from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from parse_disclosure_table import
import os as os
import re
import requests
import pandas as pd
import fitz
import csv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#下载行业分类结果PDF文件
href = 'http://www.csrc.gov.cn/csrc/c100103/c1558619/1558619/files/1638277734844_11692.pdf'
r = requests.get(href,allow_redirects=True)
f = open('2021年3季度上市公司行业分类结果.pdf','wb')
f.write(r.content)
f.close()
r.close()
#获取行业分类结果PDF文件中69类行业所有上市公司
doc = fitz.open('2021年3季度上市公司行业分类结果.pdf')
page1 = doc[72]
page2 = doc[73]
page3 = doc[74]
toc_txt1 = page1.get_text()
toc_txt2 = page2.get_text()
toc_txt3 = page3.get_text()
r1 = re.compile('(?<=\n电力、热力生产和供应业\n)(.*)(?=\n)',re.DOTALL)
txt1 = r1.findall(toc_txt1)
r2 = re.compile('(?<=\n电力、热力生产和供应业\n)(.*)(?=\n)',re.DOTALL)
txt2 = r2.findall(toc_txt2)
r3 = re.compile('(?<=\n电力、热力生产和供应业\n)(.*)(?=\n燃气生产和供应业\n)',re.DOTALL)
txt3 = r3.findall(toc_txt3)
r = re.compile('(\d{6})\s*(\w+)\s*')
text1 = r.findall(txt1[0])
text2 = r.findall(txt2[0])
text3 = r.findall(txt3[0])
firm = text1 + text2 + text3
szf = re.compile('^0d{5}(.*)',re.DOTALL)
szfirm = szf.findall(firm)
browser = webdriver.Firefox()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
#报告类型选择
element = browser.find_element(By.CSS_SELECTOR,"#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT,"年度报告").click()
#日期选择
element = browser.find_element(By.CSS_SELECTOR, ".input-left").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
element = browser.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
element = browser.find_element(By.LINK_TEXT, "6月").click()
element = browser.find_element(By.CSS_SELECTOR, ".active > .dropdown-menu li:nth-child(1)").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
element = browser.find_element(By.CSS_SELECTOR, ".today > .tdcontainer").click()
element = browser.find_element(By.ID, "query-btn").click()
df_sz = pd.DataFrame({'index': ['000027','000037','000040','000155','000531',
'000539','000543','000591','000600','000601','000690','000692','000722',
'000767','000791','000862','000875','000883','000899','000966','000993',
'001210','001896','002015','002039','002256','002479','002608','002893',
'003816','300335'],
'name': ['深圳能源','深南电A','东旭蓝天','川能动力','穗恒运A',
