import fitz
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
#获取行业分类中,航空运输业的上市公司基本信息,用于后续循环操作
doc = fitz.open('行业分类.pdf')
p = re.compile('(\d+)\n\*?(.*)')
result = []
for page in doc.pages(83,85):
txt = page.get_text()
result = result+p.findall(txt)
result = sorted(set(result), key=result.index)
beg = 0
end = 0
for t in result:
if t[0]=='56':
beg = result.index(t)
elif t[0]=='58':
end = result.index(t)
df = pd.DataFrame({'行业大类代码': result[beg][0],
'行业大类名称': result[beg][1],
'上市公司代码': [t[0] for t in result[beg+1:end]],
'上市公司简称': [t[1] for t in result[beg+1:end]]})
df.to_csv('行业信息.csv')
#爬取深交所上市公司年报链接
browser = webdriver.Edge()
class DisclosureTable_sz():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?) ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
self.txt_to_df()
def txt_to_df(self):
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
browser.implicitly_wait(5)
for name in df.iloc[0:4,3]:
element = browser.find_element(By.ID, 'input_code')
element.send_keys(name + Keys.RETURN)
browser.find_element(By.LINK_TEXT, '请选择公告类别').click()
browser.find_element(By.LINK_TEXT, '年度报告').click()
y_start = browser.find_element(By.CLASS_NAME, 'input-left')
y_start.send_keys('2013' + Keys.RETURN)
y_end = browser.find_element(By.CLASS_NAME, 'input-right')
y_end.send_keys('2023' + Keys.RETURN)
time.sleep(1)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
browser.find_element(By.CSS_SELECTOR, ".btn-clearall").click()
html = innerHTML
dt = DisclosureTable_sz(html)
df1 = dt.get_data()
p = re.compile(".*?(\*).*?")
biaoti = [p.sub("",t) for t in df1['公告标题']]
df1['公告标题'] = biaoti;del p,biaoti
df1.to_csv(name+'.csv')
browser.quit()
#爬取上交所上市公司年报链接
class DisclosureTable_sh():
'''
解析上交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix_href = 'http://www.sse.com.cn/'
p_span = re.compile('(.*?)', re.DOTALL)
self.get_span = lambda txt: p_span.search(txt).group(1).strip()
self.txt_to_df()
def txt_to_df(self):
html = self.html
p = re.compile('(.+?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
href = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
def get_data(self):
get_span = self.get_span
get_link = self.get_link
df = self.df_txt
codes = [get_span(td) for td in df['证券代码']]
short_names = [get_span(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [td for td in df['公告时间']]
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def check_nextpage(driver):
try:
driver.find_element(By.LINK_TEXT, '下一页')
return True
except:
return False
browser = webdriver.Edge()
browser.implicitly_wait(5)
i = 4
for code in df.iloc[4:,2]:
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
time.sleep(1)
element = browser.find_element(By.ID, 'inputCode')
element.send_keys(code)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1)
element = browser.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
html = innerHTML
dt = DisclosureTable_sh(html)
df1 = dt.get_data()
if check_nextpage(browser) == True:
while True:
nextpage = browser.find_element(By.LINK_TEXT,'下一页')
nextpage.click()
time.sleep(1)
element = browser.find_element(By.CLASS_NAME, 'table-responsive')
innerHTML = element.get_attribute('innerHTML')
html = innerHTML
dt = DisclosureTable_sh(html)
df2 = dt.get_data()
df1 = df1.append(df2)
break
df1.reset_index(drop=True,inplace=True)
name = df.iloc[i,3]
p = re.compile(".*?(\*).*?")
biaoti = [p.sub("",t) for t in df1['公告标题']]
df1['公告标题'] = biaoti;del p,biaoti
df1.to_csv(name+'.csv')
i = i+1
browser.quit()
import pandas as pd
import requests
import os
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
#链接筛选
def filter_links(words,df,include = True):
ls=[]
for word in words:
if include:
ls.append([word in f for f in df['公告标题']])
else:
ls.append([word not in f for f in df['公告标题']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
for name in df['上市公司简称']:
df1 = pd.read_csv(name+'.csv',index_col=0,dtype=(str))
df_all = filter_links(['摘要','意见','关于','情况','补充','说明','计划','公告'],df1,include = False)
df_orig = filter_links(["(","("],df_all,include = False)
df_orig.reset_index(drop=True,inplace=True)
df_orig = df_orig.iloc[:10]
df_orig.to_csv(name+'new.csv')
#建立文件夹,下载年报并放入文件夹
path = os.getcwd()
j = 0
for name in df['上市公司简称']:
df1 = pd.read_csv(name+'new.csv',index_col=0,dtype=(str))
os.makedirs(path+'\\'+name,exist_ok = True)
os.chdir(path+'\\'+name)
for i in range(len(df1)):
href = df1.iloc[i,3]
r = requests.get(href, allow_redirects=True)
biaoti = df1.iloc[i,2]
riqi = df1.iloc[i,-1]
f = open(biaoti+'('+riqi+')'+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
j = j+1
print(name+'年报下载进度:'+str(i+1)+'/'+str(len(df1)))
os.chdir('../')
print('总共下载完成'+str(j)+'份年报')
详细内容可通过以下链接查看:
#提取营业收入
import fitz
import re
import pandas as pd
import os
import numpy as np
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
path = os.getcwd()
df_revenue = pd.DataFrame()
for name in df['上市公司简称']:
file_list = []
for files in os.walk(path+'\\'+name):
for file in files[2]:
file_list.append(file)
df1 = pd.DataFrame(columns=[name+'主营业务收入',name+'主营业务收入单位'])
for file in file_list:
doc = fitz.open(path+'\\'+name+'\\'+file)
year = doc.name[-15:-11]
year = int(year)
year = year-1
year = str(year)
text = ''
for page in doc:
text += page.get_text()
text = text.replace("�","")
text = text.replace(" ","\n")
text = text.replace("\n\n\n\n","\n")
text = text.replace("\n\n\n","\n")
text = text.replace("\n\n","\n")
doc.close()
p1 = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据\D*?(?=\\n)(.*?)经营活动产生的|(?<=\\n)[\D、]?\D*?主要\D*?數據\D*?(?=\\n)(.*?)經營活動產生的',re.DOTALL)
content = p1.search(text)
if content != None:
content = content.group(0)
subp = "([0-9,.%\- ]*?\n)"
p2 = re.compile("(?<=\\n)[营业|營業](\D*?\n+)(%s)" % subp)
lines = p2.search(content)
if lines != None:
lines = lines[2]
lines = lines.split('\n')
revenue = lines[0]
if ',' not in revenue:
subp = '([0-9,.%\- ]*?\n,?)'
p2 = re.compile("(?<=\\n)[营业|營業](\D*?\n+)(%s%s%s)" % (subp,subp,subp))
lines = p2.search(content)
if lines !=None:
lines = lines[2]
lines = lines.replace('\n','')
revenue = lines
if ',' not in revenue:
subp = '([0-9,.%\- ]*?\n?)'
