import fitz
import xlwt
import re
import os
import csv
import pandas as pd
import numpy as np
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import matplotlib
import random
import matplotlib.pyplot as plt
from pylab import mpl
import matplotlib.lines as mlines
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
%matplotlib qt5
"""深交所解析"""
class DisclosureTable_SZ():
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?) ', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?) '
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
"""上交所解析"""
class DisclosureTable_SH():
'''
解析上交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix_href = 'http://static.sse.com.cn'
#
p_a = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)#测试
h = trs[2]
while h in trs:
trs.remove(h)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df_SH = pd.DataFrame({'证券代码': [td[0] for td in tds],
'证券简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df_SH
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([attachpath, title])
def get_data(self):
get_code = self.get_code
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['证券简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [td.strip() for td in df['公告时间']]
#
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'attachpath': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
#美化HTML
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
#过滤名称信息
def filter_links(words,df,include=True):
ls=[]
for word in words:
if include:
# ls.append([word in f for f in df.f_name])
ls.append([word in f for f in df['公告标题']])
else:
# ls.append([word not in f for f in df.f_name])
ls.append([word not in f for f in df['公告标题']])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return(df2)
# 上交所爬取定义
def get_innerhtml(code_name):
browser.find_element(By.ID, "inputCode").click()
browser.find_element(By.ID, "inputCode").send_keys(code_name)
time.sleep(0.5)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(0.5)
#
content = browser.find_element_by_class_name('table-responsive')
content = content.get_attribute('innerHTML')
return(content)
#上市公司分类爬取
corp = fitz.open('上市行业分类.pdf')
page82 = corp.load_page(82)
text = page82.get_text()
pt = '(?<=道路运输业\n)(.*?)(?=\n55)' # 向左、右看
p = re.compile(pt, re.DOTALL)
