获取所有公司HTML
import re
import time
import pdfplumber
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#获取所有公司简称
doc = pdfplumber.open(r'H:\python\作业\行业分类.PDF')
pages = doc.pages
page59 = pages[58]
table = page59.extract_tables()
df = pd.DataFrame(table[1:], columns = table[0])
companys = list(list(df)[-1])[-4:]
companys_all = []
for a in range(len(companys)):
company = companys[a]
companys_all.append(company)
for i in range(59, 70, 1):
page = pages[i]
table = page.extract_tables()
df = pd.DataFrame(table[1:], columns = table[0])
companys = list(list(df)[-1])[1:]
for b in range(len(companys)):
company = companys[b]
companys_all.append(company)
companys_all = [t.replace('*','') for t in companys_all]
#深交所公司获取HTML
def get_HTML_szse(company):
companys_all_szse = []
companys_all_sse = []
browser = webdriver.Edge()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(2)
element = browser.find_element(By.ID, 'input_code')
element.send_keys(company + Keys.RETURN)
browser.find_element(By.CSS_SELECTOR, "#select_gonggao .glyphicon").click()
browser.find_element(By.LINK_TEXT, "年度报告").click()
time.sleep(2)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
time.sleep(2)
p1 = '(.*?)'
text = re.findall(p1, innerHTML, re.DOTALL)
if text is not None:
companys_all_szse.append(company)
return(companys_all_szse)
f = open(company + 'innerHTML.html', 'w', encoding = 'utf-8')
f.write(innerHTML)
f.close()
time.sleep(2)
browser.quit()
if text == '':
browser.quit()
companys_all_sse.append(company)
return(companys_all_sse)
for company in companys_all:
try:
get_HTML_szse(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#上交所公司获取HTML
def get_HTML_sse(company):
browser = webdriver.Edge()
time.sleep(2)
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
time.sleep(5)
element = browser.find_element(By.ID, 'inputCode')
element.send_keys(company + Keys.RETURN)
time.sleep(2)
element = browser.find_element(By.ID, 'js_panMenu')
html = element.get_attribute('innerHTML')
p2 = ''
x = re.findall(p2, html, re.DOTALL)
browser.quit()
browser = webdriver.Edge()
time.sleep(2)
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
time.sleep(5)
element = browser.find_element(By.ID, 'inputCode')
element.send_keys(x[0] + Keys.RETURN)
time.sleep(2)
browser.find_element_by_css_selector('body > div.container.sse_content > div > div.col-lg-3.col-xxl-2 > div > div.sse_outerItem.js_reportType > div.sse_searchInput').click()
browser.find_element_by_css_selector("body > div.container.sse_content > div > div.col-lg-3.col-xxl-2 > div > div.sse_outerItem.js_reportType > div.sse_searchInput > div > div > div > ul > li:nth-child(2) > a > span").click()
time.sleep(2)
element = browser.find_element_by_css_selector('body > div.container.sse_content > div > div.col-lg-9.col-xxl-10 > div > div.sse_colContent.js_regular > div.table-responsive > table')
innerHTML = element.get_attribute('innerHTML')
time.sleep(2)
f = open(company + 'innerHTML.html', 'w', encoding = 'utf-8')
f.write(innerHTML)
f.close()
time.sleep(2)
browser.quit()
for company in companys_all_sse:
try:
get_HTML_sse(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#获取PDF
import re
import time
import requests
import pandas as pd
#深交所公司获取近十年内下载链接
def get_link(company):
attachpath = []
date = []
attachpaths = []
dates = []
attachpaths_all = []
dates_all = []
p_attachpath = ''
p_date = '(.*?)'
