from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import requests
import time
# from parse_disclosure_table import DisclosureTable
import re
import requests
import pandas as pd
# import fitz
import csv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from urllib.parse import urljoin # 用于拼接 URL
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
# 报告类型选择
# 选择年度报告类型
element = browser.find_element(By.CSS_SELECTOR, "#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(1)
firm = [
['000596' ,'古井贡酒'],
['000729' ,'燕京啤酒'],
['000858' ,'五粮液'],
['000799','酒鬼酒'],
['000848','承德露露'],
['000860','顺鑫农业'],
['000869','张裕A'],
['000929','兰州黄河'],
['002034','洋河股份'],
]
# 自动控制浏览器选择所取的公司
# 手动一个一个获取
for i in range(len(firm)):
name = firm[i][1]
code = firm[i][0]
f = open('inner_HTML_%s.html' %name,'w',encoding='utf-8')
element = browser.find_element(By.ID, "input_code").click()
element = browser.find_element(By.ID,'input_code').send_keys('%s' %code)
time.sleep(0.5)
element = browser.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
element = browser.find_element(By.ID,'disclosure-table')
time.sleep(0.5)
innerHTML = element.get_attribute('innerHTML')
f.write(innerHTML)
time.sleep(0.5)
f.close()
element = browser.find_element(By.CSS_SELECTOR, ".selected-item:nth-child(2) > .icon-remove").click()
time.sleep(0.5)
browser.quit()
"""
解析上市公司年报代码html,下载公司年报
"""
# 将获取的公司年报地址存入csv文件中
for i in range(len(firm)):
name = firm[i][1]
f = open('inner_HTML_%s.html' %name,encoding='utf-8')
t = f.read()
soup = BeautifulSoup(t, 'html.parser')
# print(type(t))
comments = soup.find_all('div', {'class': 'text-title-box'})
data_list = []
for item in comments:
content = item.find('span', {'class': 'pull-left title-text ellipsis'})
# print(content.text)
if content.text[-5:] != f"年年度报告":
continue
print(content.text)
# 找到报告的下载地址和名称
link = item.find("a", {"attachformat": "pdf"})
url = urljoin("https://www.szse.cn", link.get("href"))
name = link.find("span", {"class": "title-text"}).get("title")
# 将报告名和下载地址追加到 CSV 文件中
with open(f"{firm[i][1]}.csv", "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([name, url])
f.close()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
for i in range(len(firm)):
name = firm[i][1]
df = pd.read_csv(f'{name}.csv')
urls = df.iloc[:, 1].tolist()
for j in range(len(urls)):