daima = p.findall(text)
pm='(\d{6})\n(\w+)\n'
p1 = re.compile(pm, re.DOTALL)
fenge = p1.findall(daima[0])
fenge_new = pd.DataFrame(fenge, columns=['代码', '公司名称'])
feature = pd.DataFrame(columns=['代码首字','交易所'])
fenge_new = pd.concat([fenge_new, feature], axis = 1)
for i in range(0, len(fenge_new)):
if fenge_new['代码'][i][0] == '0':
fenge_new['交易所'][i] = 'SZ'
fenge_new['代码首字'][i] = fenge_new.loc[i][0][0]
else:
fenge_new['交易所'][i] = 'SH'
fenge_new['代码首字'][i] = fenge_new.loc[i][0][0]
#文件目录创建
for i in range(0,len(fenge_new)):
if fenge_new['交易所'][i] == 'SZ':
folder_path = 'D:/从C盘移过来的/havdif/Desktop/python/金融数据获取' + '/年报下载/深交所/%s'%fenge_new['公司名称'][i] +"/"
if not os.path.exists(folder_path):
os.makedirs(folder_path)
else:
folder_path = 'D:/从C盘移过来的/havdif/Desktop/python/金融数据获取' + '/年报下载/上交所/%s'%fenge_new['公司名称'][i] +"/"
if not os.path.exists(folder_path):
os.makedirs(folder_path)
#设置自定义下载路径
driver_url = r"C:\edgedriver_win64\msedgedriver.exe"
Years = ['2013','2014','2015','2016','2017','2018','2019','2020','2021','2022']
###循环下载数据
for i in range(0,len(fenge_new)):
if fenge_new['交易所'][i] == 'SZ':
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory':
r'D:\从C盘移过来的\havdif\Desktop\python\金融数据获取\年报下载\深交所\%s'
%fenge_new['公司名称'][i]}
# prefs = {'profile.default_content_settings.popups': 0,
# 'download.default_directory':
# r'D:\从C盘移过来的\havdif\Desktop\python\金融数据获取\年报下载\深交所\盐田港'}#测试
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
browser = webdriver.Edge(executable_path=driver_url, options=options)
#相应操作
cor_name = fenge_new['公司名称'][i]
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
browser.implicitly_wait(10)
element = browser.find_element(By.ID, 'input_code') # Find the search box
#element.send_keys('盐田港' + Keys.RETURN)#测试
element.send_keys(cor_name + Keys.RETURN)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
browser.find_element(By.CSS_SELECTOR, ".input-left").click()
browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-2 .selected > .tdcontainer").click()
browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
browser.find_element(By.CSS_SELECTOR, ".active li:nth-child(114)").click()
browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-month span").click()
