关宇翔的实验报告
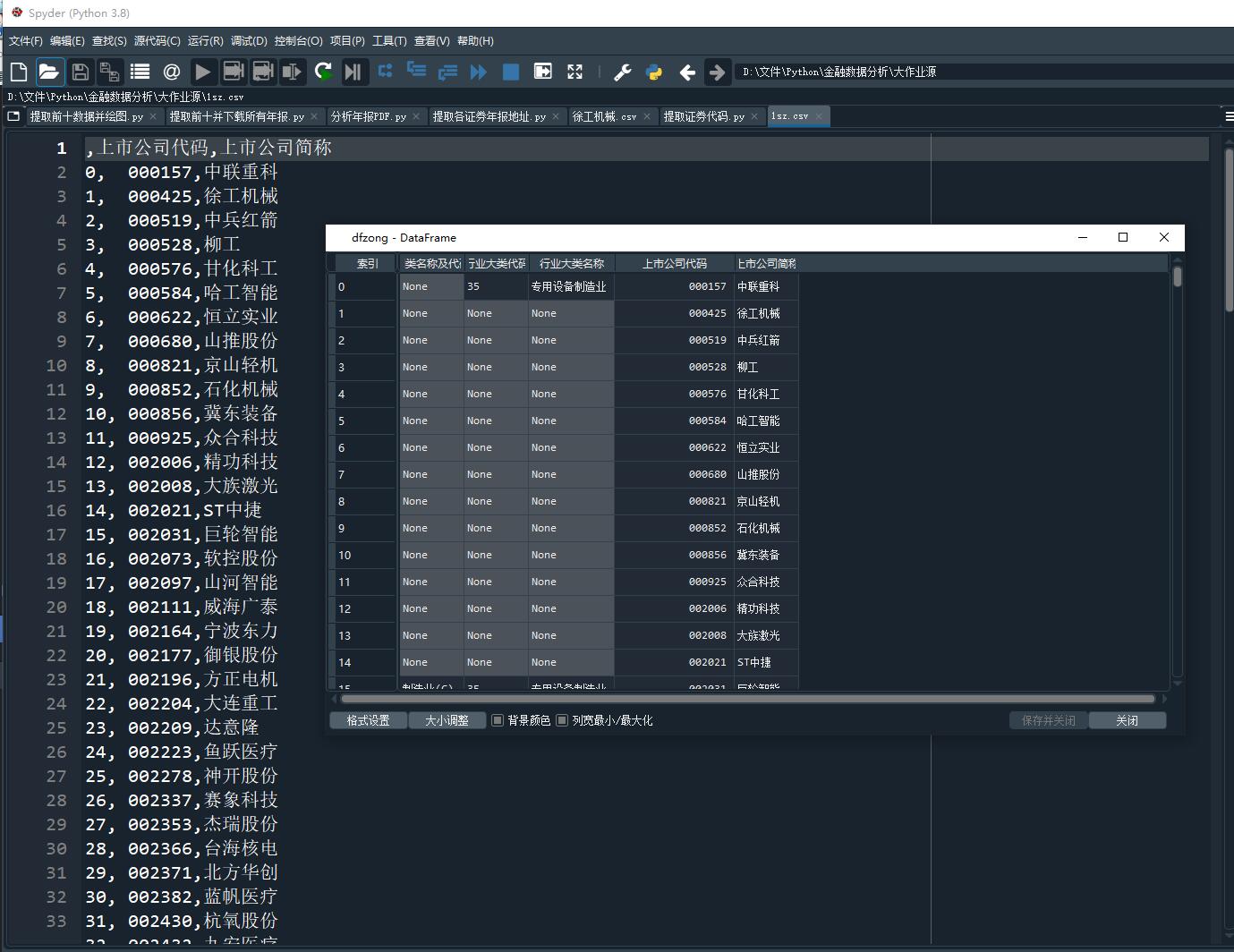
代码一:提取所分配行业的所有证券代码
import pandas as pd
import pdfplumber
import os
dfzong = pd.DataFrame(columns=('门类名称及代码','行业大类代码','行业大类名称','上市公司代码','上市公司简称'))
with pdfplumber.open('行业分类.pdf') as pdf:
for i in range(39,47):
page = pdf.pages[i]
table = page.extract_tables()
for t in table:
dfz = pd.DataFrame(t[1:],columns=t[0])
dfzong = dfzong.append(dfz)
dfzong.reset_index(drop=True,inplace=True)
for i in range(0,27):
dfzong = dfzong.drop(index=i)
for i in range(326,336):
dfzong = dfzong.drop(i)
dfzong.reset_index(drop=True,inplace=True)
gongsi = dfzong.iloc[:,3:]
sz = gongsi.iloc[0:160]
sh = gongsi.iloc[160:]
for i in range(len(sz['上市公司代码'])):
sz.loc[i,'上市公司代码'] = '\t' + sz.loc[i,'上市公司代码']
for i in range(len(sz['上市公司简称'])):
for t in sz['上市公司简称'][i]:
if t == '*' :
sz.loc[i,'上市公司简称'] = sz.loc[i,'上市公司简称'].replace( t ,'')
sz=sz.astype(str)
sz=sz.astype(str)
sz.to_csv('1sz.csv',encoding='utf-8-sig')
sh.to_csv('1sh.csv',encoding='utf-8-sig')
代码一运行结果及感悟
①:提取自己所分配行业时可以利用正则表达式来提高适用性。此处为了方便直接手动查看了所需页码。
②:分类深交所和上交所代码时可利用条件筛选以防止代码顺序混乱的情况。
代码二:爬取各证券年报地址并下载
import re
import os
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import pdfplumber
import requests
starttime = time.time()
def InputTime(start,end):
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind):
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
browser = webdriver.Chrome()
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
time.sleep(1)
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2013-01-01',End)
SelectReport(4)
ActionChains(browser).move_by_offset(200, 100).click().perform()
for i in sz['上市公司简称']:
element = browser.find_element(By.ID, 'input_code')
element.send_keys( i + Keys.RETURN)
time.sleep(2)
element = browser.find_element(By.ID, 'disclosure-table')
innerHTML = element.get_attribute('innerHTML')
f = open(i+'.html','w',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
time.sleep(2)
n=0
for i in sz['上市公司简称']:
f = open(i+'.html',encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html,features='lxml')
html_prettified = soup.prettify()
p = re.compile('(.*?)', re.DOTALL)
trs = p.findall(html_prettified)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
p_code = re.compile('(.*?)', re.DOTALL)
codes = [p_code.search(td[0]).group(1).strip() for td in tds]
p_shortname = p_code
short_names = [p_shortname.search(td[1]).group(1).strip() for td in tds]
p_link_ftitle = re.compile('(.*?)',
re.DOTALL)
link_ftitles = [p_link_ftitle.findall(td[2])[0] for td in tds]
p_pub_time = re.compile('(.*?)', re.DOTALL)
p_times = [p_pub_time.search(td[3]).group(1) for td in tds]
prefix = 'https://disc.szse.cn/download'
prefix_href = 'http://www.szse.cn'
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [lf[2].strip() for lf in link_ftitles],
'attachpath': [prefix+lf[0].strip() for lf in link_ftitles],
'href': [prefix_href+lf[1].strip() for lf in link_ftitles],
'公告时间': [t.strip() for t in p_times]
})
btlist = []
for index, row in df.iterrows():
bt = row[2]
a = re.search('摘要|取消|英文', bt)
if a!= None:
btlist.append(index)
df1 = df.drop(btlist)
df1.reset_index(drop=True,inplace=True)
time.sleep(2)
endtime = time.time()
df1.to_csv(i+'.csv',encoding='utf-8-sig')
os.makedirs(i,exist_ok=True)
os.chdir(i)
f = requests.get(df1.iat[0,3])
with open (df1.iat[0,2]+".pdf", "wb") as code:
code.write(f.content)
n+=1
print('正在下载第',n,'份',i,'共',len(sz['上市公司简称']),'份')
os.chdir('../')
print('爬取完毕','共耗时',endtime - starttime)
代码二运行结果及感悟
①:一定要多使用def定义函数,这样不仅可以提高代码的普适性,也方便进行代码的阅读和修改。这里借鉴了部分傅元娴同学的作业三代码,提高了爬取代码的运行速度。
②:尽可能的把一些不必要的操作可以写在for循环之前,提高爬取速度。
③:此处因为所分配行业企业过多,下载所有符合条件的年报较为费时且麻烦,所以只下载了最近发布的一份年报,等后期提取出排名后再下载所有需要的年报。
代码三:分析所下载的最近一年年报
import os
import re
import pandas as pd
import fitz
import pdfplumber
Company = pd.read_csv('1sz.csv',header=None, dtype={0:'str'}).iloc[:,1:]
company=Company.iloc[1:,1].tolist()
n=0
for com in company:
n+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str})
df = df.drop(df.columns[0], axis=1)
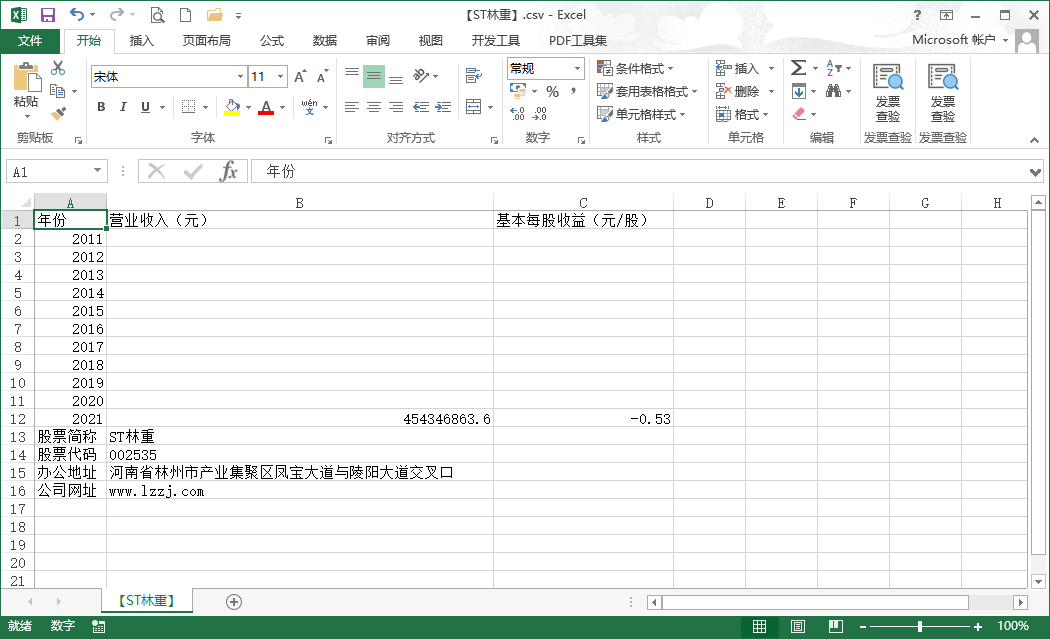
income = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)'])
income.index.name='年份'
code = '\t'+str(df.iloc[0,0])
name = df.iloc[0,1].replace(' ','')
title = df.iloc[0,2]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for i in range(25):
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}).*?年度报告.*?')
