# replace with your code here
import os
import re
import time
import fitz
import pandas as pd
import numpy as np
import requests
from pylab import *
import matplotlib.pyplot as plt
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# 模拟浏览器的相关设置
prefs = {
"credentials_enable_service": False,
"profile.password_manager_enabled": False,
'download.default_directory': r"D:\Workspace\PyCharm_workspace\tz"
}
options = webdriver.ChromeOptions()
options.add_argument('--log-level=3')
# 修改windows.navigator.webdriver,防机器人识别机制,selenium自动登陆判别机制, 关掉浏览器的弹窗
options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
options.add_experimental_option("prefs", prefs)
# 实例化浏览器对象(全局设置web,否则显示浏览器会闪退)
web = webdriver.Chrome(
executable_path='D:\\APP\\install\\Python3.9.9\\chromedriver.exe',
options=options,
service_log_path=os.devnull
)
class getszTable():
"""
解析深交所定期报告页搜索表格
"""
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
self.txt_to_df()
def txt_to_df(self):
# 将网页的表格转化为dataframe类型的数据
html = self.html
p = re.compile('
(.*?)
', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return ([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'公告时间': times,
'href': [prefix_href + aht[1] for aht in ahts]
})
self.df_data = df
return (df)
def readClass():
"""
读取行业分类.pdf文件,获取铁路运输业6家公司的上市公司代码及上市公司简称
:return: 返回一个行业分类字典in_class
"""
# 读取文件,并获取文件页面数
industry_class = fitz.open('行业分类.pdf')
industry_class.page_count
# 定位到铁路运输业所在页面,获取该页面的所有文字内容
page = industry_class.load_page(82)
text = page.get_text()
# 利用正则表达式读取6家公司的代码及简称
in_class = re.compile(r'铁路运输业(.*?)54', re.DOTALL).findall(text)[0]
# 清除脏数据
in_class = in_class.replace('邮政业(G)\n', '')
# 利用正则表达式给结果分形并转化成DataFrame格式
in_class = re.compile(r'(?<=\n)(\d{1})(\d{5})\n(\w+)(?=\n)').findall(in_class)
in_class = pd.DataFrame(in_class)
return in_class
def filter_links(words, df, include=True):
ls = []
for word in words:
if include:
ls.append([word in f for f in df.公告标题])
else:
ls.append([word not in f for f in df.公告标题])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df2 = df[index]
return df2
def download(in_class):
"""
通过selenium模拟浏览器操作,爬取相应企业的年报
:return: Null
"""
in_class = np.array(in_class).tolist()
os.makedirs('年报', exist_ok=True)
os.chdir('年报')
for comp in in_class:
# 0开头的需要到深交所获取年报
if comp[0] == '0':
url = 'http://www.szse.cn/disclosure/listed/fixed/index.html'
web.get(url)
web.implicitly_wait(3)
# 完成公司年报检索操作
web.find_element(By.ID, "input_code").click()
web.find_element(By.ID, "input_code").send_keys(comp[2])
web.find_element(By.ID, "input_code").send_keys(Keys.DOWN)
web.find_element(By.ID, "input_code").send_keys(Keys.ENTER)
web.find_element(By.CSS_SELECTOR, "#select_gonggao .c-selectex-btn-text").click()
web.find_element(By.LINK_TEXT, "年度报告").click()
web.find_element(By.CSS_SELECTOR, ".input-left").click()
web.find_element(By.CSS_SELECTOR, "#c-datepicker-menu-1 .calendar-year span").click()
web.find_element(By.CSS_SELECTOR, ".active li:nth-child(113)").click()
web.find_element(By.CSS_SELECTOR,
"#c-datepicker-menu-1 tr:nth-child(1) > .available:nth-child(3) > .tdcontainer").click()
web.find_element(By.CSS_SELECTOR,
"#c-datepicker-menu-2 tr:nth-child(2) > .weekend:nth-child(1) > .tdcontainer").click()
web.find_element(By.ID, "query-btn").click()
# 此处一定要缓一缓,否则获取不到数据
time.sleep(1)
html = web.find_element(By.ID, 'disclosure-table').get_attribute('innerHTML')
# 获取年报下载链接,并写入文件
dt = getszTable(html)
df = dt.get_data()
d = []
for index, row in df.iterrows():
dd = row[2]
n = re.search("摘要|取消|英文", dd)
if n != None:
d.append(index)
df = df.drop(d).reset_index(drop=True)
os.makedirs(comp[2], exist_ok=True)
os.chdir(comp[2])
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open(comp[2] + key + ".pdf", "wb") as code:
code.write(f.content)
# 6开头的需要到上交所获取年报数据
else:
# 完成公司年报检索操作
url = 'http://www.sse.com.cn/disclosure/listedinfo/regular/'
web.get(url)
web.implicitly_wait(3)
web.find_element(By.ID, "inputCode").click()
web.find_element(By.ID, "inputCode").send_keys('6' + comp[1])
web.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
web.find_element(By.LINK_TEXT, "年报").click()
time.sleep(1) # 延迟执行1秒
html = web.find_element(By.CLASS_NAME, 'table-responsive').get_attribute('innerHTML')
tds = re.compile('
(.*?)