browser.find_element(By.CSS_SELECTOR, ".active > .dropdown-menu li:nth-child(1)").click()
browser.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
time.sleep(0.3)
browser.find_element(By.ID, "query-btn").click()
data_ele = browser.find_element(By.ID, 'disclosure-table')
innerHTML = data_ele.get_attribute('innerHTML')
f = open(r'.\年报下载\深交所\%s\innerHTML.html'%fenge_new['公司名称'][i],'w',
encoding='utf-8')
#f = open(r'.\年报下载\innerHTML_SZ.html','w', encoding='utf-8')#测试
f.write(innerHTML)
f.close()
html = to_pretty(r'.\年报下载\深交所\%s\innerHTML.html'%fenge_new['公司名称'][i])
#html = to_pretty(r'.\年报下载\innerHTML_SZ.html')#测试
dt = DisclosureTable_SZ(html)
df = dt.get_data()
df = filter_links(['摘要', '已取消','补充公告'], df, include=False)
df['年份'] = pd.to_datetime(df['公告时间']).dt.year
df_vise_SZ = pd.DataFrame()
for year in Years:
Year = int(year)
df_new = df[df['年份']==Year]
if len(df_new)>=2:
Name = []
for name in df_new['公告标题']:
Name.append(name)
if Name[0]==Name[1]:
df_new = df_new.loc[[0]]
else:
df_new = filter_links(['修订版', '更新后'], df_new, include=True)
df_vise_SZ = pd.concat([df_vise_SZ, df_new], axis=0)
index_vise_SZ = list(range(len(df_vise_SZ)))
df_vise_SZ.index = index_vise_SZ
for j in range(len(df_vise_SZ)):
download_link = df_vise_SZ['attachpath'][j]
r = requests.get(download_link, allow_redirects=True)
#f = open(r'.\年报下载\深交所\盐田港\%s.pdf'%df_vise_SZ['公告标题'][j], 'wb')#测试
f = open(r'.\年报下载\深交所\%s\%s.pdf' %(fenge_new['公司名称'][i],df_vise_SZ['公告标题'][j]), 'wb')
f.write(r.content)
f.close()
r.close()
else:
prefs = {'profile.default_content_settings.popups': 0,
'download.default_directory':
r'D:\从C盘移过来的\havdif\Desktop\python\金融数据获取\年报下载\上交所\%s'
%fenge_new['公司名称'][i]}
options = webdriver.EdgeOptions()
options.add_experimental_option('prefs', prefs)
browser = webdriver.Edge(executable_path=driver_url, options=options)
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
browser.implicitly_wait(10)
browser.set_window_size(1936, 1048)
dropdown = browser.find_element(By.CSS_SELECTOR, ".selectpicker-pageSize")
time.sleep(1)
dropdown.find_element(By.XPATH, "//option[. = '每页100条']").click()
browser.find_element(By.ID, "inputCode")
browser.find_element(By.ID, "inputCode").send_keys(fenge_new['代码'][i])
time.sleep(0.5)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(0.5)
