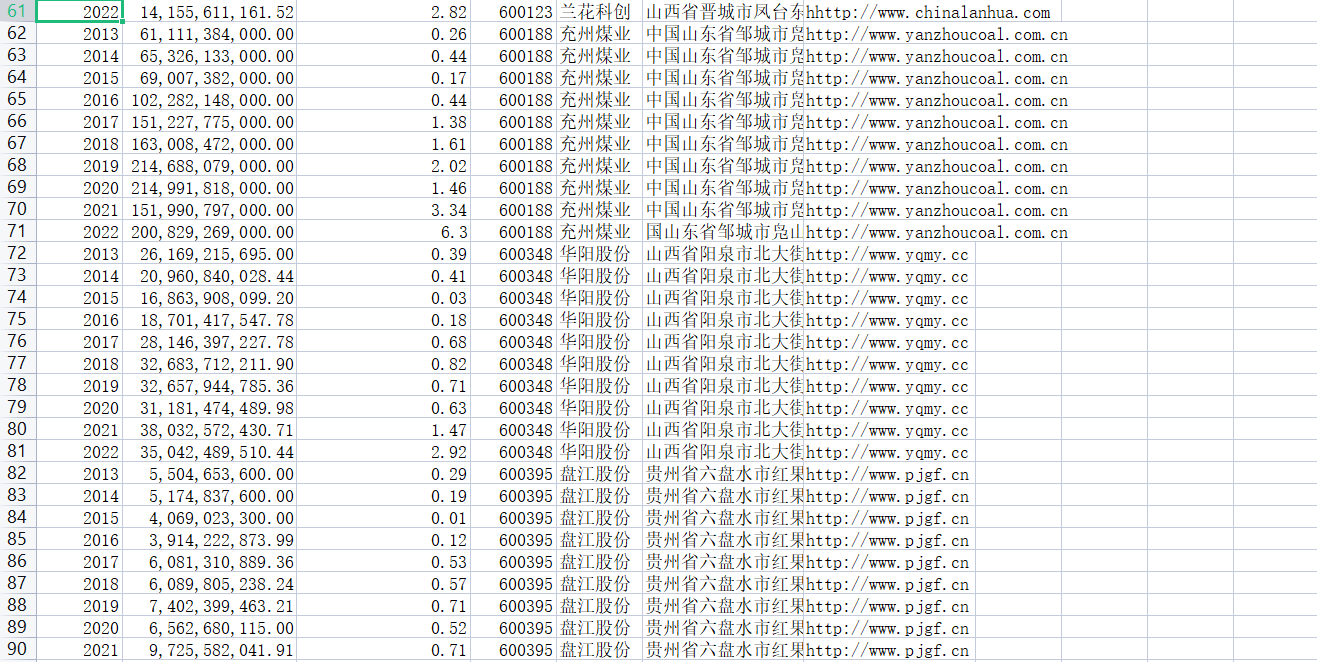
根据营业收入随时间变化的趋势图(2013-2022),目前煤炭开采和洗选业的第一梯队公司当属中国神华、兖州煤业、中煤能源和陕西煤业。
(1)中国神华能源股份有限公司(以下简称中国神华)成立于2004年11月8日,作为国家能源投资集团有限责任公司旗下的A+H股上市公司,是目前国内第一大煤炭上市公司。中国神华是全球领先的以煤炭为基础的综合能源上市公司,主要经营煤炭、电力等六大板块业务。 在2013-2022年这10年间,中国神华的营业收入虽然起起伏伏,但一直处于营业收入第一的位置,公司规模最大。而中国神华2014-2015年营业收入的下降主要与当时的煤炭价格整体下降有关,从图中我们也可以看到2014-2015两年不仅是中国神华,营业收入前10的十家上市公司营业收入基本都出现了不同程度的下降。从2016年开始,煤炭价格开始快速回升,中国神华的业绩也从2016年开始快速向上,基本回到了2013年的水平。而2019年中国神华营业收入出现小幅度下滑,报告提到,主要原因包括中国神华在组建合资公司交易中投出标的资产的售电量及收入自2019年2月1日起不再纳入合并报表范围。
2021年,中国神华的营业收入为3352.16亿元人民币,同比增长43.7%。主要有以下四个原因: ①煤炭市场需求旺盛,煤炭价格上涨,集团煤炭销售量和平均销售价格同比分别增长8.0%和43.4%。 ②国内用电需求增长,集团积极发挥一体化运营优势保障电厂燃煤供应,以及2021年以来多台新机组陆续投产,集团售电量同比增长22.3%。 ③集团整合航运资源,提升航运业务的规模化和集约化,确保能源保供有力有效,航运货运量同比增长7.3%,以及海运价格上涨。 ④受国际油价等因素影响,聚乙烯和聚丙烯销售价格同比分别上涨21.7%和13.9%。
(2)兖州煤业是以煤炭生产经营为基础,煤炭深加工和综合利用一体化的国际化大型能源企业,是华东地区最大煤炭生产商,国内动力煤龙头企业,所属兖煤澳洲公司是澳大利亚最大专营煤炭生产商。 在2015-2020年间,兖州煤业的营业收入总体上呈现逐年增长的趋势,稳坐行业第二,但由于2021年其营业收入出现大幅下降,被中煤能源赶超。据2021年年报显示,主要是由于受安全环保政策影响,报告期内商品煤产量同比减少,进而导致煤炭销售量减少。
(3)中国中煤能源股份有限公司(简称“中煤能源”)是中国中煤能源集团有限公司于2006年8月22日独家发起设立的股份制公司,总部设在北京,是超大型煤炭央企上市公司。中煤能源以煤炭、煤化工、电力和煤矿装备为核心业务,其煤炭主业规模居于全国前列,优质产能占比、煤炭资源储备、煤炭开采、洗选和混配技术行业领先,煤矿规模化、低成本竞争优势突出。 中煤能源自2016年起,营业收入总体呈现稳定增长的趋势,其中2021年其营业收入较上年同期增长64%,创历史新高,主要是由于公司商品煤产量和市场煤价齐升所致。
(4)陕西煤业化工集团有限责任公司(以下简称“陕西煤业”)是陕西省省属特大型能源化工企业。公司主要从事煤炭开采、洗选、运输、销售以及生产服务等业务,煤炭产品主要用于电力、化工及冶金等行业。据营业收入随时间变化的趋势图(2013-2022)可知,陕西煤业自2016年起,营业收入呈现逐年增长的趋势,总体规模稳步扩大。2021年由于我国煤炭行业需求超预期增长,国内煤炭市场整体供应偏紧,价格大幅波动。2021年陕西煤业实现营业收入1523亿元,同比增长60.17%。
