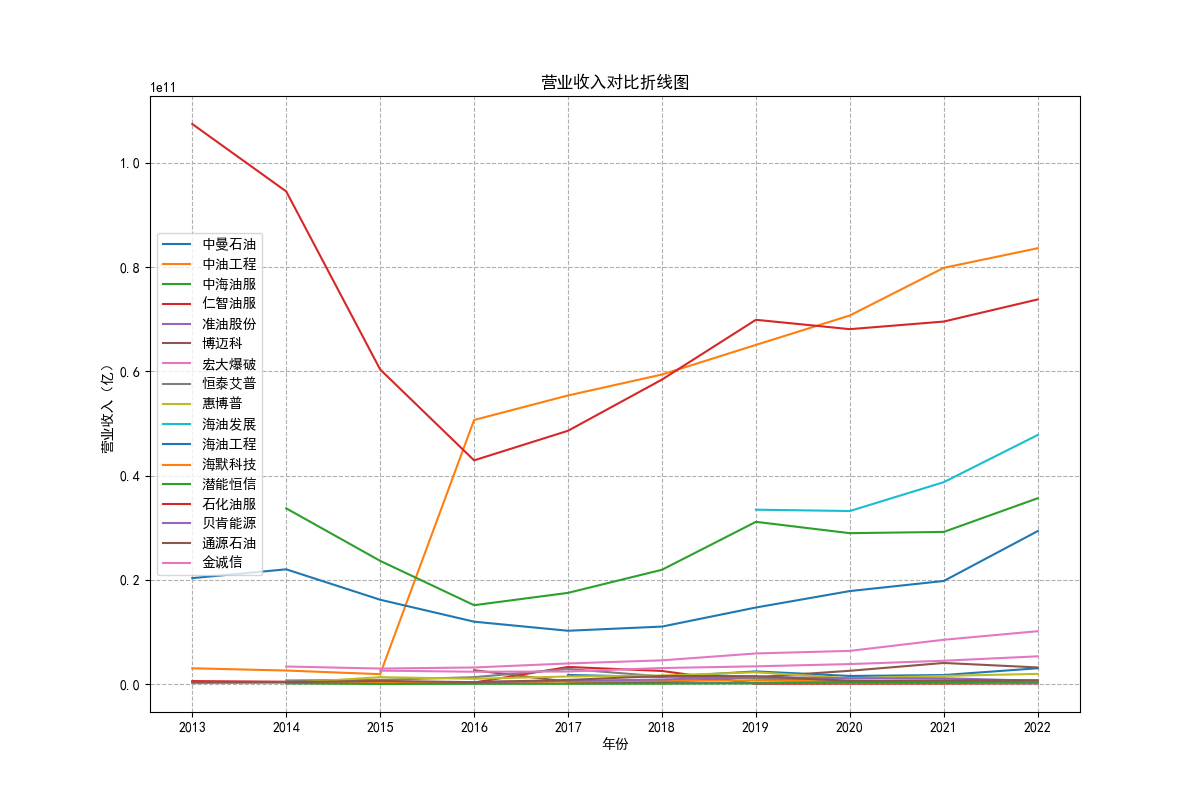
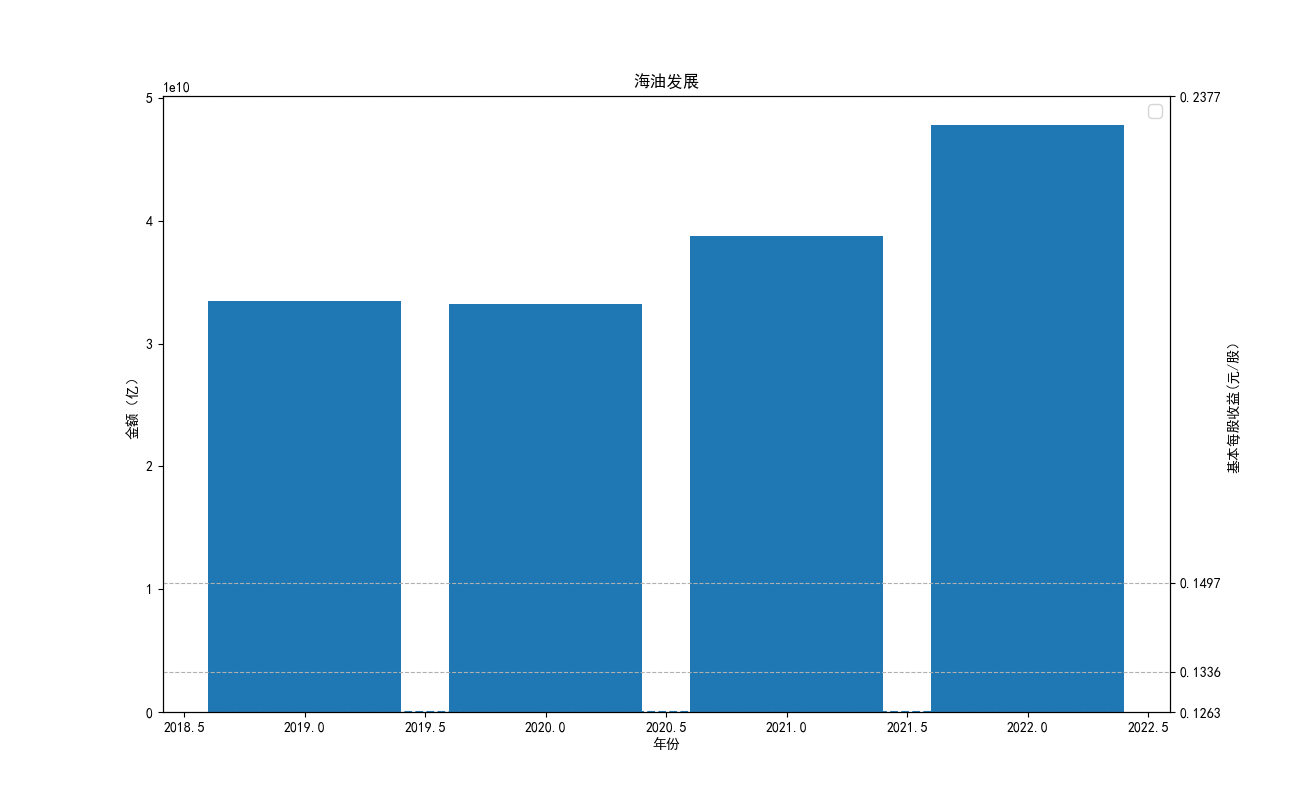
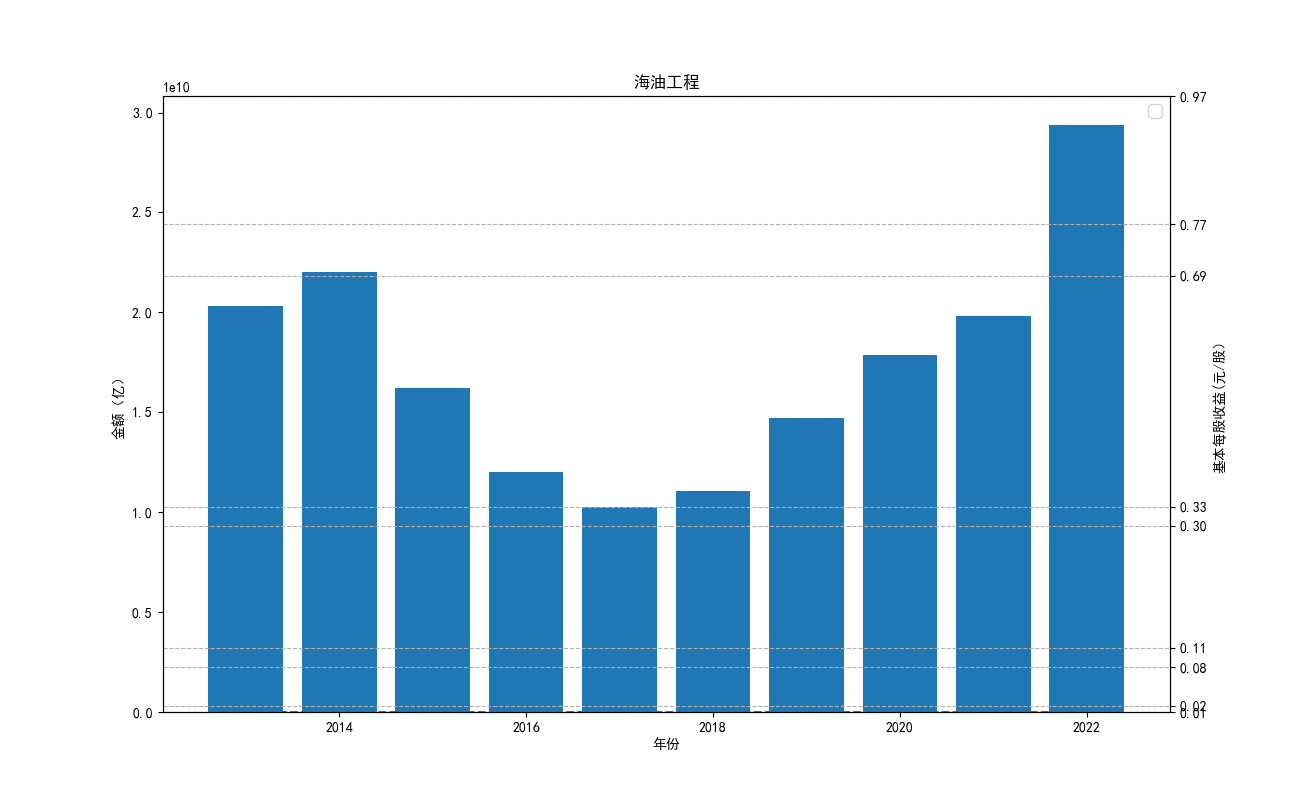
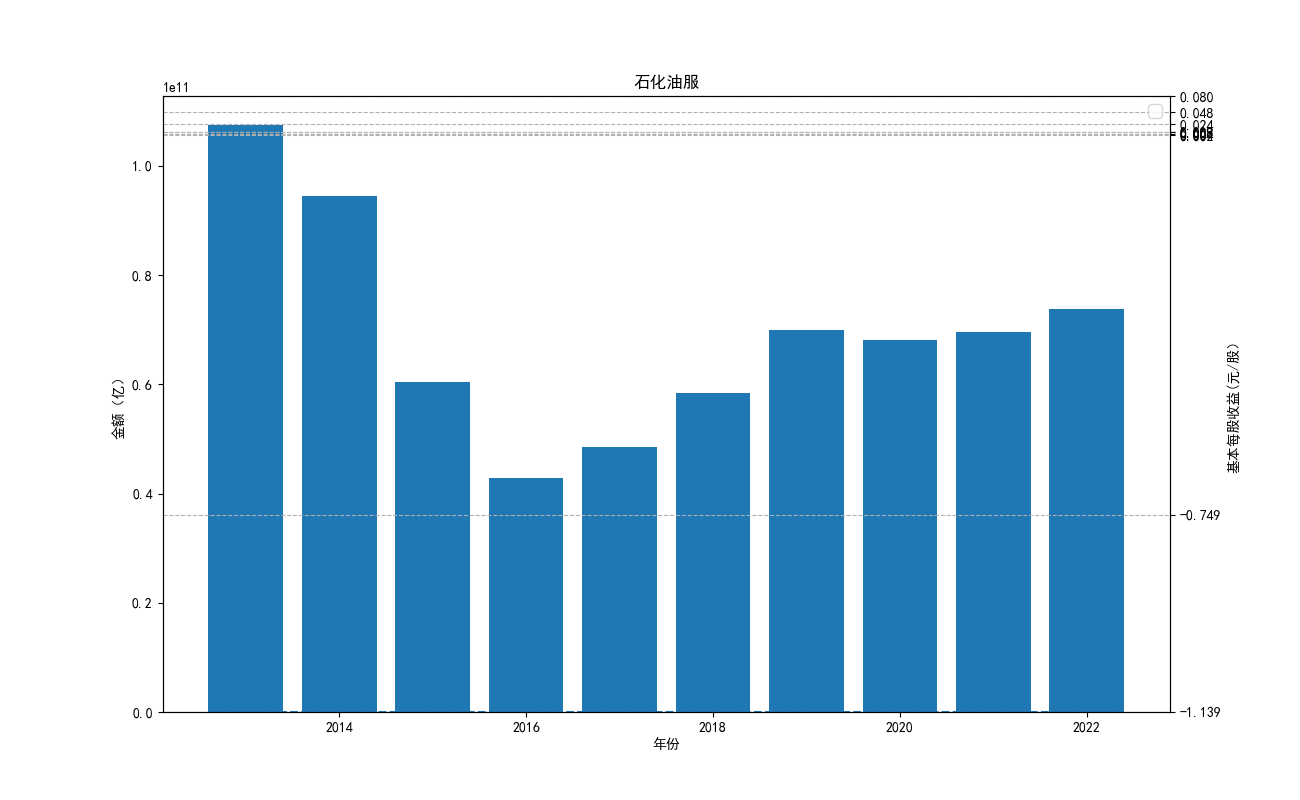
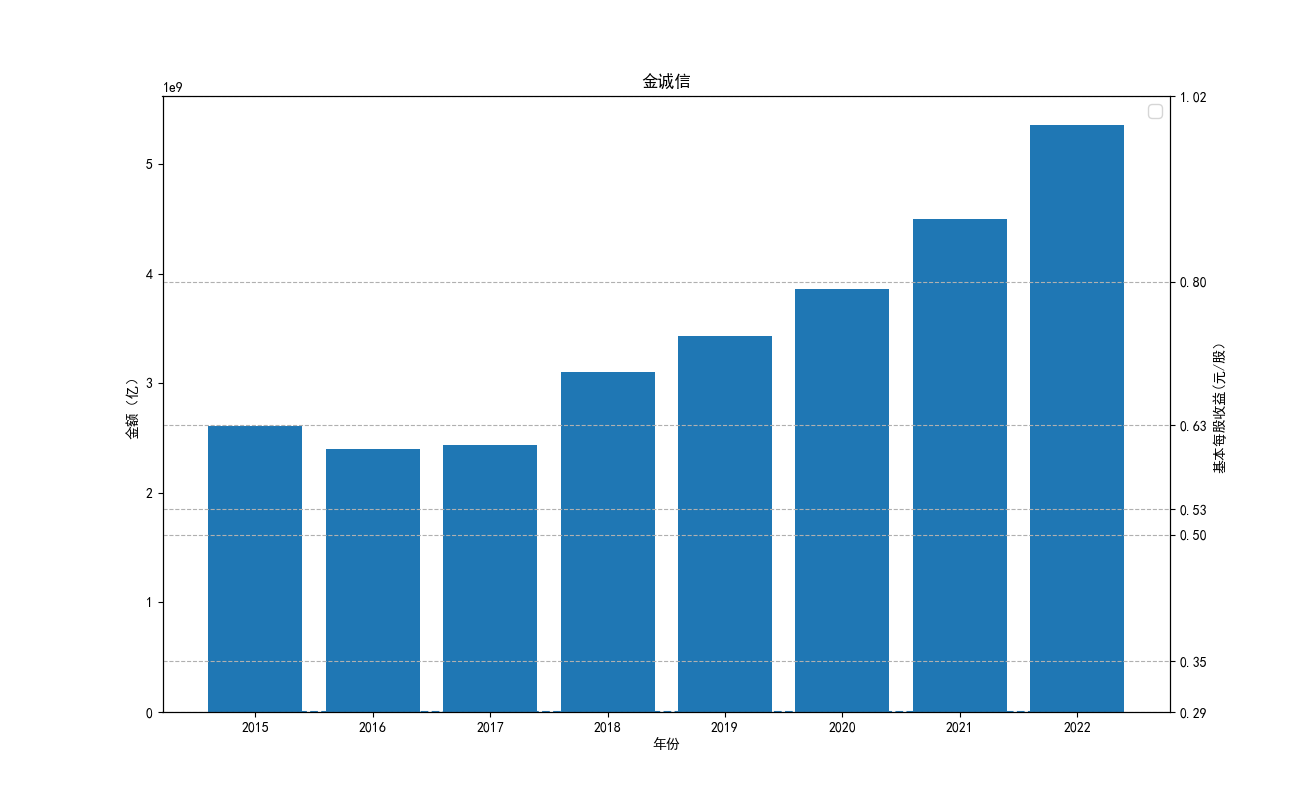
由“各公司10年来营业收入图”可知,海油工程公司营业收入波动性极大,在2022年其营业收入达到最低点。 剩余一些股票波动性很小,基本维持一种稳定状态。但海油发展自发行后营业收入便遥遥领先。其中,海油 工程的营业收入本来远远高于其他公司,但自2020年后,该公司受到某一刺激后,营业收入急剧下降,跌入 谷底。而宏大爆破和金诚信的营业收入基本没有什么变化。
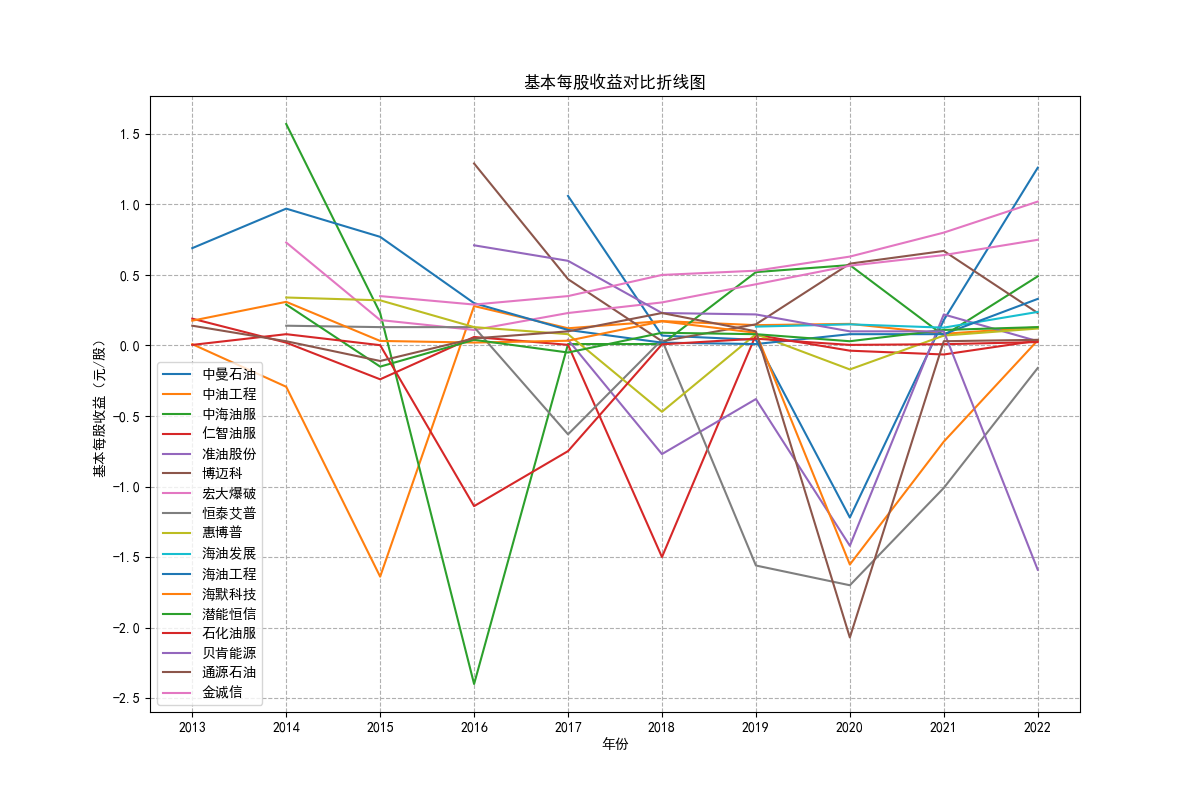
由“各公司10基本每股收益”可知,基本每股收益整体波动性较大,呈现下降趋势。但2022年与2012年相比 较,我们发现,其每股收益基本没有变化,可见,疫情下的股市逐渐恢复稳定。与上图相对应,基本每股收益 与营业收入的波动性往往同向变化,海油工程的每股收益波动性较其他股票波动性强。
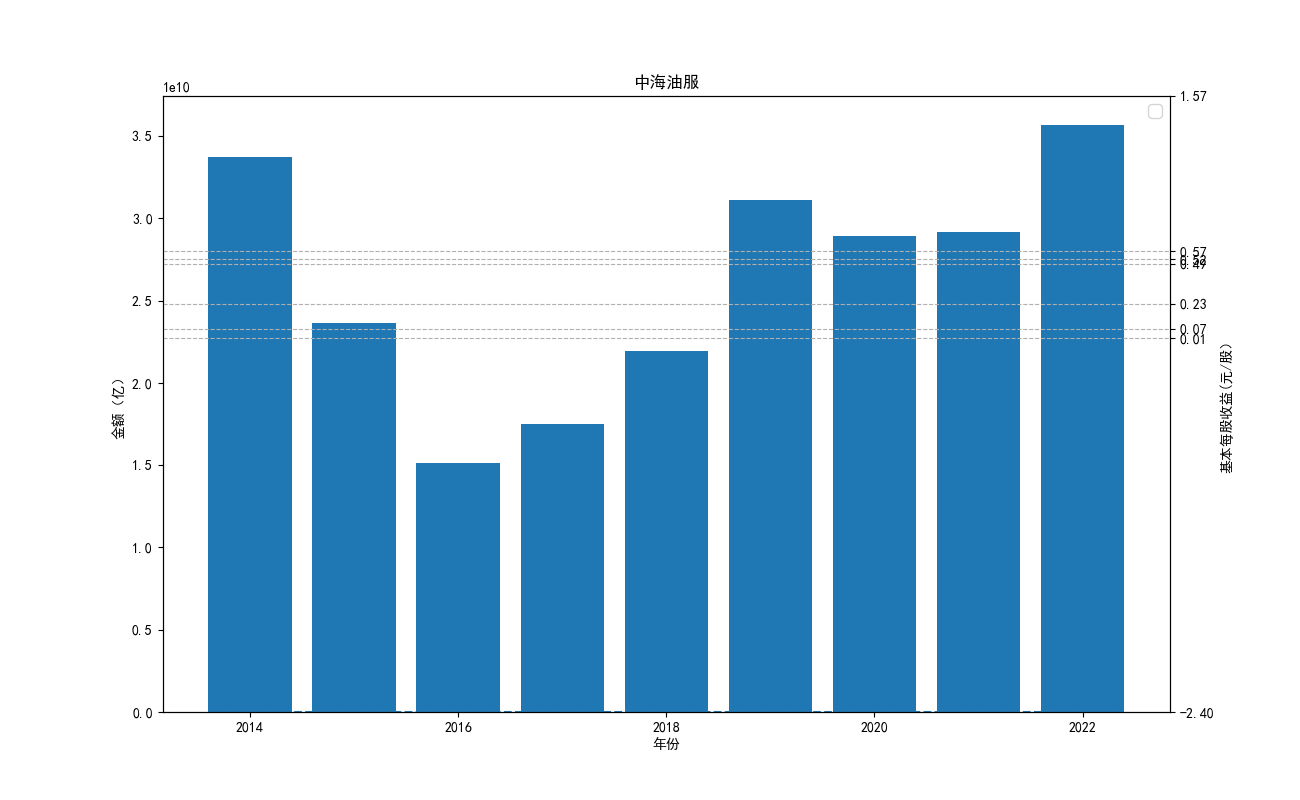
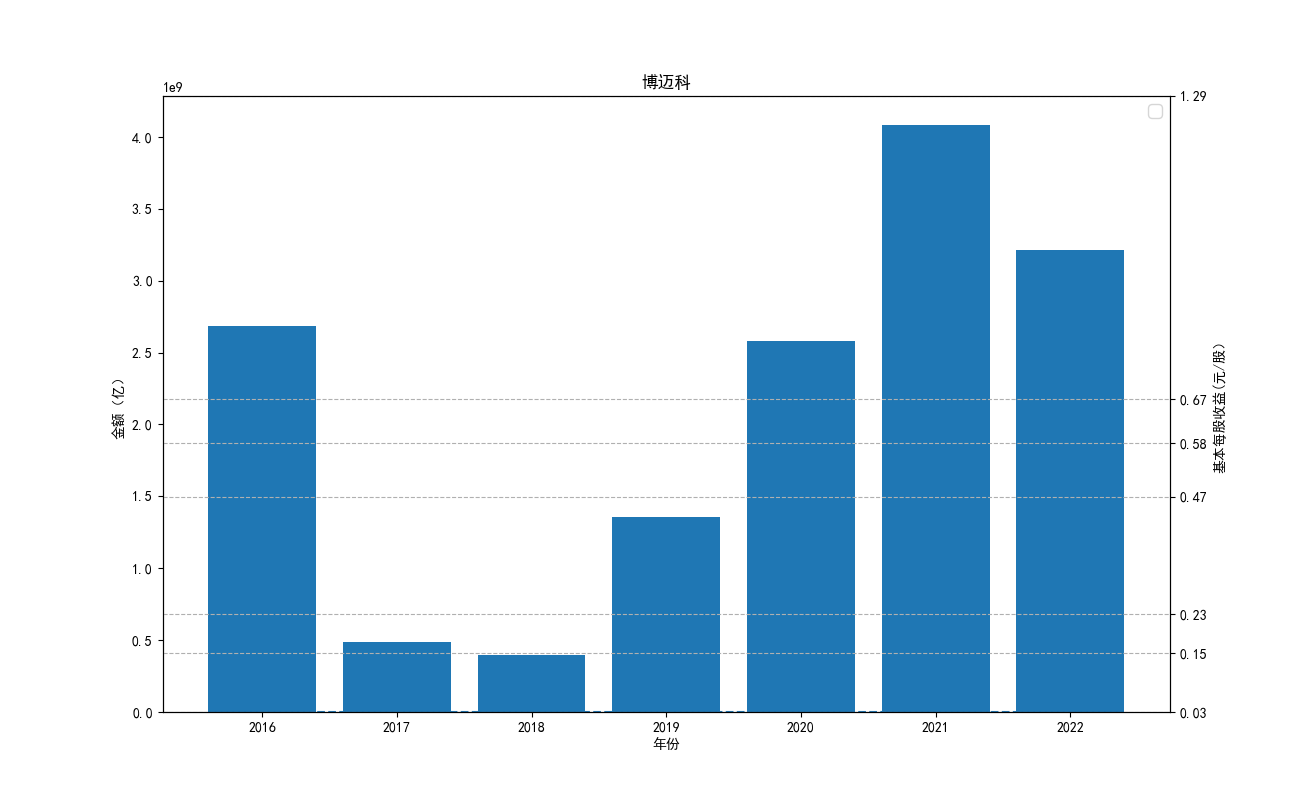
