding='utf-8', index=0):
# 获取文本对象
self.data = xlrd.open_workbook(excel_path)
# 根据index获取某个sheet
self.table = self.data.sheets()[index]
# 获取当前sheet页面的总行数,把每一行数据作为list放到 list
self.rows = self.table.nrows
def get_data(self):
result = []
for i in range(self.rows):
# 获取每一行的数据
col = self.table.row_values(i)
print(col)
result.append(col)
print(result)
return result
# 运用函数生成待爬取企业的code_list
code_list = []
code_list.extend(excel_read().get_data())
def get_and_download_pdf_flie(pageNum, stock, searchkey='', category='', seDate=''):
url = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
pageNum = int(pageNum)
# 定义表单数据
data = {'pageNum': pageNum,
'pageSize': 30,
'column': 'szse',
'tabName': 'fulltext',
'plate': '',
'stock': stock,
'searchkey': searchkey,
'secid': '',
'category': category,
'trade': '',
'seDate': seDate,
'sortName': '',
'sortType': '',
'isHLtitle': 'true'}
# 定义请求头
headers = {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '181',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Referer': 'http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'}
# 提交请求
r = requests.post(url, data=data, headers=headers)
# 获取单页年报的数据,数据格式为json,解析并获取json中的年报信息
result = r.json()['announcements']
# 2.对数据信息进行提取
for i in result:
# 避免下载一些年报摘要等不需要的文件
if re.search('摘要', i['announcementTitle']):
pass
else:
title = i['announcementTitle']
# 获取公告文件名,并在下载前将公告文件名中带*号的去掉,因为文件命名规则不能带*号,否则程序会中断
secName = i['secName']
secName = secName.replace('*', '')
# 获取公司股票代码
secCode = i['secCode']
# 获取adjunctUrl,并组合生成pdf文件下载地址(分析得知巨潮资讯数据库pdf下载地址格式:http://static.cninfo.com.cn/+adjunctUrl)
adjunctUrl = i['adjunctUrl']
down_url = 'http://static.cninfo.com.cn/' + adjunctUrl
# 定义下载之后需要保存到本地的文件名
filename = f'{secCode}{secName}{title}.pdf'
# 定义文件存放地址
filepath = saving_path + '\\' + filename
# 提交下载请求
r = requests.get(down_url)
# 用response.content来写入文件信息
with open(filepath, 'wb') as f:
f.write(r.content)
# 设置进度条
print(f'{secCode}{secName}{title}下载完毕')
# 设置存储年报的文件夹,把路径改成自己的
saving_path = r'D:\crawler_SZSE-main\black_metal'
# 根据code_list计算待爬企业数量
Num = len(code_list)
print(Num)
# 从code_list中根据待爬企业数量遍历提取code与orgId
for i in range(0, Num):
code = code_list[i][0]
orgId = code_dic[code]
# 定义stock
stock = '{},{}'.format(code, orgId)
print(stock)
# 定义searchkey
searchkey = ''
# 定义category
category = 'category_ndbg_szsh'
# 定义seDate
seDate = '2010-01-01~2022-09-26'
# 定义pageNum(需要通过观测,确保pageNum能够涵盖每一次遍历请求的结果页数,此处定为2页即可)
for pageNum in range(1, 3):
try:
get_and_download_pdf_flie(pageNum, stock, searchkey, category, seDate, )
except:
# 超出页数后会报错,需要跳过异常以便于继续遍历执行
pass
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\crawler_SZSE-main\black_metal'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("2018年年度报告.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