f = open(company + 'innerHTML.html', encoding = 'utf-8')
html = f.read()
f.close()
attachpath = re.findall(p_attachpath, html, re.DOTALL)
date = re.findall(p_date, html, re.DOTALL)
for i in range(len(date)):
attachpath1 = 'https://disc.szse.cn/download' + attachpath[i]
date1 = date[i]
attachpaths.append(attachpath1)
dates.append(date1)
for b in range(len(attachpaths)):
for a in range(2012, 2022, 1):
if str(a) in dates[b]:
attachpaths_all.append (attachpaths[b])
dates_all.append (dates[b])
df = pd.DataFrame({'attachpath': attachpaths_all,'date': dates_all})
df.to_excel(company + '.xlsx')
for company in companys_all_szse:
try:
get_link(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#获取完整年报
def get_time(company):
data = pd.read_excel(company + '.xlsx')
attachpaths = (data[['attachpath']]).values.tolist()
dates = (data[['date']]).values.tolist()
attachpath1 = []
date1 = []
attachpaths_all = []
dates_all = []
for i in range(len(attachpaths)):
attachpath = attachpaths[i][0]
attachpath1.append(attachpath)
for i in range(len(dates)):
date = dates[i][0]
date1.append(date)
p = '20\d{2}年(.*)'
for i in range(len(dates)):
x = re.findall(p, date1[i])
if x[0] == '年度报告':
attachpath = attachpath1[i]
date = date1[i]
attachpaths_all.append(attachpath)
dates_all.append(date)
if x[0] == '年度报告(更新后)':
attachpath = attachpath1[i]
date = date1[i].strip('(更新后)')
attachpaths_all.append(attachpath)
dates_all.append(date)
df = pd.DataFrame({'attachpath': attachpaths_all,'date': dates_all})
df.to_excel(company + '(更新后).xlsx')
for company in companys_all_szse:
try:
get_time(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#下载PDF
def get_pdf(company):
data = pd.read_excel(company + '(更新后).xlsx')