ann_url = urls[j]
# 创建 WebDriver 对象
driver = webdriver.Chrome()
# 打开深交所网站并进入目标页面
driver.get(ann_url)
# 等待下载按钮可单击
download_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "a#annouceDownloadBtn[href*='info/download']")))
# 点击 "公告下载"
download_btn.click()
# 等待下载并关闭浏览器
time.sleep(10)
driver.quit()
# 在pdf中获取数据
import PyPDF2
import pandas as pd
# 打开PDF文件
for i in range(10):
name = firm[i]
for j in range(2012,2023):
with open(f'{name}{j}年年度报告.pdf', 'rb') as pdf_file:
# 创建文件阅读器
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
# 获取PDF中文本内容(一般情况下,表格一般在最后一页)
page_text = pdf_reader.getPage(pdf_reader.getNumPages()-1).extractText()
# 把文本内容分割成行
lines = page_text.split('\n')
# 提取表格数据
data = []
for line in lines:
# 通过判断年份来确定新的一行开始
if line.strip().isdigit():
year = line.strip()
continue
# 判断行是否包含股票代码,以此判断是否属于表格数据
if 'SH' in line or 'SZ' in line:
# 分割行中的数据,并在末尾添加年份
row_data = line.split()
row_data.append(year)
data.append(row_data)
# 创建DataFrame,并设置列名
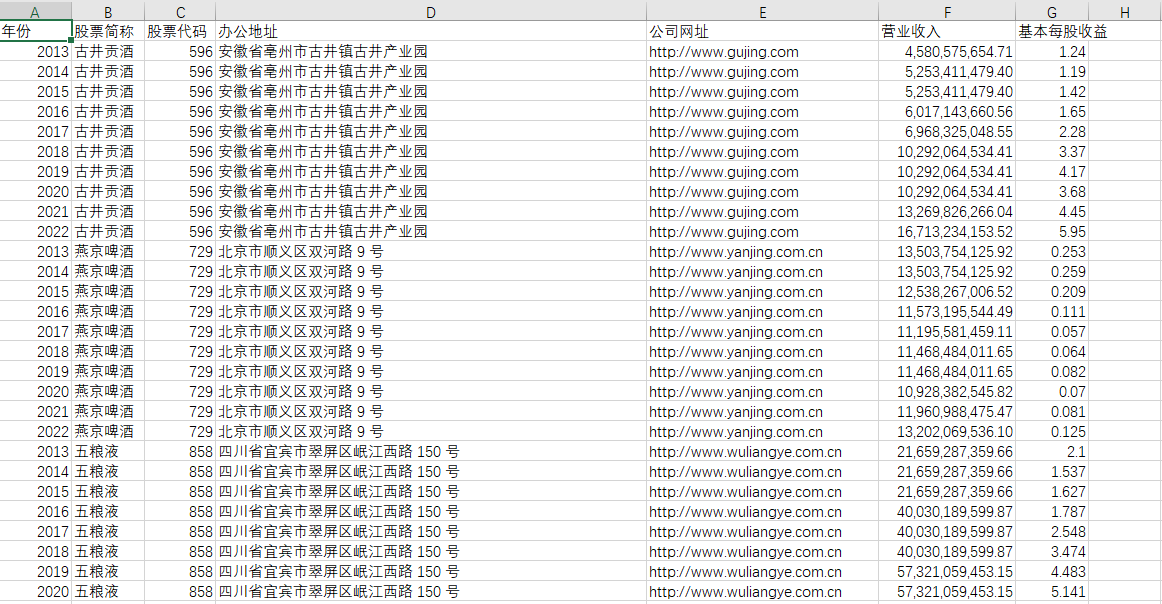
df = pd.DataFrame(data, columns=['股票代码', '股票简称', '办公地址', '公司网址', '营业收入', '基本每股收益', '年份'])
# 将DataFrame数据写入CSV文件
df.to_csv('公司.csv', index=False, encoding='utf-8')


