import re
import pandas as pd
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
df=pd.read_excel(r"AllCompany.xlsx",converters={u"code":str}) #导入所分配的上市公司
Company_SZ = df.iloc[:172,1] #深交所上市股票
"""
定义所需函数
下载深交所上市公司的年报代码html
"""
def Input_code(name): #定义函数输入公司简称
Name = browser.find_element(By.ID,"input_code")
time.sleep(0.2)
Name.send_keys(name + Keys.RETURN)
def Input_time(start,end): #定义函数输入所需要年报的起止时间
START = browser.find_element(By.CLASS_NAME,"input-left")
END = browser.find_element(By.CLASS_NAME,"input-right")
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def Choose_report(): #定义函数选择年度报告
browser.find_element(By.LINK_TEXT,"请选择公告类别").click()
browser.find_element(By.LINK_TEXT,"年度报告").click()
def Save(filename,content): #创建并保存上市公司年报html
f = open(filename+'.html','w',encoding='utf-8')
f.write(content)
f.close()
def Clear():
browser.find_element(By.CLASS_NAME,"btn-clearall").click()
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(2)
Input_time('2012-01-01','2021-12-31')
for company in Company_SZ.values:
time.sleep(2)
Choose_report()
Input_code(company)
time.sleep(2)
html = browser.find_element(By.ID,"disclosure-table")
time.sleep(2)
innerHTML = html.get_attribute("innerHTML")
Save(company,innerHTML)
Clear()

"""
解析深交所上市公司年报代码html,下载公司年报
"""
#参考吴老师上课分享的代码
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Read_html(filename):
f = open(filename+'.html', encoding='utf-8-sig')
html = f.read()
f.close()
return html
def Clean(df): #清除“摘要”型、“(已取消)”型文件、“英文版”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消|英文", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Load_pdf(df): #下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
os.chdir(r"E:\python scripts\html\html_sz")
for company in Company_SZ.values: #下载深圳证券交易所的年报
html = Read_html(company)
dt = DisclosureTable(html)
dt1 = dt.get_data()
df = Clean(dt1)
df.to_csv("../../html/"+company+".csv",encoding="utf-8-sig")
os.makedirs("../../年报_sz/"+company,exist_ok=True)
os.chdir("../../年报_sz/"+company)
Load_pdf(df)
os.chdir("../../html/html_sz")

df=pd.read_excel(r"AllCompany.xlsx",converters={u"code":str}) #导入所分配的上市公司
Company_SH = df.iloc[172:,0] #上交所上市股票
"""
下载上交所上市公司的年报代码html
"""
code_sh = Company_SH.tolist()
driver = webdriver.Edge()
def getshHTML(code): #定义获取上交所公司html的函数
driver.get("http://www.sse.com.cn/disclosure/listedinfo/regular/")
driver.maximize_window()
driver.implicitly_wait(3)
driver.find_element(By.ID, "inputCode").click()
driver.find_element(By.ID, "inputCode").send_keys(code)
driver.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
driver.find_element(By.LINK_TEXT, "年报").click()
for code in code_sh:
getshHTML(code)
time.sleep(1)
html = driver.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = html.get_attribute('innerHTML')
Save(code,innerHTML)
"""
解析上交所公司html,下载年报
"""
def CB(lst):
chart=[]
for ls in lst:
if ls !=[]:
chart.append(ls)
return chart
def gain_df(txt):
p=re.compile("(.*?)")
p1=re.compile("(.*?)")
trs =p.findall(txt)
tds = [p1.findall(tr) for tr in trs]
tds = CB(tds)
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return df
def gain_link(txt):
p_a = re.compile('(.*?)')
