import fitz
import re
import pandas as pd
import numpy as np
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import matplotlib.pyplot as plt
option = webdriver.EdgeOptions()
option.binary_location = "C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
os.chdir(r'C:\Users\史上最强的男人\Desktop\qimozuoye')
from parse_cninfo_table import *
#Step1 提取对应行业股票代码
pdf1 = fitz.open('上市公司行业分类.pdf')
text = ''
for page in pdf1:
text += page.get_text()
p1 = re.compile('\n64\n(.*?)\n65', re.DOTALL)
text_ind = re.findall(p1, text)
p2 = re.compile('.*?\n(\d{6})\n.*?')
code = re.findall(p2, text_ind[0])
#Step2 下载年报
browser = webdriver.Edge(r"C:\Users\史上最强的男人\AppData\Local\Programs\Python\Python37\edgedriver_win64\msedgedriver.exe") #使用Edge浏览器
browser.maximize_window()
def get_cninfo(code): #爬取巨潮网年报信息
browser.get('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&checkedCategory=category_ndbg_szsh')
browser.find_element(By.CSS_SELECTOR, ".el-autocomplete > .el-input--medium > .el-input__inner").send_keys(code)
time.sleep(2.5)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.DOWN)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.ENTER)
time.sleep(2.5)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").click()
time.sleep(0.3)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").clear()
