# -*- coding: utf-8 -*-
"""
Created on Fri Jun 3 20:58:56 2022
@author: lenovomp10
"""
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
from bs4 import BeautifulSoup
import pdfplumber
import json
#面向对象定义所需函数
def SZ(data):
sz=['200','300','301','00','080']
lst = [ x for x in data for startcode in sz if x[3].startswith(startcode)==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
return df
def SH(data): #上交所股票代码6开头
lst = [ x for x in data if x[3].startswith('6')==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
return df
def Getcompany(matched,df):
df_final = pd.DataFrame()
df_final = df.loc[df['行业大类代码']==matched[0]]
return df_final
def Match(Namelist,industry):
match = pd.DataFrame()
for name in Namelist:
match = pd.concat([match,industry.loc[industry['完成人']==name]])
Number = match['行业'].tolist()
return Number
def INPUTNAME():
Names = str(input('please input name:'))
Namelist = Names.split()
return Namelist
def cleanst(lst): #st公司处理
for i in range(len(lst)):
lst[i] = lst[i].replace('*','')
return lst
'''
利用selenium爬取所需公司年报
'''
#根据个人浏览器定义函数里的browser
#爬取上交所
def get_and_download_pdf_file():
url = 'http://query.sse.com.cn/commonQuery.do?jsonCallBack=jsonpCallback97417902&isPagination=true&pageHelp.pageSize=25&pageHelp.cacheSize=1&type=inParams&sqlId=COMMON_PL_SSGSXX_ZXGG_L&START_DATE=2021-06-15&END_DATE=2021-09-15&SECURITY_CODE=&TITLE=&BULLETIN_TYPE=00%2C0101%2C0102%2C0104%2C0103&pageHelp.pageNo=2&pageHelp.beginPage=2&pageHelp.endPage=2&_=1631613647901'
referer = 'http://www.sse.com.cn/'
response = requests.get(url=url, headers={'Referer': referer})
json_data = response.text.split('(')[-1].replace(')', '')
format_data = json.loads(json_data)
for every_report in format_data['result']:
source_pdf_url = 'http://static.sse.com.cn' + every_report['URL']
pdf_url = source_pdf_url.split('
')[0]
# print(pdf_url)
file_name = every_report['TITLE'].split('
')[0] + '.pdf'
# print(file_name)
pdf_file = requests.get(pdf_url, stream=True)
with open(file_name, 'wb') as f:
# f.write(pdf_file.content)
for chunk in pdf_file.iter_content(1024):
f.write(chunk)
print('上市公司报告:%s' % file_name + "已经完成下载")
def timeofpdf(start,end): #找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): #找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code') # Find the search box
Searchbox.send_keys(name)
time.sleep(0.2)
Searchbox.send_keys(Keys.RETURN)
def delehistory(): #清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): #点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename,content):
with open(filename+'.html','w',encoding='utf-8') as f:
f.write(content)
'''
解析html获取年报表格
'''
class DisclosureTable():
#解析深交所定期报告页搜索表格
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def sina_to_dataframe(filename):
f = open(filename+'.html',encoding='utf-8')
html = f.read()
f.close()
p_time=re.compile('(\d{4})(-\d{2})(-\d{2})')
times=p_time.findall(html)
y=[int(t[0]) for t in times]
m=[t[0]+t[1].replace('0','') for t in times]
d=[t[0]+t[1]+t[2] for t in times]
soup = BeautifulSoup(html,features="html.parser")
links = soup.find_all('a')
href=[]
Code=[]
Name=[]
Title=[]
Href=[]
Year=[]
p_id=re.compile('&id=(\d+)')
for link in links:
Title.append(link.text)
href.append(link.get('href'))
for n in range(0,len(Title)):
Code.append(code)
Name.append(name)
matchedID=p_id.search(href[n]).group(1)
Href.append('http://file.finance.sina.com.cn/211.154.219.97:9494/MRGG/CNSESH_STOCK/%s/%s/%s/%s.PDF'
%(str(y[n]),m[n],d[n],matchedID))
Year.append(y[n])
df=pd.DataFrame({'代码':Code,
'简称':Name,
'公告标题':Title,
'链接':Href,
'年份':Year})
df=df[df['年份']>=2011]
return df
#过滤年报并下载文件
def GEThtml(filename):
with open(filename+'.html', encoding='utf-8') as f:
html = f.read()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def loaddown(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
#进行自动爬取
pdf = pdfplumber.open('industry.pdf')
page1=pdf.pages[7]#pdf.pages[7,8]
table = page1.extract_table()
for i in range(len(table)): #填充每行的行业大类代码
if table[i][1] == None:
table[i][1] = table[i-1][1]
asign = pd.read_csv('001班行业安排表.csv',converters={'行业':str})[['行业','完成人']]
Names = INPUTNAME()
MatchedI = Match(Names,asign)
sz = SZ(table)
sh = SH(table)
df_sz = Getcompany(MatchedI,sz) #获取深交所所分配行业
df_sh = Getcompany(MatchedI,sh) #获取上交所所分配行业
Company = df_sz['上市公司简称'].tolist()
Company = cleanst(Company)
Company1 = df_sh['上市公司简称'].tolist()
Company1 = cleanst(Company1)
Company2 = df_sh[['上市公司代码','上市公司简称']]
My_Company=pd.Series(Company+Company1)
My_Company.to_csv('company.csv',encoding='utf-8-sig') #将分配到的所有公司保存到本地文件
print('\n(爬取中......)')