# file_list = ['D:\\crawler_SZSE-main\\not_metal\\nMteal002066\\002066_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002080\\002080_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002088\\002088_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002162\\002162_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002205\\002205_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002225\\002225_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002233\\002233_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002271\\002271_2018_4.pdf']
import pandas as pd
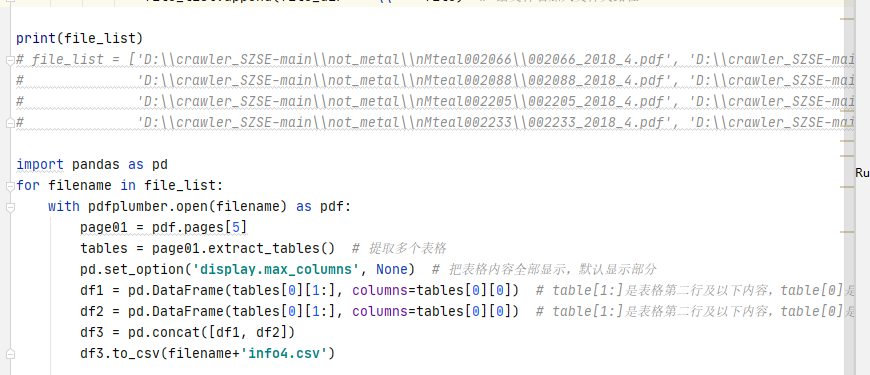
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[5]
tables = page01.extract_tables() # 提取多个表格
pd.set_option('display.max_columns', None) # 把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1, df2])
df3.to_csv(filename+'info4.csv')
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'D:\crawler_SZSE-main\black_metal'#遍历的文件夹
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
print(file)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
if file.endswith("年度报告.pdf"):
file_list.append(file_dir + '\\' + file) # 给文件名加入文件夹路径
print(file_list)
# file_list = ['D:\\crawler_SZSE-main\\not_metal\\nMteal002066\\002066_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002080\\002080_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002088\\002088_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002162\\002162_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002205\\002205_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002225\\002225_2018_4.pdf',
# 'D:\\crawler_SZSE-main\\not_metal\\nMteal002233\\002233_2018_4.pdf', 'D:\\crawler_SZSE-main\\not_metal\\nMteal002271\\002271_2018_4.pdf']
import pandas as pd
for filename in file_list:
with pdfplumber.open(filename) as pdf:
page01 = pdf.pages[6]
tables = page01.extract_tables() # 提取多个表格
pd.set_option('display.max_columns', None) # 把表格内容全部显示,默认显示部分
df1 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df2 = pd.DataFrame(tables[0][1:], columns=tables[0][0]) # table[1:]是表格第二行及以下内容,table[0]是表格第一行,及表头内容
df3 = pd.concat([df1, df2])
df3.to_csv(filename+'income_year.csv')
# 对福建三钢闽光股份有限公司进行数据可视化
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
x = range(2012,2022)
data = pd.read_excel("income.xlsx")
print(data)
data = data.T
data = data.rename(columns={0:"三钢闽光"})
print(data)
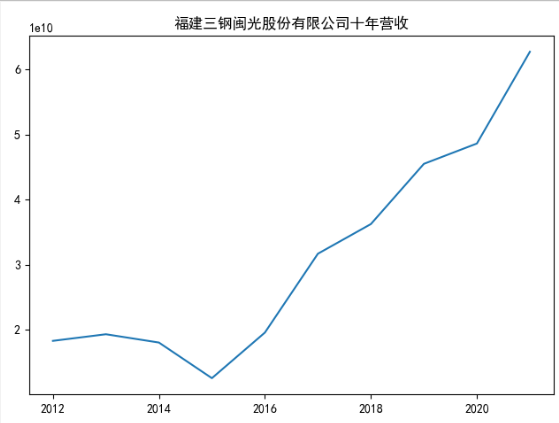
data['三钢闽光'].plot()
plt.title("福建三钢闽光股份有限公司十年营收")
plt.show()
#
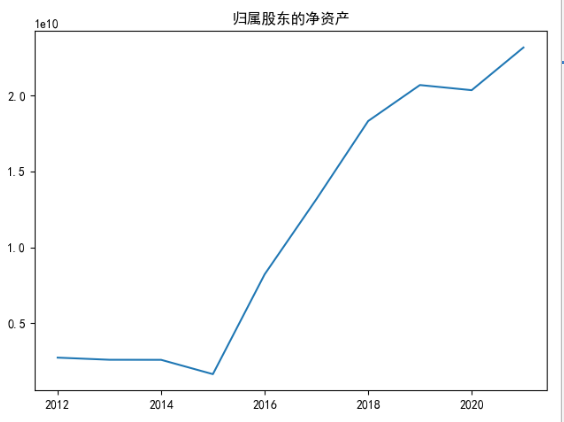
plt.title("归属股东的净资产")
data[10].plot()
plt.show()
# 对十家公司十年的营业收入绘制图像
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
x = range(2012,2022)
data = pd.read_excel("income.xlsx")
print(data)
data = data.T
# data = data.rename(columns={0:"002066"})
print(data)
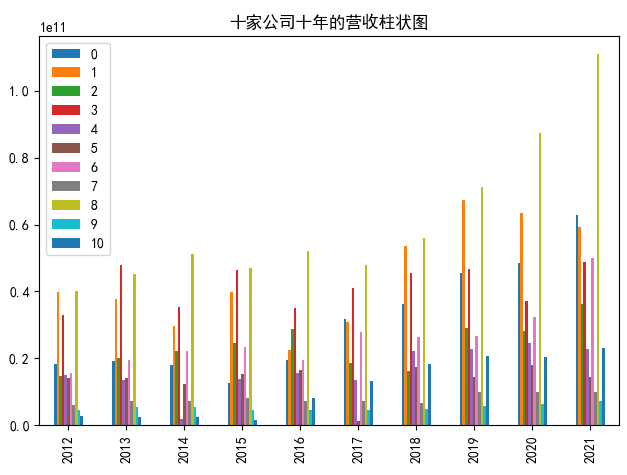
data.plot.bar()
plt.title("十家公司十年的营收柱状图")
plt.show()