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys("2013-01-01")
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys(Keys.ENTER)
time.sleep(0.3)
browser.find_element(By.CSS_SELECTOR, ".query-btn").click()
time.sleep(2.5)
element = browser.find_element(By.CLASS_NAME, 'el-table__body')
innerHTML = element.get_attribute('innerHTML')
return innerHTML
def html_to_df(innerHTML): #转换为Dataframe
f = open('innerHTML.html','w',encoding='utf-8') #创建html文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
return df
df = pd.DataFrame()
for i in code:
innerHTML = get_cninfo(i)
time.sleep(0.1)
df = df.append(html_to_df(innerHTML))
time.sleep(0.1)
#df.to_csv('list.csv')
#df = pd.read_csv('list.csv')
#df = df.iloc[:,1:]
#df['证券代码'] = df['证券代码'].apply(lambda x:'{:0>6d}'.format(x))
def filter_links(words,df0,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df0['公告标题']])
else:
ls.append([word not in f for f in df0['公告标题']])
index = []
for r in range(len(df0)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df1 = df0[index]
return(df1)
words1 = ["摘要","已取消","英文"]
list = filter_links(words1,df,include=False) #去除摘要和已取消的报告
fun1 = lambda x: re.sub('(?<=报告).*', '', x)
fun2 = lambda x: re.sub('.*(?=\d{4})', '', x)
list['公告标题'] = list['公告标题'].apply(fun1) #去除“20xx年度报告”前后内容
list['公告标题'] = list['公告标题'].apply(fun2)
#exception = list[~list['公告标题'].str.contains('年年度报告')]
