import re
import tool
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import requests
def download_pdf_from_szse(url):
options = webdriver.ChromeOptions()
download_path ="C:\\Users\\37036\\Desktop\\nianbao\\src\\pdf\\"
profile = {"plugins.plugins_list": [{"enabled": False, "name": "Chrome PDF Viewer"}],
"download.default_directory": download_path}
options.add_experimental_option("prefs", profile)
browser = webdriver.Chrome(chrome_options=options)
browser.get(url)
time.sleep(3)
browser.set_window_size(1552, 840)
browser.find_element(By.ID, "annouceDownloadBtn").click()
time.sleep(15)
print(url + '\n下载完成')
def get_pdf_link_from_szse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('',re.DOTALL)
links = pattern.findall(html)
for lk in links:
if '摘要' in lk[1] or '英文' in lk[1]:
continue
else:
full_links.append(lk[0])
for i in range(0,len(full_links)):
full_links[i] = 'https://www.szse.cn' + full_links[i]
'''
以上是获取所有的下载链接
下面是下载,需要调用download_pdf模块
'''
for i in range(0,min(len(full_links),10)):
try: download_pdf_from_szse(full_links[i])
except: print('股票'+code+'缺失,请到'+
full_links[i]+'重新下载')
def download_pdf_from_sse(url):
fname = '../pdf/' + url.split('/')[-1]
with open(fname,'wb') as pdf:
pdf.write(requests.get(url).content)
print(url + '\n下载完成')
def get_pdf_link_from_sse(code):
fname = f'../nianbao/{code}.html'
html = ''
with open(fname,'r',encoding = 'utf-8') as f:
html = f.read()
pattern = re.compile('class="table_titlewrap" href="(.*?)" target="_blank">(.*?)
读取数据并绘图
import re
import pandas as pd
import os
import tool
import pdfplumber
def is_fin_number(string):
if string == '':
return False
try:
string = string.strip()
string = string.replace(',','')
except: return False
for s in string:
if s.isdigit() == True or s == '-' or s == '.' or s == ' ' or s == '\n':
continue
else:
return False
return True
def get_data(row,name_mode):
rc = re.compile(name_mode,re.DOTALL)
bound = 0
for i in range(0,len(row)):
rs = None
try:
rs = rc.search(row[i]) #row[i]可能是None
except:
continue
if rs is None:
continue
else:
bound = i
break
if rs is None:
return -1
for i in range(bound,len(row)):
if is_fin_number(row[i]) == True:
return row[i]
return 'other row'
def is_this_page(text):
mode = '\n.*?主+要+会+计+数+据+和+财+务+指+标+.*?\n'
if re.search(mode,text) is None:
return False
else:
return True
def get_twin_data(fname):
earnings = -1
try:
with pdfplumber.open('../pdf/' + fname) as pdf:
s = 0
for i in range(0,len(pdf.pages)):
text = pdf.pages[i].extract_text()
if is_this_page(text) == True:
s = i
break
else:
continue
page_index = 0
bound = 0
for i in range(s,s+2): #deterministic
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
for j in range(0,len(table)):
e = get_data(table[j],'.*?营业收入.*?')
if e == 'other row':
for k in range(j-1, 0,-1):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
e = table[k][h]
break
else:
continue
else:
if is_fin_number(e) == True:
break
if e != -1:
earnings = e
bound = j
break
else:
continue
if earnings == -1:
continue
page_index = i
break
if earnings == 0:
return None
net_income = -1
for i in range(page_index,page_index + 2):
table = pdf.pages[i].extract_table()
try: len(table)
except: continue
ni_mode = '.*?归属于.*?(所有者|股东)?的?.?净?.?利?.?润?.*?'
if i == page_index: #说明此时还没有换页
for j in range(bound + 1,len(table)):
ni = get_data(table[j], ni_mode)
if ni == 'other row':
for k in range(j, len(table)):
for h in range(0,len(table[k])):
if is_fin_number(table[k][h]) == True:
net_income = table[k][h]
return [earnings,net_income]
else:
continue
if ni == 'other row':
return 'data is at the next page'
elif ni != -1:
net_income = ni
break
else:
continue
else: #换页
for j in range(0,len(table)):
ni = get_data(table[j], ni_mode)
if ni != -1:
net_income = ni
break
else:
continue
if net_income == -1: continue
else: return [earnings,net_income]
except: print(fname+'出现AssertionError')
#该函数需要在pdf目录下查找对应的文件名
def read_all_data(df):
#df为包含两列(code_list和name_list)的dataframe
filename_list = []
year_list = []
data_list = []
for index,row in df.iterrows():
for filepath,dirnames,filenames in os.walk('../pdf'):
for filename in filenames:
#print(filename)
if (row['name_list'] in filename) or (row['code_list'] in filename):
print(filename)
data = get_twin_data(filename)
if data is not None:
filename_list.append(filename)
year_list.append(tool.get_year(filename,row['code_list']))
data_list.append(get_twin_data(filename))
print(filename + ' completed')
rt_list,ni_list = zip(*data_list)
df_data = {'filename':filename_list,'year':year_list,
'营业收入':rt_list,'净利润':ni_list}
df_data = pd.DataFrame(df_data)
return df_data
#以下是绘图代码:
import matplotlib.pyplot as plt
import numpy as np
import tool
def draw_pics_twinx(df):
plt.rcParams['figure.dpi'] = 200
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图片显示中文
x = df['year']
tool.to_year_list(x)
y_inc = df['营业收入']
tool.to_num_list(y_inc)
y_np = df['净利润']
tool.to_num_list(y_np)
fig = plt.figure()
ax1 = fig.subplots()
ax1.plot(x, y_inc,'steel blue',label="营业收入",linestyle='-',linewidth=2,
marker='o',markeredgecolor='pink',markersize='2',markeredgewidth=2)
ax1.set_xlabel('年份')
ax1.set_ylabel('营业收入(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_inc[i],(y_inc[i]),fontsize = '10')
ax1.legend(loc = 6)
ax2 = ax1.twinx()
ax2.plot(x, y_np, 'orange',label = "归属于股东的净利润",linestyle='-',linewidth=2,
marker='o',markeredgecolor='teal',markersize='2',markeredgewidth=2)
ax2.set_ylabel('归属于股东的净利润(单位:亿元)')
for i in range(len(x)):
plt.text(x[i],y_np[i],(y_np[i]),fontsize = '10')
ax2.legend(loc = 2)
title = df['name'][0] + '历年' + '财务数据'
plt.title(title)
plt.savefig('../pics/' + title + '.png')
plt.show()
结果
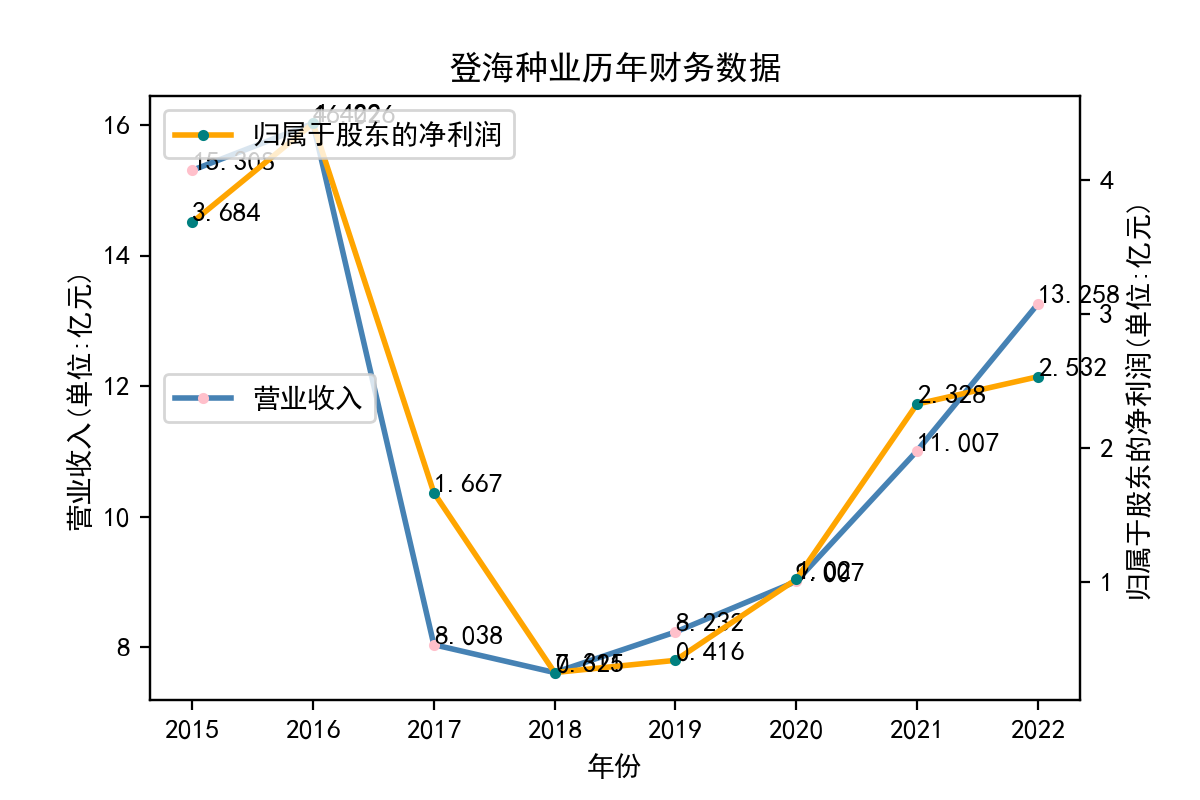
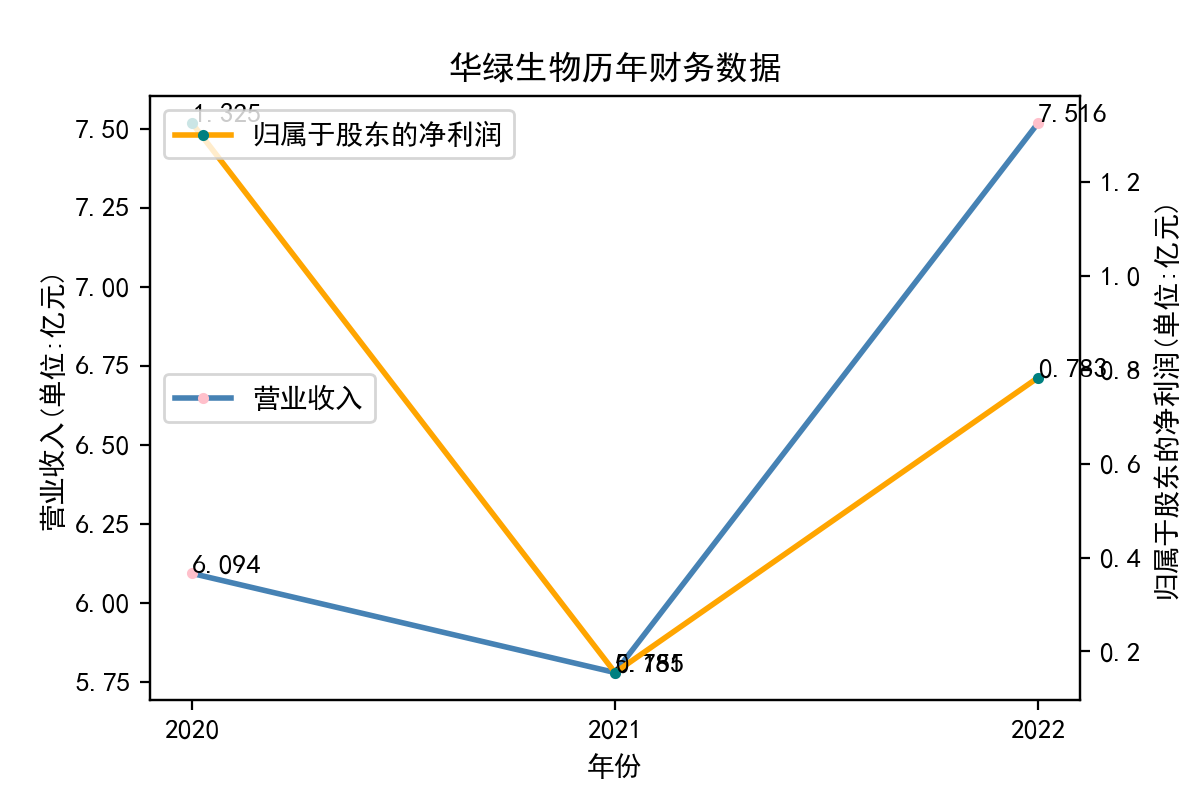
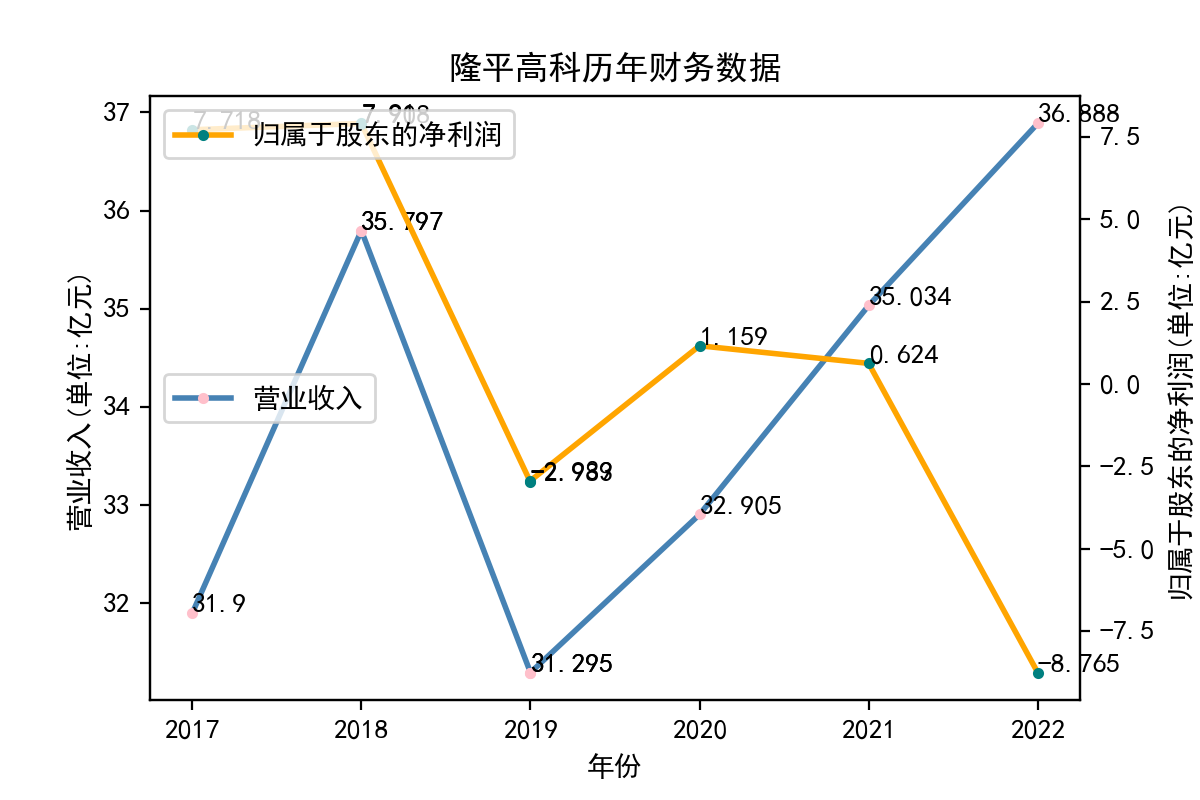

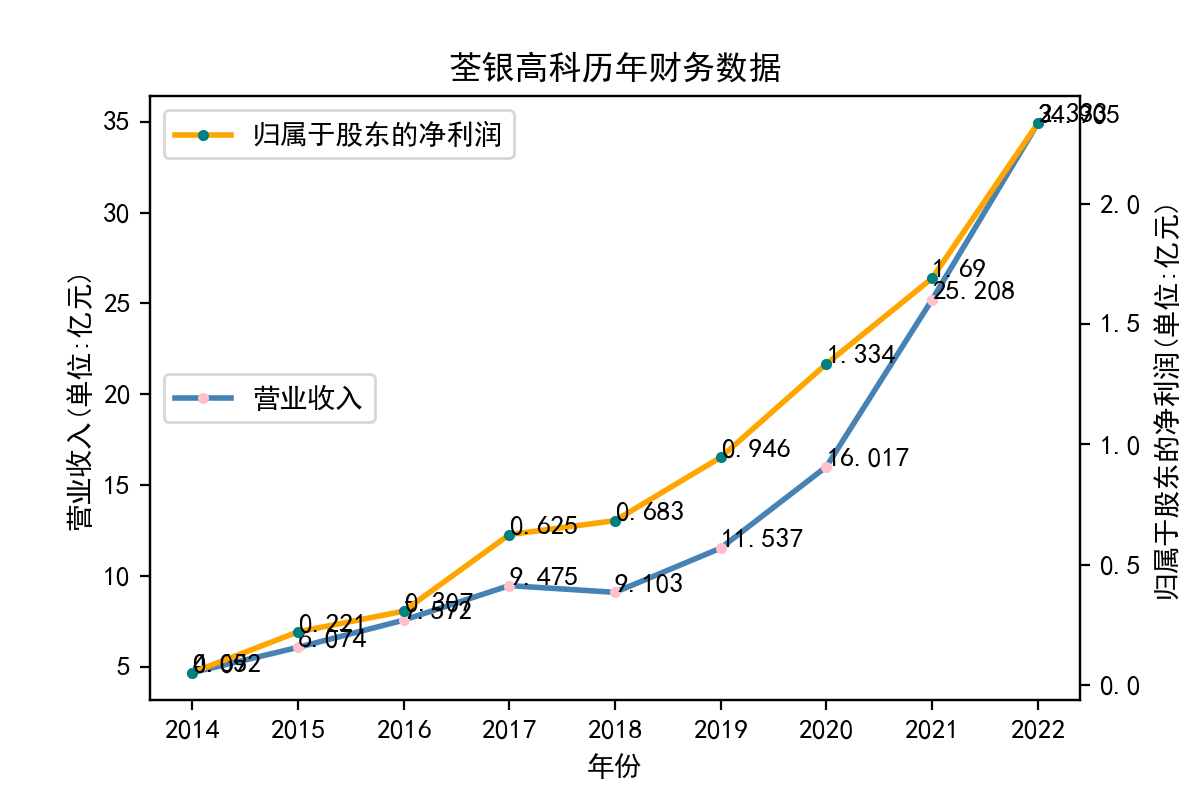
分析
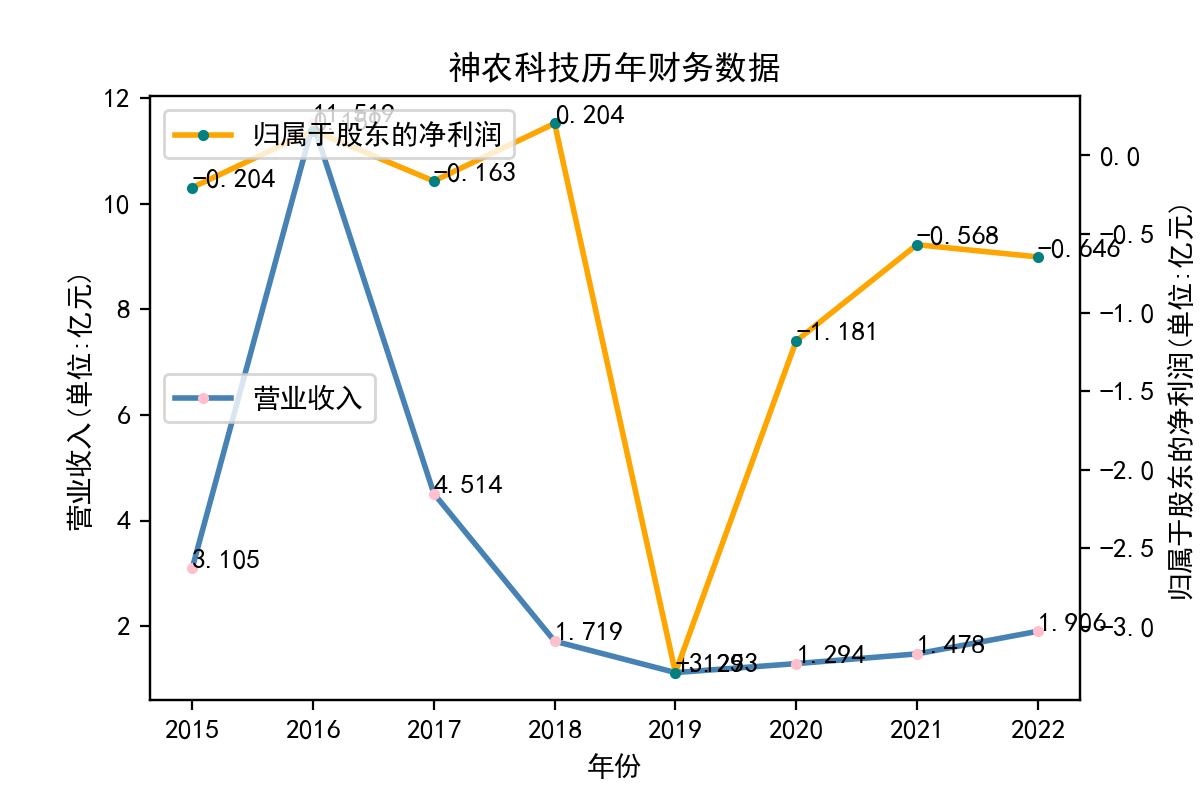
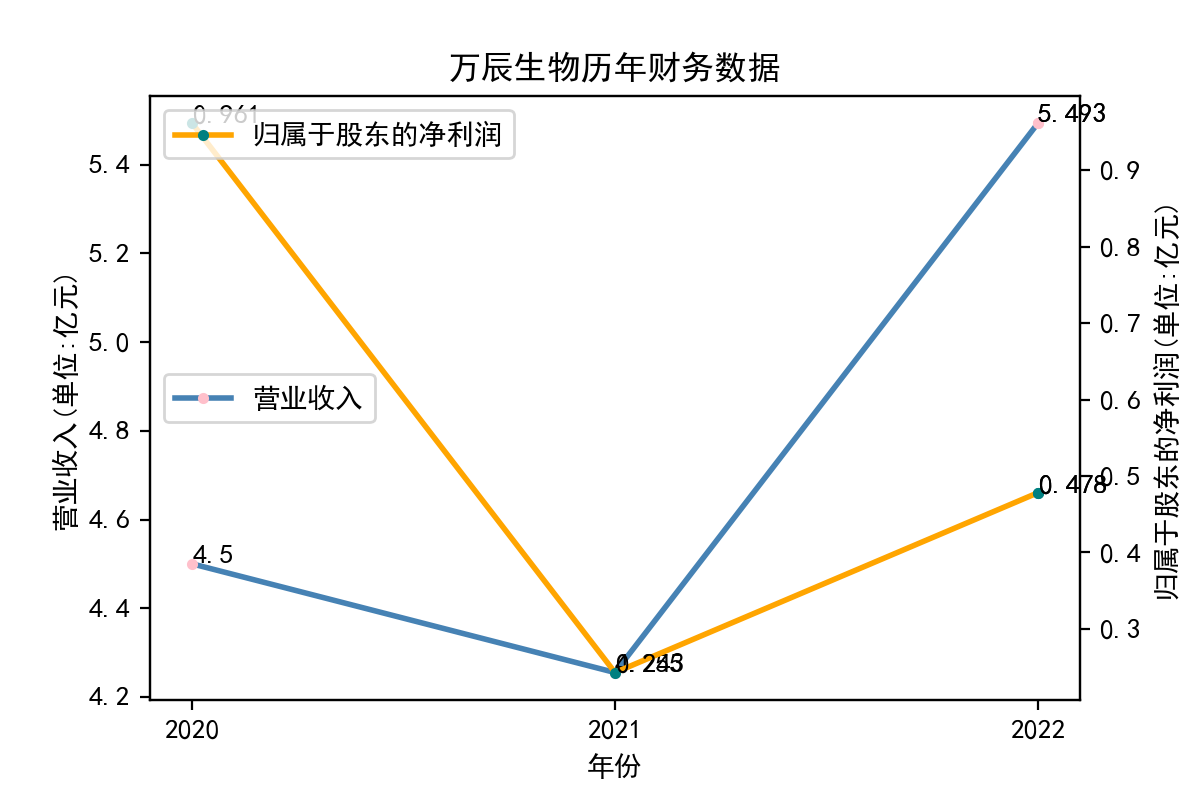
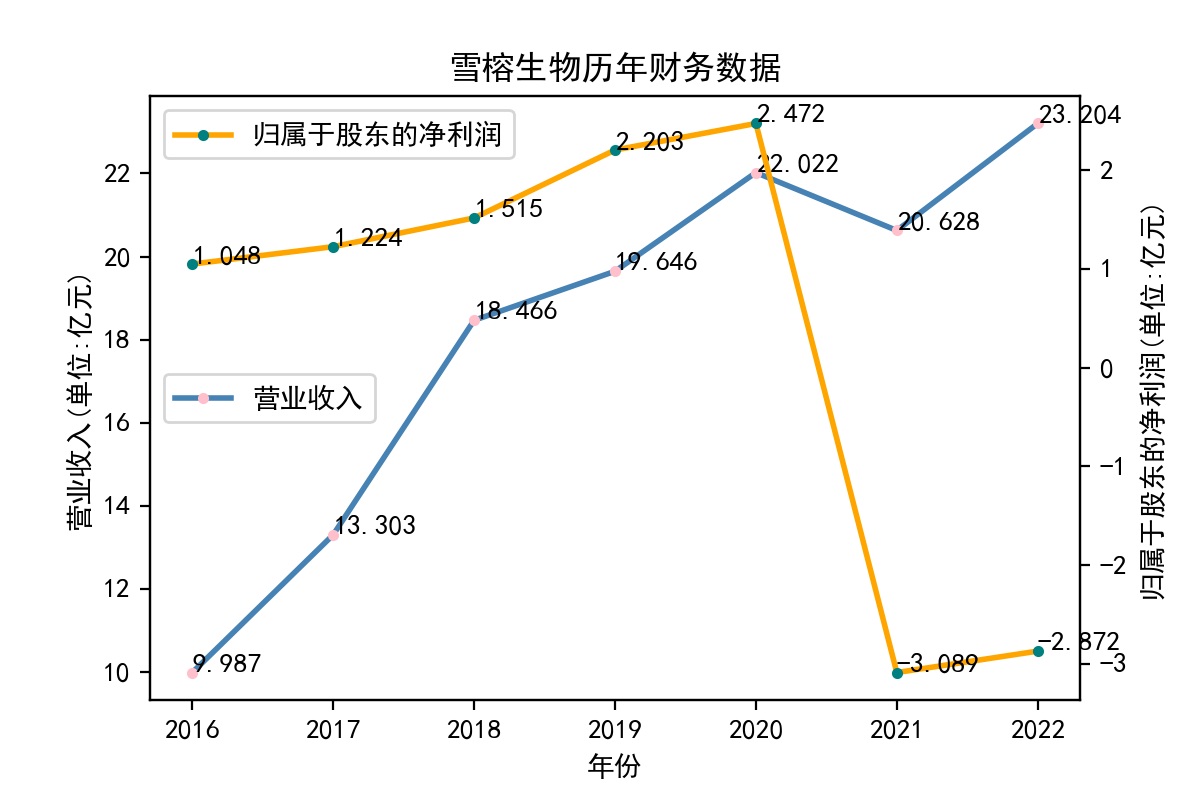
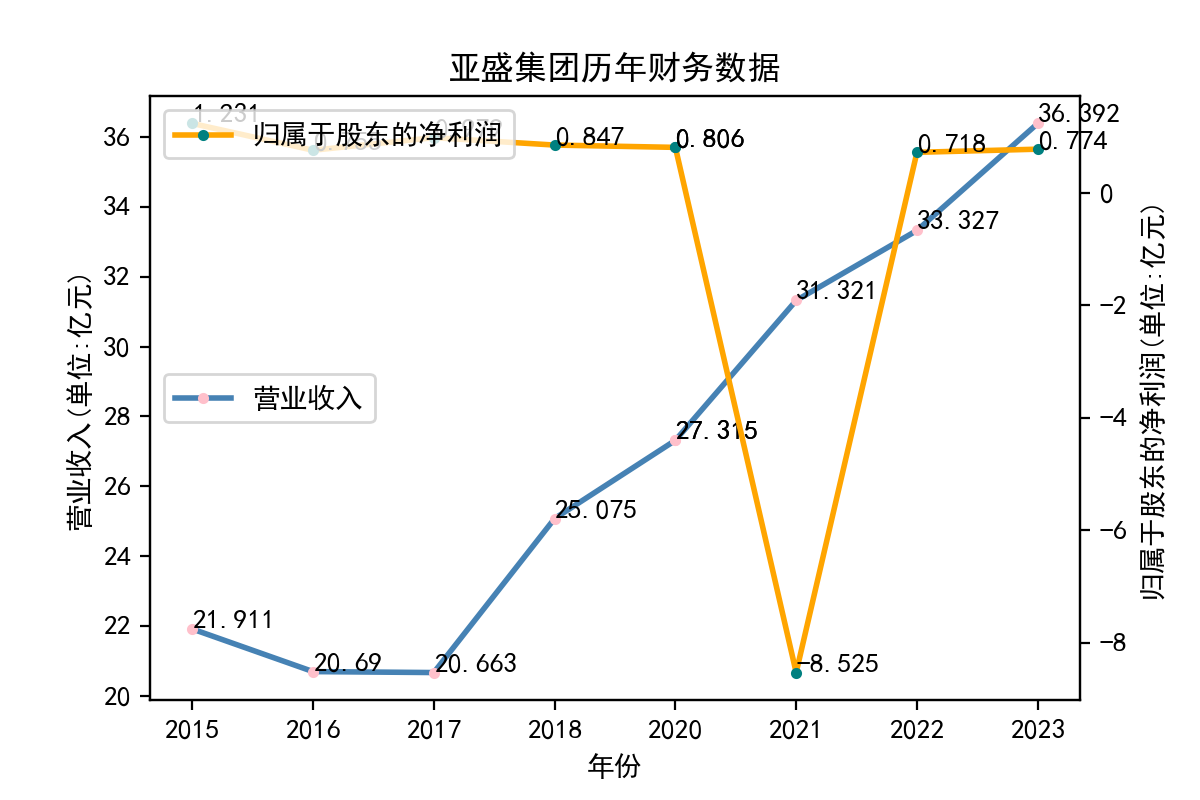
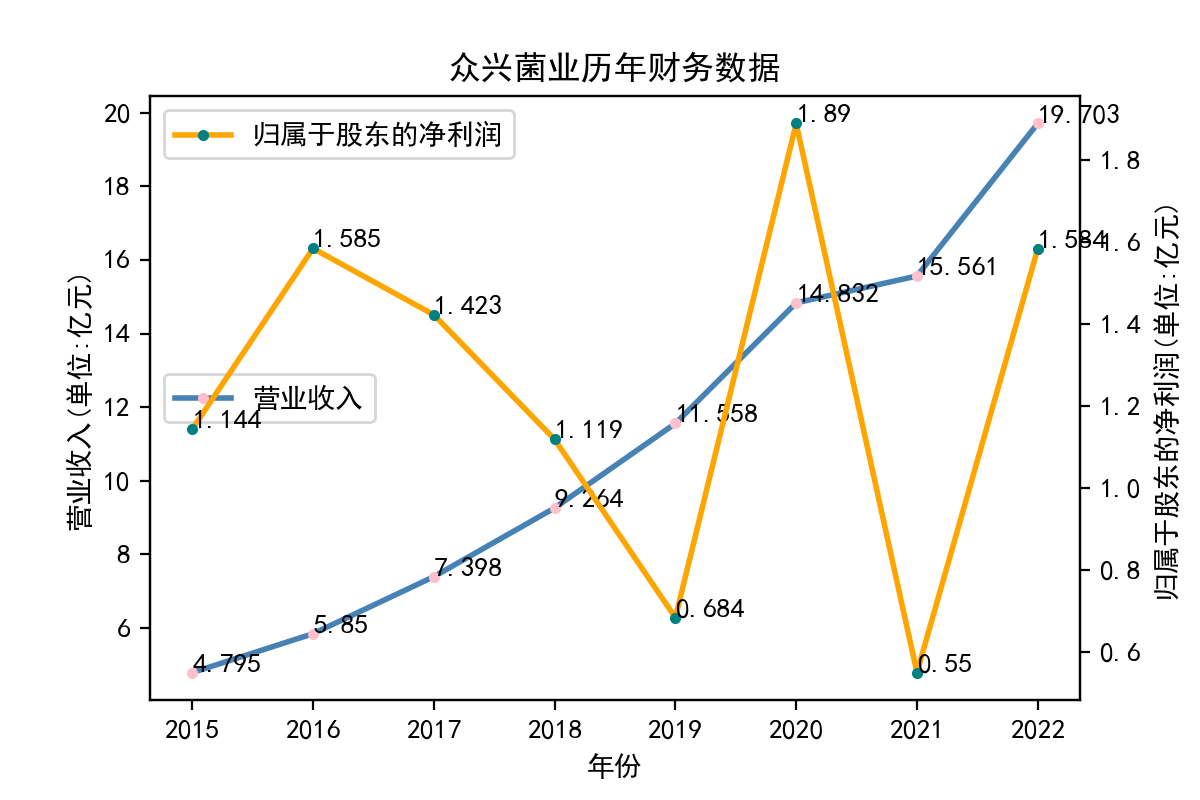
从归属于股东的净利润看,每个企业近十年左右的表现大相径庭。荃银高科每年的归属于股东净利润不断提高,呈现逐步增长的趋势。一部分企业,如隆平高科、登海种业神农科技、众兴菌业,在2018-2019年出现了下滑。华绿生物,万辰生物、亚盛集团、众兴菌业、雪榕生物在2021年大幅度降低,然而除了雪榕生物,其他几家企业归属于股东净利润在2022年回升至2020年左右的水平。
从营业收入看,大部分企业在2014-2023年内均呈现上升趋势,但存在个体差异,如登海种业在2016-2017年间营业收入大幅度下滑;农发种业在2016-2018年间持续下滑,并于后续回升。神农科技则完全与总趋势相反,在2016到2019年间急剧下降,并一直保持在较低水平,由此可推断神农科技营业收入的下滑应当与经济环境和自然灾害无关,而与其自身经营有关。