#导入所需要的模块
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import re
import requests
import pandas as pd
import fitz
import csv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from urllib.parse import urljoin
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
#报告类型选择
element = browser.find_element(By.CSS_SELECTOR,"#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT,"年度报告").click()
#日期选择
element = browser.find_element(By.CSS_SELECTOR, ".input-left").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
element = browser.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
element = browser.find_element(By.LINK_TEXT, "6月").click()
element = browser.find_element(By.CSS_SELECTOR, ".active > .dropdown-menu li:nth-child(1)").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
element = browser.find_element(By.CSS_SELECTOR, ".today > .tdcontainer").click()
element = browser.find_element(By.ID, "query-btn").click()
#下载行业分类结果PDF文件
href = 'http://www.csrc.gov.cn/csrc/c100103/c1558619/1558619/files/1638277734844_11692.pdf'
r = requests.get(href,allow_redirects=True)
f = open('2021年3季度上市公司行业分类结果.pdf','wb')
f.write(r.content)
f.close()
r.close()
#获取行业分类结果PDF文件中69类行业所有上市公司
doc = fitz.open('2021年3季度上市公司行业分类结果.pdf')
doc.page_count
page1 = doc[4]
page2 = doc[5]
toc_txt1 = page1.get_text()
toc_txt2 = page2.get_text()
r1 = re.compile('(?<=\农副产品加工业\n)(.*)(?=\n)',re.DOTALL)
txt1 = r1.findall(toc_txt1)
r2 = re.compile('(?<=\农副产品加工业\n)(.*?)(?=\双汇发展)',re.DOTALL)
txt2 = r2.findall(toc_txt2)
r = re.compile('(\d{6})\s*(\w+)\s*')
text1 = r.findall(txt1[0])
text2 = r.findall(txt2[0])
firm = text1 + text2
#自动控制浏览器选择所取的公司
for i in range(len(firm)):
name = firm[i][1]
code = firm[i][0]
f = open('inner_HTML_%s.html' %name,'w',encoding='utf-8')
element = browser.find_element(By.ID, "input_code").click()
element = browser.find_element(By.ID,'input_code').send_keys('%s' %code)
time.sleep(0.5)
element = browser.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
element = browser.find_element(By.ID,'disclosure-table')
time.sleep(0.5)
innerHTML = element.get_attribute('innerHTML')
f.write(innerHTML)
time.sleep(0.5)
f.close()
element = browser.find_element(By.CSS_SELECTOR, ".selected-item:nth-child(2) > .icon-remove").click()
time.sleep(0.5)
browser.quit()
# 将获取的公司年报地址存入csv文件中
for i in range(len(firm)):
name = firm[i][1]