attachpath1 = (data[['attachpath']]).values.tolist()
date1 = (data[['date']]).values.tolist()
attachpaths = []
dates = []
for i in range(len(attachpath1)):
attachpath = attachpath1[i][0]
attachpaths.append(attachpath)
for i in range(len(date1)):
date = date1[i][0]
dates.append(date)
for i in range (len(attachpaths)):
r = requests.get(attachpaths[i], allow_redirects=True)
time.sleep(10)
f = open(company + dates[i] + '.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
time.sleep(2)
for company in companys_all_szse:
try:
get_pdf(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#深交所公司获取近十年内下载链接
def get_link(company):
href = []
date = []
hrefs = []
dates = []
hrefs_all = []
dates_all = []
p_href = ''
p_date = '(.*?)'
f = open(company + 'innerHTML.html', encoding = 'utf-8')
html = f.read()
f.close()
href = re.findall(p_href, html, re.DOTALL)
date = re.findall(p_date, html, re.DOTALL)
for b in range(len(href)):
for a in range(2012, 2022, 1):
if str(a) in date[b]:
hrefs.append (href[b])
dates.append (date[b])
for i in range(len(dates)):
href1 = 'http://www.sse.com.cn' + href[i]
date1 =date[i]
hrefs_all.append(href1)
dates_all.append(date1)
df = pd.DataFrame({'href': hrefs_all,'date': dates_all})
df.to_excel(company + '.xlsx')
for company in companys_all_sse:
try:
get_link(company)
print (company + '获取成功')
except:
print (company + '获取失败')
#获取完整年报
def get_time(company):
data = pd.read_excel(company + '.xlsx')
hrefs = (data[['href']]).values.tolist()
dates = (data[['date']]).values.tolist()
href1 = []
date1 = []
hrefs_all = []
dates_all = []
for i in range(len(hrefs)):
href = hrefs[i][0]
href1.append(href)
for i in range(len(dates)):
date = dates[i][0]
date1.append(date)
p = '\w{1,}20\d{2}年(.*)'