煤炭开采和洗选业的第二梯队由淮北矿业、伊泰B股、山西焦煤和潞安环能构成。这四家公司都是近年营业收入在五百亿左右的四家上市公司。淮北矿业公司主要业务为煤炭采掘、洗选加工、销售,煤化工产品的生产、销售等业务。伊泰B股则是以煤炭生产、运输、销售为基础,集铁路与煤化工为一体的大型清洁能源企业。山西焦煤的主营业务是煤炭的生产、洗选加工、销售及发供电,矿山开发设计施工、矿用及电力器材生产经营等。潞安环能主营生产销售煤炭、焦炭产品。这四家上市公司的营业收入稳定上升,收入一般没有较大降幅。
第三梯队的公司有华阳股份和冀中能源。到了第三梯队,公司的总营收基本处于四百亿以下,都是2013年以前就已经上市的公司,但是近十年发展速度缓慢。
根据行业内营业收入横向对比图,我们可以更加直观地看到中国神华的营业收入始终处于行业领先地位,大体量领先其他的公司。而后兖州煤业和中煤能源奋起直追,直到中煤能源超越兖州煤业成为行业第二,但是二者实力不相上下,而陕西煤业自2016年起始终保持稳定增长态势,未来行业第二是谁还有待观察。
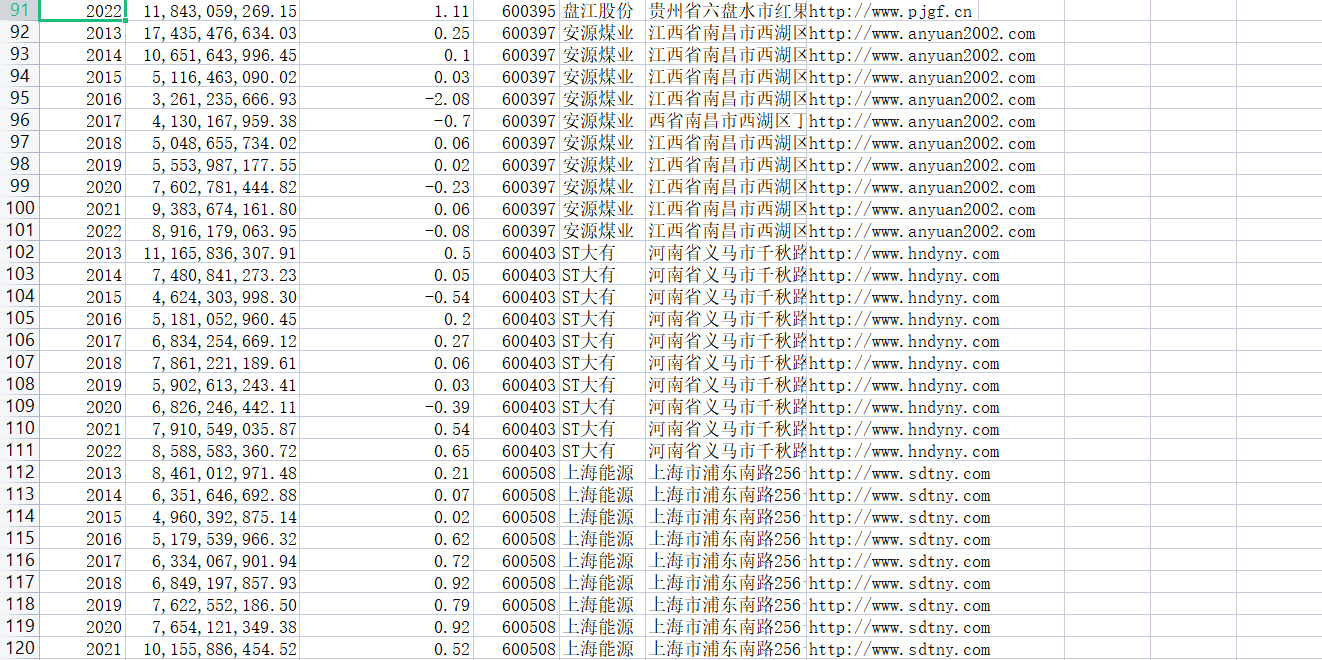
营业收入可以看见一个公司的规模,而基本每股收益可以看出公司的盈利能力和经营成果。基本每股收益是归属于普通股股东的当期净利润与当期发行在外普通股的加权平均数的比率,即每股能带来的利润。
根据每股收益随时间趋势变化图(2013-2022),可以观察到煤炭开采与洗选业的企业盈利能力较好,大部分公司近十年的基本每股收益都为正。且大部分公司近十年基本每股收益的变化趋势基本一致,呈现出2013-2015年下降,2016-2017年上升,2018-2020年较平稳,而2020年后整体波动较为剧烈,各个公司均出现不同程度的增长。
考虑到煤炭开采与洗选行业的发展与煤炭价格息息相关,煤炭价格上下波动对煤炭企业的盈利能力造成很大冲击,行业利润波动剧烈也比较正常。受国家供给侧结构性改革的影响, 2016年我国煤炭价格触底反弹,回顾过去, 从“黄金十年”的上涨到2012-2015年的急剧下降, 再到2016年的快速上涨, 煤炭价格经历了整整1个经济周期, 以及截止2021年末,环渤海动力煤(5500 大卡)价格指数 737 元/吨,较上年末上升152 元/吨;全年指数均价 673 元/吨,同比上升 124 元/吨,增幅18.4%。
2014-2015年受煤炭价格波动的冲击,煤炭开采与洗选行业大量公司净利润下降。根据2015年基本每股收益柱状图,基本每股收益为负数的公司有两家(在前十家公司中),分别为陕西煤业和中煤能源,这是近十年来前十家公司中最多公司亏损的一年。并且除了中国神华和淮北矿业外的其余六家公司的基本每股收益虽然为正,但也十分微薄。
兖州煤业2013-2022年以来基本每股收益都为正数,未曾亏损,2021年归属于上市公司股东的净利润超过162亿元,同比增长128.3%,一举超过中国神华,稳坐每股收益第一的位置。
煤炭开采与洗选行业是中国传统的重要行业之一,近十年来经历了多次调整和重构。
1. 行业整体发展态势:自2010年以来,煤炭开采与洗选行业经历了一个波动的发展过程,特别是在2015年左右,国家开始推行去产能政策,对行业造成了很大的冲击。但是,在2017年以后,随着国家环保政策的加强和经济结构的调整,行业逐渐趋于平稳。
2. 行业产值与利润:根据国家统计局数据显示,从2010年到2019年,煤炭开采与洗选行业总产值从3.5万亿元增长到5.5万亿元,年均增速为4.8%;而利润总额则从1.2万亿元增长到1.6万亿元,年均增速为3.4%。可以看出,行业产值和利润都有一定的增长,但增速并不算太快。
3. 行业结构变化:由于国家政策的影响和市场竞争的加剧,煤炭开采与洗选行业的结构也在发生变化。其中,大型企业的市场份额逐渐扩大,小型企业的市场份额逐渐缩小。同时,煤炭洗选技术也在不断更新,更加环保、高效的洗选设备正在逐步普及。
