import fitz
import re
import pandas as pd
import numpy as np
pdf = '行业分类.pdf'
def getText(pdf):
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.getText()
doc.close()
return(text)
# 定义函数获取PDF页码中的内容
kind = kind.split('\n')
kind1 = kind[9067:9200]
del kind1[56:63]
kind1 = kind1[:114]
kind2 = [kind1[1]]
del kind1[56]
del kind2[0]
for i in range(2,len(kind1)+1,2):
kind2.append(kind1[i])
del kind2[0]
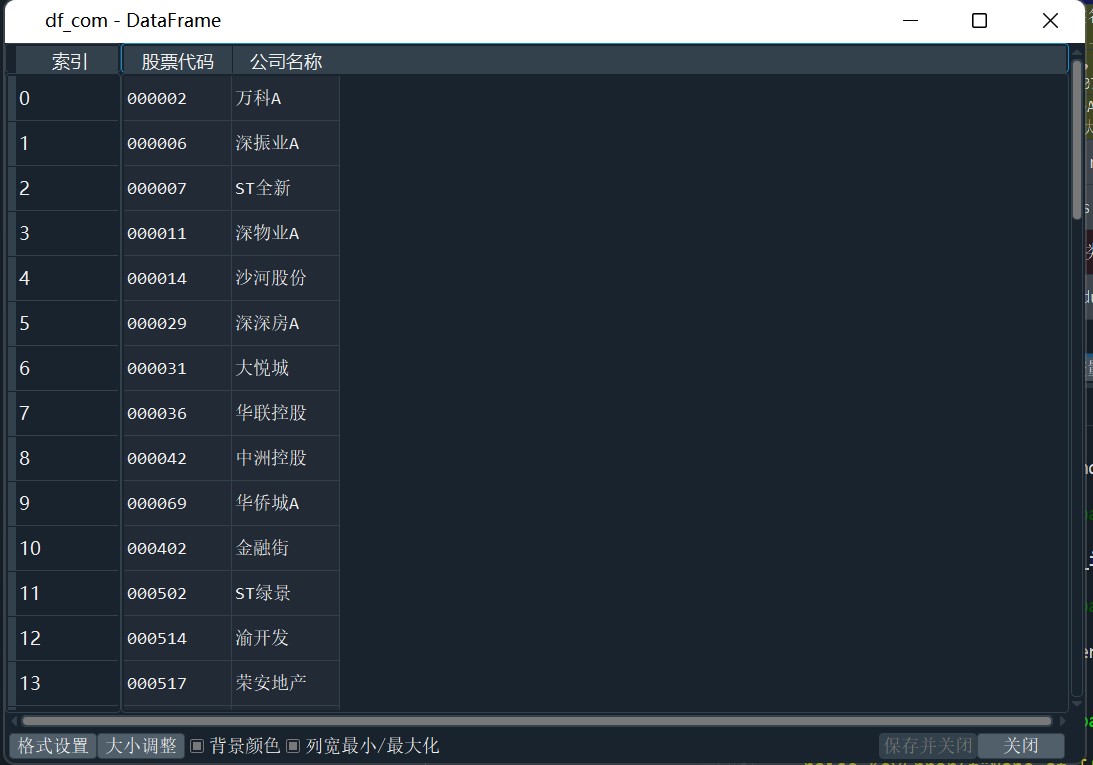
df_com=pd.DataFrame(columns=['股票代码','公司名称'],index=range(len(kind2)))
for i in range(len(kind2)):
df_com['股票代码'][[i]]=kind2[i]
kind2=[kind1[1]]
del kind2[0]
for i in range(0,len(kind1)+1,2):
kind2.append(kind1[i])
kind2 = kind2[:110]
for i in range(len(kind2)):
df_com['公司名称'][[i]]=kind2[i]
df_com.to_csv(kind1[0]+kind1[1]+'.csv')
# 处理公司的名称和代码一一对应 图1
def shou_suo(a):
# a=df_com.iloc[0,1]
# browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code')
element.send_keys(a+ Keys.ENTER)
element = browser.find_element(By.ID,'disclosure-table')
element = browser.find_element(By.CSS_SELECTOR,"#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT,"年度报告").click()
element = browser.find_element(By.ID,'disclosure-table')
return(element)
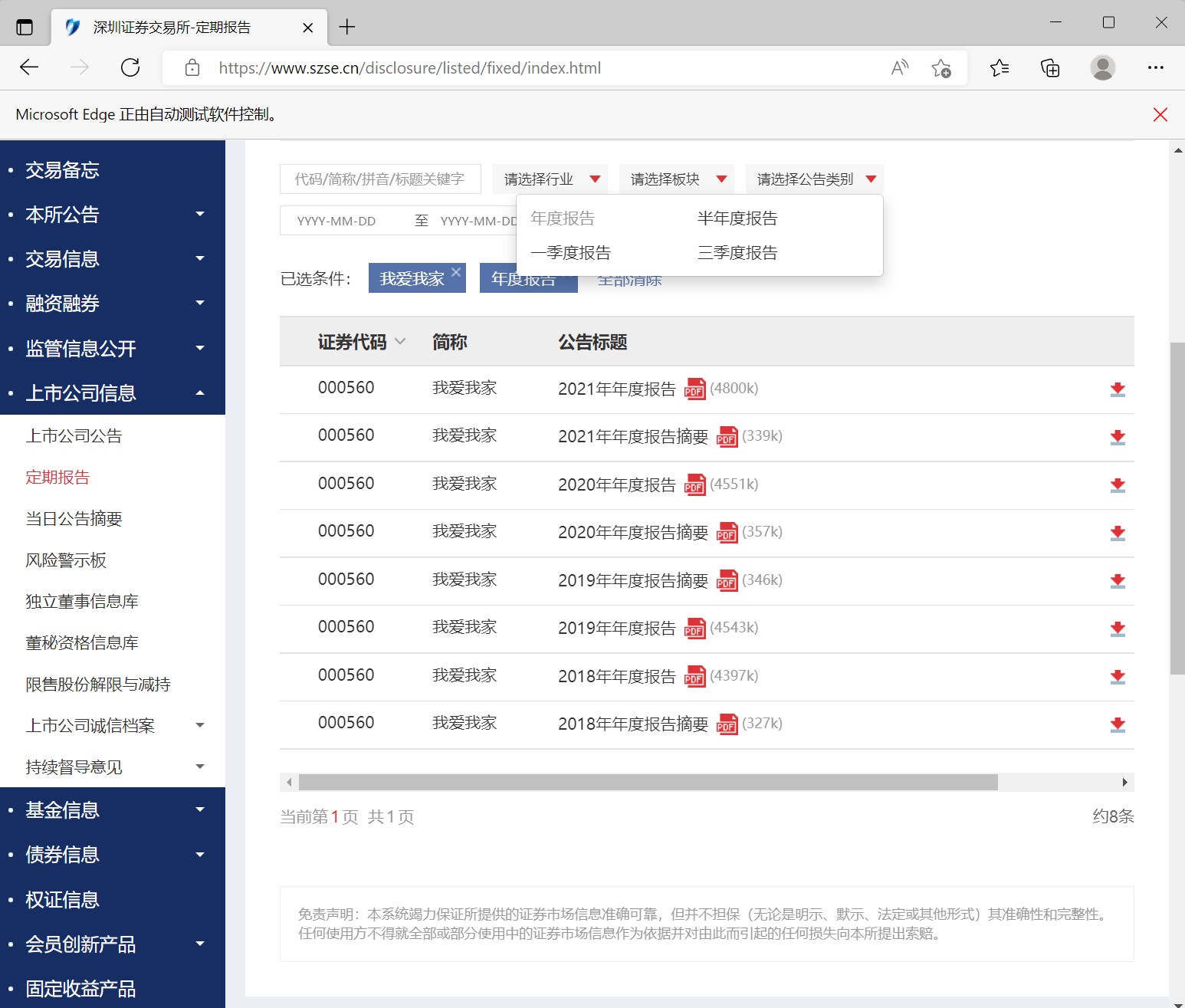
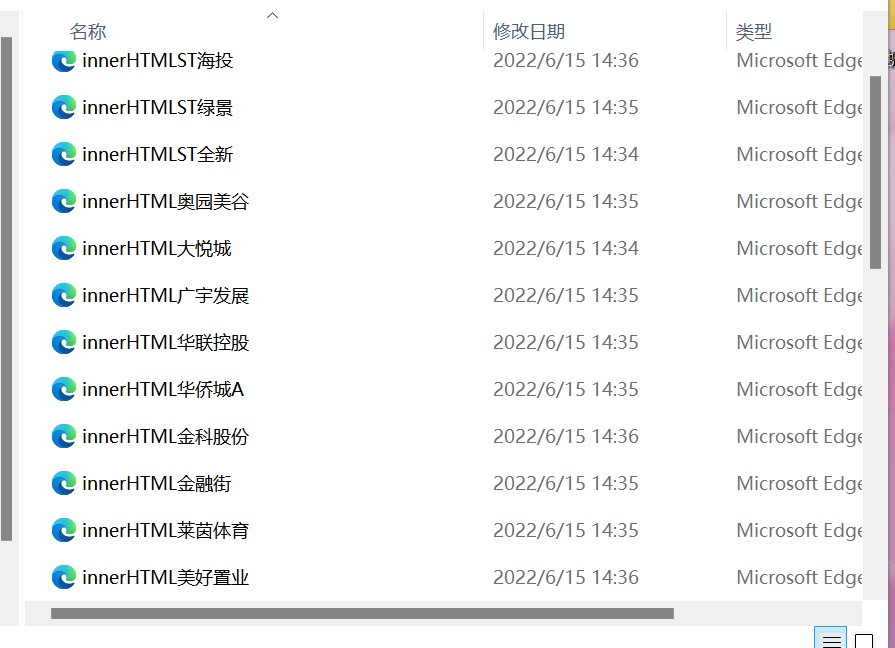
# 将在深圳证券交易所搜索的代码定义为函数
browser = webdriver.Edge()
for i in df_com.iloc[:,1]:
# i=df_com.iloc[7,1]
element=shou_suo(i)
time.sleep(3)
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML%s.html'%i,'w',encoding='utf-8')
f.write(innerHTML)
f.close()
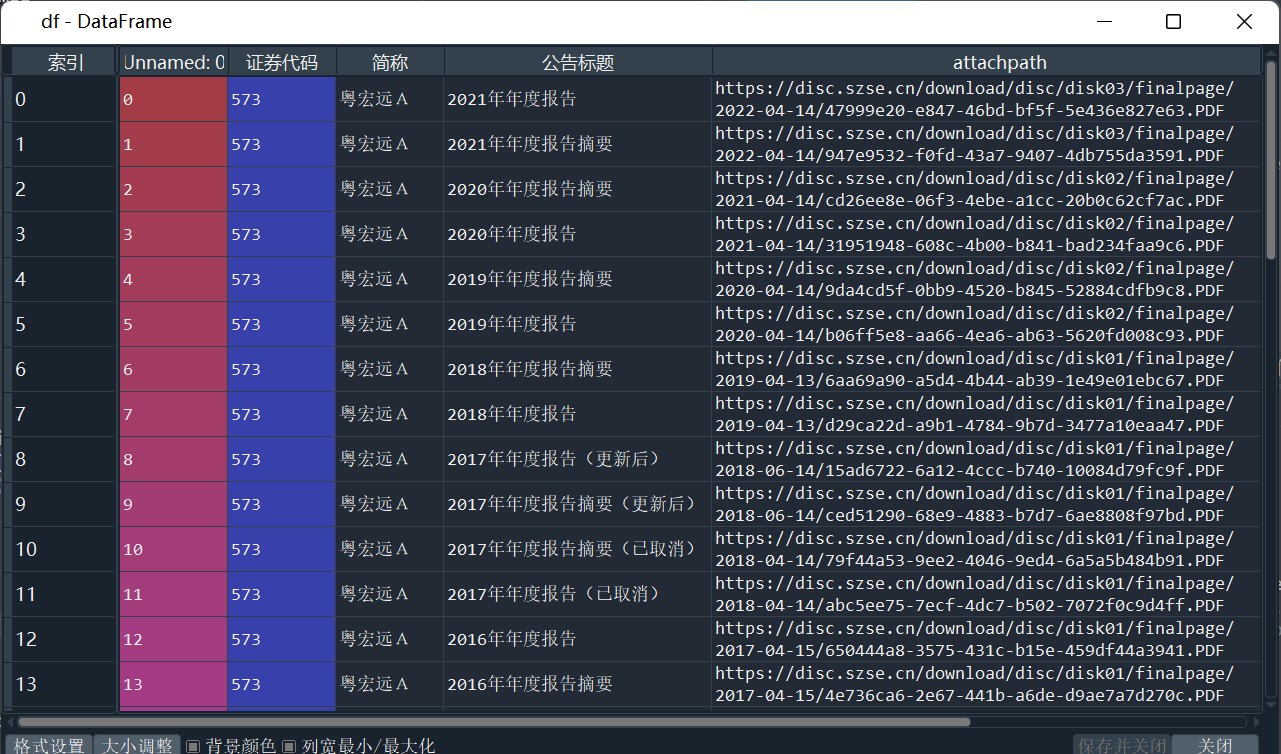
# 一一搜索并保存为对应的html 图2 图3
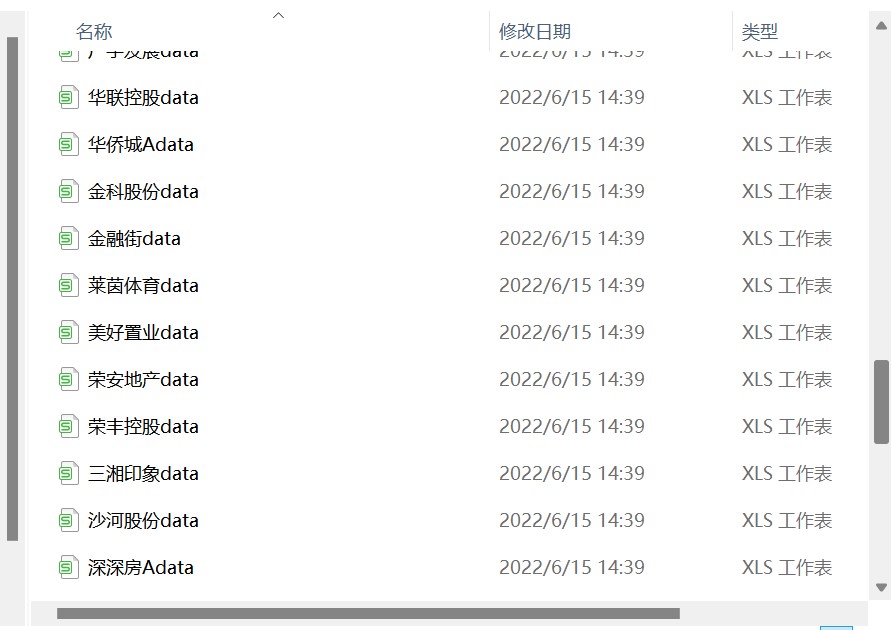
for i in df_com.iloc[:,1]:
f = open('innerHTML%s.html'%i,encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv(i+'data.csv')
# 将对应的html保存为相应的csv文件 图4
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
# 将html中的内容做成表格 图5
import requests
for i in range(17,len(df_com)+1):
# i=3
a=df_com.iloc[i,1]
df=pd.read_csv(a+'data.csv')
# print(i,len(df))
for l in range(len(df)):
# print(l)
# l=0
href =df.iloc[l,4]
#l=str(l)
r = requests.get(href, allow_redirects=True)
f = open('%s%s.pdf'%(df.iloc[l,2],df.iloc[l,3]),'wb')
# f = open('%s%s.pdf'%(a,l),'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(3)
# 将所得的表格对应的网址中的报告(pdf)一一下载 图6

import os
files=os.listdir()
pdf = [f for f in files if f.endswith('.pdf')]
for i in range(len(pdf)):
report1=getText(pdf[i])
if '年度报告摘要' in report1:
os.remove(pdf[i])
if '已取消' in report1:
os.remove(pdf[i])
elif '年度报告' not in report1:
os.remove(pdf[i])
# 删除多余文件,整理文件名 图7
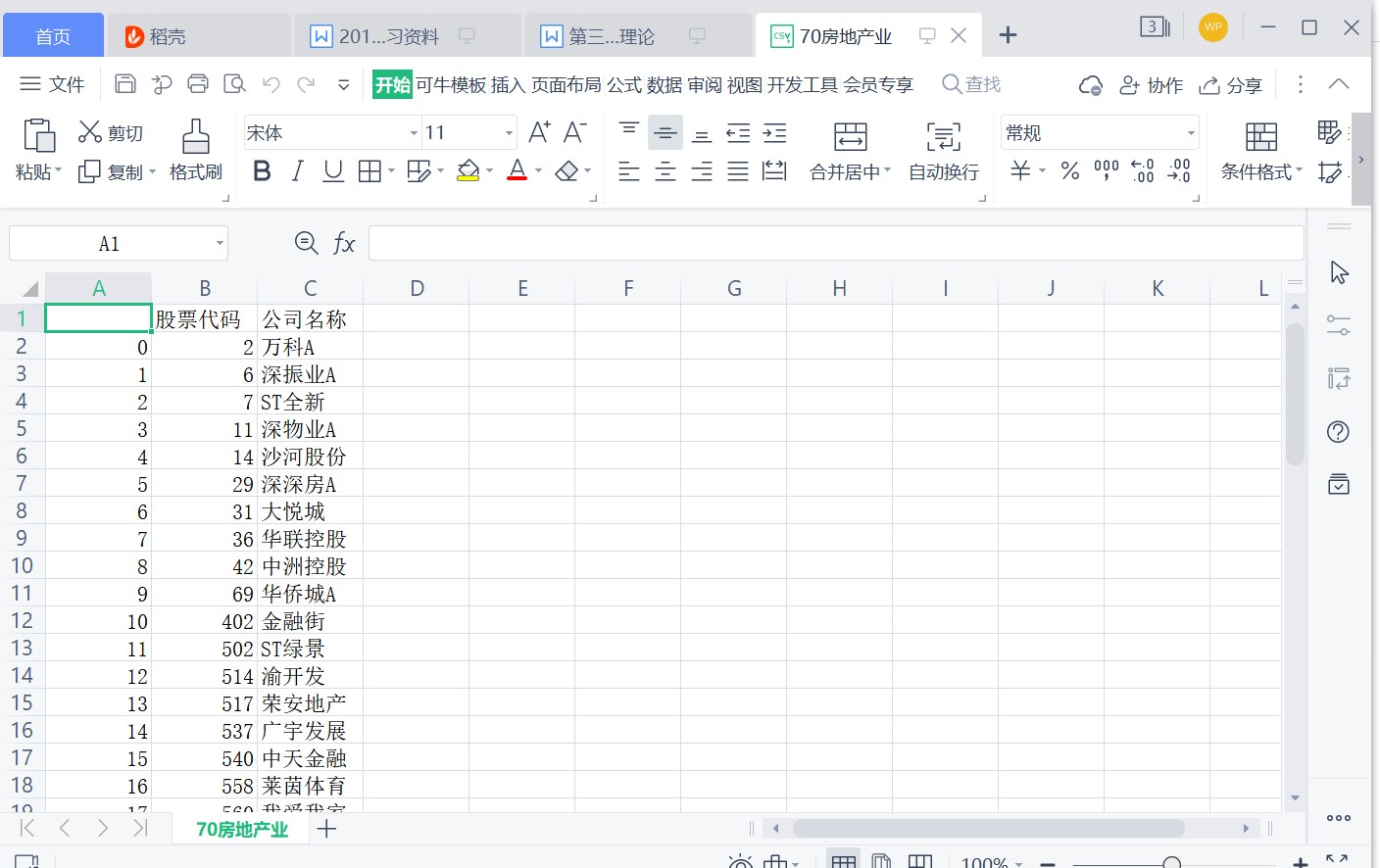
files=os.listdir(r'C:\Users\兰芝蓝\Desktop\测试')
df_com=pd.read_csv('70房地产业.csv')
# 保存为csv文件 图8
def parse_data_line(pdf):
