'''
其他金融行业年度报告分析
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from parse_disclosure_table import DisclosureTable
import re
import requests
import pandas as pd
import fitz
import csv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
#报告类型选择
element = browser.find_element(By.CSS_SELECTOR,"#select_gonggao .glyphicon").click()
element = browser.find_element(By.LINK_TEXT,"年度报告").click()
#日期选择
element = browser.find_element(By.CSS_SELECTOR, ".input-left").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
element = browser.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
element = browser.find_element(By.LINK_TEXT, "6月").click()
element = browser.find_element(By.CSS_SELECTOR, ".active > .dropdown-menu li:nth-child(1)").click()
element = browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
element = browser.find_element(By.CSS_SELECTOR, ".today > .tdcontainer").click()
element = browser.find_element(By.ID, "query-btn").click()
#下载行业分类结果PDF文件
href = 'http://www.csrc.gov.cn/csrc/c100103/c1558619/1558619/files/1638277734844_11692.pdf'
r = requests.get(href,allow_redirects=True)
f = open('2021年3季度上市公司行业分类结果.pdf','wb')
f.write(r.content)
f.close()
r.close()
#获取行业分类结果PDF文件中69类行业所有上市公司
doc = fitz.open('2021年3季度上市公司行业分类结果.pdf')
page1 = doc[95]
page2 = doc[96]
toc_txt1 = page1.get_text()
toc_txt2 = page2.get_text()
r1 = re.compile('(?<=\n其他金融业\n)(.*)(?=\n)',re.DOTALL)
txt1 = r1.findall(toc_txt1)
r2 = re.compile('(?<=\n其他金融业\n)(.*?)(?=\n房地产业)',re.DOTALL)
txt2 = r2.findall(toc_txt2)
r = re.compile('(\d{6})\s*(\w+)\s*')
text1 = r.findall(txt1[0])
text2 = r.findall(txt2[0])
firm = text1 + text2
#自动控制浏览器选择所取的公司
for i in range(len(firm)):
name = firm[i][1]
code = firm[i][0]
f = open('inner_HTML_%s.html' %name,'w',encoding='utf-8')
element = browser.find_element(By.ID, "input_code").click()
element = browser.find_element(By.ID,'input_code').send_keys('%s' %code)
time.sleep(0.5)
element = browser.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
#element = browser.find_element(By.ID,'input_code')