'粤电力A','皖能电力','太阳能','建投能源','韶能股份','宝新能源','惠天热电',
'湖南发展','晋控电力','甘肃电投','银星能源','吉电股份','湖北能源','赣能股份',
'长源电力','闽东电力','金房节能','豫能控股','协鑫能科','黔源电力','兆新股份',
'富春环保','江苏国信','华通热力','中国广核','迪森股份']})
df_sh = pd.DataFrame({'index': ['600011','600021','600023','600025','600027',
'600032','600098','600101','600116','600149','600157','600163','600167',
'600236','600310','600396','600452','600483','600505','600509','600578',
'600642','600644','600674','600719','600726','600744','600780','600795',
'600821','600863','600868','600886','600900','600905','600969','600979',
'600982','600995','601016','601619','601778','601985','601991','603693',
'605011','605028','605162','605580'],
'name': ['华能国际','上海电力','浙能电力','华能水电','华电国际',
'浙江新能','广州发展','明星电力','三峡水利','廊坊发展','永泰能源','中闽能源',
'联美控股','桂冠电力','桂东电力','金山股份','涪陵电力','福能股份','西昌电力',
'天富能源','京能电力','申能股份','乐山电力','川投能源','大连热电','华电能源',
'华银电力','通宝能源','国电电力','金开新能','内蒙华电','梅雁吉祥','国投电力',
'长江电力','三峡能源','郴电国际','广安爱众','宁波能源','文山电力','节能风电',
'嘉泽新能','晶科科技','中国核电','大唐发电','江苏新能','杭州热电','世茂能源',
'新中港','恒盛能源']})
name_sz = df_sz['name'].tolist()
code_sh = df_sh['index'].tolist()
driver = webdriver.Firefox()
def getszHTML(name): #定义获取深交所公司html的函数
driver.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "input_code").click()
driver.find_element(By.ID, "input_code").send_keys(name)
driver.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
driver.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
driver.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
driver.find_element(By.LINK_TEXT, "年度报告").click()
driver.find_element(By.CSS_SELECTOR, ".input-left").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
driver.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
driver.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
driver.find_element(By.ID, "query-btn").click()
element = driver.find_element(By.ID, 'disclosure-table')
def getshHTML(code): #定义获取上交所公司html的函数
driver.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "inputCode").click()
driver.find_element(By.ID, "inputCode").send_keys(code)
driver.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
driver.find_element(By.LINK_TEXT, "年报").click()
def Save(filename,content): #保存文件
name = open(filename+'.html','w',encoding='utf-8')
