import fitz
import re
import pandas as pd
import numpy as np
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import matplotlib.pyplot as plt
os.chdir('/Users/h/Desktop/python金融数据获取与处理/期末大作业')
import re
import pandas as pd
class DisclosureTable():
'''
解析巨潮网公告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'http://www.cninfo.com.cn'
#
p_code = re.compile('(.*?)', re.DOTALL)
p_time = re.compile('(.*?)', re.DOTALL)
p_name = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_code.search(txt).group(1).strip()
self.get_time = lambda txt: p_time.search(txt).group(1).strip()
self.get_name = lambda txt: p_name.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
href = matchObj.group(1).strip()
href = re.sub('amp;','',href)
title = matchObj.group(2).strip()
return([href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
get_name = self.get_name
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_name(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix + aht[0] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
'''
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data() #提取信息
df #获得结果
df.to_csv('data.csv')
'''

browser = webdriver.Safari() #使用Safari浏览器
browser.maximize_window()
def get_cninfo(code): #爬取巨潮网年报信息
browser.get('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&checkedCategory=category_ndbg_szsh')
browser.find_element(By.CSS_SELECTOR, ".el-autocomplete > .el-input--medium > .el-input__inner").send_keys(code)
time.sleep(1)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.DOWN)
browser.find_element(By.CSS_SELECTOR, ".query-btn").send_keys(Keys.ENTER)
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").click()
time.sleep(0.5)
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").clear()
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys("2013-01-01")
browser.find_element(By.CSS_SELECTOR, ".el-range-input:nth-child(2)").send_keys(Keys.ENTER)
time.sleep(0.1)
browser.find_element(By.CSS_SELECTOR, ".query-btn").click()
time.sleep(2)
element = browser.find_element(By.CLASS_NAME, 'el-table__body')
innerHTML = element.get_attribute('innerHTML')
return innerHTML
def html_to_df(innerHTML): #转换为Dataframe
f = open('innerHTML.html','w',encoding='utf-8') #创建html文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
return df
df = pd.DataFrame()
for i in code:
innerHTML = get_cninfo(i)
time.sleep(0.2)
df = df.append(html_to_df(innerHTML))
time.sleep(0.2)
def filter_links(words,df0,include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df0['公告标题']])