f = open('inner_HTML_%s.html' %name,encoding='utf-8')
t = f.read()
soup = BeautifulSoup(t, 'html.parser')
# print(type(t))
comments = soup.find_all('div', {'class': 'text-title-box'})
data_list = []
for item in comments:
content = item.find('span', {'class': 'pull-left title-text ellipsis'})
# print(content.text)
if content.text[-5:] != f"年年度报告":
continue
print(content.text)
# 找到报告的下载地址和名称
link = item.find("a", {"attachformat": "pdf"})
url = urljoin("https://www.szse.cn", link.get("href"))ArithmeticError
name = link.find("span", {"class": "title-text"}).get("title")
# 将报告名和下载地址追加到 CSV 文件中
with open(f"{firm[i][1]}.csv", "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([name, url])
f.close()
# PDF文件下载
# 创建 WebDriver 对象
driver = webdriver.Chrome()
# 打开浏览器并访问目标页面
ann_url = "https://www.szse.cn/disclosure/listed/bulletinDetail/index.html?94f2f5f8-d805-4b0f-bc7c-b30a5d33f8a2"
driver.get(ann_url)
# 后续代码的部分不变
# 3. 在 "年度报告" 页面下载 PDF 文件
# 点击 "公告下载"
download_btn = driver.find_element(By.LINK_TEXT, "公告下载")
download_btn.click()
# 等待下载并关闭浏览器
time.sleep(10)
driver.quit()
def find_table(filename, target_title):
doc = fitz.open(filename)
for page in doc:
# 搜索目标标题所在的矩形区域
rect = page.search_for(target_title)[0]
