1.def req(stock, year, org_dict):
2.# post请求地址(巨潮资讯网的那个查询框实质为该地址)
“以下url,实际上对应的巨潮搜索的个股”
3. url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
4.# 表单数据,需要在浏览器开发者模式中查看具体格式
“表单数据,在query的负载可以查到”
5. data = {
6. "pageNum": "1",
7. "pageSize": "30",
8. "tabName": "fulltext",
9. "stock": stock + "," + org_dict[stock],
# 按照浏览器开发者模式中显示的参数格式构造参数
10. '''每个个股实际上就是在stock和sedate这里不同,
11. 故需要在这里寻找特定的值,而这个特定的值在szse_stock_json里面,
12. 有巨潮给每个个股编的代码但因为这是jason文件,所以后面找这个的时候需要jason解析'''
13. "seDate": f"{str(int(year) + 1)}-01-01~{str(int(year) + 1)}-12-31",
# 这里实际上就是搜索年份,而且要注意11年的年报12年才出这个问题
14. "column": "szse",
15. "category": "category_ndbg_szsh",
16. "isHLtitle": "true",
17. "sortName": "time",
18. "sortType": "desc"
19. }
20. # 请求头
21. headers = {"Content-Length": "201", "Content-Type": "application/x-www-form-urlencoded"}
22. # 发起请求
23. req = requests.post(url, data=data, headers=headers)
24. # 发现返回的是json数据,需要将其文本化后用json.load()读取化成python的字典
25. if json.loads(req.text)["announcements"]:
# 确保json.loads(req.text)["announcements"]非空,是可迭代对象
26. for item in json.loads(req.text)["announcements"]:
# 遍历announcements列表中的数据,目的是排除英文报告和报告摘要,唯一确定年度报告或者更新版
27. if "摘要" not in item["announcementTitle"]:
28. if "英文" not in item["announcementTitle"]:
29. if "修订" not in item["announcementTitle"] and "更新" not in item["announcementTitle"]:
30. if year in item["announcementTitle"] :#or "更新" in item["announcementTitle"]:
31. print('当前年份为',year)
32. print(item)
33. adjunctUrl = item["adjunctUrl"]
# "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
34. pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
35. r = requests.get(pdfurl)
36. f = open("年报" + "/" + stock + "-" + year + "年度报告" + ".pdf", "wb")
37. f.write(r.content)
38. print(f"{stock}-{year}年报下载完成!") # 打印进度
39. break
由于行业内个股有深交所上市、上交所上市,若通过深交所、上交所网站进行爬取,需要进行多次操作
故本文选择信息公开平台“巨潮资讯”爬取公司年报信息
# 进入巨潮资讯网,手动搜索某证券的年报信息
# 通过浏览器F12调出“控制台“页面,寻找“某证券”、“某年份”、“某份报告”对应的请求信息、表单数据等,确定“年报”下载地址的真实请求链接
# 通过查找,可以寻找出年报的真实请求信息存放于“query”中
1. def get_orgid():
2. org_dict = {}
3. org_json = requests.get("http://www.cninfo.com.cn/new/data/szse_stock.json").json()["stockList"]