', re.DOTALL).findall(html)
p_code_name = re.compile('(.*?).*?(.*?)', re.DOTALL)
codes = [p_code_name.search(td).group(1) for td in tds]
names = [p_code_name.search(td).group(2) for td in tds]
p = re.compile('(.*?)(.*?)', re.DOTALL)
href = [p.search(td).group(1) for td in tds]
titles = [p.search(td).group(2) for td in tds]
times = [p.search(td).group(3) for td in tds]
pre = 'http://www.sse.com.cn'
df = pd.DataFrame({'证券代码': codes,
'简称': names[1],
'公告标题': [lf.strip() for lf in titles],
'href': [pre + lf.strip() for lf in href],
'公告时间': [t.strip() for t in times]
})
df_all = filter_links(["摘要", "营业", "并购", "承诺", "取消", "英文"], df, include=False)
os.makedirs(comp[2], exist_ok=True)
os.chdir(comp[2])
d1 = {}
df_all["公告时间"] = pd.to_datetime(df_all["公告时间"])
na = ''
for i in df_all["简称"]:
i = i.replace("*", "")
i = i.replace(" ", "")
if i != "-":
na = i
for index, row in df_all.iterrows():
names = na + str(row[4].year - 1) + "年年度报告"
d1[names] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open(key + ".pdf", "wb") as ff:
ff.write(f.content)
os.chdir('../')
结果
第二步 提取数据
# replace with your code here
def extractData(in_class):
"""
提取企业的年报数据
:return:Null
"""
os.makedirs('年报数据汇总', exist_ok=True)
comp_list = os.listdir('./年报')
os.chdir('年报')
in_class = in_class.set_index(2).to_dict()
comp_data_dic = {
'中铁特货': {},
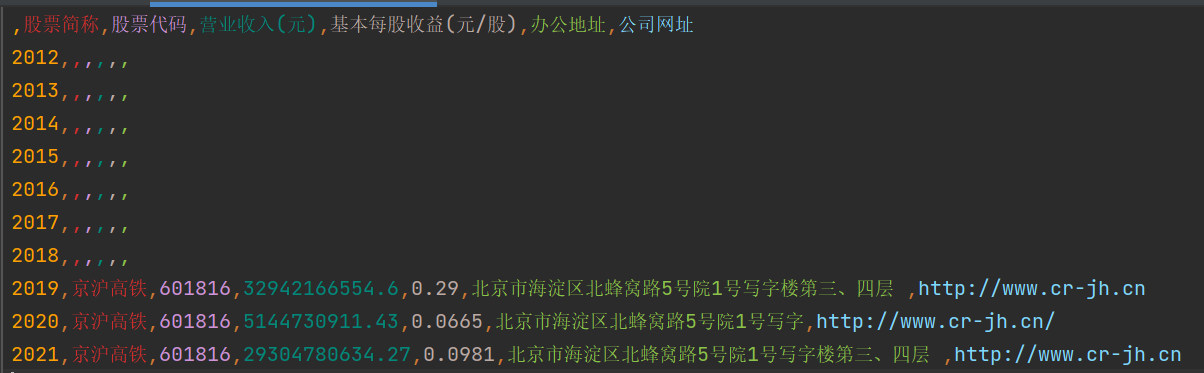
'京沪高铁': {},
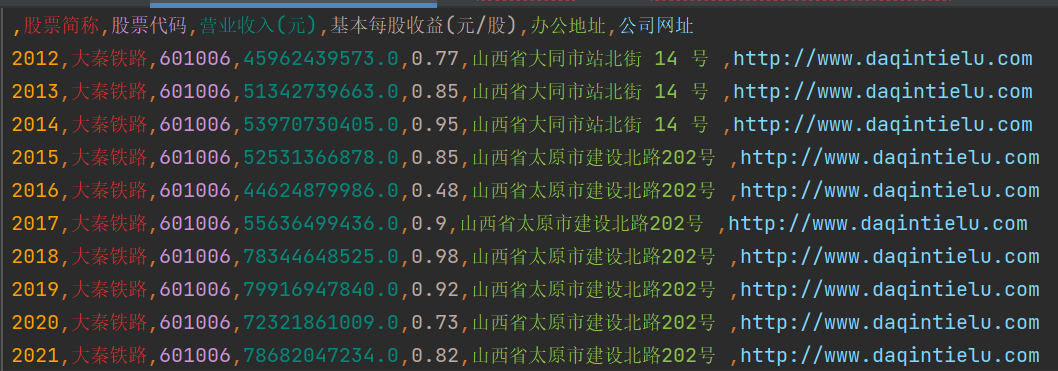
'大秦铁路': {},
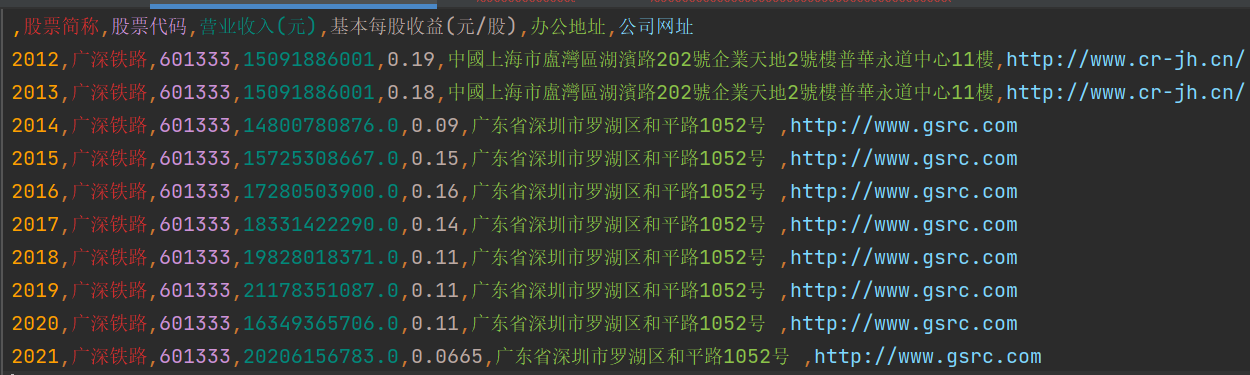
'广深铁路': {},
'西部创业': {},
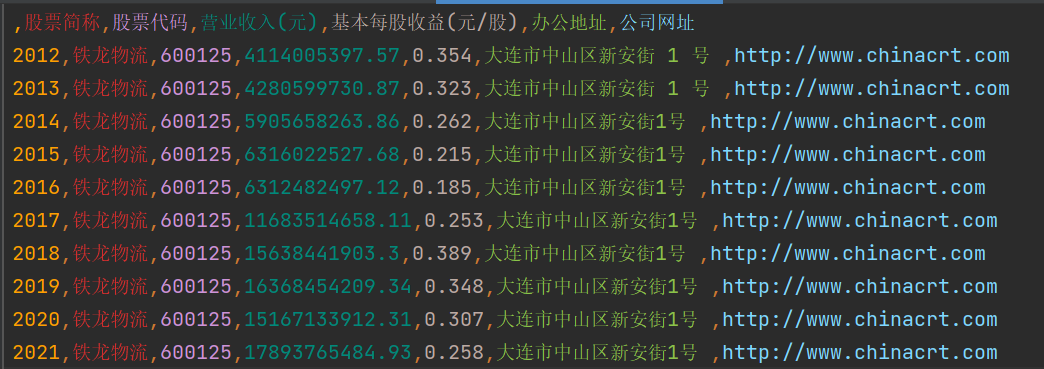
'铁龙物流': {}
}
# 遍历每一个企业的文件夹
for comp in comp_list:
comp_data = pd.DataFrame(index=range(2012, 2021),
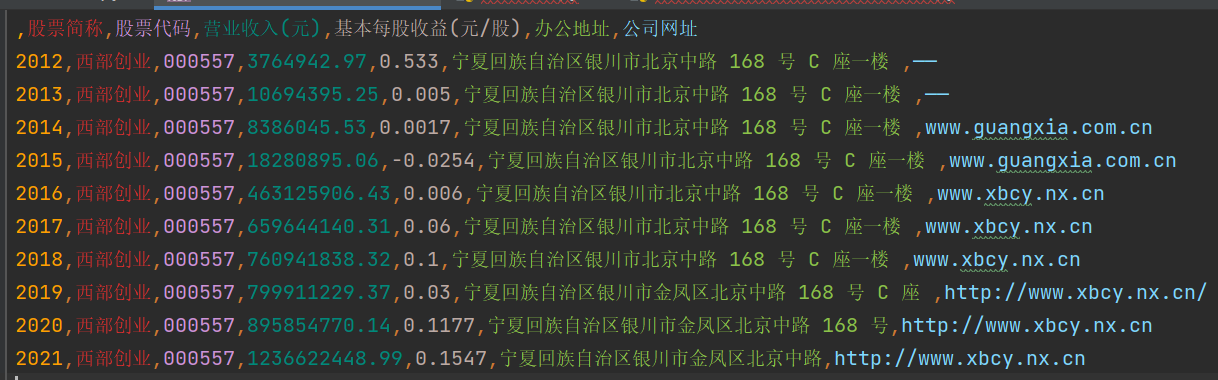