import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司.csv', usecols=['年份', '营业收入', '基本每股收益'])
plt.figure()
plt.plot(df['年份'], df['营业收入'], 'o-', label='营业收入', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.title('金陵体育近十年营业收入变化趋势图')
plt.legend()
plt.show()
plt.figure()
plt.plot(df['年份'], df['基本每股收益'], 'x-', label='基本每股收益', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.title('金陵体育近十年基本每股收益变化趋势图')
plt.legend()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司.csv', usecols=['年份', '股票简称', '股票代码', '办公地址', '公司网址', '营业收入', '基本每股收益'])
grouped = df.groupby(['年份'])
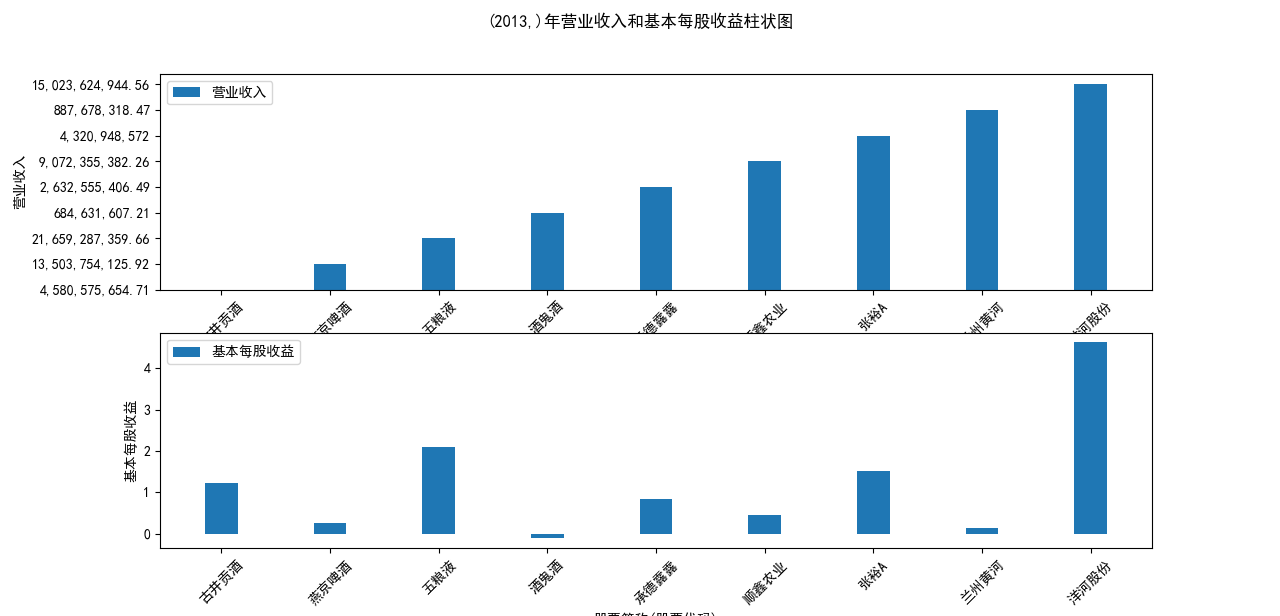
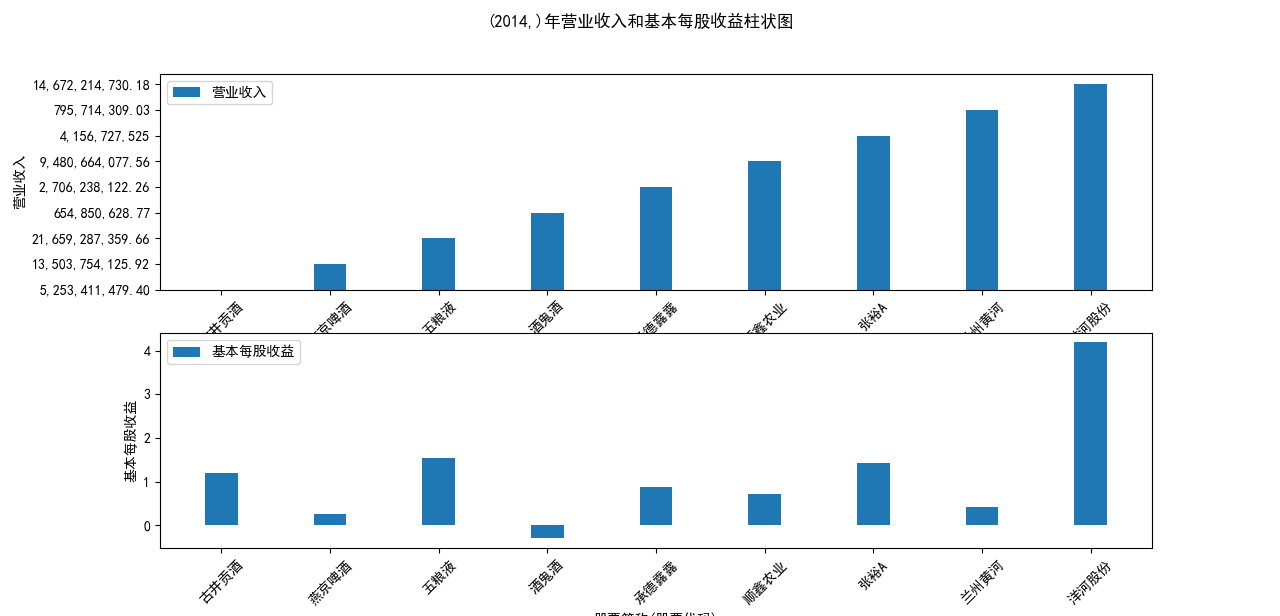
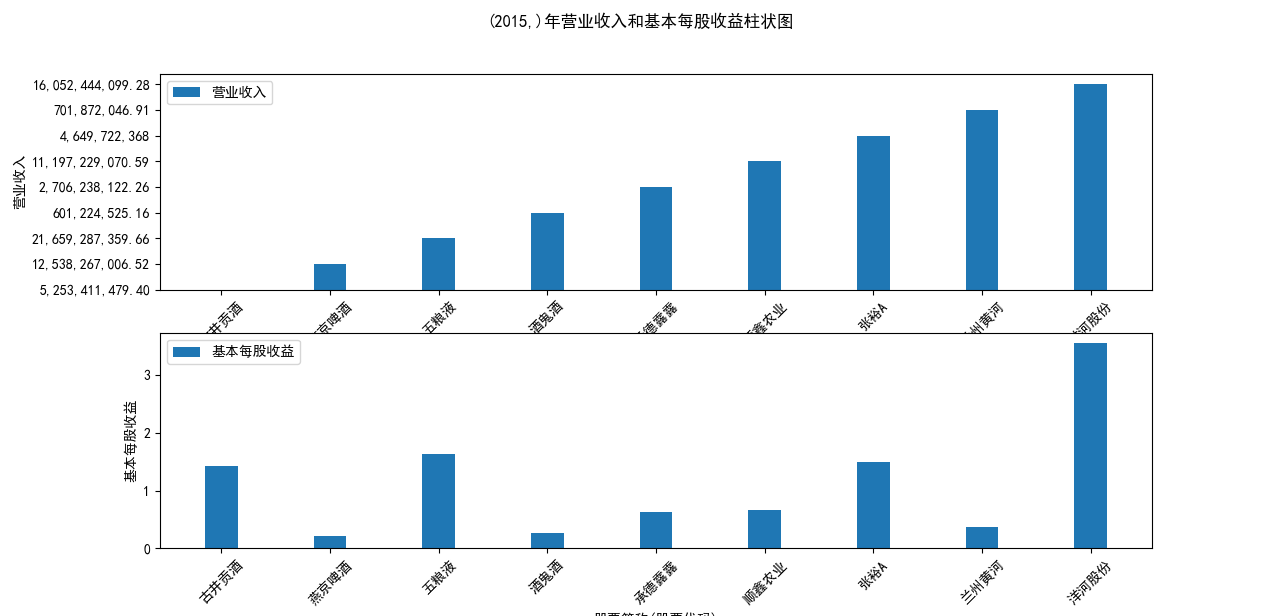
for name, group in grouped:
plt.figure(figsize=(12, 6))
plt.suptitle(f"{name}年营业收入和基本每股收益柱状图")
plt.subplot(211)
plt.bar(group['股票简称'], group['营业收入'], width=0.3, label='营业收入')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('营业收入')
plt.legend()
plt.subplot(212)
plt.bar(group['股票简称'], group['基本每股收益'], width=0.3, label='基本每股收益')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('基本每股收益')
plt.legend()
plt.show()
data = pd.read_csv('公司.csv')
