import pandas as pd #导入模块
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告")#更改工作目录
df=pd.read_excel(r"Company.xlsx",converters={u"code":str})#导入要分析的公司
Company_sz = df.iloc[:22,1] #需要研究的深圳证券交易所上市公司的名单
Company_sh = df.iloc[22:,0] #需要I上海证券交易所上市的公司名单
print("需要分析的深圳证券交易所上市的公司是:","\n",Company_sz)
print("需要分析的上海证券交易所上市的公司是:","\n",Company_sh)#上海证券交易所的输入框输入证券代码才可以查询
需要分析的深圳证券交易所上市的公司是: 0 洪兴股份 1 伟星股份 2 七匹狼 3 报喜鸟 4 美邦服饰 5 星期六 6 嘉欣丝绸 7 嘉麟杰 8 搜于特 9 森马服饰 10 ST步森 11 朗姿股份 12 棒杰股份 13 ST摩登 14 乔治白 15 金发拉比 16 汇洁股份 17 比音勒芬 18 安奈儿 19 欣贺股份 20 探路者 21 酷特智能 Name: name, dtype: object 需要分析的上海证券交易所上市的公司是: 22 600107 23 600137 24 600146 25 600177 26 600398 27 600400 28 601566 29 601718 30 603157 31 603196 32 603511 33 603518 34 603555 35 603587 36 603808 37 603839 38 603877 Name: code, dtype: object
def Inputtime(start,end):#定义输入开始和截至时间的函数
START = browser.find_element(By.CLASS_NAME,"input-left")
END = browser.find_element(By.CLASS_NAME,"input-right")
START.send_keys(start)
END.send_keys(end+Keys.RETURN)
def Clear(): #定义清除所选内容的函数
browser.find_element(By.CLASS_NAME,"btn-clearall").click()
def Inputcode(name):#输入公司的名称
In = browser.find_element(By.ID,"input_code")
In.send_keys(name+Keys.RETURN)
def Choose_an():#选择年度报告
browser.find_element(By.LINK_TEXT,"请选择公告类别").click()
browser.find_element(By.LINK_TEXT,"年度报告").click()
def Save(filename,content):
f = open(filename+'.html','w',encoding='utf-8')
f.write(content)
f.close()
browser = webdriver.Firefox()
browser.get("http://www.szse.cn/disclosure/listed/fixed/index.html")
time.sleep(5)
os.getcwd()
'C:\\Users\\冰雪飘\\Documents\\python files\\pachong\\爬取年报_实验报告'
End = time.strftime('%Y-%m-%d', time.localtime()) #在python中执行过,把html文件下载下来了,截图如下所示
Inputtime('2012-10-01',End)
for company in Company_sz.values:
time.sleep(1)
Choose_an()#选择年度报告
Inputcode(company)#输入公司名称
time.sleep(2)#延迟2秒执行
html = browser.find_element(By.ID,"disclosure-table")
time.sleep(5)
innerHTML = html.get_attribute("innerHTML")
Save(company,innerHTML)
Clear()
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
#
p_a = re.compile('<a.*?>(.*?)</a>', re.DOTALL)
p_span = re.compile('<span.*?>(.*?)</span>', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
#
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('<tr>(.*?)</tr>', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
def get_link(self, txt):
p_txt = '<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span>'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
f = open(filename+'.html', encoding='utf-8')
html = f.read()
f.close()
return html
def Clean(df):#清除“摘要”型、“(已取消)”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告\html\html_sz")
for company in Company_sz.values: #下载深圳证券交易所的年报
html = Readhtml(company)
dt = DisclosureTable(html)
dt1 = dt.get_data()
df = Clean(dt1)