for i in range(len(dates)):
x = re.findall(p, date1[i])
if x[0] == '年度报告':
href = href1[i]
date = date1[i]
hrefs_all.append(href)
dates_all.append(date)
if x[0] == '年度报告(更新后)':
href = href1[i]
date = date1[i].strip('(更新后)')
hrefs_all.append(href)
dates_all.append(date)
df = pd.DataFrame({'href': hrefs_all,'date': dates_all})
df.to_excel(company + '(更新后).xlsx')
for company in companys_all_sse:
try:
get_time(company)
print (company + '获取成功')
except:
print (company + '获取失败')
import re
import fitz
import pandas as pd
company_list = []
code_list = []
address_list = []
web_list = []
def get_main_info(company):
doc = fitz.open(company + '2021年年度报告.pdf')
text = [page.get_text() for page in doc]
text = ''.join(text)
p_s = re.compile(r'(?<=\n).*?联系人和联系方式.*?(?=\n)')
section = p_s.search(text)
s_idx = section.start()
txt = text[:s_idx]
p_code = re.compile('(?<=\n)\w*股票代码:?\s?\n?(\d{6})\s?(?=\n)', re.DOTALL)
p_address = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)', re.DOTALL)
p_web = re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-z-A-Z./:\d+]*)\s?(?=\n)', re.DOTALL)
code = p_code.findall(txt)[0].replace('\n','')
address = p_address.findall(txt)[0].replace('\n','')
web = p_web.findall(txt)[0].replace('\n','')
company_list.append(company)
code_list.append(code)
address_list.append(address)
web_list.append(web)
return(company_list, code_list, address_list, web_list)
for company in companys_all:
try:
get_main_info(company)
print (company + '获取成功')
except:
print (company + '获取失败')
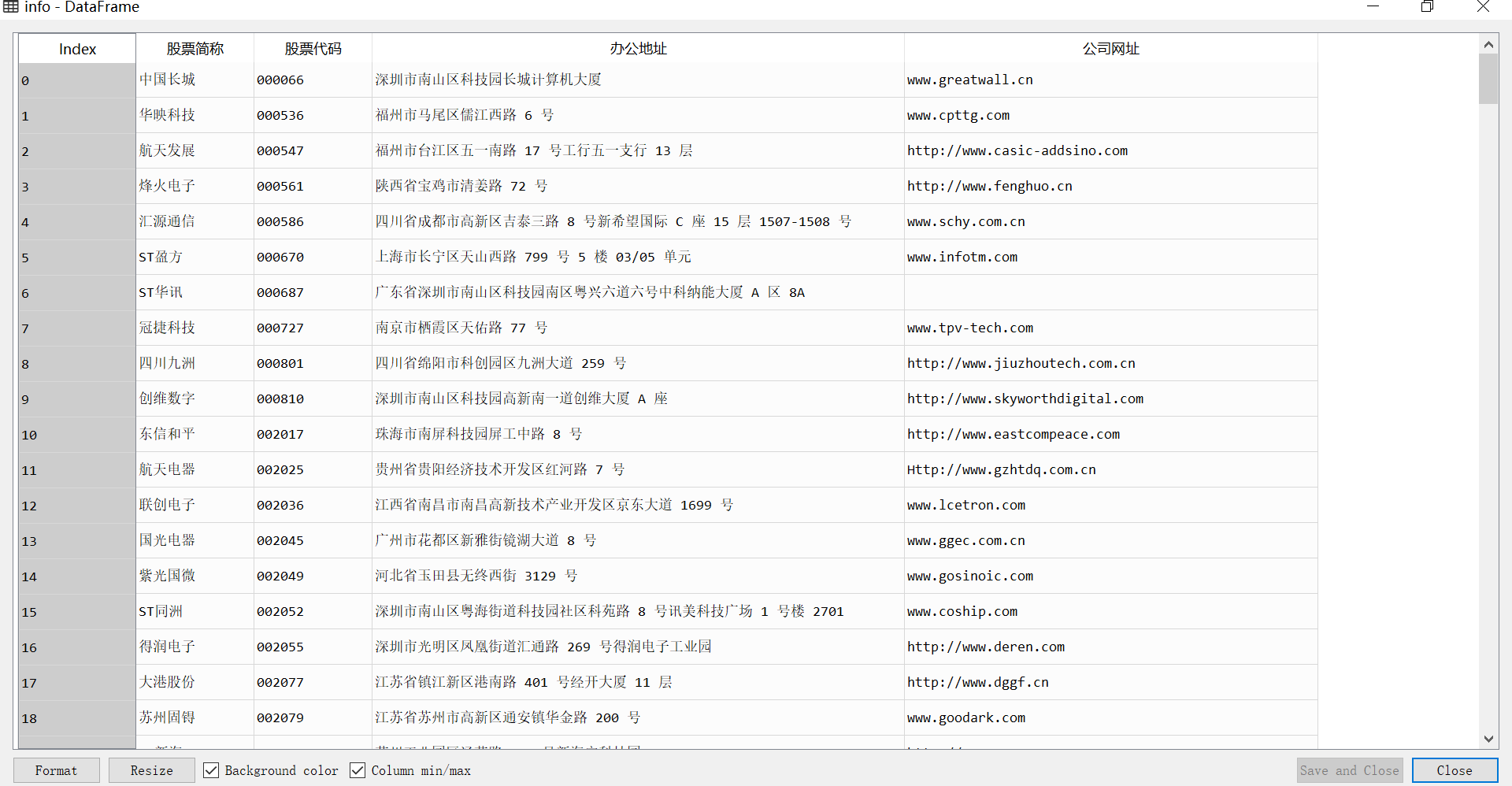
info = pd.DataFrame({'股票简称': company_list,
'股票代码': code_list,
'办公地址': address_list,
'公司网址': web_list})
info.to_csv('公司基本信息.csv')
import re
import fitz
import pandas as pd