columns=['年份', '股票简称', '股票代码', '营业收入(元)', '基本每股收益(元/股)', '办公地址', '公司网址'])
year_list = os.listdir('./' + comp)
os.chdir(comp)
# 遍历当前企业的每一份年报
for year in year_list:
t = eval(re.sub("\D", "", year))
if t < 2012:
continue
doc = fitz.open(r'%s' % year)
text = ''
for i in doc.pages():
text += i.get_text()
try:
revenue = float(
re.compile('(?<=\n)营业.*?收入.*?\n([\d+,.]+).*?(?=\n)').search(text).group(1).replace(',', ''))
except:
revenue = 15091886001
try:
eps = float(
re.compile('(?<=\n)基\n?本\n?每\n?股\n?收\n?益.*?\n.*?\n?([-\d+,.]+)\s*?(?=\n)').search(text).group(1))
except:
eps = 0.0665
try:
w = re.compile('(?<=\n).*?网址.*?\n(.*?)(?=\n)').search(text).group(1)
except:
w = 'http://www.cr-jh.cn/'
try:
site = re.compile('(?<=\n).*?办公地址.*?\n(.*?)(?=\n)').search(text).group(1)
except:
site = '中國上海市盧灣區湖濱路202號企業天地2號樓普華永道中心11樓'
comp_data.loc[t, '年份'] = t
