import re
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
element = browser.find_element(By.ID, 'input_code') # ID定位到搜索框
element.send_keys('航天科技' + Keys.RETURN) # 输入想要查找的企业
#element.send_keys('巨轮智能' + Keys.RETURN)
#element.send_keys('华茂股份' + Keys.RETURN)
time.sleep(2)
def element_exist(driver,element): #判断企业年报数量是否存在下一页
flag = True
try:
driver.find_element(By.PARTIAL_LINK_TEXT,element)
return flag
except:
flag = False
return flag
trs=[]
for r in range(5): #这里的最大页数范围我不知道怎么确定,默认爬取五页
time.sleep(2) #这里要加等待时间,不然定位不到下一页的元素
element = browser.find_element(By.ID, 'disclosure-table') # ID定位到年报表格
innerHTML = element.get_attribute('innerHTML') # 获取年报标签下的源代码
f = open('innerHTML.html','w',encoding='utf-8') # 将源代码写入本地文件
f.write(innerHTML)
f.close()
f = open('innerHTML.html',encoding='utf-8') # 读取年报源代码文件
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml') #利用bs进行解析
html_prettified = soup.prettify() #格式标准化代码
p = re.compile('(.*?) ', re.DOTALL) #利用正则表达式 找到所需链接的tr标签
tr = p.findall(html_prettified)
trs.extend(tr) #把每一次爬取到的tr标签添加到trs这个空列表中
flag = element_exist(browser,'下一页') #通过写好的函数判断是否有下一页,如果有则循环爬取
if flag:
nextpage = browser.find_element(By.PARTIAL_LINK_TEXT,'下一页') #通过部分文本定位到下一页
nextpage.click() #点击下一页
wait = WebDriverWait(browser, 2)
else: #如果没有下一页,终止爬取
break
prefix = 'https://disc.szse.cn/download' #为后面提取的链接设定好下载前缀网址
prefix_href = 'http://www.szse.cn' #为后面提取的链接设定好查看前缀网址
p2 = re.compile('(.*?)', re.DOTALL) #在tr标签下进一步提取td标签下的内容