year = int(p_year.findall(text)[0])
p_shouru = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_shouyi = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_dizhi = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_wangzhi =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
shouru=float(p_shouru.search(text).group(1).replace(',',''))
shouyi=p_shouyi.search(text).group(1)
income.loc[year,'营业收入(元)']=shouru
income.loc[year,'基本每股收益(元/股)']=shouyi
os.chdir(com)
income.to_csv('【%s】.csv' %com,encoding='utf-8-sig')
dizhi=p_dizhi.search(text).group(1)
wangzhi=p_wangzhi.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f:
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,dizhi,wangzhi)
f.write(content)
os.chdir('../')
print(name+'数据已保存完毕'+'(',n,'/',len(company),')')
代码三运行结果及感悟
①因为有160个公司,所以只下载了最近发布的一份年报并进行分析。
②存入本地csv文件时,编码要使用'utf-8-sig'格式,便于直接通过本地资源管理器查看。
代码四:筛选收入前十公司下载所有年报并分析
import os
import re
import pandas as pd
import fitz
import pdfplumber
import matplotlib.pyplot as plt
import requests
os.chdir('../')
Company = pd.read_csv('1sz.csv',header=None, dtype={0:'str'}).iloc[:,1:]
company=Company.iloc[1:,1].tolist()
dflist=[]
for name in company:
com = name.replace('*','')
os.chdir(com)
data=pd.read_csv('【'+com+'】.csv')
dflist.append(data)
os.chdir('../')
com_number = len(dflist)
for i in range(com_number):
dflist[i]=dflist[i].set_index('年份')
df=pd.DataFrame(columns=('上市公司代码','股票简称','最近一年营业收入(元)'))
for i in range(com_number):
df.loc[i,'上市公司代码']=dflist[i].iloc[12,0]
df.loc[i,'股票简称']=dflist[i].iloc[11,0]
df.loc[i,'最近一年营业收入(元)']=dflist[i].iloc[10,0]
rank=df.sort_values('最近一年营业收入(元)',ascending=False).head(10)
names=list(rank['股票简称'])
codes=list(rank['上市公司代码'])
indexes=[]
for i in rank['上市公司代码']:
indexes.append(i)
rank.to_csv('rank.csv',encoding='utf-8-sig')
os.makedirs('收入前十',exist_ok=True)
n=0
for name in names:
indexes.append(company.index(name))
dfx = pd.read_csv(name+'.csv').iloc[:,1:]
os.chdir('收入前十')
os.makedirs(name,exist_ok=True)
os.chdir(name)
d1={}
for index , row in dfx.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
n+=1
print('正在下载第',n,'份',name,'共',len(dfx),'份')
os.chdir('../../')
os.chdir('收入前十')
n=0
for name in names:
n+=1
name = name.replace('*','')
df = pd.read_csv(name+'.csv',converters={'证券代码':str})
df = df.drop(df.columns[0], axis=1)
income = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)'])