4.
5. for i in range(len(org_json)):
6. org_dict[org_json[i]["code"]] = org_json[i]["orgId"]
7.
8. return org_dict
1. if __name__ == "__main__": # 程序入口
2. # 读取需要爬取的股票代码
3. pdlist = pd.read_excel(r"F:\许晶作业\stockcode1.xlsx", converters={'stockcode': str})["stockcode"]
4. stock_list = pdlist.to_numpy().tolist()
5.
6. org_dict = get_orgid()
7.
8. for stock in stock_list: # 一层循环,按股票代码循环
9. for year in ["2013", "2014", "2015", "2016", "2017", "2018", "2019", "2020", "2021", '2022']: # 二层按年份循环
10. req(stock, year, org_dict) # 调用req函数
11. time.sleep(random.randint(0, 2)) # 适当休眠,避免爬虫过快
生成的年报的截图
# 为提取“营业收入“、”基本每股收益“、”办公住址“等信息,本文采用pdf文字化并通过观察规律构建正则表达式的方法进行提取
1. pip uninstall fitz
2. pip install PyMuPDF
3. import fitz
4. import re
5. import pandas as pd
6. import os
7. import matplotlib.pyplot as plt
8. import matplotlib
9. import numpy as np
10.
11. def getText(pdf):#定义函数获取文本
12. text = ''
13. doc = fitz.open(pdf)
14. for page in doc:
15. text += page.get_text()
16. doc.close()
17. text = text.replace(" "," \n")
18. text = text.replace("\n\n","\n")
# 由于后续subp匹配过程中,有的数字后面没有换行符,无法成功进行非贪婪的匹配,所以通过文本内部符号替换
19. return(text)
1. path = 'F:\许晶作业\年报' #年报所处路径
2. 全部文件 = os.listdir(r'F:\许晶作业\年报')
3. #j=0 #用来控制for
4. 董秘信息 = pd.DataFrame()
5. 营业收入 = pd.DataFrame()
6. 收益 = pd.DataFrame()
7. 地址 = pd.DataFrame()
8. 网址 = pd.DataFrame()
9. 邮箱 = pd.DataFrame()
10. for 年报 in range(len(全部文件)):
11. #j = j+1
12. # if j >5:
13. # break
14. 路径 = os.path.join(r'F:\许晶作业\年报',全部文件[年报])
15. text = getText(路径)
# 匹配出董秘信息
17.try:
18. p_site = re.compile('(?<=\n)\w*董事会秘书?\s?\n证券事务代表\s\n姓名?\s?\n?(.*?)\s?(?=\n)', re.DOTALL) # 匹配出董事会秘书姓名
19. site1 = p_site.search(text).group(0)
20. p_site2 = re.compile(
21. '(?<=\n)\w*董事会秘书?\s?\n证券事务代表\s\n姓名?\s?\n?(.*?)\s?(?=电话)\s?\电话?\s\n?(.*?)(?=\n)', re.DOTALL)
22. site2 = p_site2.search(text).group(0)
23. len(site2)
24. 董秘姓名 = site1[19:]
25. 董秘电话 = site2[-13:]
26. # print(pd.DataFrame(data = [董秘姓名,董秘电话],index = ['董秘姓名','董秘电话'],columns = [年报[7:11]]))
27. df = (pd.DataFrame(data = [董秘姓名,董秘电话],index = ['{年报}董秘姓名'.format(年报=全部文件[年报][:6]),'{年报}董秘电话'.format(年报=全部文件[年报][:6])],columns = [全部文件[年报][7:11]]))