4. 行业未来发展趋势:随着国家对环保和能源结构的重视,煤炭开采与洗选行业未来将面临许多挑战和机遇。未来,该行业将继续推进去产能、提升技术水平、加强环保治理,同时也将探索多元化的发展模式,如煤炭炭化、煤化工等新兴领域。
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
import json
import os
from time import sleep
from urllib import parse
import requests
import time
import random
from fake_useragent import UserAgent
import pdfplumber
ua = UserAgent()
userAgen = ua.random
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': userAgen,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
get_json = requests.post(url, headers=hd, data=data)
data_json = get_json.content
toStr = str(data_json, encoding="utf-8")
last_json = json.loads(toStr)
orgId = last_json["keyBoardList"][0]["orgId"] # 获取参数
plate = last_json["keyBoardList"][0]["plate"]
code = last_json["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name): # 下载pdf
url = url
r = requests.get(url)
f = open(company + "/" + file_name + ".pdf", "wb")
f.write(r.content)
f.close()
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 20,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'User-Agent': ua.random,
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
}
data = parse.urlencode(data)
data_json = requests.post(url, headers=hd, data=data)
toStr = str(data_json.content, encoding="utf-8")
last_json = json.loads(toStr)
reports_list = last_json['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + pdf_url, "存放在当前目录:/" + company + "/" + file_name)
download_PDF(pdf_url, file_name)
time.sleep(random.random()*3)
if __name__ == '__main__':