income.index.name='年份'
code = '\t'+str(df.iloc[0,0])
name10 = df.iloc[0,1].replace(' ','')
os.chdir('收入前十')
for i in range(len(df)):
title = df.iloc[i,2]
doc = fitz.open('./%s/%s.pdf'%(name,title))
text=''
for i in range(30):
page = doc[i]
text += page.get_text()
p_year=re.compile('.*?(\d{4}).*?年度报告.*?')
year = int(p_year.findall(text)[0])
p_shouru = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_shouyi = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_dizhi = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_wangzhi =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
shouru=float(p_shouru.search(text).group(1).replace(',','')+'0')
shouyi=p_shouyi.search(text).group(1)
income.loc[year,'营业收入(元)']='\t'+str(shouru)
income.loc[year,'基本每股收益(元/股)']=shouyi
income.to_csv('【%s】.csv' %name,encoding='utf-8-sig')
dizhi=p_dizhi.search(text).group(1)
wangzhi=p_wangzhi.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f:
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,dizhi,wangzhi)
f.write(content)
os.chdir('../')
print(name10+'数据已保存'+'(',n,'/10)')
代码四运行结果及感悟
代码五:提取收入前十公司的所有年报数据并绘图
import os
import re
import pandas as pd
import fitz
import pdfplumber