matchObj = p_a.search(txt)
href= matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
p_span = re.compile('(.*?)', re.DOTALL)
gain_cn = lambda txt: p_span.search(txt).group(1) #定义一个函数获得股票的代码和简称
def gain_data(df_txt):
prefix = "http://static.sse.com.cn/"
df = df_txt
codes = [gain_cn(dt) for dt in df["证券代码"]]
short_names = [gain_cn(dt) for dt in df["简称"]]
ahts =[gain_link(dt) for dt in df["公告标题"]]
times = [time for time in df["公告时间"]]
df = pd.DataFrame({"证券代码":codes,
"公司简称":short_names,
"公告标题":[aht[1] for aht in ahts],
"href":[prefix + aht[0]for aht in ahts],
"公告时间":times})
return df
def Short_Name(df): #获得上海证券交易所公司的简称
for i in df["公司简称"]:
i=i.replace("*","")
if i !="-":
sn=i
return sn
def Loadpdf_sh(df):
d1 = {}
df["公告时间"] = pd.to_datetime(df["公告时间"])
name = Short_Name(df)
for index, row in df.iterrows():
na = name+str(row[4].year-1)+"年年度报告"
d1[na] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df["公告标题"]])
else:
ls.append([word not in f for f in df["公告标题"]])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df= df[index]
return(df)
def new_df(df_orig,df_updt):
m=[]
df_orig = df_orig.reset_index()
df_updt = df_updt.reset_index()
df_orig =df_orig.iloc[:,1:]
df_updt = df_updt.iloc[:,1:]
for date in df_updt["公告时间"]:
year1 = date[:4]
for index,row in df_orig.iterrows():
year2 = row[4][:4]
if year2 == year1:
m.append(index)
df_orig = df_orig.drop(m)
df = pd.concat([df_orig,df_updt],axis=0) #合并
df=df.reset_index()
df = df.iloc[:,1:]
return df
os.chdir(r"E:\python scripts\html\html_sh")
for company in Company_SH.values: #下载上海证券交易所年报的循环