else:
ls.append([word not in f for f in df0['公告标题']])
index = []
for r in range(len(df0)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df1 = df0[index]
return(df1)
words1 = ["摘要","已取消"]
list = filter_links(words1,df,include=False) #删除摘要和已取消的报告
fun1 = lambda x: re.sub('(?<=报告).*', '', x)
fun2 = lambda x: re.sub('.*(?=\d{4})', '', x)
list['公告标题'] = list['公告标题'].apply(fun1) #去除“20xx年度报告”前后内容
list['公告标题'] = list['公告标题'].apply(fun2)
#exception = list[~list['公告标题'].str.contains('年年度报告')]
list = list.drop_duplicates(['证券代码','公告标题','公告时间'], keep='first') #删去重复值,保留最新一项
list['公告标题'].iloc[-20] = '2021年年度报告' #以下两行为修改格式不同一的公告标题
list['公告标题'].iloc[-19] = '2020年年度报告'
list['年份'] = [re.search('\d{4}', title).group() for title in list['公告标题']]
list['公告标题'] = list['简称']+list['公告标题']
os.makedirs('files')
os.chdir('/Users/h/Desktop/python金融数据获取与处理/期末大作业/files')
def get_pdf(r): #构建下载巨潮网报告pdf函数
p_id = re.compile('.*var announcementId = "(.*)";.*var announcementTime = "(.*?)"',re.DOTALL)
contents = r.text
a_id = re.findall(p_id, contents)
new_url = "http://static.cninfo.com.cn/finalpage/" + a_id[0][1] + '/' + a_id[0][0] + ".PDF"
result = requests.get(new_url, allow_redirects=True)
time.sleep(1)
return result