text = getText(pdf)
p1 = re.compile('\w{1,2}、主要会计数据和财务指标(.*?)(?=\w{1,2}、)',re.DOTALL)
subtext = p1.search(text)
if subtext is None:
p1 = re.compile('(\w{1,2})\s*主要会计数据(.*?)(?=(\w{1,2})\s*主要财务指标)',re.DOTALL)
subtext = p1.search(text).group(0)
else:
subtext = p1.search(text).group(0)
subp='([0-9,.%\- ]*?)\n' and '([0-9,.%\- ]*?)\s'
psub='%s%s%s%s'%(subp,subp,subp,subp)
p=re.compile('(\D+\n)+%s'%psub)
lines=p.findall(subtext)
return(lines)
# 寻找“主要会计数据和财务指标”所在的页码并记录内容将其定义为函数
def get_basic(pdf):
# pdf=list_rp[22]
text = getText(pdf)
p1 = re.compile('\w{1,2}、公司信息(.*?)(?=\w{1,2}、联系人)',re.DOTALL)
subtext = p1.findall(text)
if subtext[0] is None:
p1 = re.compile('\w{1,2}、\s+公司信息(.*?)(?=\w{1,2}、联系人)',re.DOTALL)
subtext = p1.findall(text)
# subtext.remove('')
subtext=subtext[0].replace('\n','')
p2=re.compile('(?<=股票简称)(.*?)(?=股票代码)')
co_name=p2.findall(subtext)
p3=re.compile('(?<=股票代码)(.*?)(?=股票)')
code=p3.findall(subtext)
p4=re.compile('(?<=办公地址)(.*?)(?=办公地址的)')
ad=p4.findall(subtext)
p5=re.compile('(?<=公司网址)(.*?)(?=电子信箱)')
web=p5.findall(subtext)
return co_name,code,ad,web
# 寻找“公司信息”所在的页码记录内容,提取其中的“股票简称”“股票代码”“办公地址”“公司网址”将其定义为函数
list_rp=[c for c in files if c.endswith('.pdf') and '年度报告' in c and '2021'in c]
# 将所有公司2021年的PDF挑选出来保存为列表
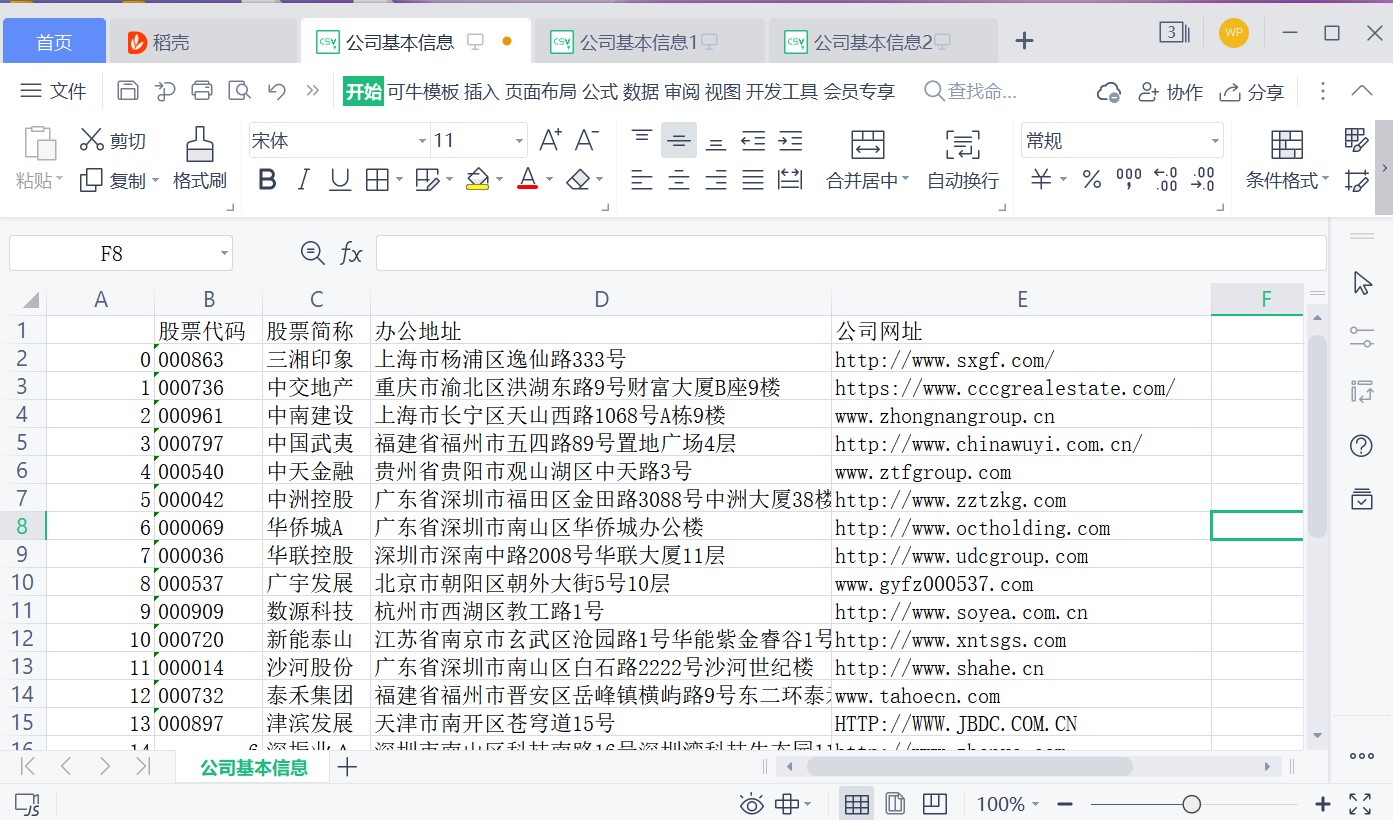
df3=pd.DataFrame(index=range(len(df_com)))