txt =Read_html(company)
txt_df = gain_df(txt)
data= gain_data(txt_df)
df_all = filter_links(["摘要","社会责任","审计","财务","风险","债券","图文","董事","意见","监事"],data,include= False)
df_orig = filter_links(["(","("],df_all,include = False)
df_updt = filter_links(["(","("],df_all,include = True)
df1 = new_df(df_orig,df_updt)
name = Short_Name(df1)
df1.to_csv("../../html/"+name+".csv",encoding="utf-8-sig")
os.makedirs("../../年报_sh/"+name,exist_ok=True)
os.chdir("../../年报_sh/"+name)
Loadpdf_sh(df1)
os.chdir("../../html/html_sh")

import os
import re
import pandas as pd
import requests
import fitz
Company = pd.read_excel(r'E:\python scripts\Company.xlsx')
company = Company.iloc[:,2].tolist()
t=0
for com in company:
t+=1
os.chdir(r"E:\python scripts\Csv")
df = pd.read_csv(com+'.csv',converters={'证券代码':str})
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2012,2021),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)):
os.chdir(r"E:\python scripts\年报")
title = df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(20):
page = doc[j]
text += page.get_text()
p_year = re.compile('.*?\n?(20\d{2})\s?.*?\n?年\n?度\n?报\n?告\n?.*?')
year = int(p_year.findall(text)[0]) #运行时偶尔会出现问题,有待进一步解决
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web = re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue = float(p_rev.search(text).group(1).replace(',',''))
eps = p_eps.search(text).group(1)
final.loc[year,'营业收入(元)'] = revenue
final.loc[year,'基本每股收益(元/股)'] = eps
final.to_csv('%s数据.csv' %com,encoding='utf-8-sig')
site = p_site.search(text).group(1)