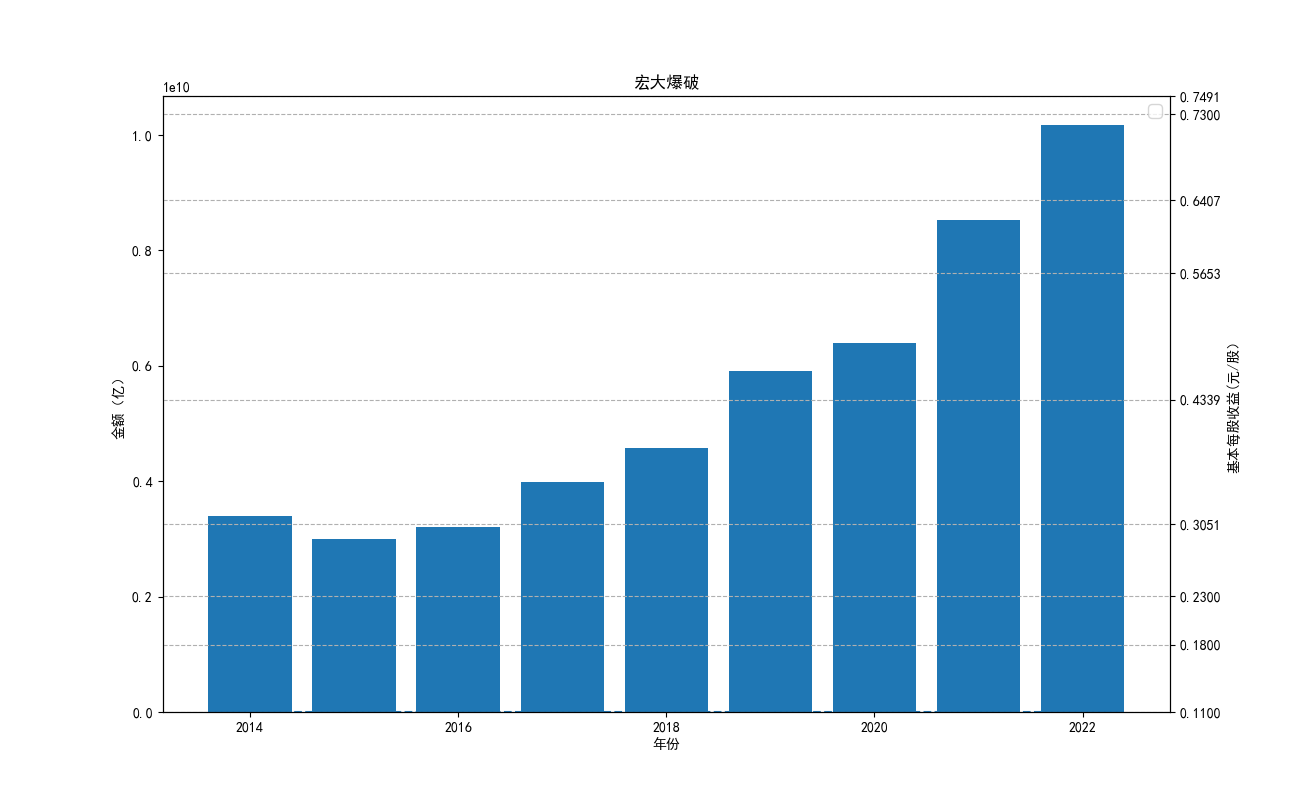
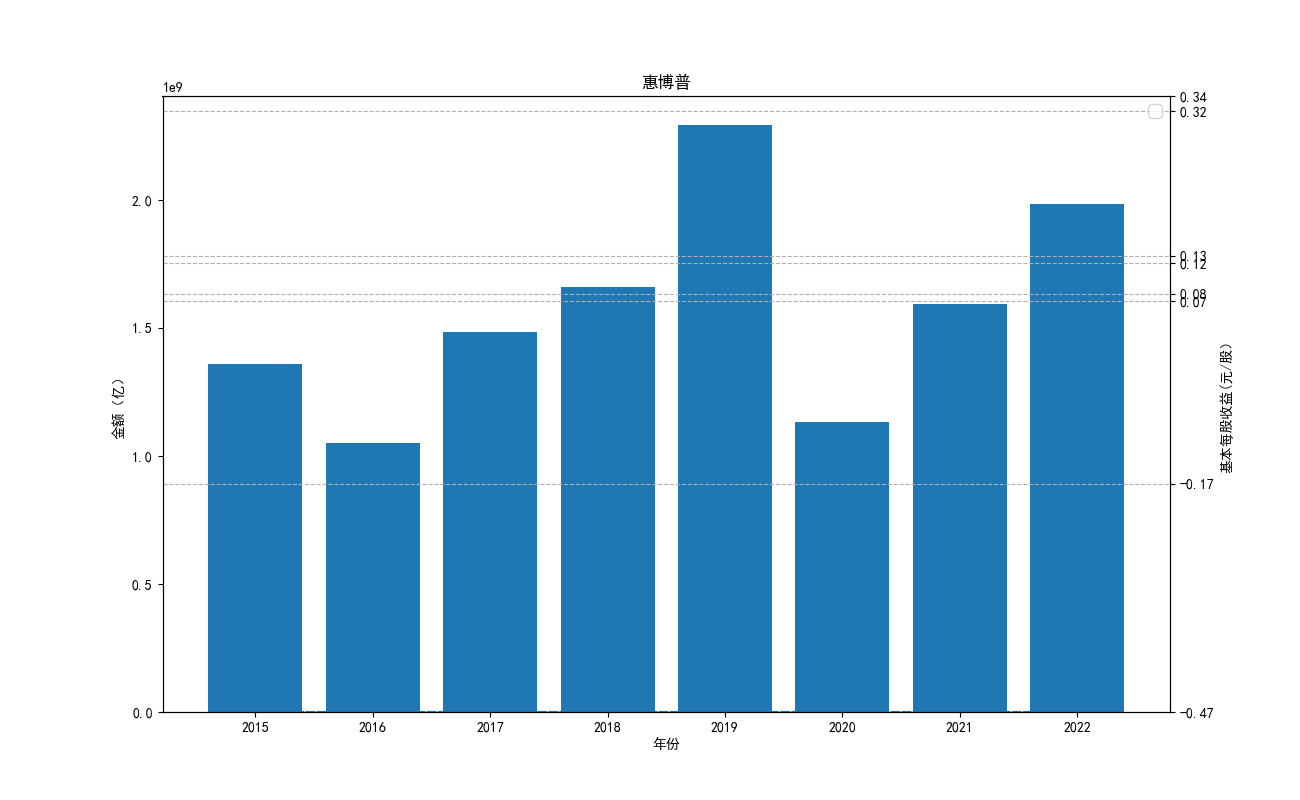
import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
list = ["002207","002554","002629","002683","002828","300084","300157","300164","300191","600339","600583","600871",
"600968","601808","603619","603727","603979"]
for company in list:
os.mkdir(company)
orgId, plate, code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")

将所分配的公司的年报从网站上爬取下来.
import pdfplumber
import os
import pandas as pd
import pdfplumber
def getfns(path,suffix):
res=[os.path.join(path,fname) for fname in os.listdir(path) if fname.endswith(suffix)]
return res