df3['股票简称']=''
df3['股票代码']=''
df3['办公地址']=''
df3['公司网址']=''
df3.to_csv('公司基本信息.csv')
# 将“股票简称”“股票代码”“办公地址”“公司网址”列为标题并保存为“公司基本信息”名称的csv文件
for i in range(len(list_rp)):
list3=get_basic(list_rp[i])
for l in range(4):
while ' ' in list3[l][0]:
list3[l][0]=list3[l][0].replace(' ','')
df3['股票简称'][[i]]=list3[0][0]
df3['股票代码'][[i]]=list3[1][0]
df3['办公地址'][[i]]=list3[2][0]
df3['公司网址'][[i]]=list3[3][0]
df3.to_csv('公司基本信息.csv')
# 从2021年的年报中解析出公司的“股票简称”“股票代码”“办公地址”“公司网址”并保存为“公司基本信息”名称的csv文件 图9
df3['营业收入(元)']=''
df3['基本每股收益(元/股)']=''
for i in range(3,len(list_rp)):
# i=22
pdf=list_rp[i]
lines=parse_data_line(pdf)
if '营业收入' in lines[0][0]:
income=[l for l in lines[0]]
elif '营业收入' in lines[1][0]:
income=[l for l in lines[1]]
elif '营业收入' in lines[2][0]:
income=[l for l in lines[2]]
while '' in income:
income.remove('')
while ',' in income[1]:
income[1].replace(',','')
df3['营业收入(元)'][[i]]=eval(income[1])
if '基本每股收益' in lines[4][0]:
eps=[l for l in lines[4]]
if '基本每股收益' in lines[5][0]:
eps=[l for l in lines[5]]
elif '基本每股收益' in lines[6][0]:
eps=[l for l in lines[6]]
while '' in eps:
eps.remove('')
df3['基本每股收益(元/股)'][[i]]=eval(eps[1])
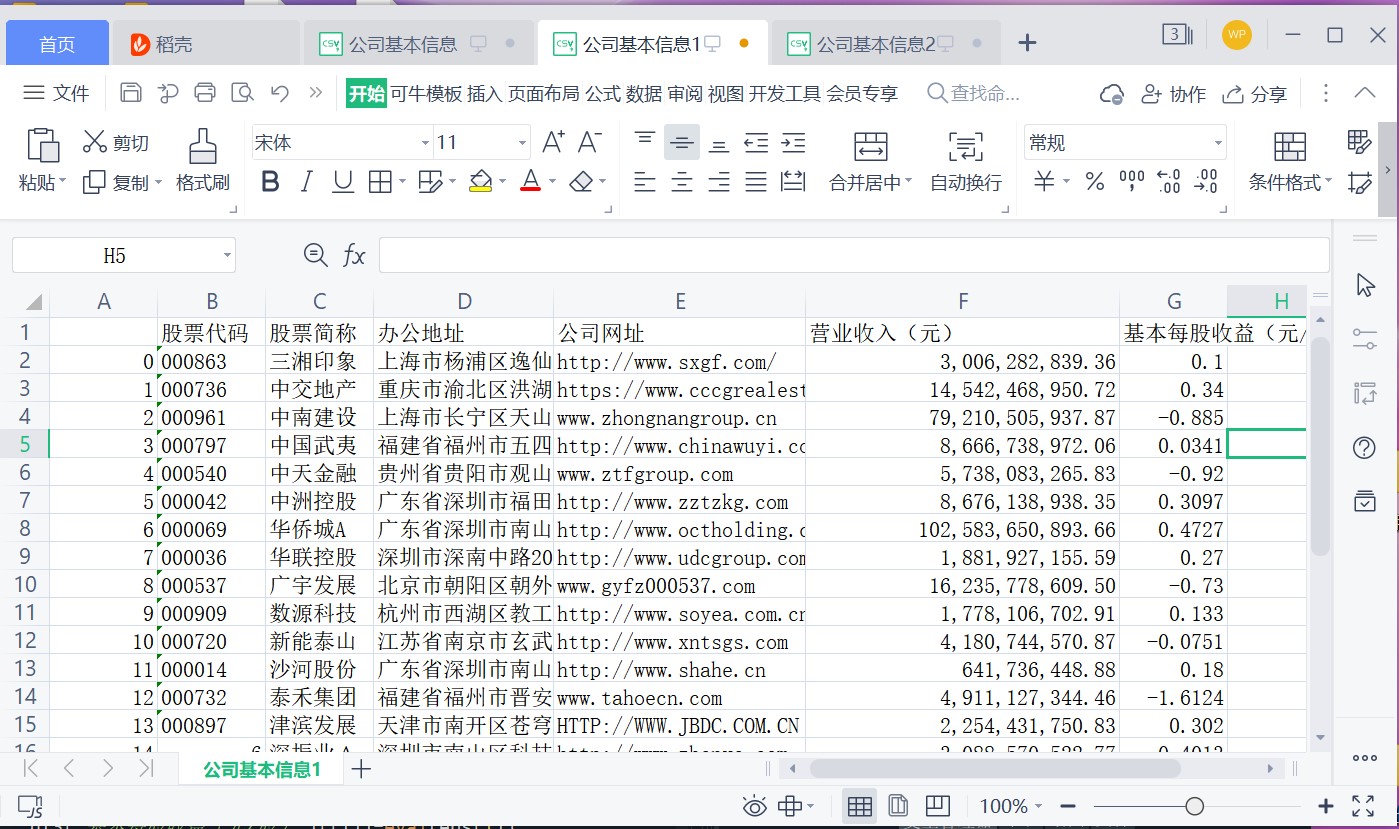
df3.to_csv('公司基本信息1.csv')
# 从2021年的年报中解析出公司的“营业收入(元)”“基本每股收益(元/股)”并保存为“公司基本信息1”名称的csv文件 图10
df4=df3.sort_values(by='营业收入(元)',ascending=False)
df4=df4.reset_index()
