吴诗一的期末大作业
第一步代码
#第一步:下载所分配行业各公司近10年年报,上市不足10年的,下载自上市年至2021年年报;
import pdfplumber
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
#定义所需函数
def Pdf_extract_table(filename):
pdf =pdfplumber.open(filename)
page_count = len(pdf.pages)
data = []
for i in range(page_count):
data += pdf.pages[i].extract_table()
pdf.close()
return data
def Get_sz(data):
sz=['200','300','301','00','080']
lst = [ x for x in data for startcode in sz if x[3].
startswith(startcode)==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
df = df.ffill()
return df
def InputStu():
Names = str(input('请输入姓名,以空格隔开:'))
Namelist = Names.split()
return Namelist
def Match(Namelist,assignment):
match = pd.DataFrame()
for name in Namelist:
match = pd.concat([match,assignment.
loc[assignment['完成人']==name]])
Number = match['行业'].tolist()
return Number
def SelectMode(mode,matched,df):
df_final = pd.DataFrame()
if mode == 'first':
for num in matched:
df_final = pd.concat([df_final,
df.loc[df['行业大类代码']==num].head(85)])
elif mode == 'all':
for num in matched:
df_final = pd.concat([df_final,
df.loc[df['行业大类代码']==num].sample(85)])
return df_final
def InputTime(start,end):
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind):
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name):
Searchbox = browser.find_element(By.ID, 'input_code')
Searchbox.send_keys(name + Keys.RETURN)
def Clearicon():
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank():
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename,content):
f = open(filename+'.html','w',encoding='utf-8')
f.write(content)
f.close()
class DisclosureTable():
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
self.txt_to_df()
def txt_to_df(self):
html = self.html
p = re.compile('(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '
(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
f = open(filename+'.html', encoding='utf-8')
html = f.read()
f.close()
return html
def tidy(df):
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
print('(读取解析行业分类文件中,这可能需要10秒)')
table = Pdf_extract_table("industry.pdf")
asign = pd.read_csv('001班行业安排表.csv',converters={'行业':str})
[['行业','完成人']]
SZ = Get_sz(table)
Names = InputStu()
MatchedI = Match(Names,asign)
mode = str(input('''
【请选择模式】:
默认(取行业内第一家深市公司)输入"first"
行业内随机选择深市公司输入"random":'''))
df_final = SelectMode(mode,MatchedI,SZ)
Company = df_final['上市公司简称'].tolist()
print('\n(爬取网页中......)')