browser = webdriver.Edge()#这里别忘了根据个人浏览器选择
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
timeofpdf('2012-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
#在深交所官网爬取深交所上市公司年报链接
for name in Company:
SearchCompany(name)
time.sleep(0.5) # 延迟执行1秒,等待网页加载
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
delehistory()
#在新浪财经爬取上交所上市公司年报下载链接
for index,row in Company2.iterrows():
code = row[0]
name = row[1].replace('*','')
browser.get('https://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/%s/page_type/ndbg.phtml'%code)
html = browser.find_element(By.CLASS_NAME, 'datelist')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
browser.quit()
print('正在下载深交所上市公司年报')
for name in Company: #下载在深交所上市的公司的年报
html = GEThtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
loaddown(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司,当前第',Company.index(name)+1,'所。')
os.chdir('../')
print('正在下载上交所上市公司年报')
i=0
for index,row in Company2.iterrows():
i+=1
name= row[1].replace('*','')
html = GEThtml(name)
df = sina_to_dataframe(name)
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
loaddown(df1)
print(name+'年报已保存完毕。共',len(Company2),'所公司,当前第',i,'所。')
os.chdir('../')
注:
保存下来的纺织行业的pdf年报
import fitz
import re
import pandas as pd
doc = fitz.open('SF2021.pdf')
class NB():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages = {}
jie_title = {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for p in pages:
page = self.doc[p]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = p
break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
def parse_revenue_table(self):
page_number = self.key_fin_data_page
page = self.doc[page_number]
txt = page.get_text()
#
pt = '(.*?)(20\d{2}年)\s*(20\d{2}年)\s*(.*?)\s*(20\d{2}年)\s*'
pt = '(?<=主要会计数据和财务指标)' + pt + '(?=营业收入)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0] # 获取标题行
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[:txt.find('总资产')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[3] for t in data],
title[4]: [t[4] for t in data]})
# return((df,title))
self.revenue_table = df
return(df)
sf2021 = NB('SF2021.pdf')
# sf2021.jie_pages_title()
jie_pages = sf2021.jie_pages
jie_title = sf2021.jie_title
df = sf2021.parse_revenue_table()
Company=pd.read_csv('company.csv').iloc[:,1:] #读取上一步保存的公司名文件并转为列表
company=Company.iloc[:,0].tolist()
t=0
for com in company:
t+=1
com = com.replace('*','')
df = pd.read_csv(com+'.csv',converters={'证券代码':str}) #读取存有公告名称的csv文件用来循环访问pdf年报
df = df.sort_index(ascending=False)
final = pd.DataFrame(index=range(2011,2022),columns=['营业收入(元)','基本每股收益(元/股)']) #创建一个空的dataframe用于后面保存数据
final.index.name='年份'
code = str(df.iloc[0,1])
name = df.iloc[-1,2].replace(' ','')
for i in range(len(df)): #循环访问每年的年报
title=df.iloc[i,3]
doc = fitz.open('./%s/%s.pdf'%(com,title))
text=''
for j in range(15): #读取每份年报前15页的数据(一般财务指标读15页就够了,全部读取的话会比较耗时间)
page = doc[j]
text += page.get_text()
p_year=re.compile('.*?(\d{4}) .*?年度报告.*?') #捕获目前在匹配的年报年份
year = int(p_year.findall(text)[0])
#设置需要匹配的四种数据的pattern
p_rev = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
p_eps = re.compile('(?<=\n)基本每股收益(元/?/?\n?股)\s?\n?([-\d+,.]*)\s?\n?')