name.write(content)
name.close()
i=1
for code in code_sh:
getshHTML(code)
time.sleep(1) # 延迟执行1秒
html = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
Save(code,innerHTML)
print('上交所共有',len(code_sh),'家,已获取第',i,'/',len(code_sh))
i=i+1
i=1
for name in name_sz:
getszHTML(name)
time.sleep(1) # 延迟执行1秒
html = driver.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
driver.refresh()
time.sleep(1)
print('深交所共有',len(name_sz),'家,已获取第',i,'/',len(name_sz))
i=i+1
driver.quit()
print('获取完毕')
i = 0
for index,row in df_sh.iterrows(): #提取上交所的信息表格
i+=1
code = row[0]
name = row[1]
df = getshDATA(code)
df_all = filter_links(["摘要","营业","并购","承诺","取消","英文"],df,include= False)
df_orig = filter_links(["(","("],df_all,include = False)
df_updt = filter_links(["(","("],df_all,include = True)
df_updt = filter_links(["取消"],df_updt,include = False)
df_all.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf_sh(df_all)
print(code+'年报已保存完毕。共',len(code_sh),'所公司,当前第',i,'所。')
os.chdir('../')

class Disclosuretable:
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('innerHTML.html')
def txt_to_df(html): #有问题
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
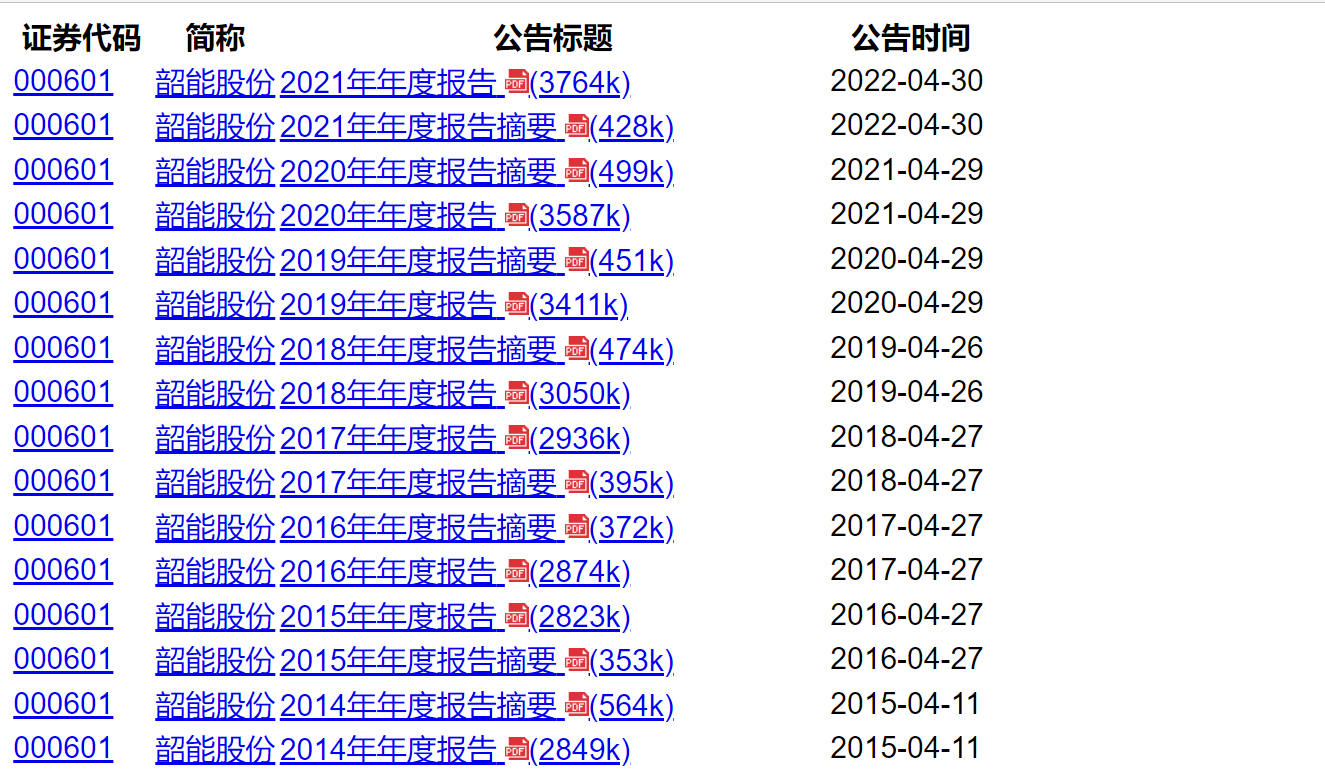
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
def get_code(txt):
get_code = p_a.search(txt).group(1).strip()
return(get_code)
def get_time(txt):
get_time = p_span.search(txt).group(1).strip()
return(get_time)
#get_code = lambda txt: p_a.search(txt).group(1).strip()
#get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
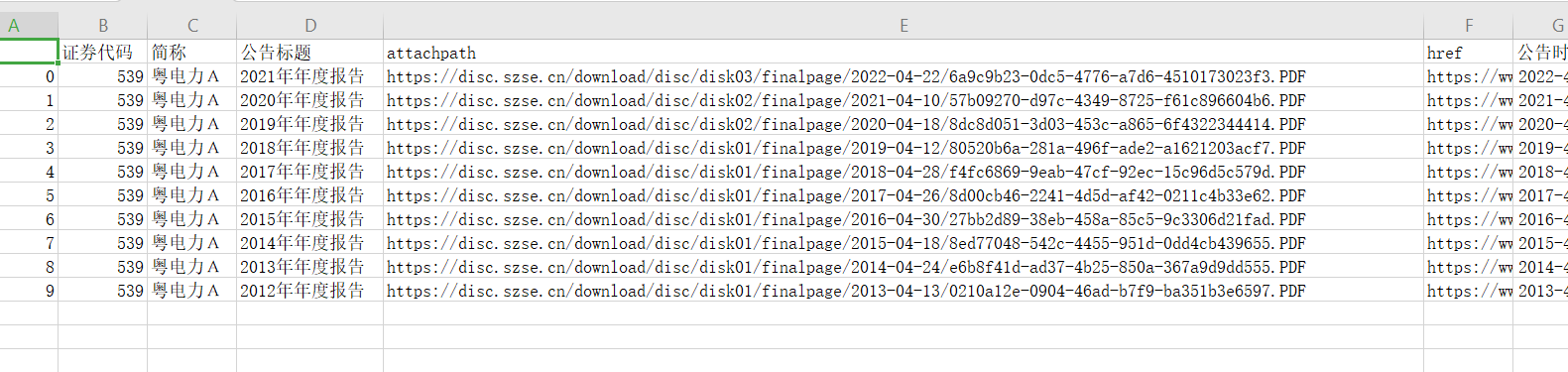
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
f = open(filename+'.html', encoding='utf-8')
html = f.read()
f.close()
return html
def tidy(df): #清除
d = []
for index, row in df.iterrows():
dd = row[2]
n = re.search("摘要|取消|英文", dd)
if n != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df.公告标题])
else:
ls.append([word not in f for f in df.公告标题])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
for name in name_sz:
html = Readhtml(name)
df_txt = txt_to_df(html)
df = df_txt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(name_sz),'所公司。当前第',name_sz.index(name)+1,'所。')
os.chdir('../')
大作业的时间安排上不到位,最后一直在努力完成报告,后悔没有早点开始做以及多 问问同学和老师。但是我已经尽力了。