paths = ['E:/系统/桌面/作业/002207', 'E:/系统/桌面/作业/002554','E:/系统/桌面/作业/002629','E:/系统/桌面/作业/002683','E:/系统/桌面/作业/002828','E:/系统/桌面/作业/300084','E:/系统/桌面/作业/300157','E:/系统/桌面/作业/300164','E:/系统/桌面/作业/300191','E:/系统/桌面/作业/600339','E:/系统/桌面/作业/600583','E:/系统/桌面/作业/600871','E:/系统/桌面/作业/600968','E:/系统/桌面/作业/601808','E:/系统/桌面/作业/603619','E:/系统/桌面/作业/603727','E:/系统/桌面/作业/603979'] # 文件夹路径列表
suffix = '.pdf'
def f1(lst): # get c1
c1 = [e[0] for e in lst]
return c1
def f2(lst): # get c1 and c2
c12 = [e[:2] for e in lst]
c6 = d[5]
return c12
for path in paths:
company_code = os.path.basename(path)
fns = getfns(path,'.pdf')
for e in fns:
if '更新' not in e:
with pdfplumber.open(e) as pdf:
for page in pdf.pages:
d = page.extract_table()
if d is not None:
c1 = f1(d)
if '' == c1[0] and '营业收入(元)' in c1 and '基本每股收益(元/股)' in c1:
c12 = f2(d)
print(c12[0][1], c12[1][1])
for c in c12:
if c[0] == '基本每股收益(元/股)':
print(c[1])
data = {
'年份': c12[0][1],
'营业收入(元)': c12[1][1],
'基本每股收益(元/股)': c[1],
'股票代码': company_code,
'办公地址': c12[10],
'公司网址': c12[12],
}
df = pd.DataFrame([data])
df.to_csv('数据.csv', index=False, mode='a', header=not os.path.exists('数据.csv'))
break # 添加注释,结束循环
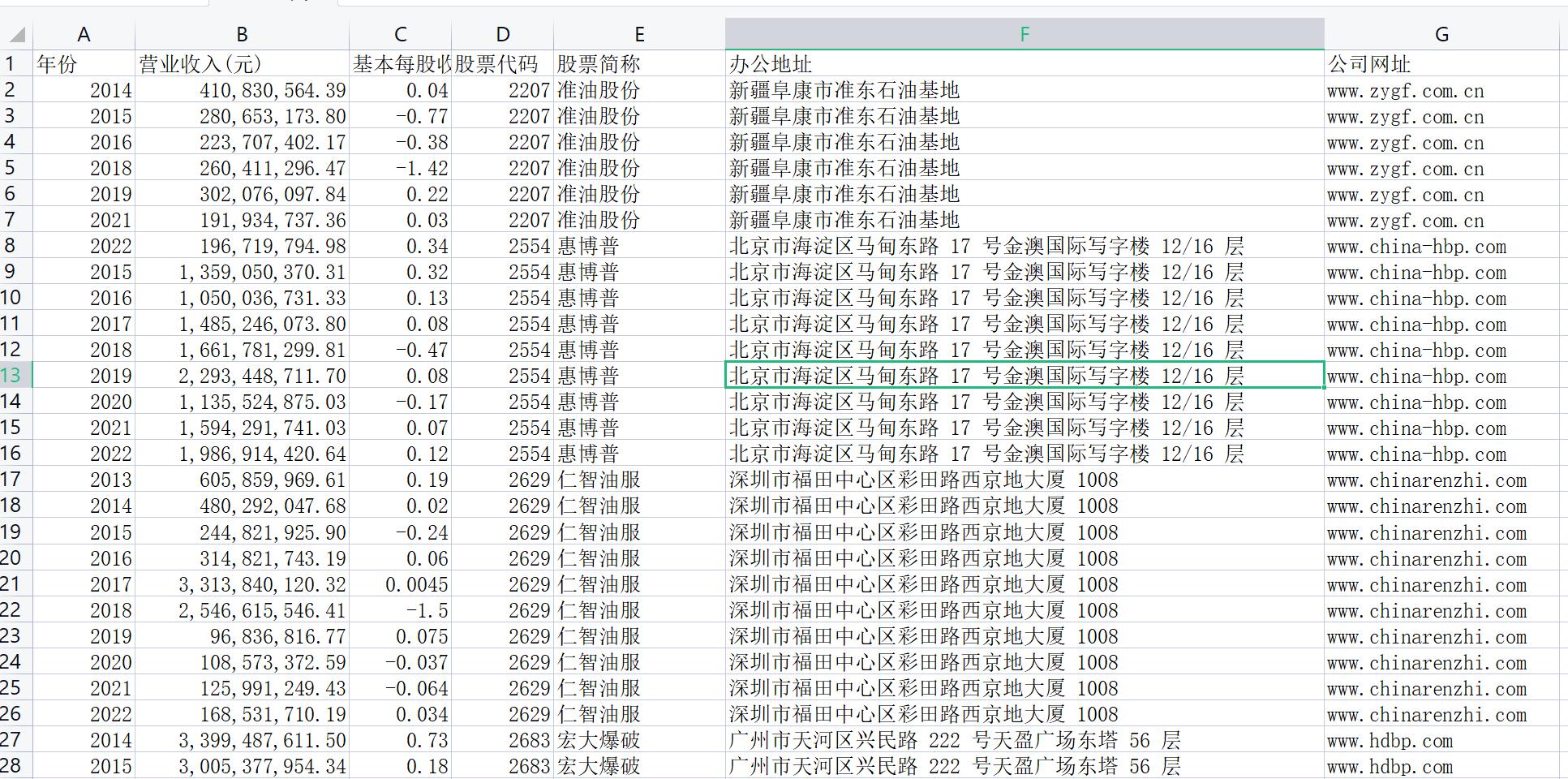
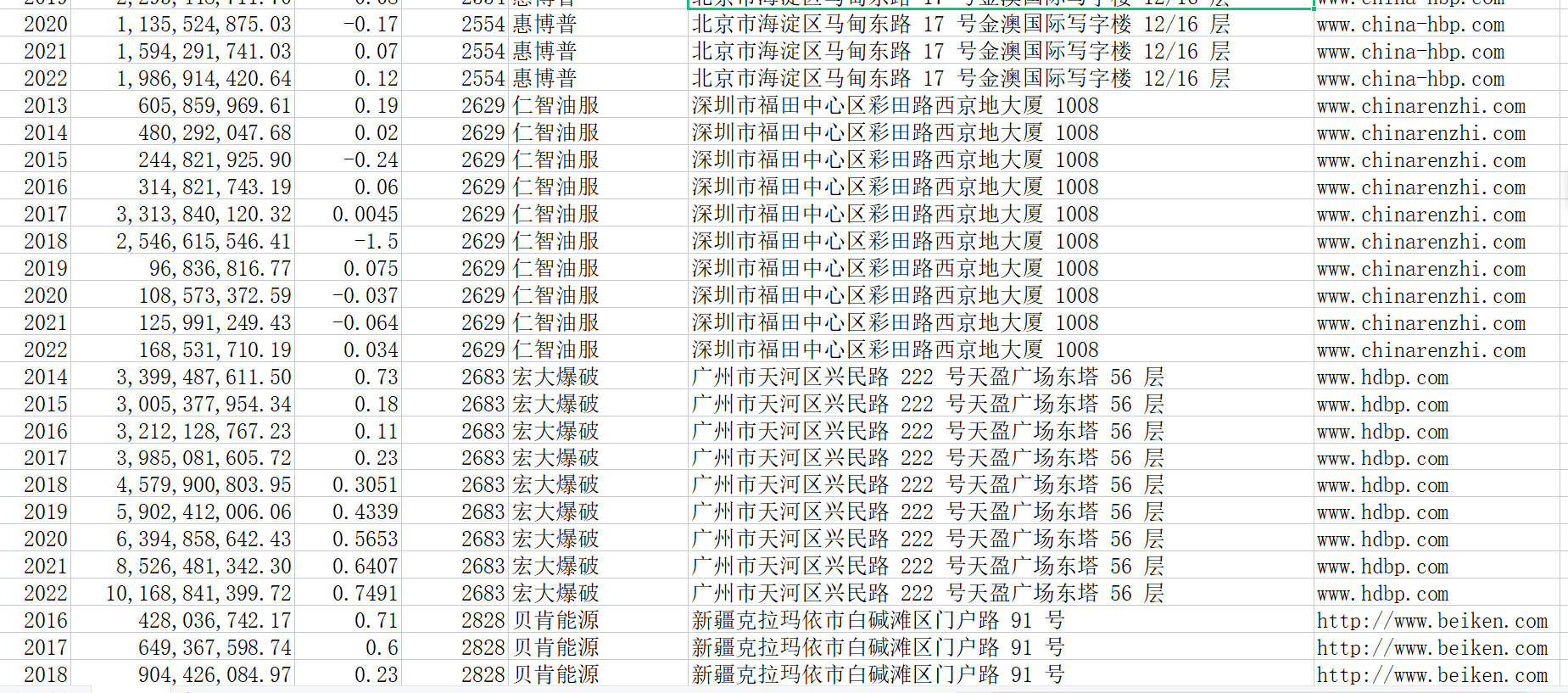


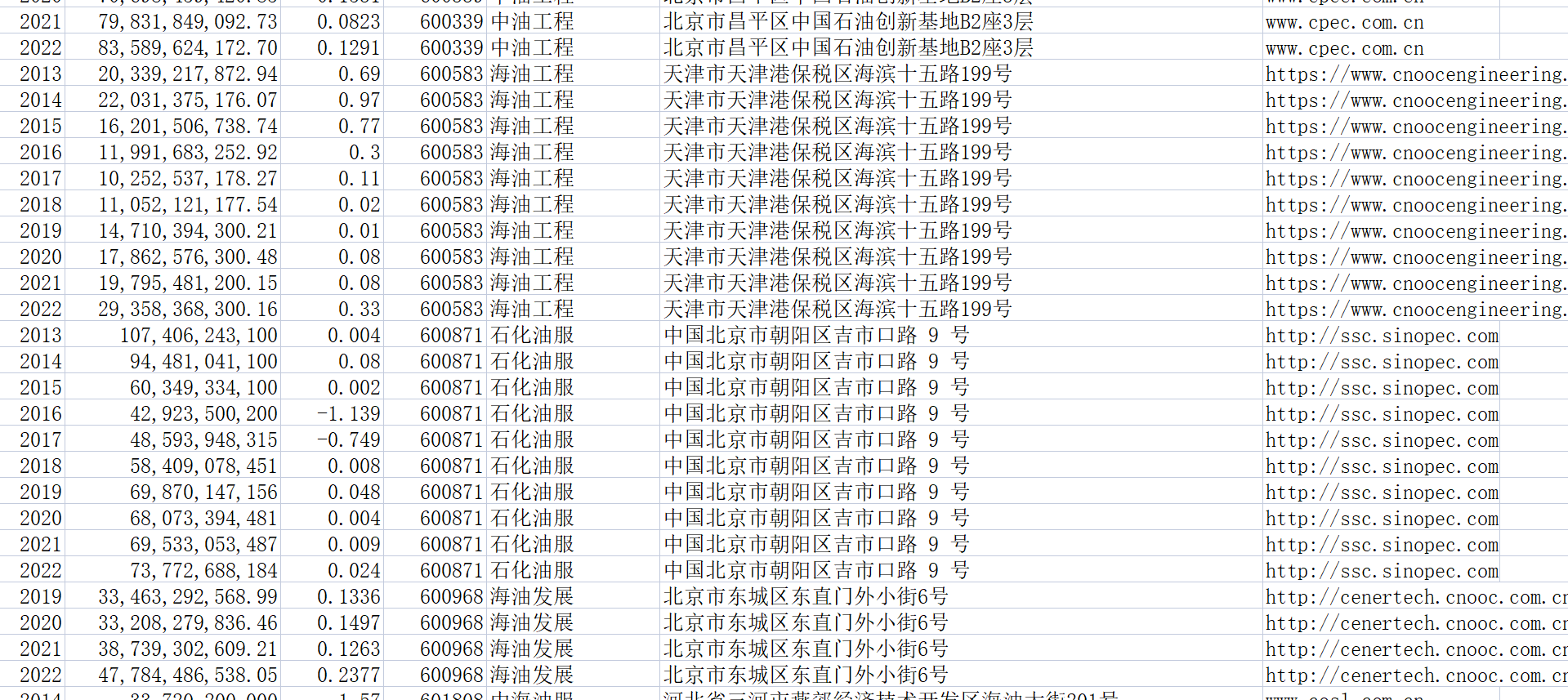
此代码并不会生成文件,因为文件数据比较少。因此用代码来做辅助,然后直接把数据整理至文件“数据.csv”中。
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10)