list = list.drop_duplicates(['证券代码','公告标题'], keep='first') #删去重复值,保留最新一项
list['年份'] = [re.search('\d{4}', title).group() for title in list['公告标题']]
list['公告标题'] = list['简称']+list['公告标题']
os.makedirs('files')
os.chdir(r'C:\Users\史上最强的男人\Desktop\qimozuoye\files')
def get_pdf(r): #构建下载巨潮网报告pdf函数
p_id = re.compile('.*var announcementId = "(.*)";.*var announcementTime = "(.*?)"',re.DOTALL)
contents = r.text
a_id = re.findall(p_id, contents)
new_url = "http://static.cninfo.com.cn/finalpage/" + a_id[0][1] + '/' + a_id[0][0] + ".PDF"
result = requests.get(new_url, allow_redirects=True)
time.sleep(1)
return result
for c in code:
rpts = list[list['证券代码']==c]
for row in range(len(rpts)):
r = requests.get(rpts.iloc[row,3], allow_redirects=True)
time.sleep(0.3)
try:
result = get_pdf(r)
f = open(rpts.iloc[row,2]+'.PDF', 'wb')
f.write(result.content)
f.close()
r.close()
except:
print(rpts.iloc[row,2])
pass
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
p_a = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
p_span = re.compile('\n\s*(.*?)\s*?', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_data(df_txt):
prefix_href = 'http://www.sse.com.cn/'
df = df_txt
ahts = [get_link(td) for td in df['公告标题']]
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['名称']]
#
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