import matplotlib.pyplot as plt
import requests
from pylab import *
Company=pd.read_csv('rank.csv',header=None, dtype={0:'str'}).iloc[:,1:3]
company=Company.iloc[1:,1].tolist()
dflist=[]
for name in company:
com = name.replace('*','')
data=pd.read_csv('【'+com+'】.csv')
dflist.append(data)
com_number = len(dflist)
for i in range(com_number):
dflist[i]=dflist[i].set_index('年份')
'''
x=dflist[1].iloc[5:,0]
Number_new=[]
for i in x:
Number_new.append(i)
'''
datalist1=[]
datalist2=[]
for i in range(len(dflist)):
datalist1.append(pd.DataFrame(dflist[i].iloc[:,0]))
for df in datalist1:
df.index=df.index.astype(int)
df['营业收入(元)']=df['营业收入(元)'].astype(float)/1000000000
for i in range(len(dflist)):
datalist2.append(pd.DataFrame(dflist[i].iloc[:,1]))
for df in datalist2:
df.index=df.index.astype(int)
df['基本每股收益(元/股)']=df['基本每股收益(元/股)'].astype(float)
shouru=pd.concat(datalist1,axis=1)
meigushouyi=pd.concat(datalist2,axis=1)
shouru.columns=Company.iloc[1:,1]
meigushouyi.columns=Company.iloc[1:,1]
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
for i in range(10):
title=shouru.columns[i]
x= shouru.index.tolist()
y1=shouru.iloc[:,i]
y1=y1.tolist()
y2=meigushouyi.iloc[:,i]