for c in code:
rpts = list[list['证券代码']==c]
for row in range(len(rpts)):
r = requests.get(rpts.iloc[row,3], allow_redirects=True)
time.sleep(0.3)
try:
result = get_pdf(r)
f = open(rpts.iloc[row,2]+'.PDF', 'wb')
f.write(result.content)
f.close()
r.close()
except:
print(rpts.iloc[row,2])
pass




def get_data(rpt): #构建获取营业收入和每股收益数据的函数
text = ''
for page in rpt:
text += page.get_text()
p_s = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据和\D*?(?=\\n)(.*?)稀', re.DOTALL)
txt = p_s.search(text).group(0) #匹配对应内容
p1 = re.compile('营(.*?)归',re.DOTALL) #匹配年报中3年的营业收入
data = p1.search(txt).group()
data = data.replace('\n', '') #替换掉换行符
p_digit = re.compile(r'(-)?\d[,0-9]*?\.\d{1,2}') #匹配内容中的数字到小数点后2位
revenue = p_digit.search(data).group()
revenue = turnover.replace(',','') #去掉逗号
p2 = re.compile('基(.*?)稀',re.DOTALL) #匹配年报中3年的基本每股收益
data = p2.search(txt).group()
data = data.replace('\n', '')
pe = p_digit.search(data).group()
return revenue,pe
def get_information(rpt): #构建获取办公地址、公司网址等信息的函数
text = ''
for page in rpt:
text += page.get_text()
p1 = re.compile('(?<=\\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\\n)', re.DOTALL)
infom1 = p1.findall(text)[0]
p2 = re.compile('(?<=\n)公司\w*网\s?址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