web = p_web.search(text).group(1)
with open('%s数据.csv'%com,'a',encoding='utf-8-sig') as f:
content = '股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
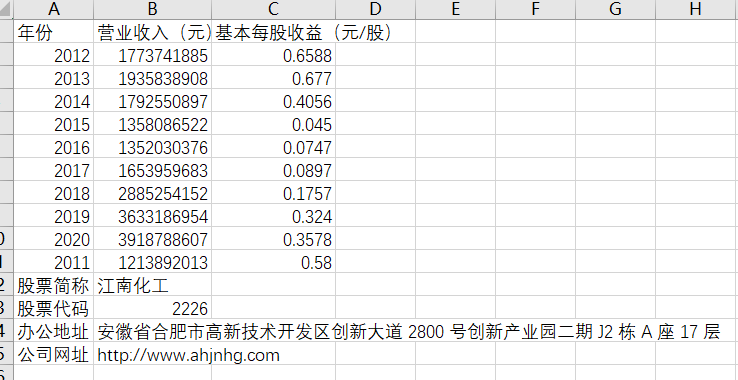
import pandas as pd
import matplotlib.pyplot as plt
import os
Company = pd.read_excel(r'E:\python scripts\Company.xlsx')
company = Company.iloc[:,2].tolist()
data_list = []
for com in company:
os.chdir(r"E:\python scripts\数据csv")
data = pd.read_csv(com+'数据.csv')
data_list.append(data)
comps = len(data_list)
for i in range(comps):
data_list[i] = data_list[i].set_index('年份')
#定义一个函数将近十年营业收入之和排序
def compare_rev(data):
df=pd.DataFrame(columns=['近十年总营业收入(元)'])
for i in range(comps):
df.loc[data_list[i].loc['股票简称','营业收入(元)'],'近十年总营业收入(元)']=data_list[i].iloc[:9,0].astype(float).sum()
return df
rank=compare_rev(data_list).sort_values('近十年总营业收入(元)',ascending=False).head(10)
names = ['中核钛白','中钢天源','司尔特','四川美丰','永太科技','江南化工','道明光学','青岛金王','鲁西化工','鸿达兴业']
indexes = []
for idx in names:
indexes.append(company.index(idx))
data_list1 = []
data_list2 = []
for i in range(10):
data_list1.append(pd.DataFrame(data_list[i].iloc[:9,0]))
for df in data_list1:
df.index=df.index.astype(int)
df['营业收入(元)']=df['营业收入(元)'].astype(float)/1000000000
for i in indexes:
data_list2.append(pd.DataFrame(data_list[i].iloc[:9,1]))
for df in data_list2:
df.index=df.index.astype(int)
df['基本每股收益(元/股)']=df['基本每股收益(元/股)'].astype(float)
#汇总成表,为绘制图表做准备
hori_rev=pd.concat(data_list1,axis=1)
hori_eps=pd.concat(data_list2,axis=1)
hori_rev.columns=rank.index
hori_eps.columns=rank.index