df.to_csv("../../df/"+company+".csv",encoding="utf-8-sig")#将csv文件保存到df目录下
os.makedirs("../../nb_sz/"+company,exist_ok=True)#将年报保存到该文件夹
os.chdir("../../nb_sz/"+company)
Loadpdf(df)
os.chdir("../../html/html_sz")#回到保存html的文件夹
print(company,"公司年报已保存完毕")
洪兴股份 公司年报已保存完毕 伟星股份 公司年报已保存完毕 七匹狼 公司年报已保存完毕 报喜鸟 公司年报已保存完毕 美邦服饰 公司年报已保存完毕 星期六 公司年报已保存完毕 嘉欣丝绸 公司年报已保存完毕 嘉麟杰 公司年报已保存完毕 搜于特 公司年报已保存完毕 森马服饰 公司年报已保存完毕 ST步森 公司年报已保存完毕 朗姿股份 公司年报已保存完毕 棒杰股份 公司年报已保存完毕 ST摩登 公司年报已保存完毕 乔治白 公司年报已保存完毕 金发拉比 公司年报已保存完毕 汇洁股份 公司年报已保存完毕 比音勒芬 公司年报已保存完毕 安奈儿 公司年报已保存完毕 欣贺股份 公司年报已保存完毕 探路者 公司年报已保存完毕 酷特智能 公司年报已保存完毕

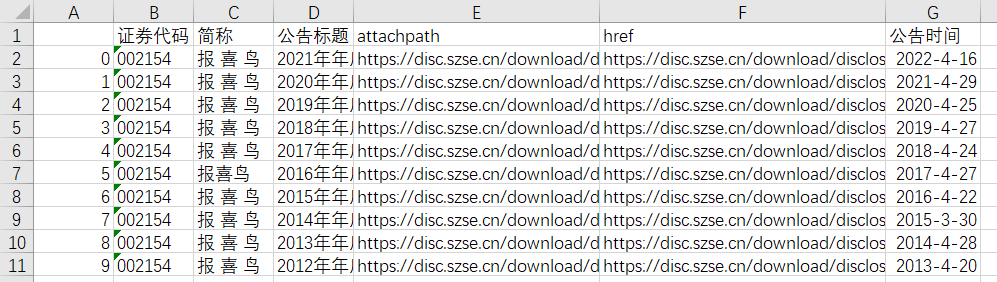
def Time_start():#定义一个公式选择2013-01-01到2016-01-01的日期
web.find_element(By.XPATH,"/html/body/div[8]/div/div[1]/div/div[5]/div[2]/input").click()
web.find_element(By.CSS_SELECTOR, ".input_focus > .form-control").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 .laydate-prev-y").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(14)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 tr:nth-child(1) > td:nth-child(3)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 tr:nth-child(1) > td:nth-child(6)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()
def time_median():#定义一个公式选择2016-01-01到2019-01-01的日期
web.find_element(By.XPATH,"/html/body/div[8]/div/div[1]/div/div[5]/div[2]/input").click()
web.find_element(By.CSS_SELECTOR, ".input_focus > .form-control").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 tr:nth-child(1) > td:nth-child(6)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 tr:nth-child(1) > td:nth-child(3)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()
def time_m2(): #时间设置为2019-1-1至2022-1-1日
web.find_element(By.XPATH,"/html/body/div[8]/div/div[1]/div/div[5]/div[2]/input").click()
web.find_element(By.CSS_SELECTOR, ".input_focus > .form-control").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(5)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 tr:nth-child(1) > td:nth-child(3)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-1 tr:nth-child(1) > td:nth-child(7)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()
def time_end(): #爬取2022-1-1至今年报
web.find_element(By.XPATH,"/html/body/div[8]/div/div[1]/div/div[5]/div[2]/input").click()
web.find_element(By.CSS_SELECTOR, ".input_focus > .form-control").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 span:nth-child(2)").click()
web.find_element(By.CSS_SELECTOR, ".layui-laydate-list > li:nth-child(1)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-main-list-0 tr:nth-child(1) > td:nth-child(7)").click()
web.find_element(By.CSS_SELECTOR, ".laydate-btns-confirm").click()
def Inputname(name):
In = web.find_element(By.ID, "inputCode").send_keys(name)
en = web.find_element(By.ID,"inputCode").send_keys(Keys.ENTER)
def Choose():#选择年度报告
web.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