company_list = ["000552", "000937", "000983", "002128", "600121", "600123", "600188", "600348", "600395",
"600397", "600403", "600508", "600758", "600971", "600985", "601001", "601088", "601101", "601225",
"601666", "601699", "601898", "601918", "900948"]
for company in company_list:
os.mkdir(company)
orgId, plate,code = get_adress(company)
get_PDF(orgId, plate, code)
print("下载成功")

import os
import pandas as pd
import pdfplumber
def getfns(path,suffix):
res=[os.path.join(path,fname) for fname in os.listdir(path) if fname.endswith(suffix)]
return res
paths = ['E:/系统/桌面/作业/000552', 'E:/系统/桌面/作业/000937','E:/系统/桌面/作业/000983','E:/系统/桌面/作业/002128','E:/系统/桌面/作业/600121','E:/系统/桌面/作业/600123','E:/系统/桌面/作业/600188','E:/系统/桌面/作业/600348','E:/系统/桌面/作业/600395','E:/系统/桌面/作业/600397','E:/系统/桌面/作业/600403','E:/系统/桌面/作业/600508','E:/系统/桌面/作业/600758','E:/系统/桌面/作业/600971','E:/系统/桌面/作业/600985','E:/系统/桌面/作业/601001','E:/系统/桌面/作业/601088','E:/系统/桌面/作业/601101', 'E:/系统/桌面/作业/601225','E:/系统/桌面/作业/601666','E:/系统/桌面/作业/601699','E:/系统/桌面/作业/601898','E:/系统/桌面/作业/601918','E:/系统/桌面/作业/900948'] # 文件夹路径列表
suffix = '.pdf'
def f1(lst): # get c1
c1 = [e[0] for e in lst]
return c1
def f2(lst): # get c1 and c2
c12 = [e[:2] for e in lst]
c6 = d[5]
return c12
for path in paths:
company_code = os.path.basename(path)
fns = getfns(path,'.pdf')
for e in fns:
if '更新' not in e:
with pdfplumber.open(e) as pdf:
for page in pdf.pages:
d = page.extract_table()
if d is not None:
c1 = f1(d)
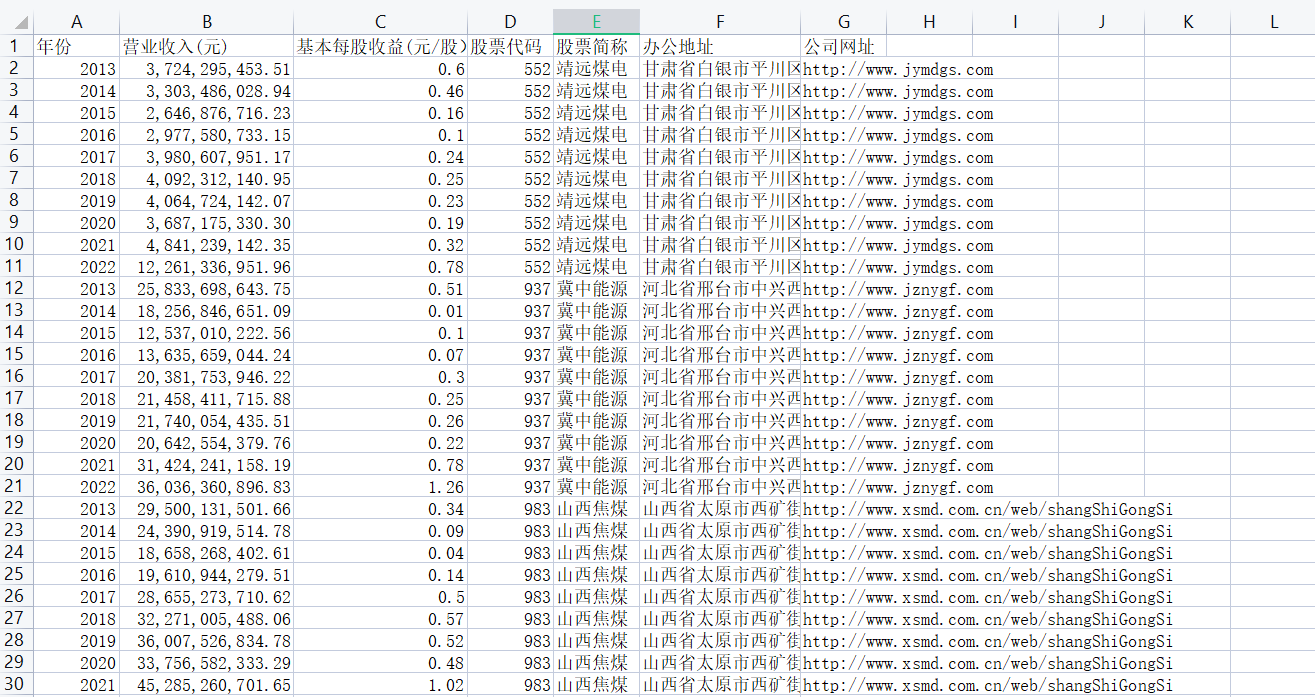
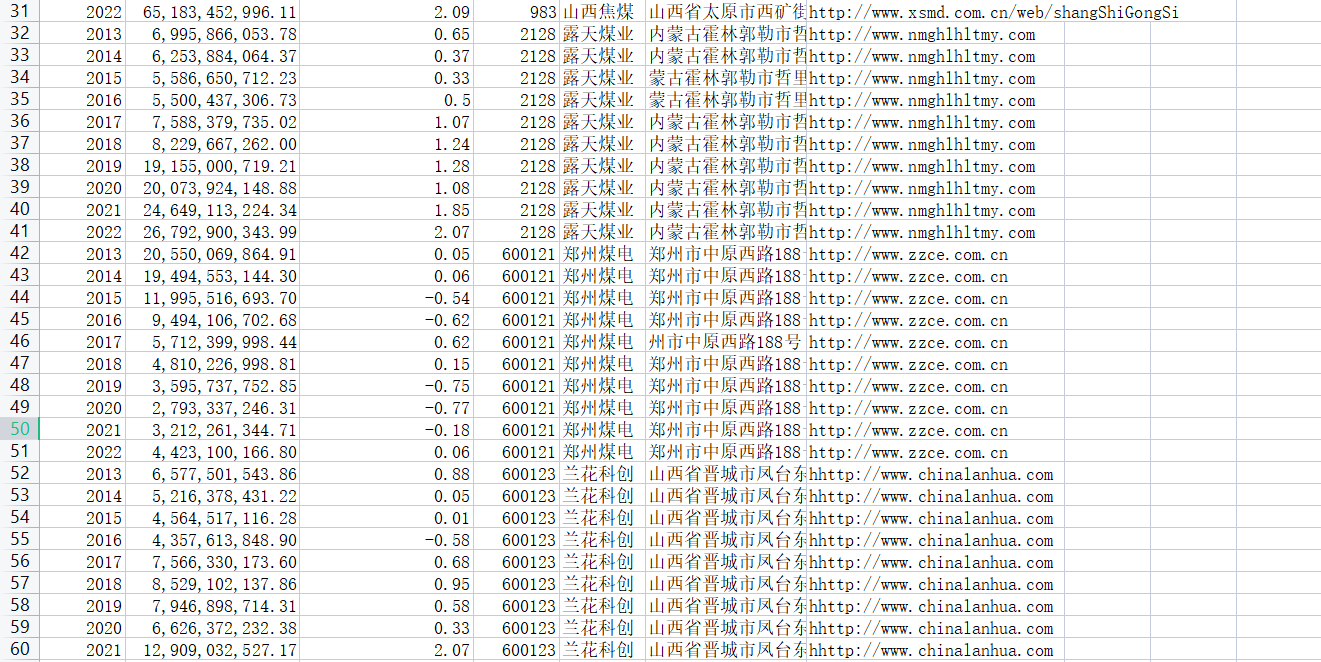
if '' == c1[0] and '营业收入(元)' in c1 and '基本每股收益(元/股)' in c1:
c12 = f2(d)
print(c12[0][1], c12[1][1])
for c in c12:
if c[0] == '基本每股收益(元/股)':
print(c[1])
data = {
'年份': c12[0][1],
'营业收入(元)': c12[1][1],
'基本每股收益(元/股)': c[1],
'股票代码': company_code,
'办公地址': c12[10],
'公司网址': c12[12],
}
df = pd.DataFrame([data])
df.to_csv('数据.csv', index=False, mode='a', header=not os.path.exists('数据.csv'))
break # 添加注释,结束循环
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10)
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
import os
data = pd.read_csv("数据.csv")
map_data = dict(Counter(data['股票简称']))
print(map_data)
print("=========================================================")
print("共有{}家公司".format(len(map_data)))
data["营业收入(元)"] = [i.replace(",", "") for i in data["营业收入(元)"]]
data["营业收入(元)"] = data["营业收入(元)"].astype("float")
data["基本每股收益(元/股)"] = data["基本每股收益(元/股)"].astype("float")
top_10 = data.groupby("股票简称").sum().sort_values("营业收入(元)", ascending=False)["营业收入(元)"][0:10]
print(top_10.index.tolist())
year = dict(Counter(data['年份']))
year_list = [int(i) for i in year.keys()]
year_list.sort()
print(year_list)

#coding=utf-8
import seaborn as sns
import pandas as pd
from matplotlib import pyplot as plt
### 导入数据
df = pd.read_excel('营业收入和基本每股收益数据.xlsx', sheet_name=0)
np = df['股票简称'].value_counts()
### 因为公司超过10家,需要计算出 营业收入最好的10家;
moneys_count_arr = []
for stock in np.index:
df_stock = df[df['股票简称'] == stock]
moneys_list = df_stock['营业收入(元)'].to_list()
moneys_count = 0
for aa in moneys_list:
cc = float(aa)
moneys_count = moneys_count + cc
moneys_count_arr.append(moneys_count)
print('合计', moneys_count)
df_temp = pd.DataFrame()