})
return(df)
driver.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
driver.implicitly_wait(10)
driver.set_window_size(1552, 840)
dropdown = driver.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
time.sleep(1)
for i in range(len(sse)):
os.chdir(r'C:\Users\史上最强的男人\Desktop\qimozuoye\files')
code = sse['code'][i]
driver.find_element(By.ID, "inputCode").clear()
driver.find_element(By.ID, "inputCode").send_keys("%s"%code)
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "全部").click()
driver.find_element(By.CSS_SELECTOR, ".js_reportType .btn").click()
driver.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
soup = BeautifulSoup(innerHTML)
html = soup.prettify()
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
#解析出来的trs中含有空格行,按以下方法进行删除
n = len(trs)
for i in range(len(trs)):
if n >= i:
if len(trs[i]) == 5:
del trs[i]
n = len(trs)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'名称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
df_data = get_data(df)
df_data = pd.concat([df_data, df['公告时间']], axis=1)
df_data['公告时间'] = pd.to_datetime(df_data['公告时间'])
df_data['year'] = df_data['公告时间'].dt.year
df_data['year'] = df_data['year'] - 1
name = df_data['简称'][0]
df_data['简称'] = name
#提取营业收入和基本每股收益数据
df_com = pd.read_csv('仓储业.csv',header=0,index_col=0)
for j in df_com['简称']:
com=pd.read_csv(j+'.csv',header=0,index_col=0)
for k in com['f_name']:
p_year = re.compile('\d{4}')
year = p_year.findall(k)
year1 = int(year[0])
if year1>2011:
year_list.append(year1)
doc = fitz.open(k+'.pdf')
for i in range(20):
page = doc[i]
txt =page.get_text()
p_sales = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?',re.DOTALL)
a=p_sales.findall(txt)
if a !=[]:
c=len(a[0])
if c>0:
sales = re.sub(',','',a[0])
sales_list.append(sales)
list2.append(k)
break
for i in range(20):
page = doc[i]
txt =page.get_text()
p_pe = re.compile('(?<=\n)基本每股收益\s?\n?(?:(元/?/?╱?\n?股))?\s?\n?([-\d+,.]*)\s?\n?',re.DOTALL)
b = p_pe.findall(txt)
if b !=[]:
d=len(b[0])
if d>0 and ',' not in b[0]:
pe_list.append(b[0])
list1.append(k)
break
sales_list = [ float(x) for x in sales_list ]
pe_list = [ float(x) for x in pe_list ]
dff=pd.DataFrame({'年份':year_list,
'营业收入(元)':sales_list,
'基本每股收益(元/股)':pe_list})
dff.to_csv(j+'data.csv',encoding='utf-8-sig')
year_list=[]
sales_list=[]
pe_list=[]
add_list=[]
web_list=[]
for i in df_com['简称']:
doc = fitz.open(i+'2021年年度报告.pdf')
for j in range(15):
page = doc[j]
txt = page.get_text()
p_add = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
com_add=p_add.findall(txt)
if com_add !=[]:
n = len(com_add[0])
if n >1:
add_list.append(com_add[0])
break
for i in df_com['简称']:
doc = fitz.open(i+'2021年年度报告.pdf')