# 获取标题下的一段文本,文本中包含表格内容
text = page.get_text("text")
start = text.find(target_title) + len(target_title)
end = text.find("\n\n", start)
table_text = text[start:end].strip()
# 使用正则表达式提取表格中的数据
pattern = r"(\S+)\s+(\S+)[^\n]*\n"
header = ["营业收入(元)", "基本每股收益(元/股)"]
data = dict(zip(header, re.findall(pattern, table_text)))
print(f"营业收入: {data['营业收入(元)']}")
print(f"基本每股收益: {data['基本每股收益(元/股)']}")
return
print("没有找到目标标题")
# 获取信息得到csv文件
find_table('./test.pdf', '主要会计数据和财务指标')
# 绘图(以新希望企业为例)
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('ans.csv', usecols=['年份', '营业收入', '基本每股收益'])
plt.figure()
plt.plot(df['年份'], df['营业收入'], 'o-', label='营业收入', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.title('新希望近十年营业收入变化趋势图')
plt.legend()
plt.show()
plt.figure()
plt.plot(df['年份'], df['基本每股收益'], 'x-', label='基本每股收益', linewidth=2)
plt.xticks(rotation=45)
plt.xlabel('年份')
plt.ylabel('基本每股收益')
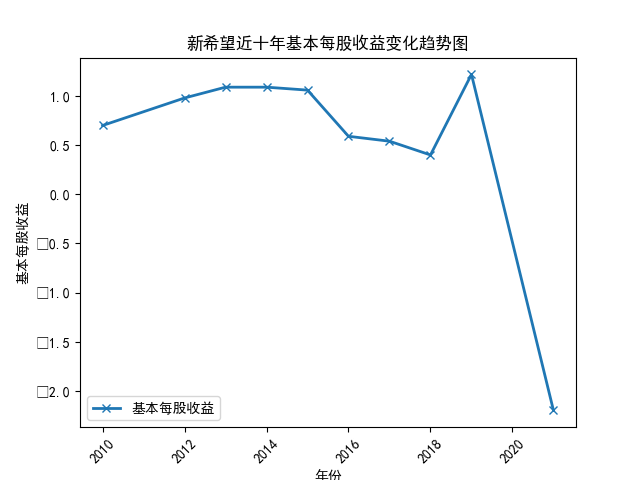
plt.title('新希望近十年基本每股收益变化趋势图')
plt.legend()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
df = pd.read_csv('ans.csv', usecols=['年份', '股票简称', '股票代码', '办公地址', '公司网址', '营业收入', '基本每股收益'])
grouped = df.groupby(['年份'])