infom2 = p2.findall(text)[0]
return infom1,infom2
#获取营业收入和每股收益数据
revenues = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
pes = pd.DataFrame(columns=['公司'] + [year for year in range(2012,2022)])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
revenues.loc[i,'公司'] = firm.iloc[0,1]
pes.loc[i,'公司'] = firm.iloc[0,1]
for item in range(len(firm)):
try:
rpt = fitz.open(firm.iloc[item,2]+'.PDF')
revenue, pe = get_data(rpt)
reveues[int(firm.iloc[item,-1])][i] = revenue
pes[int(firm.iloc[item,-1])][i] = pe
except:
print(firm.iloc[item,2]+'解析出错')
revenues_n = revenues.iloc[:,1:].astype('float')
revenues_n.index = revenues['公司']
revenues_n.to_csv('营业收入汇总.csv')
pes_n = pes.iloc[:,1:].astype('float')
pes_n.index = pes['公司']
pes_n.loc['*ST东海A',2012] = 0.0058 #因*ST大东海A公司其基本每股收益在取小数点两位后很多数值为0,故这里手动敲入其基本每股收益
pes_n.loc['*ST东海A',2013] = -0.006
pes_n.loc['*ST东海A',2014] = 0.0069
pes_n.loc['*ST东海A',2015] = -0.0205
pes_n.loc['*ST东海A',2016] = -0.0073
pes_n.loc['*ST东海A',2017] = 0.0079
pes_n.loc['*ST东海A',2018] = 0.0018
pes_n.loc['*ST东海A',2019] = 0.0021
pes_n.loc['*ST东海A',2020] = -0.0318
pes_n.loc['*ST东海A',2021] = -0.0055
pes_n.to_csv('每股收益汇总.csv')
#获取公司信息
firm = list[list['证券代码']==code[0]]