#
content = browser.find_element_by_class_name('table-responsive')
content = content.get_attribute('innerHTML')
f = open(r'.\年报下载\上交所\%s\innerHTML_SH.html'%fenge_new['公司名称'][i]
,'w', encoding='utf-8')#测试
f.write(content)
f.close()
html1 = to_pretty(r'.\年报下载\上交所\%s\innerHTML_SH.html'%fenge_new['公司名称'][i])
dt_SH = DisclosureTable_SH(html1)
df_SH = dt_SH.get_data()
df_all = filter_links(['摘要','补充公告','补充公告'], df_SH, include=False)
df_all['年份'] = pd.to_datetime(df_all['公告时间']).dt.year
df_vise_SH = pd.DataFrame()
for year in Years:
Year = int(year)
df_all1 = df_all[df_all['年份']==Year]
if len(df_all1)>=2:
Name = []
for name in df_all1['公告标题']:
Name.append(name)
if Name[0]==Name[1]:
df_all1 = df_all1.loc[[0]]
else:
df_all1 = filter_links(['修订版', '更新后'], df_all1, include=True)
df_vise_SH = pd.concat([df_vise_SH, df_all1], axis=0)
index_vise_SH = list(range(len(df_vise_SH)))
df_vise_SH.index = index_vise_SH
for m in range(len(df_vise_SH)):
link = df_vise_SH['attachpath'][m]
sequence = str(fenge_new['公司名称'][i])+str(df_vise_SH['年份'][m]-1)+'年年度报告'
r = requests.get(link, allow_redirects=True)
f = open(r'.\年报下载\上交所\%s\%s.pdf' %(fenge_new['公司名称'][i], sequence), 'wb')
f.write(r.content)
f.close()
r.close()
#创建xls文件保存文件名
for i in range(0,len(fenge_new)):
if fenge_new['交易所'][i] == 'SZ':
path=r'.\年报下载\深交所\%s'%fenge_new['公司名称'][i]
file_path=path+'\\namelist.xls'
pathDir=os.listdir(path)
f=xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet=f.add_sheet('sheet1')
i=0
for s in pathDir:
s=s.split('.')[0]
sheet.write(i,0,s)
i+=1
f.save(file_path)
else:
path=r'.\年报下载\上交所\%s'%fenge_new['公司名称'][i]
file_path=path+'\\namelist.xls'
pathDir=os.listdir(path)
f=xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet=f.add_sheet('sheet1')
i=0
for s in pathDir:
s=s.split('.')[0]
sheet.write(i,0,s)
i+=1
f.save(file_path)
#自定义公告标题获取
def get_namelist(sort, corporate):
Namelist = pd.read_excel(r'.\年报下载\%s\%s\namelist.xls'%(sort,corporate), header=None)
Namelist.columns = ['公告标题']
Namelist = filter_links(['innerHTML', 'namelist'], Namelist, include=False)
index_namelist = list(range(len(Namelist)))
Namelist.index = index_namelist
return(Namelist)
###测试:tess = get_namelist('上交所', '锦江在线')
#设置需要匹配的四种数据的pattern