28. 董秘信息 = pd.concat([董秘信息,df],axis=1)
29. #print(董秘信息)
if 年报 != len(全部文件)-1:
31. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
32. 董秘信息.to_excel(r'F:\许晶作业\董秘信息汇总\{年报}董秘信息.xlsx'.format(年报=全部文件[年报][:6])) #d
33. 董秘信息 = pd.DataFrame()
34. else:
35. 董秘信息.to_excel(r'F:\许晶作业\董秘信息汇总\{年报}董秘信息.xlsx'.format(年报=全部文件[年报][:6])) # d
36. 董秘信息 = pd.DataFrame()
37.except:
38. print(全部文件[年报],'董秘信息出错了')
39. pass
# 匹配出营业收入
41. try:
42. # p_site = re.compile('(?<=\n)\w*营业收入?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
43. # site1 = p_site.search(text).group(0)
44. # 收入 = site1[5:]
45. #text = getText(r'F:\许晶作业\年报\601225-2014年度报告.pdf')
46. p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)净利润', re.DOTALL)
47. txt = p_s.search(text).group(0)
48. p_site = re.compile('(?<=\n)\w*营业收入?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
49. site1 = p_site.search(txt).group(0)
50. 收入 = site1[6:]
51. a = re.findall(r"\d+\.?\d*", site1)
52. 收入 = ''.join(a)
53. 收入 = 收入.replace(',','')
54. 收入 = pd.to_numeric(收入)
55. if '单位:亿元' in txt:
56. 收入 = 收入 * 1000000
57. elif '单位:万元' in txt:
58. 收入 = 收入 * 10000
59. elif '单位:百万元' in txt:
60. 收入 = 收入 * 1000000
61. elif '单位:千元' in txt:
62. 收入 = 收入 * 1000
63. df = pd.DataFrame(data = [收入],index = ['{年报}收入'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
64. #print(df)
65. 营业收入 = pd.concat([营业收入,df],axis=1)
66. #print(营业收入)
67. if 年报 != len(全部文件)-1:
68. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
营业收入.to_excel(r'F:\许晶作业\营业收入汇总\{年报}营业收入.xlsx'.format(年报=全部文件[年报][:6])) #d
70. 营业收入 = pd.DataFrame()
71. else:
72. 营业收入.to_excel(r'F:\许晶作业\营业收入汇总\{年报}营业收入.xlsx'.format(年报=全部文件[年报][:6])) # d
73. 营业收入 = pd.DataFrame()
74.except:
75. print(全部文件[年报], '营业收入出错了')
76. 营业收入 = pd.DataFrame()
77. pass
# 匹配出办公地址
79.try:
80. p_site = re.compile('(?<=\n)\w*办公地址?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
81. site1 = p_site.search(text).group(0)
82. 办公地址 = site1[8:]
83. df = pd.DataFrame(data = [办公地址],index = ['{年报}办公地址'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