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2012-01-01',End)
SelectReport(4)
Clickonblank()
for name in Company:
SearchCompany(name)
time.sleep(1)
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
Clearicon()
browser.quit()
print('\n【开始保存年报】')
for name in Company:
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司,当前第',
Company.index(name)+1,'所。')
os.chdir('../')
第一步结果
第二步代码
#第二步:提取“主要会计数据和财务指标”中的“营业收入(元)”、
“基本每股收益(元 ╱ 股)”保存为csv文件;
提取“股票简称”、“股票代码”、“办公地址”、“公司网址”保存为csv文件;
import pdfplumber
import re
import os
import numpy as np
import sys
import csv
import time,datetime
path1="C:\pdf\爱仕达"#定义上一步存放pdf所在文件夹
path2="C:\pdf2"#定义提取后的数据存放文件夹
temfilename = "数据"
name_list=os.listdir(path1)#利用os库获取路径1下的pdf文件名称
print(name_list)
x='jiexijieguo'
def creat_csv(x,csv_head):
path = str(path2+"\\"+"(%s).csv" % (x))
with open(path,'w',newline='' ,encoding='utf-8_sig') as f:
csv_write = csv.writer(f)
csv_write.writerow(csv_head)
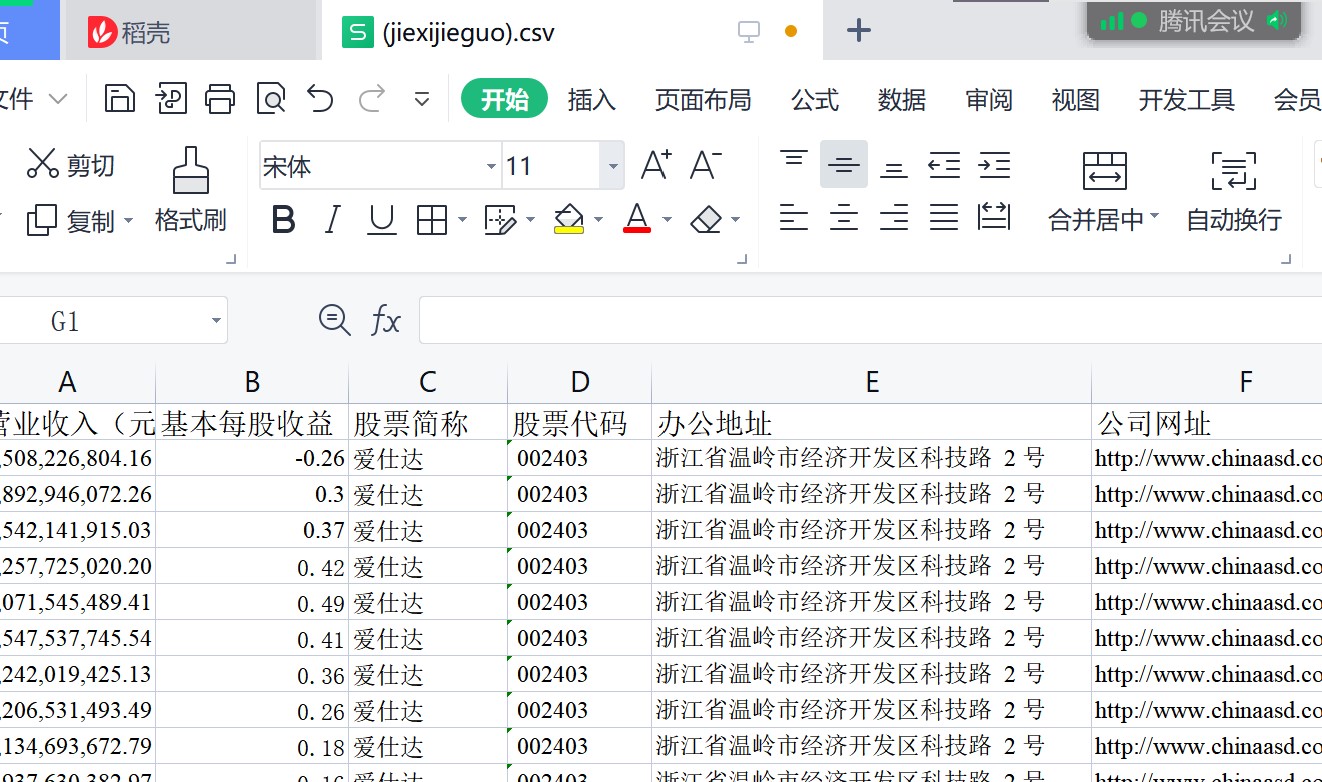
csv_head = ["营业收入(元)","基本每股收益(元/股)","股票简称",
"股票代码","办公地址","公司网址"]
creat_csv(x,csv_head)
def write_csv(x,data_row):
path = str(path2+"\\"+temfilename+"(%s).csv" % (x))
with open(path,mode="a",newline = "",encoding="utf-8_sig") as f:
csv_write = csv.writer(f)
csv_write.writerow(data_row)
import fitz
import re
import pandas as pd
doc = fitz.open('asd2021年度报表.pdf')
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
第二步结果
第二步解释
这里要先利用pdfplumber库对pdf进行目录的解析
将对应查找的对象在现在文件里找到对应包含的表格所在页码,
(因为年度报表标准16年更新问题,16年之前的公司基本营业数据一栏是在第三节,
16年之后,公司简介和公司基本营业数据都是在第二节,
所以在解析16年之前的报表的时候分两部分进行解析)
然后对相应页进行整页解析,找到对应表格,解析成csv文件
比如,营业收入是在“主要会计数据和财务指标”这一个表格里面,
而股票代码那些是在公司简介的“公司信息”表格中,
单独提取这些表格之后再对表格里面的数据进行提取
第三步代码
#第三步:对每家上市公司绘制“营业收入(元)”、“基本每股收益(元 ╱ 股)”随时间变化趋势图
(若总数超过10家,则挑选出营业收入最高的10家,进行绘图);
import numpy as np # 导入各个模块
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
mpl.rcParams['axes.unicode_minus'] = False # 解决中文字体负号显示不正常问题
xls_file = pd.ExcelFile(r'C:\Users\lenovo\.ipython\\解析.xlsx') # 打开工作簿
table = xls_file.parse('Sheet1') # 打开第一张表
table.tail()
df = table.set_index('年份') # 将年份设为索引
df.tail()
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(111)
df['营业收入(元)'].plot(ax=ax1,style='bD--',alpha=0.4,label='营业收入(千万元)')
# alpha表示点的透明程度
plt.xlabel('年份')
ax1.set_yticks(np.arange(0,4000000000,100000000)) # 设置左边纵坐标刻度
ax1.set_ylabel('营业收入(千万元)') # 设置左边纵坐标标签
plt.legend(loc=2) # 设置图例在左上方
ax2 = ax1.twinx()
df['基本每股收益(元/股)'].