def parse_revenue_table(company):
data = pd.read_excel(company + '(更新后).xlsx')
date1 = (data[['date']]).values.tolist()
dates = []
year_list = []
revenue_list = []
eps_list = []
for i in range(len(date1)):
date = date1[i][0]
dates.append(date)
for date in dates:
doc = fitz.open(company + date + '.pdf')
text = [page.get_text() for page in doc]
text = ''.join(text)
p_e = re.compile(r'(?<=\n)稀释每股收益.*?(?=\n)')
section = p_e.search(text)
e_idx = section.start()
txt = text[: e_idx]
p_revenue = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益\s?\n?(?:(元/?/?╱?\n?股))?\s?\n?([-\d+,.]*)\s?\n?')
revenue = p_revenue.findall(txt, re.DOTALL)[0]
revenue = re.sub(',', '', revenue)
eps = p_eps.findall(txt, re.DOTALL)[0]
year_list.append(date[0:4])
revenue_list.append(revenue)
eps_list.append(eps)
revenue_list = [float(x) for x in revenue_list]
eps_list = [float(x) for x in eps_list]
data = pd.DataFrame({'年份': year_list,
'营业收入(元)': revenue_list,
'基本每股收益(元/股)': eps_list})
data.to_csv(company + 'data.csv', encoding = 'utf-8-sig')
for company in companys_all:
try:
parse_revenue_table(company)
print (company + '获取成功')
except:
print (company + '获取失败')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#获取营业收入前十的公司数据
df_revenue = pd.DataFrame()
def get_all_revenue(company):
global df_revenue
df = pd.read_csv(company + 'data.csv', index_col=1, header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed', case=False)], axis=1)
df_revenues = pd.DataFrame(df['营业收入(元)'])
df_revenues = df_revenues.rename(columns={'营业收入(元)': company})
df_revenue = pd.concat([df_revenue, df_revenues], axis=1)
return(df_revenue)
for company in company_list:
try:
get_all_revenue(company)
print (company + '获取成功')
except:
print (company + '获取失败')
df_revenue = df_revenue.fillna(0).T
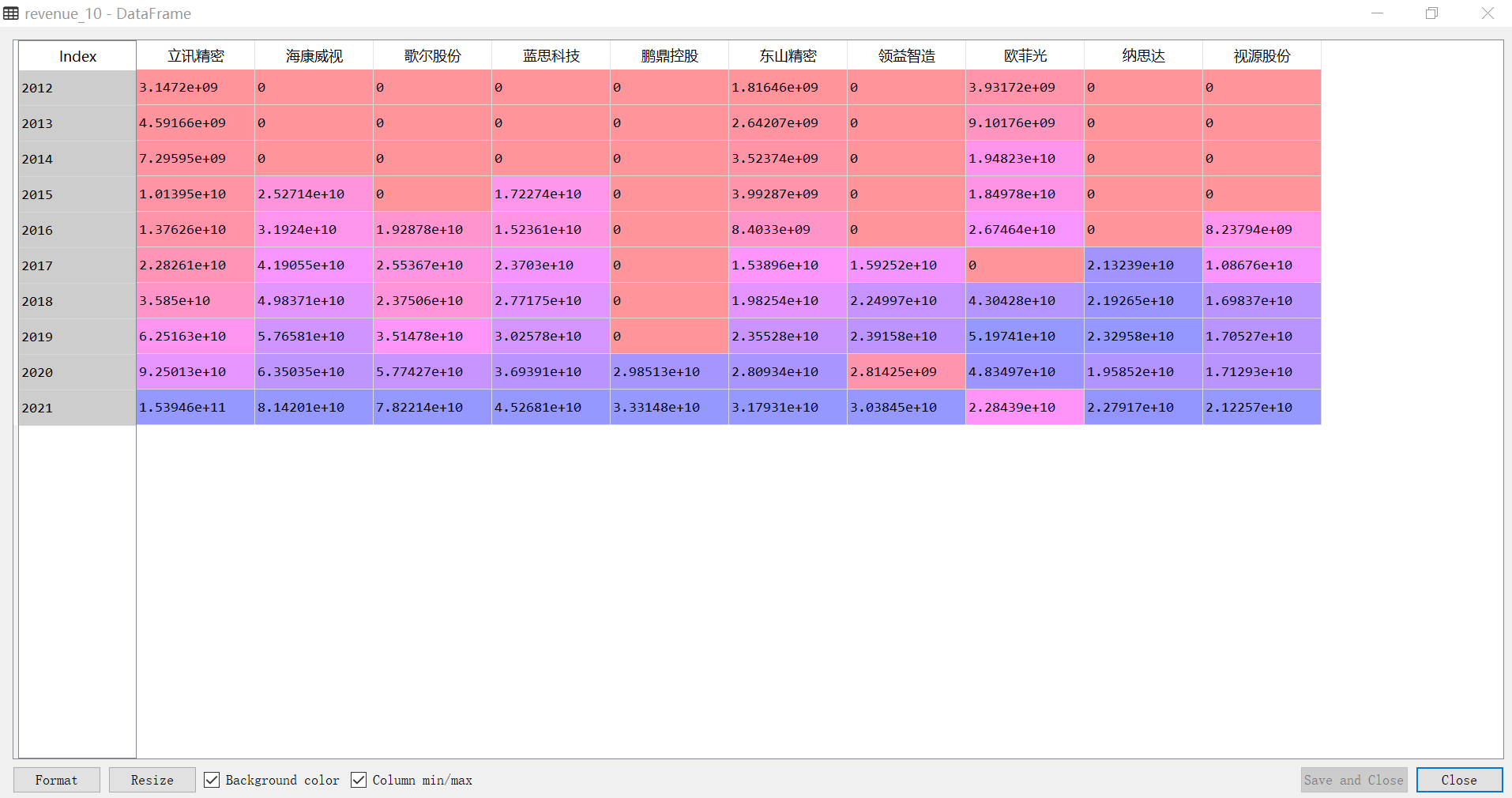
revenue_10 = df_revenue[['立讯精密', '海康威视', '歌尔股份', '蓝思科技', '鹏鼎控股', '东山精密', '领益智造', '欧菲光', '纳思达', '视源股份']]
df_eps = pd.DataFrame()
def get_all_revenue(company):
global df_eps
df = pd.read_csv(company +'data.csv', index_col=1, header=0)
df = df.drop(df.columns[df.columns.str.contains('unnamed', case=False)], axis=1)
df_epss = pd.DataFrame(df['基本每股收益(元/股)'])
df_epss = df_epss.rename(columns={'基本每股收益(元/股)': company})
df_eps = pd.concat([df_eps, df_epss], axis=1)
for company in company_list:
try:
get_all_revenue(company)
print (company + '获取成功')
except:
print (company + '获取失败')
df_eps = df_eps.fillna(0).T
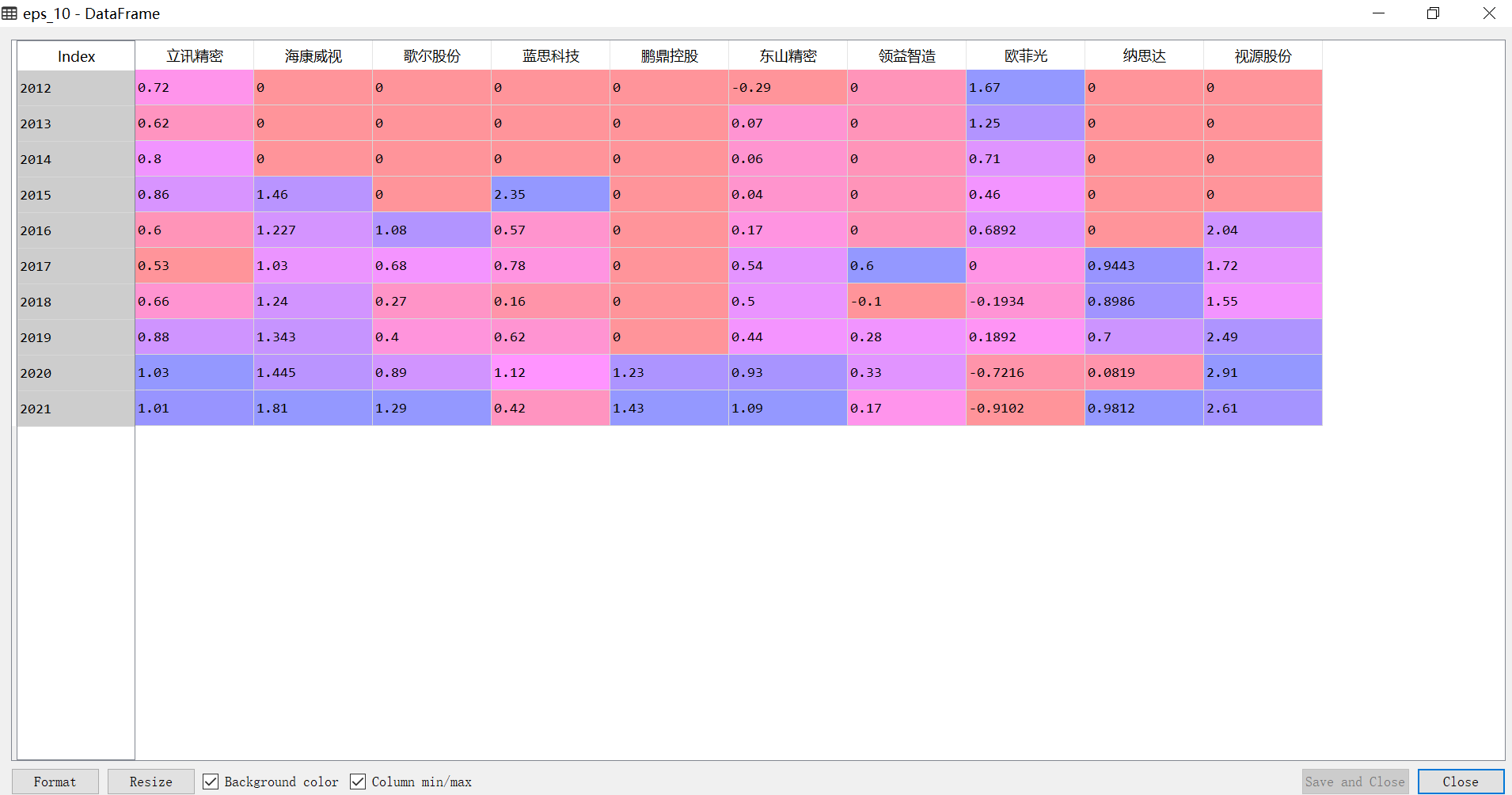
eps_10 = df_eps[['立讯精密', '海康威视', '歌尔股份', '蓝思科技', '鹏鼎控股', '东山精密', '领益智造', '欧菲光', '纳思达', '视源股份']]
#画十年营业收入和基本每股收益对比图
plt.plot(revenue_10, marker='*')
plt.legend(revenue_10.columns)
plt.title('行业上市公司营业收入时间序列图')
plt.xlabel('年份')
plt.ylabel('营业收入(元)')
plt.grid()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(eps_10,marker = '*')
plt.legend(eps_10.columns)
plt.title('行业上市公司基本每股收益时间序列图')
plt.xlabel('年份')
plt.ylabel('基本每股收益(元/股)')
plt.grid()
#画十家公司时间变化趋势图
company_10 = ['立讯精密', '海康威视', '歌尔股份', '蓝思科技', '鹏鼎控股', '东山精密', '领益智造', '欧菲光', '纳思达', '视源股份']
xpoints = np.array(revenue_10.index)
ypoints = np.array(revenue_10[['视源股份']])
plt.title('视源股份')
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.plot(xpoints, ypoints, marker = 'o')
plt.show
xpoints = np.array(eps_10.index)
ypoints = np.array(eps_10[['视源股份']])
plt.title('视源股份')
plt.xlabel('年份')
plt.ylabel('营业收入')
plt.plot(xpoints, ypoints, marker = 'o')
plt.show






















如果所写代码复杂,且没有良好的注释,那么请在这里补充解释。