#element.send_keys('股票名称' + Keys.RETURN)
element = browser.find_element(By.ID,'disclosure-table')
time.sleep(0.5)
innerHTML = element.get_attribute('innerHTML')
f.write(innerHTML)
time.sleep(0.5)
f.close()
element = browser.find_element(By.CSS_SELECTOR, ".selected-item:nth-child(2) > .icon-remove").click()
time.sleep(0.5)
browser.quit()
#将获取的公司年报地址存入csv文件中
for i in range(len(firm)):
name = firm[i][1]
f = open('inner_HTML_%s.html' %name,encoding='utf-8')
t = f.read()
f.close()
dt = DisclosureTable(t)
df = dt.get_data()
df.to_csv('data_%s.csv' %name)
#去除掉csv文件中的摘要文件链接
lst = {}
df5 = pd.DataFrame(columns = ['股票简称','attachpath'])
df4 = pd.DataFrame(columns = ['股票简称'])
for i in range(len(firm)):
name = firm[i][1]
df1 = pd.DataFrame(columns = ['股票简称','attachpath'])
with open('data_%s.csv' %name,'r',newline='',encoding='utf-8') as csvfile:
csvreader = csv.reader(csvfile)
reader = next(csvreader)
for row in csvreader:
r = re.compile('.*摘要.*',re.DOTALL)
f = r.findall(row[3])
if f == []:
lst1 = {}
lst['股票简称'] = name
lst['attachpath'] = row[4]
lst1['股票简称'] = name
df1 = df1.append(lst,ignore_index=True)
df4 = df4.append(lst1,ignore_index=True)
df5 = df5.append(lst,ignore_index=True)
df4 = df4.drop_duplicates()
#df1.drop(df1.index[df1['股票简称']=='简称'],inplace =True)
#df1.drop(df1.index[df1['attachpath']=='attachpath'],inplace =True)
#df4.drop(df4.index[df4['股票简称']=='简称'],inplace =True)
#下载获取的pdf文件
for k in range(len(df1[df1['股票简称']=='{}'.format(name)])):
r = requests.get(df1['attachpath'][k],allow_redirects=True)
f = open('{0}_{1}.pdf'.format(df1['股票简称'][k],k),'wb')
f.write(r.content)
f.close()
r.close()
df4.loc[df4['股票简称']=='陕国投A','股票简称'] = '陕国投A'
#提取PDF文件中“股票简称”,“股票代码”,“办公地址”,“公司网址”
df2 = pd.DataFrame(columns=['股票简称','股票代码','办公地址','公司网址'])
for x in range(len(df4)):
name = df4['股票简称'][x]
doc = fitz.open('{0}_0.pdf'.format(name))
lst = ['股票简称','股票代码','办公地址','公司[国际互联网]*网址']
pages = {}
lst_text = {}
for i in lst:
try:
p = re.compile(i,re.DOTALL)
page_number = doc.page_count#获取文件页数