df_temp['股票简称'] = np.index
df_temp['总销售额'] = moneys_count_arr
df_temp_new = df_temp.sort_values('总销售额', ascending=False)
df_top10 = df_temp_new[0:10]
top10_stock_arr = df_top10['股票简称'].to_list()
top10_stock_names = []
for a in top10_stock_arr:
top10_stock_names.append(a)
print(top10_stock_names)
# 基营业收入随时间变化趋势图
from matplotlib import pyplot as plt
df['年份'] = df['年份'].astype('int')
markers = ['o', '1', 's', '2', '4', 'p', 'h', '8', 'D', 'o']
data_arr = []
for stock_name in top10_stock_names:
df_stock = df[df['股票简称'] == stock_name]
df_stock_new = df_stock.sort_values('年份', ascending=True)
moneys = df_stock_new['营业收入(元)'].to_list()
money_arr = []
for money in moneys:
money_arr.append(money / 10000000000)
data_arr.append(money_arr)
labels = top10_stock_names.copy()
# 绘制图像
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文
plt.figure(figsize=(10, 10))
for i in range(len(data_arr)):
plt.plot(range(len(data_arr[i])), data_arr[i], marker=markers[i], label=labels[i]) # 制作图例
plt.xlabel('年份') # x轴标题
plt.ylabel('营业收入(百亿元)') # y轴标题
years_arr = ['2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']
plt.xticks(range(len(years_arr)), years_arr)
plt.legend() # 显示图例
plt.title('营业收入随时间变化趋势图(2013-2022)')
plt.grid(axis='x')
plt.show() # 显示图像
# 基本每股收益随时间变化趋势图
df['年份'] = df['年份'].astype('int')
markers = ['o', '1', 's', '2', '4', 'p', 'h', '8', 'D', 'o']
data_arr = []
for stock_name in top10_stock_names:
df_stock = df[df['股票简称'] == stock_name]
df_stock_new = df_stock.sort_values('年份', ascending=True)
moneys = df_stock_new['基本每股收益(元/股)'].to_list()