df4=df4.drop('index',axis=1)
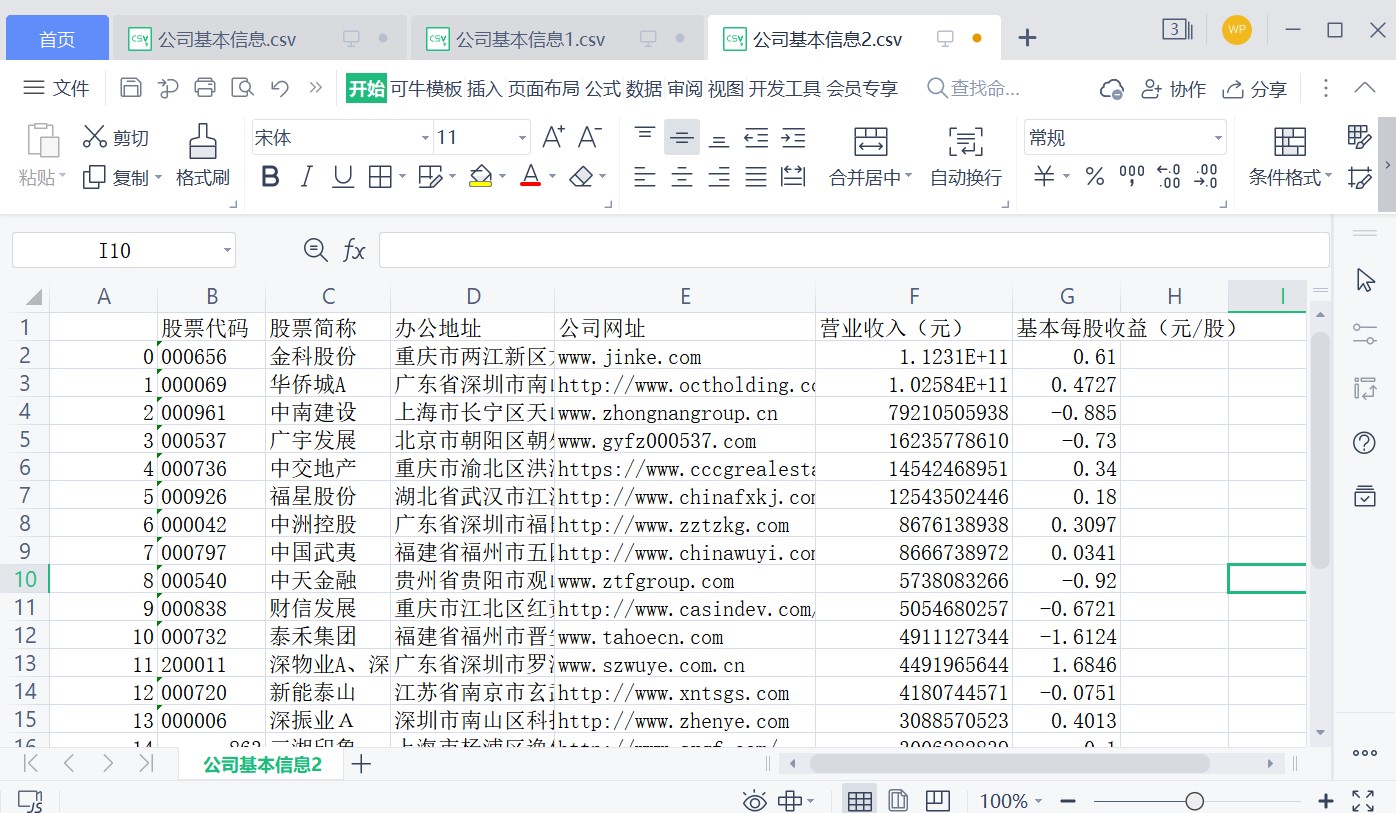
df4.to_csv('公司基本信息2.csv')
df4=pd.read_csv('公司基本信息2.csv')
# 以公司基本信息1中的“营业收入(元)”排序并保存为“公司基本信息2”名称的csv文件 图11
df5=df4.iloc[:10,:]
# 取“营业收入(元)”前十名的公司
files=os.listdir(r'C:\Users\兰芝蓝\Desktop\测试')
list_co=[d for d in df5['股票简称']]
list_rp=[f for f in files if f.endswith('.pdf') and f[:4] in list_co and '年度报告' in f]
for c in list_co:
# c=list_co[0]
list_1=[f for f in list_rp if c in f]
df6=pd.DataFrame(columns=['年份','营业收入(元)','基本每股收益(元/股)'],index=range(len(list_1)))
for i in range(len(list_1)):
# i=3
y=list_1[i]
# y[-10]
if y[-10]=='年':
year=y[-14:-9]
else:
year=y[-13:-8]
df6['年份'][[i]]=year
lines=parse_data_line(y)
if '营业收入' in lines[0][0]:
income=[l for l in lines[0]]
elif '营业收入' in lines[1][0]:
income=[l for l in lines[1]]
elif '营业收入' in lines[2][0]:
income=[l for l in lines[2]]
while '' in income:
income.remove('')
while ',' in income[1]:
income[1]=income[1].replace(',','')
# while ',' in income[1]:
# income[1]=income[1].replace(',','')
df6['营业收入(元)'][[i]]=eval(income[1])
if '基本每股收益' in lines[4][0]:
eps=[l for l in lines[4]]
if '基本每股收益' in lines[5][0]:
eps=[l for l in lines[5]]
elif '基本每股收益' in lines[6][0]:
eps=[l for l in lines[6]]
elif '基本每股收益' in lines[7][0]:
eps=[l for l in lines[7]]
while '' in eps:
eps.remove('')
df6['基本每股收益(元/股)'][[i]]=eval(eps[1])