#按年份从小到大排序
data = data.sort_values('年份')
#获取全部的股票信息
stocks = data['股票简称'].unique()
#按年份从小到大排序
data = data.sort_values('年份')
#获取全部的股票信息
stocks = data['股票简称'].unique()
fig, ax1 = plt.subplots(figsize=(12, 6))
# 绘制每个公司的营业收入
for stock in stocks:
stock_data = data[data['股票简称'] == stock]
# 将字符串中的逗号替换为空格,并将列类型转换为浮点数
stock_data['营业收入'] = stock_data['营业收入'].str.replace(',', '')
stock_data['营业收入'] = stock_data['营业收入'].str.replace(' ', '').astype(float)
ax1.plot(stock_data['年份'], stock_data['营业收入'], label=stock)
# 添加y轴标签、图例和标题
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入', color='tab:red')
ax1.tick_params(axis='y', labelcolor='tab:red')
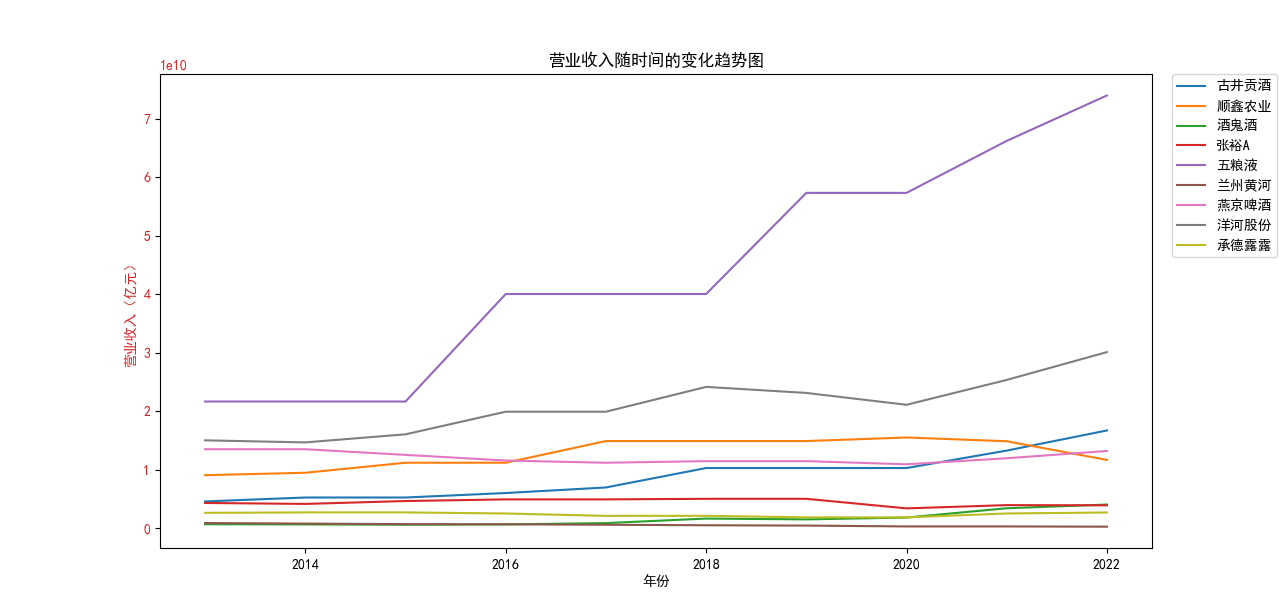
ax1.legend(loc='upper left', bbox_to_anchor=(1.02, 1), borderaxespad=0)
ax1.set_title('营业收入随时间的变化趋势图')
# 显示图形
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('公司_4.csv') # 读取文件
# 将字符串中的逗号替换为空格,并将列类型转换为浮点数
df['营业收入'] = df['营业收入'].str.replace(',', '')
df['营业收入'] = df['营业收入'].str.replace(' ', '').astype(float)
df['基本每股收益'] = df['基本每股收益'].astype(float)
# 获取不同年份的营业收入情况
year_revenue = df.pivot_table(index='年份', columns='股票简称', values='营业收入')
year_revenue.plot(kind='bar')