p_site = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
p_web =re.compile('(?<=\n)公司\w*网址:?\s?\n?([a-zA-Z./:]*)\s?(?=\n)',re.DOTALL)
revenue=float(p_rev.search(text).group(1).replace(',','')) #将匹配到的营业收入的千分位去掉并转为浮点数
if year>2011:
pre_rev=final.loc[year-1,'营业收入(元)']
if pre_rev/revenue>2:
print('%s%s营业收入下跌超过百分之50,可能出现问题,请手动查看'%(com,title))
eps=p_eps.search(text).group(1)
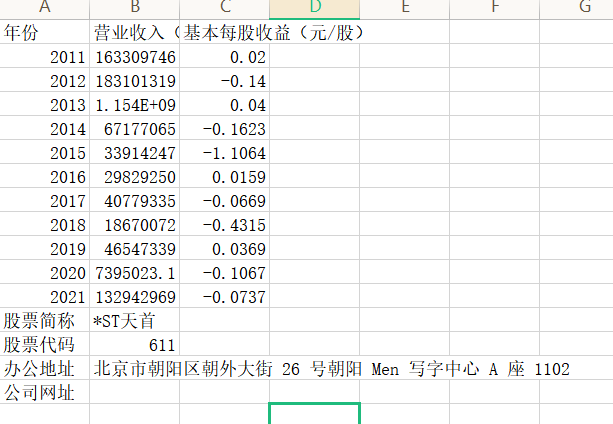
final.loc[year,'营业收入(元)']=revenue #把营业收入和每股收益写进最开始创建的dataframe
final.loc[year,'基本每股收益(元/股)']=eps
final.to_csv('【%s】.csv' %com,encoding='utf-8-sig') #将各公司数据存储到本地测csv文件
#把办公地址和网址,股票简称,代码,办公地址和网址写入文件
site=p_site.search(text).group(1)
web=p_web.search(text).group(1)
with open('【%s】.csv'%com,'a',encoding='utf-8-sig') as f:
content='股票简称,%s\n股票代码,%s\n办公地址,%s\n公司网址,%s'%(name,code,site,web)
f.write(content)
print(name+'当前保存第'+'(',t,"家公司",'共',len(company),'家')

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import numpy.random as npr
plt.rcParams['font.sans-serif']=['SimHei'] #确保显示中文
plt.rcParams['axes.unicode_minus'] = False #确保显示负数的参数设置
##第一步处理数据
#导入数据,并将csv文件数据导入数据框
data=pd.read_csv(r'C:\Users\lenovomp10\Desktop\新建文件夹\company.csv',header=0,index_col=0)
DATA=data.iloc[:,0].tolist()
dflist=[]
for name in DATA:
df=pd.read_csv('【'+name+'】.csv')
dflist.append(df)
#年份为索引
comps = len(dflist)
for i in range(comps):
dflist[i]=dflist[i].set_index('年份')
#挑选出营业收入最高的十家,构造数据框,再绘图
#纵向对比
df1=pd.DataFrame(columns=['营业收入'])
for i in range (len(dflist)):
df1.loc[dflist[i].loc['股票简称','营业收入(元)'],'营业收入']=dflist[i].iloc[:11,0].astype(float).sum()
rank=df1.sort_values("营业收入",ascending=False)
top10=rank.head(10)#选出收入最高的十家
#接下来用构造出用于画图的数据
top=[top10.index]
topna=top10.index.tolist()
topna[2]='鲁泰A'
#将十家公司的营业收入,每股收益导入新创建的数据框中
indexes=[]
for idx in topna:
indexes.append(DATA.index(idx))
datalist=[]
datalist1=[]
for i in indexes: #在dflist里选出所需公司的营业收入数据
datalist.append(pd.DataFrame(dflist[i].iloc[:11,0]))
for df in datalist:
df.index=df.index.astype(int)
df['营业收入(元)']=df['营业收入(元)'].astype(float)/1000000000
for i in indexes: #在dflist里选出所需公司的每股收益数据
datalist1.append(pd.DataFrame(dflist[i].iloc[:11,1]))
for df in datalist1:
df.index=df.index.astype(int)
df['基本每股收益(元/股)']=df['基本每股收益(元/股)'].astype(float)
shouru=pd.concat(datalist,axis=1) #将所有公司的df合并成汇总表
eps=pd.concat(datalist1,axis=1)
shouru.columns=top10.index
eps.columns=top10.index
shouru
eps
#画图进行纵向比较
eps.plot(kind='bar',subplots=True,layout=(10,1),figsize=(15,20),xlabel='年份',ylabel='eps(元)')
shouru.plot(kind='bar',subplots=True,layout=(10,1),figsize=(15,20),xlabel='年份',ylabel='营业收入(十亿元)')
#将同一时间段的各公司进行横向比较
shouruup=shouru.head(5)
shourudown=shouru.tail(6)
epsup=eps.head(5)
epsdown=eps.tail(6)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