p_all = re.compile('(�+)', re.DOTALL)
p_rev = re.compile('(?<=\n)营业总?收入.*?([\d+,.]+).*?(?=\n)', re.DOTALL)
p_eps = re.compile('(?<=\n)基\s?本\s?每\s?股\s?收\s?益.*?([-\d+.]+).*?(?=\n)', re.DOTALL)
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_site_test = re.compile('(?<=\n)(\w*办公地址).*?(?=\n)', re.DOTALL)
p_web = re.compile('(?<=\n)公司\w*网址.*?([a-zA-Z0-9./:-]+).*?(?=\n)',re.DOTALL)
p_web_test = re.compile('(?<=\n)(公司\w*网址).*?(?=\n)',re.DOTALL)
p_year=re.compile('.*?(\d{4})年') #捕获目前在匹配的年报年份
#自定义爬取指定年报数据
def get_pdf_text(doc):
text=''
for x in range(15):
page = doc[x]
text += page.get_text()
return(text)
doc_test = fitz.open(r'.\年报下载\上交所\山东高速\山东高速2015年年度报告.pdf')
sdgs_2015 = get_pdf_text(doc_test)
sdgs = p_web_test.search(sdgs_2015)
def get_pdf_data(doc, namelist, number, cor_name, cor_code):
text_SZ=''
for x in range(15):
page = doc[x]
text_SZ += page.get_text()
year = int(p_year.findall(namelist['公告标题'][number])[0])
if len(p_all.findall(text_SZ))<=50:
revenue=float(p_rev.search(text_SZ).group(1).replace(',',''))
eps = float(p_eps.search(text_SZ).group(1))
if p_site_test.search(text_SZ)!=sdgs:
site = p_site.search(text_SZ).group(1)
else:
site = '没有检索到办公地址'
if p_web_test.search(text_SZ)!=sdgs:
web = p_web.search(text_SZ).group(1)
else:
web = '没有检索到网址'
else:
revenue = None
eps = None
site = '文件格式不对劲'
web = '文件格式不对劲'
list_cor = [cor_name,cor_code,revenue,eps,site,web,year]
return(list_cor)
##测试
tec = fitz.open(r'.\年报下载\深交所\现代投资\2013年年度报告(更新后).pdf')
tass = get_pdf_data(tec, tess, 3, '现代哦兔子', '000021')
test = tess[3].get_text()
#循环爬取年报数据
Converge = pd.DataFrame()
for i in range(0,len(fenge_new)):
if fenge_new['交易所'][i] == 'SZ':
sort_SZ = '深交所'
corporate_SZ = fenge_new['公司名称'][i]
namelist = get_namelist(sort_SZ, corporate_SZ)
for j in range(len(namelist)):
doc = fitz.open(r'.\年报下载\深交所\%s\%s.pdf'%(corporate_SZ,namelist['公告标题'][j]))
text_SZ = get_pdf_text(doc)
if text_SZ!='':
list_SZ = get_pdf_data(doc, namelist, j, fenge_new['公司名称'][i], fenge_new['代码'][i])
Converge = Converge.append([list_SZ])
else:
sort_SH = '上交所'
corporate_SH = fenge_new['公司名称'][i]
namelist = get_namelist(sort_SH, corporate_SH)
for j in range(len(namelist)):
doc = fitz.open(r'.\年报下载\上交所\%s\%s.pdf'%(corporate_SH,namelist['公告标题'][j]))
text_SH = get_pdf_text(doc)