p2 = re.compile("(?<=\\n)[营业|營業]([\D\d\n]*?)(%s)(?=\\n0)" % subp, re.DOTALL)
lines = p2.search(content)
if lines !=None:
lines = lines[2]
lines = lines.replace('\n','')
revenue = lines
if ',' not in revenue:
print(name+year+'年年报营业收入查找可能出错,请手动检查')
revenue = np.nan
else:
print(name+year+'年年报营业收入查找可能出错,请手动检查')
revenue = np.nan
else:
print(name+year+'年年报营业收入查找可能出错,请手动检查')
revenue = np.nan
p3 = re.compile('(?<=\n)\D*?单位:?(.*?)(?=\n)|(?<=\n)單位:?(.*?)(?=\n)',re.DOTALL)
danwei = p3.search(content)
if danwei != None:
if danwei.group(1) !=None:
danwei = danwei.group(1)
danwei = danwei.replace(')', '')
if '元' not in danwei :
danwei = np.nan
print(name+year+'年年报营业收入单位查找可能出错,请手动检查')
else:
danwei = danwei.group(2)
danwei = danwei.replace(')', '')
if '元' not in danwei :
danwei = np.nan
print(name+year+'年年报营业收入单位查找可能出错,请手动检查')
else:
danwei = '元'
df1.loc[year] = [revenue,danwei]
else:
print(name+year+'年年报营业收入查找失败')
else:
print(name+year+'年年报财务数据文本定位失败')
df1 = df1.sort_index()
df_revenue = pd.concat([df_revenue,df1],axis=1)
#无法正常提取的进行手动填充
df_revenue.loc['2013','中国东航主营业务收入'] = '88,009,236'
df_revenue.loc['2013','中国东航主营业务收入单位'] = '千元'
df_revenue = df_revenue.reset_index(drop=False)
df_revenue.rename(columns = {"index":"年份"}, inplace=True)
df_revenue = df_revenue.set_index(['年份'])
df_revenue.to_csv('航空运输业主营业务收入数据raw.csv')
#把数字里的逗号去掉,并转换为浮点数
for i in range(len(df_revenue)):
for j in range(0,len(df_revenue.columns),2):
if pd.notnull(df_revenue.iloc[i,j]):
df_revenue.iloc[i,j] = df_revenue.iloc[i,j].replace(',','')
df_revenue.iloc[i,j] = float(df_revenue.iloc[i,j])
#把单位统一转换为元
for i in range(len(df_revenue)):
for j in range(1,len(df_revenue.columns),2):
if pd.notnull(df_revenue.iloc[i,j]):
if '百万' in df_revenue.iloc[i,j]:
df_revenue.iloc[i,j-1] = df_revenue.iloc[i,j-1]*1000000
df_revenue.iloc[i,j] = '元'
elif '百萬' in df_revenue.iloc[i,j]:
df_revenue.iloc[i,j-1] = df_revenue.iloc[i,j-1]*1000000
df_revenue.iloc[i,j] = '元'
elif '万' in df_revenue.iloc[i,j]:
df_revenue.iloc[i,j-1] = df_revenue.iloc[i,j-1]*10000
df_revenue.iloc[i,j] = '元'
elif '千' in df_revenue.iloc[i,j]:
df_revenue.iloc[i,j-1] = df_revenue.iloc[i,j-1]*1000
df_revenue.iloc[i,j] = '元'
df_revenue.drop(df_revenue.columns[[1,3,5,7,9,11,13,15,17,19,21,23,25,27]], axis=1, inplace=True)
df_revenue.to_csv('航空运输业主营业务收入数据.csv')
#提取基本每股收益
import fitz
import re
import pandas as pd
import os
import numpy as np
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