y2=y2.tolist()
fig = plt.figure(figsize=(10.8, 7.2),dpi=150)
ax1 = fig.add_subplot(111)
ax1.plot(x, y1,label='营业收入')
ax1.set_ylabel('营业收入(十亿元)',)
ax1.set_title(title,)
ax1.legend(loc=0)
ax2 = ax1.twinx()
ax2.plot(x, y2, 'r',label='每股收益')
ax2.set_ylabel('每股收益',)
ax2.set_xlabel('年份')
ax2.legend(loc=0)
plt.savefig(title+".png")
plt.show()
shouru1=shouru.head(4)
shouru2=shouru.iloc[4:8]
shouru3=shouru.tail(3)
meigushouyi1=meigushouyi.head(4)
meigushouyi2=meigushouyi.iloc[4:8]
meigushouyi3=meigushouyi.tail(3)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
ax1=shouru1.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax1.set_xlabel('年份',loc='left',fontsize=18)
ax1.set_ylabel('营业收入(十亿元)',fontsize=18)
ax1.set_title('行业内横向对比营业收入(2011-2014)',fontsize=20)
ax1.figure.savefig('2011-2014营业收入对比')
ax2=shouru2.plot(kind='bar',figsize=(16 ,8),fontsize=18,alpha=0.7,grid=True)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax2.set_xlabel('年份',loc='left',fontsize=18)
ax2.set_ylabel('营业收入(十亿元)',fontsize=18)
ax2.set_title('行业内横向对比营业收入(2015-2017)',fontsize=20)
ax2.figure.savefig('2015-2016营业收入对比')