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
import os
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10.index.tolist())
year = dict(Counter(data['年份']))
year_list = [int(i) for i in year.keys()]
year_list.sort()
print(year_list)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
for name in top_10.index.tolist():
plt.figure(figsize=(13,8)) # 每家公司单独绘制一张图
plt.rcParams['lines.linestyle']='--' # 线条显示形式
temp = data[data['股票简称'] == name] # 获取某家公司的数据
plt.bar(temp['年份'], temp['营业收入(元)'], label="营业收入(元)") # 绘制营业收入柱状图
plt.plot(temp['年份'], temp['基本每股收益(元/股)'], label="基本每股收益(元/股)", marker='o') # 绘制基本每股收益折线图
plt.title(name) # 添加图标题
plt.xlabel('年份') # 添加x轴标签
plt.ylabel('金额(亿)') # 添加y轴标签
ax2 = plt.gca().twinx() # 添加副坐标轴
ax2.set_ylabel('基本每股收益(元/股)') # 设置副坐标轴y轴标签
ax2.set_ylim((temp["基本每股收益(元/股)"].min(), temp["基本每股收益(元/股)"].max())) # 设置副坐标轴y轴范围
plt.yticks(temp["基本每股收益(元/股)"].unique()) # 设置副坐标轴刻度标签
plt.legend(fontsize=12) # 添加图例,并调整字体大小
plt.grid(linestyle='--') # 添加网格线
# 自动保存图片到文件夹中
if not os.path.exists('公司图片'):
os.makedirs('公司图片')
plt.savefig('公司图片/{}.png'.format(name))
plt.show() # 显示图像
import pandas as pd
import matplotlib.pyplot as plt
import os
# 设置字体为SimHei显示中文
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("数据.csv", dtype={"营业收入(元)": float}, thousands=',', na_values=['--'])