#对每一页进行遍历,匹配lst中的每一个元素
for page in range(page_number):
txt = doc[page].get_text()
match = p.findall(txt)
#若匹配到的macth不为空,则提取此时的页码
if len(match) != 0:
pages[i] = page
for k,v in pages.items():
text = doc[v].get_text()
r1 = re.compile('股票简称\s+(.+?)\n',re.DOTALL)
p1 = r1.findall(text)
lst_text['股票简称'] = p1[0]
r2 = re.compile('股票代码\s+(\d+)\s+',re.DOTALL)
p2 = r2.findall(text)
lst_text['股票代码'] = p2[0]
r3 = re.compile('办公地址\s+(.+?)\n',re.DOTALL)
p3 = r3.findall(text)
lst_text['办公地址'] = p3[0]
r4 = re.compile('公司[国际互联网]*网址\s+(.*?.+?)\s+',re.DOTALL)
p4 = r4.findall(text)
lst_text['公司网址'] = p4[0]
except Exception:
print('错误')
df2 = df2.append(lst_text,ignore_index=True)
#因越秀金控的文件无法读取,所以手动写入其相关信息
doc = fitz.open('越秀金控_0.pdf')
f = doc[6].get_text()
r1 = re.compile('股票简称\s+(.+?)\n',re.DOTALL)
p1 = r1.findall(f)
lst_text['股票简称'] = p1[0]
r2 = re.compile('股票代码\s+(\d+)\s+',re.DOTALL)
p2 = r2.findall(f)
lst_text['股票代码'] = p2[0]
r3 = re.compile('办公地址\s+(.+?)\n',re.DOTALL)
p3 = r3.findall(f)
lst_text['办公地址'] = p3[0]
r4 = re.compile('公司[国际互联网]*网址\s+(.*?.+?)\s+',re.DOTALL)
p4 = r4.findall(f)
lst_text['公司网址'] = p4[0]
df2 = df2.append(lst_text,ignore_index=True)
df2 = df2.dropna(how='all')
#将提取的信息写入csv文件
df2.to_csv('公司信息.csv',encoding='utf-8')
#提取“主要会计数据和财务指标”中的“营业收入(元)”
r1 = re.compile('\s营业[总]*收入(元)\s*(-?[\d,.]+)\s*',re.DOTALL)
r2 = re.compile('\n(20[\d]{2}\s年)年度报告',re.DOTALL)
r3 = re.compile('\s基本每股收益(元/股)\s*(-?[\d,.]+)\s*',re.DOTALL)
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r1.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——营业收入.csv'.format(x),encoding='utf-8')
#提取“基本每股收益(元/股)”
for n in range(len(df4)):
x = df4['股票简称'][n]
data = pd.DataFrame()
for i in range(len(df5[df5['股票简称']=='{}'.format(x)])):
#遍历每一个PDF文件
doc = fitz.open('{0}_{1}.pdf'.format(x,i))
#读取报告年份
f2 = doc[0].get_text()
year = r2.findall(f2)
page_num = doc.page_count
#name = df4.loc[n]
for page in range(page_num):
#匹配营业收入
f1 = doc[page].get_text()
match1 = r3.findall(f1)
if match1 != []:
profit = match1[0]