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info = pd.DataFrame(columns=['股票代码', '股票简称', '办公地址', '公司网址'])
for i in range(len(code)):
firm = list[list['证券代码']==code[i]]
try:
rpt = fitz.open(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'.PDF')
info1,info2 = get_information(rpt)
info.loc[i,'股票代码'] = firm.iloc[0,0]
info.loc[i,'股票简称'] = firm.iloc[0,1]
info.loc[i,'办公地址'] = info1
info.loc[i,'公司网址'] = info2
except:
print(firm.iloc[firm['年份'].argsort().iloc[-1],2]+'解析出错')
info.to_csv('公司信息.csv')



详细内容可通过以下链接查看:

详细内容可通过以下链接查看:

详细内容可通过以下链接查看:
#绘制营业收入变化趋势图表
figure1 = revenues_n
figure1['公司简称'] = revenues_n.index
figure1.index = [i for i in range(len(figure1))]
figure1['mean'] = figure1.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
figure1 = figure1.sort_values('mean', ascending=False)[:10]
figure1.iloc[:,:10] = figure1.iloc[:,:10]/100000000
import matplotlib.font_manager as fm
fname = "/System/Library/Fonts/STHeiti Light.ttc"
zhfont1 = fm.FontProperties(fname=fname)
i = 0
plt.plot(figure1.columns[:10], figure1.iloc[i,:10], marker='o')
plt.xticks(np.linspace(2012,2021,10))
plt.xlabel('年份',fontsize=13,fontproperties=zhfont1)
plt.ylabel('营业收入(亿元)',fontsize=11,fontproperties=zhfont1)
plt.title(figure1.iloc[i,10]+"营业收入折线图",fontsize=14,fontproperties=zhfont1)
