import pandas as pd
import fitz
import re
import os
def Short_Name(df):#获得上海证券交易所公司的简称
for i in df["公司简称"]:
i=i.replace("*","")
if i !="-":
sn=i
return sn
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告")
Company=pd.read_excel('Company.xlsx').iloc[:,1:] #读取保存的公司名文件
company=Company.iloc[:,0].tolist()#转为列表
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告\df\df_sz")#更改路径到储存年报的df文件夹下
t=0
for com in company[:22]:#前22个公司的年报发布在深圳证券交易所
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
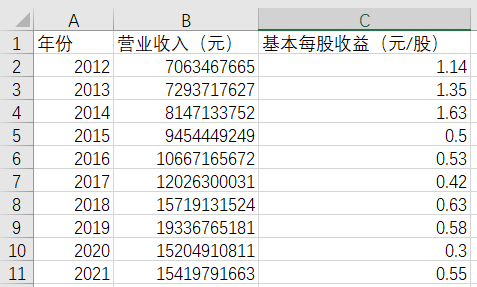
final = pd.DataFrame(index=range(2012,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('../../nb_sz/%s/%s.pdf'%(com,title))#打开储存在nb_sz文件夹的年报
text=''
for j in range(15): #需要提取的指标在前15页之前的页码,因此读取每份年报前15页的数据
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
text=text.replace(".\n",".")
p_rev = re.compile(r'(?<=\n)营业总?收入\(?(?\w?)?\)?[\x7f]?\s?\n?([\d+,.]*)\s?\n?')#匹配营业收入
p_eps = re.compile('(?<=\n)基本每股收益\s*(元/?/?\n?股)[\x7f]?\s?\n?([-\d+,.]*)\s?\n?')#匹配基本每股收益
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)#匹配办公地址
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./\-:]*)\s?(?=\n)',re.DOTALL) #匹配公司网址
text=text.replace(".\n",".")#替换掉里面的换行符
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
eps=p_eps.search(text).group(1)
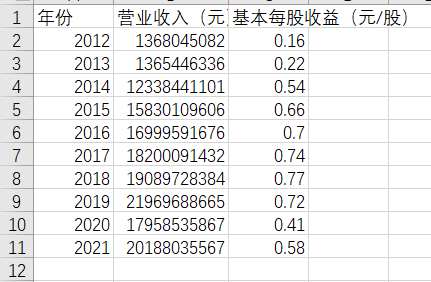
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('../../营业收入/sz/%s.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地文件
site=p_site.search(text).group(1) #匹配办公地址和网址,取最近一年。
web=p_web.search(text).group(1)
f = open('../../营业收入/sz/【%s】.csv'%com,'a',encoding='utf-8-sig') #把股票简称,代码,办公地址和网址写入csv文件
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
f.close()
print(name+'数据已保存完毕'+'(',t,'/',len(company[:22]),')')
洪兴股份数据已保存完毕( 1 / 22 ) 伟星股份数据已保存完毕( 2 / 22 ) 七匹狼数据已保存完毕( 3 / 22 ) 报喜鸟数据已保存完毕( 4 / 22 ) 美邦服饰数据已保存完毕( 5 / 22 ) 星期六数据已保存完毕( 6 / 22 ) 嘉欣丝绸数据已保存完毕( 7 / 22 ) 嘉麟杰数据已保存完毕( 8 / 22 ) 搜于特数据已保存完毕( 9 / 22 ) 森马服饰数据已保存完毕( 10 / 22 ) ST步森数据已保存完毕( 11 / 22 ) 朗姿股份数据已保存完毕( 12 / 22 ) 棒杰股份数据已保存完毕( 13 / 22 ) ST摩登数据已保存完毕( 14 / 22 ) 乔治白数据已保存完毕( 15 / 22 ) 金发拉比数据已保存完毕( 16 / 22 ) 汇洁股份数据已保存完毕( 17 / 22 ) 比音勒芬数据已保存完毕( 18 / 22 ) 安奈儿数据已保存完毕( 19 / 22 ) 欣贺股份数据已保存完毕( 20 / 22 ) 探路者数据已保存完毕( 21 / 22 ) 酷特智能数据已保存完毕( 22 / 22 )
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告")
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告")
Company=pd.read_excel('Company.xlsx').iloc[:,1:] #读取上一步保存的公司名文件
company=Company.iloc[:,0].tolist()#转为列表
os.chdir(r"C:\Users\冰雪飘\Documents\python files\pachong\爬取年报_实验报告\df\df_sh")
t=0
for com in company[22:]:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2012,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = Short_Name(df).replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=name+str(2021-i)+"年年度报告"
doc = fitz.open('../../nb_sh/%s/%s.pdf'%(com,title))
text=''
for j in range(15): #读取每份年报前15页的数据
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?\n?(20\d{2})\s?.*?\n?年\n?度\n?报\n?告\n?.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile(r'(?<=\n)营业总?收入\s?\(?(?\w?)?\)?[\x7f]?\s?\n+([\d+,.]*)\s?\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?\s?╱?\s?/?\n?股)[\x7f]?\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址\s?:?\s?\n?([a-zA-Z./\-:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
eps=p_eps.search(text).group(1)
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('../../营业收入/sh/%s.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
site=p_site.search(text).group(1) #匹配办公地址和网址,取最近一年的。
web=p_web.search(text).group(1)
f = open('../../营业收入/sh/【%s】.csv'%com,'a',encoding='utf-8-sig') #把股票简称,代码,办公地址和网址写入csv文件
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
f.close()
print(name+'数据已保存完毕'+'(',t,'/',len(company[22:]),')')
美尔雅数据已保存完毕( 1 / 17 ) 浪莎股份数据已保存完毕( 2 / 17 ) ST环球数据已保存完毕( 3 / 17 ) 雅戈尔数据已保存完毕( 4 / 17 ) 海澜之家数据已保存完毕( 5 / 17 ) 红豆股份数据已保存完毕( 6 / 17 ) 九牧王数据已保存完毕( 7 / 17 ) 际华集团数据已保存完毕( 8 / 17 ) ST拉夏数据已保存完毕( 9 / 17 ) 日播时尚数据已保存完毕( 10 / 17 ) 爱慕股份数据已保存完毕( 11 / 17 ) 锦泓集团数据已保存完毕( 12 / 17 ) ST贵人数据已保存完毕( 13 / 17 ) 地素时尚数据已保存完毕( 14 / 17 ) 歌力思数据已保存完毕( 15 / 17 ) 安正时尚数据已保存完毕( 16 / 17 ) 太平鸟数据已保存完毕( 17 / 17 )