data1 = pd.DataFrame(profit,index=[x],columns=year)
data = pd.concat([data1,data],join='outer',axis=1)
data.to_csv('{}——每股收益.csv'.format(x),encoding='utf-8')
'''
绘制折线图
'''
#读取营业收入数据
dt0 = pd.read_csv('指南针——营业收入.csv',encoding='utf-8')
dt0 = dt0.rename(columns={'Unnamed: 0':'Data'})
dt0 = dt0.set_index('Data')
#删除重复列
del dt0['2020 年.1']
#将数据转换为浮点型
dt0.loc['指南针'] = dt0.loc['指南针'].str.replace(',','').astype(float)
dt1 = pd.read_csv('泛海控股——营业收入.csv',encoding='utf-8')
dt1 = dt1.rename(columns={'Unnamed: 0':'Data'})
dt1 = dt1.set_index('Data')
dt1.loc['泛海控股'] = dt1.loc['泛海控股'].str.replace(',','').astype(float)
dt2 = pd.read_csv('东方能源——营业收入.csv',encoding='utf-8')
dt2 = dt2.rename(columns={'Unnamed: 0':'Data'})
dt2 = dt2.set_index('Data')
dt2.loc['东方能源'] = dt2.loc['东方能源'].str.replace(',','').astype(float)
dt3 = pd.read_csv('民生控股——营业收入.csv',encoding='utf-8')
dt3 = dt3.rename(columns={'Unnamed: 0':'Data'})
dt3 = dt3.set_index('Data')
dt3.loc['民生控股'] = dt3.loc['民生控股'].str.replace(',','').astype(float)
dt4 = pd.read_csv('陕国投A——营业收入.csv',encoding='utf-8')
dt4 = dt4.rename(columns={'Unnamed: 0':'Data'})
dt4 = dt4.set_index('Data')
dt4.loc['陕国投A'] = dt4.loc['陕国投A'].str.replace(',','').astype(float)
dt5 = pd.read_csv('海德股份——营业收入.csv',encoding='utf-8')
dt5 = dt5.rename(columns={'Unnamed: 0':'Data'})
dt5 = dt5.set_index('Data')
dt5.loc['海德股份'] = dt5.loc['海德股份'].str.replace(',','').astype(float)
dt6 = pd.read_csv('越秀金控——营业收入.csv',encoding='utf-8')
dt6 = dt6.rename(columns={'Unnamed: 0':'Data'})
dt6 = dt6.set_index('Data')
dt6.loc['越秀金控'] = dt6.loc['越秀金控'].str.replace(',','').astype(float)
dt7 = pd.read_csv('中粮资本——营业收入.csv',encoding='utf-8')
dt7 = dt7.rename(columns={'Unnamed: 0':'Data'})
dt7 = dt7.set_index('Data')
dt7.loc['中粮资本'] = dt7.loc['中粮资本'].str.replace(',','').astype(float)
dt8 = pd.read_csv('仁东控股——营业收入.csv',encoding='utf-8')
dt8 = dt8.rename(columns={'Unnamed: 0':'Data'})
dt8 = dt8.set_index('Data')
#删除重复列
del dt8['2021 年.1']
dt8.loc['仁东控股'] = dt8.loc['仁东控股'].str.replace(',','').astype(float)