for j in range(15):
page = doc[j]
txt = page.get_text()
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-z-A-Z./:\d+]*)\s?(?=\n)',re.DOTALL)
com_web=p_web.findall(txt)
if com_web !=[]:
n = len(com_web[0])
if n >1:
web_list.append(com_web[0])
list1.append(i)
break
df_com['办公地址'] = add_list
df_com['公司网址'] = web_list
df_com.to_csv('公司基本信息表.csv')
#画图
df_sale = pd.DataFrame()
for j in df_com['简称']:
df = pd.read_csv(j+'data.csv',index_col=1,header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed',case=False)],axis=1)
df_sales = pd.DataFrame(df['营业收入(元)'])
df_sales = df_sales.rename(columns={'营业收入(元)':j})
df_sale = pd.concat([df_sale,df_sales],axis=1)
df_eps = pd.DataFrame()
for j in df_com['简称']:
df = pd.read_csv(j+'data.csv',index_col=1,header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed',case=False)],axis=1)
df_epss = pd.DataFrame(df['基本每股收益(元/股)'])
df_epss = df_epss.rename(columns={'基本每股收益(元/股)':j})
df_eps = pd.concat([df_eps,df_epss],axis=1)
from matplotlib import pyplot as plt
plt.plot(df_sale,marker='*')
plt.legend(df_sale.columns)
plt.title('行业上市公司营业收入时间序列图')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.grid()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.plot(df_eps,marker='*')
plt.legend(df_eps.columns)
plt.title('行业上市公司基本每股收益时间序列图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid()
