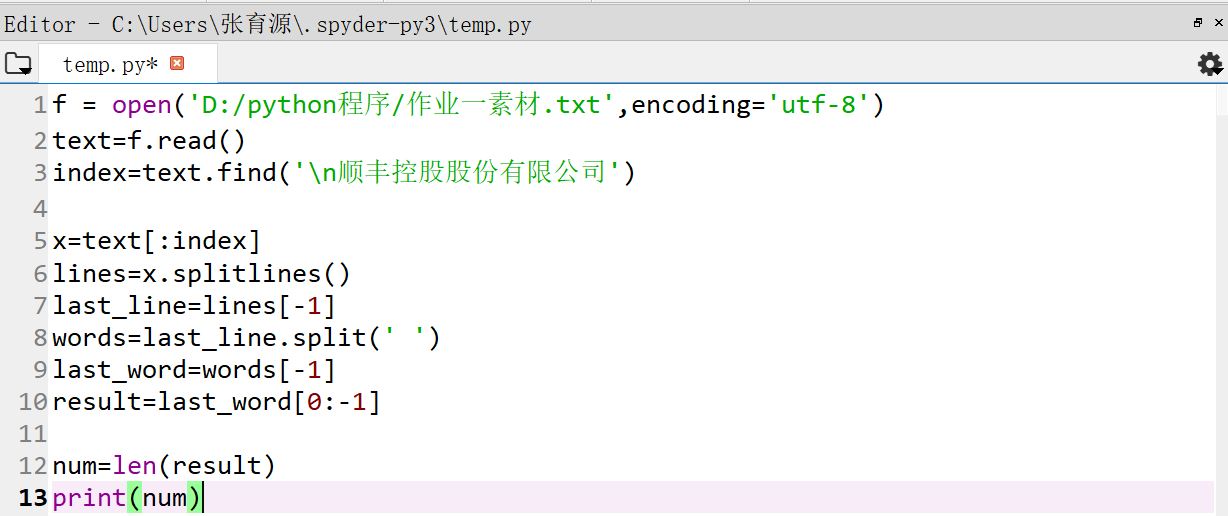
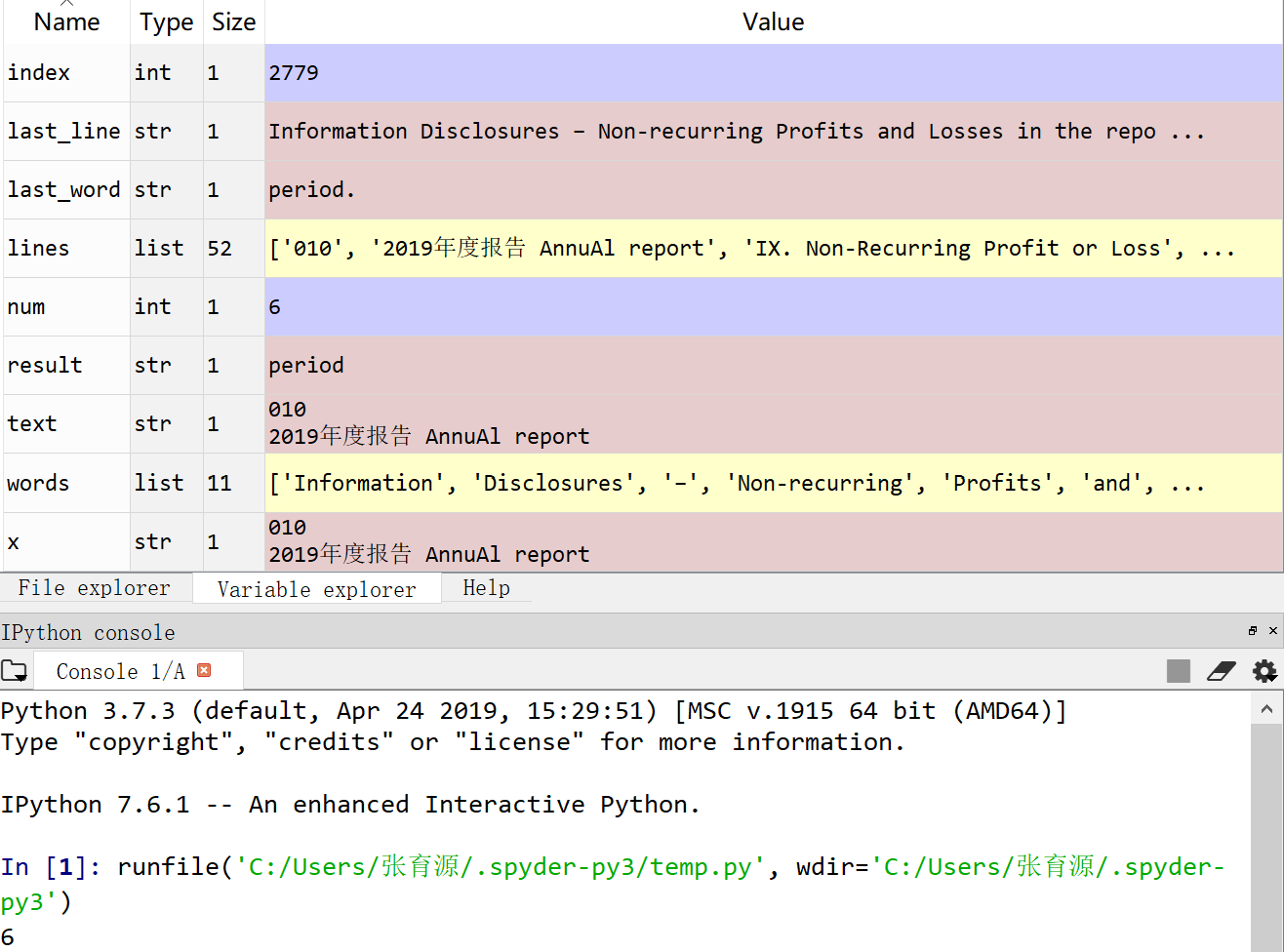
f = open('D:/python程序/作业一素材.txt',encoding='utf-8')
text=f.read()
index=text.find('\n顺丰控股股份有限公司')
x=text[:index]
lines=x.splitlines()
last_line=lines[-1]
words=last_line.split(' ')
last_word=words[-1]
result=last_word[0:-1]
num=len(result)
print(num)