plot(ax=ax2,grid=True,label='基本每股收益(元/股)',style='y>-.',alpha=0.7)
ax2.set_yticks(np.arange(0,2,0.1)) # 设置右边纵坐标刻度
ax2.set_ylabel('基本每股收益(元/股)') # 设置右边纵坐标标签
plt.legend(loc=1) # 设置图例在右上方
plt.title('xx股票简称') # 给整张图命名
plt.savefig('xx股票简称.png', dpi=2000, bbox_inches='tight')
第三步结果










第三步解释
第二步中已经将营业收入和基本每股收益填入创建的excel表格中
我们先提取所有公司2021年的营业收入,进行排序(这一步在excel中进行)
然后取最高的十家公司,将这十家公司的营业收入和基本每股收益另存一个新的表格,
建立csv文件,再运用python中的画图专用库Matplotlib进行画图
(这里有一个很烦人的地方,有的公司可能不怎么严谨,
最近几年的年度报告确实有按照证监会给出的标准进行制作,
但是往前的年份,尤其是12,13,14,15这几年,
各个公司的表格真的是花样百出,
我实在是能力有限,发现数据有误的时候已经做到了这一步,
一开始将这十家公司的数据重新整理出来的时候,
我找了一下有哪些公司哪几年的数据找不到,
一共有七个数据没有匹配成功,
然后想着单独写一份代码进行提取然后再重新填入我的表格里,
试了两个文件,数据确实提出来了,
但是新的问题是,由于各个公司有的时候每一年的都不一样,
单独对每一份文件提取这样两个数据用这么长的时间,
有点得不偿失(用了三个小时多才提了两份文件里的四个数据,我实在是太笨了)
所以我将剩下的五个文件里的数据通过
“最高级的电脑和摄像机”——我的大脑和眼睛直接进行提取,
这一过程只用了不到两分钟)
第四步代码
#第四步:按每一年度,对该行业内公司“营业收入(元)”、“基本每股收益(元 ╱ 股)”绘制
对比图(若总数超过10家,则挑选出营业收入最高的10家,进行绘图);
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
xls_file = pd.ExcelFile(r'C:\Users\lenovo\.ipython\\最后一步.xlsx')
table = xls_file.parse('Sheet1')
table.tail()
df = table.set_index('股票简称')
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(111)
df['营业收入(元)'].plot(ax=ax1,style='bD--',alpha=0.4,label='营业收入(千万元)')
plt.xlabel('股票简称')
ax1.set_yticks(np.arange(0,4000000000,100000000))
ax1.set_ylabel('营业收入(千万元)')
plt.legend(loc=2)
ax2 = ax1.twinx()
df['基本每股收益(元/股)'].plot(ax=ax2,grid=True,label='基本每股收益(元/股)',style='y>-.',alpha=0.7)
ax2.set_yticks(np.arange(0,2,0.1))
ax2.set_ylabel('基本每股收益(元/股)')
plt.legend(loc=1)
plt.title('各公司年度对比')
plt.savefig('我终于写完了.jpg', dpi=2000, bbox_inches='tight')
第四步结果

第四步解释
在第三步的基础上,将这十家公司的数据按照年份进行分类,
另存为csv文件,再用Matplotlib进行画图