path = os.getcwd()
df_eps = pd.DataFrame()
for name in df['上市公司简称']:
file_list = []
for files in os.walk(path+'\\'+name):
for file in files[2]:
file_list.append(file)
df1 = pd.DataFrame(columns=[name+'基本每股收益'])
for file in file_list:
doc = fitz.open(path+'\\'+name+'\\'+file)
year = doc.name[-15:-11]
year = int(year)
year = year-1
year = str(year)
text = ''
for page in doc:
text += page.get_text()
text = text.replace("�","")
text = text.replace(" ","\n")
text = text.replace("\n\n\n\n","\n")
text = text.replace("\n\n\n","\n")
text = text.replace("\n\n","\n")
doc.close()
p1 = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据\D*?(?=\\n)(.*?)稀释每股\D*?收益|(?<=\\n)[\D、]?\D*?主要\D*?數據\D*?(?=\\n)(.*?)稀釋每股\D*?收益',re.DOTALL)
content = p1.search(text)
if content != None:
content = content.group(0)
subp = "([0-9.%\-() ]*?\n)"
p2 = re.compile("(?<=\\n)基本每股\D*?收益\D*?\n+(%s)" % subp)
lines = p2.search(content)
if lines != None:
lines = lines[1]
lines = lines.replace('\n', '')
lines = lines.replace('(', '-')
lines = lines.replace(')', '')
eps = lines
df1.loc[year] = [eps]
else:
p1 = re.compile('(?<=\\n)[\D、]?\D*?主要\D*?数据\D*?(?=\\n)(.*?)经营活动产生的|(?<=\\n)[\D、]?\D*?主要\D*?數據\D*?(?=\\n)(.*?)經營活動產生的',re.DOTALL)
content = p1.search(text)
if content != None:
content = content.group(0)
subp = "([0-9.%\-() ]*?\n)"
p2 = re.compile("(?<=\\n)每股收益\D*?元\D*?\n+(%s)" % subp)
lines = p2.search(content)
if lines != None:
lines = lines[1]
lines = lines.replace('\n', '')
lines = lines.replace('(', '-')
lines = lines.replace(')', '')
eps = lines
df1.loc[year] = [eps]
else:
print(name+year+'年年报基本每股收益查找失败')
else:
print(name+year+'年年报基本每股收益查找失败')
else:
print(name+year+'年年报财务数据文本定位失败')
df1 = df1.sort_index()
df_eps = pd.concat([df_eps,df1],axis=1)
#无法正常提取的进行手动填充
df_eps.loc['2013','中国东航基本每股收益'] = '0.1965'
df_eps = df_eps.reset_index(drop=False)
df_eps.rename(columns = {"index":"年份"}, inplace=True)
df_eps = df_eps.set_index(['年份'])
df_eps.to_csv('航空运输业基本每股收益数据.csv')
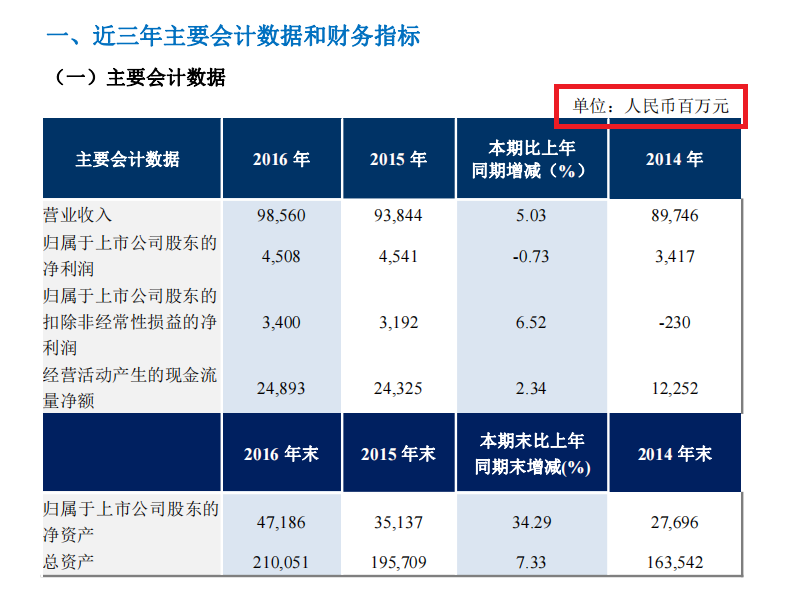

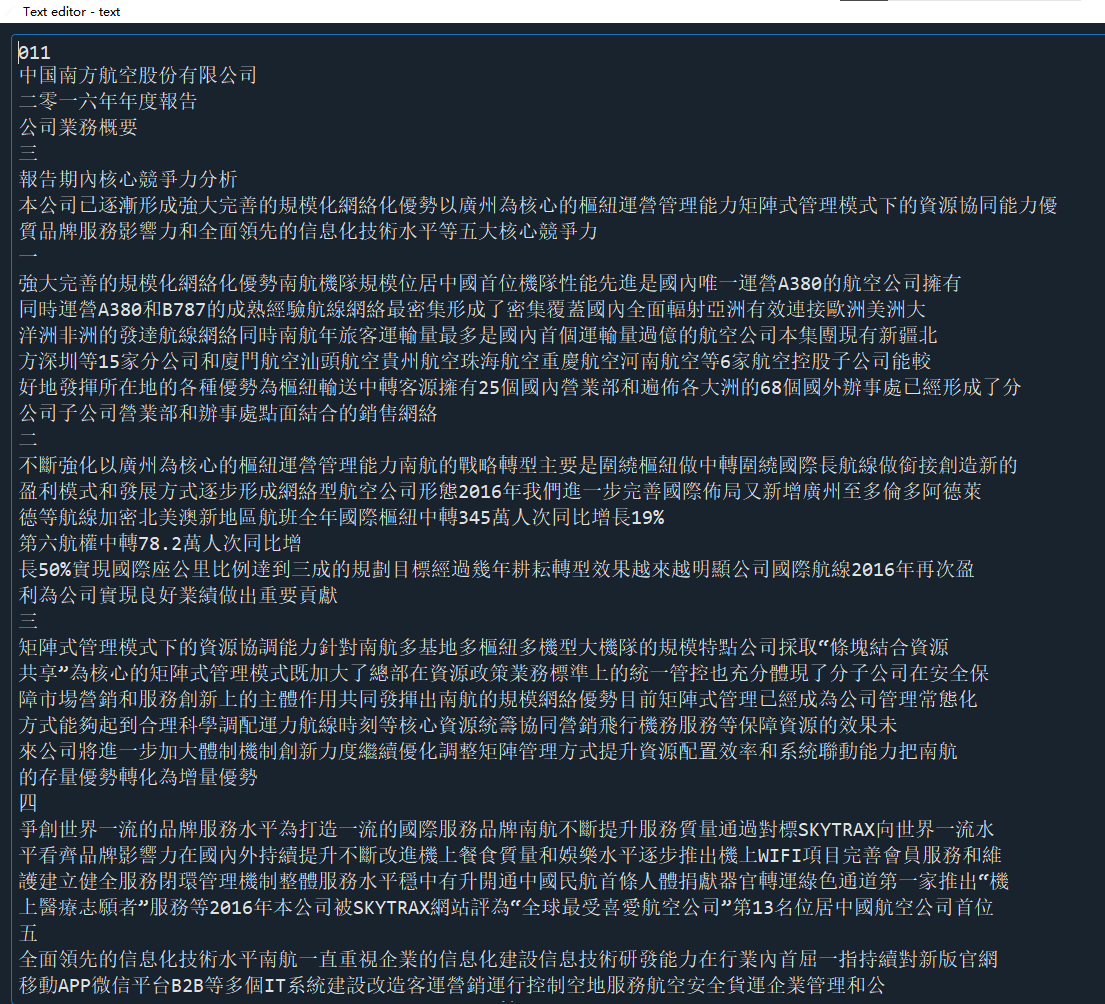
文本顺序完全打乱,数据被拆分重新排列组合。
比如2013年中国东航年报(东方航空2013年年报.pdf)的营业收入,本来为'88,009,236',但是导入后完整的数字被拆开并打乱顺序。

详细内容可通过以下链接查看:

详细内容可通过以下链接查看:
import fitz
import re
import pandas as pd
import os
import numpy as np
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
path = os.getcwd()
df_information = pd.DataFrame()
for name in df['上市公司简称']:
file_list = []
for files in os.walk(path+'\\'+name):