dt9 = pd.read_csv('同花顺——营业收入.csv',encoding='utf-8')
dt9 = dt9.rename(columns={'Unnamed: 0':'Data'})
dt9 = dt9.set_index('Data')
dt9.loc['同花顺'] = dt9.loc['同花顺'].str.replace(',','').astype(float)
#绘制营业收入折线图
#显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
#显示负号
plt.rcParams['axes.unicode_minus'] = False
# fname为你下载的字体库路径,
# 注意 SourceHanSansSC-Bold.otf
# 字体的路径
fname = "C:\Windows\Fonts\STXINGKA.TTF"
zhfont1 = fm.FontProperties(fname=fname)
#设置显示图片清晰度
plt.rcParams['figure.dpi'] = 100
#绘制营业收入
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('营业收入',fontsize=40)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt0.loc['指南针'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('营业收入',fontsize=14)
ax0.set_title('指南针',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt1.loc['泛海控股'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('营业收入',fontsize=14)
ax1.set_title('泛海控股',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt2.loc['东方能源'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('营业收入',fontsize=14)
ax2.set_title('东方能源',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt3.loc['民生控股'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('营业收入',fontsize=14)
ax3.set_title('民生控股',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt4.loc['陕国投A'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('营业收入',fontsize=14)
ax4.set_title('陕国投A',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt5.loc['海德股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('营业收入',fontsize=14)
ax5.set_title('海德股份',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt6.loc['越秀金控'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('营业收入',fontsize=14)
ax6.set_title('越秀金控',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt7.loc['中粮资本'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('营业收入',fontsize=14)
ax7.set_title('中粮资本',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt8.loc['仁东控股'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('营业收入',fontsize=14)