if text_SH!='':
list_SH = get_pdf_data(doc, namelist, j, fenge_new['公司名称'][i], fenge_new['代码'][i])
Converge = Converge.append([list_SH])
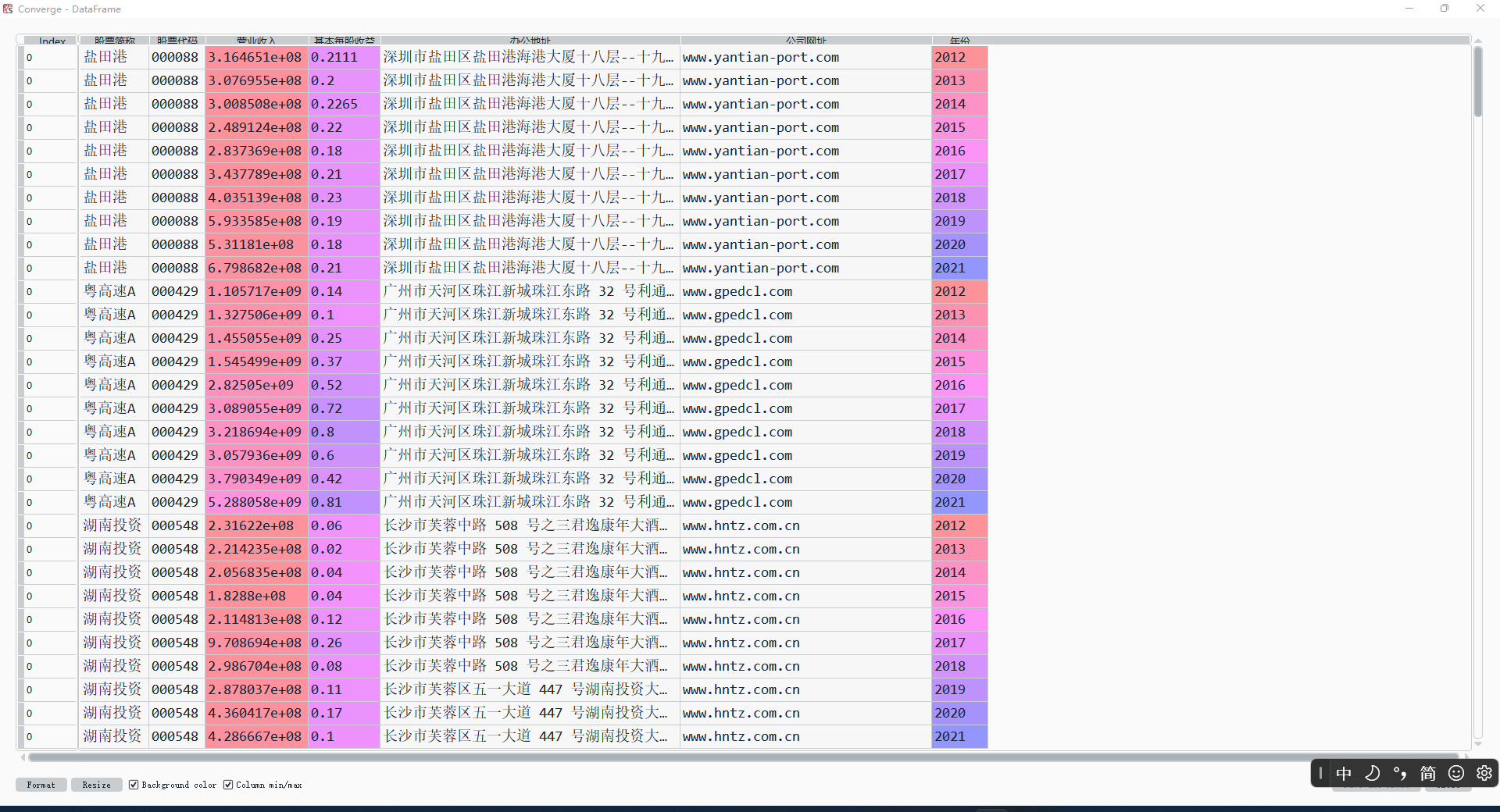
Converge.columns= ['股票简称', '股票代码', '营业收入', '基本每股收益', '办公地址', '公司网址', '年份']
Converge = Converge.astype({'营业收入':'float','基本每股收益':'float'})
Converge.to_csv('数据汇总.csv')
'''数据处理'''
#挑选出营业收入最高的十家公司
cors = fenge_new['公司名称'].tolist()
sum_cor = pd.DataFrame()
for cor in cors:
Rev_sum = Converge[Converge['股票简称']==cor]['营业收入'].sum()
nian = Converge[Converge['股票简称']==cor]['年份'].tolist()
fenshu = len(nian)
data_list = [cor, Rev_sum, nian, fenshu]
sum_cor= pd.concat([sum_cor,pd.DataFrame([data_list])],axis=0)
sum_cor.columns=['股票简称','营业收入汇总','年份集','年份数']
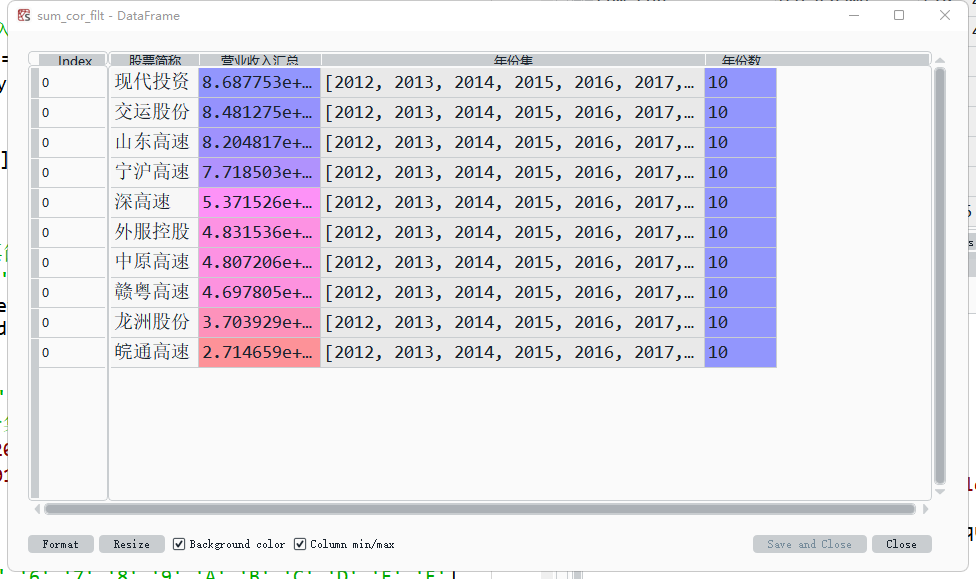
sum_cor = sum_cor[sum_cor['年份数']==10]
sum_cor_filt=sum_cor.sort_values(by='营业收入汇总',ascending=False).head(10)
#获取十家公司的数据
cors_high = sum_cor_filt['股票简称'].tolist()
plot_revenue = pd.DataFrame()
plot_eps = pd.DataFrame()
for cor in cors_high:
revenue=Converge[Converge['股票简称']==cor]['营业收入'].tolist()
eps=Converge[Converge['股票简称']==cor]['基本每股收益'].tolist()
plot_revenue=pd.concat([plot_revenue,pd.DataFrame(revenue)],axis=1)
plot_eps=pd.concat([plot_eps,pd.DataFrame(eps)],axis=1)
plot_revenue.columns = cors_high
plot_eps.columns = cors_high
plot_revenue.index = sum_cor_filt['年份集'].head(1).tolist()
plot_eps.index = sum_cor_filt['年份集'].head(1).tolist()
plot_eps['年份']= [2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
plot_revenue['年份']= [2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
###开始画图咯
###定义随机颜色
def randomcolor():
colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
color = ""
for i in range(6):
color += colorArr[random.randint(0,14)]
return "#"+color
color = randomcolor()
###定义折线图函数
def plot_line(frame):
plt.figure(figsize=(16,30))
x = frame['年份']
y_1 = frame.iloc[:,0]
y_2 = frame.iloc[:,1]
y_3 = frame.iloc[:,2]
y_4 = frame.iloc[:,3]
y_5 = frame.iloc[:,4]
y_6 = frame.iloc[:,5]
y_7 = frame.iloc[:,6]
y_8 = frame.iloc[:,7]
y_9 = frame.iloc[:,8]
y_10 = frame.iloc[:,9]
#
plt.xlim(2011.8,2021.2,1)
plt.xticks(range(2012,2022,1),fontsize=18)
plt.yticks(fontsize=18)
#
plt.plot(x, y_1, randomcolor(), marker='^',markersize=10, linestyle='-', label=frame.columns[0],linewidth=2.5,alpha=0.8)