for file in files[2]:
file_list.append(file)
df1 = pd.DataFrame(columns=[name+'股票简称',name+'股票代码',name+'办公地址',name+'公司网址'])
for file in file_list:
doc = fitz.open(path+'\\'+name+'\\'+file)
year = doc.name[-15:-11]
year = int(year)
year = year-1
year = str(year)
text = ''
for page in doc:
text += page.get_text()
text = text.replace("�","")
text = text.replace(" ","\n")
text = text.replace("\n\n\n\n","\n")
text = text.replace("\n\n\n","\n")
text = text.replace("\n\n","\n")
doc.close()
p1 = re.compile('(?<=\\n)\D、?\n*公司信息(?=\\n)(.*?)(?<=\\n)[\D、]?\D*?主要\D*?数据\D*?(?=\\n)|(?<=\\n)[\D、]?\n*公司資料(?=\\n)(.*?)(?<=\\n)[\D、]?\D*?主要\D*?數據\D*?(?=\\n)',re.DOTALL)
content = p1.search(text)
if content != None:
content = content.group(0)
p2 = re.compile("(?<=\\n)\D*?简称:?\n*(.*?\n[B]?).*?(?=\\n)|(?<=\\n)\D*?簡稱:?\n*(.*?\n[B]?).*?(?=\\n)",re.DOTALL)
lines = p2.search(content)
if lines !=None:
if lines[1] !=None:
short_name = lines[1].replace('\n', '')
if '股票' in short_name:
p2 = re.compile("(?<=\\n)\D*?证券交易所\n+(.*?)(?=\\n)",re.DOTALL)
lines = p2.search(content)
if lines !=None:
short_name = lines[1].replace('\n', '')
else:
print(name+year+'年年报股票简称查找失败')
short_name = np.nan
else:
short_name = lines[2].replace('\n', '')
else:
print(name+year+'年年报股票简称查找失败')
short_name = np.nan
p3 = re.compile("(?<=\\n)股票代码.*?(\d+)(?=\\n)|(?<=\\n)\D*?代碼.*?(\d+)(?=\\n)",re.DOTALL)
lines = p3.search(content)
if lines !=None:
if lines[1] !=None:
code = lines[1]
if len(code)<6:
p3 = re.compile("(?<=\\n)\D*?A股.*?(\d+)(?=\\n)",re.DOTALL)
lines = p3.search(content)
if lines !=None:
code = lines[1]
else:
print(name+year+'年年报股票代码查找失败')
code = np.nan
else:
code = lines[2]
else:
print(name+year+'年年报股票代码查找失败')
code = np.nan
p4 = re.compile("(?<=\\n)\D*?办公地址:?\n+(.*)(?=\\n\D*?办公地址的邮政编码)|(?<=\\n)\D*?辦公地址:?\n+(.*?)(?=\\n)",re.DOTALL)
lines = p4.search(content)
if lines !=None:
if lines[1] !=None:
address = lines[1].replace('\n', '')
else:
address = lines[2].replace('\n', '')
else:
print(name+year+'年年报办公地址查找失败')
address = np.nan
p5 = re.compile("(?<=\\n)公司网址\n+(.*?)(电?子?传真\D*?|移动应用\D*?|手机网址\D*?|移动网址\D*?|电子信箱)(?=\\n)",re.DOTALL)
lines = p5.search(content)
if lines !=None:
web = lines[1].replace('\n', '')
else:
p5 = re.compile("(?<=\\n)公司网址:?\n*(.*?)(?=\\n)|(?<=\\n)公司網址:?\n*(.*?)(?=\\n)",re.DOTALL)
lines = p5.search(content)
if lines !=None:
if lines[1] !=None:
web = lines[1].replace('\n', '')
else:
web = lines[2].replace('\n', '')