84. # print(df)
85. 地址 = pd.concat([地址,df],axis=1)
86. #print(地址)
87. if 年报 != len(全部文件)-1:
88. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
89. 地址.to_excel(r'F:\许晶作业\办公地址汇总\{年报}办公地址.xlsx'.format(年报=全部文件[年报][:6])) #d
90. 地址 = pd.DataFrame()
91. else:
92. 地址.to_excel(r'F:\许晶作业\办公地址汇总\{年报}办公地址.xlsx'.format(年报=全部文件[年报][:6])) # d
93. 地址 = pd.DataFrame()
94.except:
95. print(全部文件[年报], '办公地址出错了')
96. pass
运行结果
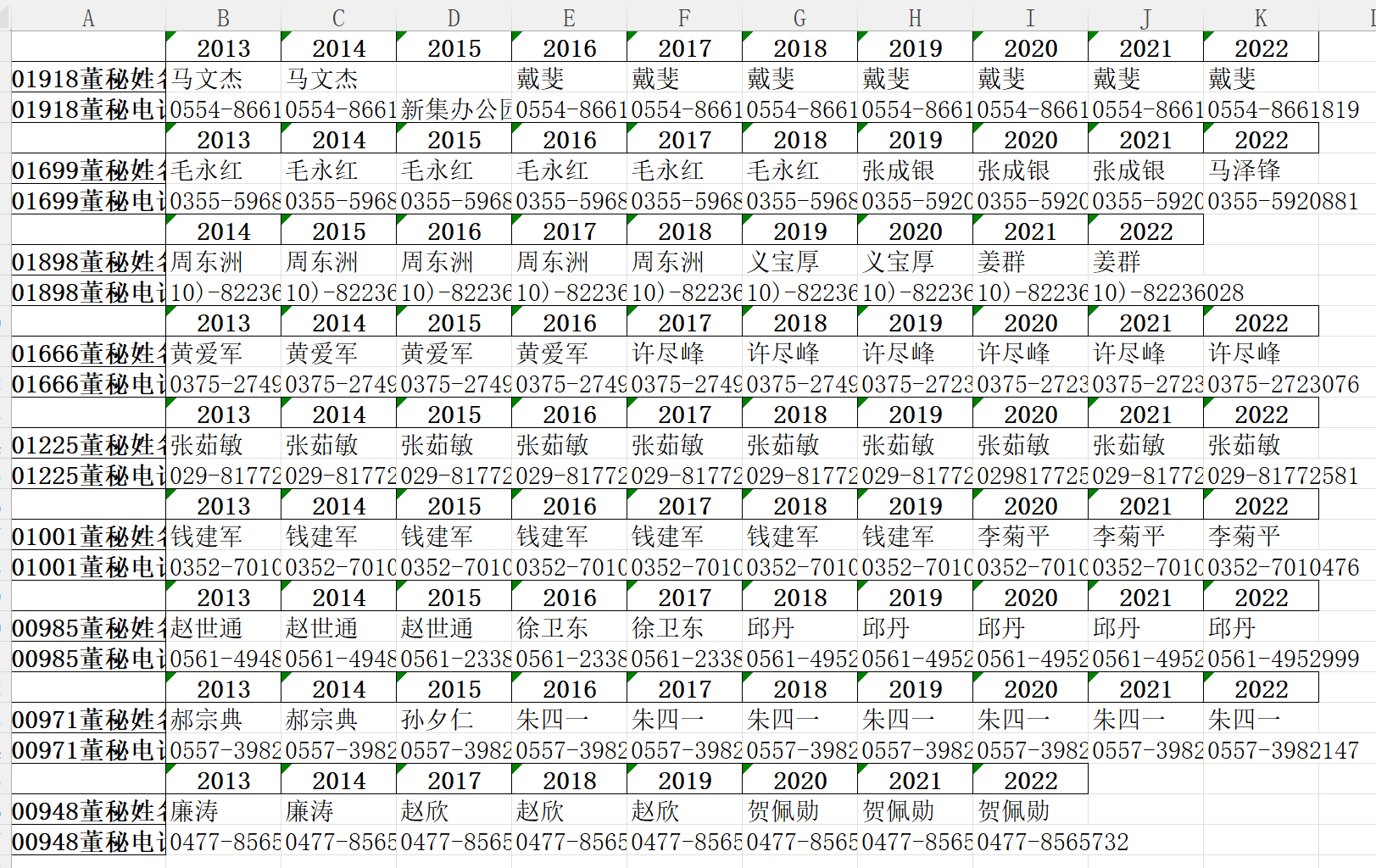
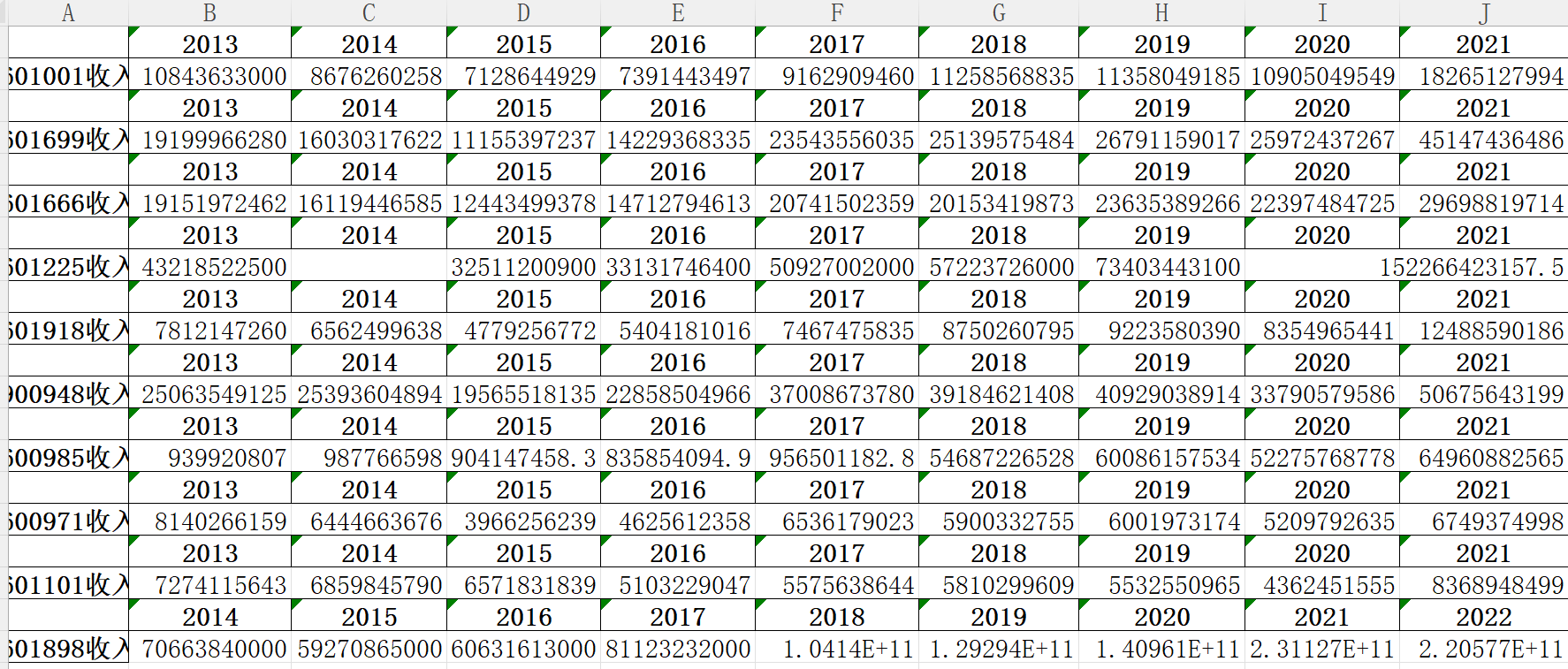
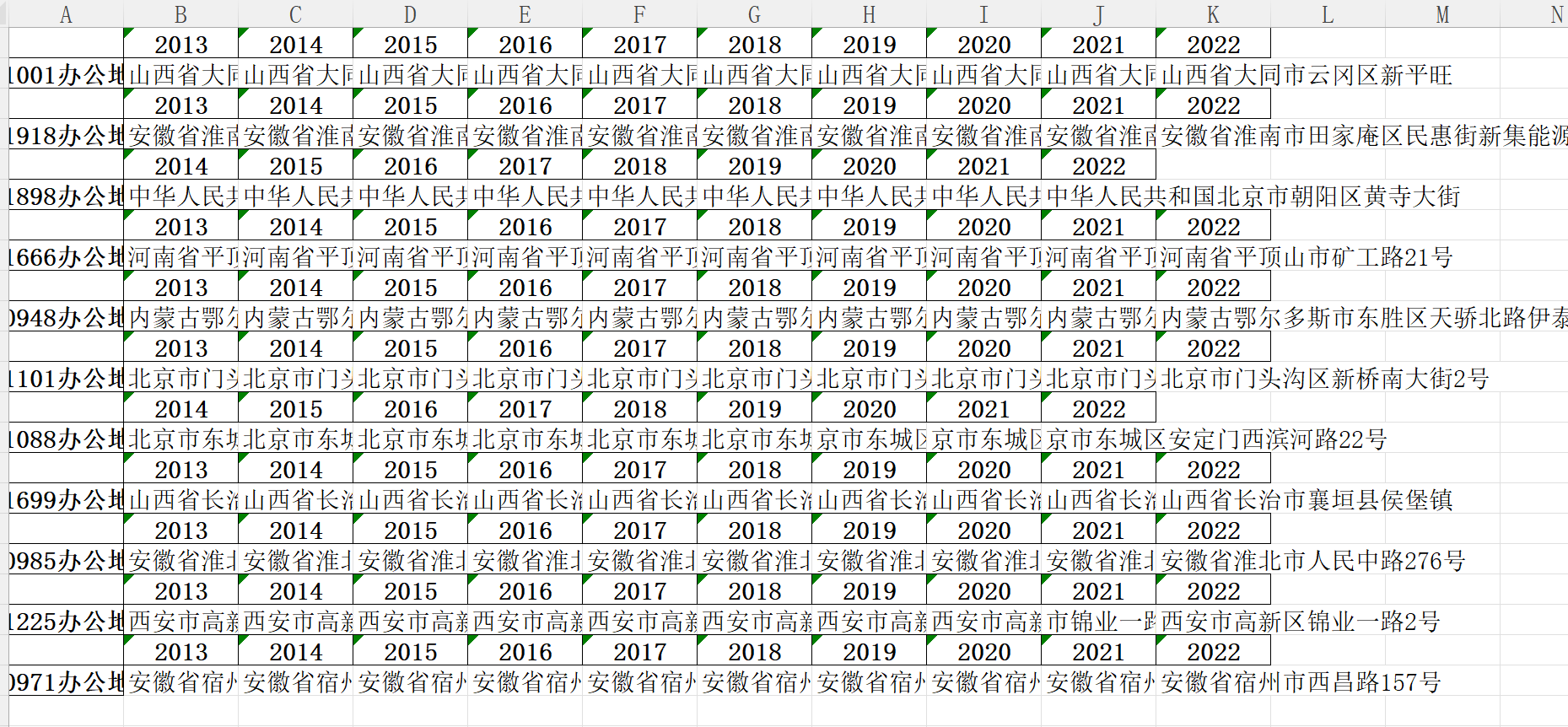
# 匹配出电子邮箱
98.try:
99. p_site = re.compile('(?<=\n)\w*电子信箱?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
100. site1 = p_site.search(text).group(0)
101. 电子信箱 = site1[6:]
102. df = pd.DataFrame(data = [电子信箱],index = ['{年报}邮箱'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
103. # print(df)
104. 邮箱 = pd.concat([邮箱,df],axis=1)
# print(邮箱)
106. if 年报 != len(全部文件)-1:
107. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
108. 邮箱.to_excel(r'F:\许晶作业\邮箱汇总\{年报}邮箱.xlsx'.format(年报=全部文件[年报][:6])) #d
109. 邮箱 = pd.DataFrame()
110. else:
111. 邮箱.to_excel(r'F:\许晶作业\邮箱汇总\{年报}邮箱.xlsx'.format(年报=全部文件[年报][:6])) # d
112. 邮箱 = pd.DataFrame()
113.except:
114. print(全部文件[年报], '邮箱出错了')
115. pass
116 # 匹配出公司网址
117.try:
118. p_site = re.compile('(?<=\n)\w*公司?网址\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
119. p_site = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
120. site1 = p_site.search(text).group(0)
121. 公司网址 = site1[6:]
122. df = pd.DataFrame(data = [公司网址],index = ['{年报}网址'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
123. # print(df)
124. 网址 = pd.concat([网址,df],axis=1)
125. #print(网址)
126. if 年报 != len(全部文件)-1:
127. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
128. 网址.to_excel(r'F:\许晶作业\网址汇总\{年报}网址.xlsx'.format(年报=全部文件[年报][:6])) #d
129. 网址 = pd.DataFrame()
130. else:
131. 网址.to_excel(r'F:\许晶作业\网址汇总\{年报}网址.xlsx'.format(年报=全部文件[年报][:6])) # d
132. 网址 = pd.DataFrame()
133.except:
134. print(全部文件[年报], '网址出错了')
135. pass
136. # 匹配出每股收益
137.try:
138. # text = getText(r'F:\许晶作业\年报\601088-2020年度报告.pdf')