plt.plot(x, y_2, randomcolor(), marker='^', markersize=10,linestyle='-', label=frame.columns[1],linewidth=2.5,alpha=0.8)
plt.plot(x, y_3, randomcolor(), marker='^', markersize=10,linestyle='-', label=frame.columns[2],linewidth=2.5,alpha=0.8)
plt.plot(x, y_4, randomcolor(), marker=9, markersize=9,linestyle='-', label=frame.columns[3],linewidth=2,alpha=0.8)
plt.plot(x, y_5, randomcolor(), marker=9,markersize=9, linestyle='-', label=frame.columns[4],linewidth=2,alpha=0.8)
plt.plot(x, y_6, randomcolor(), marker=9, markersize=9,linestyle='-', label=frame.columns[5],linewidth=2,alpha=0.8)
plt.plot(x, y_7, randomcolor(), marker='D', markersize=7,linestyle='-', label=frame.columns[6],linewidth=1.5,alpha=0.8)
plt.plot(x, y_8, randomcolor(), marker='s', markersize=7,linestyle='-', label=frame.columns[7],linewidth=1.5,alpha=0.8)
plt.plot(x, y_9, randomcolor(), marker='D',markersize=7, linestyle='-', label=frame.columns[8],linewidth=1.5,alpha=0.8)
plt.plot(x, y_10, randomcolor(), marker='s', markersize=7,linestyle='-', label=frame.columns[9],linewidth=1.5,alpha=0.8)
plt.legend(loc = "upper left",prop={'family':'simsun', 'size': 20}) # 显示图例
plt.grid(True)
if frame.iloc[0,10]==2012:
plt.title("营业收入随时间变化趋势图(2012-2021)",fontsize=25)
plt.ylabel("营业收入(十亿元)",fontsize=22) # 设置Y轴标签
else:
plt.title("基本每股收益随时间变化趋势图(2012-2021)",fontsize=25)
plt.ylabel("基本每股收益(元)",fontsize=22) # 设置Y轴标签
plt.xlabel("年份",fontsize=22,loc='left') # 设置X轴标签
return(plt.show())
###营业收入对比图绘制
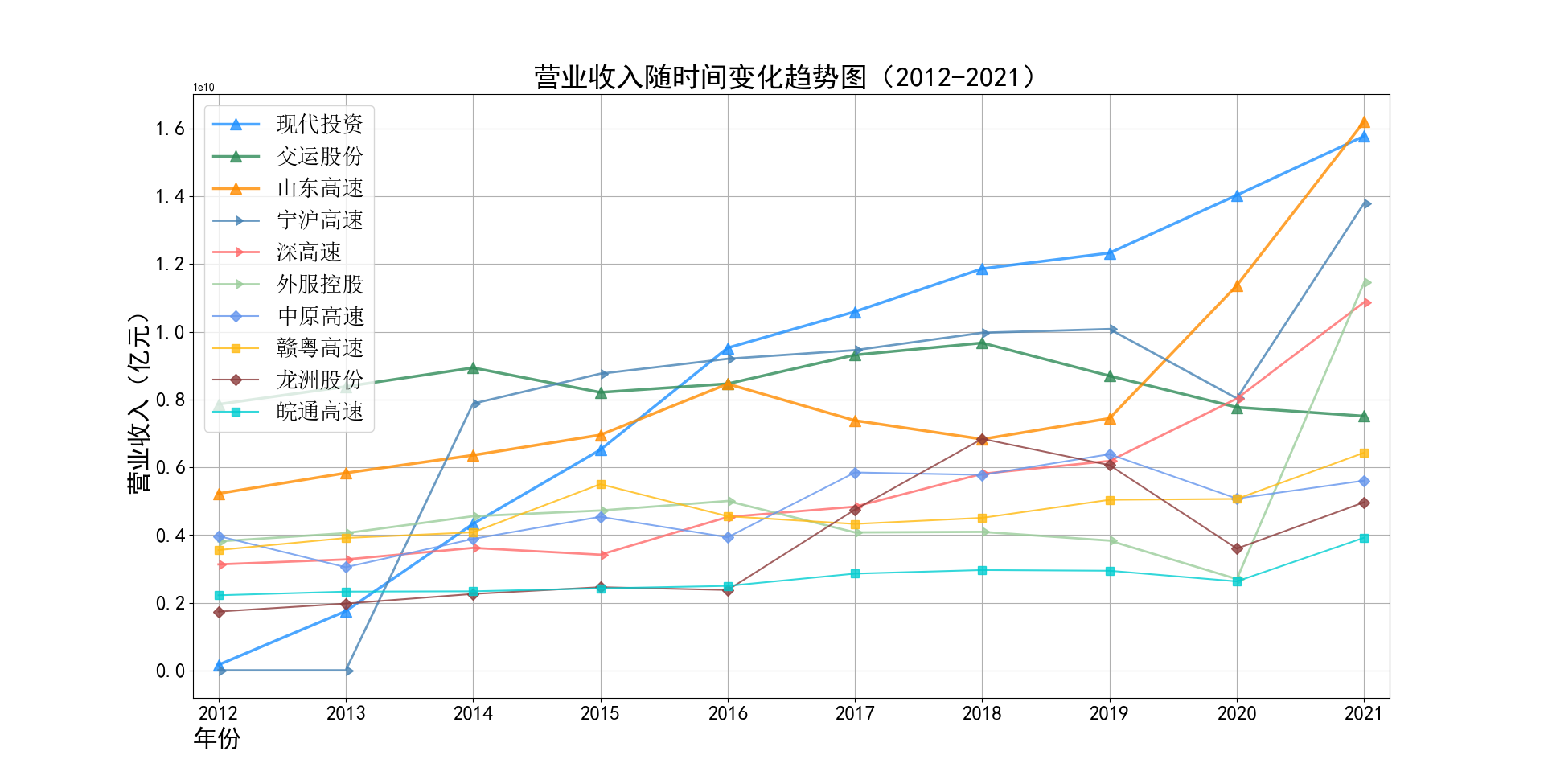
plot_line(plot_revenue)
###基本每股收益图绘制
plot_line(plot_eps)
###对比图绘制
def bar_plot(frame):
frame = frame.drop(columns=['年份'])
ax=frame.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax.set_xlabel('年份',loc='left',fontsize=18)
if frame.iloc[0,0]>=100:
ax.set_ylabel('营业收入(十亿元)',fontsize=18)
if frame.iloc[0,10]==2012:
ax.set_title('行业内横向对比营业收入(2012-2016)',fontsize=20)
else:
ax.set_title('行业内横向对比营业收入(2017-2021)',fontsize=20)
else:
ax.set_ylabel('基本每股收益(元)',fontsize=18)
if frame.iloc[0,10]==2012:
ax.set_title('行业内横向对比基本每股收益(2012-2016)',fontsize=20)
else:
ax.set_title('行业内横向对比基本每股收益(2017-2021)',fontsize=20)
return(ax)
plot_revenue_head = plot_revenue.head(5)
plot_revenue_head.index = plot_revenue_head['年份']