plt.show()
#绘制每股收益变化趋势图表
figure2 = pes_n
figure2['公司简称'] = pes_n.index
figure2.index = [i for i in range(len(figure2))]
figure2['mean'] = figure2.iloc[:,:10].apply(lambda x: x.sum()/10, axis=1)
figure2 = figure2.sort_values('mean', ascending=False)[:10]
import matplotlib.font_manager as fm
fname = "/System/Library/Fonts/STHeiti Light.ttc"
zhfont1 = fm.FontProperties(fname=fname)
i = 4
plt.plot(figure2.columns[:10], figure2.iloc[i,:10], marker='o')
plt.xticks(np.linspace(2012,2021,10))
plt.xlabel('年份',fontsize=13,fontproperties=zhfont1)
plt.ylabel('基本每股收益(元/股)',fontsize=11,fontproperties=zhfont1)
plt.title(figure2.iloc[i,10]+"基本每股收益折线图",fontsize=14,fontproperties=zhfont1)
plt.show()
#绘制逐年营业收入和每股收益图表
import matplotlib.font_manager as fm
fname = "/System/Library/Fonts/STHeiti Light.ttc"
zhfont1 = fm.FontProperties(fname=fname)
year = 2021
item = pd.concat([revenues_n[year], revenues_n['公司简称']], axis=1)
item[year] = item[year]/100000000
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.2)
plt.title(str(year)+'年营业收入分布柱状图',fontproperties=zhfont1)
plt.ylabel('营业收入(亿元)',fontsize=11,fontproperties=zhfont1)
plt.xticks(rotation=45,fontproperties=zhfont1)
plt.show()
year = 2021
item = pd.concat([pes_n[year], pes_n['公司简称']], axis=1)