else:
print(name+year+'年年报公司网址查找失败')
web = np.nan
df1.loc[year] = [short_name,code,address,web]
else:
p1 = re.compile('(?<=\\n)[\D、]?\n*公司信息(?=\\n)(.*?)(?<=\\n)[\D、]?\D*?主要\D*?数据\D*?(?=\\n)|(?<=\\n)[\D、]?\n*公司資料(?=\\n)(.*?)(?<=\\n)[\D、]?\D*?主要\D*?數據\D*?(?=\\n)',re.DOTALL)
content = p1.search(text)
if content != None:
content = content.group(0)
p2 = re.compile("(?<=\\n)\D*?简称:?\n*(.*?\n[B]?).*?(?=\\n)|(?<=\\n)\D*?簡稱:?\n*(.*?\n[B]?).*?(?=\\n)",re.DOTALL)
lines = p2.search(content)
if lines !=None:
if lines[1] !=None:
short_name = lines[1].replace('\n', '')
if '股票' in short_name:
p2 = re.compile("(?<=\\n)\D*?证券交易所\n+(.*?)(?=\\n)",re.DOTALL)
lines = p2.search(content)
if lines !=None:
short_name = lines[1].replace('\n', '')
else:
print(name+year+'年年报股票简称查找失败')
short_name = np.nan
else:
short_name = lines[2].replace('\n', '')
else:
print(name+year+'年年报股票简称查找失败')
short_name = np.nan
p3 = re.compile("(?<=\\n)股票代码.*?(\d+)(?=\\n)|(?<=\\n)\D*?代碼.*?(\d+)(?=\\n)",re.DOTALL)
lines = p3.search(content)
if lines !=None:
if lines[1] !=None:
code = lines[1]
if len(code)<6:
p3 = re.compile("(?<=\\n)\D*?A股.*?(\d+)(?=\\n)",re.DOTALL)
lines = p3.search(content)
if lines !=None:
code = lines[1]
else:
print(name+year+'年年报股票代码查找失败')
code = np.nan
else:
code = lines[2]
else:
print(name+year+'年年报股票代码查找失败')
code = np.nan
p4 = re.compile("(?<=\\n)\D*?办公地址:?\n+(.*)(?=\\n\D*?办公地址的邮政编码)|(?<=\\n)\D*?辦公地址:?\n+(.*?)(?=\\n)",re.DOTALL)
lines = p4.search(content)
if lines !=None:
if lines[1] !=None:
address = lines[1].replace('\n', '')
else:
address = lines[2].replace('\n', '')
else:
print(name+year+'年年报办公地址查找失败')
address = np.nan
p5 = re.compile("(?<=\\n)公司网址\n+(.*?)(电?子?传真\D*?|移动应用\D*?|手机网址\D*?|移动网址\D*?|电子信箱)(?=\\n)",re.DOTALL)
lines = p5.search(content)
if lines !=None:
web = lines[1].replace('\n', '')
else:
p5 = re.compile("(?<=\\n)公司网址:?\n*(.*?)(?=\\n)|(?<=\\n)公司網址:?\n*(.*?)(?=\\n)",re.DOTALL)
lines = p5.search(content)
if lines !=None:
if lines[1] !=None:
web = lines[1].replace('\n', '')
else:
web = lines[2].replace('\n', '')
else:
print(name+year+'年年报公司网址查找失败')
web = np.nan
df1.loc[year] = [short_name,code,address,web]
else:
df1.loc[year] = [np.nan,np.nan,np.nan,np.nan]
print(name+year+'年年报公司基本信息文本定位失败')
df1 = df1.sort_index()
df_information = pd.concat([df_information,df1],axis=1)
#无法正常提取的进行手动填充
df_information.loc['2013','中国东航股票简称'] = '东方航空'
df_information.loc['2013','中国东航股票代码'] = '600115'