139. p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)收益率', re.DOTALL)
140. txt = p_s.search(text).group(0)
141. p_site = re.compile('(?<=\n)\w*基本每股(.*?)亏?损?\s?\n?(.*?)\s?(?=\n)\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
142. site1 = p_site.search(txt).group(0)
143. if site1[:11] == '基本每股收益(元/股)' or site1[:11] == '基本每股收益(元/股)' or site1[:11] == '基本每股收益(元/股)':
144. 每股收益 = site1[13:]
145. else:
146. 每股收益 = site1[16:]
147.
148. df = pd.DataFrame(data = [每股收益],index = ['{年报}每股收益'.format(年报 = 全部文件[年报][:6])],columns = [全部文件[年报][7:11]])
149. #print(df)
150. 收益 = pd.concat([收益,df],axis=1)
151. #print(收益)
152. if 年报 != len(全部文件)-1:
153. if 全部文件[年报][:6] != 全部文件[年报+1][:6]:
154. 收益.to_excel(r'F:\许晶作业\收益汇总\{年报}收益.xlsx'.format(年报=全部文件[年报][:6])) #d
155. 收益 = pd.DataFrame()
156. else:
157. 收益.to_excel(r'F:\许晶作业\收益汇总\{年报}收益.xlsx'.format(年报=全部文件[年报][:6])) # d
158. 收益 = pd.DataFrame()
159.except:
160. print(全部文件[年报], '每股收益出错了')
161. 收益 = pd.DataFrame()
162. pass
运行结果
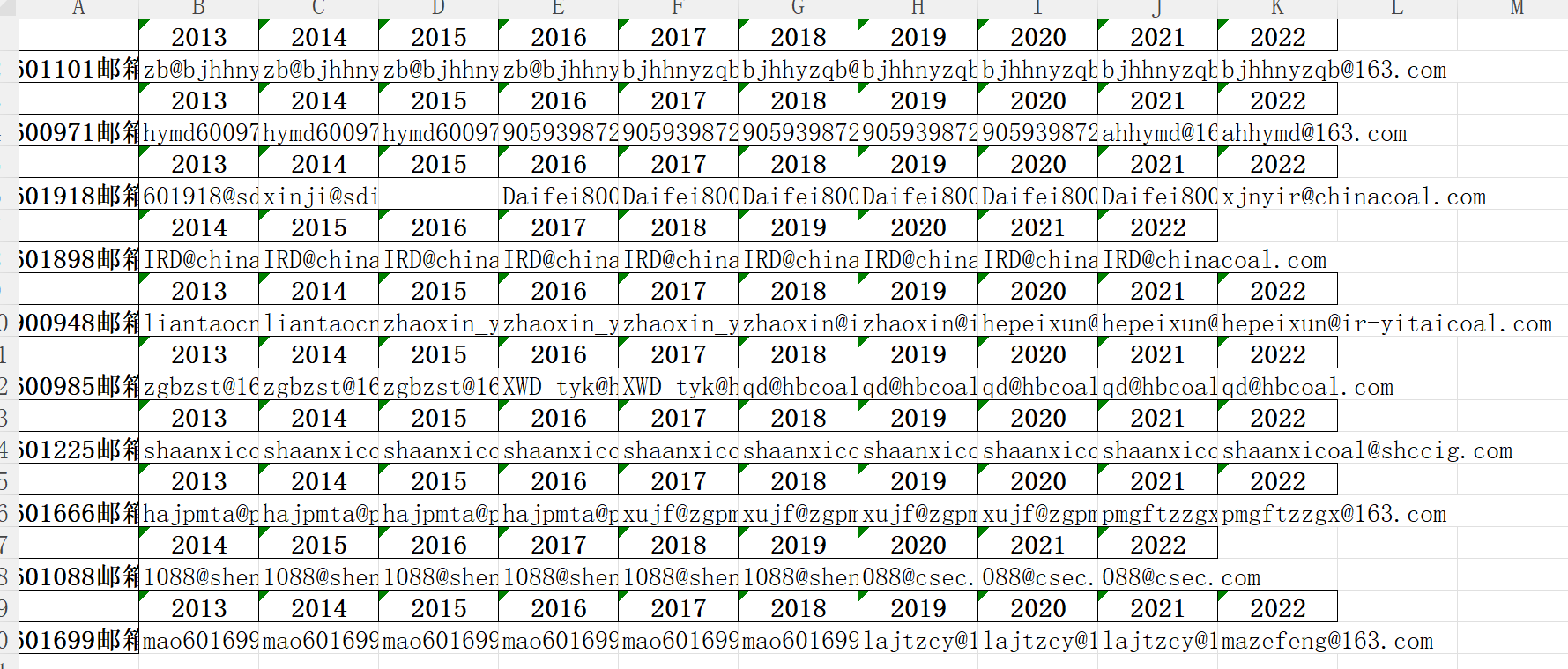

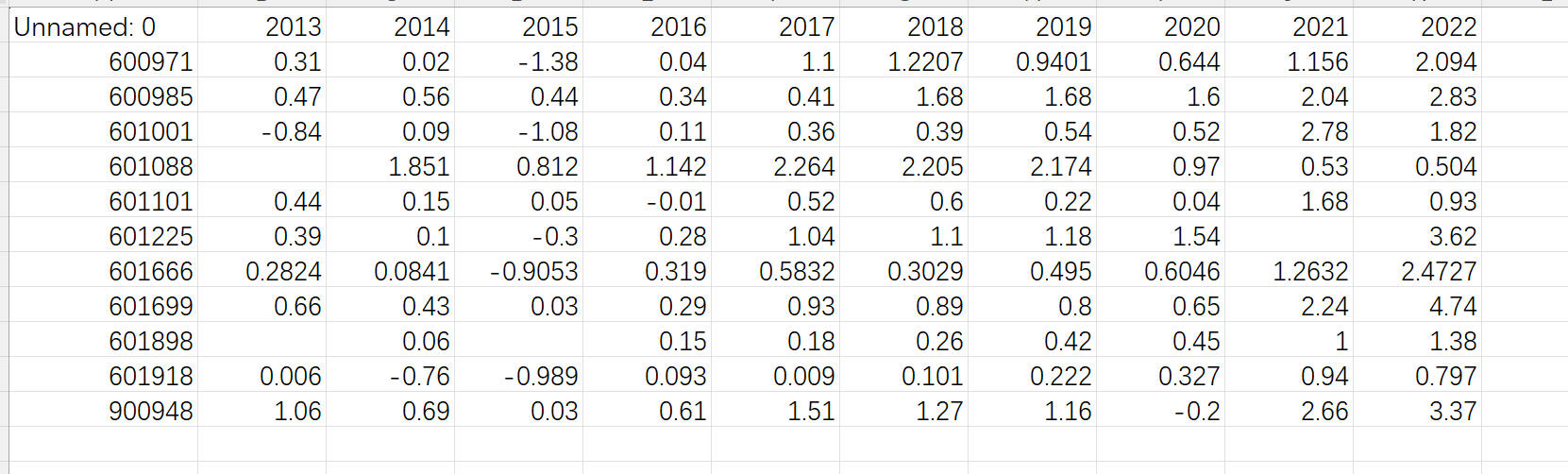
1. #合并所有的每股收益和所有的营业收入
2. 全部文件 = os.listdir(r'F:\许晶作业\营业收入汇总')
3. 营业收入汇总 = pd.DataFrame()
4. for i in 全部文件:
5. path = os.path.join(r'F:\许晶作业\营业收入汇总',i)
6. a = pd.read_excel(path)
7. #a = a.set_index('index')
8. 营业收入汇总 = pd.concat([营业收入汇总,a],axis =0)
9. print(营业收入汇总.T)
10. 营业收入汇总.to_csv(r'F:\许晶作业\营业收入汇总.csv',index = False)
11.
12. 全部文件 = os.listdir(r'F:\许晶作业\收益汇总')
13. 每股收益汇总 = pd.DataFrame()
14. for i in 全部文件:
15. path = os.path.join(r'F:\许晶作业\收益汇总',i)
16. a = pd.read_excel(path)
17. #a = a.set_index('index')
18. 每股收益汇总 = pd.concat([每股收益汇总,a],axis =0)
19. print(每股收益汇总.T)
20. 每股收益汇总.to_csv(r'F:\许晶作业\每股收益汇总.csv',index = False)
21.
22.
23. #开始绘图
24. import matplotlib.pyplot as plt
25. plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
26. plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
27.
28. import seaborn as sns
29.
30. #选择一家公司进行十年的收入绘图
31. 营业收入汇总 = pd.read_csv(r'F:\许晶作业\营业收入汇总.csv')
32. 营业收入汇总 = 营业收入汇总.rename(columns = {'Unnamed: 0':'代码'})
33. 营业收入汇总 = 营业收入汇总.set_index('代码')
34.
35.