ax3=shouru3.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax3.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax3.set_xlabel('年份',loc='left',fontsize=18)
ax3.set_ylabel('营业收入(十亿元)',fontsize=18)
ax3.set_title('行业内横向对比营业收入(2018-2021)',fontsize=20)
ax3.figure.savefig('2017-2021营业收入对比')
ax1=meigushouyi1.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.7)
ax1.set_xlabel('年份',loc='right',fontsize=18)
ax1.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax1.set_title('行业内横向对比基本每股收益(2011-2014)',fontsize=20)
ax1.figure.savefig('2011-2014每股收益对比')
ax2=meigushouyi2.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax2.set_xlabel('年份',loc='right',fontsize=18)
ax2.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax2.set_title('行业内横向对比基本每股收益(2015-2017)',fontsize=20)
ax2.figure.savefig('2015-2016每股收益对比')
ax3=meigushouyi3.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax3.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.3)
ax3.set_xlabel('年份',loc='left',fontsize=18)
ax3.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax3.set_title('行业内横向对比基本每股收益(2018-2021)',fontsize=20)
ax3.figure.savefig('2017-2021每股收益对比')
代码五运行结果及感悟
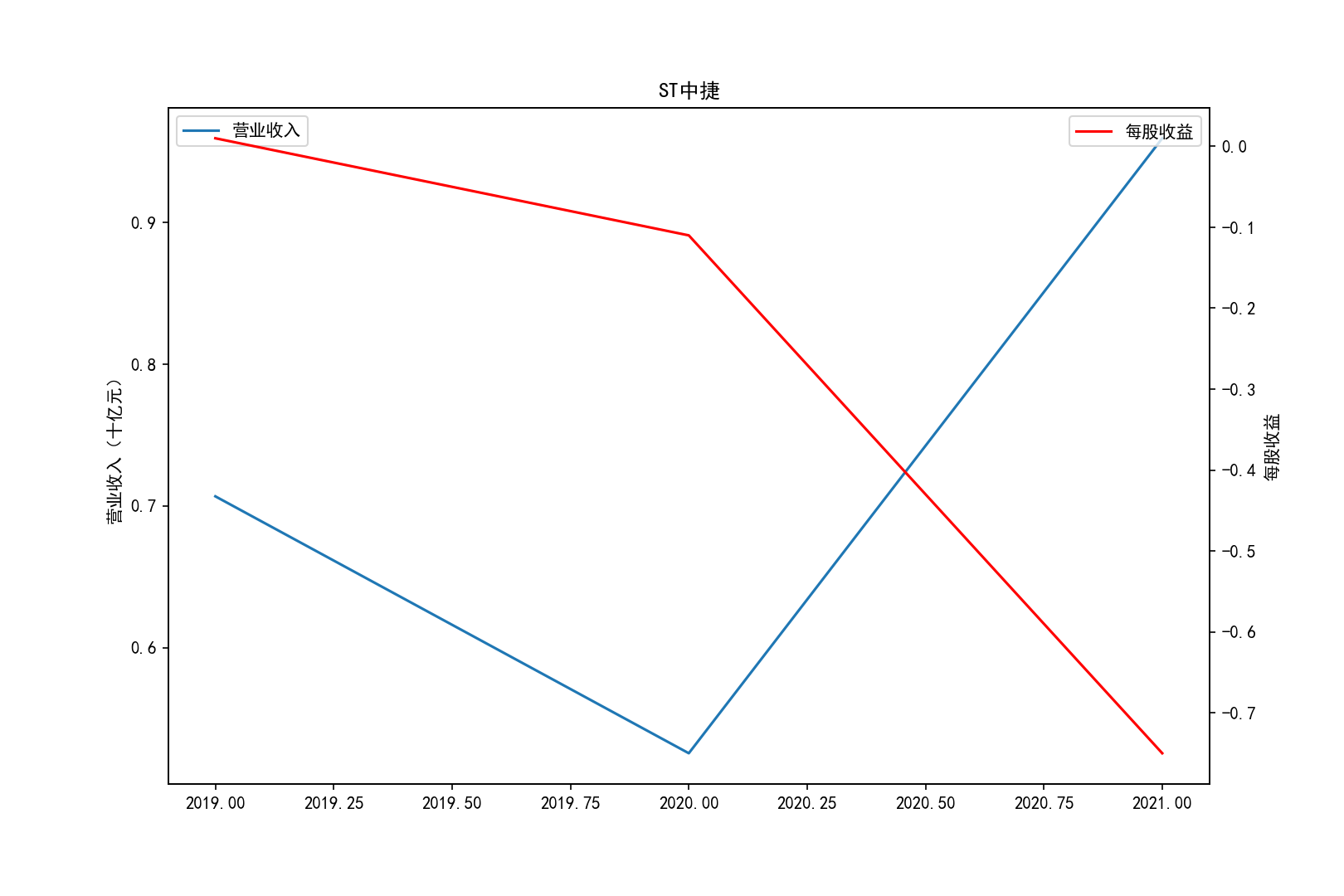
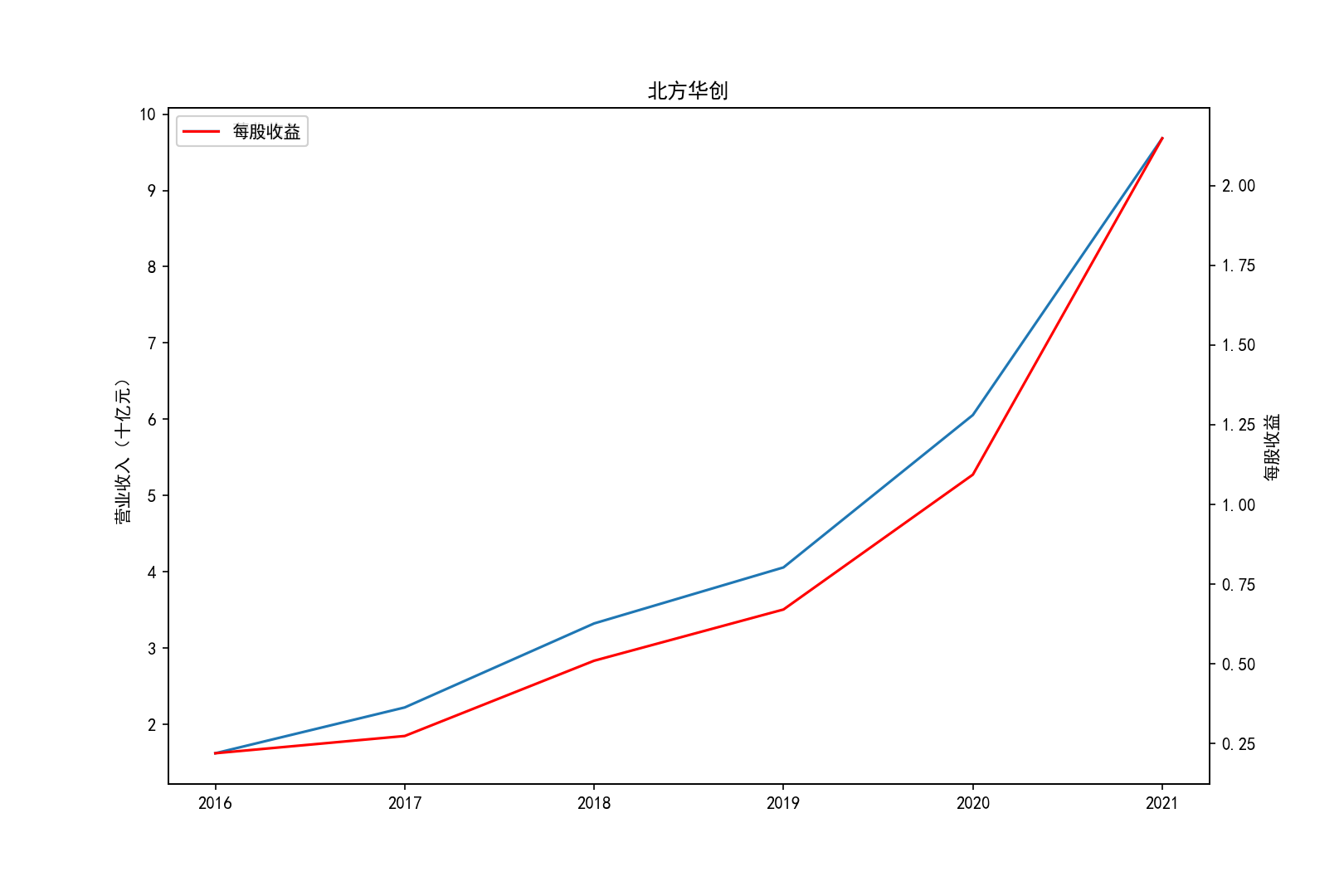