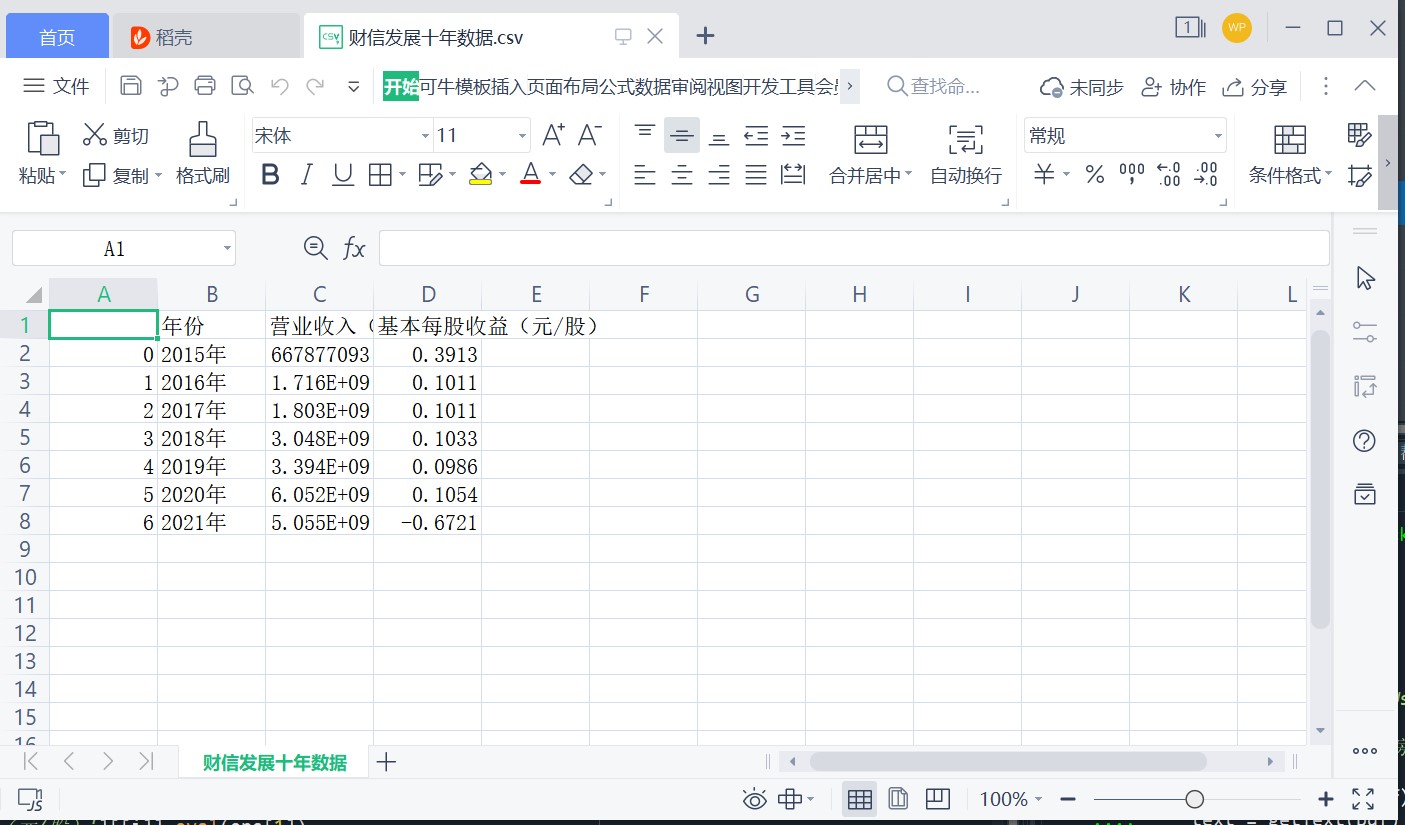
df6.to_csv('%s十年数据.csv'%c)
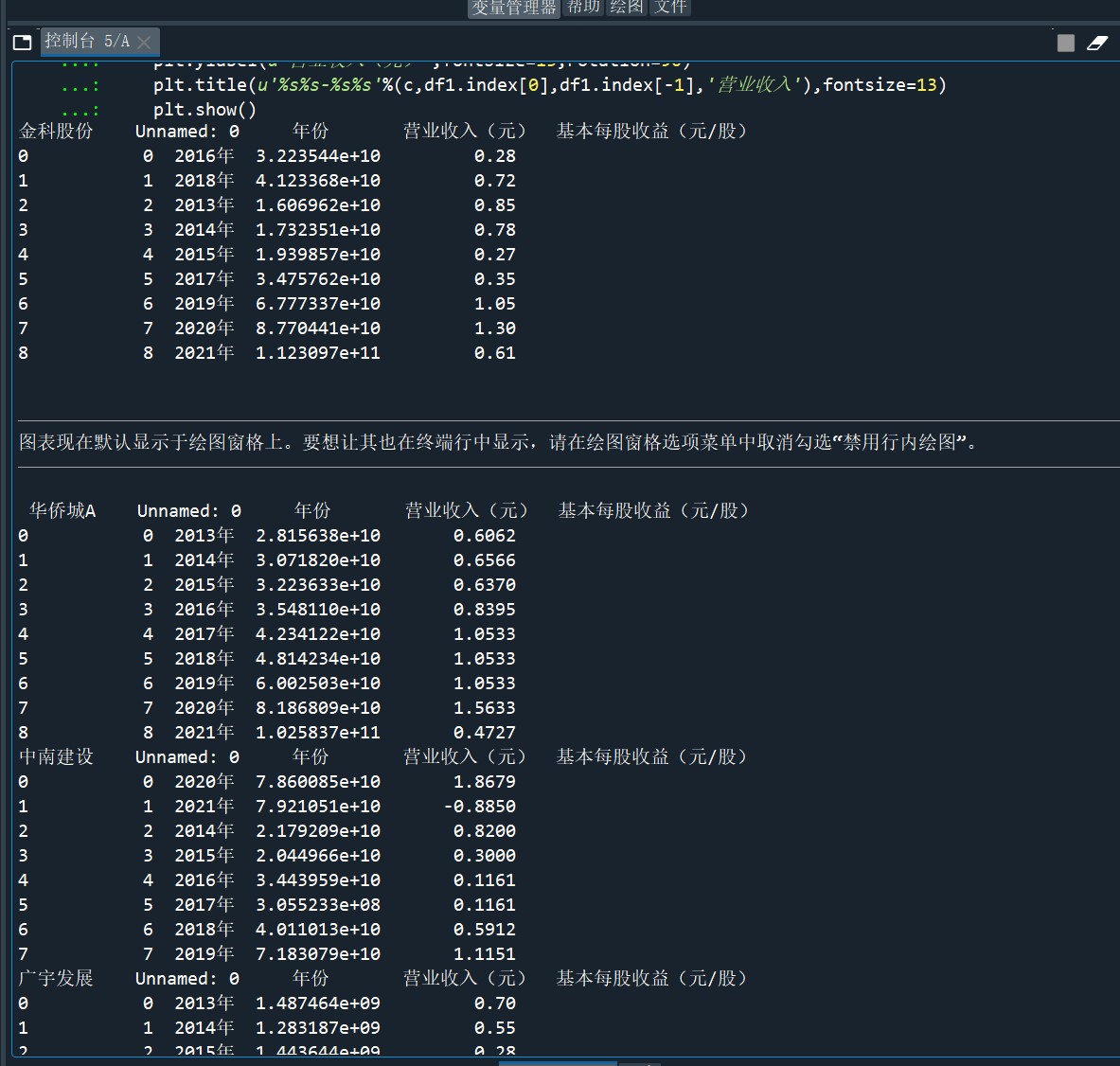
print(df6)
# 解析PDF提取前十名公司每一年的“营业收入(元)”“基本每股收益(元/股)”并保存为csv文件 图12 图13
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 确保显示中文,确保显示负数的参数设置
df4=pd.read_csv('公司基本信息2.csv')
list_co=[d for d in df4['股票简称']]
list_co=list_co[:10]
for c in list_co:
df_data=pd.read_csv('%s十年数据.csv'%c)
print(c,df_data)
df1=df_data.sort_values(by='年份')
df1=df1.set_index('年份')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
plt.plot(df1.index,df1['营业收入(元)'],label=u'年营业收入',color='r')
plt.xlabel(u'(年)',fontsize=13)
plt.ylabel(u'营业收入(元)',fontsize=13,rotation=90)
plt.title(u'%s%s-%s%s'%(c,df1.index[0],df1.index[-1],'营业收入'),fontsize=13)
plt.savefig(u'%s%s-%s%s'%(c,df1.index[0],df1.index[-1],'营业收入'))
plt.show()
# 用每一个公司的十年的“营业收入”绘图,并保存 图14 图15
plt.figure()
plt.plot(df1.index,df1['基本每股收益(元/股)'],label=u'基本每股收益',color='blue')
plt.xlabel(u'(年)',fontsize=13)
plt.ylabel(u'(元/股)',fontsize=13,rotation=90)
plt.title(u'%s%s-%s%s'%(c,df1.index[0],df1.index[-1],'基本每股收益'),fontsize=13)
plt.savefig(u'%s%s-%s%s'%(c,df1.index[0],df1.index[-1],'基本每股收益'))
plt.show()
# 用每一个公司的十年的“基本每股收益”绘图,并保存 图16
c=list_co[0]
df_data=pd.read_csv('%s十年数据.csv'%c)
df1=df_data.sort_values(by='年份')
df1=df1.set_index('年份')
year=df1.index
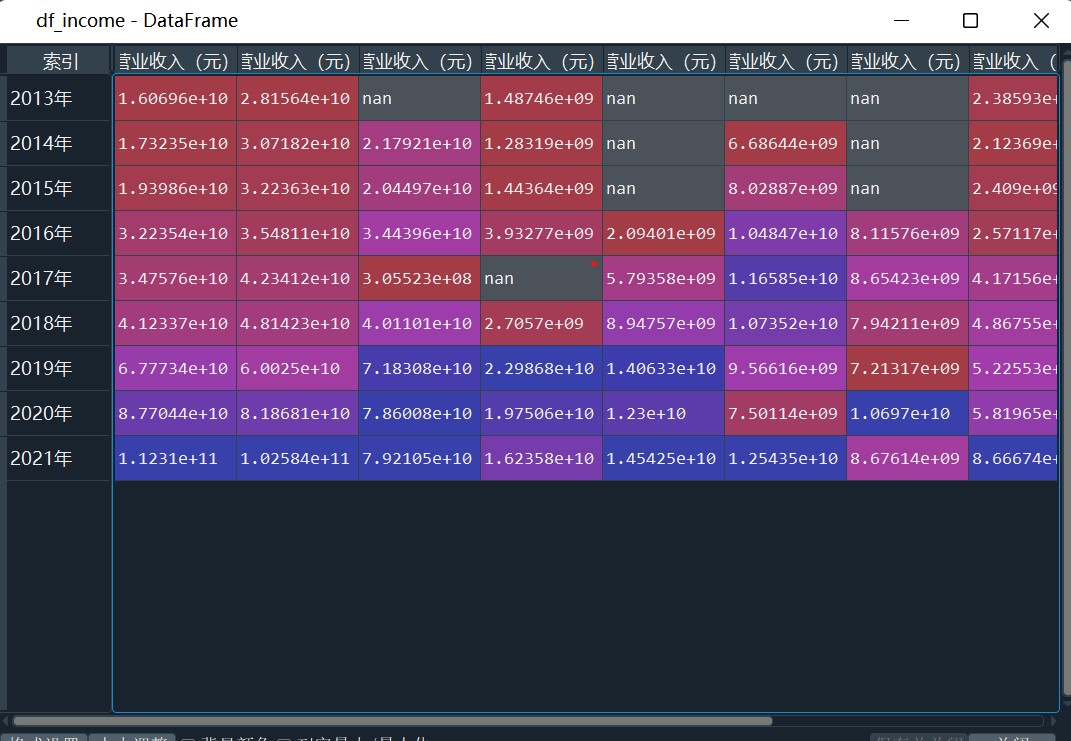