36. 绘图数据 = 营业收入汇总.iloc[0,:]
37. 绘图数据 = 绘图数据.str.replace(',','')
38. 绘图数据 = pd.to_numeric(绘图数据)
39. plt.plot(绘图数据)
40. plt.xlabel('年份',size = 20)
41. plt.ylabel('营业收入',size = 20)
42. plt.title(营业收入汇总.index[0],size = 26)
43. plt.show(block = True)
44.
45. 每股收益汇总 = pd.read_csv(r'F:\许晶作业\每股收益汇总.csv')
46. 每股收益汇总 = 每股收益汇总.rename(columns = {'Unnamed: 0':'代码'})
47. 每股收益汇总 = 每股收益汇总.set_index('代码')
48.
49.
50. 绘图数据1 = 每股收益汇总.iloc[0,:]
51. plt.plot(绘图数据1)
52. plt.xlabel('年份',size = 20)
53. plt.ylabel('每股收益',size = 20)
54. plt.title(每股收益汇总.index[0],size = 26)
55. plt.show(block = True)
56.
57.
最终提取的信息截图
公司1的营业收入:
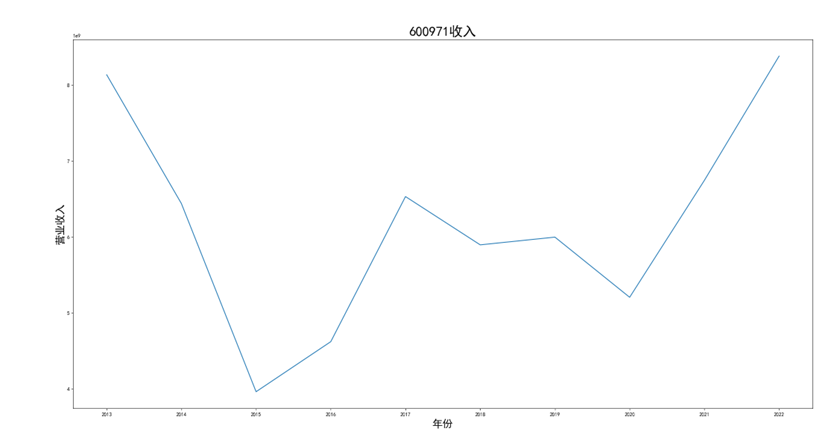
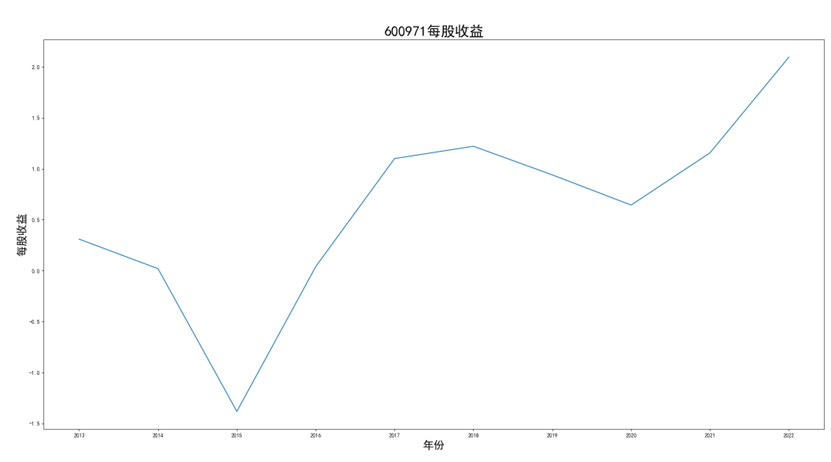
公司1的每股收益:
57. #按年度绘制对比图
58. 营业收入汇总 = pd.read_csv(r'F:\许晶作业\营业收入汇总.csv')
59. 营业收入汇总 = 营业收入汇总.rename(columns = {'Unnamed: 0':'代码'})
60. 营业收入汇总 = 营业收入汇总.set_index('代码')
61. 营业收入汇总 = 营业收入汇总.fillna(0.00)
62. #j = 0