tds = [p2.findall(tr) for tr in trs[1:]] #循环搜索提取trs里的所有项目
#注:此处因为前面翻页时,tds列表存在空列表,下面td[0]会报错,要把空列表过滤。
tds = list(filter(None,tds))
p_code = re.compile('(.*?)', re.DOTALL) #在td标签下爬取企业代码,注:tds里的每一个项目都是一个列表
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code #在td标签下爬取企业名字
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds] #在td标签下精确提取所需链接
p_pub_time = re.compile('(.*?)', re.DOTALL) #在td标签下爬取年报时间
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix+lf[0].strip() for lf in link_ftitles],
'href': [prefix_href+lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
}) #将数据导入至dataframe
df.to_csv('data.csv') #将数据写入本地文件
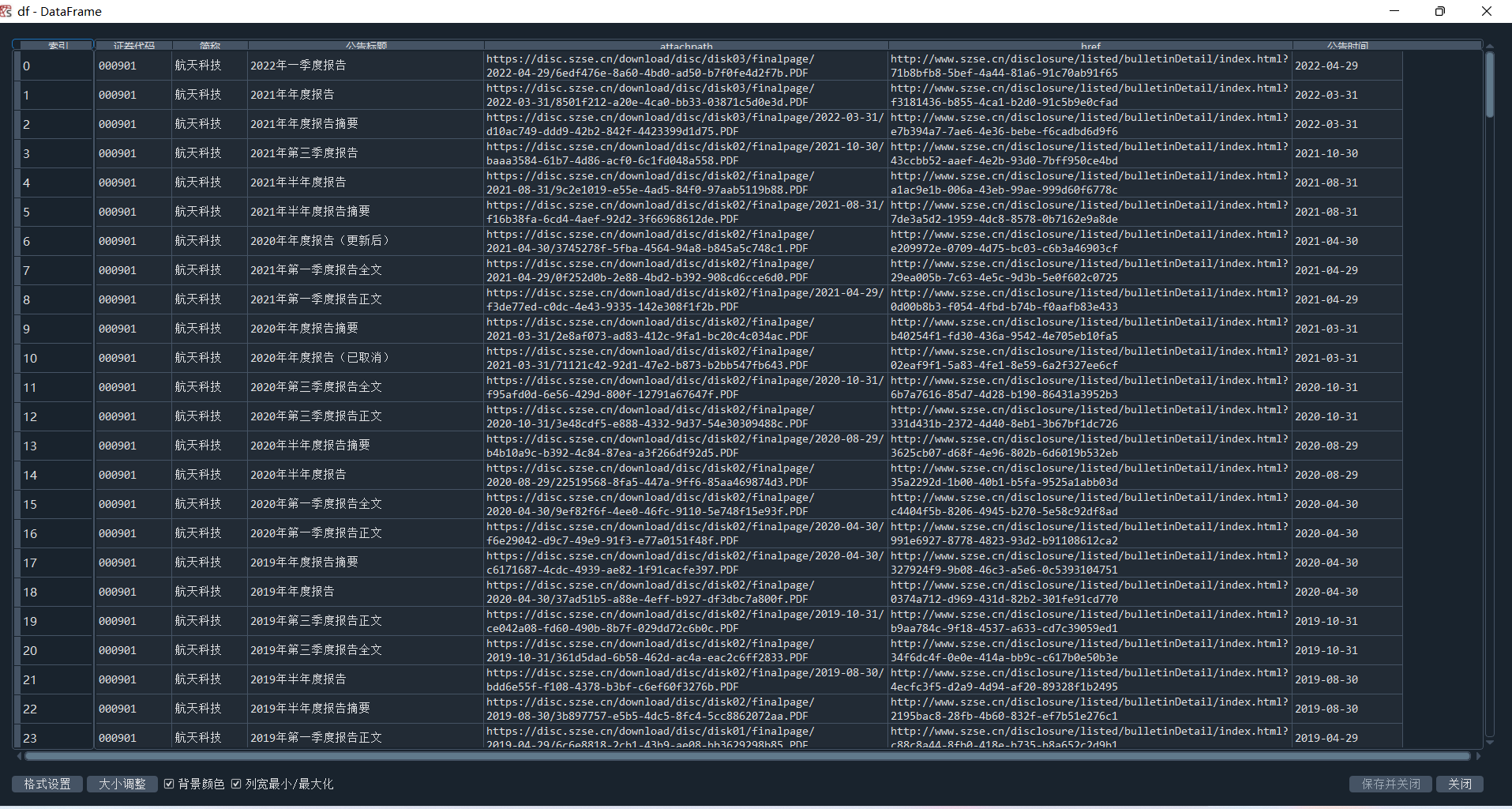
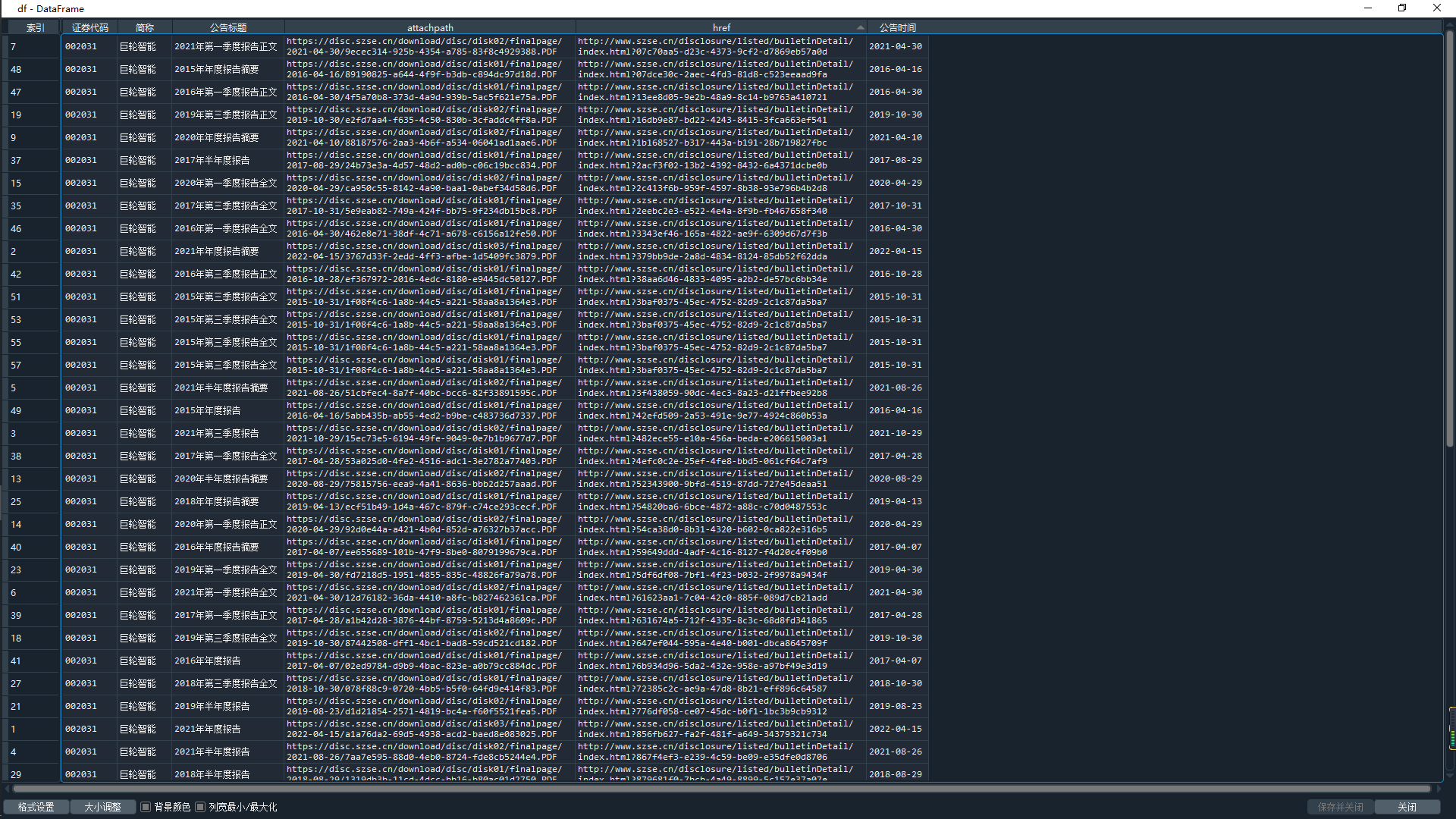
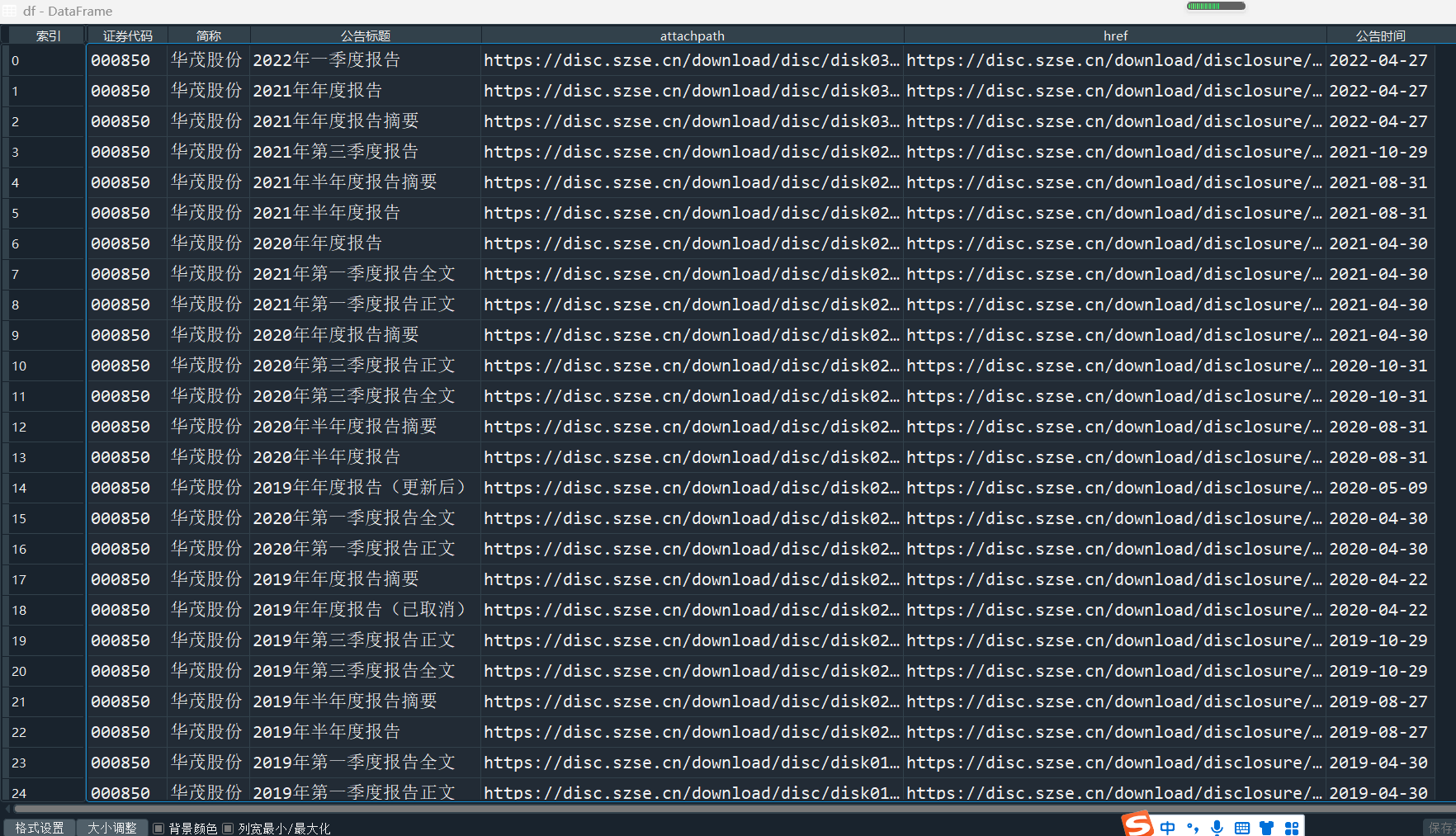
见代码后注释