plt.title('营业收入对比图')
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.show()
# 获取不同年份的基本每股收益情况
year_eps = df.pivot_table(index='年份', columns='股票简称', values='基本每股收益')
year_eps.plot(kind='bar')
plt.title('基本每股收益对比图')
plt.xlabel('年份')
plt.ylabel('基本每股收益')
plt.show()
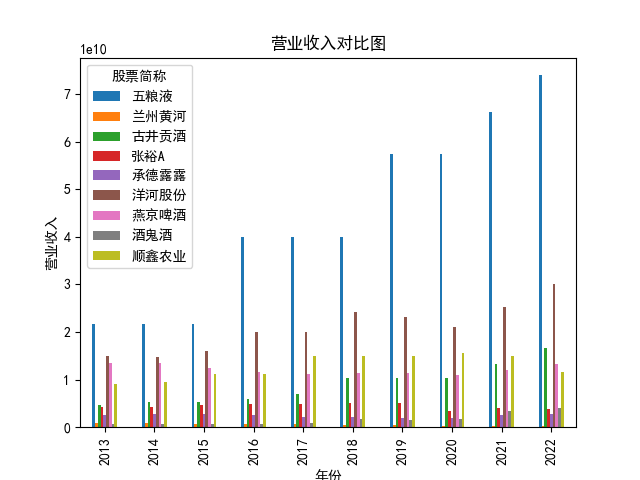
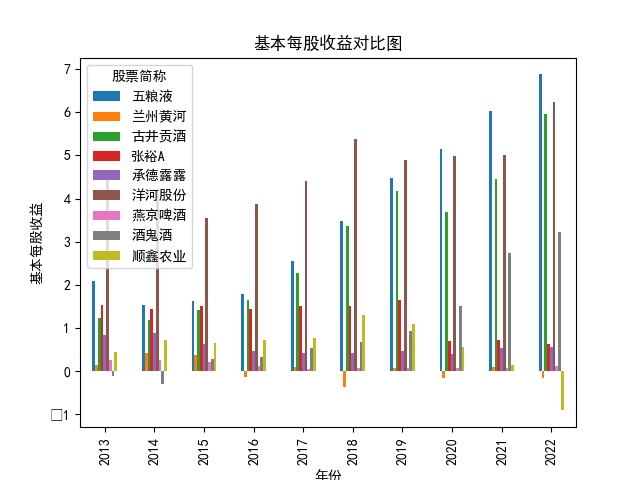
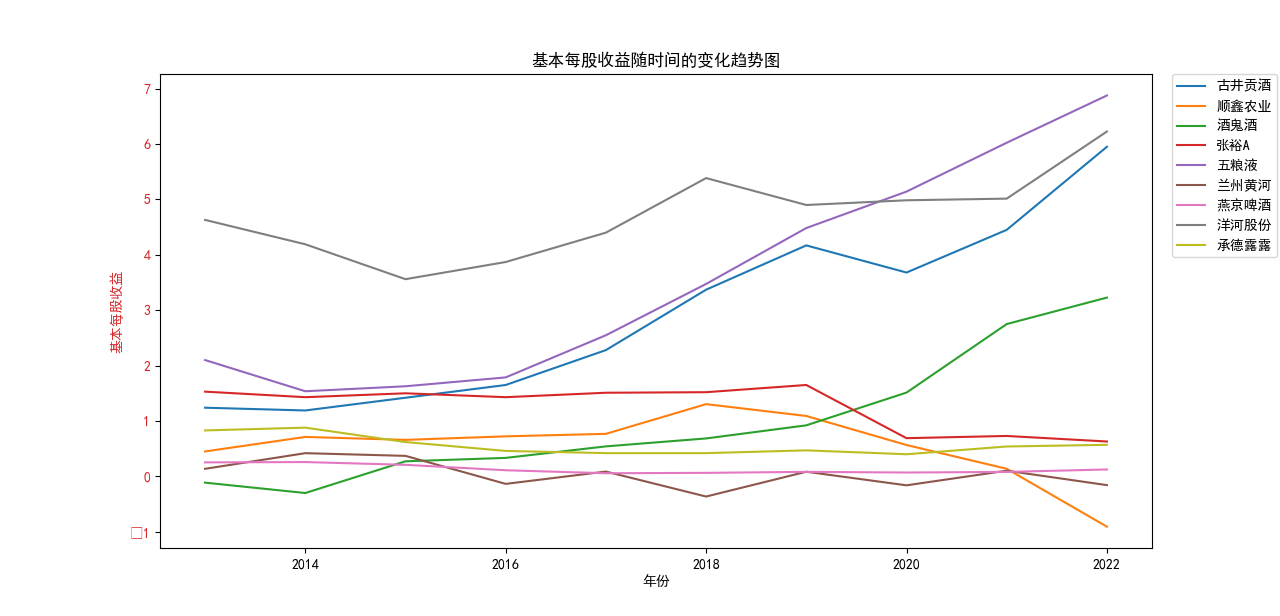
本次实验报告我所被分配到的行业是酒精、饮料,通过此次对数据的获取与处理, 就该行业多家企业的营业收入和基本每股收益我都有了较为初步的理解与认识。 从营业收入的角度来看,近十年五粮液始终遥遥领先于其他公司,并且在2018至2022年营业收入持 续突破新高,并且一直呈稳步增长态势;洋河股份与顺鑫农业经营表现也很不错,燕京啤酒与顺鑫 农业多年来营业收入也不相上下,但燕京啤酒近两年营业收入有下滑趋势。其中,古井贡酒十年中 一直保持一个较慢的速度增长;兰州黄酒和酒鬼酒近十年营业收入数据远远比不上其他企业。就统 计的这十家企业,总体看来营业收入都呈现相对稳定并且有上升趋势,由此可以推及该行业其他公 司大体趋势是上升的,或者可以看出,近几年该行业的行业环境比较稳定。 从基本每股收益变化的角度来看,除了洋河股份、古井贡酒、五粮液之外,大部分公司的基本每股 收益都有一定的起伏波动,其中中兰州黄河、酒鬼酒的波动幅度比较突出;而如张裕A等小部分公 司的基本每股收益波动不大。值得一提的是,五粮液虽在2013-2016年每股收益呈下降趋势,但 2017-2022年稳步上升,已经达到了这些企业中每股收益最高的企业,发展态势很好。洋河股份在 2018年达到巅峰后略有下降,在2022年再次回到顶峰,总体来看发展趋势也很不错。 总体来看,该行业近十年行业环境较为稳定,只有小部分企业存在一定的波动。
总的来说,本次作业对我来说真的是一个巨大的挑战。以前对于python只接触了一些比较简单的 代码以及作图,没有涉及到数据获取、处理分析这些内容,通过本学期的学习让我感受到了python 拥有非常强大的功能,能够快速而准确地处理大量数据,为我们的分析工作大大减少了工作量, 希望在将来我还能够继续学习更多的python技术并且将它运用到今后的工作中去。