import numpy as np
from matplotlib import pyplot as plt
bar_width = 0.15
bar_1 = np.arange(len(df_sale.index))
plt.bar(bar_1-2*bar_width, df_sale.iloc[:,0], width=bar_width, label=df_sale.columns[0])
plt.bar(bar_1-bar_width, df_sale.iloc[:,1], width=bar_width, label=df_sale.columns[1])
plt.bar(bar_1, df_sale.iloc[:,2], width=bar_width, label=df_sale.columns[2])
plt.bar(bar_1+bar_width, df_sale.iloc[:,3], width=bar_width, label=df_sale.columns[3])
plt.bar(bar_1+2*bar_width, df_sale.iloc[:,4], width=bar_width, label=df_sale.columns[4])
plt.xticks(bar_1, labels=df_sale.index)
plt.title('行业上市公司营业收入对比时间序列图')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.grid()
plt.legend()
bar_1 = np.arange(len(df_eps.index))
bar_width = 0.15
plt.bar(bar_1-2*bar_width, df_eps.iloc[:,0], width=bar_width, label=df_eps.columns[0])
plt.bar(bar_1-bar_width, df_eps.iloc[:,1], width=bar_width, label=df_eps.columns[1])
plt.bar(bar_1, df_eps.iloc[:,2], width=bar_width, label=df_eps.columns[2])
plt.bar(bar_1+bar_width, df_eps.iloc[:,3], width=bar_width, label=df_eps.columns[3])
plt.bar(bar_1+2*bar_width, df_eps.iloc[:,4], width=bar_width, label=df_eps.columns[4])
plt.xticks(bar_1, labels=df_eps.index)
plt.title('行业上市公司基本每股收益对比时间序列图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid()
plt.legend()