plt.rcParams['font.sans-serif']=['SimHei'] #设置字体为黑体
plt.figure(figsize=(16,24))
x = data_list1[0].index
plt.xlim(2011,2021,1)
plt.xticks(range(2012,2021),fontsize=18)
plt.yticks(fontsize=18)
y_1 = hori_rev.iloc[:,0]
y_2 = hori_rev.iloc[:,1]
y_3 = hori_rev.iloc[:,2]
y_4 = hori_rev.iloc[:,3]
y_5 = hori_rev.iloc[:,4]
y_6 = hori_rev.iloc[:,5]
y_7 = hori_rev.iloc[:,6]
y_8 = hori_rev.iloc[:,7]
y_9 = hori_rev.iloc[:,8]
y_10 = hori_rev.iloc[:,9]
plt.plot(x, y_1, color='#9BCD9B', marker='^',markersize=10, linestyle='-', label=hori_rev.columns[0],linewidth = 2,alpha=0.8)
plt.plot(x, y_2, color='#2E8B57', marker=9, markersize=10,linestyle='-', label=hori_rev.columns[1],linewidth = 2,alpha=0.8)
plt.plot(x, y_3, color='#FF8C00', marker='^', markersize=10,linestyle='-', label=hori_rev.columns[2],linewidth = 2,alpha=0.8)
plt.plot(x, y_4, color='#4682B4', marker='D', markersize=9,linestyle='-', label=hori_rev.columns[3],linewidth = 2,alpha=0.8)
plt.plot(x, y_5, color='#FF6A6A', marker=9,markersize=9, linestyle='-', label=hori_rev.columns[4],linewidth = 2,alpha=0.8)
plt.plot(x, y_6, color='#1E90FF', marker='s', markersize=9,linestyle='-', label=hori_rev.columns[5],linewidth =2,alpha=0.8)
plt.plot(x, y_7, color='#6495ED', marker='^', markersize=7,linestyle='-', label=hori_rev.columns[6],linewidth =2,alpha=0.8)
plt.plot(x, y_8, color='#FFB90F', marker=9, markersize=7,linestyle='-', label=hori_rev.columns[7],linewidth =2,alpha=0.8)
plt.plot(x, y_9, color='#8B3A3A', marker='D',markersize=7, linestyle='-', label=hori_rev.columns[8],linewidth =2,alpha=0.8)
plt.plot(x, y_10, color='#00CED1', marker='s', markersize=7,linestyle='-', label=hori_rev.columns[9],linewidth =2,alpha=0.8)
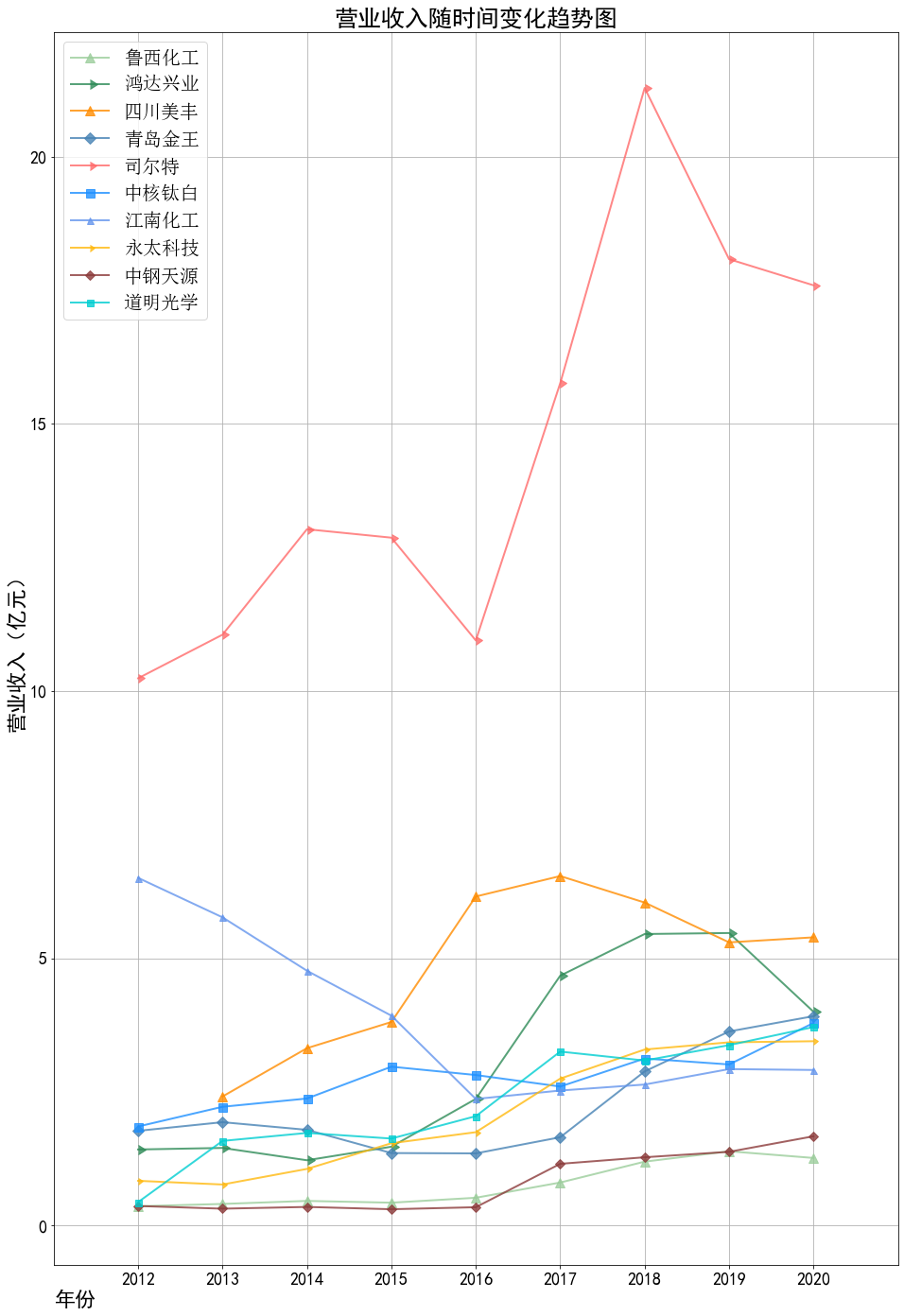
plt.title("营业收入随时间变化趋势图",fontsize=25)
plt.ylabel("营业收入(亿元)",fontsize=22) # 设置Y轴标签
plt.xlabel("年份",fontsize=22,loc='left') # 设置X轴标签
plt.legend(loc = "upper left",prop={'family':'simsun', 'size': 20})
plt.grid(True)
plt.show()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(16,24))
x = data_list1[0].index
plt.xlim(2011,2021,1)
plt.xticks(range(2012,2021),fontsize=18)
plt.yticks(fontsize=18)
y_1 = hori_eps.iloc[:,0]
y_2 = hori_eps.iloc[:,1]
y_3 = hori_eps.iloc[:,2]
y_4 = hori_eps.iloc[:,3]
y_5 = hori_eps.iloc[:,4]
y_6 = hori_eps.iloc[:,5]
y_7 = hori_eps.iloc[:,6]
y_8 = hori_eps.iloc[:,7]
y_9 = hori_eps.iloc[:,8]
y_10 = hori_eps.iloc[:,9]
plt.plot(x, y_1, color='#9BCD9B', marker='^',markersize=9, linestyle='-', label=hori_eps.columns[0],linewidth = 2,alpha=0.8)
plt.plot(x, y_2, color='#2E8B57', marker='D', markersize=9,linestyle='-', label=hori_eps.columns[1],linewidth = 2,alpha=0.8)
plt.plot(x, y_3, color='#FF8C00', marker='^', markersize=9,linestyle='-', label=hori_eps.columns[2],linewidth = 2,alpha=0.8)
plt.plot(x, y_4, color='#4682B4', marker=9, markersize=9,linestyle='-', label=hori_eps.columns[3],linewidth = 2,alpha=0.8)
plt.plot(x, y_5, color='#8B3A3A', marker='s',markersize=9, linestyle='-', label=hori_eps.columns[4],linewidth = 2,alpha=0.8)
plt.plot(x, y_6, color='#1E90FF', marker=9, markersize=9,linestyle='-', label=hori_eps.columns[5],linewidth =2,alpha=0.8)