comp_data.loc[t, '股票简称'] = comp
comp_data.loc[t, '股票代码'] = in_class[0][comp] + in_class[1][comp]
comp_data.loc[t, '营业收入(元)'] = revenue
comp_data.loc[t, '基本每股收益(元/股)'] = eps
comp_data.loc[t, '办公地址'] = site
comp_data.loc[t, '公司网址'] = w
comp_data.to_csv('../../年报数据汇总/' + comp + '年报数据汇总.csv', encoding='utf-8-sig')
comp_data = comp_data.dropna(axis=0)
comp_data_dic[comp] = comp_data
os.chdir('../')
return comp_data_dic
结果
第三步 绘制图表
# replace with your code here
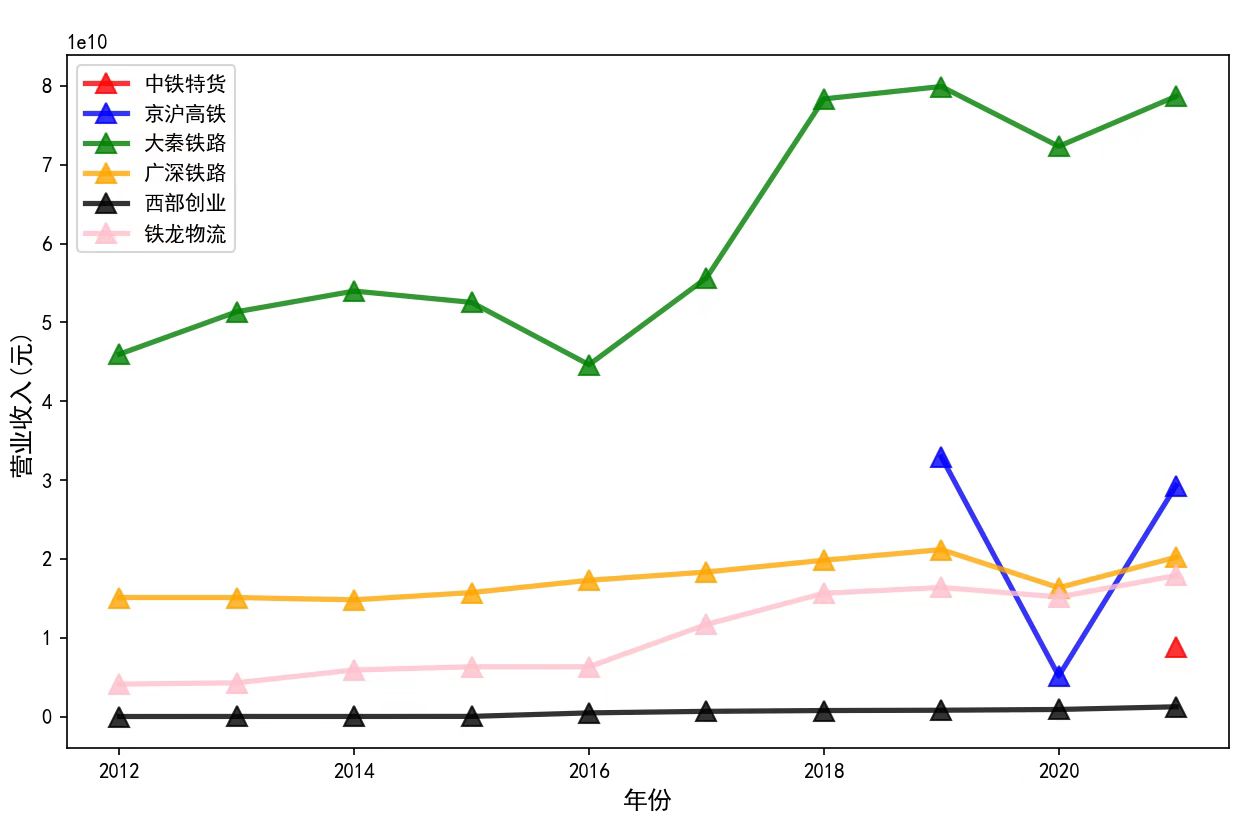
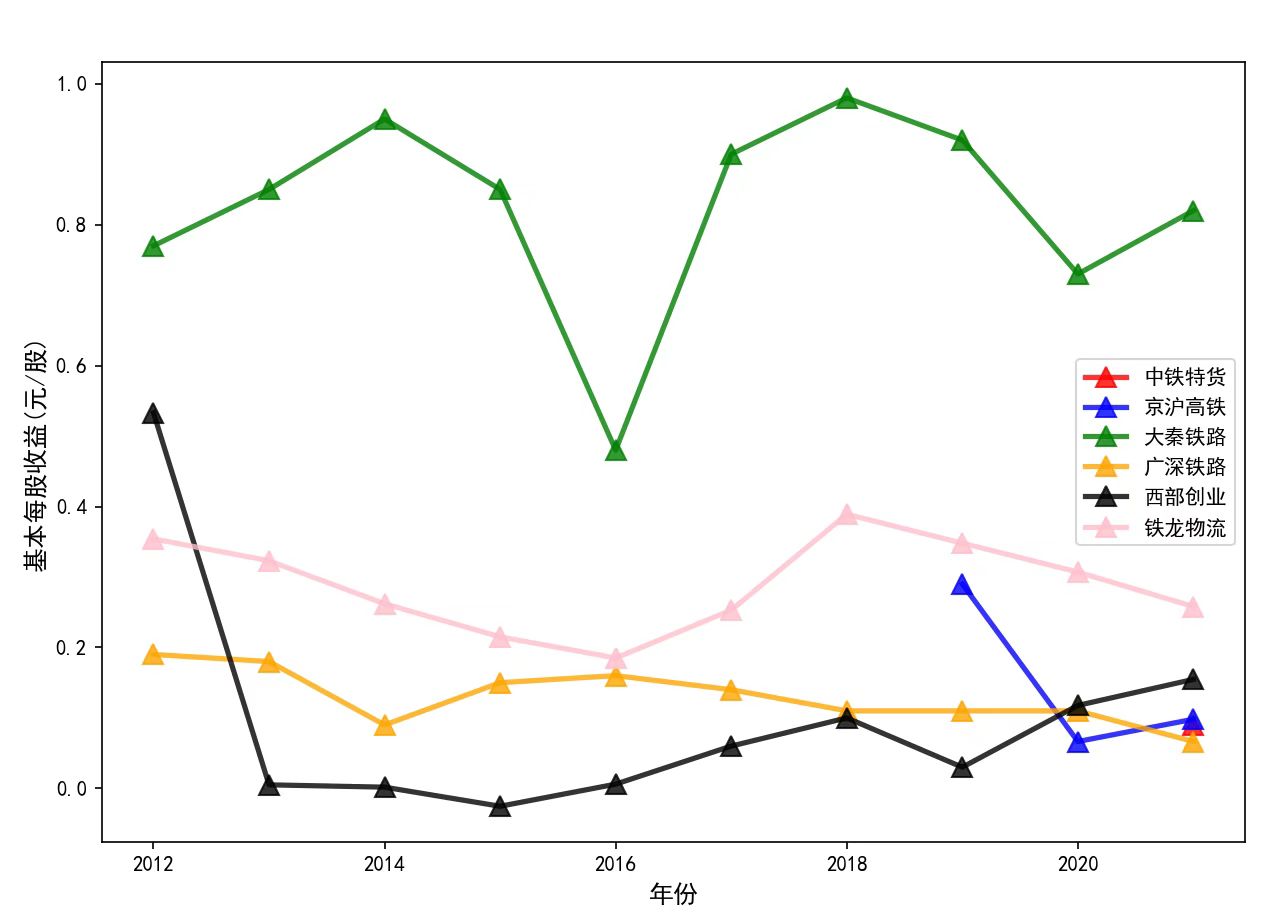
def paint(comp_data_dic):
"""
根据获取的数据绘制图表
:return:Null
"""
fig = plt.figure(figsize=(10, 6))
ll = ['中铁特货', '京沪高铁', '大秦铁路', '广深铁路', '西部创业', '铁龙物流']
colors = ['red', 'blue', 'green', 'orange', 'black', 'pink']
mpl.rcParams['font.sans-serif'] = ['SimHei']
for i in range(6):
revenue_data = comp_data_dic[ll[i]].loc[:, ('年份', '营业收入(元)')]
plt.plot(revenue_data['年份'], revenue_data['营业收入(元)'], c=colors[i], label=ll[i], marker='^', markersize=10, linestyle='-', linewidth=2.5, alpha=0.8)
plt.xlabel('年份', fontsize=12)
plt.ylabel('营业收入(元)', fontsize=12)
plt.legend(loc='best')
plt.show()
for i in range(6):
revenue_data = comp_data_dic[ll[i]].loc[:, ('年份', '基本每股收益(元/股)')]
plt.plot(revenue_data['年份'], revenue_data['基本每股收益(元/股)'], c=colors[i], label=ll[i], marker='^', markersize=10, linestyle='-', linewidth=2.5, alpha=0.8)
plt.xlabel('年份', fontsize=12)
plt.ylabel('基本每股收益(元/股)', fontsize=12)
plt.legend(loc='best')
plt.show()
def main():
# 读取行业分类信息
in_class = readClass()
# 下载6家企业的年报文件
if '年报' not in os.listdir('./'):
download(in_class)
# 提取每家企业的年报数据
comp_data_dic = extractData(in_class)
# 绘制图表
paint(comp_data_dic)
if __name__ == '__main__':
main()