63. for i in range(len(营业收入汇总.columns)):
64. # j = j+1
65. # if j >1:
66. # break
67. 绘图数据 = 营业收入汇总.iloc[:, i]
68. 绘图数据 = 绘图数据.str.replace(',', '')
69. 绘图数据 = 绘图数据.str.replace(' ', '0')
70. 绘图数据 = 绘图数据.fillna(0)
71. 绘图数据 = pd.to_numeric(绘图数据)
72. 绘图数据 = 绘图数据.reset_index()
73. sns.barplot(x='代码' , y=营业收入汇总.columns[i],data = 绘图数据)
74. plt.ylabel('收入',size = 15)
75. plt.xlabel('公司', size=15)
76. plt.title(str(营业收入汇总.columns[i]) + '收入对比',size = 20)
77. plt.show(block = True)
各年度10家公司营业收入对比图(由于存在不同大部分样式的年报,故出现数据提取失败,这里将爬取数据失败的公司的数据填充为0)
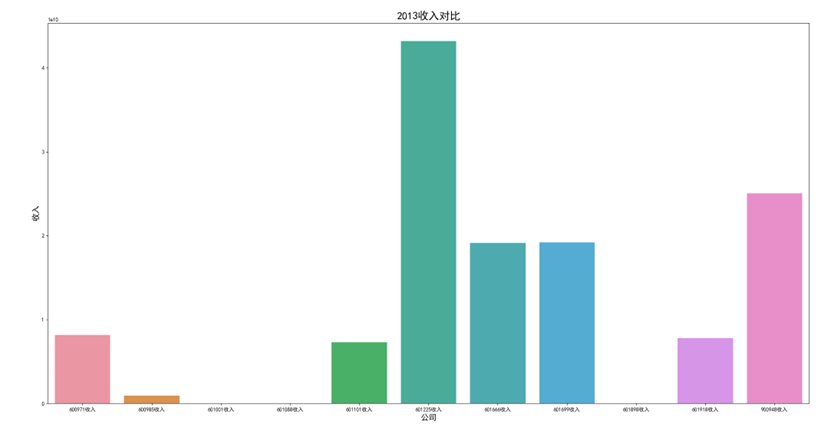
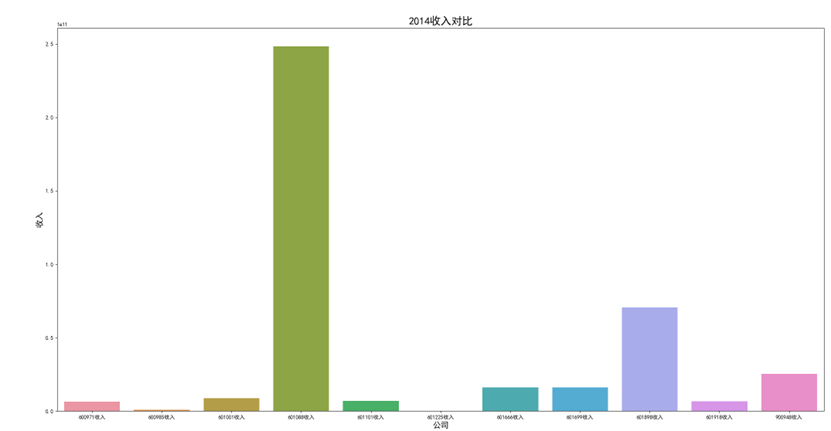
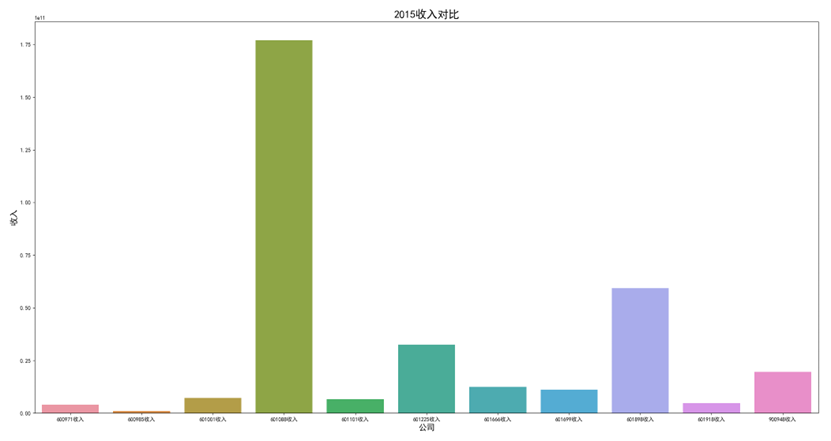
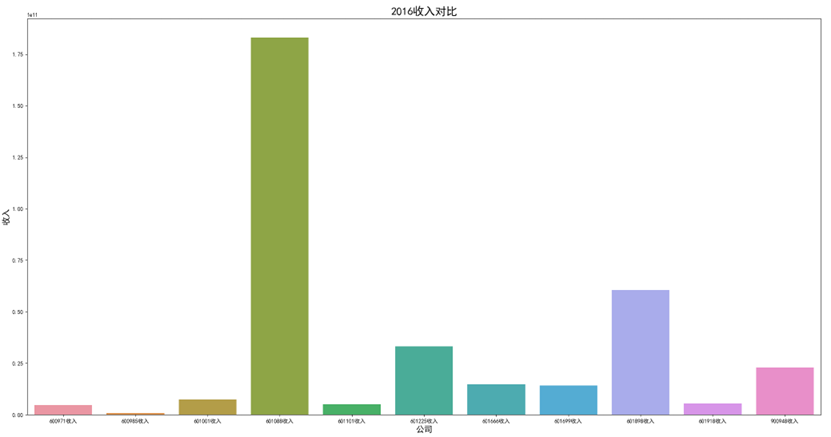
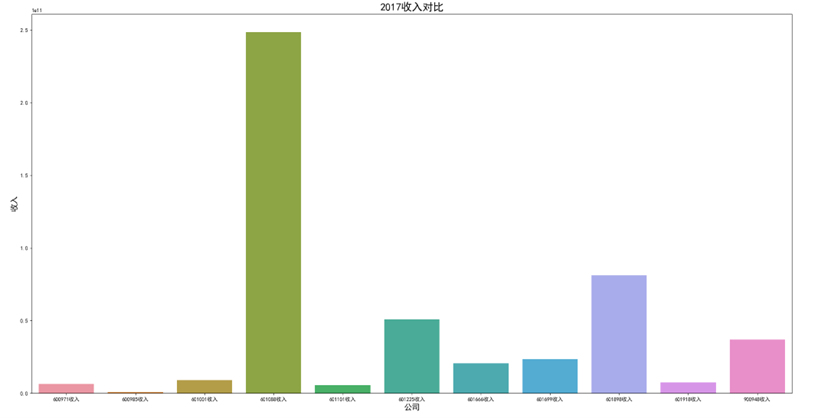
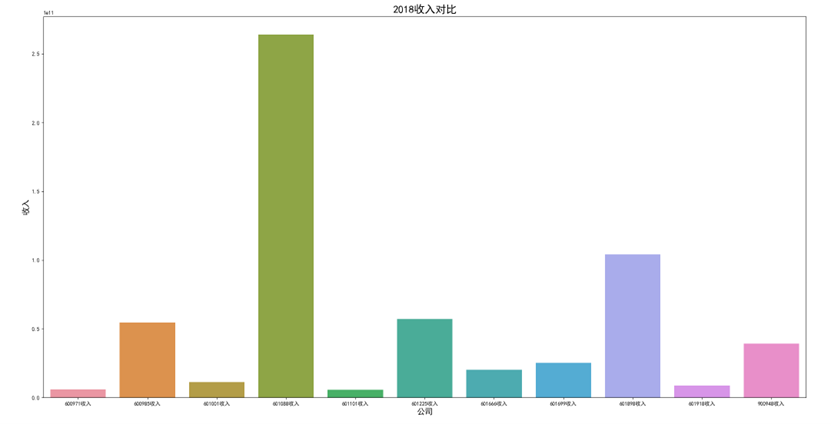
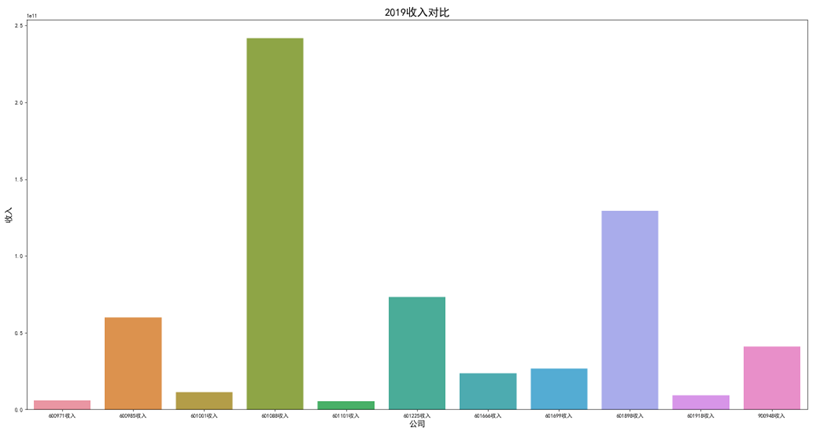
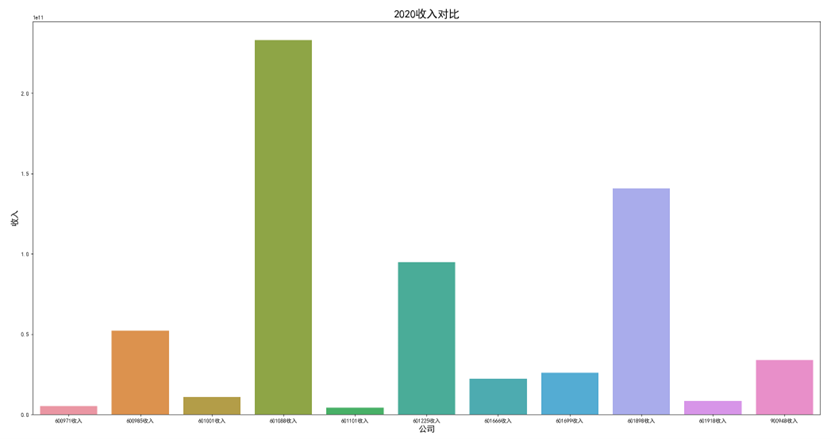
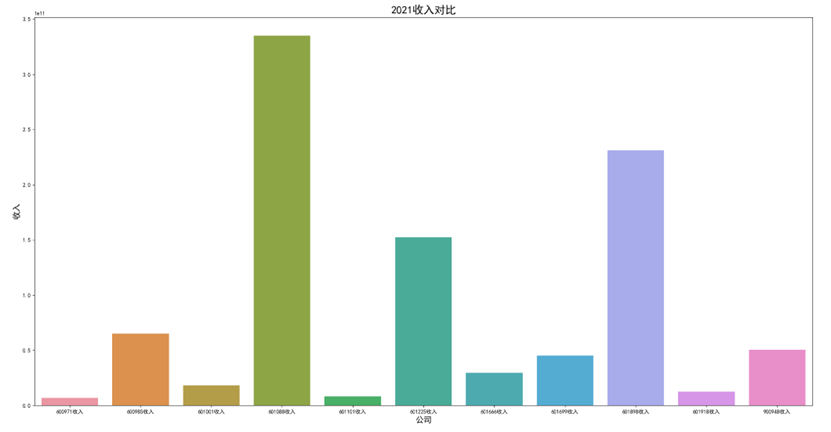