各公司营业收入及每股收益随时间趋势变化图
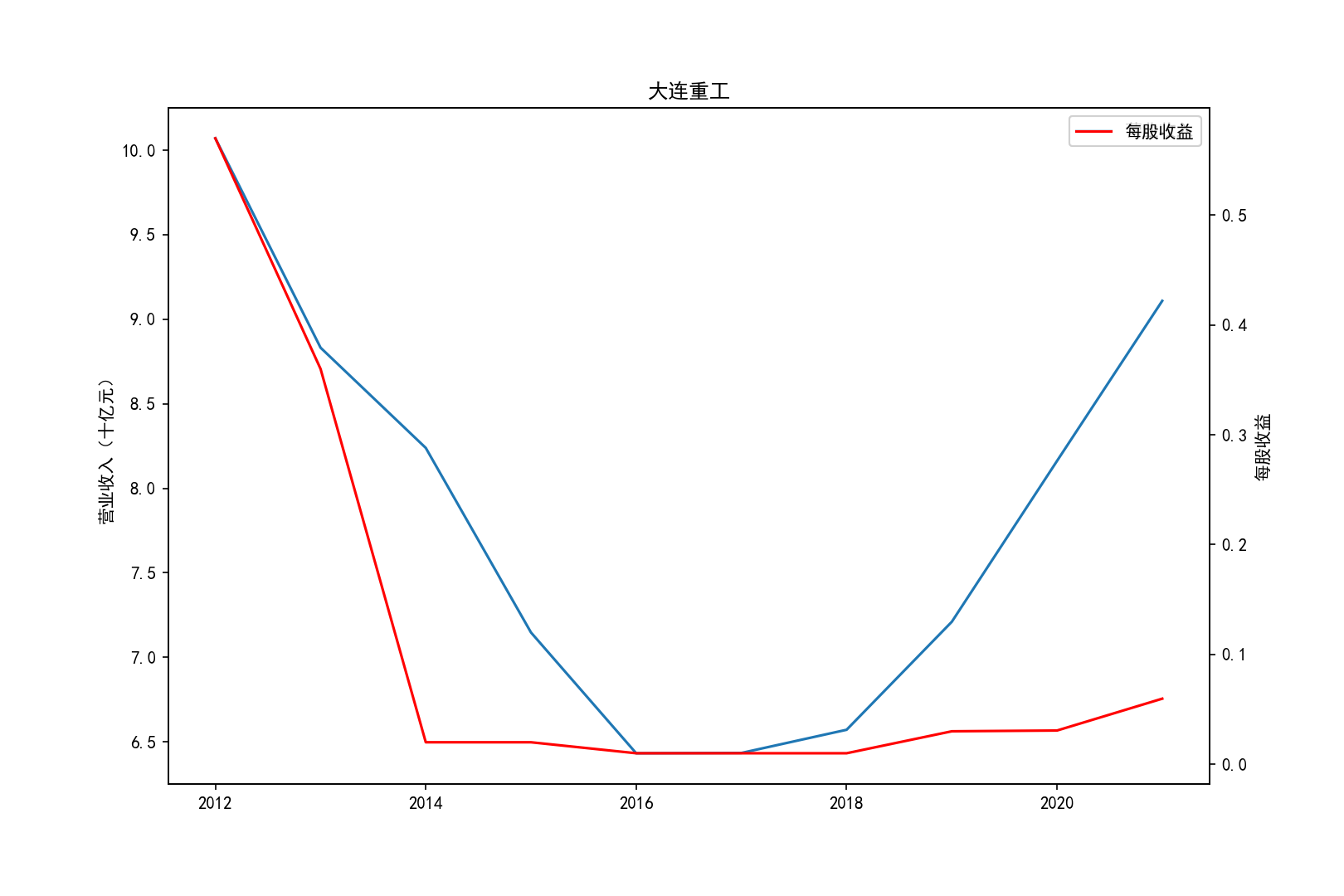
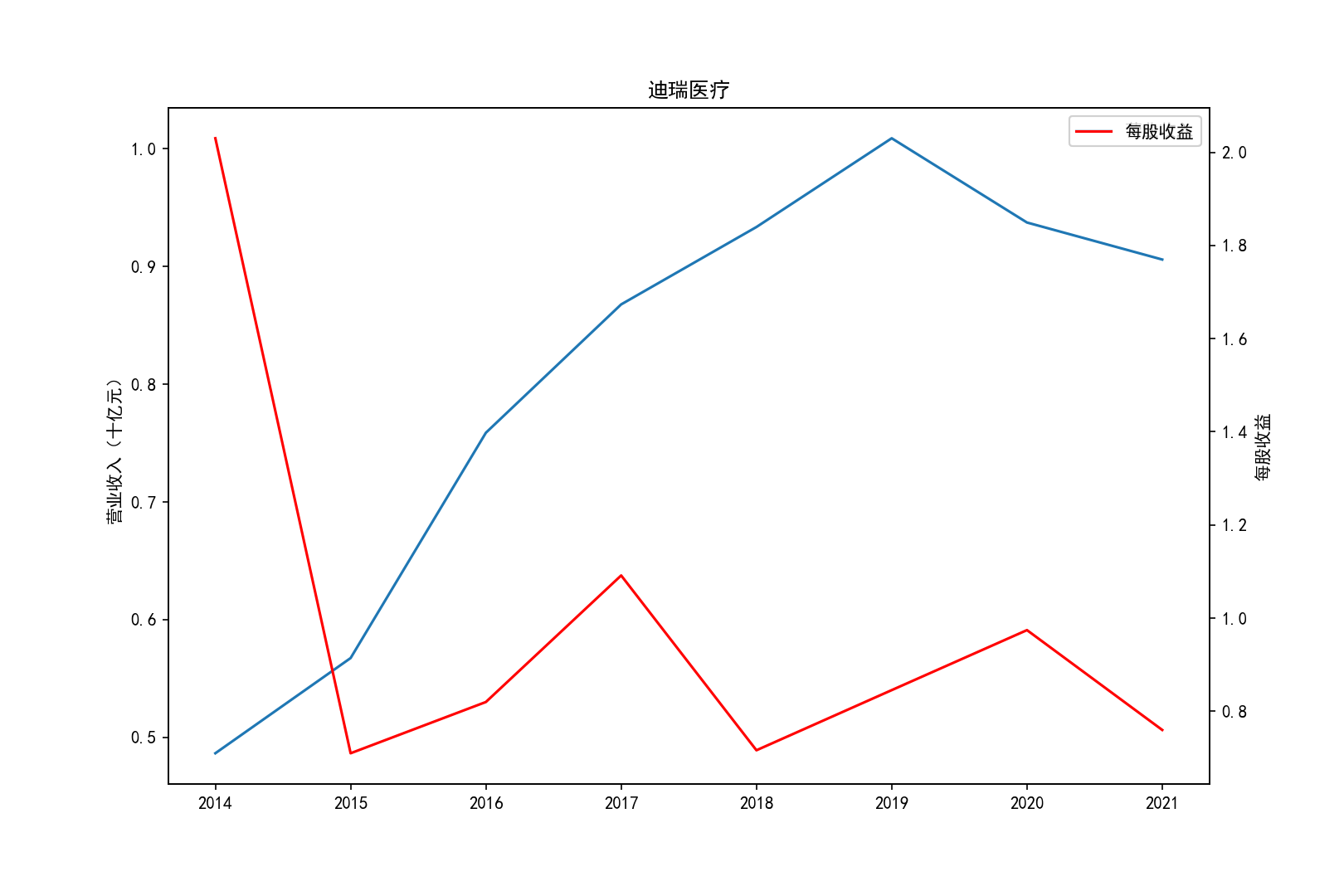
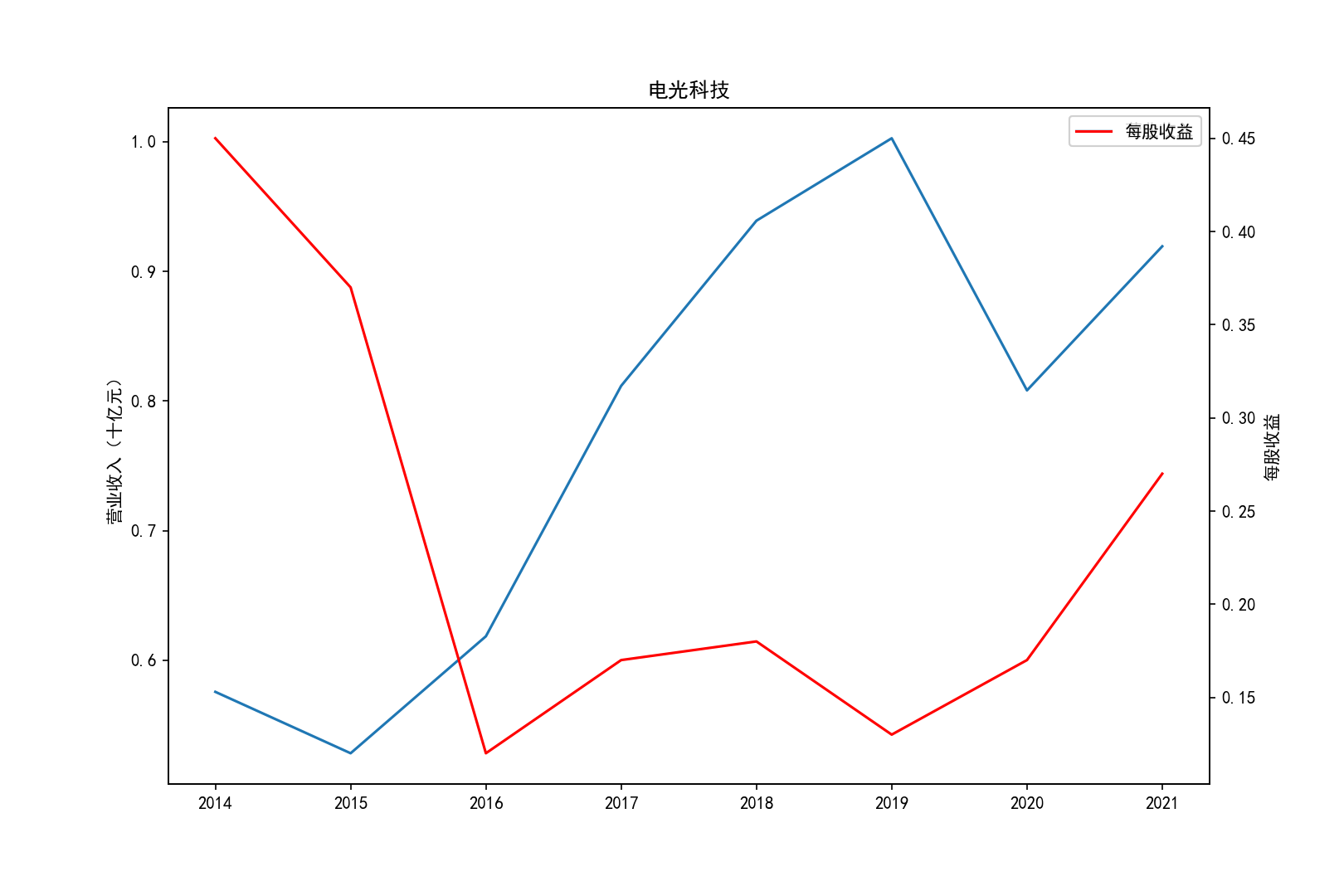
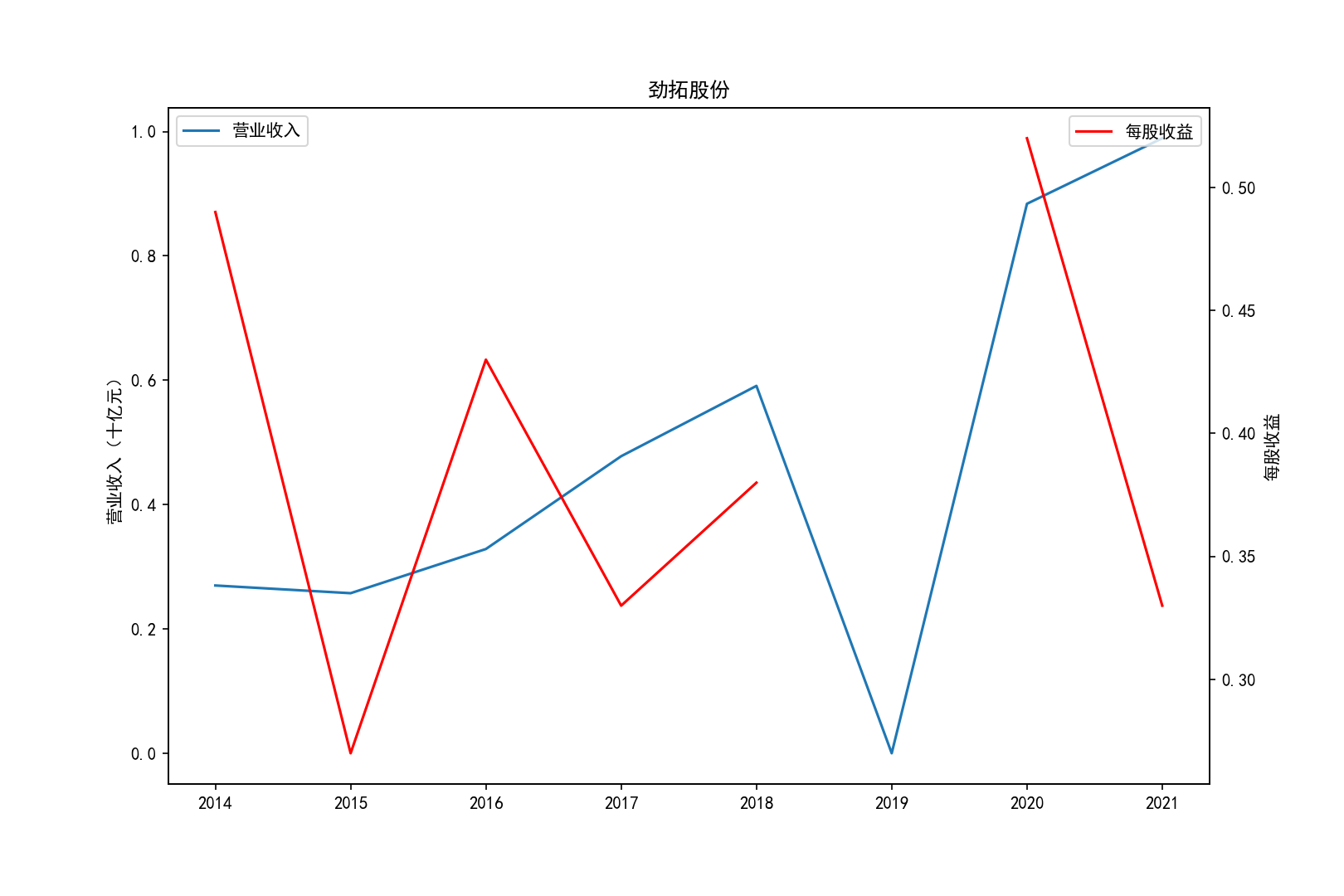
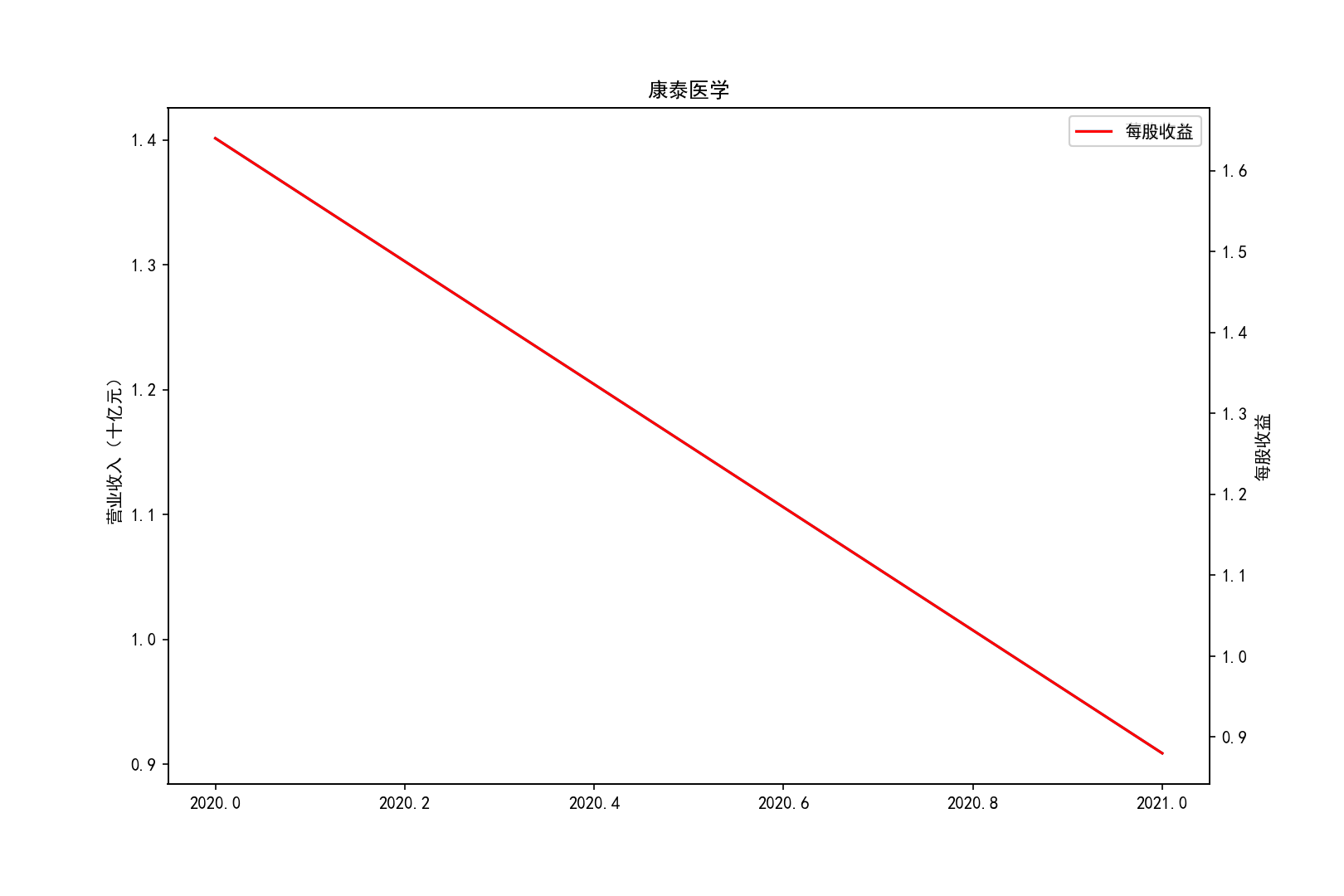
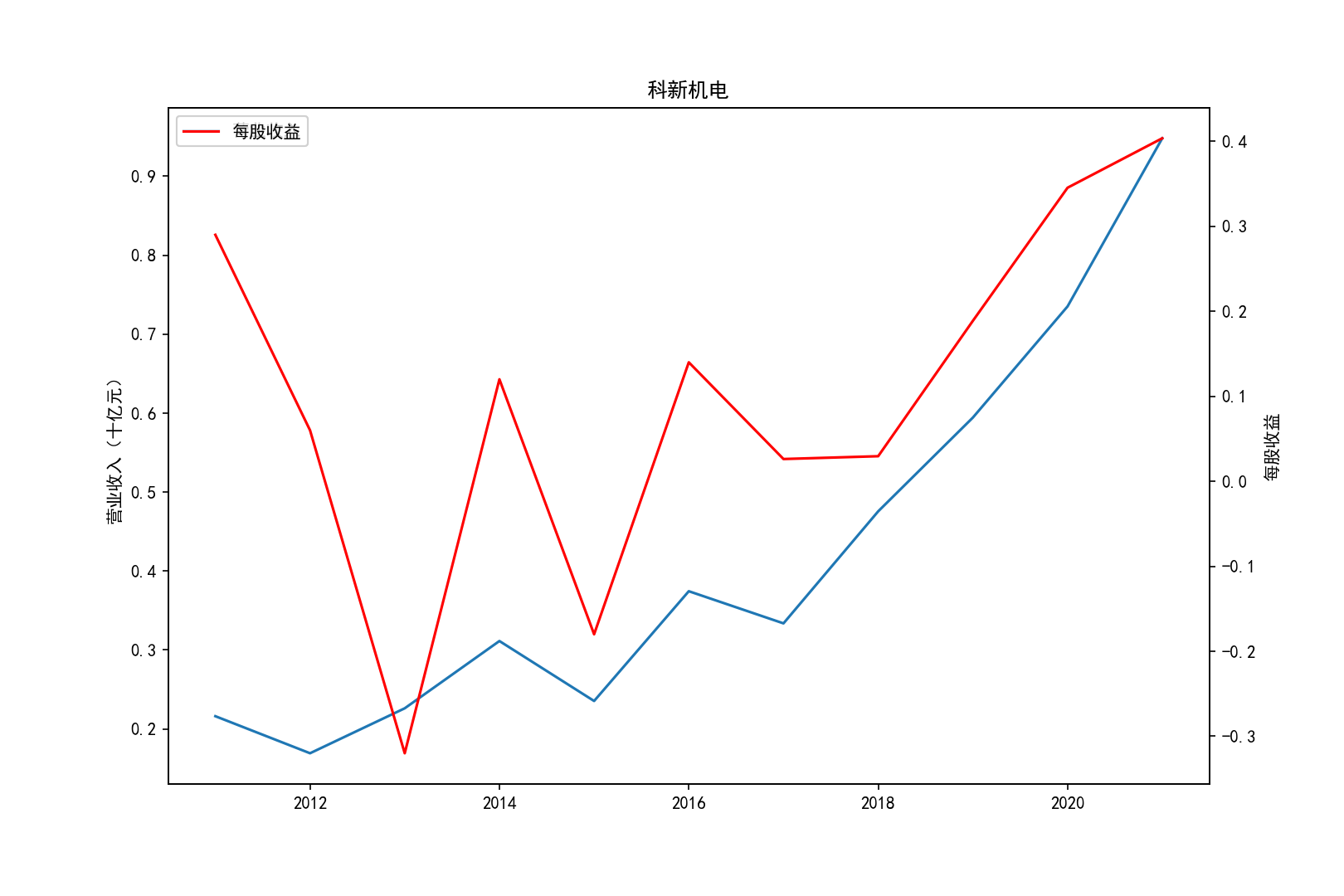
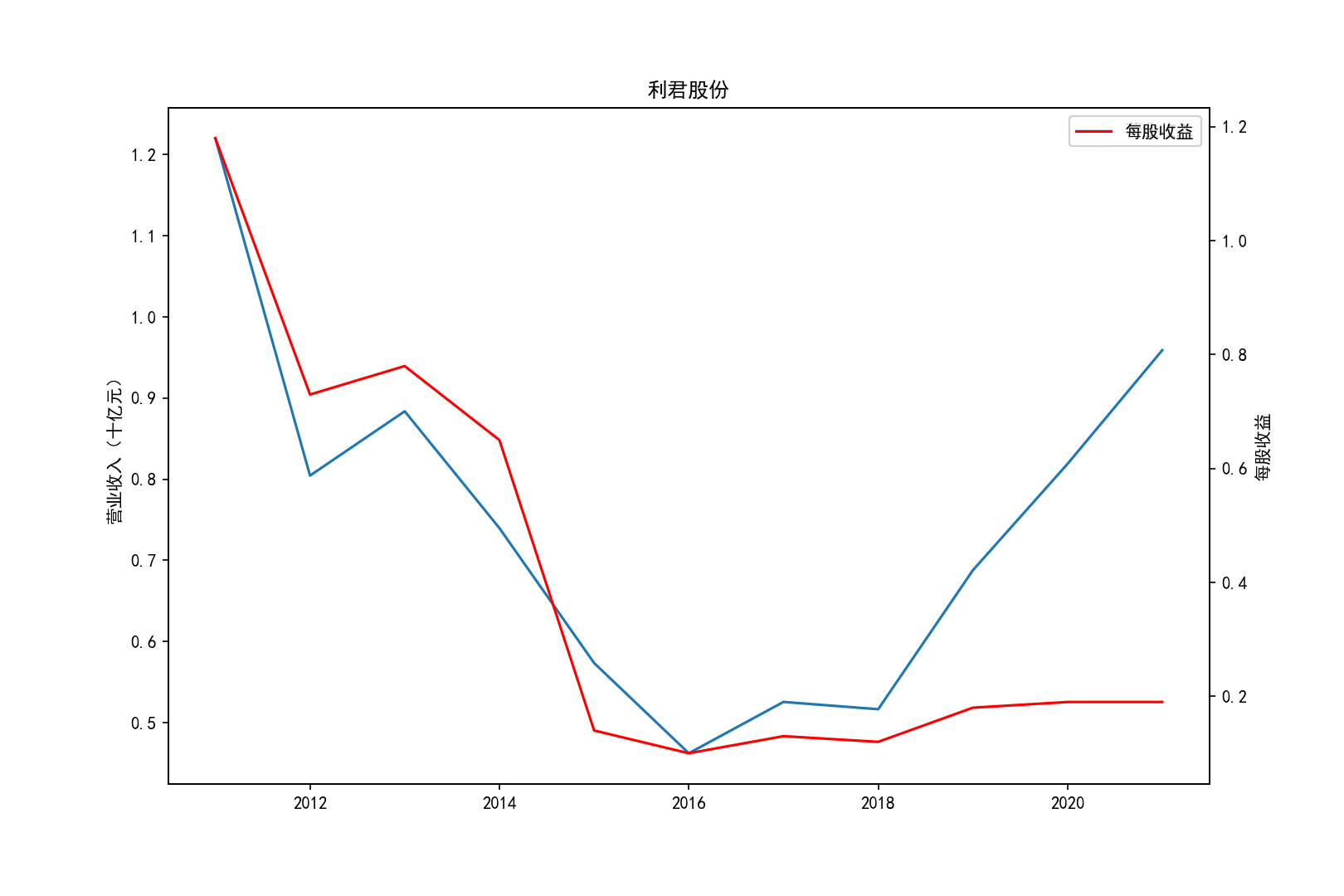
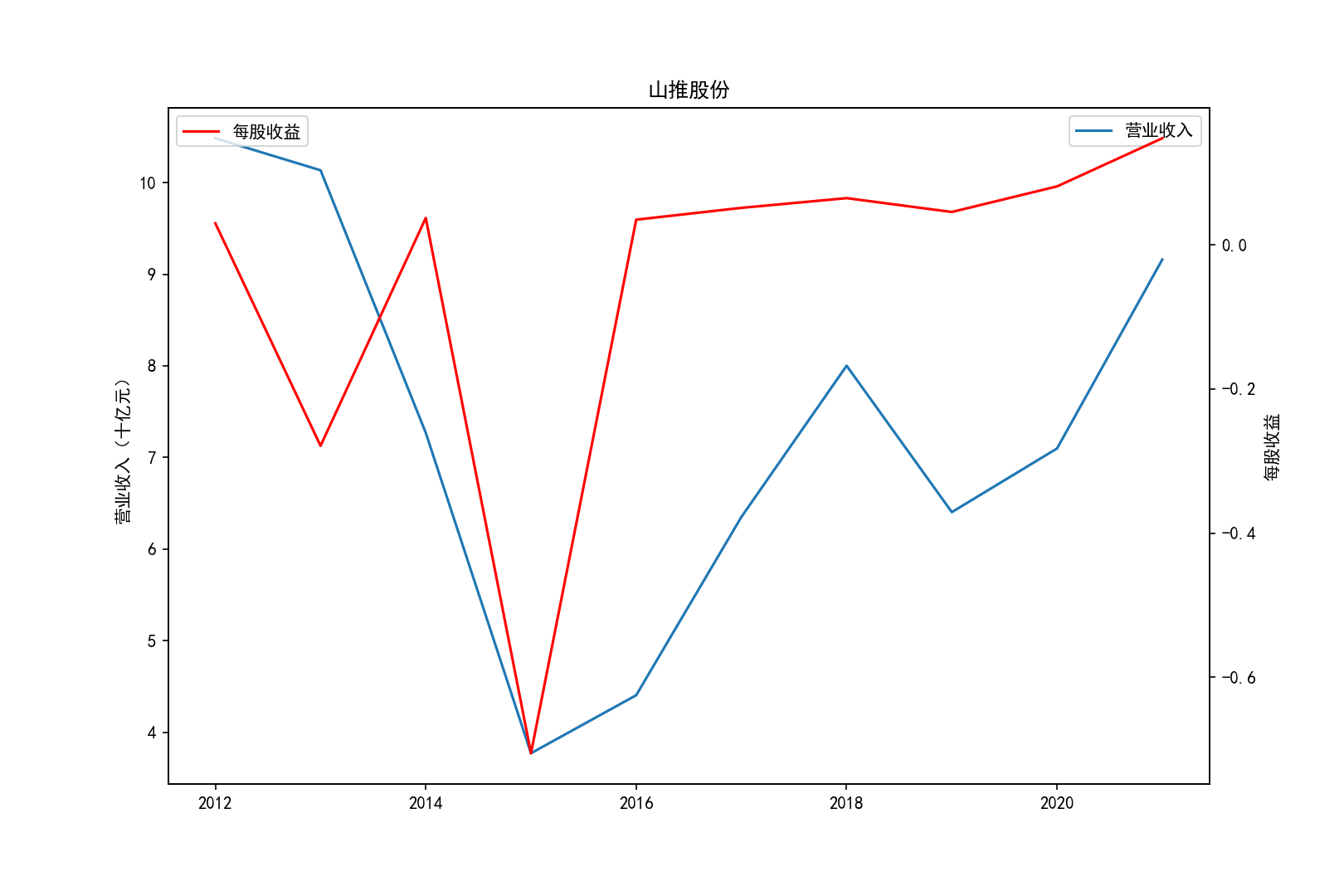
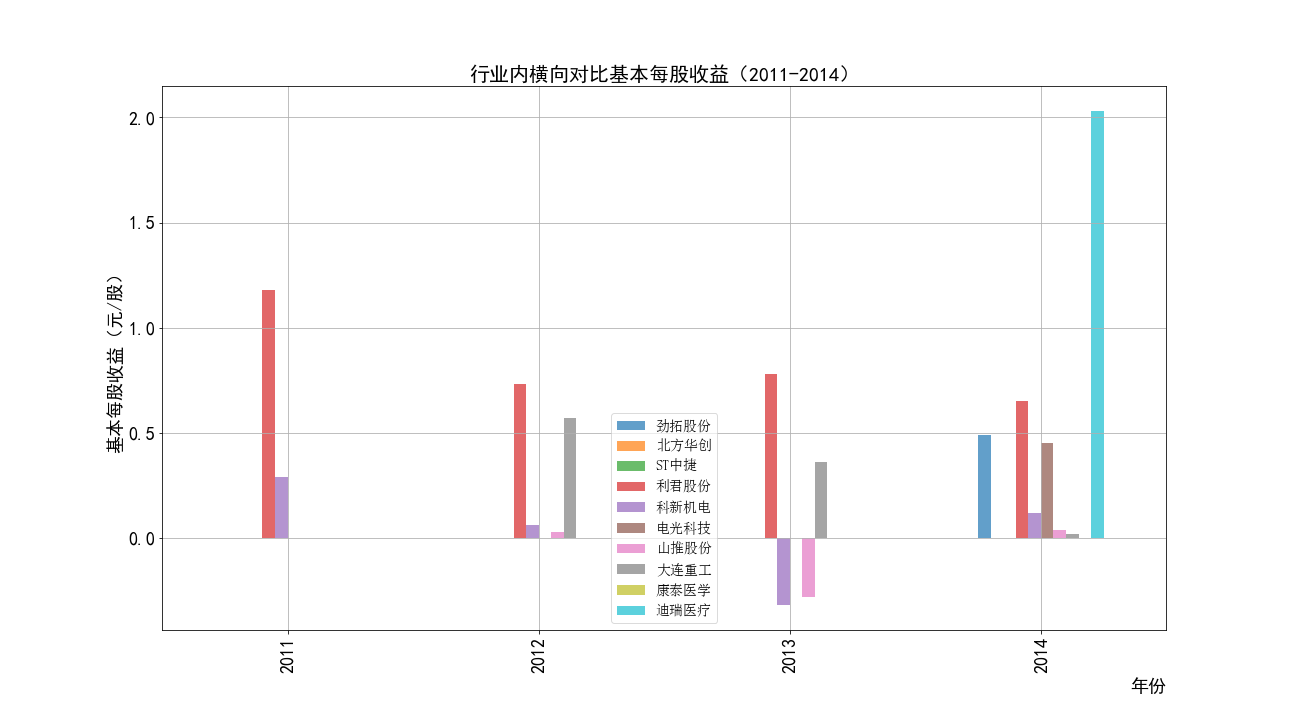
2011-2014年每股收益横向对比
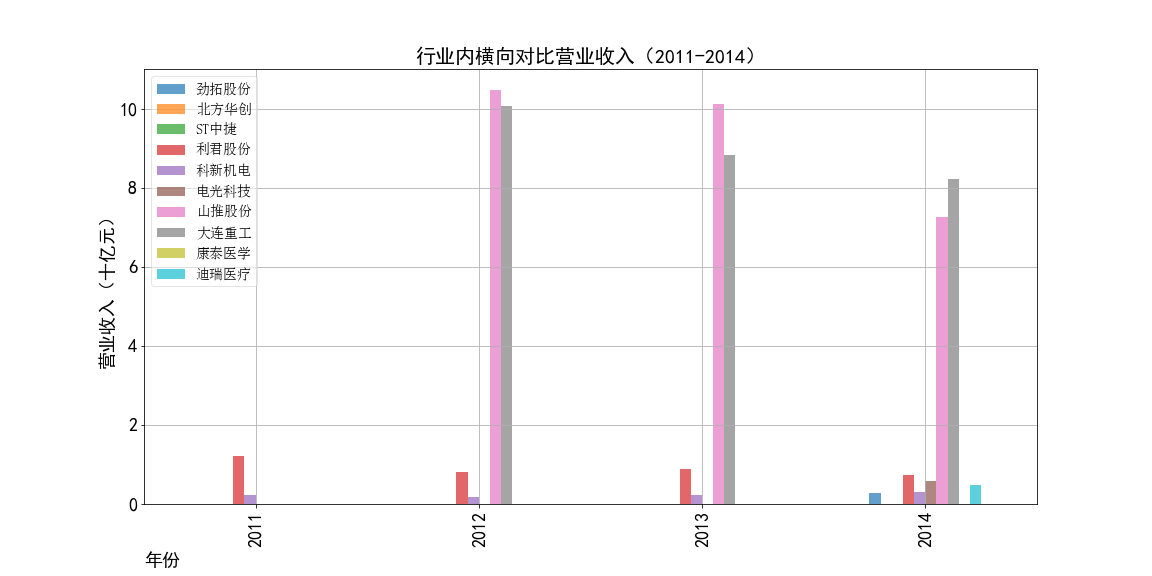
2011-2014年营业收入横向对比
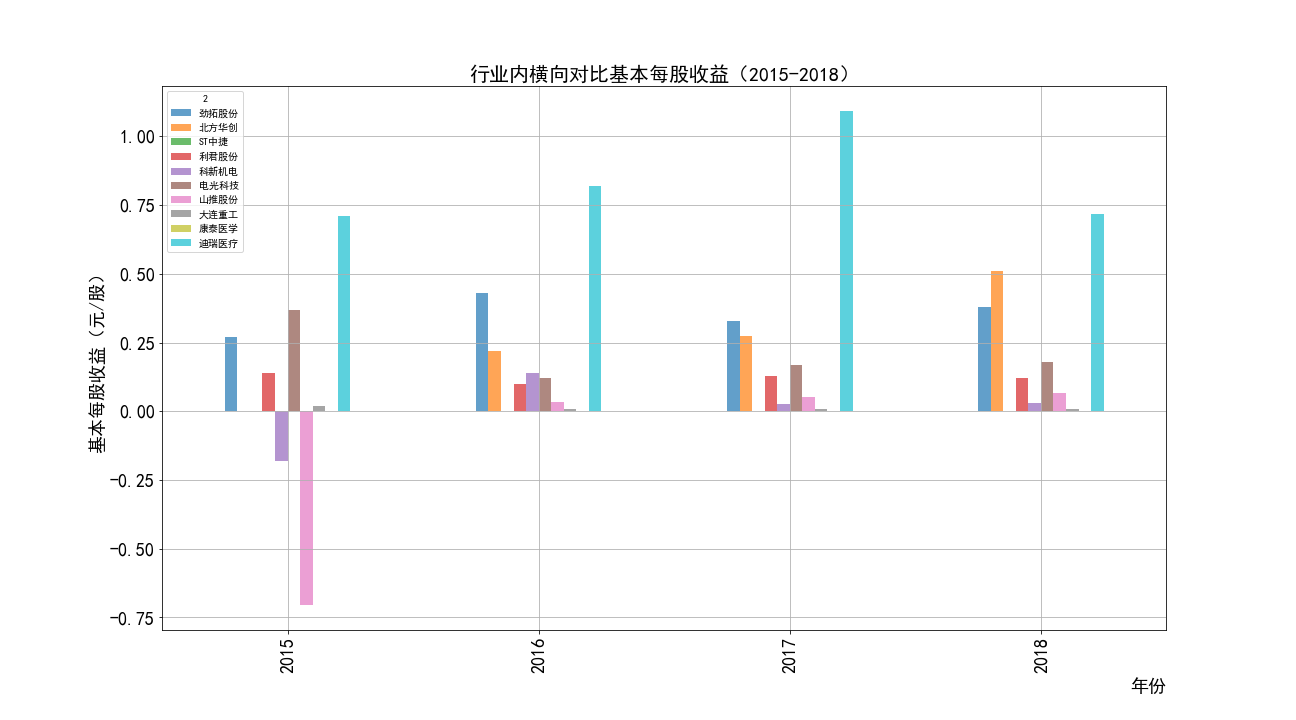
2015-2018年每股收益横向对比
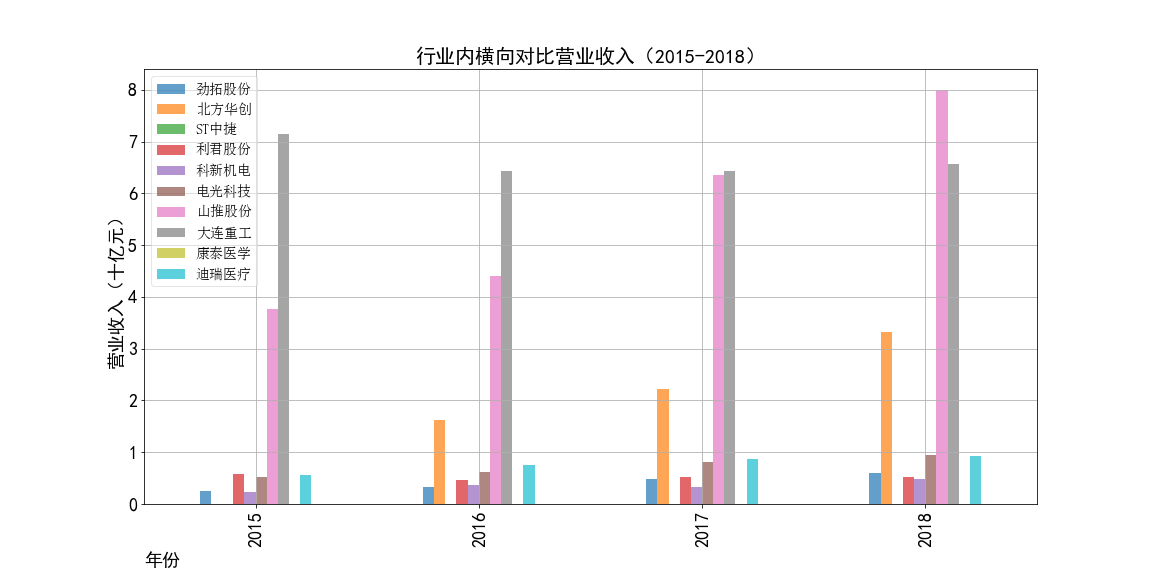
2015-2018年营业收入横向对比
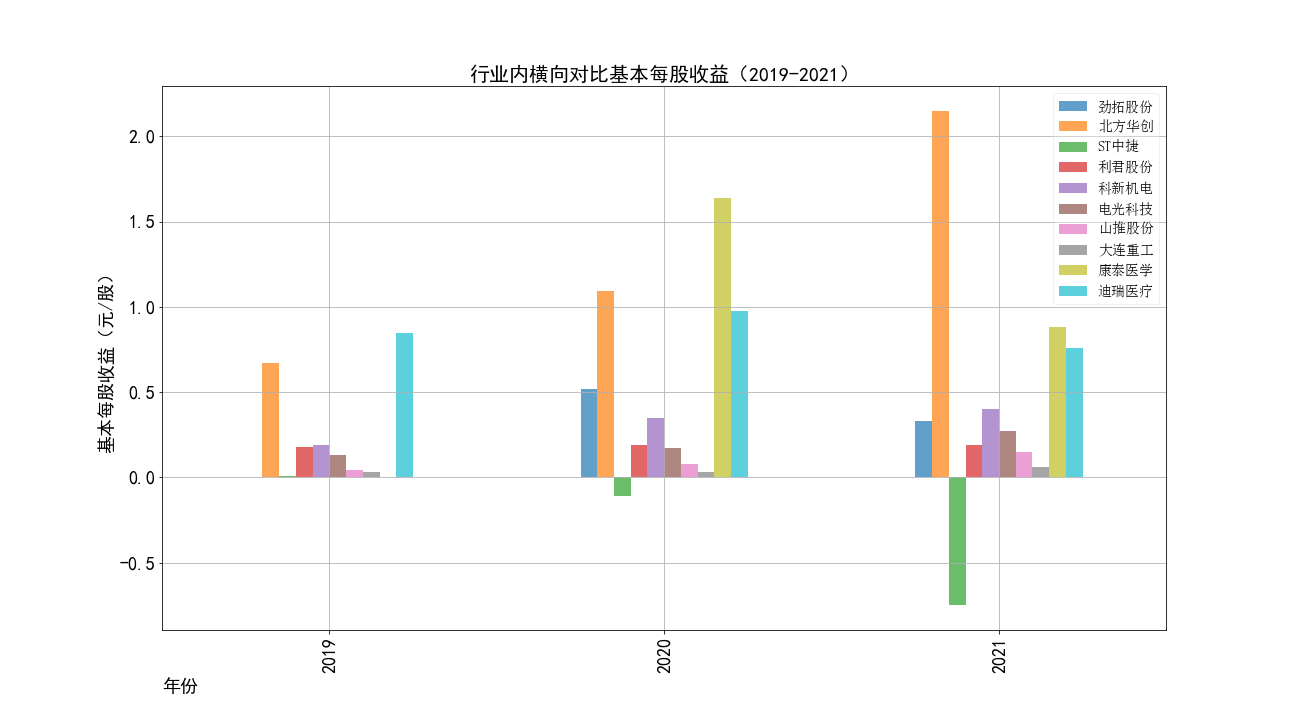
2019-2021年每股收益横向对比
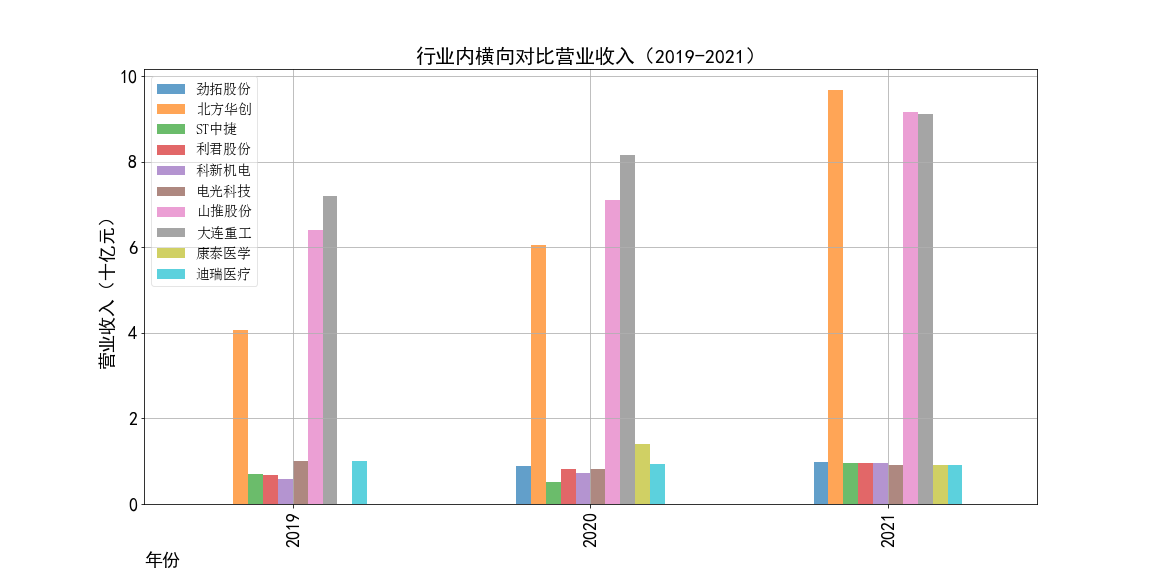
2019-2021年营业收入横向对比
简单的报告分析与学习总结
报告分析
①山推股份和大连重工的营业收入常年领先,但是他们的每股收益却不是很多,说明这两个公司是在公司运营规模上
超过了其他几家公司,但是收益规模比并不是很高,且大连重工的每股收益在2014年之后一直处于一个较低的水平。
②北方华创的营业收入和每股收益逐年增加,是一所非常具有发展潜力的企业,与之类似的还有科新机电,但是并不如北方华创稳定。
③迪瑞医疗的每股收益在2018年之前一直处于领先,在18年之后逐渐弱于北方华创和康泰医学。
学习总结
完成大作业的过程中确实学到了很多东西。最让我印象深刻的一点就是在爬取160家公司年报链接并下载的过程。
当时还在固执的使用自己原来的作业三代码,但实际上那个代码的爬取效率是非常低的,无法满足如此大量的爬取以及下载需求。
在参考了其他同学的作业三代码后,优化了自己的代码以及爬取下载方案,也是深刻体会到了在写代码的过程中函数模块的重要性,
如果可以多使用函数模块写代码,可以大大提高代码的运行效率、普适性、可读性,修改起来也很方便。
~~~~~~~~The End~~~~~~~~