plot_revenue_tail = plot_revenue.tail(5)
plot_revenue_tail.index = plot_revenue_tail['年份']
plot_eps_head = plot_eps.head(5)
plot_eps_head.index = plot_eps_head['年份']
plot_eps_tail = plot_eps.tail(5)
plot_eps_tail.index = plot_eps_tail['年份']
###营业收入柱状对比图绘制
bar_plot(plot_revenue_head)
bar_plot(plot_revenue_tail)
###基本每股收益柱状对比图绘制
bar_plot(plot_eps_head)
bar_plot(plot_eps_tail)
def contrast(df):
def newline(p1,p2,i):
ax=plt.gca()
l=mlines.Line2D([p1,p2],y=i,color='skyblue')
ax.add_line(l)
return l
fig,ax=plt.subplots(1,1,figsize=(8,6))
ax.scatter(y=sum_cor_filt['股票简称'],x=df.iloc[0,:-1],s=50,color='#0e66FF',alpha=0.7)
ax.scatter(y=sum_cor_filt['股票简称'],x=df.iloc[9,:-1],s=50,color='#a3c4FF',alpha=0.7)
for i,p1,p2 in zip(sum_cor_filt['股票简称'],df.iloc[0,:-1],df.iloc[9,:-1]):
newline(p1,p2,i)
ax.set_title('十年间变化',fontdict={'size':12})
ax.set_xlim(0,1)
ax.set_xlabel('变化率')
ax.set_yticks(sum_cor_filt['股票简称'])
ax.grid(alpha=0.5,axis='x')
plt.show()
return()
contrast(plot_revenue)
contrast(plot_eps)
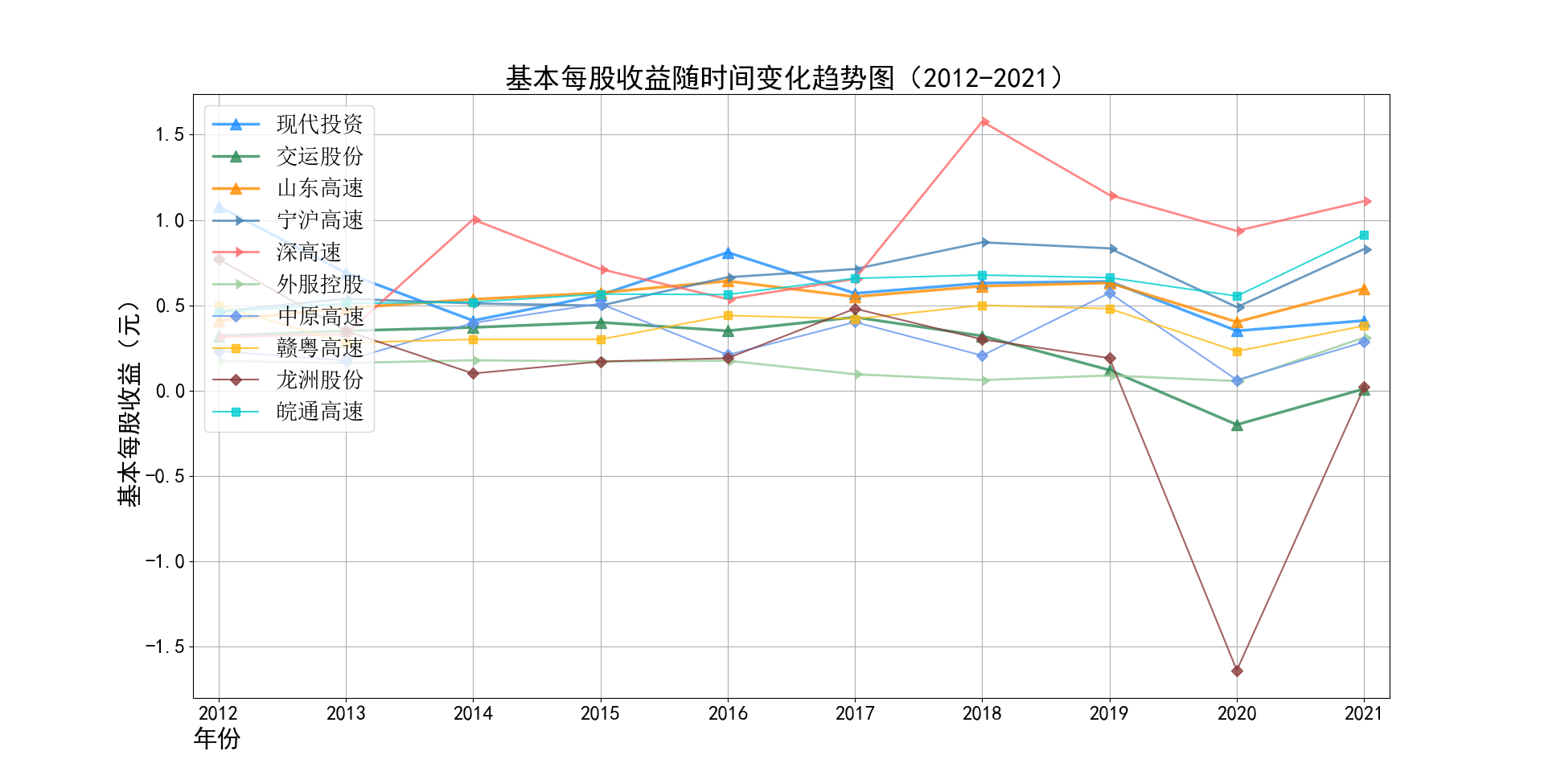
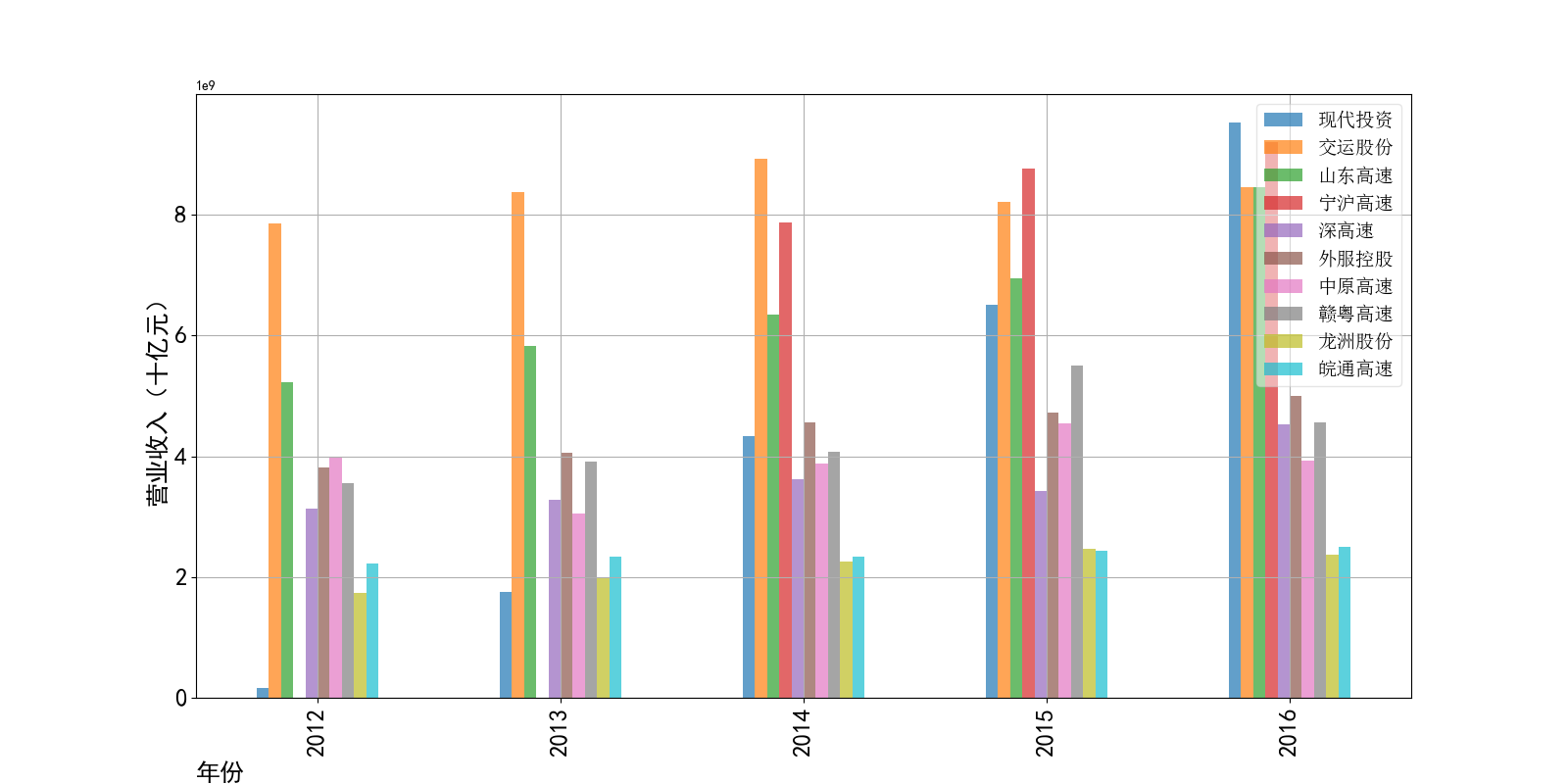
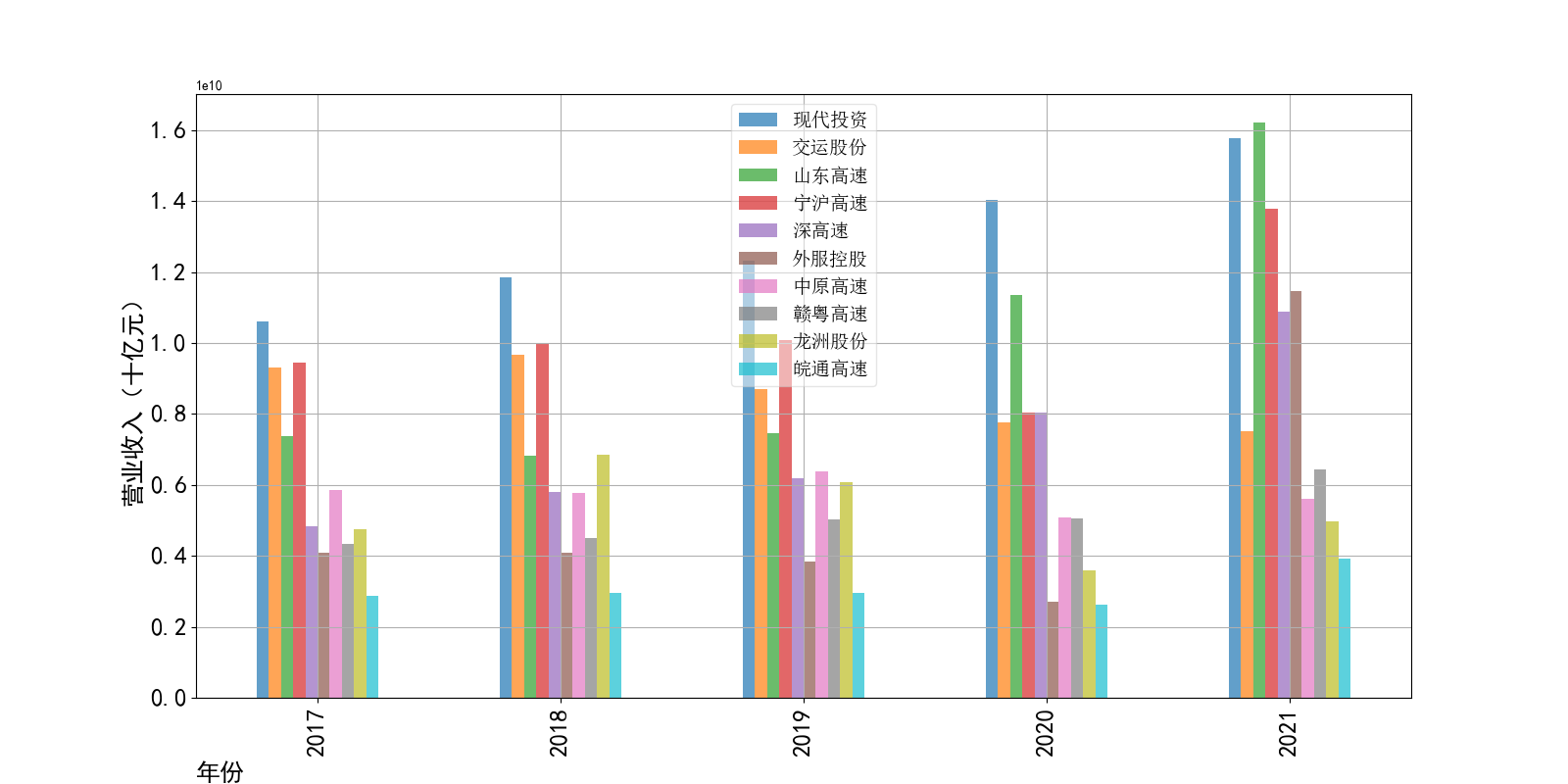
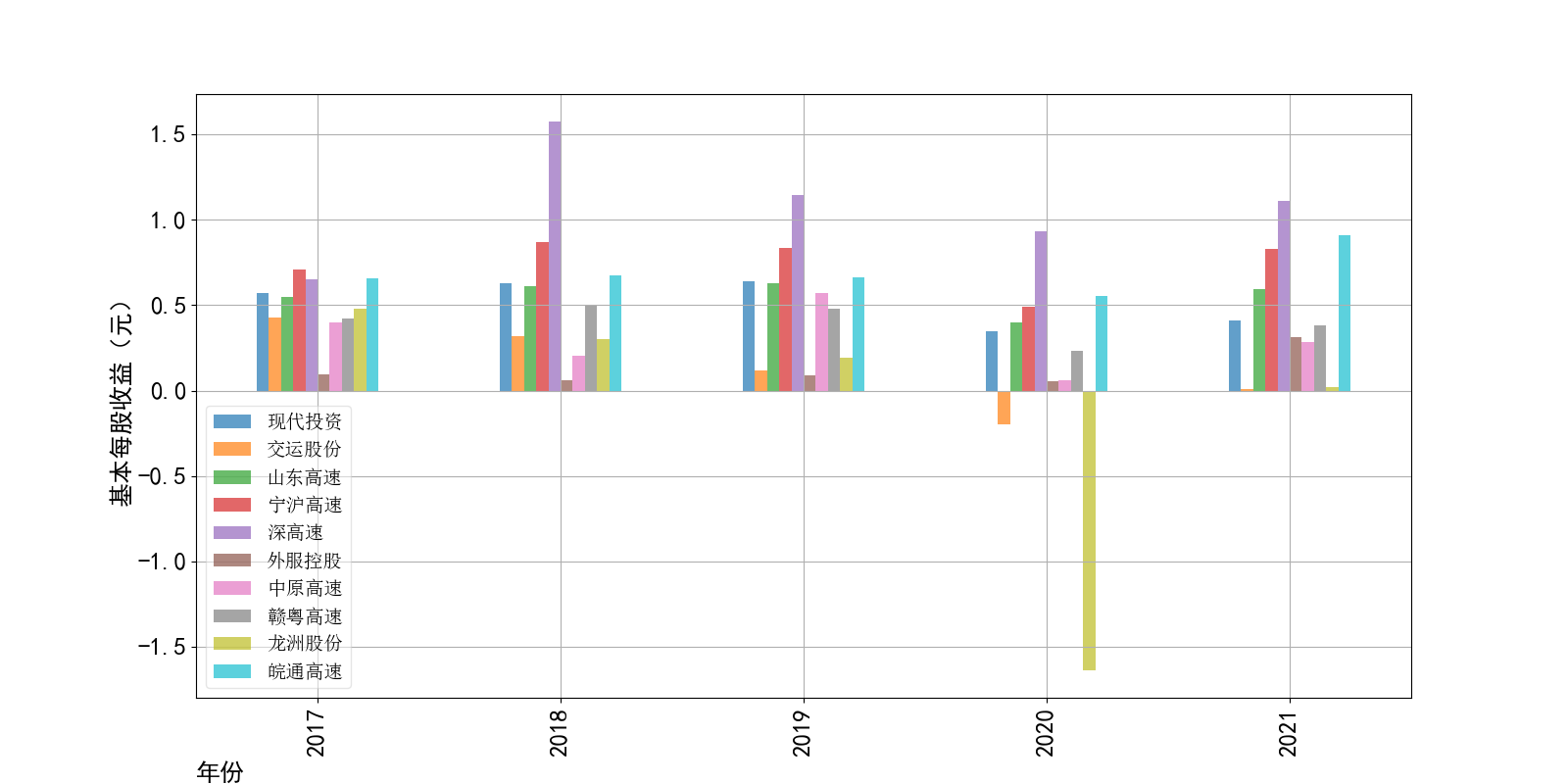
物流运输行业的主管部门为交通运输部,其主要职责是承担涉及综合运输体系的规划协调工作,组织拟订并监督实施公路、水路、民航等行业规划、 政策和标准,组织起草法律法规草案,制定部门规章,承担道路、水路运输市场监管责任。 县级以上地方人民政府交通主管部门负责组织领导本行政区域的道路运输管理工作,县级以上道路运输管理机构负责具体实施道路运输管理工作。道路运输行业的自律组织为中国道路运输协会、中国物流与采购联合会、中国交通运输协会等组织,主要承担行业引导和服务职能。
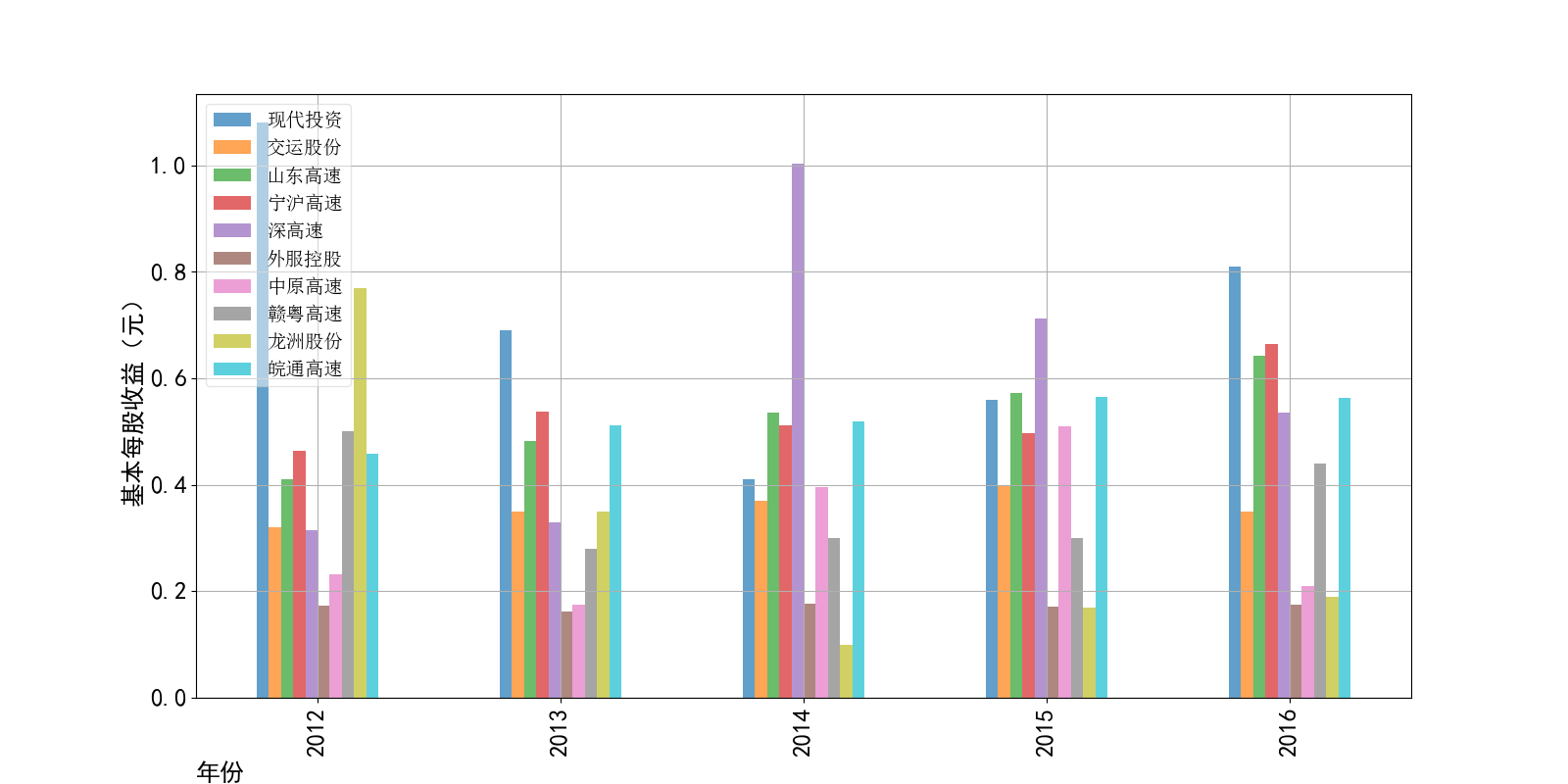
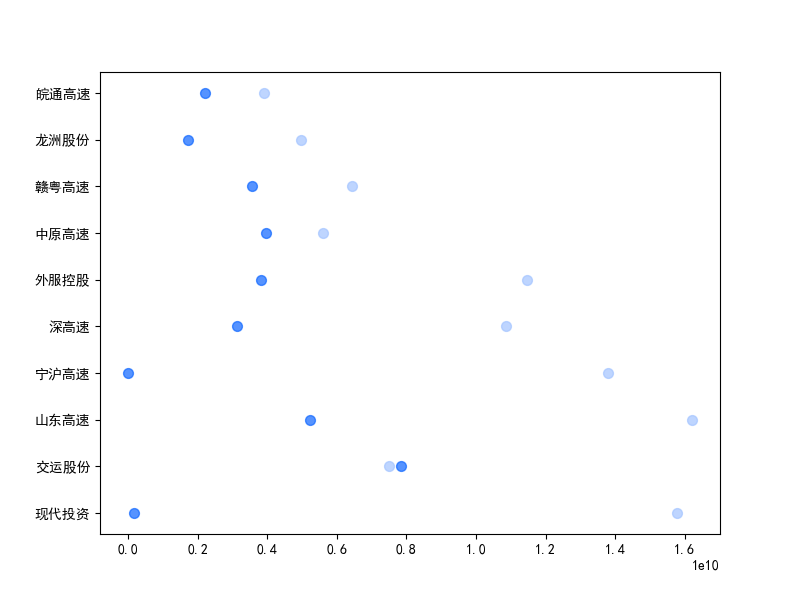
营业收入解读,根据绘图结果可知,道路运输行业的几家头部公司均为国企,在国家力量的支持下近十年来营业收入在稳步上升,总体上上升平稳。其中现代 投资更是从十年前的末尾一直以高速度增长冲击行业龙头。此外还可以观察到在2020年行业内各上市公司的营业收入大都有所下滑,并在2021年又迎来了营业 收入增长的高峰,表明在2021年度国家的疫情防控政策下,稳中有进。
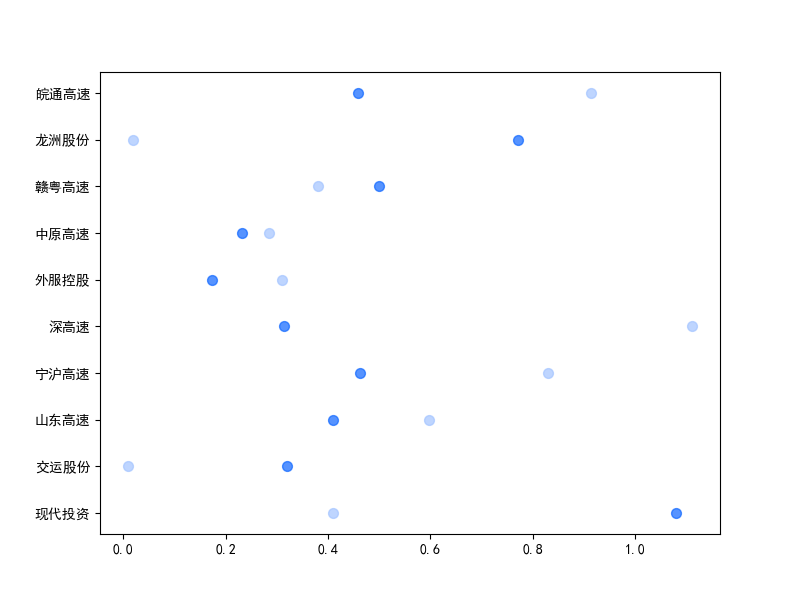
基本每股收益解读,根据绘图结果可知,十家上市公司十年来,除去疫情的冲击影响外,净利润基本保持不变。然而在2020年,有两家公司的净利润为负, 作为十家行业标杆,其中两家公司的净利润依然下降为负,足见疫情冲击对于整个行业利润的巨大影响。然而作为国企,担当大于使命,在2021年后,基本每股 收益又回归到了合理的水平。
这真的是一次超大体量的作业,个人在不断的学习与交流中才一点一点地将代码摸索出来,这个过程中发现每个人的代码逻辑其实是极不一样的, 很多时候并不能死磕自己的逻辑,有时候适当放松借鉴别人的代码逻辑会有柳暗花明又一村的感觉,整个过程中是要不断去修改删减的,而且在基础功 并不扎实的情况下,也许细水长流每天写一些些代码会是很有帮助的,如果在大脑十分疲惫的情况下死磕一点,将会得不偿失
感谢老师的悉心教导
,本学期的教学方式非常独特,老师有自己个人的教学平台,我们也有机会实操一把设计自己网页的机会,是十分难得的。而且老师 上课循循善诱的样子、以及非常贴心的各种教学资料、错误总结等等为我们整合出自己的实验报告扫平了很多障碍,整个学期的学习十分充实!!! 本学期了解并运用了正则表达式、网络爬虫、数据存储、年报解析等等,涉及的编程知识十分丰富,参与的软件也十分多,让个人的逻辑思维与电脑操作水平 得到了长足的进步