web.find_element(By.LINK_TEXT, "年报").click()
# web.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
# web.find_element(By.LINK_TEXT, "年报").click()
def Saveadd(filename,content):#追加写的模式,将同一个公司的html代码保存到同一个文件夹
f = open(filename+'.html','a',encoding='utf-8')
f.write(content)
f.close()
def Clearall():#2013-1-1至2019-1-1清楚所有内容的xpath路径
web.find_element(By.XPATH, ".bi-chevron-double-down").click()
web.find_element(By.XPATH, "/html/body/div[8]/div/div[1]/div/div[1]/ul/li[5]/a/span").click()
def Clearall2():#2019-1-1自以后的清除所有内容的xpath路径
web.find_element(By.XPATH, "/html/body/div[8]/div/div[1]/div/div[1]/span/i").click()
web.find_element(By.XPATH, "/html/body/div[8]/div/div[1]/div/div[1]/ul/li[5]/a/span").click()
web = webdriver.Firefox()
time.sleep(4)
url = "http://www.sse.com.cn/disclosure/listedinfo/regular/"
web.get(url)
p = re.compile("暂无数据")
for code in Company_sh.values: #下载2013-1-1至2016-1-1数据
Inputname(code)
time.sleep(1)
Choose()
time.sleep(3)
Time_start()
time.sleep(4)
html = web.find_element(By.XPATH,"/html/body/div[8]/div/div[2]/div/div[1]/div[1]")
innerHTML = html.get_attribute("innerHTML")
kong = p.findall(innerHTML)
if kong ==[]:
Saveadd(code,innerHTML)
Clearall()
for code in Company_sh.values: #下载2016-1-1至2019-1-1数据
Inputname(code)
time.sleep(1)
Choose()
time.sleep(3)
time_median()
time.sleep(4)
html = web.find_element(By.XPATH,"/html/body/div[8]/div/div[2]/div/div[1]/div[1]")
innerHTML = html.get_attribute("innerHTML")
kong = p.findall(innerHTML)
if kong ==[]:
Saveadd(code,innerHTML)
Clearall()
for code in Company_sh.values: #下载2019-1-1至2022-1-1数据
Inputname(code)
time.sleep(1)
Choose()
time.sleep(3)
time_m2()
time.sleep(4)
html = web.find_element(By.XPATH,"/html/body/div[8]/div/div[2]/div/div[1]/div[1]")
innerHTML = html.get_attribute("innerHTML")
kong = p.findall(innerHTML)
if kong ==[]:
Saveadd(code,innerHTML)
Clearall2()
for code in Company_sh.values: #下载2022-1-1至今数据
Inputname(code)
time.sleep(1)
Choose()
time.sleep(3)
time_end()
time.sleep(4)
html = web.find_element(By.XPATH,"/html/body/div[8]/div/div[2]/div/div[1]/div[1]")
innerHTML = html.get_attribute("innerHTML")
kong = p.findall(innerHTML)
if kong ==[]:
Saveadd(code,innerHTML)
Clearall2()
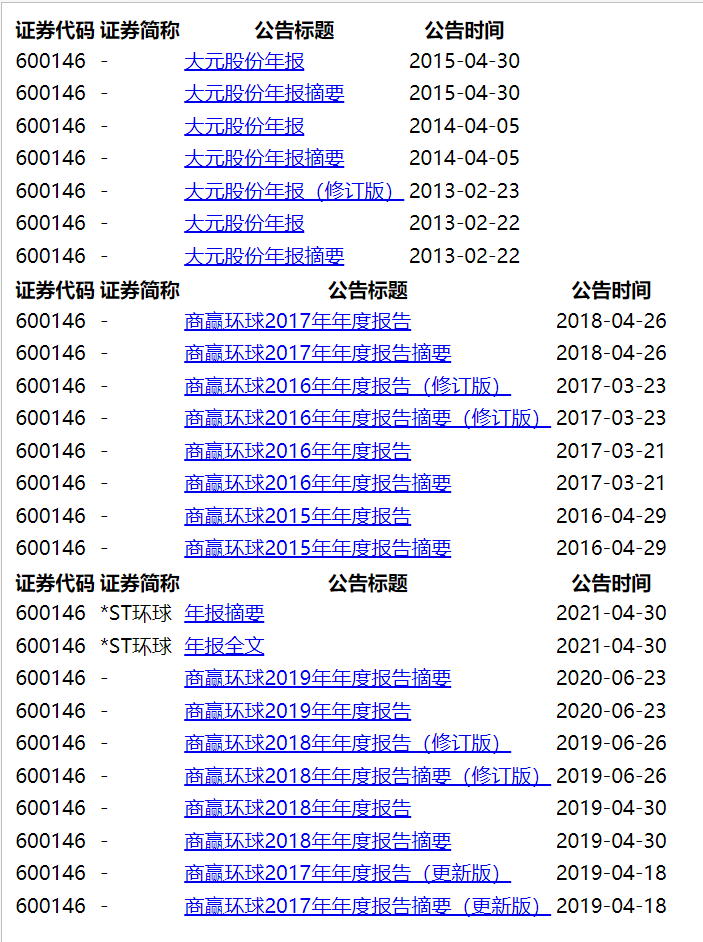
def Clearblank(lst):#清除空列表
chart=[]
for ls in lst:
if ls !=[]:
chart.append(ls)
return chart
def gain_df(txt):
p=re.compile("<tr.*?>(.*?)</tr>")
p1=re.compile("<td.*?>(.*?)</td>")
trs =p.findall(txt)
tds = [p1.findall(tr) for tr in trs]
tds = Clearblank(tds)
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return df
def gain_link(txt):
p_a = re.compile('<a.*?href="(.*?)".*?>(.*?)</a>')
matchObj = p_a.search(txt)
href= matchObj.group(1).strip()
title = matchObj.group(2).strip()
return([href, title])
p_span = re.compile('<span.*?>(.*?)</span>', re.DOTALL)