# 获取所有公司名称和年份范围
company_names = sorted(set(data['股票简称']))
year_range = range(2013, 2023)
# 绘制营业收入对比折线图
plt.figure(figsize=(12, 8))
plt.title('营业收入对比折线图')
plt.xlabel('年份')
plt.ylabel('营业收入(亿)')
plt.grid(linestyle='--')
for company in company_names:
company_data = data[data['股票简称'] == company]
if len(company_data) == 0:
continue
# 将y轴数据的长度设置为10
y_data = company_data['营业收入(元)'].tolist()
if len(y_data) < 10:
y_data = [None] * (10 - len(y_data)) + y_data
# 绘制折线图
plt.plot(year_range, y_data, label=company)
# 设置x轴刻度标签
plt.xticks(year_range)
# 添加图例
plt.legend(loc='best')
# 自动保存图片到文件夹中
if not os.path.exists('营业收入对比图片'):
os.makedirs('营业收入对比图片')
plt.savefig('营业收入对比图片/营业收入对比折线图.png')
plt.show()
# 绘制基本每股收益对比折线图
plt.figure(figsize=(12, 8))
plt.title('基本每股收益对比折线图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid(linestyle='--')
for company in company_names:
company_data = data[data['股票简称'] == company]
if len(company_data) == 0:
continue
# 将y轴数据的长度设置为10
y_data = company_data['基本每股收益(元/股)'].tolist()
if len(y_data) < 10:
y_data = [None] * (10 - len(y_data)) + y_data
# 绘制折线图
plt.plot(year_range, y_data, label=company)
# 设置x轴刻度标签
plt.xticks(year_range)
# 添加图例
plt.legend(loc='best')
# 自动保存图片到文件夹中
if not os.path.exists('基本每股收益对比图片'):
os.makedirs('基本每股收益对比图片')
plt.savefig('基本每股收益对比图片/基本每股收益对比折线图.png')
plt.show()