ax8.set_title('仁东控股',fontsize=14)
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt9.loc['同花顺'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('营业收入',fontsize=14)
ax9.set_title('同花顺',fontsize=14)
plt.show()
#读取基本每股收益数据
dt_0 = pd.read_csv('指南针——每股收益.csv',encoding='utf-8')
dt_0 = dt_0.rename(columns={'Unnamed: 0':'Data'})
dt_0 = dt_0.set_index('Data')
#删除重复列
del dt_0['2020 年.1']
dt_0.loc['指南针'] = dt_0.loc['指南针'].astype(float)
dt_1 = pd.read_csv('泛海控股——每股收益.csv',encoding='utf-8')
dt_1 = dt_1.rename(columns={'Unnamed: 0':'Data'})
dt_1 = dt_1.set_index('Data')
dt_1.loc['泛海控股'] = dt_1.loc['泛海控股'].astype(float)
dt_2 = pd.read_csv('东方能源——每股收益.csv',encoding='utf-8')
dt_2 = dt_2.rename(columns={'Unnamed: 0':'Data'})
dt_2 = dt_2.set_index('Data')
dt_2.loc['东方能源'] = dt_2.loc['东方能源'].astype(float)
dt_3 = pd.read_csv('民生控股——每股收益.csv',encoding='utf-8')
dt_3 = dt_3.rename(columns={'Unnamed: 0':'Data'})
dt_3 = dt_3.set_index('Data')
dt_3.loc['民生控股'] = dt_3.loc['民生控股'].astype(float)
dt_4 = pd.read_csv('陕国投A——每股收益.csv',encoding='utf-8')
dt_4 = dt_4.rename(columns={'Unnamed: 0':'Data'})
dt_4 = dt_4.set_index('Data')
del dt_4['2014 年.1']
del dt_4['2014 年.2']
del dt_4['2014 年.3']
del dt_4['2021 年.1']
dt_4.loc['陕国投A'] = dt_4.loc['陕国投A'].astype(float)
dt_5 = pd.read_csv('海德股份——每股收益.csv',encoding='utf-8')
dt_5 = dt_5.rename(columns={'Unnamed: 0':'Data'})
dt_5 = dt_5.set_index('Data')
dt_5.loc['海德股份'] = dt_5.loc['海德股份'].astype(float)
dt_6 = pd.read_csv('越秀金控——每股收益.csv',encoding='utf-8')
dt_6 = dt_6.rename(columns={'Unnamed: 0':'Data'})
dt_6 = dt_6.set_index('Data')
dt_6.loc['越秀金控'] = dt_6.loc['越秀金控'].astype(float)
dt_7 = pd.read_csv('中粮资本——每股收益.csv',encoding='utf-8')
dt_7 = dt_7.rename(columns={'Unnamed: 0':'Data'})
dt_7 = dt_7.set_index('Data')
dt_7.loc['中粮资本'] = dt_7.loc['中粮资本'].astype(float)
dt_8 = pd.read_csv('仁东控股——每股收益.csv',encoding='utf-8')
dt_8 = dt_8.rename(columns={'Unnamed: 0':'Data'})
dt_8 = dt_8.set_index('Data')
del dt_8['2021 年.1']
dt_8.loc['仁东控股'] = dt_8.loc['仁东控股'].astype(float)
dt_9 = pd.read_csv('同花顺——每股收益.csv',encoding='utf-8')
dt_9 = dt_9.rename(columns={'Unnamed: 0':'Data'})
dt_9 = dt_9.set_index('Data')
dt_9.loc['同花顺'] = dt_9.loc['同花顺'].astype(float)
#绘制基本每股收益
fig = plt.figure(figsize=(15,20))
plt.subplots_adjust(wspace=0.3,hspace=0.6)
fig.suptitle('基本每股收益',fontsize=30)
ax0 = fig.add_subplot(5,2,1)
ax0.plot(dt_0.loc['指南针'])
ax0.set_xlabel('年 份',fontsize=14)
ax0.set_ylabel('基本每股收益',fontsize=14)
ax0.set_title('指南针',fontsize=14)
ax1 = fig.add_subplot(5,2,2)
ax1.plot(dt_1.loc['泛海控股'])
ax1.set_xlabel('年 份',fontsize=14)
ax1.set_ylabel('基本每股收益',fontsize=14)
ax1.set_title('泛海控股',fontsize=14)
ax2 = fig.add_subplot(5,2,3)
ax2.plot(dt_2.loc['东方能源'])
ax2.set_xlabel('年 份',fontsize=14)
ax2.set_ylabel('基本每股收益',fontsize=14)
ax2.set_title('东方能源',fontsize=14)
ax3 = fig.add_subplot(5,2,4)
ax3.plot(dt_3.loc['民生控股'])
ax3.set_xlabel('年 份',fontsize=14)
ax3.set_ylabel('基本每股收益',fontsize=14)
ax3.set_title('民生控股',fontsize=14)
ax4 = fig.add_subplot(5,2,5)
ax4.plot(dt_4.loc['陕国投A'])
ax4.set_xlabel('年 份',fontsize=14)
ax4.set_ylabel('基本每股收益',fontsize=14)
ax4.set_title('陕国投A',fontsize=14)
ax5 = fig.add_subplot(5,2,6)
ax5.plot(dt_5.loc['海德股份'])
ax5.set_xlabel('年 份',fontsize=14)
ax5.set_ylabel('基本每股收益',fontsize=14)
ax5.set_title('海德股份',fontsize=14)
ax6 = fig.add_subplot(5,2,7)
ax6.plot(dt_6.loc['越秀金控'])
ax6.set_xlabel('年 份',fontsize=14)
ax6.set_ylabel('基本每股收益',fontsize=14)
ax6.set_title('越秀金控',fontsize=14)
ax7 = fig.add_subplot(5,2,8)
ax7.plot(dt_7.loc['中粮资本'])
ax7.set_xlabel('年 份',fontsize=14)
ax7.set_ylabel('基本每股收益',fontsize=14)
ax7.set_title('中粮资本',fontsize=14)
ax8 = fig.add_subplot(5,2,9)
ax8.plot(dt_8.loc['仁东控股'])
ax8.set_xlabel('年 份',fontsize=14)
ax8.set_ylabel('基本每股收益',fontsize=14)
ax8.set_title('仁东控股',fontsize=14)
ax9 = fig.add_subplot(5,2,10)
ax9.plot(dt_9.loc['同花顺'])
ax9.set_xlabel('年 份',fontsize=14)
ax9.set_ylabel('基本每股收益',fontsize=14)
ax9.set_title('同花顺',fontsize=14)
plt.show()
#绘制对比图
import numpy as np
dt = pd.concat([dt0,dt1,dt2,dt3,dt4,dt5,dt6,dt7,dt8,dt9])
index_row = dt.index