ax1=shouruup.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax1.set_xlabel('年份',loc='left',fontsize=18)
ax1.set_ylabel('营业收入(十亿元)',fontsize=18)
ax1.set_title('行业内横向对比营业收入(2011-2016)',fontsize=20)
ax1.figure.savefig('收入1')
ax2=shourudown.plot(kind='bar',figsize=(16,8),fontsize=18,alpha=0.7,grid=True)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.5)
ax2.set_xlabel('年份',loc='left',fontsize=18)
ax2.set_ylabel('营业收入(十亿元)',fontsize=18)
ax2.set_title('行业内横向对比营业收入(2017-2021)',fontsize=20)
ax2.figure.savefig('收入2')
ax1=epsup.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax1.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.7)
ax1.set_xlabel('年份',loc='right',fontsize=18)
ax1.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax1.set_title('行业内横向对比基本每股收益(2011-2016)',fontsize=20)
ax1.figure.savefig('eps3')
ax2=epsdown.plot(kind='bar',figsize=(18,10),fontsize=18,grid=True,alpha=0.7)
ax2.legend(loc='best',prop={'family':'simsun', 'size': 14},framealpha=0.3)
ax2.set_xlabel('年份',loc='left',fontsize=18)
ax2.set_ylabel('基本每股收益(元/股)',fontsize=18)
ax2.set_title('行业内横向对比基本每股收益(2017-2021)',fontsize=20)
ax2.figure.savefig('eps4')
纺织业营业收入排名前十的公司的“营业收入(元)”随时间变化趋势图
纺织业营业收入排名前十的公司的“基本每股收益(元 ╱ 股)”随时间变化趋势图”

纺织业上市公司“营业收入(元)”横向对比
纺织业上市公司“基本每股收益(元 ╱ 股)”横向对比
从营业收入来看,华孚时尚和申达股份毫无疑问居于龙头地位,两家公司在过去十年的营业收入都远超同行,并且2019年之前都保持了高速增长。其他公司的营业收入与前两者相比差距越来越大,并且其他公司的营业收入增长并不明显。这充分显示了纺织行业作为传统行业,马太效应明显,即强者愈强,弱者越弱。由于纺织业处于纺织服装产业的上游,利润远少于后期加工的服装产业,且与国际水平依然存在差距,目前我国部分纺织企业仍处在发展时期,需要进行技术革新。 作为色纺纱行业的龙头,华孚时尚主营中高档色纺纱,公司为全球最大的色纺纱制造商和供应商之一,主营中高档色纺纱的同时以纱线贯通产业前后链,整合前端棉花种植、棉花加工、仓储物流等与后端袜业制造与销售。早期公司通过并购扩展色纺纱主业,2006年起向产业链上游延伸,在新疆布局棉花种植、加工、仓储、交易等,业务覆盖整个棉花供应链。2019年在新冠疫情的影响下,公司的营业收入略有下滑,2020年公司开启数智化转型,搭建纺纱产业互联网平台;另外,公司于同年成立阿大袜业,开展袜子品牌运营、贴牌加工、纱线贸易等业务,实现向产业链下游端的延伸。2020年、1H21公司总营收分别为142.32亿元(-10.42%)、85.55亿元(53.98%),其中色纺纱、网链业务贡献主要营收,1H21收入占比分别达到40%、58%。2021年,公司营业收入再次实现大幅上升。 公司注册资本4.73亿元,2007年末资产总额达27.47 亿元,净资产达17.37亿元,是一个具有棉纺织、印染、服装、线带、业用纺织品、汽车装饰、内外贸、房地产等多种经营领域的跨行业、跨地区、外向型、多功能的综合型大型企业。汽车装饰纺织是其一大特色,也是其收入的重要来源,但是由于新冠疫情影响,汽车产能和需求均受限,这种情况下其营业收入难以扭转。
这是我第一次接触python爬虫,吴老师的课程给我留下了深刻的印象,就两个字:有趣。我原本以为python编程是非常枯燥和繁琐的过程,但是吴燕丰老师的教学方式的确是令我耳目一新的,老师不一味拘泥于编程规则的教学,而总是以实践为指路明灯,给人一种从高山之巅俯视大地的感觉, 了解了这些理论和实际,我们在编程时就更加明白了学习python的出发点,极大地调动了我们学习的积极性。 在学习过程中我熟悉编程规则的过程可谓是一波三折,但在老师和同学的帮助下困难都一一克服了。
通过这门课程的学习,我了解了python数据获取和处理的先进之处,老师生动的将python称作“人工智能语言”“未来语言”。
Python语言的巨大优势在于它有着丰富的拓展模块,本次课程我对于selenium,request,beautifulsoup,pdfplumber,matplotlib库等模块都有了一定的了解,有一句话叫‘人生苦短,我学python’,我想这么说也
许是由于python广泛的应用场景。我进一步了解了爬虫的原理,这不是个容易的过程,在课程中亲自上手对年报数据进行处理,这种满满的收获感是无以言表的。
我非常庆幸有吴老师这么一个领路人,将我领入金融数据获取和处理的大门。老师“多练多想”的教诲我一直铭记在心,功不唐捐,玉汝于成,这也是我一直坚信的,我会在今后的学习中践行这种理念。最后,衷心祝愿老师工作顺利,幸福快乐。
PART6 附件