# replace with your code here
import pandas as pd
import json
import os
import time
from time import sleep
from urllib import parse
from datetime import datetime
import requests
from skimage import io
df = pd.read_excel('D:\金融数据获取与处理\期末作业\gs6.xlsx')
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 20,
'maxListNum': 100,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId,plate,code)
return orgId, plate, code
def download_PDF(url, file_name): #下载pdf
url = url
r = requests.get(url)
f = open(bank +"/"+ file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '2012-01-01~2022-06-01',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle'] or '(已取消)' in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:"+pdf_url,"存放在当前目录:/"+bank+"/"+file_name)
download_PDF(pdf_url, file_name)
sleep(2)
if __name__ == '__main__':
bank_list = df['公司']
#bank_list = ["平安银行"]
for bank in bank_list:
os.mkdir(bank)
orgId, plate, code = get_adress(bank)
get_PDF(orgId, plate, code)
print("下一家~")
print("All done!")
如果所写代码复杂,且没有良好的注释,那么请在这里补充解释。
import fitz
import re
import pandas as pd
doc = fitz.open(r'SF2021.PDF')
class NB():
'''
解析上市公司年度报告
'''
#初始化
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
#解析目录
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
# p = re.compile('(第(?:[%s]|十[%s]|二十)节)' % (jie_zh,jie_zh[0:-1]))#匹配第一到二十
#p=re.compile('(第十[%s]{1,2}节)' % jie_zh[0:-1])#匹配第十一到第十九
# p=re.compile('(第二十节)')#匹配第二十
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages, jie_title = {}, {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
#目标页的页码, 即pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p; break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
def parse_revenue_table(self):
page_number = self.key_fin_data_page
page = self.doc[page_number]
txt = page.get_text()
#
pt = '(.*?)(20\d{2}年)\s*(20\d{2}年)\s*(.*?)\s*(20\d{2}年)\s*'
pt = '(?<=主要会计数据和财务指标)' + pt + '(?=营业收入)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0] # 获取标题行
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[:txt.find('总资产')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[3] for t in data],
title[4]: [t[4] for t in data]})
# return((df,title))
self.revenue_table = df
return(df)
sf2021 = NB('SF2021.pdf')
# sf2021.jie_pages_title()
jie_pages = sf2021.jie_pages
jie_title = sf2021.jie_title
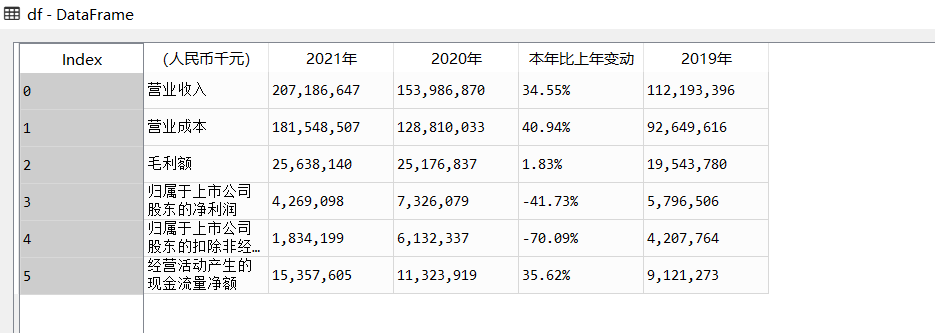
df = sf2021.parse_revenue_table()
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # Find the search box
element.send_keys('苏宁易购' + Keys.RETURN)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open('innerHTML.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
import re
import pandas as pd
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
f = open('innerHTML.html',encoding='utf-8')
html = f.read()
f.close()
dt = DisclosureTable(html)
df = dt.get_data()
df.to_csv('data.csv')