df_information.loc['2013','中国东航办公地址'] = '上海市虹桥路2550号'
df_information.loc['2013','中国东航公司网址'] = 'www.ceair.com'
df_information.loc['2018','中国国航股票简称'] = '中国国航'
df_information.loc['2018','中国国航股票代码'] = '601111'
df_information.loc['2018','中国国航办公地址'] = '中国北京市顺义区空港工业区天柱路30号'
df_information.loc['2018','中国国航公司网址'] = 'www.airchina.com.cn'
df_information = df_information.reset_index(drop=False)
df_information.rename(columns = {"index":"年份"}, inplace=True)
df_information = df_information.set_index(['年份'])
df_information.fillna(value='未上市', inplace=True)
df_information.to_csv('航空运输业上市公司基本信息.csv')
详细内容可通过以下链接查看:
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
df = pd.read_csv('行业信息.csv',index_col=0,dtype=(str))
df_eps = pd.read_csv('航空运输业基本每股收益数据.csv',index_col=0)
df_revenue = pd.read_csv('航空运输业主营业务收入数据.csv',index_col=0)
df_information = pd.read_csv('航空运输业上市公司基本信息.csv',index_col=0,dtype=(str))
df_revenue = df_revenue/100000000
df_revenue.loc['sum'] = df_revenue.sum()
df_revenue = df_revenue.T
df_revenue = df_revenue.sort_values(by='sum',ascending=False,axis=0)
df_revenue = df_revenue.iloc[:10]
top10_list = df_revenue.index.values.tolist()
for i in range(len(top10_list)):
top10_list[i] = top10_list[i][:-6]
df_revenue = df_revenue.T
df_revenue = df_revenue.iloc[:-1]
for name in df['上市公司简称']:
if name not in top10_list:
df_eps.drop(columns=[name+'基本每股收益'], axis=1, inplace=True)
for name in top10_list:
df_revenue.rename(columns={name+'主营业务收入':name}, inplace=True)
df_eps.rename(columns={name+'基本每股收益':name}, inplace=True)
#主营业务收入
plt.figure(figsize=(10,8))
x = df_revenue.index
y_1 = df_revenue.iloc[:,0]
y_2 = df_revenue.iloc[:,1]
y_3 = df_revenue.iloc[:,2]
y_4 = df_revenue.iloc[:,3]
y_5 = df_revenue.iloc[:,4]
plt.plot(x, y_1, marker='^', markersize=8, label=df_revenue.columns[0], linewidth=2.0)
plt.plot(x, y_2, marker='^', markersize=8, label=df_revenue.columns[1], linewidth=2.0)
plt.plot(x, y_3, marker='^', markersize=8, label=df_revenue.columns[2], linewidth=2.0)
plt.plot(x, y_4, marker='^', markersize=8, label=df_revenue.columns[3], linewidth=2.0)
plt.plot(x, y_5, marker='^', markersize=8, label=df_revenue.columns[4], linewidth=2.0)
plt.xticks(range(2012,2022), fontsize=16)
plt.xlabel("年份", fontsize=16)
plt.yticks(fontsize=16)
plt.ylabel("主营业务收入(亿元)", fontsize=16)
plt.title("2012-2021年航空运输业上市公司主营业务收入随时间变化趋势图", fontsize=16)
plt.legend(loc=1, prop={'size':15})
plt.grid()
#主营业务收入(续)
plt.figure(figsize=(10,8))