gain_cn = lambda txt: p_span.search(txt).group(1)#定义一个函数获得证券的代码和简称
def gain_data(df_txt):
prefix = "http://static.sse.com.cn/"
df = df_txt
codes = [gain_cn(dt) for dt in df["证券代码"]]
short_names = [gain_cn(dt) for dt in df["简称"]]
ahts =[gain_link(dt) for dt in df["公告标题"]]
times = [time for time in df["公告时间"]]
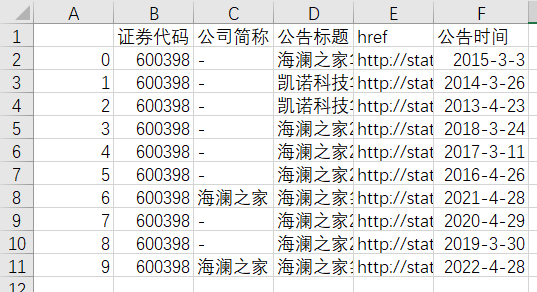
df = pd.DataFrame({"证券代码":codes,
"公司简称":short_names,
"公告标题":[aht[1] for aht in ahts],
"href":[prefix + aht[0]for aht in ahts],
"公告时间":times})
return df
def Short_Name(df):#获得上海证券交易所公司的简称
for i in df["公司简称"]:
i=i.replace("*","") #有些公司的简称以*开头,用来命名会报错,把*去掉
if i !="-":
sn=i
return sn
def Loadpdf_sh(df):#用于下载文件
d1 = {}
df["公告时间"] = pd.to_datetime(df["公告时间"])
name = Short_Name(df)
for index, row in df.iterrows():
na = name+str(row[4].year-1)+"年年度报告" #由于上海证券交易所的年度报告命名年与年之间差别大,因此自己定义新的命名格式
d1[na] = row[3]
for key, value in d1.items():
f = requests.get(value)
fo = open (key+".pdf", "wb")
fo.write(f.content)
def filter_links(words,df,include=True):#将带“(”的年报标题和没带“(”的年报分离出来
ls=[]
for word in words:
if include:
ls.append([word in f for f in df["公告标题"]])
else:
ls.append([word not in f for f in df["公告标题"]])
index = []
for r in range(len(df)):
flag = not include
for c in range(len(words)):
if include:
flag = flag or ls[c][r]
else:
flag = flag and ls[c][r]
index.append(flag)
df= df[index]
return(df)
def new_df(df_orig,df_updt):#保留修订年报,删除同年的其他年报
kk=[]
df_orig = df_orig.reset_index()
df_updt = df_updt.reset_index()
df_orig =df_orig.iloc[:,1:]
df_updt = df_updt.iloc[:,1:]
for date in df_updt["公告时间"]:
year1 = date[:4]
for index,row in df_orig.iterrows():
year2 = row[4][:4]
if year2 == year1:
kk.append(index)
df_orig = df_orig.drop(kk)
df = pd.concat([df_orig,df_updt],axis=0)
df=df.reset_index()
df = df.iloc[:,1:]
return df
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告\html\html_sh")
for company in Company_sh.values:#下载上海证券交易所年报的循环
txt =Readhtml(company)
txt_df = gain_df(txt)
data= gain_data(txt_df)
df_all = filter_links(["摘要","社会责任","审计","财务","风险","债券","图文","董事","意见","监事"],data,include= False)
df_orig = filter_links(["(","("],df_all,include = False)
df_updt = filter_links(["(","("],df_all,include = True)
df1 = new_df(df_orig,df_updt)#保留修订年报,删除同年的其他年报
name = Short_Name(df1)
df1.to_csv("../../df/df_sh/"+name+".csv",encoding="utf-8-sig")#保存df文件
os.makedirs("../../nb_sh/"+name,exist_ok=True)#创建保存年报的文件夹
os.chdir("../../nb_sh/"+name)#更改当前的工作目录
Loadpdf_sh(df1)#下载年报
os.chdir("../../html/html_sh")#回到保存了html文件的文件夹
print(company,"公司年报已保存完毕")
600107 公司年报已保存完毕 600137 公司年报已保存完毕 600146 公司年报已保存完毕 600177 公司年报已保存完毕 600398 公司年报已保存完毕 600400 公司年报已保存完毕 601566 公司年报已保存完毕 601718 公司年报已保存完毕 603157 公司年报已保存完毕 603196 公司年报已保存完毕 603511 公司年报已保存完毕 603518 公司年报已保存完毕 603555 公司年报已保存完毕 603587 公司年报已保存完毕 603808 公司年报已保存完毕 603839 公司年报已保存完毕 603877 公司年报已保存完毕