plt.plot(x, y_7, color='#6495ED', marker='D', markersize=9,linestyle='-', label=hori_eps.columns[6],linewidth =2,alpha=0.8)
plt.plot(x, y_8, color='#FFB90F', marker=9, markersize=9,linestyle='-', label=hori_eps.columns[7],linewidth =2,alpha=0.8)
plt.plot(x, y_9, color='#FF6A6A', marker='^',markersize=9, linestyle='-', label=hori_eps.columns[8],linewidth =2,alpha=0.8)
plt.plot(x, y_10, color='#00CED1', marker='s', markersize=9,linestyle='-', label=hori_eps.columns[9],linewidth =2,alpha=0.8)
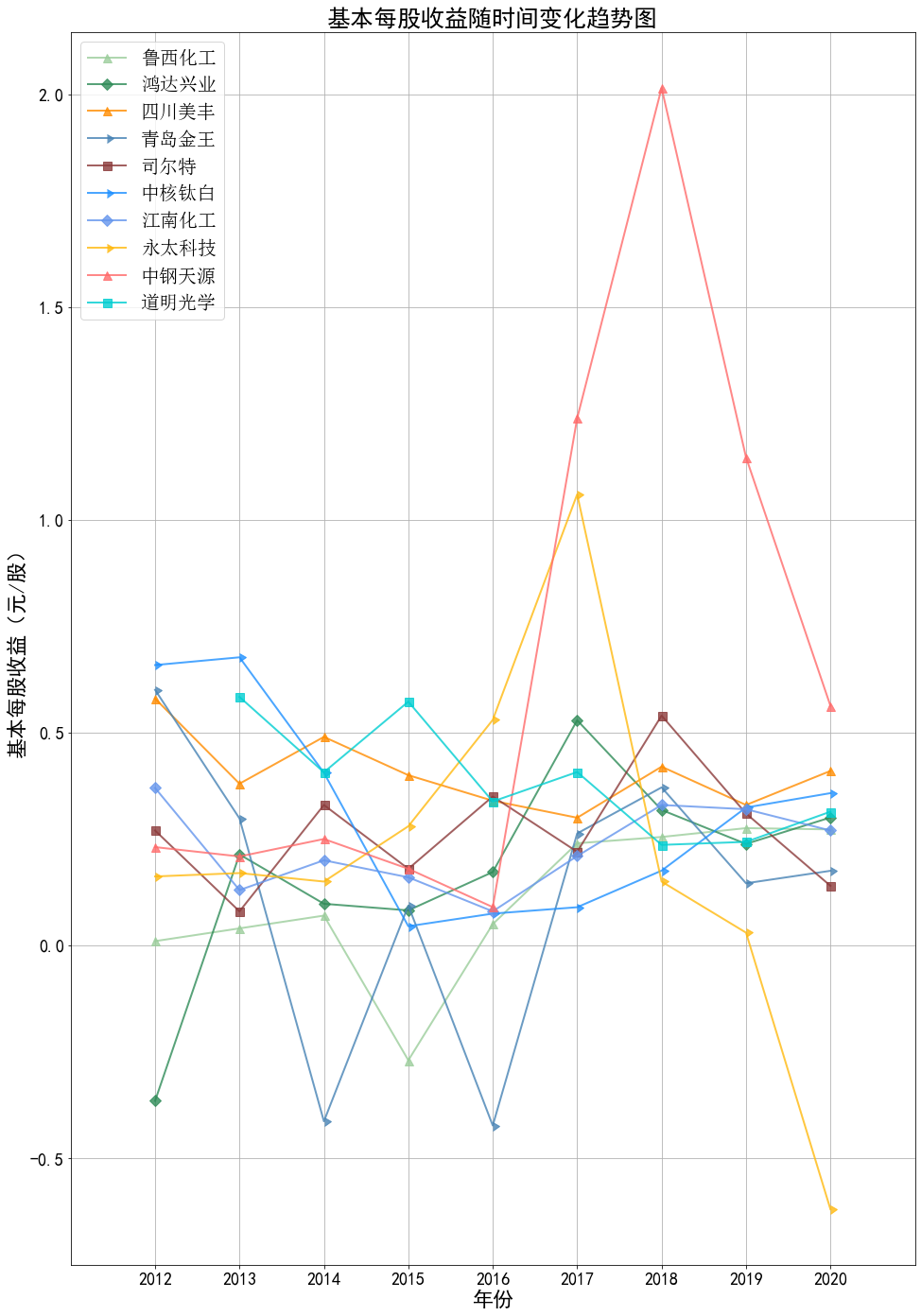
plt.title("基本每股收益随时间变化趋势图",fontsize=25)
plt.ylabel("基本每股收益(元/股)",fontsize=22) # 设置Y轴标签
plt.xlabel("年份",fontsize=22) # 设置X轴标签
plt.legend(loc = "upper left",prop={'family':'simsun', 'size': 20},framealpha=0.8) # 显示图例
plt.grid(True)
plt.show()
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
hori_revup=hori_rev.head(4)
hori_revmid=hori_rev.iloc[4:8]
hori_revdown=hori_rev.tail(3)
ax1=hori_revup.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
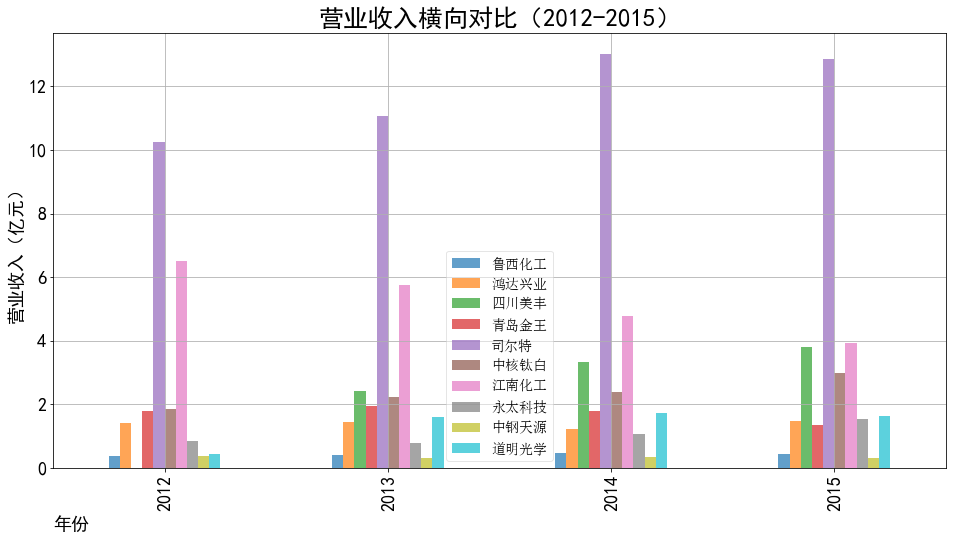
ax1.set_title('营业收入横向对比(2012-2015)',fontsize=25)
ax1.set_xlabel('年份',loc='left',fontsize=18)
ax1.set_ylabel('营业收入(亿元)',fontsize=18)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14})
ax2=hori_revmid.plot(kind='bar',figsize=(16 ,8),fontsize=18,alpha=0.7,grid=True)
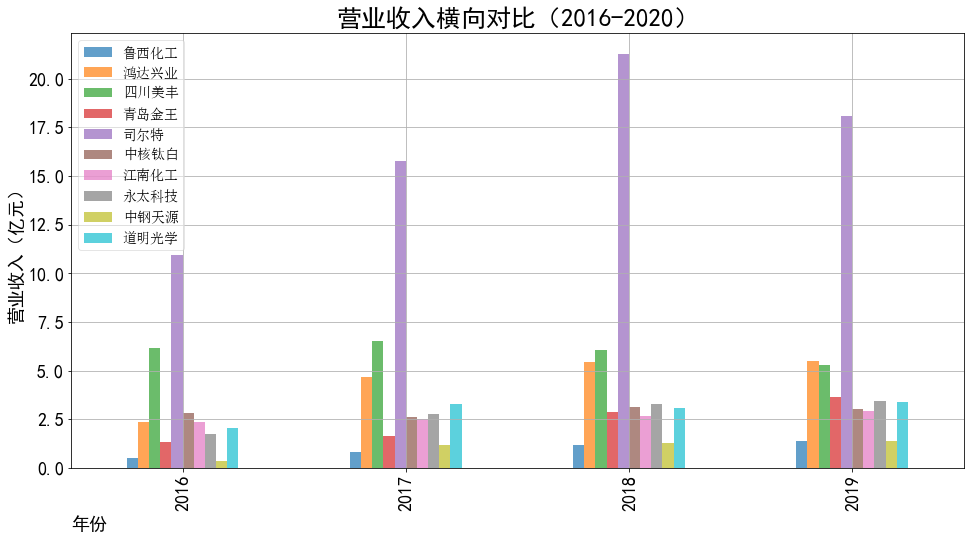
ax2.set_title('营业收入横向对比(2016-2020)',fontsize=25)
ax2.set_xlabel('年份',loc='left',fontsize=18)
ax2.set_ylabel('营业收入(亿元)',fontsize=18)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14})
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
hori_epsup=hori_eps.head(4)
hori_epsmid=hori_eps.iloc[4:8]
hori_epsdown=hori_eps.tail(3)
ax1=hori_epsup.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax1.set_title('基本每股收益横向对比(2012-2015)',fontsize=25)
ax1.set_xlabel('年份',loc='right',fontsize=18)
ax1.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14})
ax2=hori_epsmid.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax2.set_title('基本每股收益横向对比(2016-2020)',fontsize=25)
ax2.set_xlabel('年份',loc='right',fontsize=18)
ax2.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14})
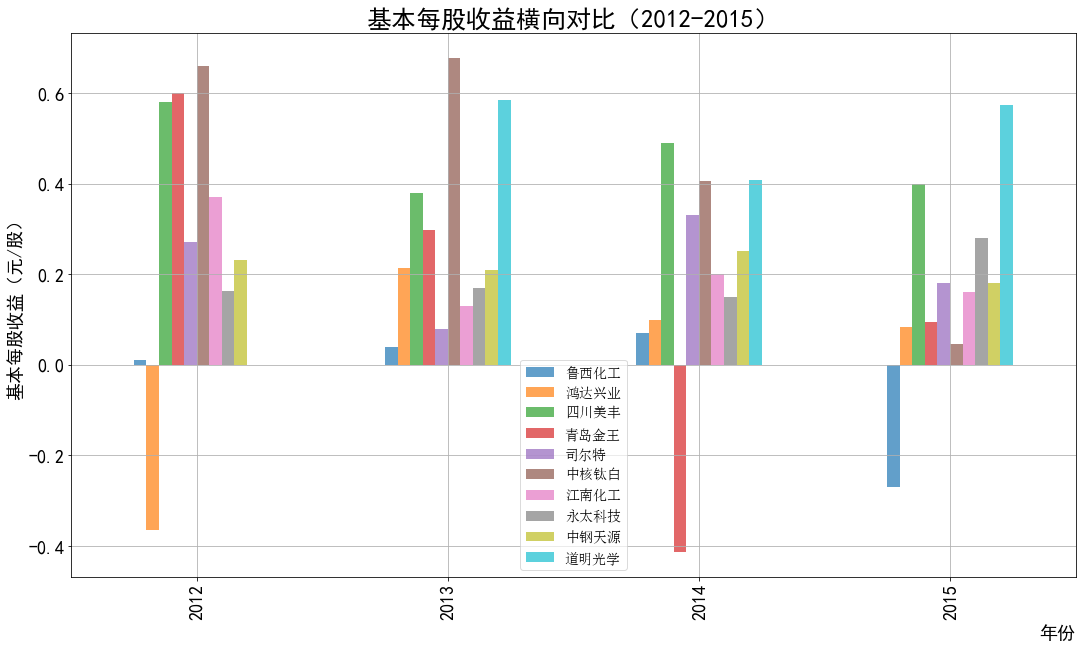
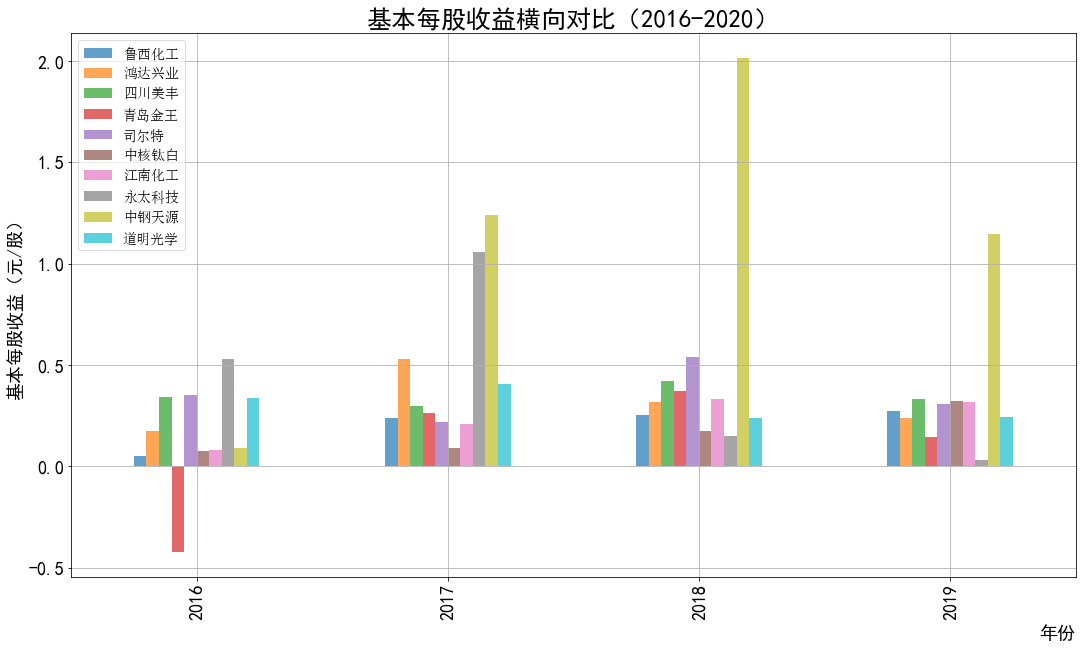
本次实验报告我所被分配到的行业是化学原料和化学制品制造业,通过此次对数据的获取与处理, 就该行业近三百家企业的营业收入和基本每股收益我都有了较为初步的理解与认识。 从营业收入的角度来看,近十年司尔特始终遥遥领先于其他公司,并且在2016至2018年营业收入有 大幅度的提升,于2019年突破20亿,但在近两年略有下降;鸿达兴业与四川美丰经营表现也很不错, 近5年营业收入都在5亿以上;相比之下,江南化工在前几年营业收入大幅度不断下降,近五年保持相 对稳定。总的来说,就统计的这十家企业,总体看来营业收入都呈现相对稳定并且有上升趋势,由 此可以推及该行业其他公司大体趋势是上升的,或者可以看出,近几年该行业的行业环境比较稳定。 从基本每股收益变化的角度来看,大部分公司的基本每股收益波动都较大,其中中钢天源、永太科 技、鸿达兴业以及青岛金王的波动幅度尤为突出;而如鲁西化工、四川美丰等小部分公司的基本每股 收益波动不大,一直保持在0-0.5元/每股之间。值得一提的是,鸿达兴业虽波动幅度较大,但其从 2012年的每股负收益逐步上升,如今以保持在0元/每股之上波动;而永太科技在2015-2017年每股 收益经历小幅度提升后出现断崖式下滑,如今每股收益仍为负数。 总体来看,该行业近十年行业环境较为稳定,并且从2019年之后的经营数据看来该行业受疫情影响 较小,企业能够较好地发展。
总的来说,本次作业对我来说真的是一个巨大的挑战。正所谓万事开头难,在还没真正着手这个 实验报告的时候只觉得一头雾水,尤其是本学期一节节网课的学习让我感觉所学知识是割裂开来 的,再加上我所被分配到的行业有近三百家公司,更是让我望而生畏。但真正开始做这份报告的 时候,又让我觉得一步一步来也没有特别复杂,从最开始自己爬取网页获取html,再到下载年报、 解析年报pdf最后整理绘图,一步一步都有迹可循。虽然在真正实操的过程中仍是经历了不少的坎, 但最终能在老师、同学的帮助以及自己的努力下完成这一份可能仍然比较粗糙有待改进的作业已经 让我收获满满!