import re
f = open('作业一素材.txt', mode='r', encoding='utf-8')
txt = f.read()
f.close()
lines = txt.splitlines() #分割句子
a = lines[-3] #提取最后一个句子(不考虑页脚)
words = re.split("\s",a) #分割单词
word1 = words[-1] #提取最后一个单词(带标点)
word2 = re.split(r'[.]', word1) #分割单词和标点符号
word = word2[0] #提取单词
length = len(word) #计算长度
print(length)
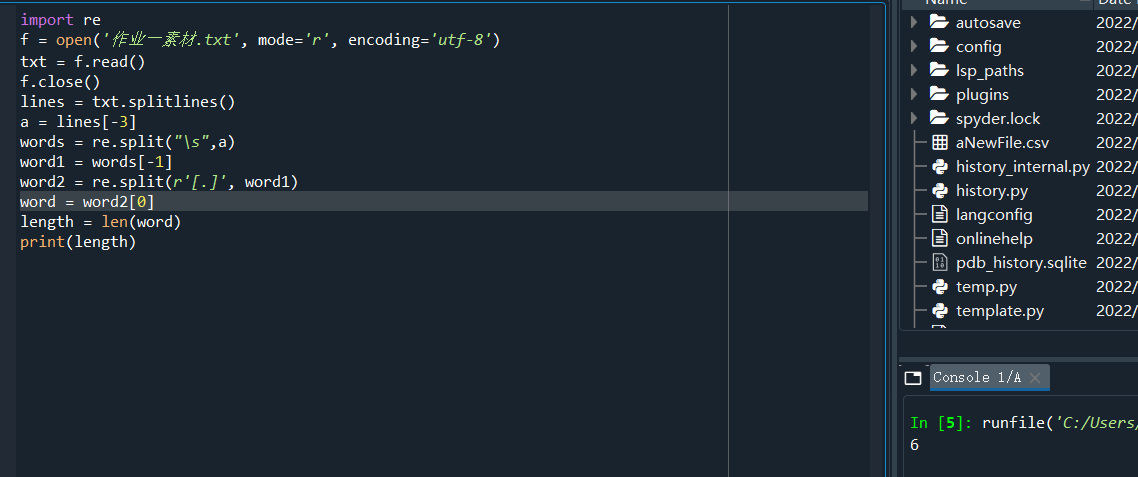
见注释