money_arr = []
for money in moneys:
money_arr.append(money)
data_arr.append(money_arr)
labels = top10_stock_names.copy()
# 绘制图像
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文
plt.figure(figsize=(10, 10))
for i in range(len(data_arr)):
plt.plot(range(len(data_arr[i])), data_arr[i], marker=markers[i], label=labels[i]) # 制作图例
plt.xlabel('年份') # x轴标题
plt.ylabel('基本每股收益(元/股)') # y轴标题
years_arr = ['2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']
plt.xticks(range(len(years_arr)), years_arr)
plt.legend() # 显示图例
plt.title('基本每股收益随时间变化趋势图(2013-2022)')
plt.grid(axis='x')
plt.show() # 显示图像
# 对数据进行处理,获取营业收入排行前10 所有股票数据
def judgeName(x):
if x in top10_stock_names:
return '1'
else:
return 0
df['judge'] = df['股票简称'].apply(judgeName)
df_ss = df[df['judge'] == '1']
# 营业收入(元) 转换为 营业收入(百亿元)
df_ss['营业收入(百亿元)'] = df_ss['营业收入(元)'].apply(lambda x: x / 10000000000)
# 2013-2015
df_201315 = df_ss[(df_ss['年份'] == 2013) | (df_ss['年份'] == 2014) | (df_ss['年份'] == 2015)]
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='营业收入(百亿元)', hue='股票简称', data=df_201315)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('营业收入(百亿元)')
plt.title('行业内横向对比营业收入(2013-2015)')
plt.grid()
plt.show()
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='基本每股收益(元/股)', hue='股票简称', data=df_201315)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.title('行业内横向对比基本每股收益(元/股)(2013-2015)')
plt.grid()
plt.show()
# 2016-2018
df_201618 = df_ss[(df_ss['年份'] == 2016) | (df_ss['年份'] == 2017) | (df_ss['年份'] == 2018)]