y_6 = df_revenue.iloc[:,5]
y_7 = df_revenue.iloc[:,6]
y_8 = df_revenue.iloc[:,7]
y_9 = df_revenue.iloc[:,8]
y_10 = df_revenue.iloc[:,9]
plt.plot(x, y_6, marker='^', markersize=8, label=df_revenue.columns[5], linewidth=2.0)
plt.plot(x, y_7, marker='^', markersize=8, label=df_revenue.columns[6], linewidth=2.0)
plt.plot(x, y_8, marker='^', markersize=8, label=df_revenue.columns[7], linewidth=2.0)
plt.plot(x, y_9, marker='^', markersize=8, label=df_revenue.columns[8], linewidth=2.0)
plt.plot(x, y_10, marker='^', markersize=8, label=df_revenue.columns[9], linewidth=2.0)
plt.xticks(range(2012,2022), fontsize=16)
plt.xlabel("年份", fontsize=16)
plt.yticks(fontsize=16)
plt.ylabel("主营业务收入(亿元)", fontsize=16)
plt.title("2012-2021年航空运输业上市公司主营业务收入随时间变化趋势图(续)", fontsize=16)
plt.legend(loc=1, prop={'size': 15})
plt.grid()
#基本每股收益
plt.figure(figsize=(10,8))
x = df_eps.index
y_1 = df_eps.iloc[:,4]
y_2 = df_eps.iloc[:,8]
y_3 = df_eps.iloc[:,5]
y_4 = df_eps.iloc[:,6]
y_5 = df_eps.iloc[:,1]
plt.plot(x, y_1, marker='s', markersize=7, label=df_eps.columns[4], linewidth=2.0)
plt.plot(x, y_2, marker='s', markersize=7, label=df_eps.columns[8], linewidth=2.0)
plt.plot(x, y_3, marker='s', markersize=7, label=df_eps.columns[5], linewidth=2.0)
plt.plot(x, y_4, marker='s', markersize=7, label=df_eps.columns[6], linewidth=2.0)
plt.plot(x, y_5, marker='s', markersize=7, label=df_eps.columns[1], linewidth=2.0)
plt.xticks(range(2012,2022), fontsize=16)
plt.xlabel("年份", fontsize=16)
plt.yticks(fontsize=16)
plt.ylabel("基本每股收益(元/股)", fontsize=16)
plt.title("2012-2021年航空运输业上市公司基本每股收益随时间变化趋势图", fontsize=16)
plt.legend(loc=0, prop={'size':15})
plt.grid()
#基本每股收益(续)
plt.figure(figsize=(10,8))
y_6 = df_eps.iloc[:,9]
y_7 = df_eps.iloc[:,7]
y_8 = df_eps.iloc[:,3]
y_9 = df_eps.iloc[:,2]
y_10 = df_eps.iloc[:,0]
plt.plot(x, y_6, marker='s', markersize=7, label=df_eps.columns[9], linewidth=2.0)
plt.plot(x, y_7, marker='s', markersize=7, label=df_eps.columns[7], linewidth=2.0)
plt.plot(x, y_8, marker='s', markersize=7, label=df_eps.columns[3], linewidth=2.0)
plt.plot(x, y_9, marker='s', markersize=7, label=df_eps.columns[2], linewidth=2.0)
plt.plot(x, y_10, marker='s', markersize=7, label=df_eps.columns[0], linewidth=2.0)
plt.xticks(range(2012,2022), fontsize=16)
plt.xlabel("年份", fontsize=16)
plt.yticks(fontsize=16)
plt.ylabel("基本每股收益(元/股)", fontsize=16)
plt.title("2012-2021年航空运输业上市公司基本每股收益随时间变化趋势图(续)", fontsize=16)