item[year] = item[year]
item = item.sort_values(year, ascending=False).iloc[:10]
plt.bar(item['公司简称'],height=item[year],width=0.2)
plt.title(str(year)+'基本每股收益分布柱状图',fontproperties=zhfont1)
plt.ylabel('基本每股收益(元/股)',fontsize=11,fontproperties=zhfont1)
plt.xticks(rotation=45,fontproperties=zhfont1)
plt.show()
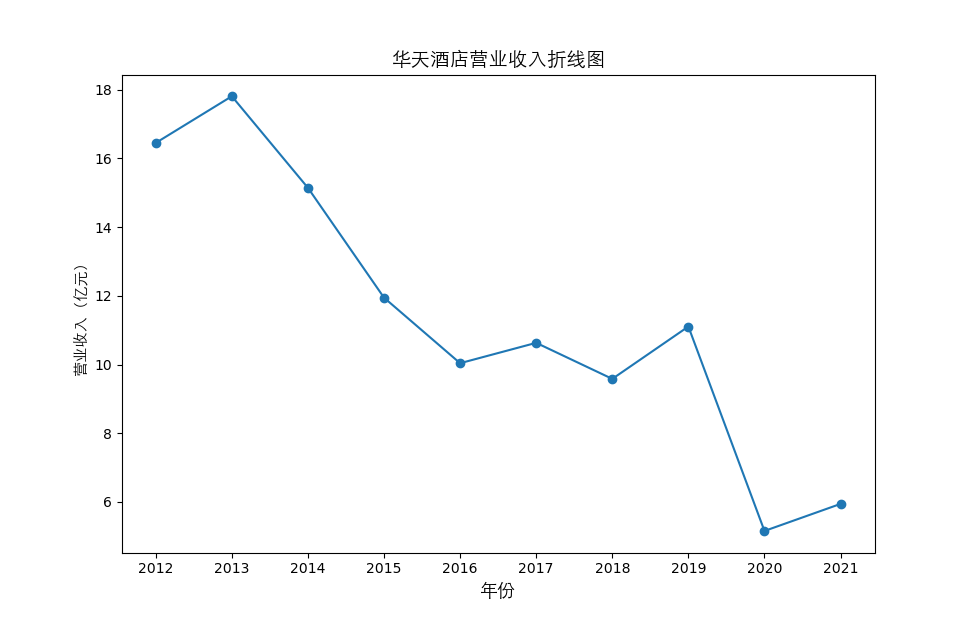
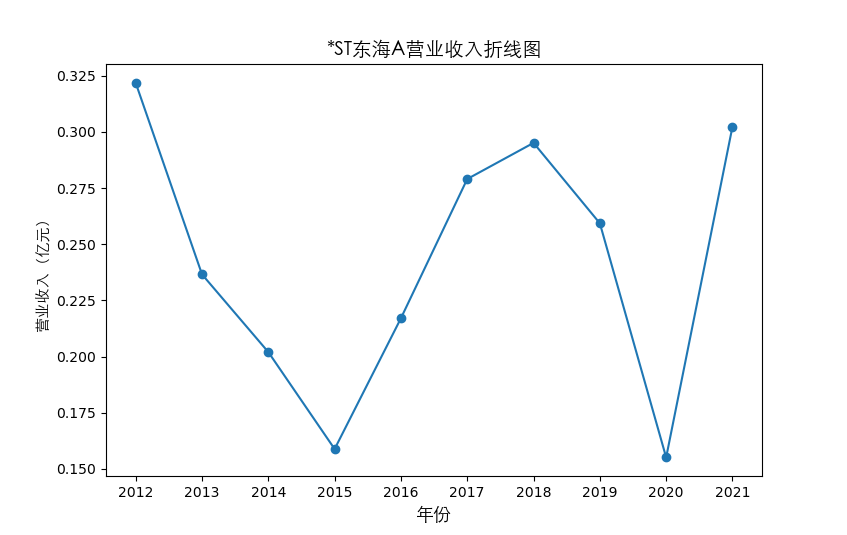
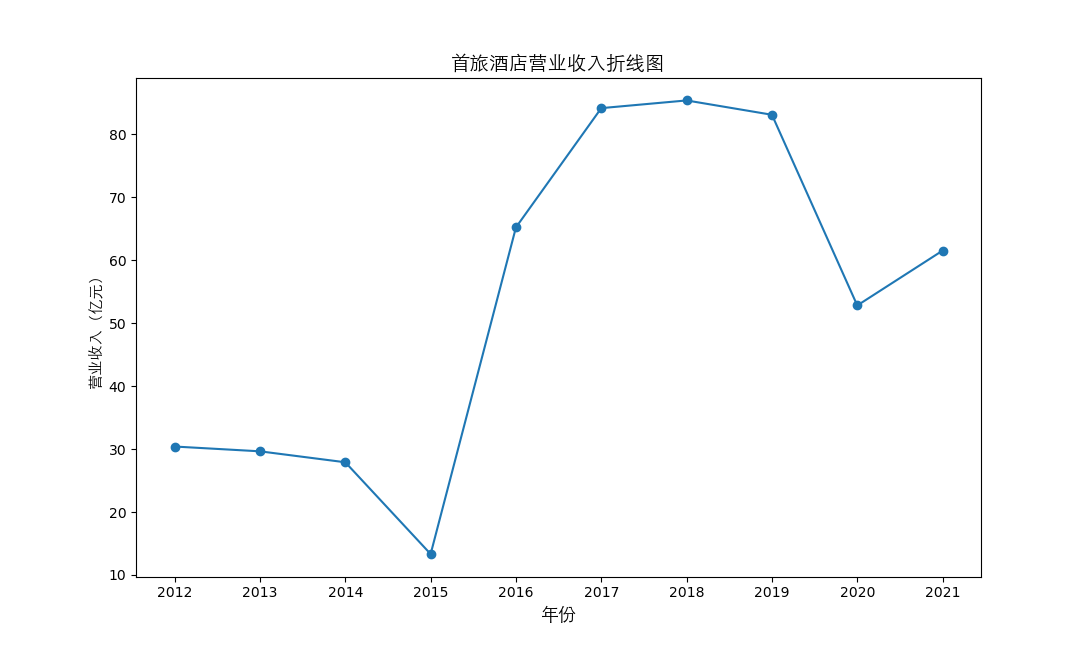
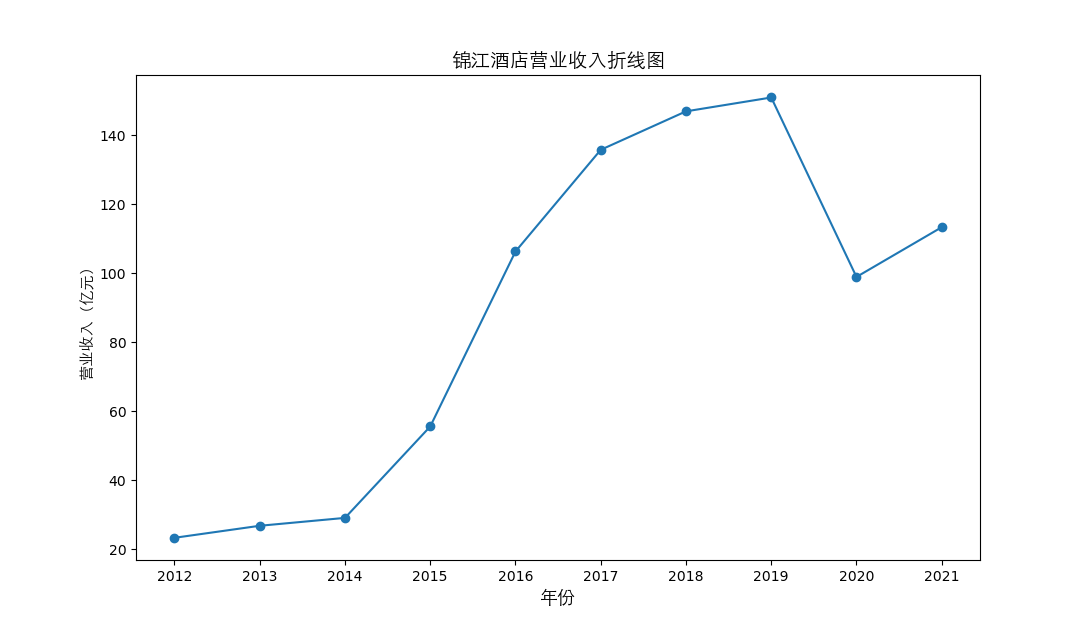



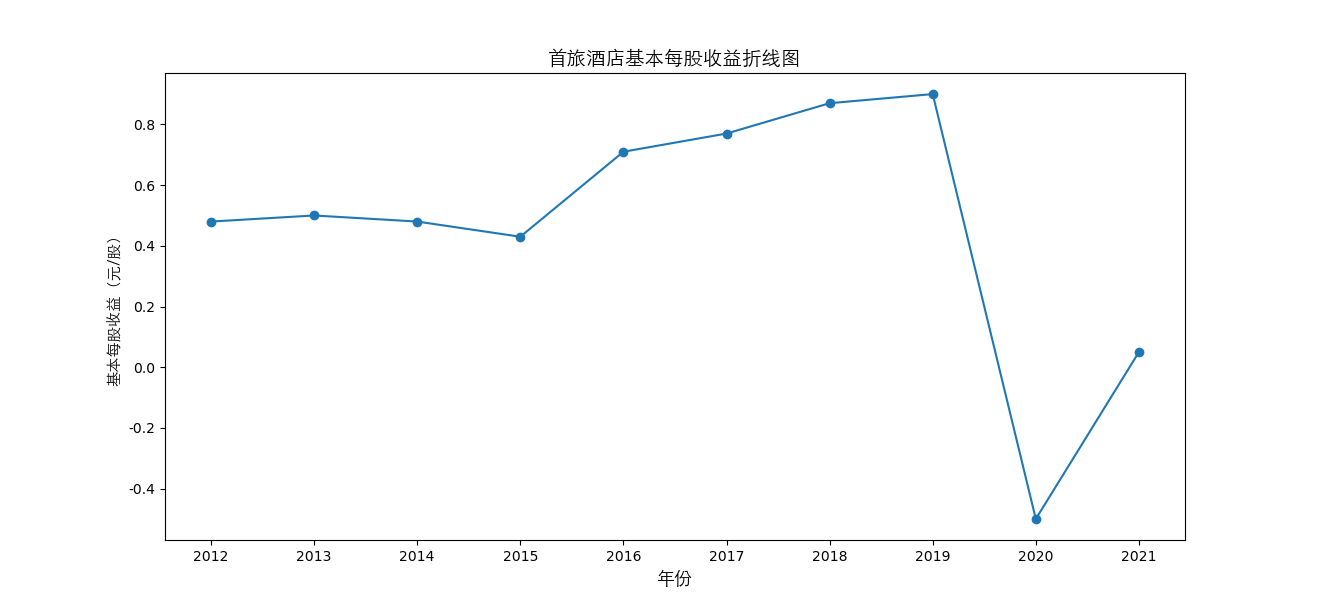
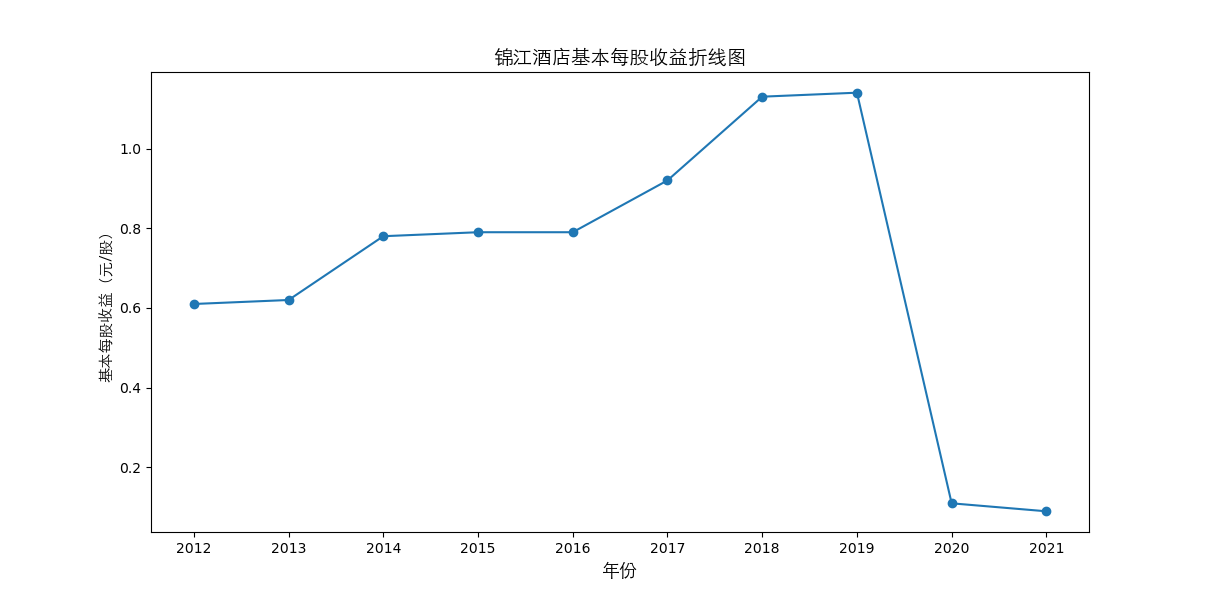


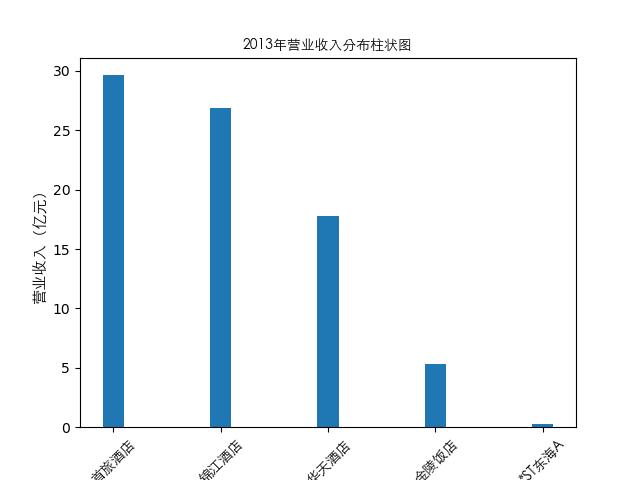

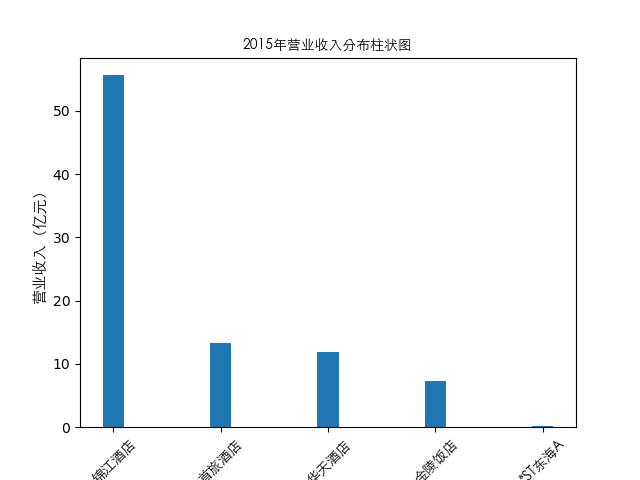
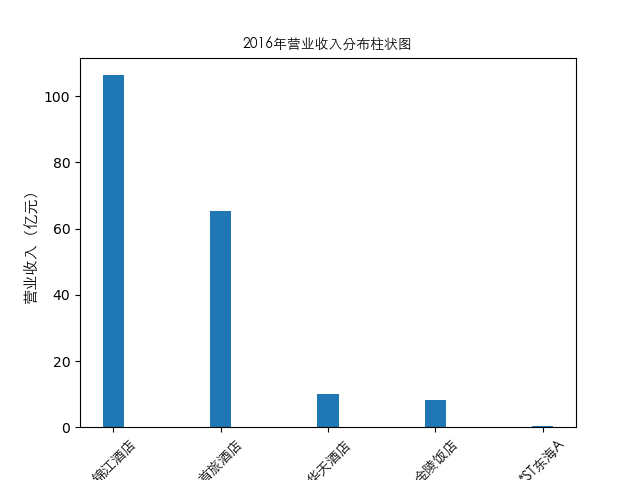
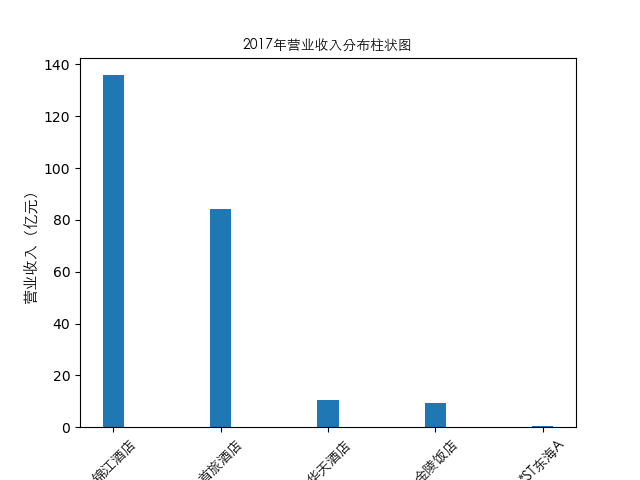
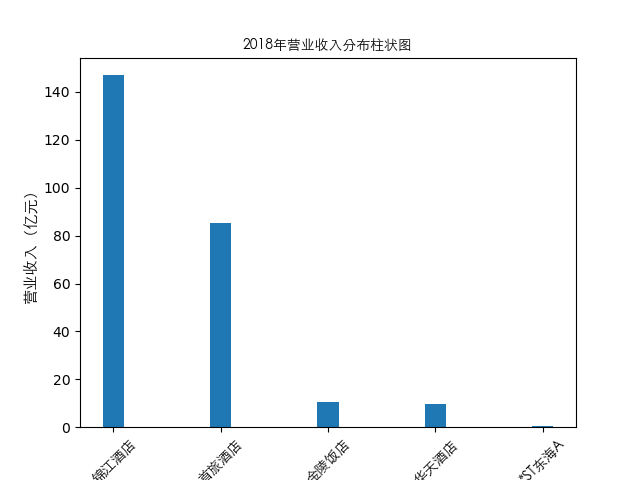
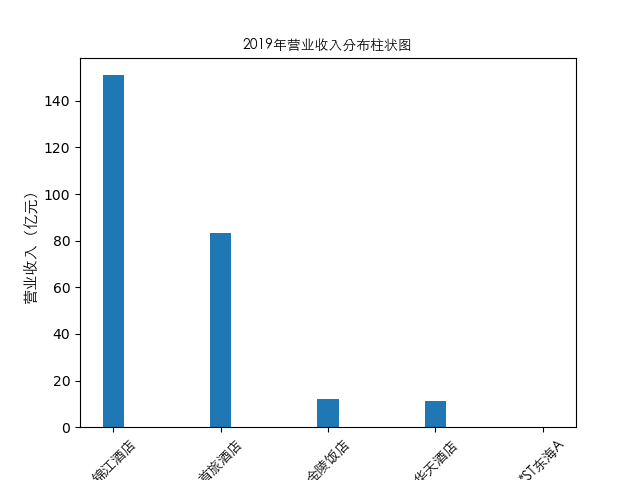
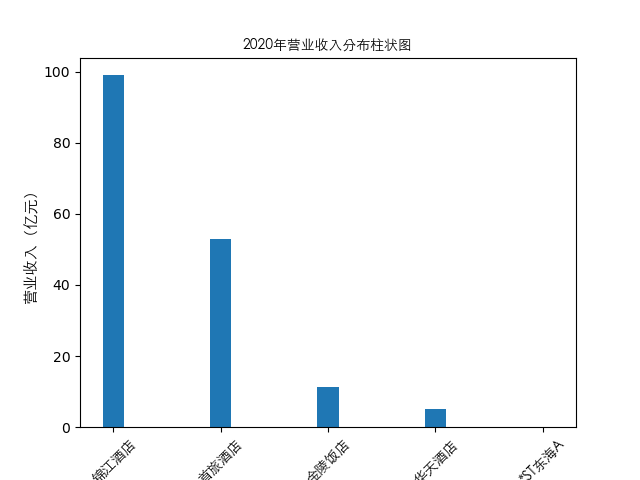
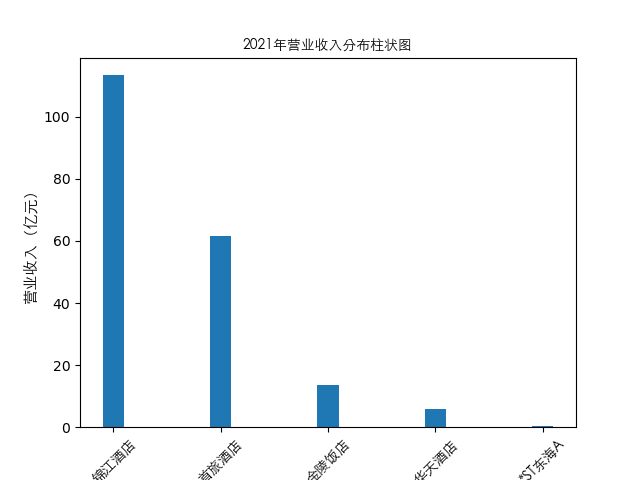

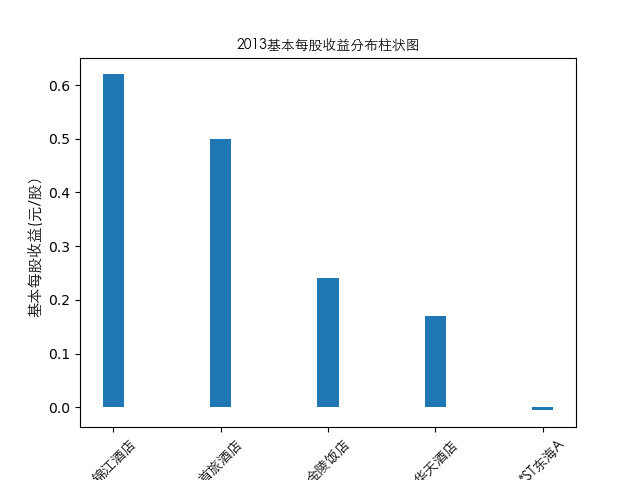

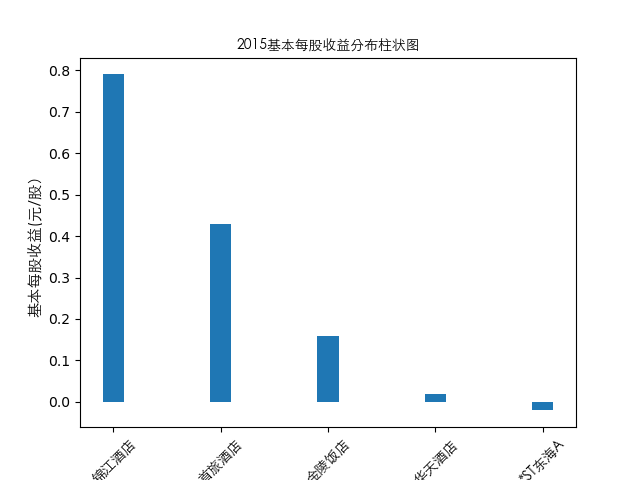
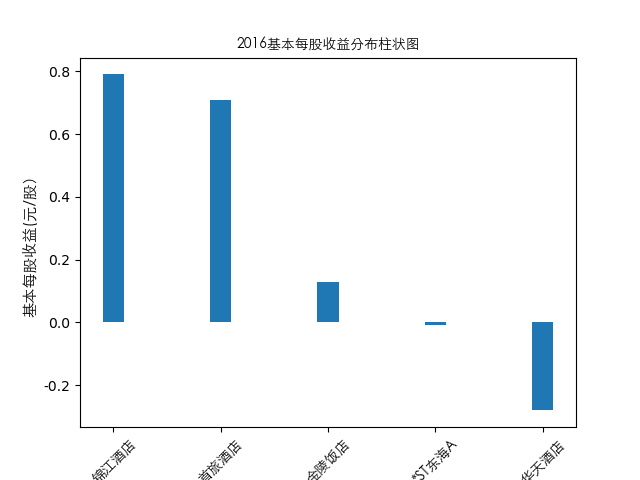

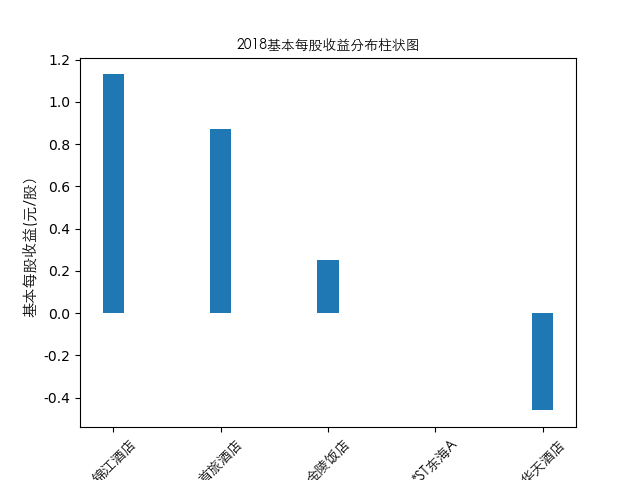
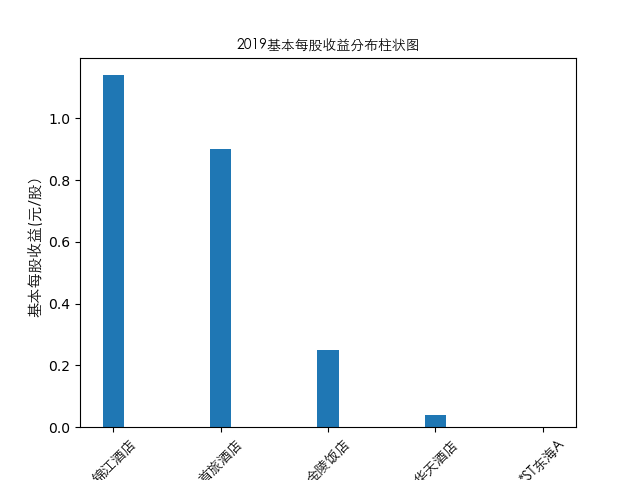
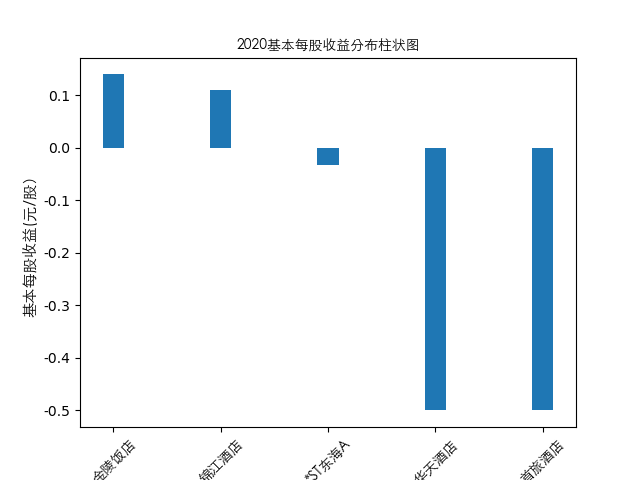
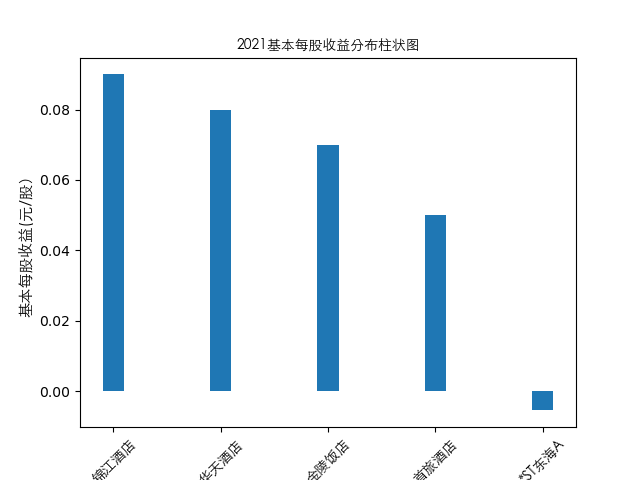
总的来说,住宿业内部的市场竞争格局还是相对稳定的,基本上以锦江酒店、首旅酒店两大龙头为主导,其他公司仅占较小的市场份额。