for name, group in grouped:
plt.figure(figsize=(12, 6))
plt.suptitle(f"{name}年营业收入和基本每股收益柱状图")
plt.subplot(211)
plt.bar(group['股票简称'], group['营业收入'], width=0.3, label='营业收入')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('营业收入')
plt.legend()
plt.subplot(212)
plt.bar(group['股票简称'], group['基本每股收益'], width=0.3, label='基本每股收益')
plt.xticks(rotation=45)
plt.xlabel('股票简称(股票代码)')
plt.ylabel('基本每股收益')
plt.legend()
plt.show()
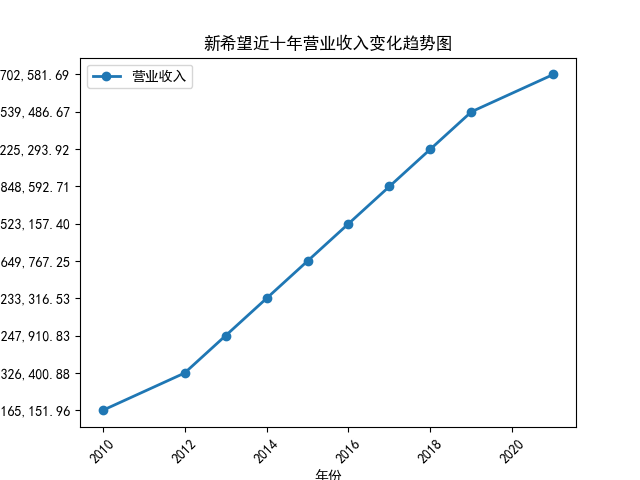
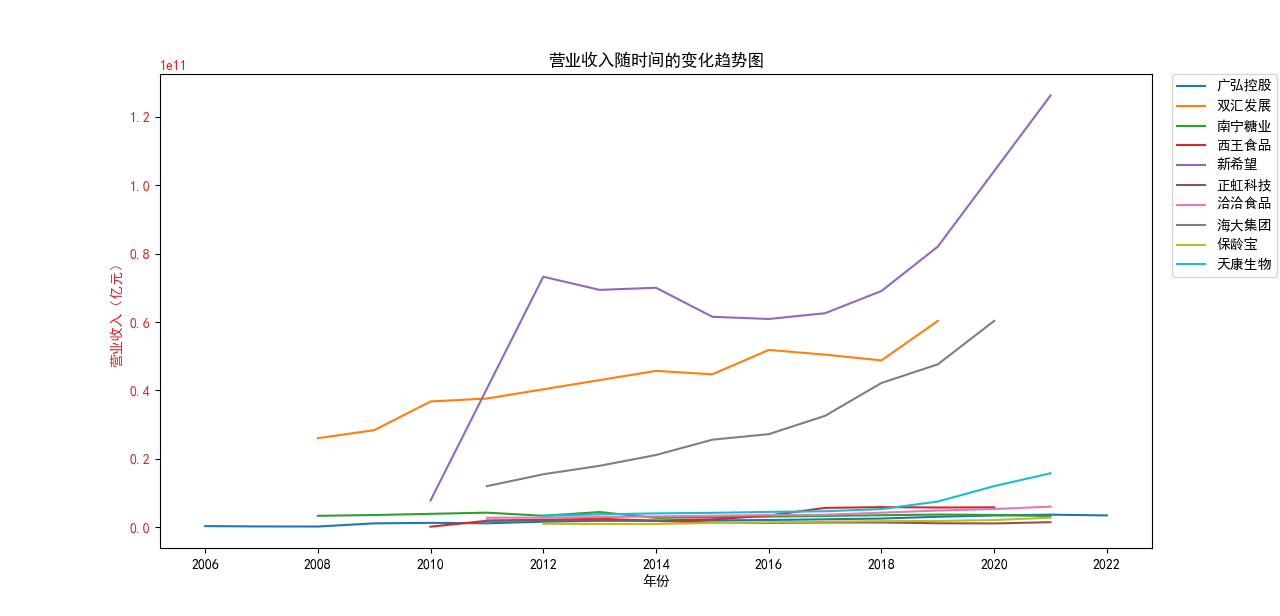
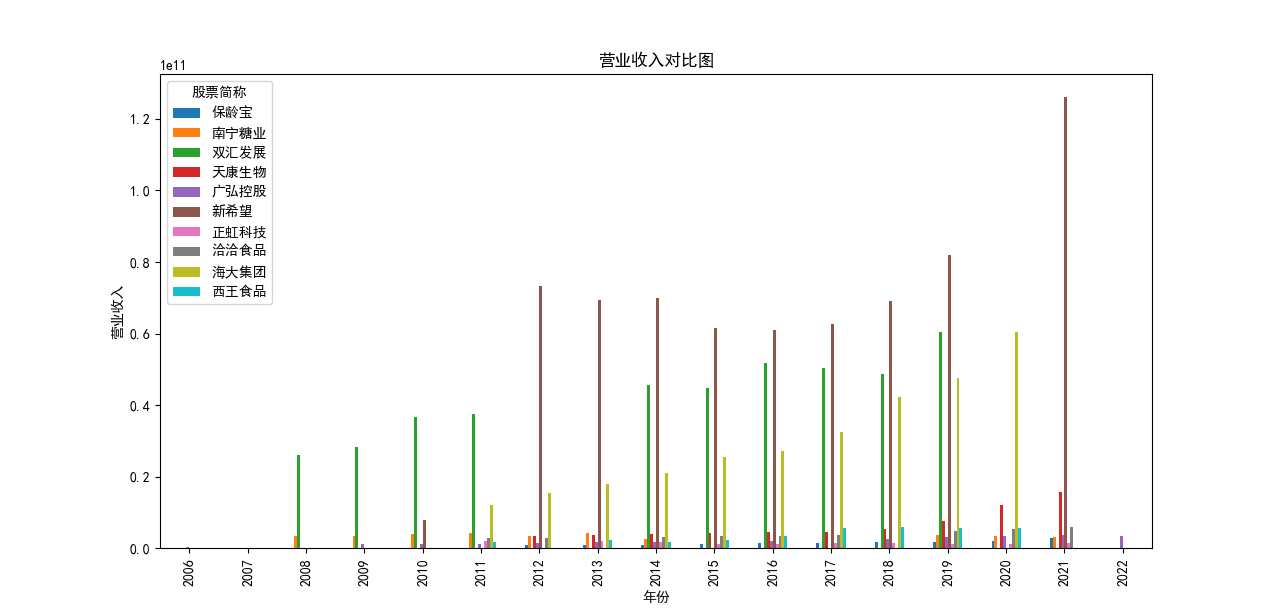
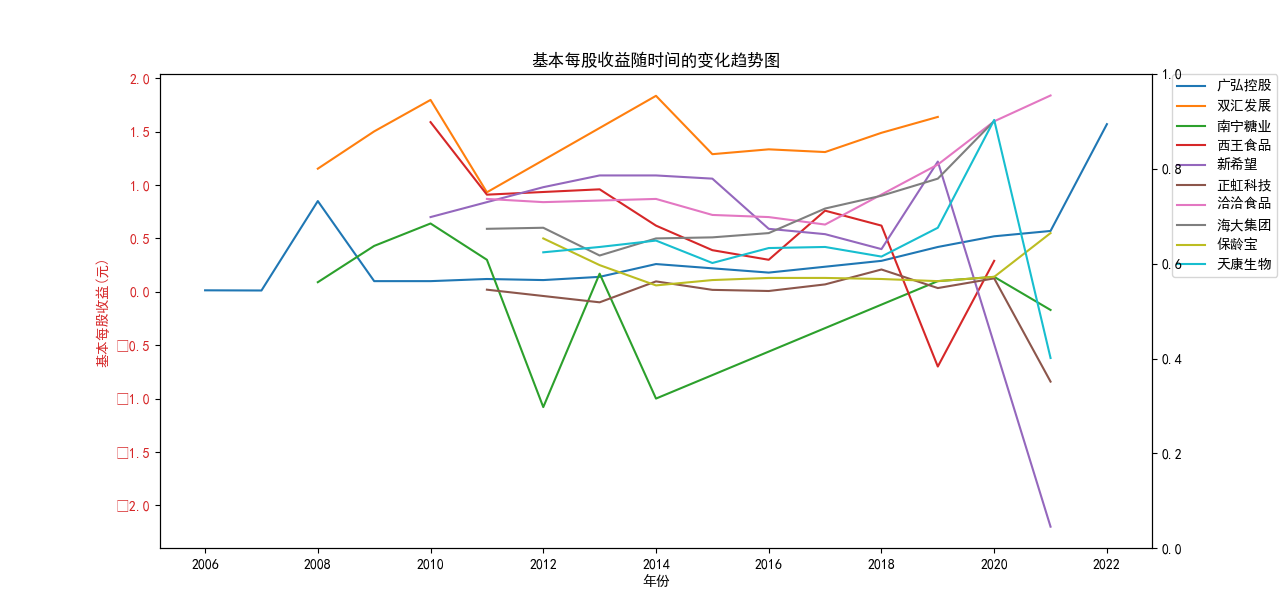
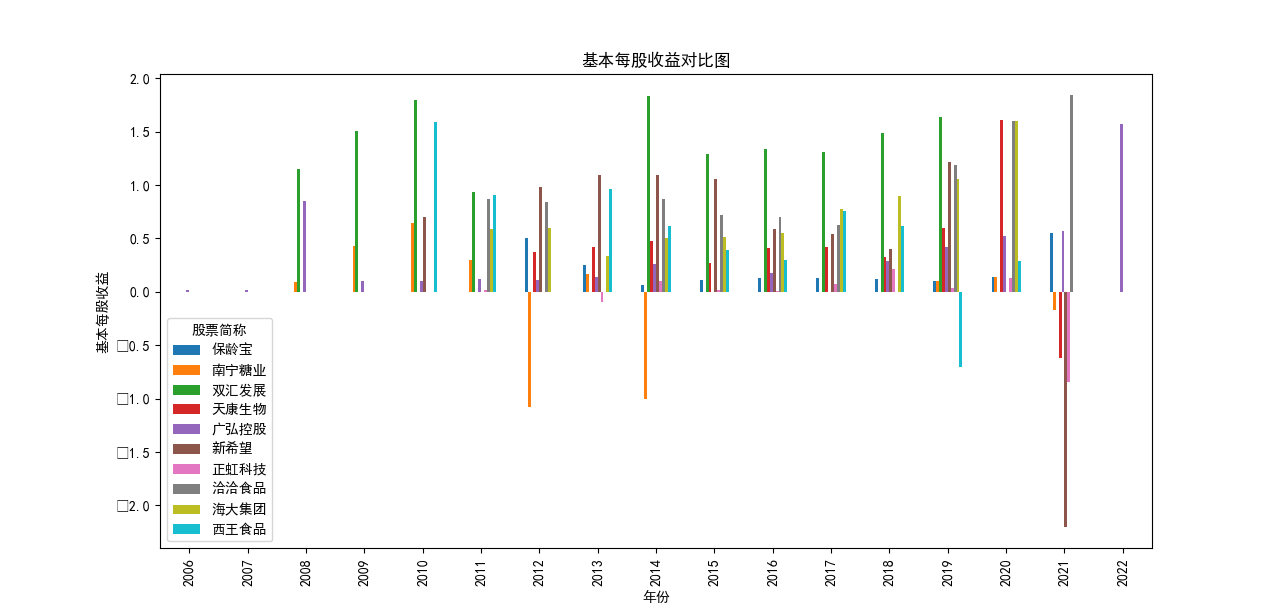
从营业收入随时间的变化趋势图来看,几乎所有企业都呈现着上涨的趋势,即便在疫情期间,农副产品加工业所包含的很多企业的营业收入并未收到很大影响, 原因是像类似这种食品企业主要是一条龙生产、打包、售卖,产业链已很成熟,且需要线下面对面接待顾客的机会很少。 总的来看,新希望企业在农副产品加工领域遥遥领先,紧跟着的双汇发展和海大集团。
从基本每股收益随时间的变化趋势图来看,营业收入排在前两位的企业:
新希望、双汇发展 波动巨大,企业所面临的预期收益率也随之变化较大。
除此之外,南宁糖业也具有很大的波动,可能与企业自身营,预期前景因素有关。
最开始对这门课程的理解是从不同的官网寻找数据,最终把他们汇总,通过建模,画出想要的图。经过慢慢的学习发现要远比我之前想的复杂, 包含了爬取年报,获取年报里的数据,生成文件,画图。其实对我来讲,每一步都是困难的,总会有当下摸不着头脑的报错,但通过网站学习,请教老师、同学也解决了挺多问题。
总得来说,这门课对我来说是一个很大的挑战,之前接触过的类似课程只有最简单的关于Python的学习,以及金融建模, 真正去实操爬取某个公司的年报再进行摘取、汇总、分析还是第一次,同时还学到了一点网页制作。很实践的一门课程,在之后学习乃至以后的工作中都有可能用到。