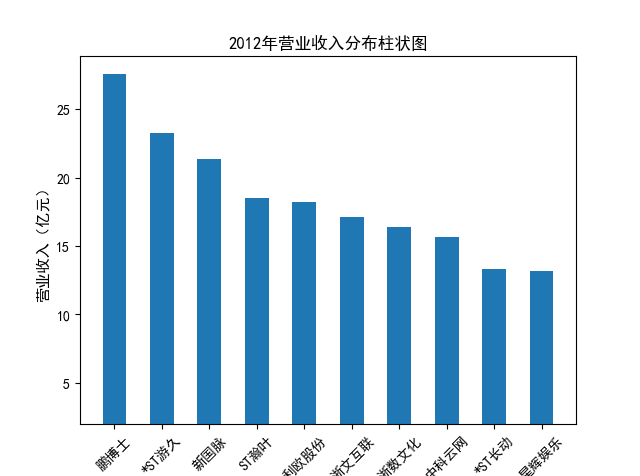
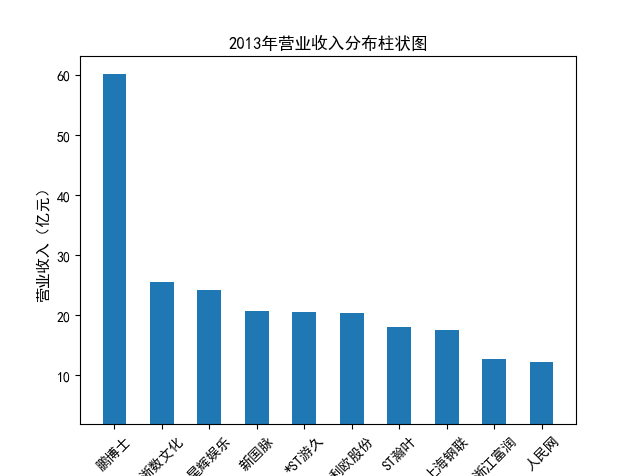
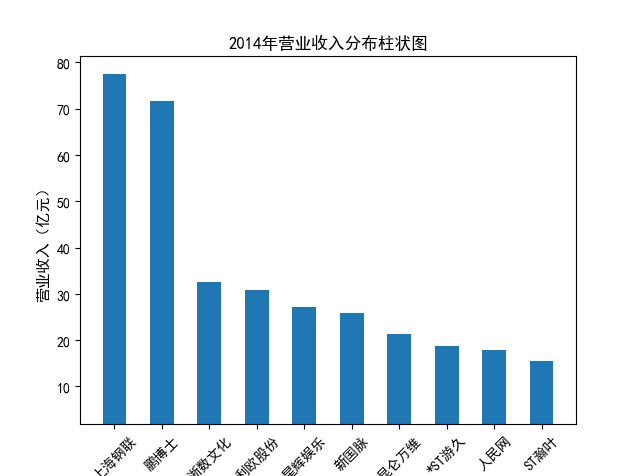
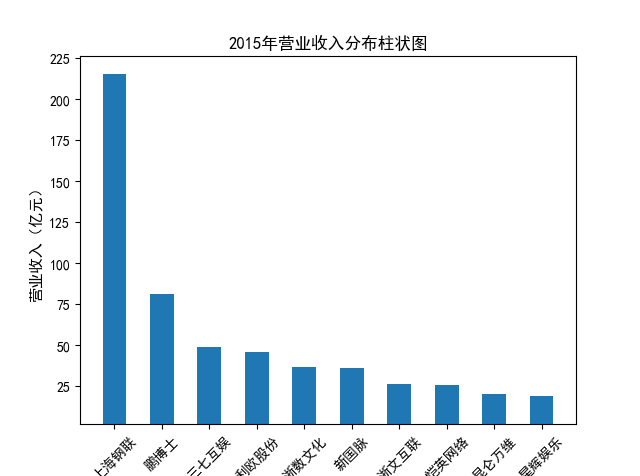
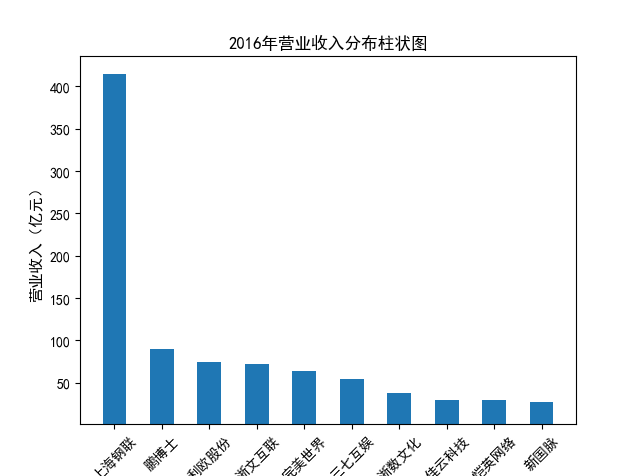
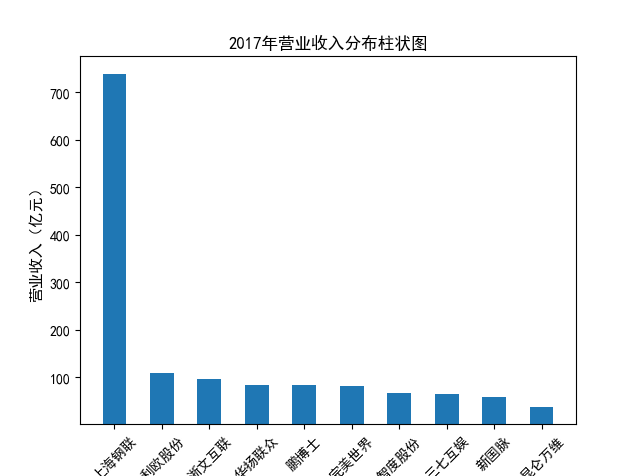
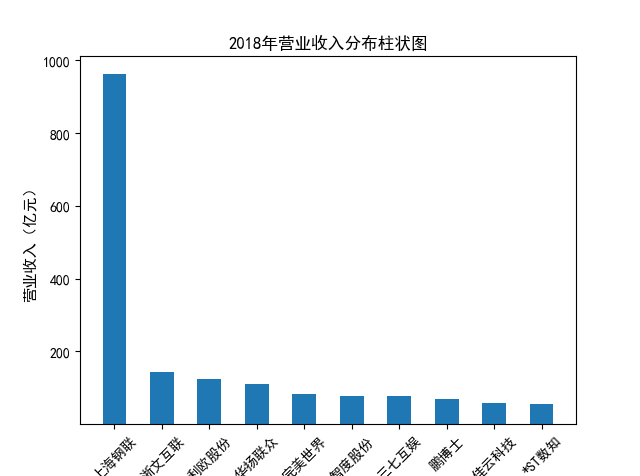
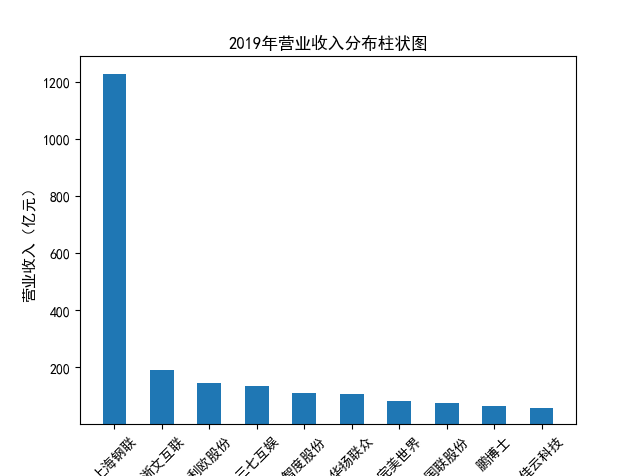
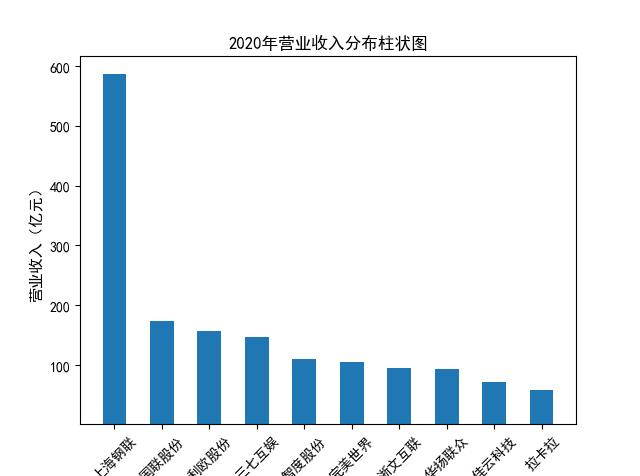
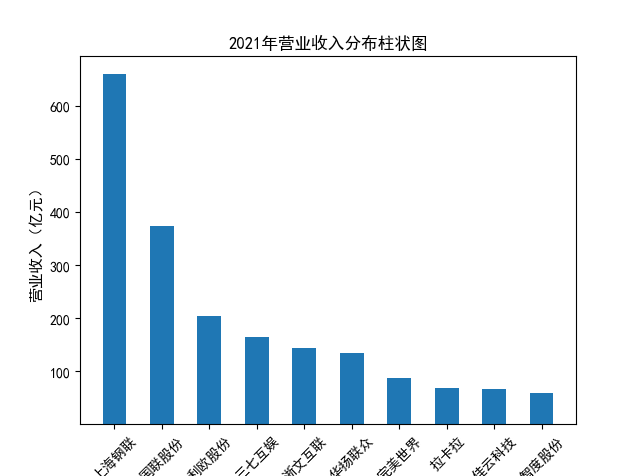
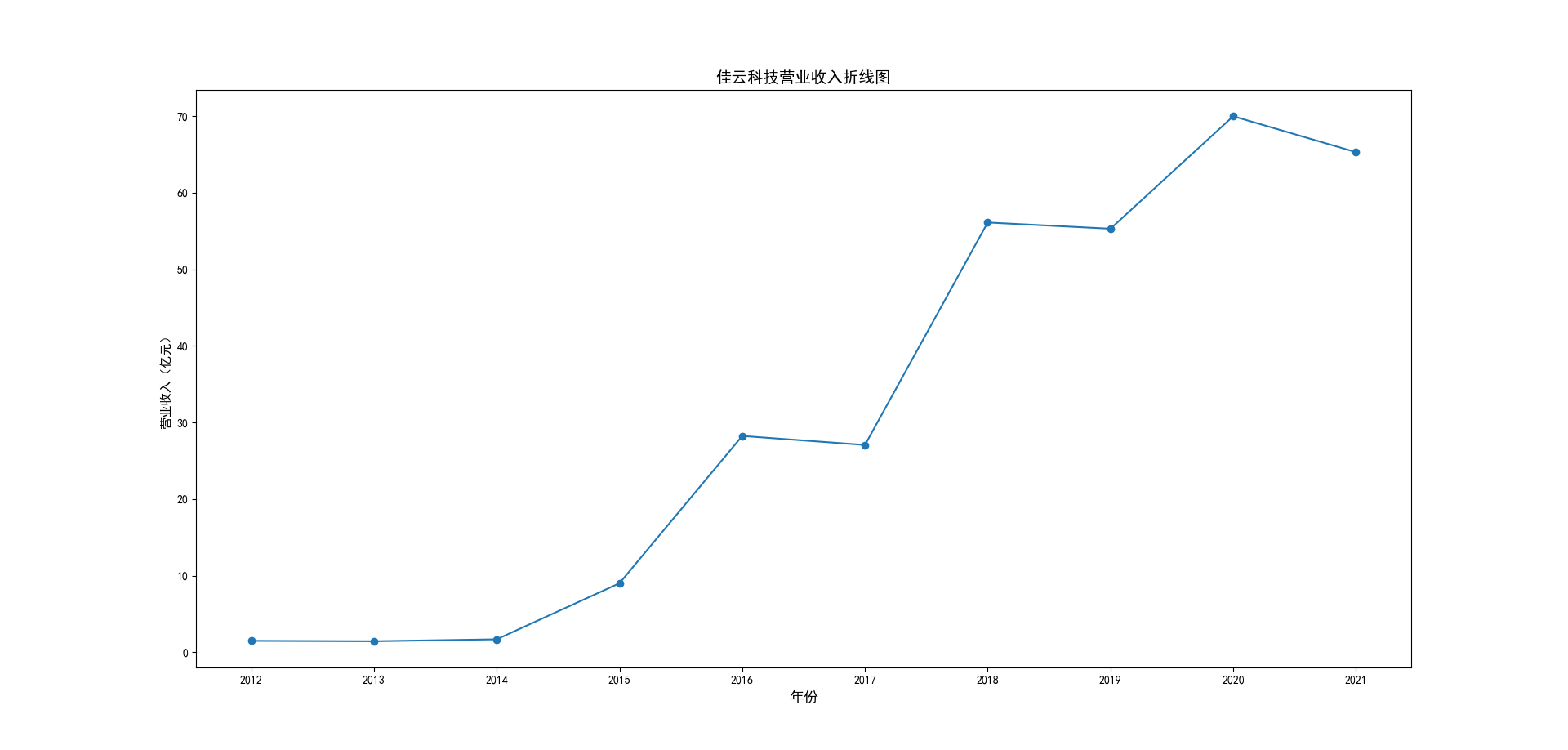
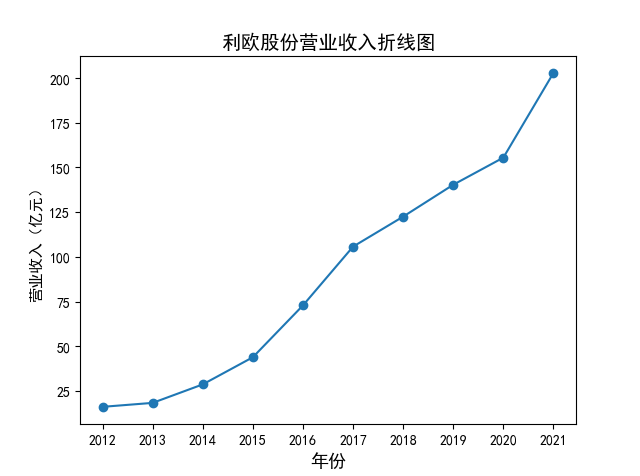
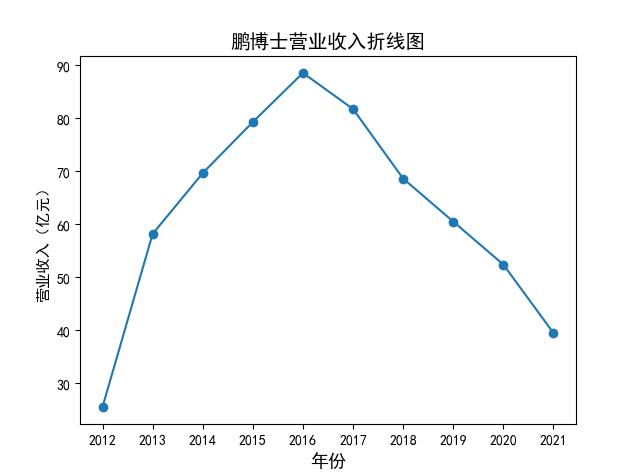

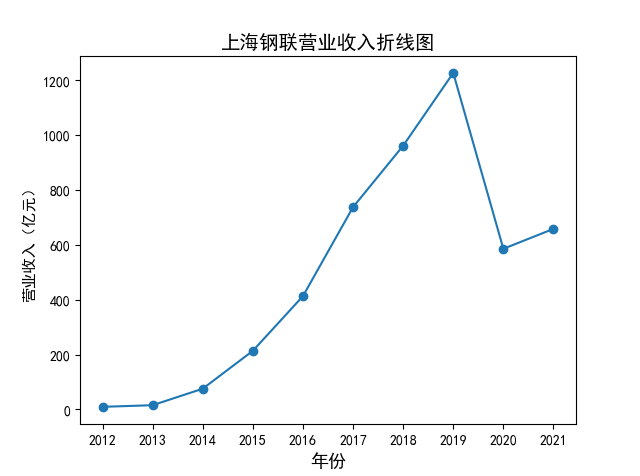
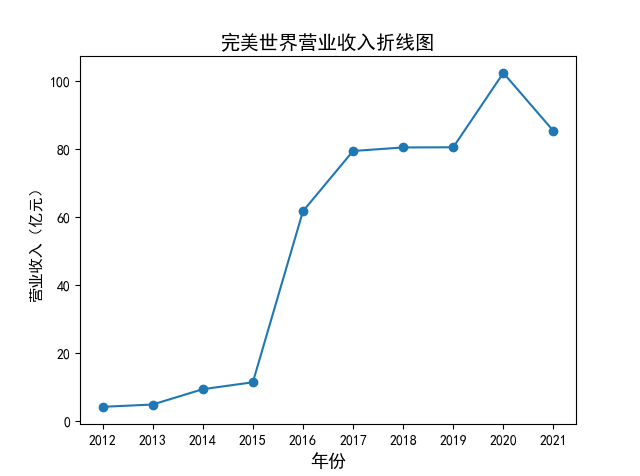
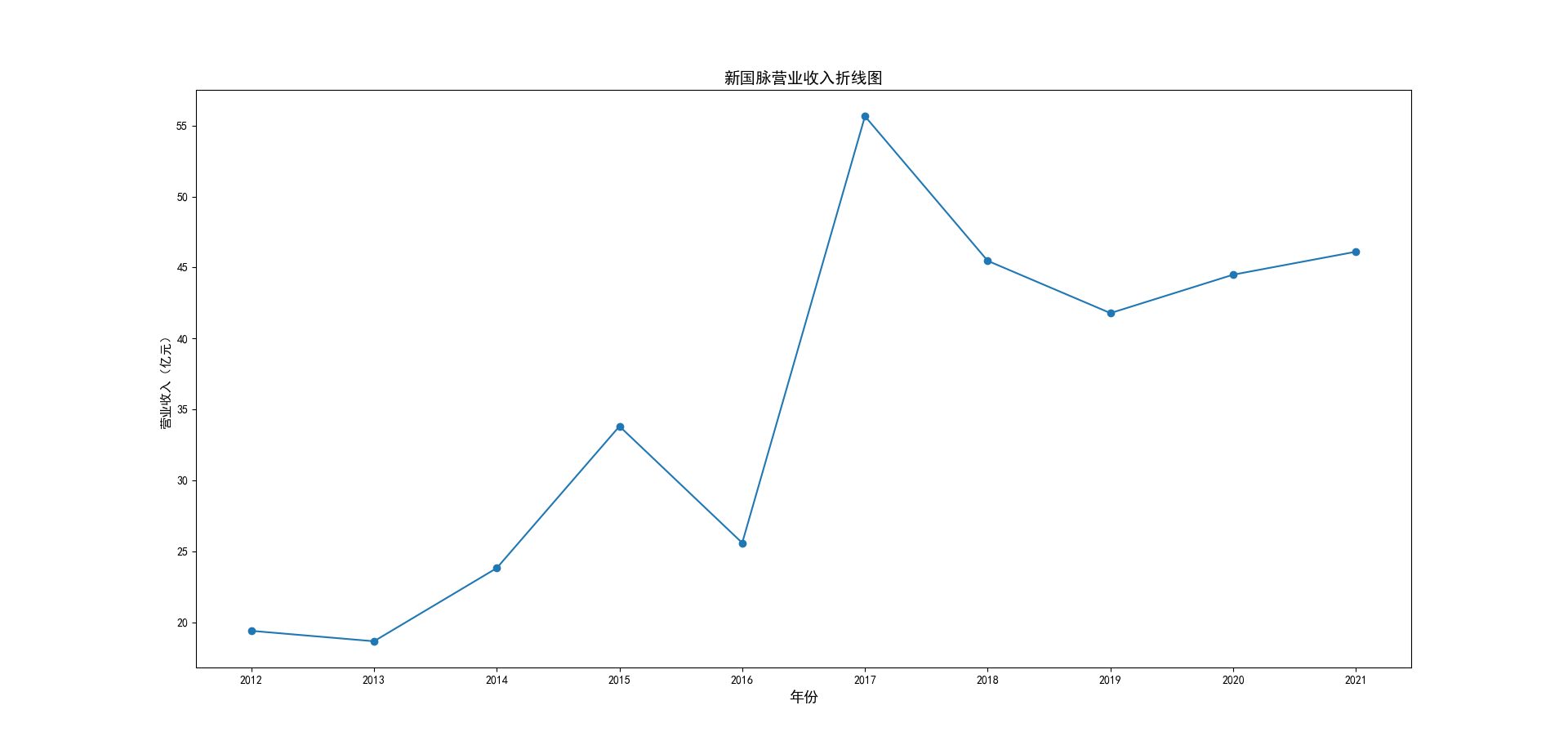

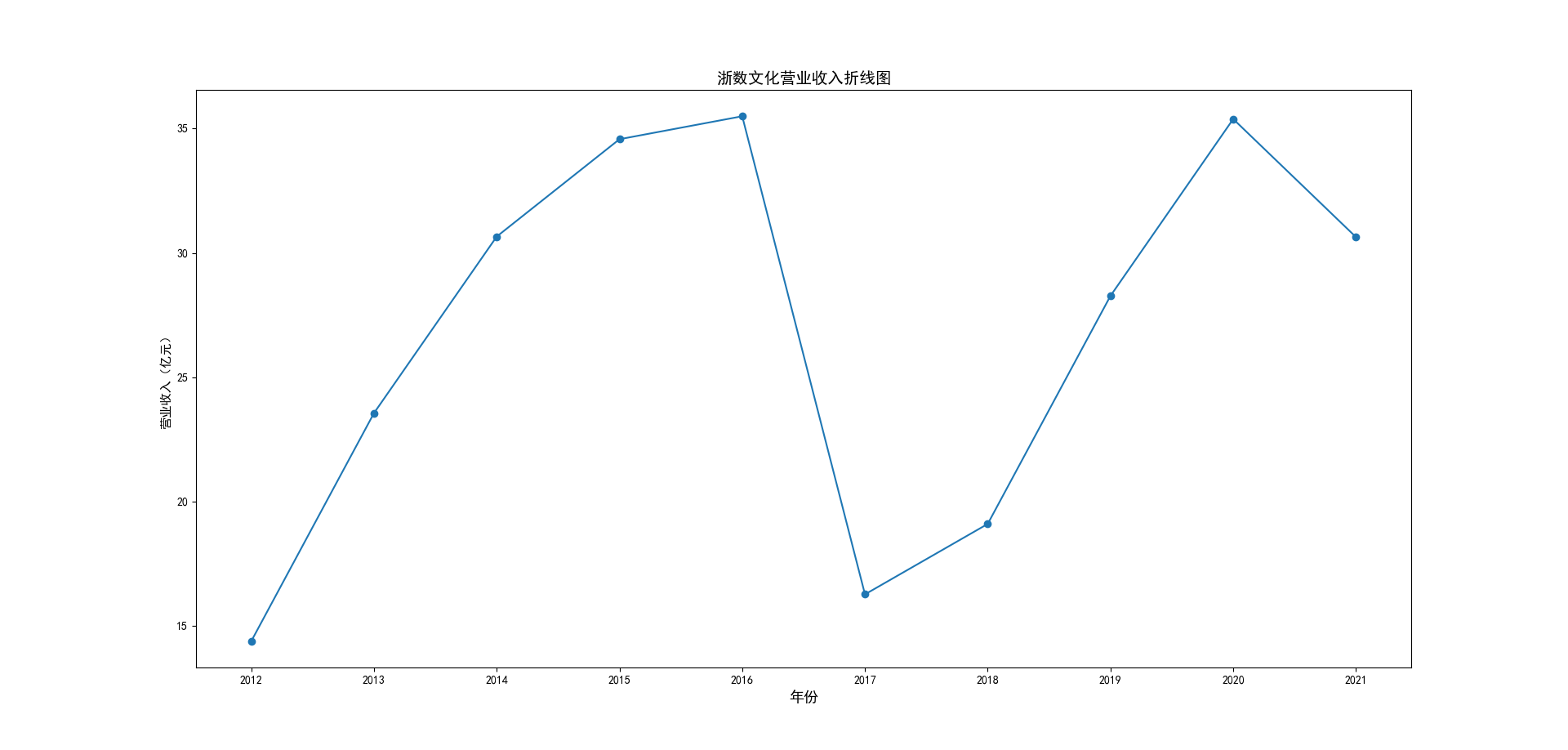
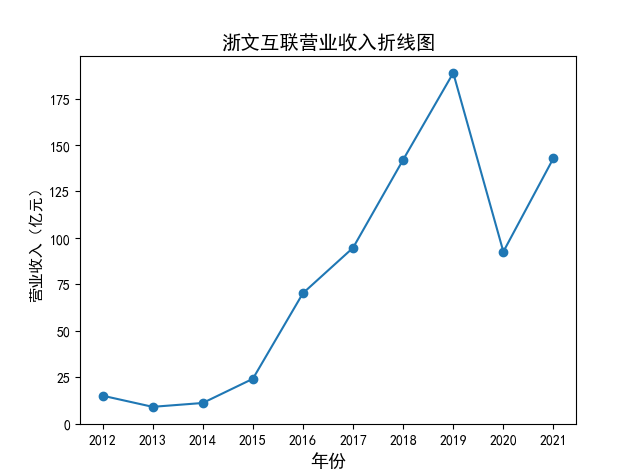
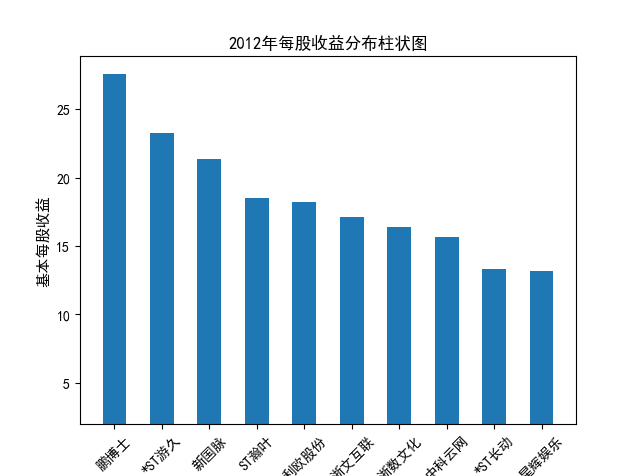
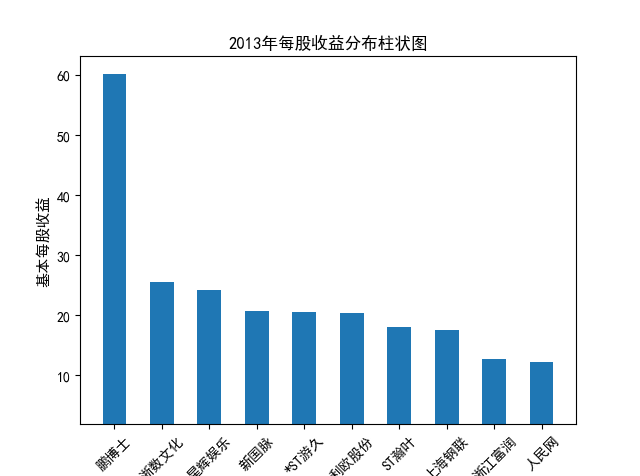
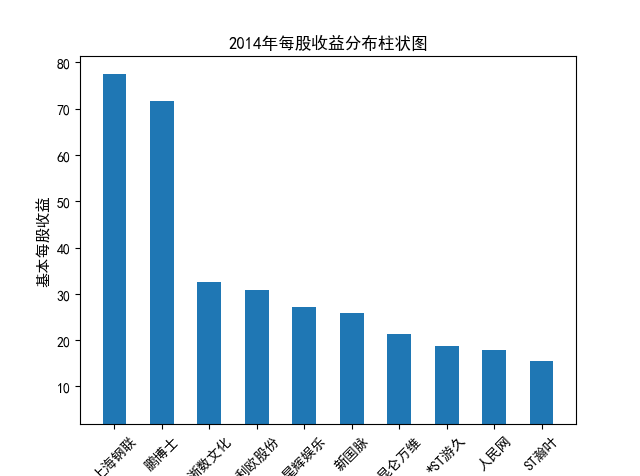
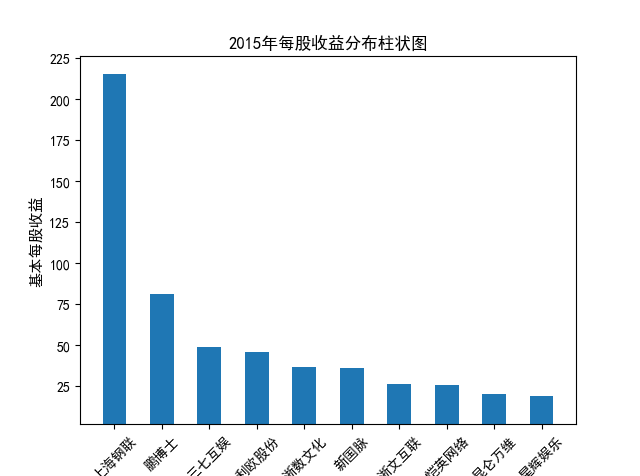
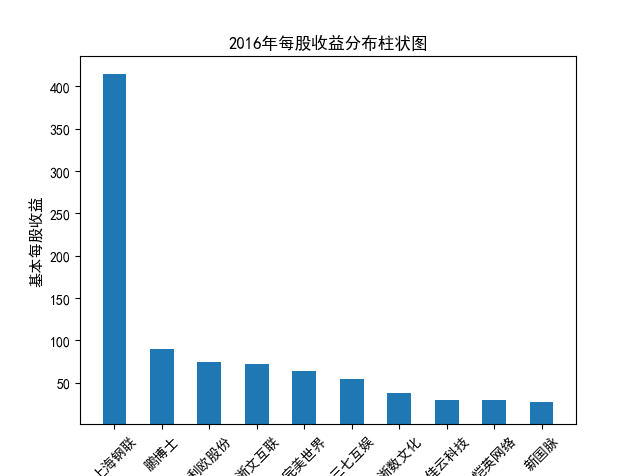
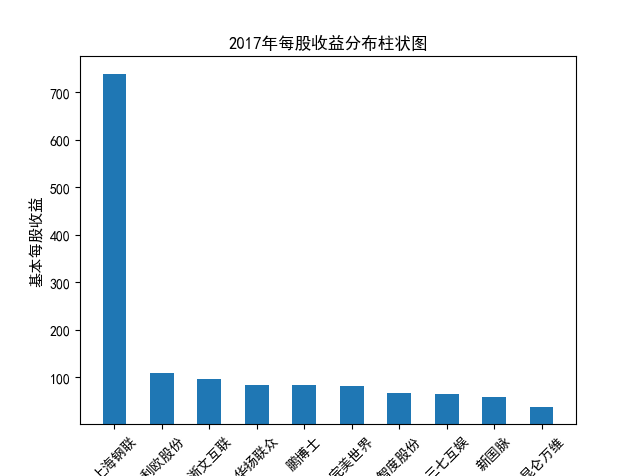
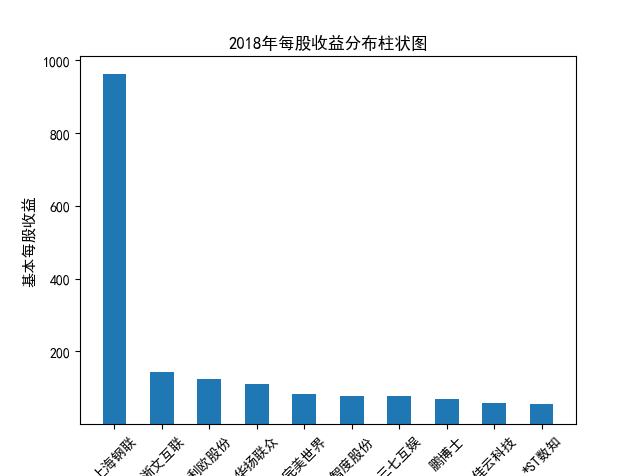
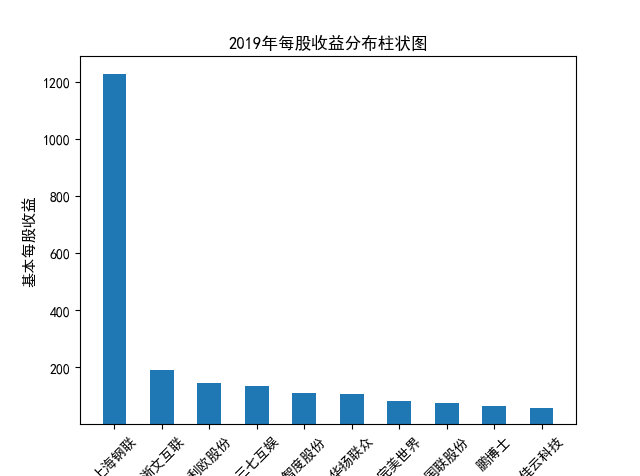
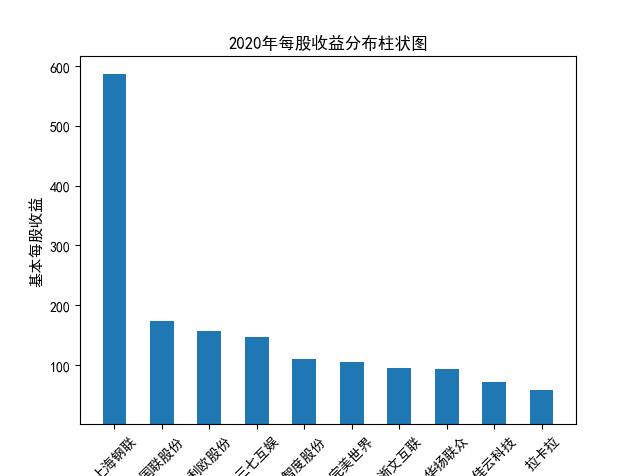
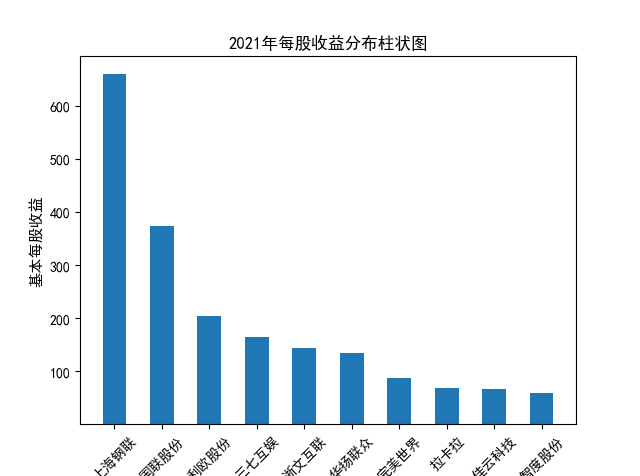
解读 由图标可以看出,互联网和相关服务行业上海钢联领先于其他企业, 是行业中的龙头。上海钢联2012年-2018年稳步增长,2019年因疫情和供应链因素 的影响大幅下滑,后随国内经济有所回升,近年来每股收益有所下降,2012-2021年行业整体呈上 升趋势,收入逐渐上升。互联网平台服务收入快速增长,网络销售、生活服务等平 台经营活跃向好。互联网接入服务收入保持增长,互联网数据服务持续快速发展。