import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from parse_disclosure_table import * #引用老师的DisclosureTable类,将py文件置于统一工作目录下
browser = webdriver.Chrome() #使用Chrome浏览器
browser.maximize_window()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html') #输入网址
#下载数据
search = browser.find_element(By.ID, 'input_code') #定位搜索框
search.send_keys('科大讯飞' + Keys.RETURN) #输入股票名称
#time.sleep(6)
element = browser.find_element(By.ID, 'disclosure-table') #获取披露表,此处应和上述代码分开运行
innerHTML = element.get_attribute('innerHTML') #获取html代码
def html_to_df(innerHTML):
f = open('innerHTML.html','w',encoding='utf-8') #创建html文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html', encoding="utf-8")
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data() #提取信息
return df
#提取数据
df = html_to_df(innerHTML)
Nextpage = browser.find_element(By.LINK_TEXT, "下一页>") #翻页对象
i = 'c'
while True: #进行翻页处理
Nextpage = browser.find_element(By.LINK_TEXT, "下一页>")
Nextpage.click()
time.sleep(3) #暂停3秒保证网页成功加载
innerHTML1 = element.get_attribute('innerHTML')
df1 = html_to_df(innerHTML1)
if i==df1.iloc[0,2]: #当翻页不能改变所获取数据时终止
browser.quit()
break
df = df.append(df1)
i = df1.iloc[0,2]
#df.to_csv('科大讯飞报告.csv')
提取数据的DisclosureTable类和方法代码⬇️(需将代码放在同一工作目录下)
parse_disclosure_table.py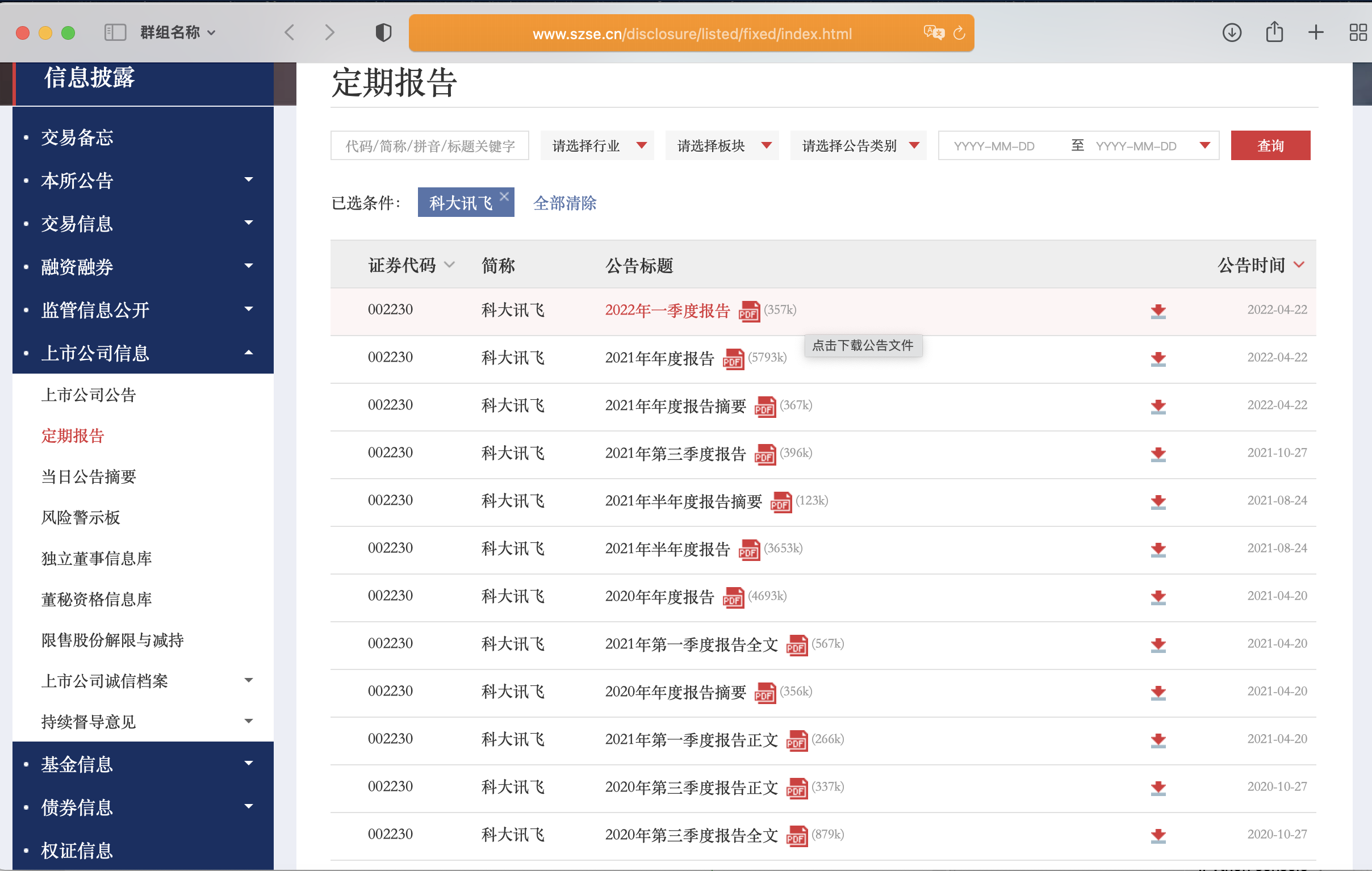
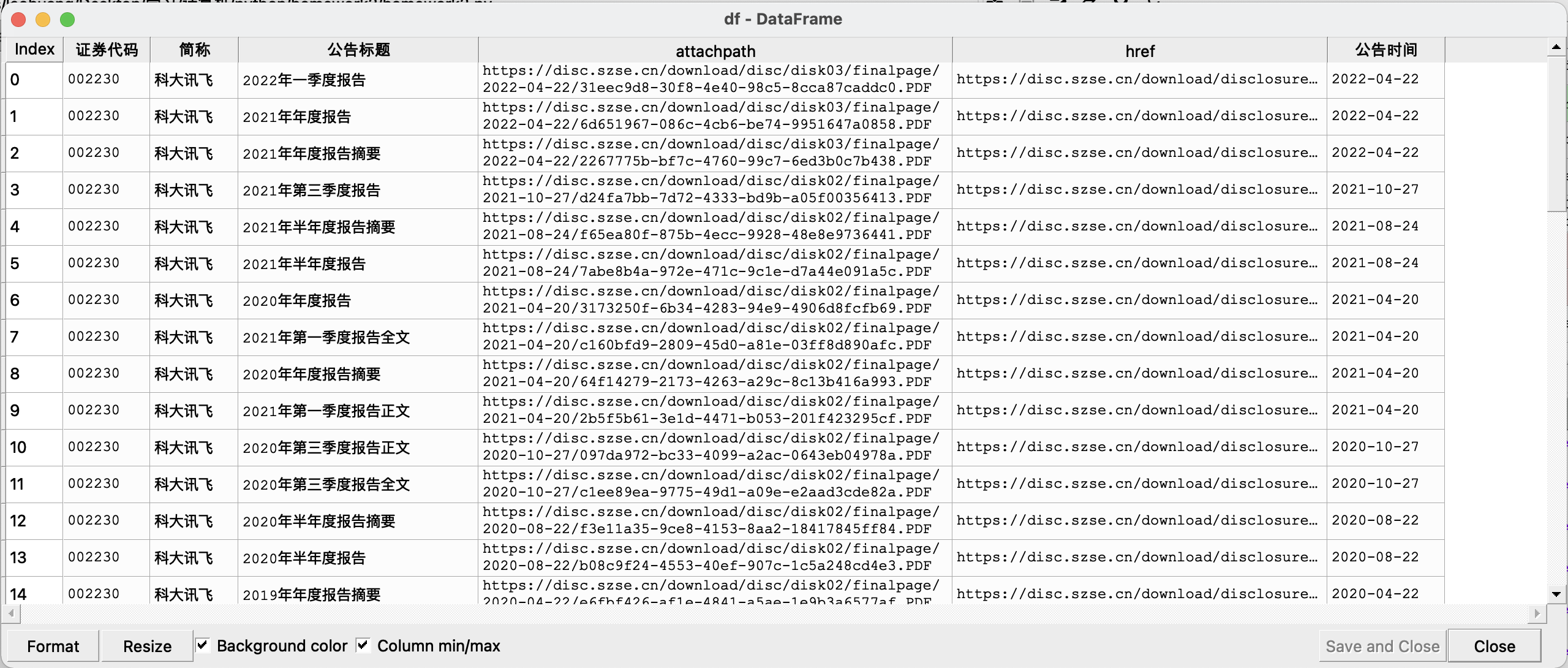
通过Selenium库自动化访问网页,定位网页源码中的搜索框,对其进行输入股票和回车操作,进入新网页后获取披露表Html,读取Html文件,通过DisclosureTable类提取数据,获得所有披露信息。应该注意到报告往往不止一页,使用Selenium的LINK_TEXT属性定位下一页的文字,用.click()方法点击即可实现翻页,这里我用了一个简单的循环对网站进行连续翻页并且每次翻页过后暂停三秒保证网页成功显示,用与上述同样的方法获取披露表,if条件判断的是翻页后新获取的df中元素如果不再更新则终止循环,说明已经到达最后一页,每次循环都将新获取的df1通过append()函数加入到df中,从而获得完整的结果。 (这次作业我一开始用的是Safari浏览器,但是在Safari中click()方法对定位的翻页对象进行操作似乎没有响应,此处推荐使用Chrome浏览器)