index_columns = dt.columns
#利用pd.values.T对dataframe进行转置
dt = pd.DataFrame(dt.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt))
plt.bar(index,dt['指南针'],width=0.05)
plt.bar(index+0.08,dt['泛海控股'],width=0.08)
plt.bar(index+0.16,dt['东方能源'],width=0.08)
plt.bar(index+0.24,dt['民生控股'],width=0.08)
plt.bar(index+0.32,dt['陕国投A'],width=0.08)
plt.bar(index+0.4,dt['海德股份'],width=0.08)
plt.bar(index+0.48,dt['越秀金控'],width=0.08)
plt.bar(index+0.56,dt['中粮资本'],width=0.08)
plt.bar(index+0.64,dt['仁东控股'],width=0.08)
plt.bar(index+0.72,dt['同花顺'],width=0.08)
plt.legend(['指南针','泛海控股','东方能源','民生控股','陕国投A','海德股份',
'越秀金控','中粮资本','仁东控股','同花顺'])
plt.xticks(index+0.3,dt.index)
dt_ = pd.concat([dt_0,dt_1,dt_2,dt_3,dt_4,dt_5,dt_6,dt_7,dt_8,dt_9])
index_row = dt_.index
index_columns = dt_.columns
dt_ = pd.DataFrame(dt_.values.T,columns=index_row,index=index_columns)
index = np.arange(len(dt_))
plt.bar(index,dt_['指南针'],width=0.08)
plt.bar(index+0.08,dt_['泛海控股'],width=0.08)
plt.bar(index+0.16,dt_['东方能源'],width=0.08)
plt.bar(index+0.24,dt_['民生控股'],width=0.08)
plt.bar(index+0.32,dt_['陕国投A'],width=0.08)
plt.bar(index+0.40,dt_['海德股份'],width=0.08)
plt.bar(index+0.48,dt_['越秀金控'],width=0.08)
plt.bar(index+0.56,dt_['中粮资本'],width=0.08)
plt.bar(index+0.64,dt_['仁东控股'],width=0.08)
plt.bar(index+0.72,dt_['同花顺'],width=0.08)
plt.legend(['指南针','泛海控股','东方能源','民生控股','陕国投A','海德股份',
'越秀金控','中粮资本','仁东控股','同花顺'])
plt.xticks(index+0.3,dt_.index)
营业收入折线图
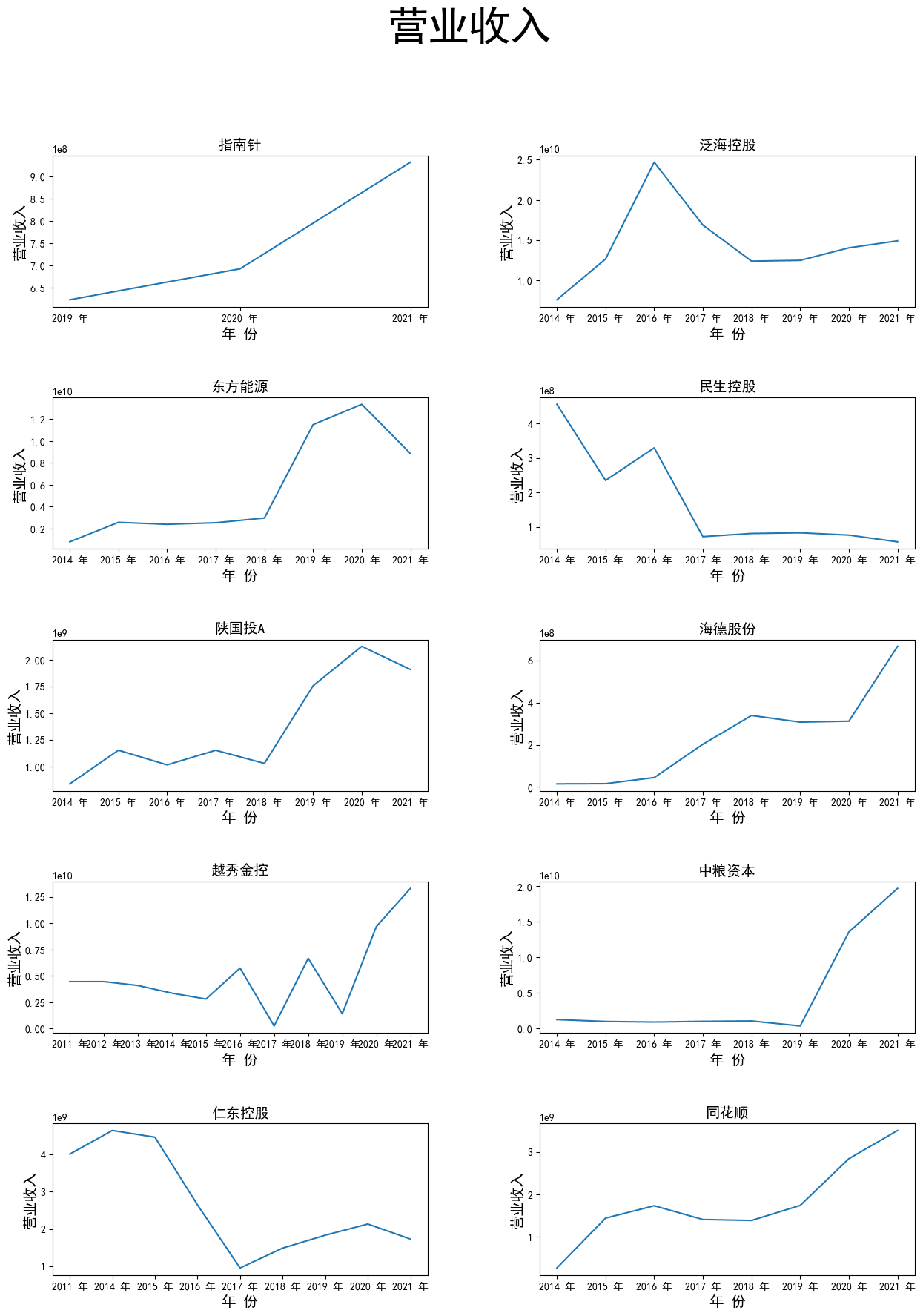
据上图可知绝大部分上市公司在2019年至2021年营业收入呈现上升趋势, 只有少数几家公司营业收入在下滑。
基本每股收益折线图
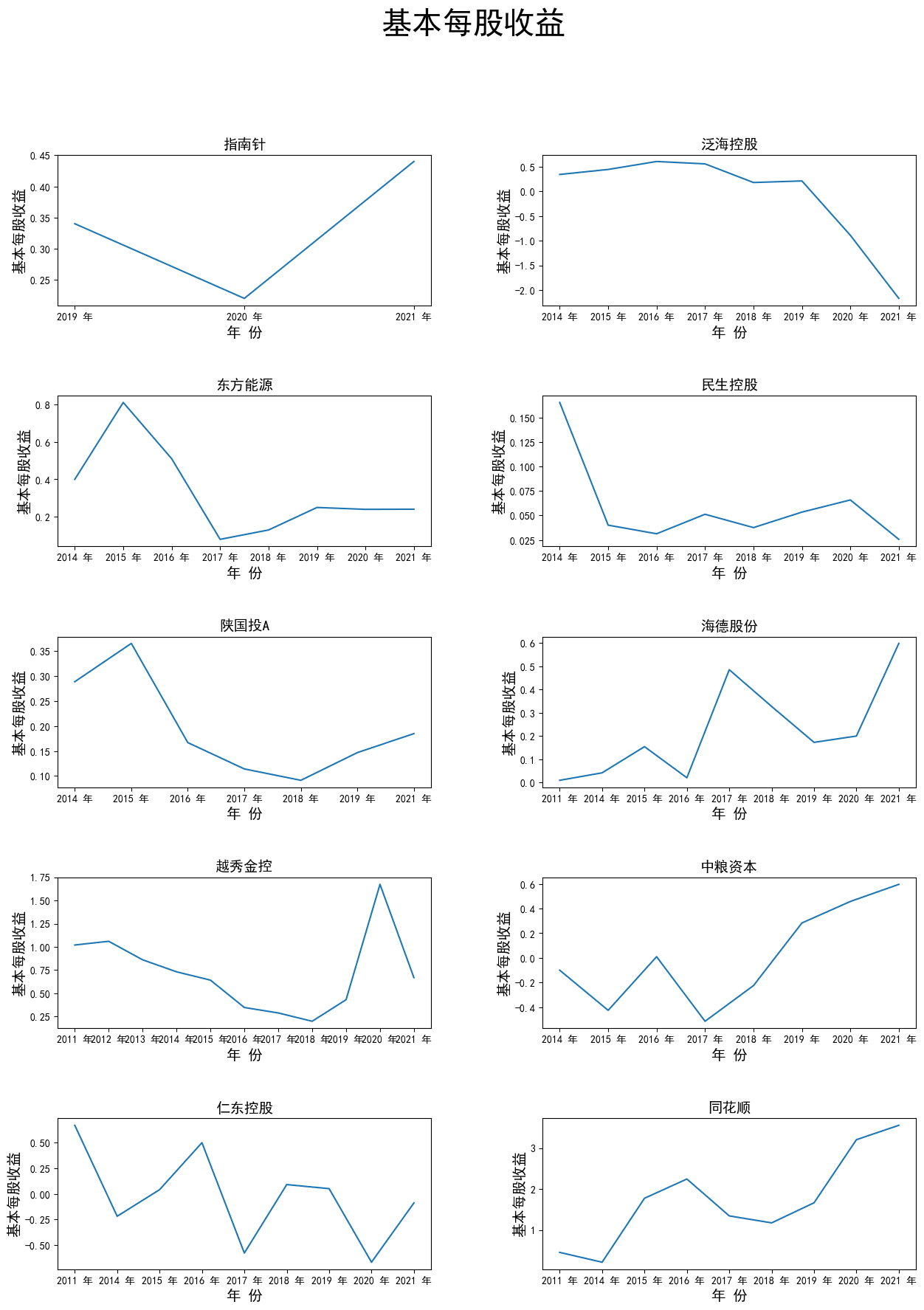
由上图可知,泛海控股、仁东控股最近三年基本每股收益处于负值,而中粮资本 由开始的负的基本每股收益变成了如今正的基本每股收益,公司在不断走好。大 部分上市公司的基本每股收益围绕着0.3、0.4上下波动,而同花顺的基本每股收 益一路高涨,达到了3.5的高度。
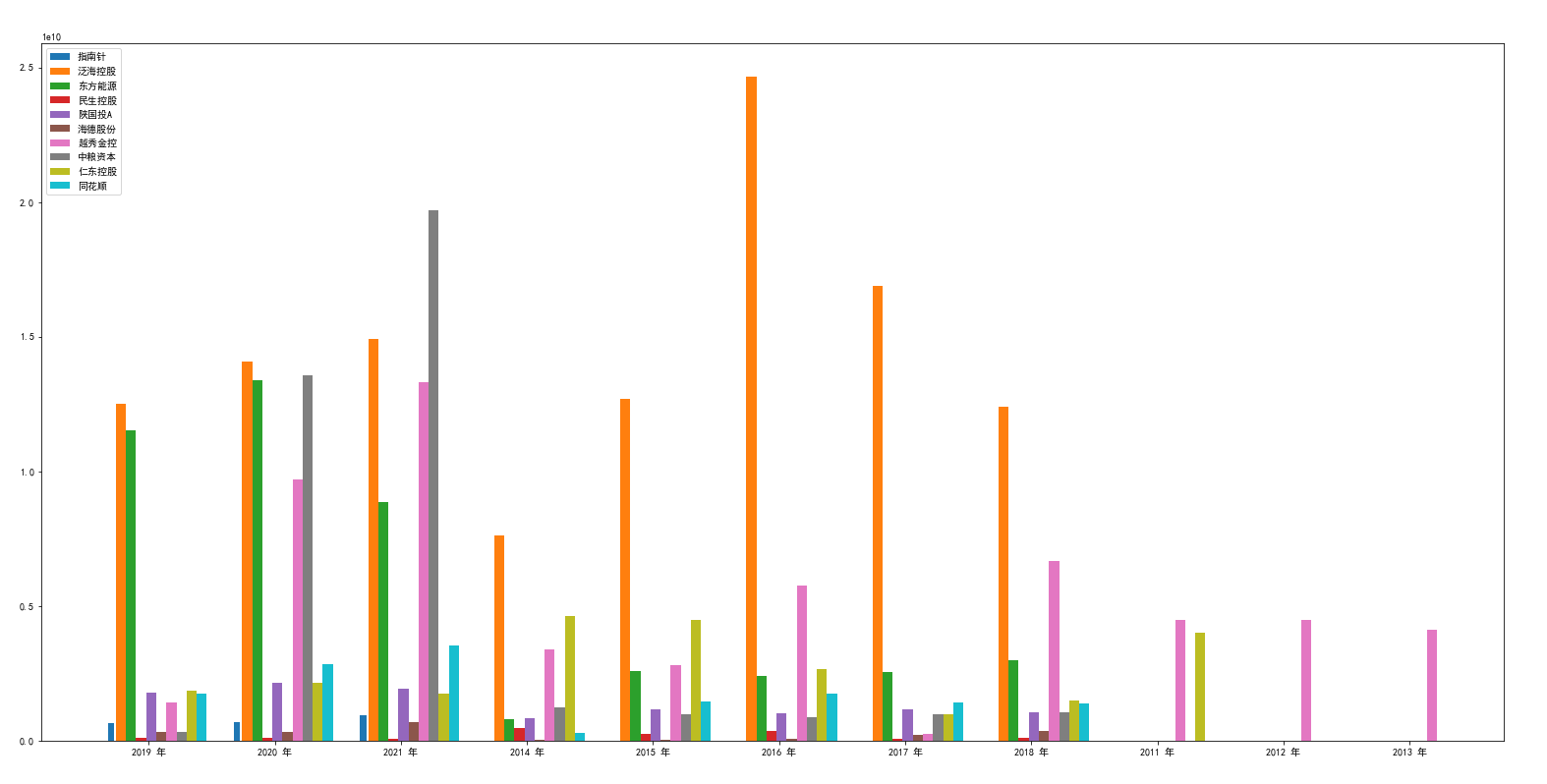
营业收入对比图
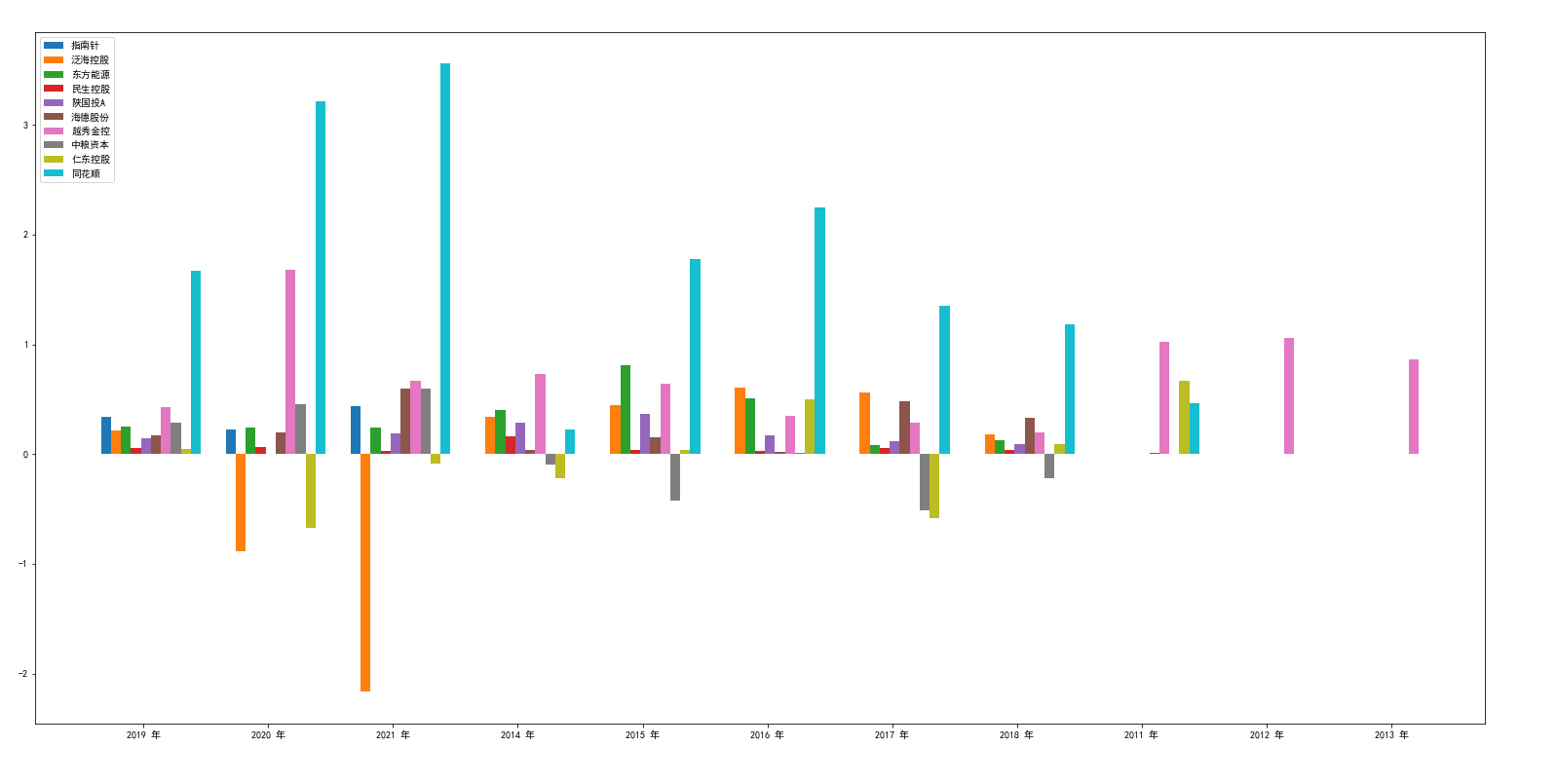
基本每股收益对比图
股票代码、股票简称、公司网址、办公地址

年报链接

首先,利用selenium对浏览器进行自动控制并对此获取所需上市公司的年报链接; 其次,利用requests对所获取的年报链接进行下载,并利用正则表达式和循环语句对 股票代码、股票简称、公司网址、办公地址进行匹配,并将该信息写入csv文件中;然 后再利用正则表达式对营业收入及基本每股收益进行匹配,并分别写入csv文件;最后, 利用matplotlib对其所提取的数据进行绘图。