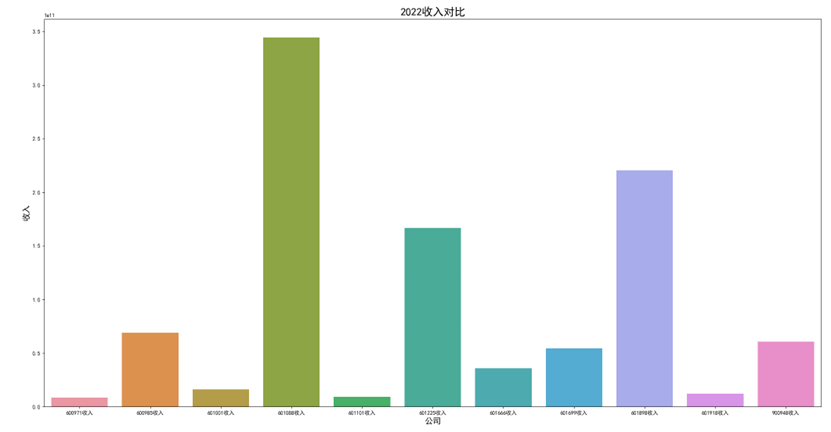
可以看出,600971恒源煤电公司采取的股利分配数额随当年收入数额变动而变动,并具有正相关关系。 这种股利分配政策充满弹性,公司可以依照当年度自身的经营情况进行分红,不会有过大的股利分配压力。 然而,这种股利分配政策也伴随一定的风险,当股利分配减少,投资者自然知晓公司近来的经营状况不佳,从而降低信心,减少持股,导致股价出现波动。 恒源煤电公司的营业收入大体呈现先减后增的形势也符合行业大体走势,回顾历史,我们可以发现: 2013 年 -2015 年,持续了约 23 个月。申万行业指数煤炭开采市盈率不断上扬。 这时期的特征是经济增速缓慢下滑,工业产出增速缓慢下滑,CPI 物价 指数缓慢下跌,煤价整体持续下跌,煤炭上市公司业绩下滑严重。 2015 年-2017年,这时期的特征是经济增速先跌后升,工业产出增速先跌后升,CPI 物价 指数低位徘徊,触底而后回升,煤炭上市公司业绩回暖。 2017年到2020年,我国开始走能源转型,需求量相对来说减少,这也影响了营业收入。 2020年以后,煤炭价格回暖,重新迎来一波新的发展机遇,公司营业收入也随之增长。
可以看出,在过去数年来,行业内各公司的排位情况大体不变,出现最大变化的为600985雷鸣科化于2018年收入呈数倍增长。 从整体而言,煤炭行业作为老牌传统行业,竞争格局数年来并没有发生太大的变化;行业向高集中度、高质量方向发展,重心向晋陕蒙三地集中。 在新能源兴起,中国能源结构改变的冲击情况下,能否对煤炭工艺做出改进、降低成本、提高产量,或许会成为各公司能否继续立足的关键之处。
本次大作业,让我深刻的理解了课上所学的正则表达式。在正则表达式的构建中,我们需要观察、发现并利用规律。 利用正则表达式去最大程度保证准确率地去提取信息,这是大作业中最为困难的地方。 本次作业,涉及“爬取年报、正则表达式搜索信息、绘图“等,让我收益颇丰,尽管付出了努力,但由于个人知识有限,学艺不精,仍有部分问题没有得到解决,希望自己之后能够再深入的去解决这些问题。