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='营业收入(百亿元)', hue='股票简称', data=df_201618)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('营业收入(百亿元)')
plt.title('行业内横向对比营业收入(2016-2018)')
plt.grid()
plt.show()
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='基本每股收益(元/股)', hue='股票简称', data=df_201618)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.title('行业内横向对比基本每股收益(元/股)(2016-2018)')
plt.grid()
plt.show()
# 2019-2022
df_201922 = df_ss[(df_ss['年份'] == 2019) | (df_ss['年份'] == 2020) | (df_ss['年份'] == 2021) | (df_ss['年份'] == 2022)]
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='营业收入(百亿元)', hue='股票简称', data=df_201922)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('营业收入(百亿元)')
plt.title('行业内横向对比营业收入(2019-2022)')
plt.grid()
plt.show()
fig = plt.figure(figsize=(17, 10))
ax = fig.subplots()
sns.barplot(x='年份', y='基本每股收益(元/股)', hue='股票简称', data=df_201922)
sns.despine()
# 设置图例
lgd = ax.legend(loc='upper right', fancybox=True, prop={'size': 10})
plt.setp(lgd.get_title(), fontsize=20)
plt.grid(axis='y')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.title('行业内横向对比基本每股收益(元/股)(2019-2022)')
plt.grid()
plt.show()
当我第一次在课堂上听老师向我们介绍整个实验报告的要求时,我深感恐惧与震惊,因为在当时对于我来说这次作业几乎是一项不可能完成的任务,但是当我真正投入时间和精力静下心来去一步一步地仔细思考,才发现原来方法远比困难多,与其囿于自己给自己编织的恐惧牢笼,不如大胆地迈出第一步,即使问题很多,但不会就学,不懂就问,多方面自学,拓展知识,耐心调错,最终呈现出这样一份实验报告报告,虽然其中还有挺多不尽如人意的地方,但还是给我带来了前所未有的自豪感,给了我莫大的激励。
通过完成整个实验报告,我认识到虽然这次的实验报告都是我们上课学过的知识的延伸,但对于我们自身知识点的掌握情况和对于正则表达式、数据储存、Python爬虫各种库的应用的熟练程度乃至网页技术应用都有较高的要求。
经过一个学期对于金融数据获取与处理课程的学习,我认识到了使用Python进行大批量的数据处理的便捷,也惊叹于各类语法的精妙,最后要感谢吴老师一学期以来的悉心教导和耐心解答,让我对Python有了更深的理解,今后我愿意继续深入学习金融数据获取与处理的相关知识,努力将所学运用到实践。