df_income=pd.DataFrame(index=year)
for c in list_co:
df_data=pd.read_csv('%s十年数据.csv'%c)
df1=df_data.sort_values(by='年份')
df1=df1.set_index('年份')
df_income=pd.concat([df_income,df1['营业收入(元)']],axis=1)
df_income.columns=list_co
df_income=df_income.fillna(0)
# 提取同年营业收入 图17
df_eps=pd.DataFrame(index=year)
for c in list_co:
df_data=pd.read_csv('%s十年数据.csv'%c)
df1=df_data.sort_values(by='年份')
df1=df1.set_index('年份')
df_eps=pd.concat([df_eps,df1['基本每股收益(元/股)']],axis=1)
df_eps.columns=list_co
df_eps=df_eps.fillna(0)
# 提取同年EPS 图18

for c in range(10):
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
plt.bar(list_co,df_income.iloc[c,:],label=u'营业收入',color='r')
plt.xlabel(u'公司名称',fontsize=13)
plt.ylabel(u'营业收入(元)',fontsize=13,rotation=90)
plt.title(u'%s%s'%(df_income.index[c],'营业收入'),fontsize=13)
plt.savefig(u'%s%s'%(df_income.index[c],'营业收入'))
plt.show()
# 用每一年各个公司的“营业收入”绘图,并保存 图19
plt.figure()
plt.bar(list_co,df_eps.iloc[c,:],label=u'基本每股收益(元)',color='blue')
plt.xlabel(u'公司名称',fontsize=13)
plt.ylabel(u'基本每股收益(元)',fontsize=13,rotation=90)
plt.title(u'%s%s'%(df_eps.index[c],'基本每股收益'),fontsize=13)
plt.savefig(u'%s%s'%(df_eps.index[c],'基本每股收益'))
plt.show()
# 用每一年各个公司的“基本每股收益”绘图,并保存 图20

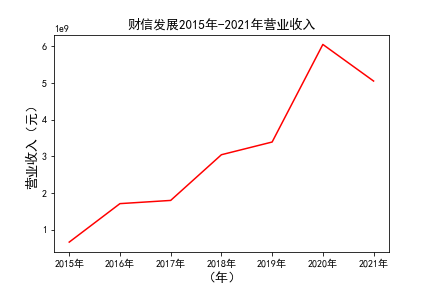
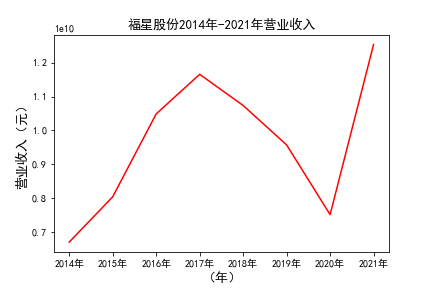
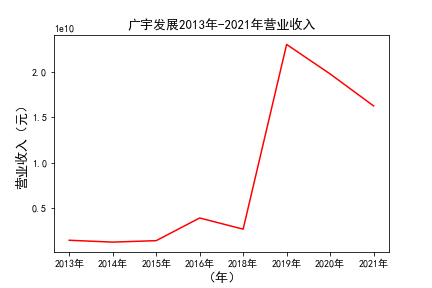
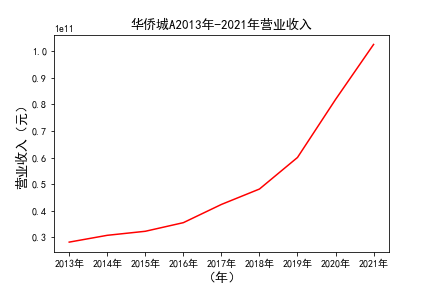