plt.legend(loc=1, prop={'size': 15})
plt.grid()
#2012-2016主营业务收入横向对比
df_revenue[:5].plot(kind='bar', figsize=(10,8), width=0.6)
plt.xticks(fontsize=16, rotation=0)
plt.xlabel('年份', fontsize=16,rotation=0)
plt.yticks(fontsize=16)
plt.ylabel('主营业务收入(亿元)', fontsize=16)
plt.title('2012-2016年航空运输业上市公司主营业务收入横向对比图', fontsize=16)
plt.legend(loc=1, prop={'size':14})
plt.grid()
#2017-2021主营业务收入横向对比
df_revenue[5:].plot(kind='bar', figsize=(10,8), width=0.6)
plt.xticks(fontsize=16, rotation=0)
plt.xlabel('年份', fontsize=16,rotation=0)
plt.yticks(fontsize=16)
plt.ylabel('主营业务收入(亿元)', fontsize=16)
plt.title('2017-2021年航空运输业上市公司主营业务收入横向对比图', fontsize=16)
plt.legend(loc=1, prop={'size':14})
plt.grid()
#2012-2016基本每股收益横向对比
df_eps.iloc[:5,[4,8,5,6,1,9,7,3,2,0]].plot(kind='bar', figsize=(18,9), width=0.6)
plt.xticks(fontsize=16, rotation=0)
plt.xlabel('年份', fontsize=16,rotation=0)
plt.yticks(fontsize=16)
plt.ylabel('基本每股收益(元/股)', fontsize=16)
plt.title('2012-2016年航空运输业上市公司基本每股收益横向对比图', fontsize=16)
plt.legend(loc=1, prop={'size':14})
plt.grid()
#2017-2021基本每股收益横向对比
df_eps.iloc[5:,[4,8,5,6,1,9,7,3,2,0]].plot(kind='bar', figsize=(18,9), width=0.6)
plt.xticks(fontsize=16, rotation=0)
plt.xlabel('年份', fontsize=16,rotation=0)
plt.yticks(fontsize=16)
plt.ylabel('基本每股收益(元/股)', fontsize=16)
plt.title('2017-2021年航空运输业上市公司基本每股收益横向对比图', fontsize=16)
plt.legend(loc=1, prop={'size':14}, ncol=2)
plt.grid()
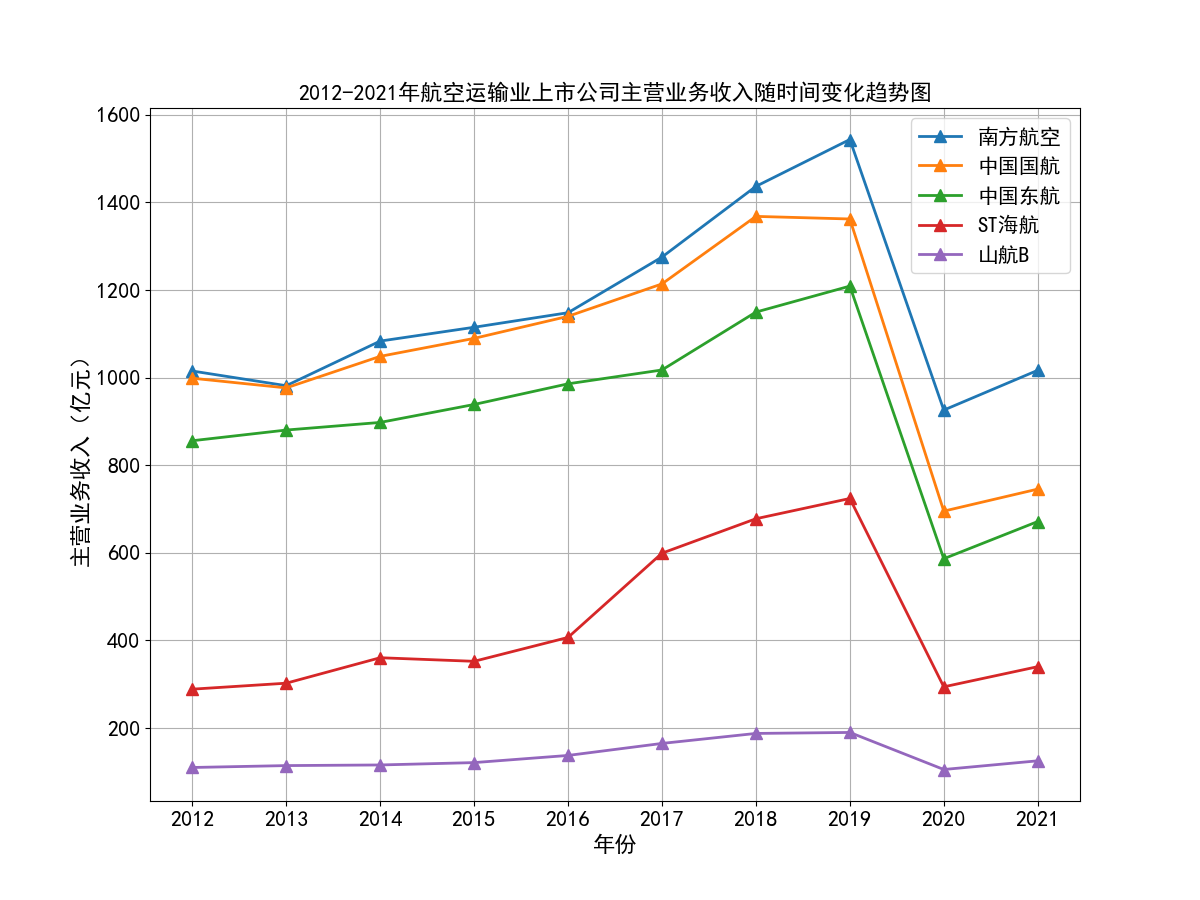
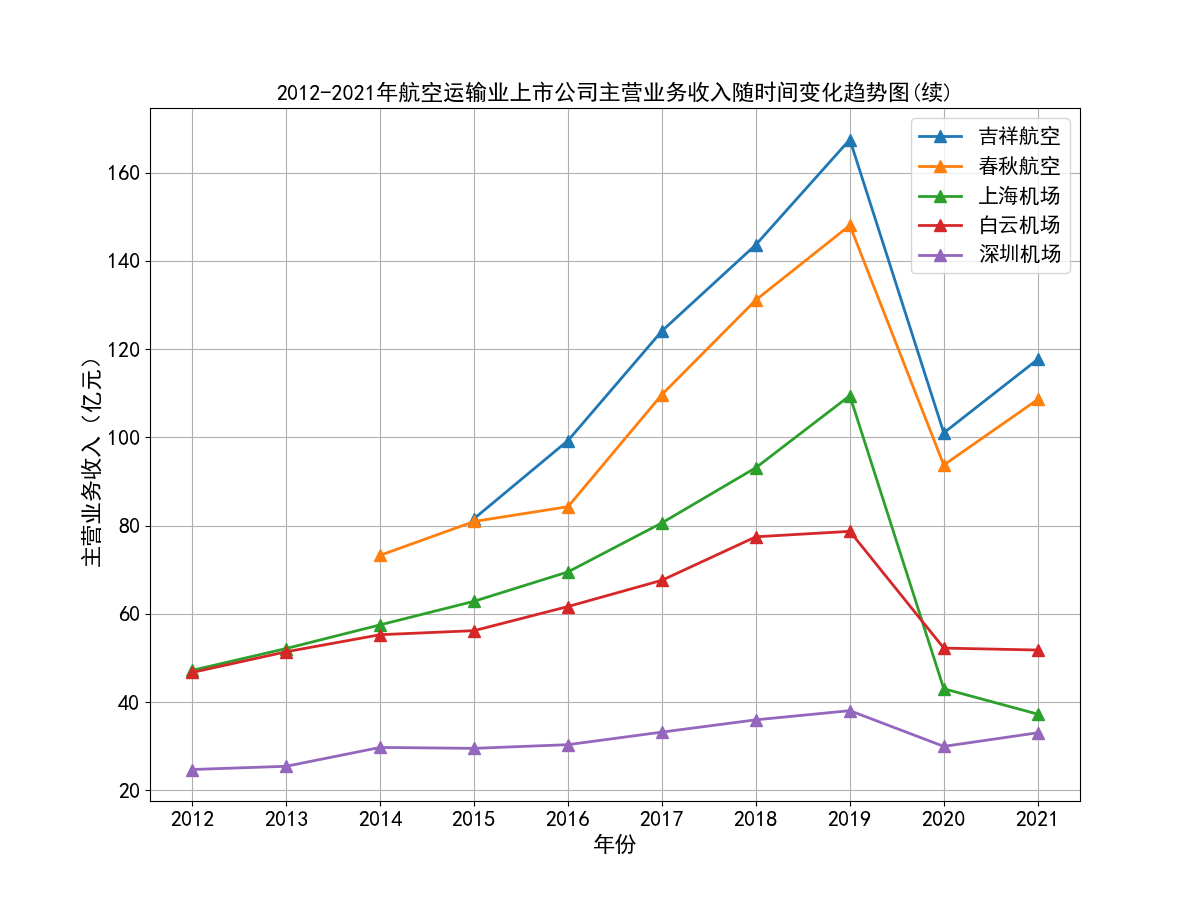
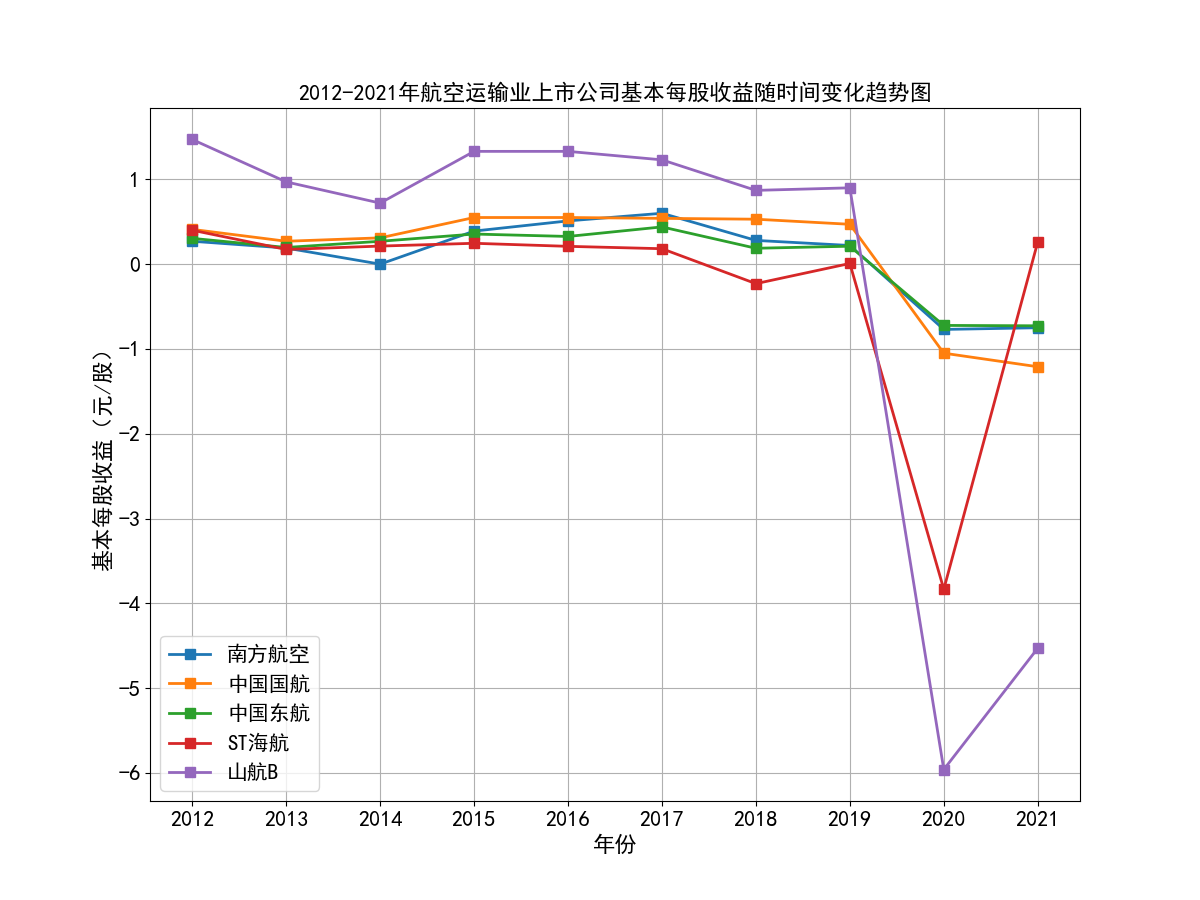
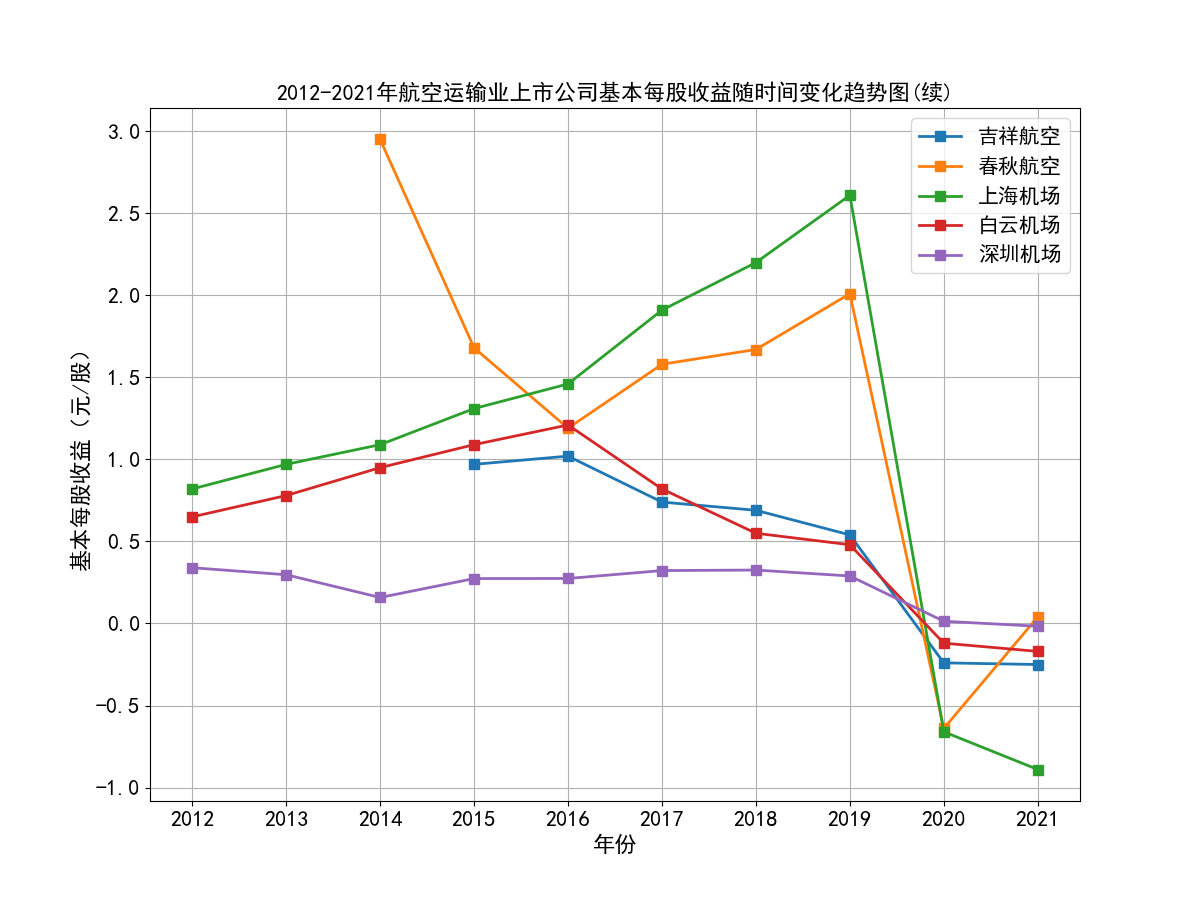

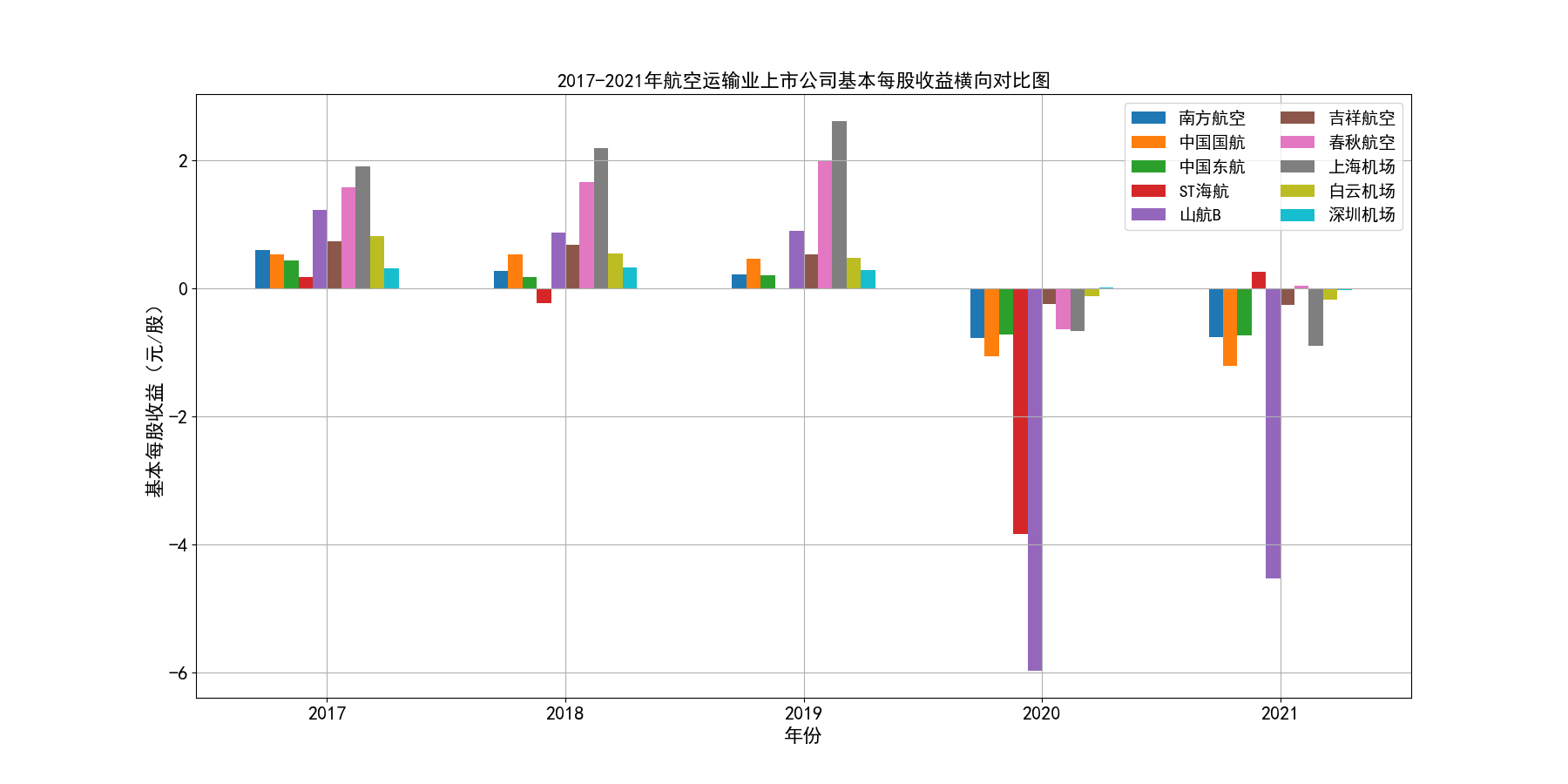
航空运输行业在2020年之前发展稳中向好。这主要得益于我国GDP的稳步增长,居民消费水平的不断提高,在长途旅行中选择航班出行逐渐普遍化。从所选出的行业内十家具有一定代表性的公司的主营业务收入时间序列图来看, 2012到2019年末营业收入均呈现稳步上升的趋势,基本每股收益大部分保持稳定或上升,仅个别公司基本每股收益波动比较大。
随着时间进入2020年,年初爆发新冠疫情,并持续了较长一段时间,我国实行了严格的交通管制、出入境管制,国际航线和国内航线大部分停运,给航空运输业造成了巨大的打击。 营业收入几乎腰斩,基本每股收益也大幅下降,可以看到2020年十家上市公司基本每股收益清一色都为负数。
随着疫情得到有效控制,国际航线和国内航线逐渐恢复,业内各上市公司的营业状况也有所好转,营业收入和基本每股收益都有一定程度的上升,但基本每股收益也基本还是维持在负数的水平, 上市公司大多入不敷出。虽然疫情得到了有效控制,但航空运输业要恢复到疫情之前的水平,还是需要一定的时间。
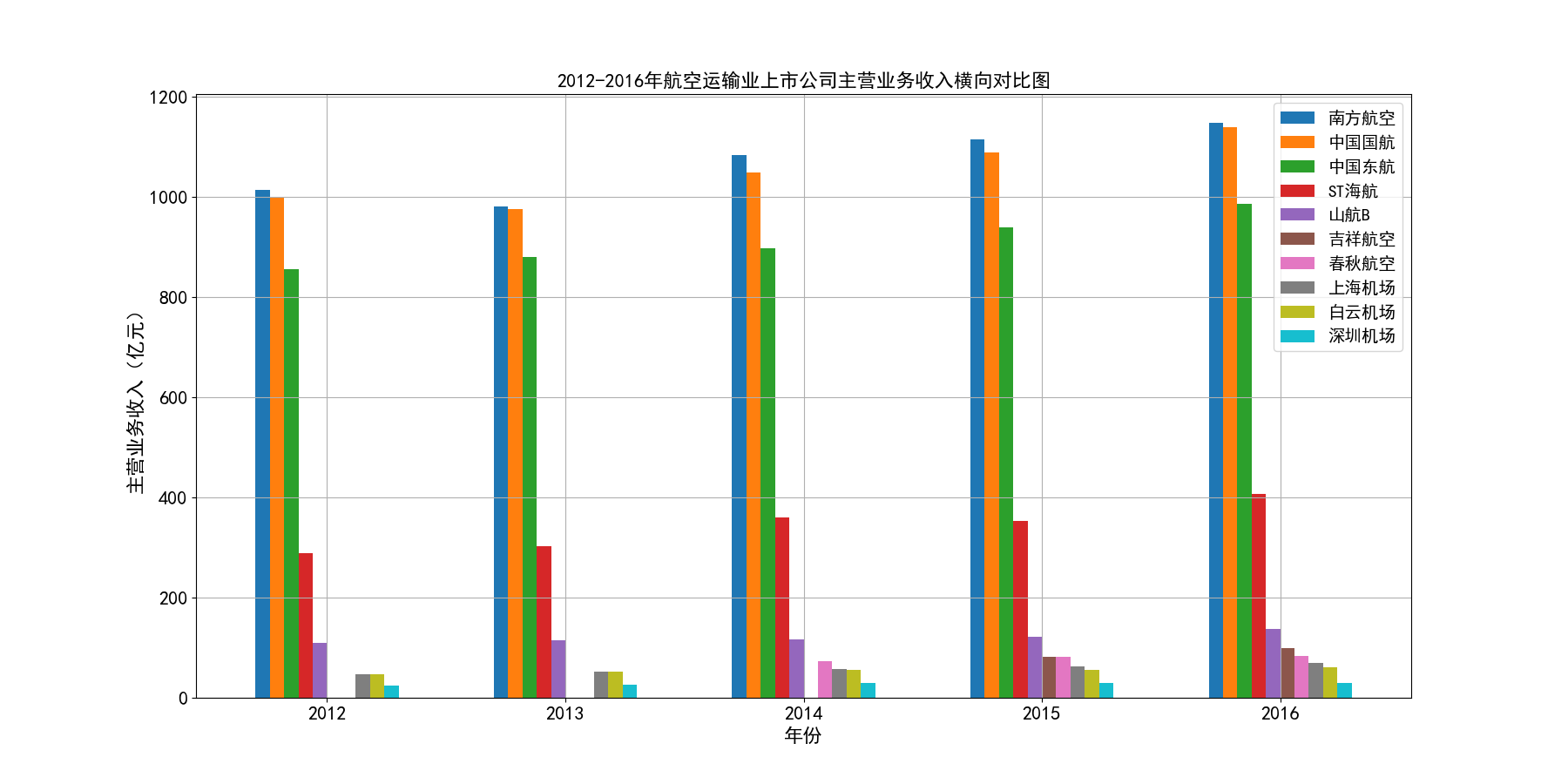
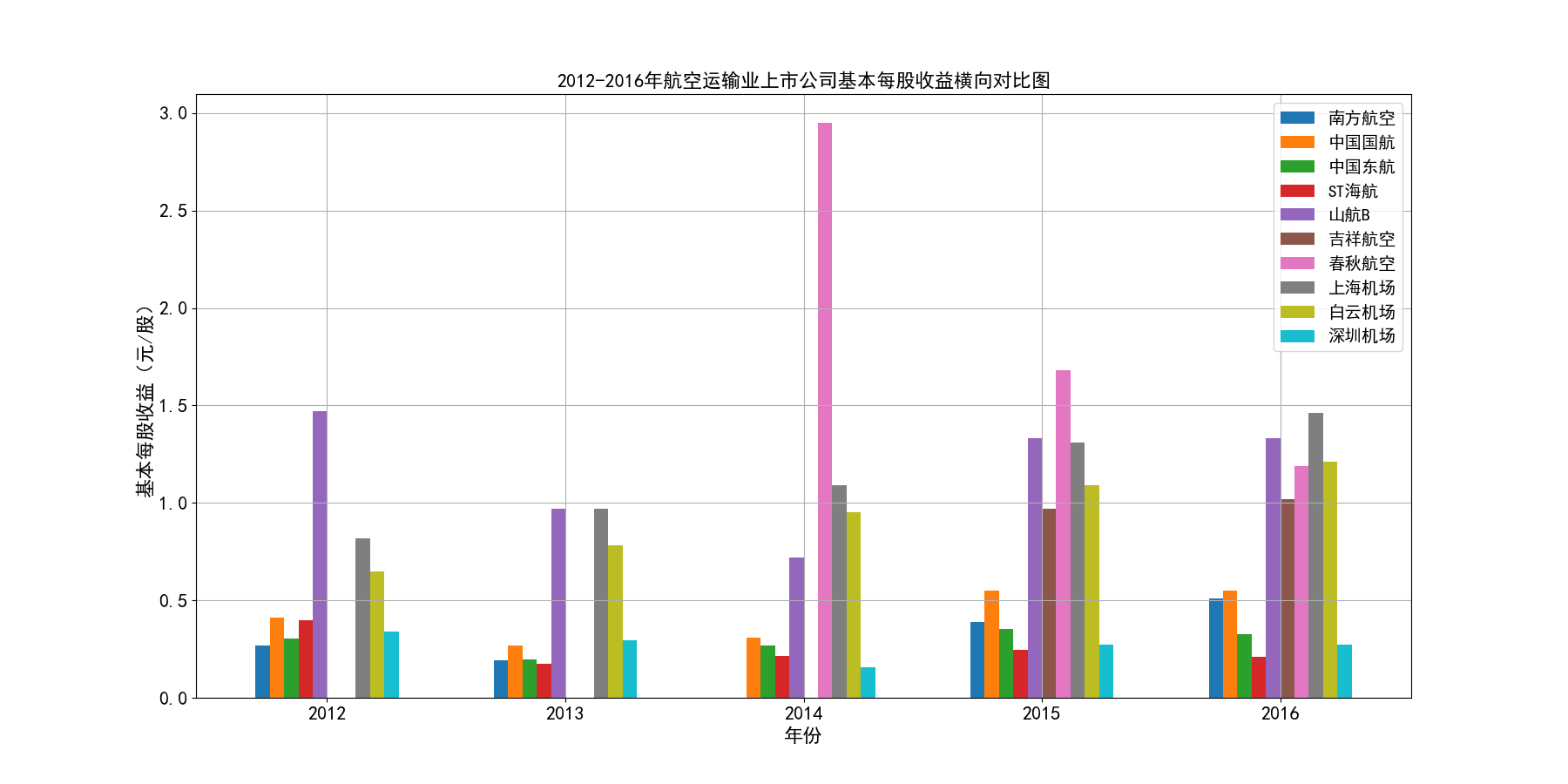
从行业横向对比来看,南方航空、中国国航、中国东航三大龙头的营业收入遥遥领先,龙头地位十分稳固,在疫情之前,南方航空和中国国航的营业收入水平都基本稳定在千亿以上, 中国东航也在2017年突破千亿水平。由于这三家上市公司体量巨大,流通股份数较多,所以基本每股收益维持在较小的0.2-0.4元/股左右。而行业内其他公司,从横向对比图可以看出, 营业收入基本没有达到第一龙头南方航空的20%,除海航控股(ST海航),其营业收入水平基本在中国东航的30%-50%左右,有成为第四大龙头的态势。
总的来说,航空运输业行业内部的竞争结构还是比较稳定的,基本上以南方航空、中国国航、中国东航三大龙头为主导,其他公司仅占较小的市场份额。