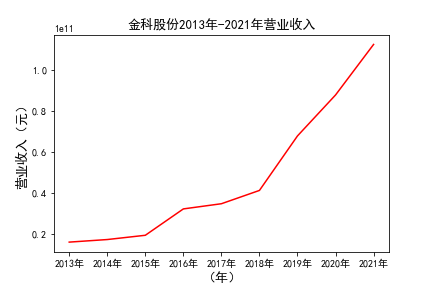
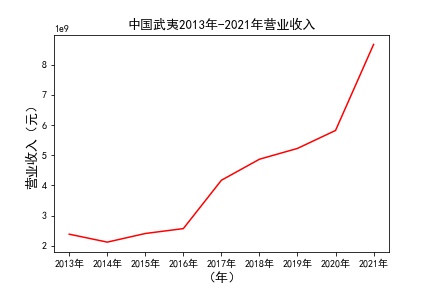
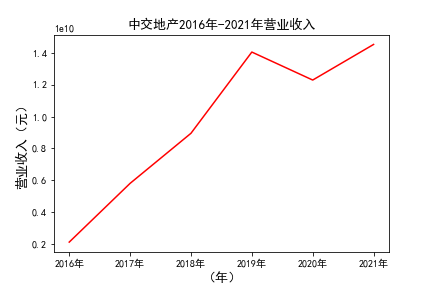
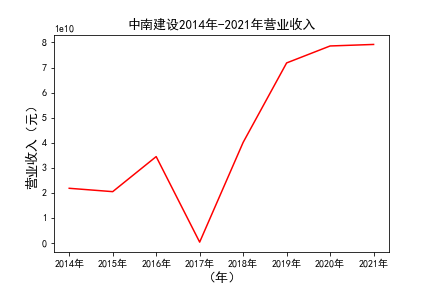
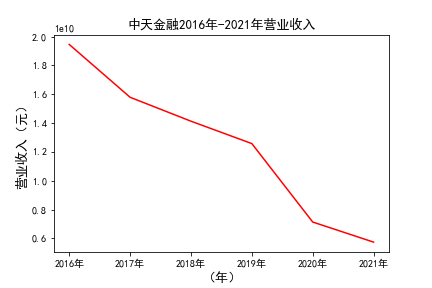
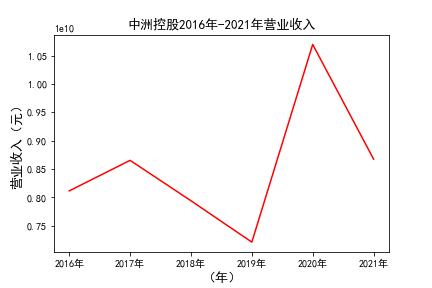
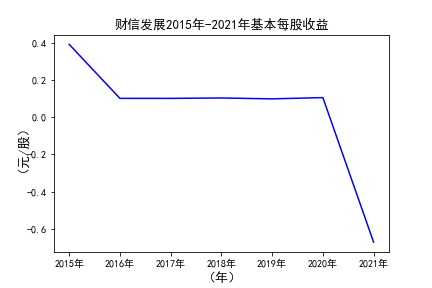
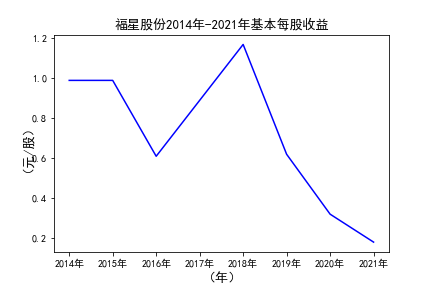
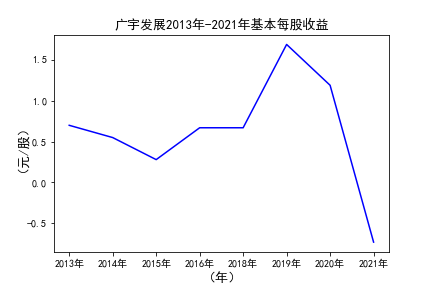

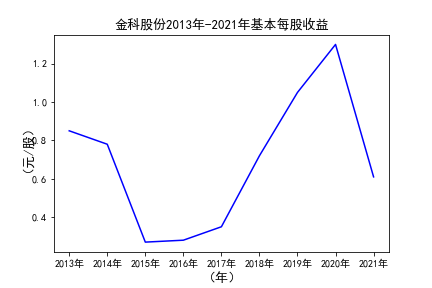
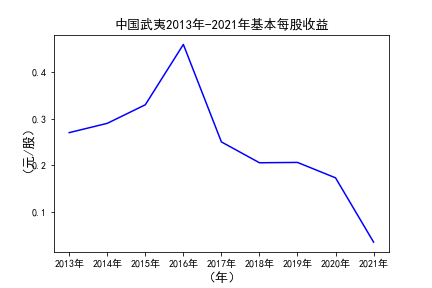
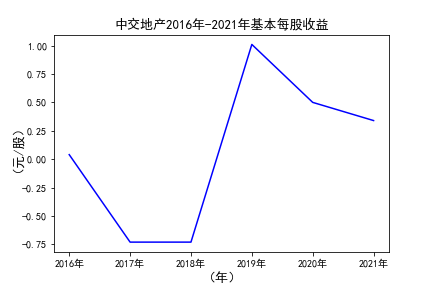
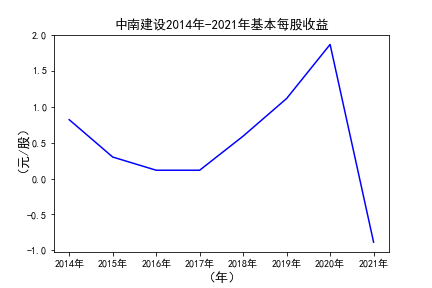
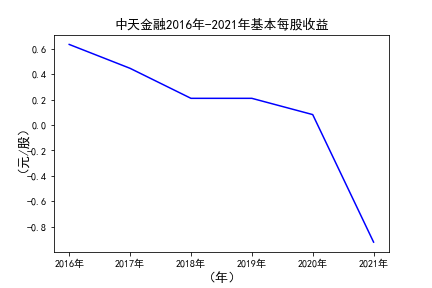
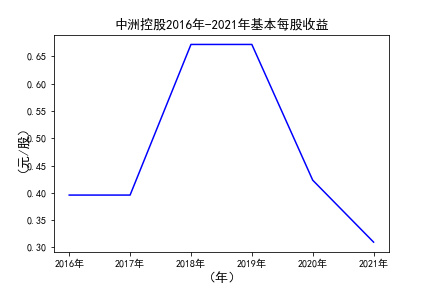
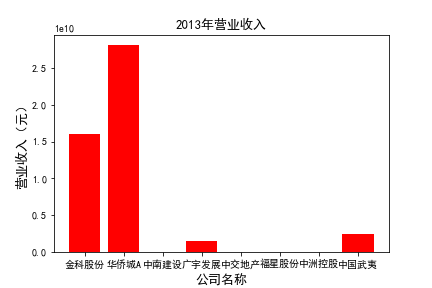
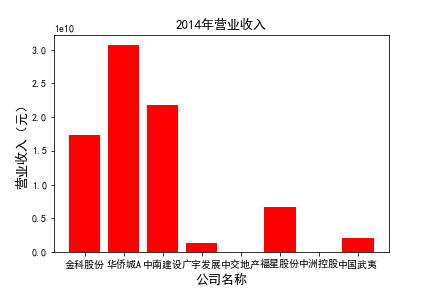
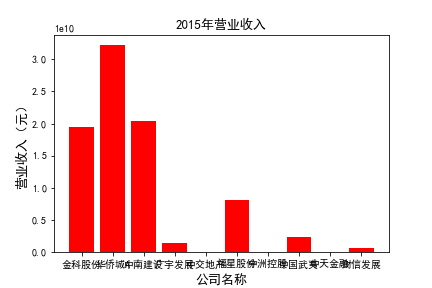
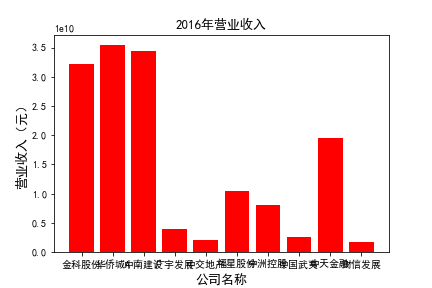
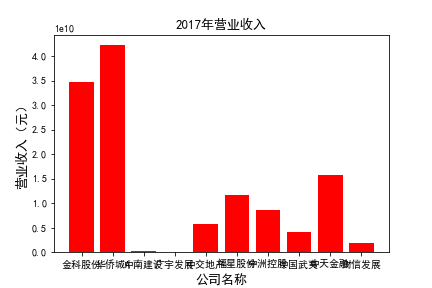
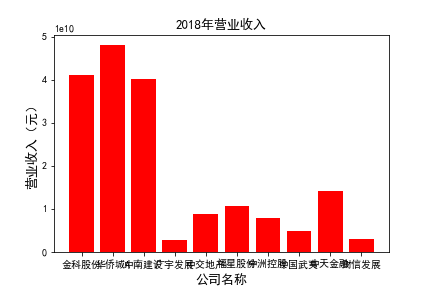
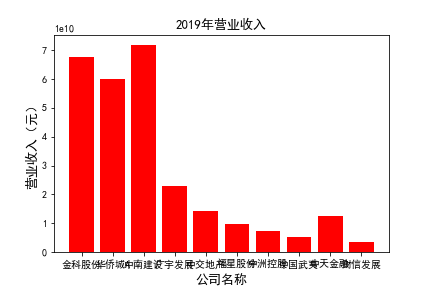
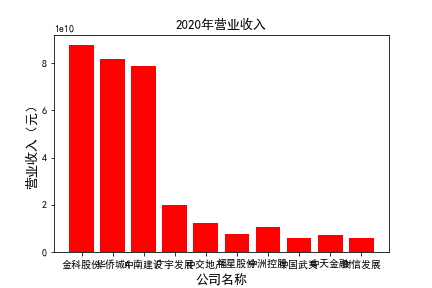
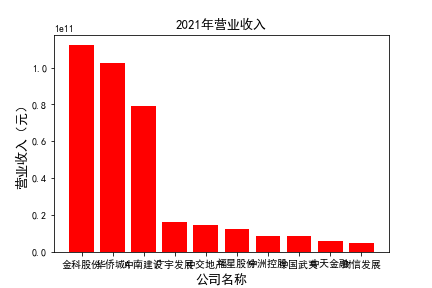
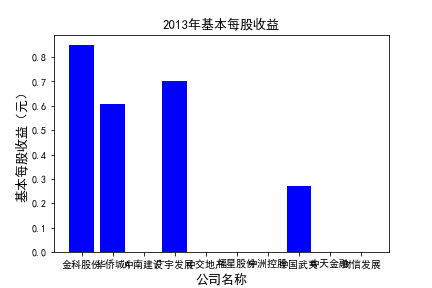
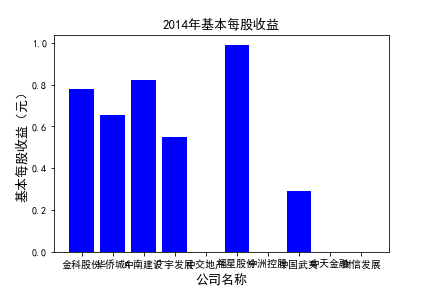
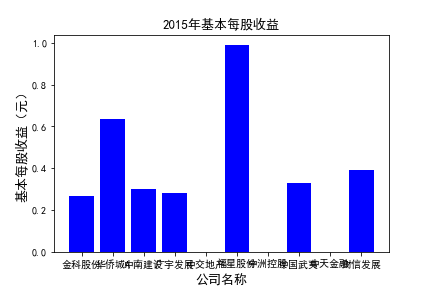
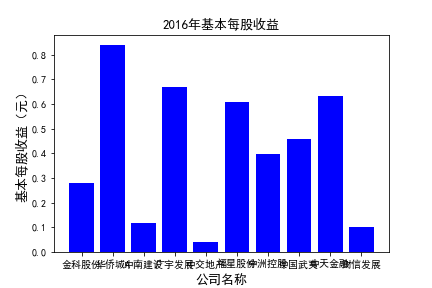

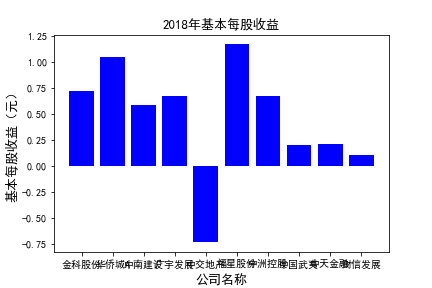
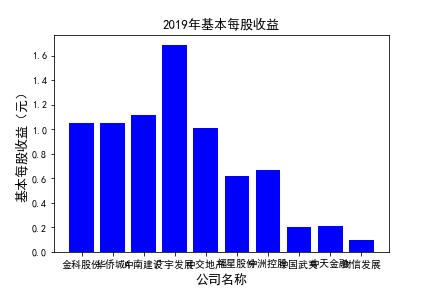
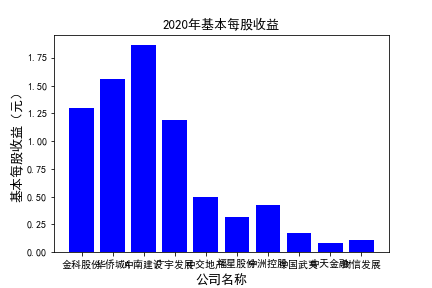
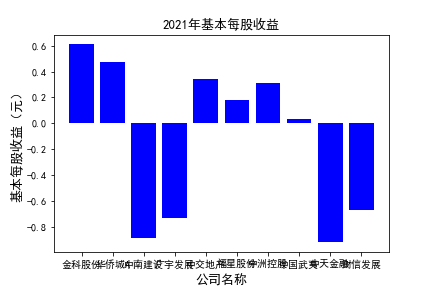
由绘制的图表可得出: